複製概觀#
MySQL 內建的 Replication(複製)是建構大規模、高效能應用程式的基石,採用所謂的「scale-out」架構。複製可讓一個或多個伺服器作為另一台伺服器的 replica(從庫),使資料與 master(主庫)保持同步。
複製不僅適用於高效能情境,也是 高可用性、可擴展性、災難復原、備份、數據分析 與 資料倉儲 等策略的核心技術。
複製解決的問題#
- 資料分佈:跨地理位置維護資料副本,頻寬需求不高,可容許間歇性連線
- 負載平衡:將讀取查詢分散到多個從庫,適合讀取密集型應用
- 備份:從庫可作為備份來源,但從庫不等於備份
- 高可用與容錯:避免 MySQL 成為單點故障
- 升級測試:在新版本從庫上測試查詢是否正常運作
複製的運作方式#
MySQL 支援兩種複製模式:statement-based replication(語句複製)與 row-based replication(行複製)。兩者都透過記錄主庫的 binary log 並在從庫重放來運作,且都是 非同步 的 — 從庫的資料不保證在任何時間點都是最新的。
複製的核心流程分為三個步驟:
- 主庫記錄變更:在每個更新資料的交易完成前,主庫將變更記錄到 binary log(二進位日誌),即使交易中的語句在執行時是交錯的,binary log 中仍是序列化寫入
- 從庫複製日誌:從庫的 I/O thread(I/O 執行緒)透過 TCP/IP 連接到主庫,啟動 binlog dump 程序,將主庫的 binary log 事件複製到自己的 relay log(中繼日誌)
- 從庫重放事件:從庫的 SQL thread(SQL 執行緒)讀取 relay log 中的事件並執行,將從庫資料更新為與主庫一致
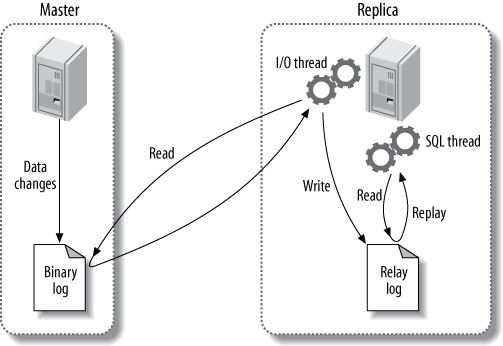
Figure 10.1: How MySQL replication works
sequenceDiagram
participant M as Master
participant IO as Replica I/O Thread
participant SQL as Replica SQL Thread
M->>M: 記錄變更到 Binary Log
IO->>M: 請求 binlog dump(TCP)
M-->>IO: 傳送 binlog 事件
IO->>IO: 寫入 Relay Log
SQL->>SQL: 讀取 Relay Log 並重放事件關鍵限制: 這種架構使得從庫的複製是 序列化 的。主庫上可能並行執行的更新,在從庫上由單一 SQL thread 逐一執行。這是許多工作負載的 效能瓶頸。
複製的效能影響#
- 主庫開銷較小,主要是 binary logging 與每個從庫的網路 I/O
- 如果從庫讀取舊的 binary log 檔案,會產生額外的磁碟 I/O 與 mutex 競爭
- 複製適合 擴展讀取,但不適合擴展寫入 — 每個從庫都必須執行所有寫入操作
- 一主十從代表 11 份相同資料,類似伺服器層級的 RAID 1,硬體利用率不高
設定複製#
建立複製帳號#
在主庫和從庫上都建立複製使用者帳號:
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.*
TO repl@'192.168.0.%' IDENTIFIED BY 'p4ssword';建議: 在兩台伺服器上都建立相同帳號。
REPLICATION CLIENT權限方便用來監控複製狀態,且從庫已預先設好帳號,日後切換主從角色更容易。
配置主庫與從庫#
主庫的 my.cnf:
log_bin = mysql-bin
server_id = 10從庫的 my.cnf:
log_bin = mysql-bin
server_id = 2
relay_log = /var/lib/mysql/mysql-relay-bin
log_slave_updates = 1
read_only = 1server_id:每台伺服器必須有唯一的 ID,建議避免使用預設值 1log_bin:明確指定 binary log 名稱,避免使用主機名稱(改名時會出問題)relay_log:指定 relay log 的位置與名稱log_slave_updates:讓從庫將收到的複製事件也寫入自己的 binary log,對容錯和級聯複製很重要read_only:防止非特權使用者在從庫上修改資料
