概述#
MySQL 5.0 和 5.1 引入了許多進階功能(分區、觸發器、視圖等),這些功能對於熟悉其他資料庫的使用者來說並不陌生。然而,這些功能的效能影響在實際大規模使用後才逐漸顯現。本章深入探討這些功能在真實世界中的效能特性與最佳實踐。
分區表 (Partitioned Tables)#
分區表是一個由多個實體子表組成的單一邏輯表。分區程式碼本質上是一組 Handler 物件的包裝器,負責將請求轉發給底層的儲存引擎。
核心概念#
- 索引是按分區定義的,而非跨整張表建立(與 Oracle 不同)
- MySQL 根據
PARTITION BY子句決定每行資料歸屬哪個分區 - 查詢最佳化器可以修剪 (prune) 不需要的分區,避免掃描整張表
- 分區的主要目的是作為一種粗粒度的索引和資料聚簇機制
分區的適用場景#
- 表太大而無法放入記憶體,或只有末端的「熱資料」頻繁被存取
- 需要輕鬆維護資料(如直接
DROP PARTITION來丟棄舊資料) - 資料需要分散到多個硬碟上
- 需要避免特定瓶頸(如 InnoDB 的 per-index mutex 或 ext3 的 per-inode locking)
分區的限制#
- 每個表最多 1,024 個分區
- MySQL 5.1 中分區表達式必須是整數;MySQL 5.5 支援
RANGE COLUMNS - 所有主鍵或唯一索引必須包含分區表達式中的所有欄位
- 不能使用外鍵約束
分區的運作方式#
所有操作(SELECT、INSERT、UPDATE、DELETE)都會先開啟並鎖定所有分區,然後才進行修剪判斷:
| 操作 | 行為 |
|---|---|
| SELECT | 開啟所有分區 → 最佳化器修剪 → 只掃描相關分區 |
| INSERT | 判斷目標分區 → 轉發該行到正確分區 |
| UPDATE | 可能涉及跨分區移動(舊分區刪除 + 新分區插入) |
InnoDB 的鎖定行為: 雖然分區層會開啟並鎖定所有分區,但 InnoDB 會指示分區層解鎖,因為它自己在行級別處理鎖定。
分區類型#
最常見的是 Range 分區:
CREATE TABLE sales (
order_date DATETIME NOT NULL,
-- Other columns omitted
) ENGINE=InnoDB PARTITION BY RANGE(YEAR(order_date)) (
PARTITION p_2010 VALUES LESS THAN (2010),
PARTITION p_2011 VALUES LESS THAN (2011),
PARTITION p_2012 VALUES LESS THAN (2012),
PARTITION p_catchall VALUES LESS THAN MAXVALUE );其他類型包括 Key、Hash、List 分區,以及 MySQL 5.5 的 RANGE COLUMNS。
大規模分區的兩種策略#
核心觀念: 在非常大的規模下,B-Tree 索引無法有效運作。分區可以作為一種低成本的粗粒度索引,將你帶到資料的「鄰近區域」。
掃描資料,不建索引:不建任何索引,僅靠分區修剪將查詢限制在少數分區內進行全掃描。適用於需要定期存取大量資料的場景,分區數建議不超過 200 個。
建立索引,隔離熱資料:將「熱」資料放在單一分區內,使其連同索引都能放入記憶體,像操作小表一樣使用索引。
分區的常見陷阱#
- NULL 值破壞修剪:
YEAR()等函數可能回傳 NULL,導致第一個分區被額外檢查。解決方法:建立一個空的虛擬第一分區(PARTITION p_nulls VALUES LESS THAN (0)),或在 MySQL 5.5 使用RANGE COLUMNS。 - 分區與索引不匹配:如果索引欄位不在分區表達式中,查詢會開啟每個分區的索引樹。
- 選擇分區的成本:Range 分區會線性掃描分區定義列表,分區數越多越慢。建議限制在約 100 個。
- 開啟和鎖定分區的成本:在修剪之前發生,對單行查找等短操作影響尤其大。
- 維護操作的成本:
REORGANIZE PARTITION類似 ALTER TABLE,需要複製資料。
查詢最佳化#
使用 EXPLAIN PARTITIONS 確認修剪是否生效:
-- 無法修剪(對分區欄位使用函數)
