概述#
MySQL 伺服器的效能取決於最弱的環節。磁碟大小、可用記憶體、CPU 資源、網路及其連結元件,共同決定了系統的最終容量。硬體選型與作業系統配置是效能優化的基礎工作。
兩大最常見的瓶頸:
- CPU 飽和(CPU saturation):資料已在記憶體中,或磁碟讀取速度足夠快時發生
- I/O 飽和(I/O saturation):需要處理的資料量遠超記憶體容量時發生
重點: 瓶頸常會偽裝成其他問題。例如記憶體不足可能表現為 I/O 問題,記憶體匯流排飽和可能看起來像 CPU 問題。必須使用 Chapter 3 的診斷技術找出真正的限制因素。
CPU 選型#
快速 CPU vs 多 CPU#
MySQL 的工作負載特性決定了 CPU 策略:
- 低延遲(快速回應):需要快速 CPU,因為每個查詢只在單一執行緒上執行
- 高吞吐量(大量並行查詢):可以從多 CPU 中受益,但前提是沒有嚴重的並行瓶頸
經驗法則: MySQL 複寫(replication)是單執行緒的,最能從快速 CPU 受益,而非更多 CPU。
CPU Bound 工作負載的分析#
查詢要嘛在「執行」,要嘛在「等待」。常見的等待原因:
- 等待 latch 或 lock:需要更多 CPU 平行處理
- 等待 I/O:需要更快的磁碟或更多記憶體
- 等待 row lock 或 table lock:這是邏輯層的問題,通常靠改查詢或 schema 來解
InnoDB 有全域共享的資料結構(如 buffer pool mutex),MyISAM 有每個 key buffer 的全域鎖。這些內部並行問題可以透過 pt-pmp 工具的 stack trace 來診斷。
CPU 架構與擴展性#
- 目前 99% 以上的 MySQL 實例執行在 x86 架構上
- 務必使用 64 位元 OS 搭配 64 位元硬體
- 頻率調節(Frequency scaling) 在伺服器上可能有害,應設為高效能模式
- Turbo Boost 技術讓 CPU 在部分核心閒置時提高其他核心頻率,對 MySQL 非常有利
擴展到多 CPU 與多核心#
OLTP 工作負載 最能從多 CPU 受益,但要注意兩種並行問題:
- 邏輯並行問題(Logical concurrency):row lock、table lock — 用較好的 SQL 和 schema 設計解決
- 內部並行問題(Internal concurrency):如 InnoDB buffer pool mutex、memory allocation mutex — 需等待 MySQL/引擎修正
注意: 某些系統在處理器過多時反而效能更差。MySQL 對 24 核以上的擴展性曾有問題(近年持續改善中)。建議不超過兩個 CPU 插座。
記憶體與磁碟資源的平衡#
大量記憶體的最大價值不在於「把資料放在記憶體裡」,而在於避免磁碟 I/O。記憶體作為快取,讓熱資料(hot data)可以被快速存取。
快取階層(Cache Hierarchy)#
電腦的快取是金字塔式結構,越上層越小、越快、越貴:
| 快取層級 | 特性 |
|---|---|
| CPU 暫存器(Registers) | 對程式透明 |
| L1 / L2 快取 | 對程式透明 |
| 主記憶體(Main Memory) | 作業系統和應用程式管理 |
| 磁碟(Disk) | 最慢但最大 |
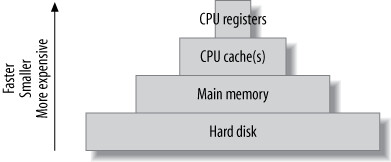
Figure 9.1: The cache hierarchy
flowchart TD
A["CPU 暫存器"] --> B["L1 / L2 快取"]
B --> C["主記憶體"]
C --> D["磁碟"]
style A fill:#ff6,stroke:#333
style B fill:#ffa,stroke:#333
style C fill:#adf,stroke:#333
style D fill:#ddd,stroke:#333資料庫伺服器的行為常常違反 CPU 快取預測的前提假設(如空間局部性),因此效能更依賴於作業系統和應用程式層的快取管理。
Working Set(工作集)#