注意: 不要在從庫的
my.cnf中放置master_host、master_port等複製設定。這是過時且已棄用的方式,會導致問題。
啟動從庫#
使用 CHANGE MASTER TO 告訴從庫如何連接主庫:
CHANGE MASTER TO MASTER_HOST='server1',
MASTER_USER='repl',
MASTER_PASSWORD='p4ssword',
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=0;
START SLAVE;使用 SHOW SLAVE STATUS\G 確認 Slave_IO_Running: Yes 和 Slave_SQL_Running: Yes。
從現有伺服器初始化從庫#
需要三樣東西:
- 主庫某個時間點的 資料快照
- 快照時的主庫 日誌座標(log file + byte offset)
- 從快照時間到當前的 binary log 檔案
常用的初始化方法:
| 方法 | 說明 | 是否需要停機 |
|---|---|---|
| Cold copy | 關閉主庫,複製檔案 | 是 |
| mysqldump | mysqldump --single-transaction --all-databases --master-data=1 --host=server1 | mysql --host=server2(適用 InnoDB) | 否 |
| 快照/備份 | 使用 LVM、SAN 或 EBS 快照 | 否 |
| Percona XtraBackup | 不中斷伺服器運作的熱備份工具,是初始化從庫的最佳選擇 | 否 |
| 從另一個從庫克隆 | 使用上述任何方法,但需用 SHOW SLAVE STATUS 取得座標 | 視方法而定 |
推薦的複製配置#
主庫設定#
sync_binlog = 1 # 每次提交交易都同步 binary log 到磁碟
innodb_flush_logs_at_trx_commit = 1 # 每次提交都刷新 InnoDB 日誌
innodb_support_xa = 1 # 確保 binary log 與 InnoDB 日誌一致
log_bin = /var/lib/mysql/mysql-bin # 明確指定路徑和名稱從庫設定#
relay_log = /path/to/logs/relay-bin # 指定 relay log 絕對路徑
skip_slave_start # 崩潰後不自動啟動複製
read_only # 防止大部分使用者修改資料MySQL 5.5 額外建議啟用:
sync_master_info = 1
sync_relay_log = 1
sync_relay_log_info = 1注意: 即使啟用所有建議選項,從庫崩潰後 relay log 和
master.info仍可能不一致,因為預設它們不是 crash-safe 的。MySQL 5.5 的 sync 選項可以改善,但有額外的fsync()開銷。
複製的內部機制#
Statement-Based Replication(SBR)#
MySQL 5.0 及更早版本僅支援 語句複製。運作方式是記錄並重放主庫上修改資料的 SQL 語句。
| 面向 | SBR | RBR |
|---|---|---|
| 實作複雜度 | 簡單 | 較複雜 |
| Binary log 大小 | 事件緊湊,頻寬需求低 | 某些情況下非常大(如全表 UPDATE) |
| 工具支援 | mysqlbinlog 使用方便 | binary log 中不包含原始 SQL,難以除錯 |
| 複製正確性 | 許多語句無法正確複製(如 CURRENT_USER()、stored procedures、triggers) | 能正確複製所有語句,包括 triggers、stored procedures |
| 鎖需求 | 需要更強的序列化,可能需要更多的鎖 | 減少鎖需求 |
| 確定性 | 非確定性語句(如帶 LIMIT 的 UPDATE)可能在主從上產生不同結果 | 記錄實際資料變更,結果確定 |
| 效率 | 某些場景較慢 | 某些場景效率更高(如大表彙總到小表) |
| 資料不一致偵測 | 可能靜默跳過 | 發現資料不一致時會停止並報錯 |