EXPLAIN PARTITIONS SELECT * FROM sales_by_day WHERE YEAR(day) = 2010;
-- 可以修剪(直接比較分區欄位)
EXPLAIN PARTITIONS SELECT * FROM sales_by_day
WHERE day BETWEEN '2010-01-01' AND '2010-12-31';規則: 雖然你可以按表達式分區,但搜尋時必須直接比較欄位。即使 WHERE 條件看似多餘,也應明確指定分區鍵來幫助修剪。
視圖 (Views)#
視圖是不儲存任何資料的虛擬表,其內容來自定義時指定的 SQL 查詢。MySQL 視圖有兩種實作演算法:
MERGE vs TEMPTABLE#
| 演算法 | 運作方式 | 效能 |
|---|---|---|
| MERGE | 將視圖的 SQL 與查詢的 SQL 合併重寫為一條查詢 | 較好 |
| TEMPTABLE | 先執行視圖的 SELECT 並將結果放入臨時表,再對臨時表執行外層查詢 | 較差 |
-- 原始查詢
SELECT Code, Name FROM Oceania WHERE Name = 'Australia';
-- TEMPTABLE 方式(效能差)
CREATE TEMPORARY TABLE TMP_Oceania AS
SELECT * FROM Country WHERE Continent = 'Oceania';
SELECT Code, Name FROM TMP_Oceania WHERE Name = 'Australia';
-- MERGE 方式(效能好)
SELECT Code, Name FROM Country
WHERE Continent = 'Oceania' AND Name = 'Australia';flowchart TD
A["查詢 View"] --> B{"演算法類型?"}
B -->|MERGE| C["合併 View SQL 與外層查詢"]
C --> D["執行合併後的單一查詢"]
D --> E["回傳結果"]
B -->|TEMPTABLE| F["執行 View 的 SELECT"]
F --> G["結果存入臨時表"]
G --> H["對臨時表執行外層查詢"]
H --> E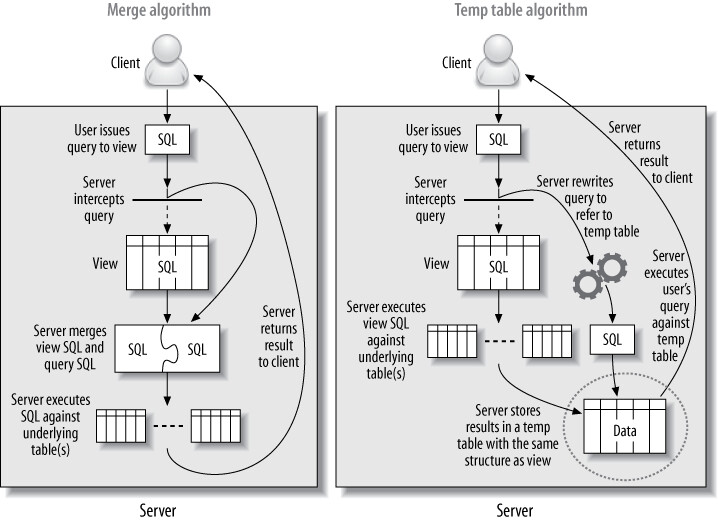
Figure 7.1: Two implementations of views
MySQL 在以下情況會使用 TEMPTABLE:視圖定義包含 GROUP BY、DISTINCT、聚合函數、UNION、子查詢,或任何破壞底層表與視圖行之間一對一關係的結構。
TEMPTABLE 的效能問題: 使用 TEMPTABLE 演算法的視圖效能可能非常差。外層查詢的 WHERE 條件不會下推到視圖內部查詢,且臨時表沒有索引,無法高效地在 JOIN 中使用。
可更新視圖 (Updatable Views)#
可更新視圖允許透過視圖修改底層表。使用 WITH CHECK OPTION 可以確保修改後的資料仍然符合視圖的 WHERE 條件。使用 TEMPTABLE 演算法的視圖不可更新。
視圖的效能注意事項#
- 視圖可用於實作欄位級權限,避免建立實際權限的開銷
- 即使是 MERGE 視圖也有額外開銷,且在高併發下可能導致最佳化器花費過多時間
- MySQL 不支援物化視圖 (materialized views),但可透過快取/摘要表或 Flexviews 工具模擬
外鍵約束 (Foreign Key Constraints)#
InnoDB 是 MySQL 內建唯一支援外鍵的儲存引擎。
效能影響#
- 每次資料變更都需要查詢另一張表進行檢查,即使有索引也有開銷
- 可能產生選擇度極低的巨大索引(如只有 3 個值的 status 欄位)
- 外鍵會導致查詢「觸及」其他表,造成額外的鎖定
- 插入子表資料時,必須鎖定父表中對應的行,可能導致意外的鎖等待和死鎖
實務建議: 在極高效能需求的場景中,許多人選擇不使用外鍵,改由應用程式碼保證一致性。可以考慮用觸發器或 ENUM 型別替代純約束用途的外鍵。
外鍵的優勢#
- 確保兩張相關表的資料一致性比在應用層做更高效
- 支援級聯刪除/更新(cascading delete/update),但是逐行操作,比批次操作慢
在 MySQL 中儲存程式碼#