Working Set 是應用程式真正需要的資料子集。並非所有資料都需要放在記憶體中——只需要工作集即可。
- 工作集以時間百分位定義最有用(如:1 小時內的 95th percentile 頁面集合)
- 包含資料和索引,以快取單位(cache unit)計算
- InnoDB 的快取單位是 16 KB 頁面,所以存取一筆 100 bytes 的列也會快取整個 16 KB 頁面
提示: 良好的 clustered index 設計讓相關資料在同一頁面上,能更有效利用快取。
有效的記憶體-磁碟比例#
- 追求可接受的快取失誤率(cache miss rate),而非零失誤率
- 快取失誤率與記憶體大小的關係是非線性的:10 GB 記憶體有 10% 失誤率,要降到 1% 可能需要 50 GB
- 判斷指標:看 CPU 使用率。如果 CPU 使用 99%、I/O 等待 1%,表示快取失誤率很好
Random vs Sequential I/O#
- Sequential I/O 本身就很快(磁碟不需搜尋),快取帶來的增益較少
- Random I/O 非常依賴磁碟搜尋,快取可以省下大量工作
- InnoDB 讀取資料時通常會順便快取同頁的其他資料(prefetch),但隨機讀取每次只需要頁面中的一小部分
快取、讀取與寫入#
- 如果所有資料都在記憶體中,每次讀取都會是快取命中
- 寫入受益於緩衝的兩個原因:
- 多次寫入,一次刷出(Many writes, one flush):同一位置的多次修改只需寫入磁碟一次
- I/O 合併(I/O merging):鄰近位置的寫入可以合併成一次操作
- Write-Ahead Logging(WAL):先將修改記錄寫入循序 log,之後再批次寫回資料檔。這讓隨機 I/O 轉為循序 I/O
磁碟選擇#
傳統硬碟讀取的三個步驟:
- 移動讀取頭到正確位置(seek)
- 等待磁碟旋轉到資料位置(rotational latency)
- 等待資料通過讀取頭(transfer)
小型隨機查找由步驟 1、2 主導;大型循序讀取由步驟 3 主導。
選擇磁碟時考量的因素:
- 存取時間(Access time):隨機查找效能的決定因素
- 主軸轉速(Spindle rotation speed):7,200 / 10,000 / 15,000 RPM
- 物理大小:2.5 吋的伺服器級磁碟通常比 3.5 吋快(搜尋距離短)
- InnoDB 能良好擴展到多磁碟;MyISAM 因 table lock 限制寫入擴展性
SSD 與固態儲存#
Flash 裝置的效能特性#
高品質 flash 裝置的優勢:
- 隨機讀寫遠優於傳統硬碟(讀取略優於寫入)
- 循序讀寫優於硬碟,但差距不如隨機 I/O 顯著
- 高並行能力:flash 裝置需要大量並行才能達到最高吞吐量
重點: 固態儲存最重要的改進在於隨機 I/O 和並行性。這正好是正規化資料庫最需要的特性,未來將根本改變 RDBMS 技術。
Flash 記憶體概述#
Flash 記憶體的核心限制:
| 特性 | 說明 |
|---|---|
| 讀取 | 可快速且小單位地讀取 |
| 寫入 | 非常具挑戰性:不能直接覆寫,必須先**擦除(erase)**整個區塊(如 512 KB) |
| 擦除 | 速度慢(幾毫秒 vs 寫入幾百微秒),且會磨損區塊 |
| Write Amplification(寫入放大) | 因資料搬移、部分區塊寫入等原因,實際寫入量大於邏輯寫入量 |
| 垃圾回收(Garbage Collection) | 裝置回收已用區塊以備新寫入,裝置越滿垃圾回收越辛苦 |
| 裝置填滿時效能下降 | 100 GB 資料在 160 GB SSD 和 320 GB SSD 上表現不同 |
SLC vs MLC#
| 特性 | SLC(Single-Level Cell) | MLC(Multi-Level Cell) |
|---|---|---|
| 每 cell 位元數 | 1 | 2(或 3) |
| 耐久性 | ~100,000 寫入週期 | ~10,000 寫入週期 |
| 速度 | 較快 | 較慢 |
| 價格 | 較貴 | 較便宜 |