| 可見性 | SQL 語句可讀 | 事件套用是黑盒,缺少可見性 |
| 從庫 schema 變更 | 支援 | 不支援在從庫做 schema 變更 |
Row-Based Replication(RBR)#
MySQL 5.1 引入 行複製,記錄實際的資料變更而非 SQL 語句。
MySQL 可以在 SBR 與 RBR 間 動態切換(binlog_format 設定),預設使用 SBR,遇到無法正確複製的語句時自動切換為 RBR。
複製相關檔案#
| 檔案 | 說明 |
|---|---|
mysql-bin.index | 追蹤磁碟上存在的 binary log 檔案 |
mysql-relay-bin.index | relay log 的索引檔 |
master.info | 從庫連接主庫所需的資訊(含密碼明文) |
relay-log.info | 從庫當前的 binary log 和 relay log 座標 |
注意: 這些檔案不是同步寫入磁碟的,伺服器斷電後可能不準確。不要手動刪除或修改這些檔案。
將事件傳遞給下游從庫#
log_slave_updates 選項讓從庫將收到的複製事件寫入自己的 binary log,使得其他從庫可以從這台從庫複製。建議預設啟用此選項。
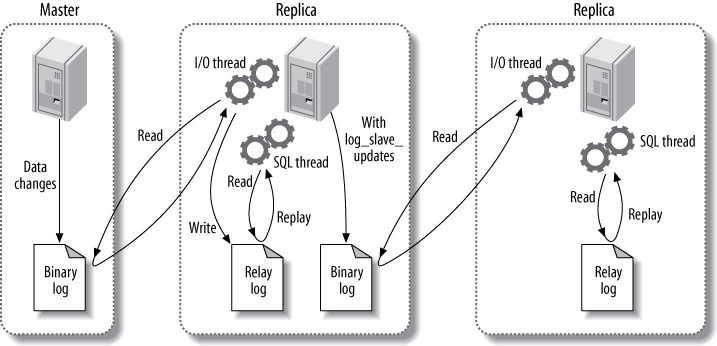
Figure 10.2: Passing on a replication event to further replicas
關鍵概念: 同一事件在不同伺服器的 binary log 中幾乎肯定在不同的位置。不能假設所有處於相同邏輯複製點的伺服器具有相同的日誌座標。MySQL 透過 server ID 來防止複製的無限迴圈 — SQL thread 會丟棄 server ID 與自己相同的事件。
複製過濾#
複製過濾允許只複製部分資料,但這遠沒有聽起來那麼好。過濾分兩種:
- 主庫過濾(
binlog_do_db、binlog_ignore_db):從 binary log 中過濾事件 - 從庫過濾(
replicate_*選項):從 relay log 中過濾事件
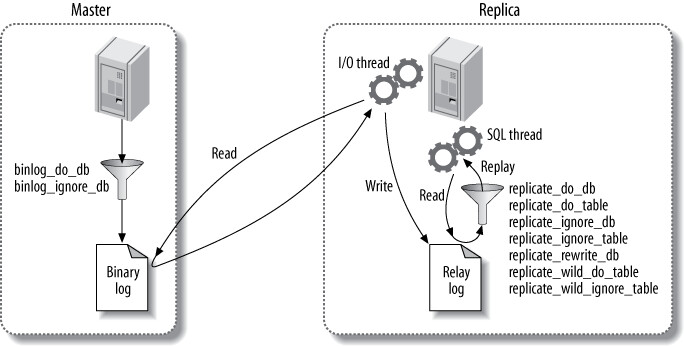
Figure 10.3: Replication filtering options
嚴重警告:
*_do_db和*_ignore_db選項是根據 當前預設資料庫(USE的資料庫)而非物件的資料庫名稱來過濾的。例如USE test; DELETE FROM sakila.film;會以test來判斷過濾,而非sakila。binlog_do_db和binlog_ignore_db不僅可能破壞複製,還會使 point-in-time recovery 變得不可能。除非真正需要,否則不要使用複製過濾。
複製拓撲#
設定 MySQL 複製時,需記住以下基本規則:
- 一個 MySQL 從庫只能有 一個主庫
- 每個從庫必須有 唯一的 server ID
- 一個主庫可以有 多個從庫
- 從庫可以傳播主庫的變更,作為其他從庫的主庫(需啟用
log_slave_updates)
一主多從(Master and Multiple Replicas)#
最簡單且最常用的拓撲。從庫之間互不交互,各自獨立連接主庫。
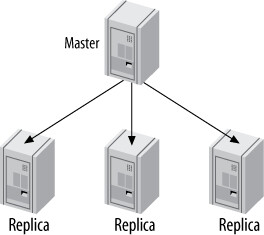
Figure 10.4: A master with multiple replicas
常見用途:
- 不同從庫用於不同角色(不同索引、不同存儲引擎)
- 其中一個從庫作為 備用主庫(standby master),不承擔流量
- 將一個從庫放在遠端資料中心做災難復原
- 延遲複製的從庫用於災難復原
- 專門用於備份、開發或測試
優點: 所有從庫(sibling)在主庫 binary log 中的位置可直接比較,簡化了主從切換等管理任務。
雙主複製 — 主動-主動模式(Active-Active)#
兩台伺服器互為主從。
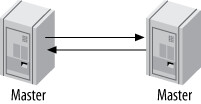
Figure 10.5: Master-master replication
嚴重警告: 同時對兩台主庫寫入是 極度危險 的。MySQL 5.0 的