MySQL 允許在伺服器端儲存和執行程式碼,包括儲存程序 (Stored Procedures)、儲存函數 (Stored Functions)、觸發器 (Triggers) 和事件 (Events)。
儲存程序和函數的優缺點#
| 面向 | 優點 | 缺點 |
|---|---|---|
| 效能 | 在資料所在的伺服器上執行,節省網路往返和延遲 | 將負載轉移到資料庫伺服器,而資料庫更難擴展 |
| 開發維護 | 集中化業務邏輯,可重複使用 | MySQL 缺乏良好的開發和除錯工具 |
| 安全 | 提供安全優勢和更細緻的權限控制 | — |
| 執行計畫 | 伺服器可快取執行計畫,降低重複呼叫的開銷 | — |
| 語言能力 | — | 語言相對緩慢和原始,不如應用語言靈活 |
| 部署 | — | 增加部署的複雜性 |
| 複寫 | — | 與基於語句的複寫互動有許多問題 |
效能對比: 在一項測試中,使用儲存程序插入一百萬行資料只需 101 秒,而透過客戶端應用程式需要 279 秒,透過 MySQL Proxy 需要 307 秒。儲存程序適合需要大量減少網路往返的場景。
觸發器 (Triggers)#
觸發器在 INSERT、UPDATE 或 DELETE 語句執行時觸發,可用於強制約束、維護反正規化表和摘要表。
主要限制:
| 限制 | 說明 |
|---|---|
| 每個表的每種事件只能有一個觸發器 | 無法對同一事件註冊多個觸發器 |
| 僅支援行級觸發器 | MySQL 只支援 FOR EACH ROW,不支援語句級觸發器,對大資料集效率較低 |
| 可能導致不明顯的死鎖和鎖等待 | 觸發器內的操作會取得額外的鎖 |
| 引擎行為差異 | InnoDB 觸發器在同一交易中運作,具有原子性;MyISAM 觸發器則無法回滾 |
事件 (Events)#
MySQL 5.1 引入的定時任務機制,類似 cron job,完全在 MySQL 內部運行:
CREATE EVENT optimize_somedb ON SCHEDULE EVERY 1 WEEK
DO
CALL optimize_tables('somedb');並行執行風險: MySQL 不會阻止同一事件的重疊執行。如果事件執行時間較長,可能在上一次未結束時再次觸發。應使用
GET_LOCK()實作互斥。
遊標 (Cursors)#
MySQL 的遊標是唯讀、只能前進的伺服器端遊標,實作基於臨時表。重要的是,遊標在 OPEN 時就執行整個查詢,即使你只 FETCH 一行也會讀取所有資料。如果只需要少量行,應使用 LIMIT。
預備語句 (Prepared Statements)#
預備語句使用增強的二進位客戶端/伺服器協定來高效傳輸資料。
優勢#
| 優勢 | 說明 |
|---|---|
| 解析一次 | 伺服器只需解析查詢一次 |
| 執行計畫快取 | 部分查詢最佳化只需執行一次(快取部分執行計畫) |
| 二進位協定更高效 | 如 DATE 只需 3 bytes 而非 ASCII 的 10 bytes |
| 減少網路流量 | 只傳輸參數而非整個查詢文字 |
| 安全性 | 提高安全性,降低 SQL 注入風險 |
最佳化階段#
| 階段 | 最佳化內容 |
|---|---|
| 準備時 | 解析查詢文字、消除否定、重寫子查詢 |
| 首次執行 | 簡化巢狀 JOIN、OUTER JOIN 轉 INNER JOIN |
| 每次執行 | 分區修剪、常數消除、JOIN 順序最佳化、存取方法分析 |
SQL 介面的預備語句#
SET @sql := 'SELECT actor_id, first_name, last_name
FROM sakila.actor WHERE first_name = ?';
PREPARE stmt_fetch_actor FROM @sql;
SET @actor_name := 'Penelope';
EXECUTE stmt_fetch_actor USING @actor_name;
DEALLOCATE PREPARE stmt_fetch_actor;主要用途是在儲存程序中建構動態 SQL,例如拼接表名和資料庫名(這些無法參數化)。
三種預備語句的區別#
| 類型 | 協定 | 運作方式 |
|---|---|---|
| 客戶端模擬 | 一般文字協定 | 客戶端驅動替換佔位符後直接發送完整 SQL |