| 容量密度 | 較低 | 較高 |
| 定位 | 企業級 | 消費級(eMLC 逐漸進入企業市場) |
MLC 裝置的品質高度依賴韌體演算法(wear leveling、remapping),好的 eMLC 裝置可以達到企業級品質。
基準測試注意事項#
Flash 裝置有 A-B-C 三階段效能特性:
- Stage A:初始高效能
- Stage B:垃圾回收啟動,過渡期
- Stage C:穩態效能(你真正關心的)
stateDiagram-v2
[*] --> StageA: 裝置初始化
StageA: Stage A(高效能期)
StageA --> StageB: 垃圾回收啟動
StageB: Stage B(過渡期)
StageB --> StageC: 達到穩態
StageC: Stage C(穩態效能)注意: 廠商規格通常報告的是 Stage A 效能和大區塊寫入的最佳值。InnoDB 通常寫入 16 KB 和 512-byte 區塊的混合。務必用實際工作負載測試穩態效能。
SSD vs PCIe 裝置#
SATA SSD:
- 模擬 SATA 硬碟,可直接替換
- 便宜、種類多、比硬碟快很多
- 可靠性不一定好,需注意是否有電池/電容保護寫入快取
- 建議搭配 RAID 使用(單碟不可信賴)
- 注意:多數 RAID 控制器未對 SSD 優化,可能成為效能瓶頸
PCIe 裝置:
- 不模擬硬碟,頻寬和延遲都優於 SATA 介面
- 效能最高,但價格最貴
- 通常有內建 RAID,不建議額外做 RAID
- 主要品牌:Fusion-io、Virident 等
何時使用 Flash?#
| 場景 | 適合度 | 原因 |
|---|---|---|
| 大量隨機 I/O | 適合 | 資料量遠超記憶體時 |
| 高吞吐量寫入 | 適合 | 記憶體緩衝無法完全吸收的工作負載 |
| 單執行緒工作負載 | 適合 | 對延遲敏感(如 MySQL replication) |
| 伺服器整合 | 適合 | PCIe 裝置可達 10-15 倍整合率 |
| 循序寫入(如 InnoDB log files) | 不適合 | flash 在循序寫入的優勢不大,且會加速磨損 |
| 買更多記憶體就能解決的問題 | 不適合 | 可能更便宜有效 |
Flashcache#
Flashcache 是 Facebook 開源的 Linux kernel module,在 RAM 和磁碟之間插入 flash 作為中間快取層:
- 建立一個虛擬 block device,由 flash + 磁碟共同支撐
- 對讀取密集的 I/O 工作負載效果最好
- 需要預熱(warmup),可能長達一週
- 效能取決於多層快取的命中率:InnoDB buffer pool → Flashcache → 磁碟
flowchart TD
A["讀取請求"] --> B{"InnoDB Buffer Pool 命中?"}
B -->|命中| C["回傳資料"]
B -->|未命中| D{"Flashcache 命中?"}
D -->|命中| C
D -->|未命中| E["從磁碟讀取"]
E --> C針對 SSD 的 MySQL 優化#
- 增加 InnoDB I/O 執行緒數到 10-15,
innodb_io_capacity設為 2000-20000 - InnoDB log files 可以設更大(4 GB+),因為 flash 上的 crash recovery 很快
- 將 log files(redo log、binlog、ibdata1)移到 RAID 磁碟(循序寫入不需要 flash)
- 考慮停用 read-ahead
- 設定
innodb_flush_neighbor_pages=0(flash 上不需要合併鄰近頁刷出) - 考慮停用 doublewrite buffer(某些 flash 裝置支援原子 16 KB 寫入)
- 限制 insert buffer 大小(flash 上隨機 I/O 已經很快)
- 確保啟用 Hyperthreading
RAID 效能優化#
RAID 級別比較#
| RAID | 特點 | 冗餘 | 磁碟需求 | 讀取 | 寫入 |