auto_increment_increment和auto_increment_offset只解決自增 ID 衝突,但無法解決其他衝突。例如同一行在兩台伺服器上同時被不同語句修改,結果會靜默地不一致(不會有複製錯誤)。
MySQL 不支援 多源複製(multisource replication),即一個從庫連接多個主庫的配置。
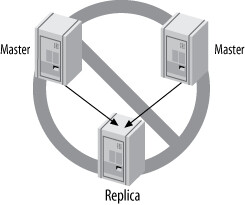
Figure 10.6: MySQL does not support multisource replication
雙主複製 — 主動-被動模式(Active-Passive)#
避免主動-主動模式的各種陷阱,是設計容錯和高可用系統的 強大方式。關鍵差異是其中一台伺服器為 read-only 的被動伺服器。
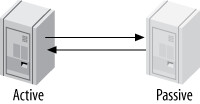
Figure 10.7: Master-master replication in active-passive mode
優點:
- 配置對稱,主從角色切換(failover/failback)非常容易
- 可在被動伺服器上執行維護操作(如
ALTER TABLE)而不中斷服務 - 被動伺服器可用於讀取查詢、備份等
設定步驟:
- 確保兩台伺服器資料完全一致
- 啟用 binary logging、唯一 server ID、複製帳號
- 啟用
log_slave_updates(對 failover 至關重要) - 被動伺服器設為
read_only - 啟動兩台伺服器,互相配置為對方的從庫
雙主加從庫(Master-Master with Replicas)#
在每個 co-master 上加掛從庫,提供額外冗餘。地理分佈的拓撲中消除了單點故障。
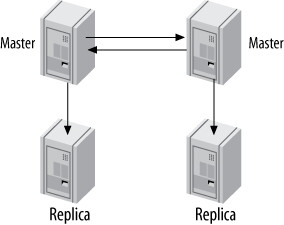
Figure 10.8: Master-master topology with replicas
環形複製(Ring Replication)#
三個或更多伺服器組成環形,每台是前一台的從庫和後一台的主庫。
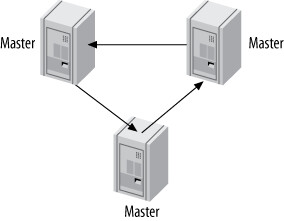
Figure 10.9: A ring replication topology
強烈不建議: 環形複製是脆弱的。完全依賴每個節點都可用;移除一個節點會導致事件 無限迴圈;任何連線中斷都會破壞整個環。
可以在環形的每個節點上加掛從庫以增加冗餘,但這只保護單一伺服器故障的風險。
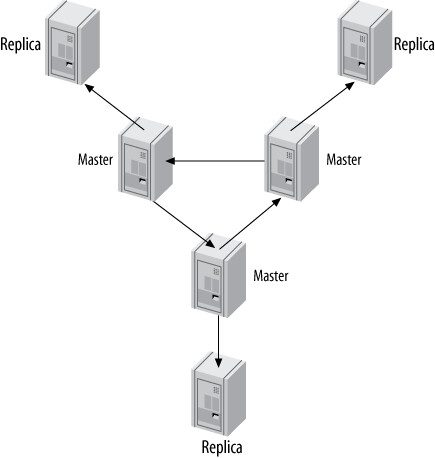
Figure 10.10: A replication ring with additional replicas at each site
分發主庫(Distribution Master)#
當從庫數量很多時,為減輕主庫負擔,可使用 distribution master — 一個專門用於讀取和轉發 binary log 的中間從庫。將其表格改為 Blackhole 存儲引擎,避免實際執行查詢的開銷。
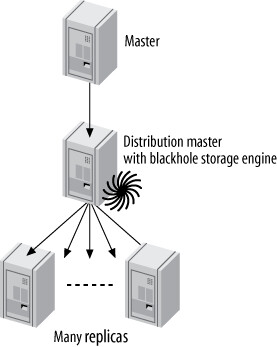
Figure 10.11: A master, a distribution master, and many replicas
經驗法則: 如果主庫接近滿載,不要掛超過約 10 個從庫。可使用 slave_compressed_protocol 節省頻寬。
注意事項:
- 需確保分發主庫上所有表格使用 Blackhole 引擎(設定
storage_engine = blackhole) - Blackhole 引擎有 bug(如某些情況下不記錄 auto-increment ID)
- 中間從庫的存在使得從庫的 binary log 座標與原始主庫不同,提升從庫到主庫角色更困難
金字塔拓撲(Tree / Pyramid)#
將複製層級化,每一層的從庫作為下一層的主庫,分散負載。
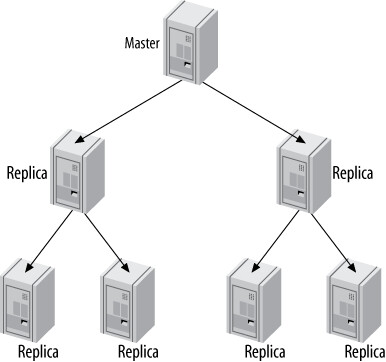
Figure 10.12: A pyramid replication topology
缺點: 中間層的故障會影響多個下游伺服器;層級越多,故障處理越複雜。
自訂複製方案#
選擇性複製(Selective Replication)#