| 伺服器端 | 二進位協定 | 發送骨架查詢,取得語句 handle 後重複執行 |
| SQL 介面 | 一般文字協定 | 透過 PREPARE/EXECUTE 語法操作 |
限制#
- 預備語句是連線本地的,斷線後失去
- MySQL 5.1 之前不能使用查詢快取
- 只使用一次時,準備的開銷可能大於直接執行
- 忘記 DEALLOCATE 會洩漏資源
使用者自定義函數 (UDF)#
UDF 使用 C/C++ 撰寫,動態連結到伺服器,具有平台相關性。相比 SQL 儲存函數,UDF 更快且能存取作業系統功能(如發送網路封包),也能建立聚合函數。
風險: UDF 中的錯誤可能導致整個伺服器崩潰、記憶體損壞或資料毀損。UDF 必須是完全執行緒安全的,因為它們在 MySQL 的多執行緒環境中執行。
外掛 (Plugins)#
MySQL 5.1 以後支援多種外掛 API:Procedure plugins、Daemon plugins(如 HandlerSocket)、INFORMATION_SCHEMA plugins、全文解析器 plugins、Audit plugins 和 Authentication plugins。
字元集與校對規則 (Character Sets and Collations)#
字元集 (character set) 是二進位編碼到符號的映射;校對規則 (collation) 是字元集的排序規則。每個字元集可以有多個校對規則,但校對規則只屬於一個字元集。
設定層級#
MySQL 的字元集設定形成一個預設值階層:
伺服器 (character_set_server)
→ 資料庫 (繼承自伺服器)
→ 表 (繼承自資料庫)
→ 欄位 (繼承自表) ← 唯一真正儲存值的層級flowchart TD
A["伺服器預設字元集"] --> B["資料庫字元集"]
B --> C["表字元集"]
C --> D["欄位字元集\n(唯一真正儲存值的層級)"]
style D fill:#ffa,stroke:#333客戶端/伺服器通訊#
三個關鍵設定控制字元集轉換:
| 設定 | 用途 |
|---|---|
character_set_client | 伺服器假設客戶端發送的語句使用的字元集 |
character_set_connection | 伺服器將語句轉換成此字元集處理 |
character_set_result | 伺服器將結果轉換成此字元集回傳給客戶端 |
sequenceDiagram
participant C as Client
participant S as MySQL Server
C->>S: 發送語句
Note over S: 用 character_set_client 解讀
S->>S: 轉換為 character_set_connection 處理
S->>S: 執行查詢
S-->>C: 轉換為 character_set_results 回傳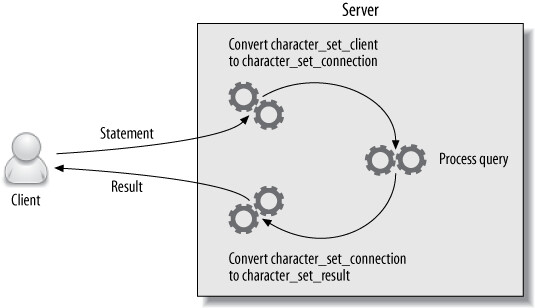
Figure 7.2: Client and server character sets
字元集不匹配的風險: 用
SET NAMES utf8告訴伺服器客戶端發送 UTF-8,但客戶端實際使用 latin1,會造成字元集不匹配,可能導致錯誤甚至安全問題。應使用mysql_set_charset()同時設定客戶端。
UTF-8 的效能影響#
- MySQL 內部使用固定大小緩衝區:
CHAR(10)在 UTF-8 下需要 30 bytes - VARCHAR/TEXT 在磁碟上不受此影響,但記憶體中的臨時表會分配最大長度
- 索引長度限制縮短為三分之一:最大鍵長 999 bytes,UTF-8 下只能索引 333 個字元
- 使用
CHAR_LENGTH()而非LENGTH()來計算字元數
字元集對查詢的影響#
- 如果 JOIN 兩張不同字元集的表,MySQL 必須轉換其中一個,可能無法使用索引
- 如果 ORDER BY 使用與索引不同的校對規則,會退化為 filesort
-- 使用索引排序(預設校對規則)
SELECT title, release_year FROM sakila.film ORDER BY title;
-- 退化為 filesort(指定不同校對規則)