|---|---|---|---|---|---|
| RAID 0 | 便宜、快速、危險 | 無 | N | 快 | 快 |
| RAID 1 | 讀取快、簡單、安全 | 有 | 2 | 快 | 普通 |
| RAID 5 | 安全/速度/成本折衷 | 有 | N+1 | 快 | 看情況 |
| RAID 10 | 昂貴、快速、安全 | 有 | 2N | 快 | 快 |
| RAID 50 | 超大資料量 | 有 | 2(N+1) | 快 | 快 |
各級別重點:
| RAID 級別 | 適用場景 | 注意事項 |
|---|---|---|
| RAID 0 | 不重要的伺服器(如可輕易從其他 replica 複製的 replica) | 無冗餘,任何一碟故障即全部遺失 |
| RAID 1 | 只有兩顆硬碟的低端伺服器,循序寫入場景 | 簡單安全但容量利用率低 |
| RAID 5 | 成本敏感的場景 | 隨機寫入代價高(每次寫入需 2 讀 + 2 寫),磁碟故障時重建效能嚴重下降(2-5 倍),不超過 10 顆碟 |
| RAID 10 | 資料儲存的最佳選擇 | 鏡像配對再做 stripe,讀寫都能良好擴展,重建速度快 |
| RAID 50 | 非常大的資料集(data warehouse) | 需要較多磁碟 |
注意: RAID 不能取代備份!同時故障兩顆碟的機率不可忽視(電源突波、過熱)。潛伏的介質損壞可能在數月後才被發現。務必監控 RAID 陣列狀態並定期做一致性檢查。
RAID 配置#
Stripe Chunk Size:
- 理論上,大 chunk size 適合隨機 I/O(單碟即可完成讀取)
- 實務上,控制器可能用 chunk size 作為快取單位,太大會浪費
- 對齊所有層(InnoDB page → filesystem block → RAID stripe → disk sector)可帶來 15%-23% 的效能提升
RAID Cache(控制器快取):
- 快取讀取:通常浪費(OS 和 DB 有自己更大的快取)
- 快取寫入:非常有價值,可大幅加速同步寫入
- RAID 0/1/10:將 100% cache 分配給寫入
- RAID 5:需保留部分 cache 給內部 parity 運算
重點: 寫入快取必須搭配 BBU(Battery Backup Unit)。沒有 BBU 的寫入快取在斷電時會導致資料損毀。啟用 BBU 寫入快取可將 log flush 工作負載的效能提升 20 倍以上。
BBU 注意事項:
- BBU 會定期進行 learning cycle,期間快取策略自動切換為 WriteThrough(效能驟降)
- 建議安排 learning cycle 在離峰時間,或做 failover
- 監控 BBU 狀態和 cache policy
- 對新硬體一律做真實斷電測試(拔電源線)
硬體 RAID vs 軟體 RAID#
10 顆碟的配置選項:
- 單一 RAID 10(控制器管理全部)
- 5 組 RAID 1 鏡像(OS 看到 5 個 volume)
- 5 組 RAID 1 + 軟體 RAID 0 串接
不同配置效能可能差異很大。ext3 的 single mutex per inode 在 O_DIRECT 模式下會導致序列化。實務上應基準測試驗證新伺服器的 I/O 並行能力。
SAN 與 NAS#
SAN 效能特性#
| 操作 | SAN 表現 | 原因 |
|---|---|---|
| 循序寫入 | 好 | 可緩衝合併 |
| 循序讀取 | 好 | 可預測和預取 |
| 隨機寫入 | 普通 | 合併程度有限 |
| 隨機讀取 | 差 | 快取失誤 + 網路延遲 |
注意: SAN 上的單執行緒隨機 I/O 操作(如 replication、大量 DELETE、ALTER TABLE)表現特別差。NFS 介面的 metadata 操作會增加額外網路往返延遲。
是否該使用 SAN?#
| 場景 | 適合度 |
|---|---|
| 集中備份管理、snapshot、CDP | 適合 |
| 簡化容量規劃 | 適合 |
| 儲存整合、資料去重 | 適合 |