將主庫資料分割到不同資料庫,每個從庫只複製一個子集(使用 replicate_wild_do_table)。利用各從庫的記憶體更有效地服務讀取查詢。
功能分離(Separating Functions)#
將 OLTP 和 OLAP 工作負載分開:主庫處理 OLTP,專用從庫處理 OLAP 查詢。
資料歸檔(Data Archiving)#
在主庫上刪除資料但保留在從庫上:
- 方法一:在刪除前設定
SET SQL_LOG_BIN=0(但會破壞 binary log 的完整性) - 方法二:在主庫上
USE特定資料庫(如purge),從庫配置replicate_ignore_db=purge
模擬多源複製(Emulating Multisource Replication)#
兩種方式:
- 使用雙主拓撲 + Blackhole 引擎:兩台主庫各自擁有自己的資料,對方的表格使用 Blackhole 引擎,掛載一台從庫即可獲得兩者的資料
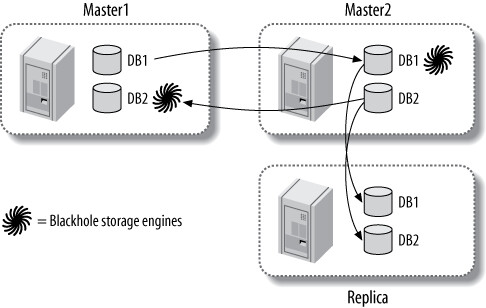
Figure 10.13: Emulating multisource replication with dual masters and the Blackhole storage engine
- 簡化版:從 server1 複製到 server2(server2 對 server1 的表格用 Blackhole),再從 server2 複製到最終從庫
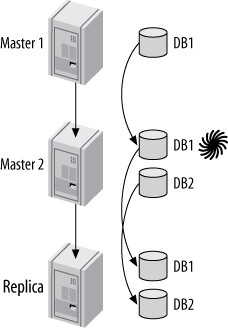
Figure 10.14: Another way to emulate multisource replication
另一選項是使用 Continuent Tungsten Replicator。
建立日誌伺服器(Log Server)#
建立一台沒有資料的 MySQL 實例,專門用來重放或過濾 binary log 事件。比 mysqlbinlog 更可靠、更快、更易監控和除錯。適用於災難復原和 point-in-time recovery。
複製與容量規劃#
複製無法擴展寫入#
複製可以擴展讀取,但 無法擴展寫入。每個從庫都必須執行所有寫入操作,系統受限於最弱環節的寫入能力。
數學範例: 假設 20% 寫入 / 80% 讀取的工作負載,每台伺服器 1000 QPS:
- 流量翻倍(2000 QPS):寫入增至 400 QPS,每個從庫只剩 600 QPS 處理讀取 → 需要 3 個從庫
- 流量再翻倍(4000 QPS):寫入增至 800 QPS,每個從庫只剩 200 QPS → 需要 16 個從庫
- 4 倍流量需要 17 倍伺服器,遠非線性擴展
核心觀念: 寫入只能透過 資料分片(partitioning)來擴展,不能透過複製。雙主拓撲分擔寫入看似可行,但 50% 序列化寫入的伺服器仍然比單台全部並行寫入的伺服器更慢。
從庫何時開始延遲?#
- 觀察延遲圖表中的 尖峰(spike):隨著接近容量上限,尖峰會越來越高越寬
- 測試方法: 停止從庫一小時後再啟動,觀察多久能追上。如果一小時追上 → 目前使用了 50% 容量
- Percona Server 和 MariaDB 可以直接測量複製利用率(
USER_STATISTICS中的BUSY_TIME)
規劃低利用率#
刻意 不讓伺服器滿載 是明智的做法。伺服器有餘裕才能應對流量尖峰、執行維護任務、跟上複製。在雙主拓撲中,讀取負載應低於 50%,確保單台故障時另一台能獨立承擔。
複製管理與維護#
監控複製#
在主庫上:
SHOW MASTER STATUS:查看當前 binary log 位置SHOW MASTER LOGS:列出磁碟上的 binary log 檔案SHOW BINLOG EVENTS:檢視特定事件
在從庫上:
SHOW SLAVE STATUS:最重要的監控命令SHOW PROCESSLIST:觀察 I/O thread 和 SQL thread 的狀態
測量複製延遲#
SHOW SLAVE STATUS 的 Seconds_behind_master 不可靠,原因包括:
| 情境 | 說明 |
|---|---|
| 從庫閒置 | 沒有處理查詢時無法報告延遲 |
| 複製停止 | 通常報告 NULL |
| 某些錯誤 | 會報告 0 而非實際問題 |
| 長交易 | 延遲值大幅波動 |
| 分發主庫的下游從庫 | 可能報告 0 延遲,但相對最上游主庫其實有延遲 |
最佳實踐: 使用 heartbeat record 機制。在主庫每秒更新一個時間戳記,在從庫上用當前時間減去 heartbeat 時間即可得到準確延遲。Percona Toolkit 的
pt-heartbeat是最流行的實現。
確認從庫與主庫的一致性#
從庫資料「漂移」(drift)比想像中更常見。即使沒有明顯錯誤,Bug、網路損壞、當機、非正常關閉等都可能導致不一致。
建議: 定期使用 pt-table-checksum 驗證。此工具在主庫上執行 INSERT ... SELECT 查詢計算校驗碼,透過複製在從庫上重新執行並比較結果,不需要同時鎖定兩台伺服器。
pt-table-checksum --replicate=test.checksum <master_host>從主庫重新同步從庫#
發現不一致時的處理方式:
- 傳統方法: 停止從庫、重新克隆(最徹底但最耗時)
- 部分同步: 使用
mysqldump只匯出受影響的資料 - 最佳工具:
pt-table-sync可高效找到並修復差異,透過複製操作(在主庫上執行查詢),避免競爭條件
切換主庫#
計劃性提升#
- 停止舊主庫的寫入
- 讓所有從庫追上複製進度
- 在新主庫上執行
STOP SLAVE、CHANGE MASTER TO MASTER_HOST=''、RESET SLAVE - 用
SHOW MASTER STATUS記錄新主庫的 binary log 座標 - 確保所有其他從庫追上進度
- 關閉舊主庫
- 在每個從庫上執行
CHANGE MASTER TO指向新主庫
flowchart TD
A["1. 停止舊主庫寫入"] --> B["2. 所有從庫追上舊主庫"]
B --> C["3. 新主庫 STOP SLAVE"]
C --> D["4. 新主庫 CHANGE MASTER TO"]
D --> E["5. 記錄新主庫 binlog 座標"]
E --> F["6. 其他從庫追上新主庫"]
F --> G["7. 關閉舊主庫,重新指向"]非計劃性提升#
當主庫崩潰時:
- 找出資料最新的從庫(比較
Master_Log_File/Read_Master_Log_Pos) - 讓所有從庫執行完 relay log
- 提升最新的從庫為新主庫
- 其他從庫需計算在新主庫 binary log 中的對應位置
flowchart TD
A["Master 崩潰"] --> B["比較所有從庫的 relay log"]
B --> C["找出最新的從庫"]
C --> D["所有從庫執行完 relay log"]
D --> E["提升最新從庫為新 Master"]
E --> F["其他從庫計算新座標並重新指向"]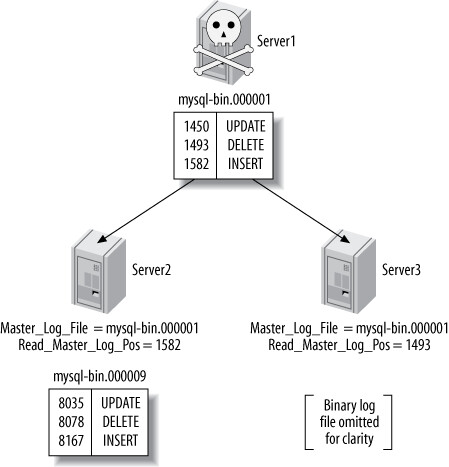
Figure 10.15: When server1 crashed, server2 was caught up, but server3 was not
定位日誌位置的技巧: 計算落後的從庫與新主庫的位元組偏移差,從新主庫當前位置減去此差值,然後用
mysqlbinlog驗證該位置的事件是否正確。
雙主模式角色切換#
- 停止主動伺服器的寫入
- 在主動伺服器上
SET GLOBAL read_only = 1 - 記錄主動伺服器的 binary log 座標
- 在被動伺服器上
SELECT MASTER_POS_WAIT()等待追上 - 在被動伺服器上
SET GLOBAL read_only = 0 - 重新設定應用程式指向新的主動伺服器
sequenceDiagram
participant Active as 主動伺服器
participant Passive as 被動伺服器
participant App as 應用程式
Active->>Active: 停止寫入
Active->>Active: SET read_only = ON
Active->>Active: 記錄 binlog 座標
Passive->>Passive: MASTER_POS_WAIT(等待追上)
Passive->>Passive: SET read_only = OFF
App->>Passive: 切換指向新主動伺服器
Note over Active,Passive: 角色對調完成複製的問題與解決方案#