| 需要高效能隨機 I/O 的工作負載 | 不適合 |
| 作為高可用方案(SAN 本身也是故障點) | 不適合 |
| 追求高 cost/performance 比 | 不適合 |
提示: 多數 Web 應用的資料庫不使用 SAN。SAN 更常見於企業應用中。如果使用 SAN,至少需要兩台(否則只是昂貴的單點故障)。
多磁碟 Volume 配置#
- Transaction log 和 data 是否分開取決於磁碟數量:少於 20 顆碟時,分開不划算(減少了 data 可用的碟數)
- 有 BBU RAID 控制器時,log 寫入通常很小,不會干擾 data I/O
- Binary log 建議放在不同 volume(即使資料遺失仍可做 point-in-time recovery)
- 臨時目錄最好放在 tmpfs(記憶體檔案系統)
- 典型配置:OS + swap + binlog 放 RAID 1,其餘放 RAID 5 或 RAID 10
網路配置#
- 延遲比頻寬更常成為瓶頸(大量小型查詢的延遲累積)
- 啟用
skip_name_resolve避免 DNS 查找問題 - 調高
back_log選項(預設 50 對繁忙系統不夠) - 監控每個網路埠的效能和錯誤
- 跨資料中心操作要考慮光速限制(美國東西岸往返至少 32 ms)
# 擴大本地連接埠範圍
echo 1024 65535 > /proc/sys/net/ipv4/ip_local_port_range
# 增加連接佇列
echo 4096 > /proc/sys/net/ipv4/tcp_max_syn_backlog作業系統選擇與配置#
作業系統選擇#
- GNU/Linux:最常見,推薦使用伺服器導向的發行版(RHEL、CentOS、Ubuntu Server)
- Solaris:高可靠性需求,有 ZFS、DTrace 等先進功能
- FreeBSD:近年執行緒支援已大幅改善,可大規模部署
- Windows:主要用於開發環境
檔案系統選擇#
推薦使用 XFS 檔案系統。
| 檔案系統 | 日誌 | 大目錄支援 | 備註 |
|---|---|---|---|
| ext3 | 可選 | 部分 | single mutex per inode,fsync 會 flush 整個 FS |
| ext4 | 是 | 是 | 較新,逐漸普及 |
| XFS | 是 | 是 | 推薦用於 MySQL |
| ZFS | 是 | 是 | Solaris / FreeBSD |
ext3/ext4 的三種日誌模式:
| 日誌模式 | 行為 | 效能 |
|---|---|---|
| data=writeback | 只記錄 metadata | 最快,搭配 InnoDB 通常安全 |
| data=ordered | metadata 寫入前先寫 data | 比 writeback 略慢但更安全 |
| data=journal | 完整日誌 | 開銷最大,通常不必要 |
掛載選項建議:
# /etc/fstab 範例
/dev/sda2 /usr/lib/mysql ext3 noatime,nodiratime,data=writeback 0 1noatime,nodiratime:停用存取時間記錄,可提升 5-10% 效能- 停用或限制 read-ahead(InnoDB 有自己的 read-ahead)
I/O 排程器#
# 查看目前排程器
cat /sys/block/sda/queue/scheduler
# noop deadline [cfq]| 排程器 | 特性 | 適用場景 |
|---|---|---|
| cfq(預設) | 對伺服器非常不利,會造成不必要的請求延遲 | 桌面環境,不適合伺服器 |
| noop | 最簡單,不做額外排程 | 有自己排程的裝置(RAID 控制器、SAN) |
| deadline | 確保請求在期限內完成 | RAID 控制器和直接連接的磁碟 |
重點: 伺服器上務必將 I/O 排程器從預設的
cfq改為noop或deadline,否則可能造成嚴重的效能問題。
Swap 管理#
Swap 對 MySQL 效能極為有害:
- MySQL 假設記憶體操作很快,可能在持有全域 mutex 時存取被 swap 出去的記憶體
- 這會導致所有操作停滯,比單純的 I/O 問題嚴重得多
監控方式: 看 vmstat 的 si 和 so 欄位(swap in/out),而非 swpd(swap 使用量)。si 和 so 應保持 0,絕不超過 10 blocks/sec。
防範措施:
# 將 swappiness 設為 0(預設 60 對伺服器太高)
echo 0 > /proc/sys/vm/swappiness
# 使用 O_DIRECT 避免雙重快取造成記憶體壓力
# my.cnf 中設定:
# innodb_flush_method=O_DIRECT- 設定 SSH 的
oom_adj避免 OOM killer 殺掉 SSH - 不建議完全停用 swap(MySQL 記憶體尖峰需求可能導致崩潰)
- 分配充足的 swap 空間,並設定監控警報
作業系統監控工具#
vmstat#
$ vmstat 5
procs -----------memory---------- ---swap-- -----io---- --system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa各欄位解讀:
| 欄位 | 說明 |
|---|---|
| r | 等待 CPU 的程序數 |
| b | 不可中斷睡眠(通常在等 I/O) |
| si / so | swap in/out(應為 0) |
| bi / bo | block I/O 讀入/寫出 |
| us | user CPU 使用率 |
| sy | system CPU 使用率(超過 20% 需注意) |
| id | 閒置 |
| wa | I/O 等待 |
iostat#
$ iostat -dx 5重要欄位:
| 欄位 | 說明 |
|---|---|
| r/s、w/s | 每秒讀寫請求數 |
| avgrq-sz | 平均請求大小 |
| avgqu-sz | 佇列中等待的請求數 |
| await | 佇列等待時間(ms) |
| svctm | 服務時間(ms) |
| %util | 裝置忙碌百分比(RAID 陣列可能服務並行 > 1,但此值不超過 100%) |
並行度公式(Little’s Law):
concurrency = (r/s + w/s) × (svctm / 1000)識別不同的工作負載模式#
CPU-Bound:
- vmstat:
us高(80-90%),r有多個等待程序,I/O 適中 - iostat:
%util低於 50%
I/O-Bound:
- vmstat:
b高(多個程序在等 I/O),wa高(50-60%+) - iostat:
%util接近 100%,佇列長 - 通常是讀取造成 I/O 等待(寫入可被緩衝,讀取天生是同步的)
Swapping:
- vmstat:
si和so高,系統可能變得無法回應
提示: 除了 vmstat 和 iostat,推薦使用 pt-diskstats(Percona Toolkit)取代 iostat,它能分別顯示讀寫統計並支援互動式分析。mpstat 則可查看各 CPU 的個別統計。
硬體選型建議摘要#
CPU:
- 不超過兩個 CPU 插座(四插座的 CPU 貴、頻率低、跨插座同步成本高)
- 選快速 CPU 優先於多 CPU
記憶體:
- 填滿伺服器的經濟型記憶體
- 常見配置:18 DIMM 插槽 × 8 GB = 144 GB
儲存選項(效能由低到高):
- SAN:功能豐富、大容量,但隨機 I/O 延遲高
- 傳統硬碟 + RAID 10 + BBU WriteBack cache:大多數工作負載的最佳選擇
- SSD:便宜但需 RAID,多數 RAID 控制器未對 SSD 優化
- PCIe flash:效能最高,不需 RAID,但價格高、容量有限
提示: Replica 的硬體選型要看用途——作為 failover 備援應與 master 相同配置;若僅為增加讀取容量,可用較便宜的硬體或 RAID 0。在 replica 上使用 SSD 對加速單執行緒複寫特別有效。