資料損壞或遺失#
主庫非預期關閉:
- 未設定
sync_binlog時,最後幾個 binary log 事件可能未刷新到磁碟 - 解決:讓從庫從下一個 binary log 檔案的開頭開始讀取,然後用
pt-table-checksum檢查一致性
從庫非預期關閉:
master.info未同步到磁碟,重啟後位置資訊可能不正確- 從庫可能重複執行事件,導致唯一索引衝突
- InnoDB 可以從錯誤日誌中的恢復資訊找到正確座標
Binary log 損壞:
- 主庫上損壞:嘗試跳過損壞部分(
SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1) - 從庫 relay log 損壞:
CHANGE MASTER TO重新指向當前位置,丟棄並重新取得 relay log
非事務表的問題#
語句在非事務表(如 MyISAM)上部分執行後被中斷時,主庫修改了部分行但從庫會重放完整語句,導致不一致。
建議: 使用 MyISAM 表時,關閉從庫前務必先執行
STOP SLAVE。
混合事務與非事務表#
如果 rollback 涉及混合引擎的表格,事務引擎的變更可以回滾但非事務引擎的不行。從庫上的 deadlock 可能導致主從資料不一致。唯一的預防方式是 避免混合使用事務與非事務表。
非確定性語句#
使用 SBR 時,以下情況可能導致主從不一致:
UPDATE ... LIMIT(行順序不保證相同)REPLACE或INSERT IGNORE在有多個唯一索引的表上- 涉及
INFORMATION_SCHEMA的語句 - 大多數伺服器變數(如
@@server_id、@@hostname)在 MySQL 5.1 之前
InnoDB 鎖定導致的鎖競爭#
使用 SBR 時,INSERT ... SELECT 預設會鎖定所有讀取的源表行,以確保在從庫上重放時結果一致。
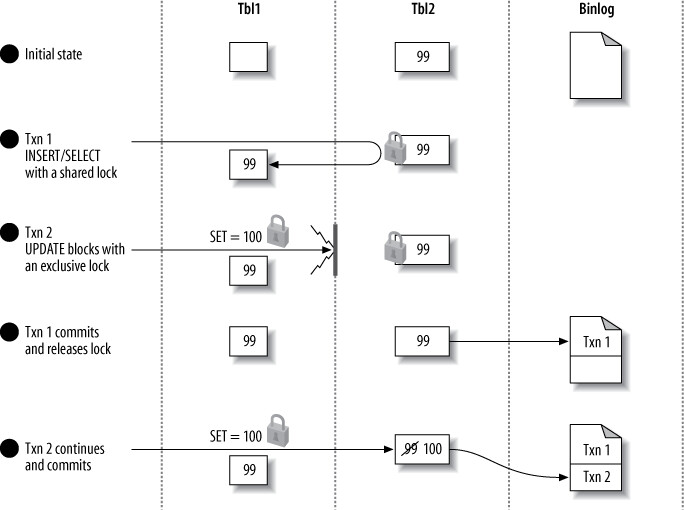
Figure 10.16: Two transactions update data, with shared locks to serialize access
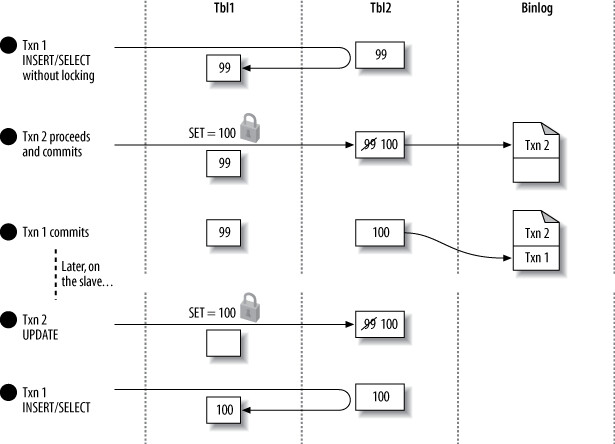
Figure 10.17: Two transactions update data, but without a shared lock to serialize access
緩解方式:
- 儘快提交交易,釋放鎖
- 將大語句拆分為多個小語句
- 用
SELECT INTO OUTFILE+LOAD DATA INFILE取代INSERT ... SELECT
注意:
innodb_locks_unsafe_for_binlog = 1可以停用鎖定,但會導致從庫靜默地不一致,且 binary log 無法用於復原。RBR 完全避免了這個問題。
其他常見問題#
| 問題 | 說明 |
|---|---|
| 非唯一 Server ID | 兩個從庫用相同 ID 時會互相踢對方下線,產生頻繁的斷線重連,可能遺漏或重複事件 |
| 未定義 Server ID | START SLAVE 會報錯,即使 SELECT @@server_id 有值也不行——必須明確設定 |
| 依賴未複製的資料 | 主庫上存在但從庫上不存在的資料庫或表格,會在複製重放時出錯 |
| 臨時表遺失 | 從庫崩潰後臨時表消失,後續引用會失敗。建議改用永久表 + CONNECTION_ID() 命名 |
| 漏複製更新 | 誤用 SET SQL_LOG_BIN=0 或不理解過濾規則 |
max_allowed_packet 不匹配 | 主庫的值必須與從庫一致 |
| 磁碟空間不足 | binary log、relay log 和臨時檔案可能填滿磁碟 |
複製延遲#
延遲的根本原因#
- 單執行緒瓶頸:從庫的 SQL thread 只用一個 CPU 和一個磁碟
- 從庫上的鎖競爭:其他查詢可能阻塞複製執行緒
- 延遲模式:尖峰型(單一長查詢引起)或持續型(整體跟不上)
解決方案#
1. 減少重複的昂貴寫入#
將昂貴的計算從主庫移到從庫執行,再將結果 LOAD DATA INFILE 回主庫:
-- 不要在主庫上執行:
REPLACE INTO summary_table (col1, col2, ...)
SELECT col1, sum(col2, ...) FROM enormous_table GROUP BY col1;
-- 改為:在從庫上查詢,結果用 LOAD DATA INFILE 寫回主庫這樣 N 個從庫可以省下 N-1 次昂貴的 GROUP BY 查詢。
2. 在複製之外並行寫入#
某些寫入(如資料歸檔)可以在主庫和從庫上各自獨立執行,而非透過複製。停用這些語句的 binary logging,保留從庫的序列化寫入容量給真正需要複製的寫入。
3. 預取快取(Cache Prefetching)#
使用程式讀取 relay log 中稍前方的事件,轉為 SELECT 語句先載入資料到記憶體。適用條件:
- 從庫的 SQL thread 是 I/O-bound,但整體伺服器不是
- 有大量磁碟(8+ drives)
- 使用 InnoDB 且 working set 遠大於記憶體
注意: 預取快取技術適用場景非常有限。大多數人不應使用它,優先考慮其他方案。
4. 從庫調效選項(犧牲安全性)#
innodb_flush_log_at_trx_commit = 2- 停用 binary logging
innodb_locks_unsafe_for_binlog = 1delay_key_write = ALL(MyISAM)
注意: 這些設定犧牲安全性換取速度。如果提升從庫為主庫,務必恢復安全設定。
進階複製功能#
半同步複製(Semisynchronous Replication)#
MySQL 5.5 基於 Google 的工作引入 半同步複製。提交交易後,binary log 事件必須傳輸到至少一個從庫 確認收到 後,客戶端才會收到提交完成的通知。
半同步複製的誤解澄清:
- 不是在主庫上阻塞提交 — 提交已完成,只是延遲通知客戶端
- 不是等從庫 執行 交易 — 從庫收到後即確認
- 不是萬無一失 — 超時後會退回普通非同步模式
效能影響: 每次提交增加約 200 微秒延遲。可以配合放寬主庫的 sync_binlog 來提升效能(寫入遠端記憶體比寫入本地磁碟快),測試顯示可有約 2 倍效能提升。
sequenceDiagram
participant C as Client
participant M as Master
participant R as Replica
C->>M: 提交交易
M->>M: 寫入 Binary Log
M->>R: 傳送 binlog 事件
R-->>M: ACK(確認收到)
M-->>C: 回傳提交完成
Note over R: 收到不代表已執行,只是已寫入 relay logMySQL 5.5 / 5.6 其他改進#
- 複製心跳:讓從庫偵測到靜默斷線
- MySQL 5.6 開發中的功能:
- 事務性複製狀態(不再依賴
master.info等非 crash-safe 檔案) - Binary log event checksums(偵測 relay log 中的損壞事件)
- 延遲複製(time-delayed replication)
- RBR 事件中包含原始 SQL
- 多執行緒複製(parallel replication apply)
- Group commit 修復
- 事務性複製狀態(不再依賴
其他複製技術#
Tungsten Replicator#
Continuent 的 Tungsten Replicator 是開源的 Java 中介複製產品,取代 而非管理 MySQL 內建複製。
主要功能:
- 多執行緒複製(宣稱可達 3 倍速度提升)
- 跨平台複製(MySQL ↔ PostgreSQL / Oracle)
- 多源複製(多個來源複製到單一目標)
- 全域交易 ID(Global Transaction ID),不再需要匹配 binary log 名稱和偏移量
- System of Record 模式:每個節點擁有並可寫入特定資料,其他節點為唯讀副本
- 內建資料一致性檢查
- 從庫自動提升為主庫
缺點:
- 比內建複製更複雜,屬於中介軟體
- 單執行緒效能不如 MySQL 內建複製
- 部署量較少,Bug 風險較高
總結#
MySQL 複製是 MySQL 內建功能中的「瑞士刀」,大幅擴展了 MySQL 的功能範圍。關鍵實踐建議:
- 使用
pt-table-checksum定期驗證 從庫資料一致性 - 監控 複製運行狀態與延遲
- 理解複製的 非同步本質,設計應用程式容忍讀取舊資料
- 只寫入一台主庫,從庫設為
read_only並限制權限 - 啟用本章建議的 安全設定
- 保持簡單(K.I.S.S.):除非真正需要,避免環形複製、Blackhole 表格、複製過濾等複雜設定
- 讓從庫在各方面與主庫 保持一致