SELECT title, release_year
FROM sakila.film ORDER BY title COLLATE utf8_bin;簡化原則: 盡量在伺服器層級選擇合理的預設字元集,避免混合使用多種字元集。統一字元集可以避免隱式轉換破壞索引使用和排序效能。
全文搜尋 (Full-Text Searching)#
全文搜尋允許對 CHAR、VARCHAR 和 TEXT 欄位進行基於相關性的關鍵字搜尋,支援自然語言和布林搜尋模式。
重要限制#
- 在撰寫時只有 MyISAM 支援全文索引(InnoDB 在 MySQL 5.6 預覽中)
- MyISAM 的表級鎖和缺乏崩潰恢復使其在大規模場景下基本不可用
- 實務上建議使用 Sphinx、Lucene、Solr 等外部方案
自然語言全文搜尋#
SELECT film_id, title, RIGHT(description, 25),
MATCH(title, description) AGAINST('factory casualties') AS relevance
FROM sakila.film_text
WHERE MATCH(title, description) AGAINST('factory casualties');- 全文索引中的欄位必須與
MATCH()中的欄位完全相同且順序一致 - MySQL 的全文搜尋只回傳相關度大於零的結果
- 在 WHERE 中使用
MATCH()會自動按相關度排序
布林全文搜尋#
SELECT film_id, title, RIGHT(description, 25)
FROM sakila.film_text
WHERE MATCH(title, description)
AGAINST('+factory +casualties' IN BOOLEAN MODE);- 布林搜尋支援運算子:
+(必須包含)、-(必須排除)、>(提高相關度)等 - 布林搜尋可以不使用全文索引,但無索引時會非常慢
- 布林搜尋不使用相關度排序
全文索引設計考量#
- 預設停用詞 (stopwords) 清單中的常見詞語會被忽略
- 預設最小詞長為 4 個字元(
ft_min_word_len),可調整但需重建索引 - 預設使用 50% 規則:出現在超過 50% 文件中的詞語會被忽略(布林模式不受此限)
- 全文索引不儲存每個詞在文件中的位置,因此無法用於鄰近搜尋 (proximity search)
效能提示: 可以透過
MATCH()在 WHERE 和 SELECT 中同時使用相同表達式來避免重複計算——MySQL 會識別出這是相同的全文搜尋,只執行一次。
全文搜尋的替代方案#
- Sphinx:專為全文搜尋設計的高效能引擎,強烈推薦用於大規模搜尋
- 使用布林搜尋時要注意其使用者定義的相關度排序,可能與自然語言搜尋差異很大
- 大型資料集上,考慮使用
MATCH()搭配LIMIT來避免過度掃描
分散式 (XA) 交易#
內部 XA 交易#
MySQL 內部使用 XA 交易來協調儲存引擎和二進位日誌(binary log)的同步。這在架構上是必要的,因為儲存引擎和伺服器是分離的。
不要隨意關閉
innodb_support_xa: 它不僅用於外部 XA 交易,還控制 InnoDB 和 binary log 之間的內部協調。關閉它會導致崩潰恢復不正確。
效能影響#
- XA 交易破壞了 InnoDB 的群組提交 (group commit) 能力,導致更多的
fsync()呼叫 - 啟用 binary log 時,每個交易至少需要三次
fsync() - 強烈建議使用帶有電池備援寫入快取的 RAID 控制器來改善效能
sequenceDiagram
participant C as Client
participant M as MySQL Server
participant I as InnoDB
participant B as Binary Log
C->>M: COMMIT
M->>I: Prepare(fsync #1)
M->>B: Write binary log event(fsync #2)
M->>I: Commit(fsync #3)
I-->>M: 完成
M-->>C: OK外部 XA 交易#
MySQL 可以參與但不能管理外部分散式交易。一般建議避免在不可預測的環境(如 WAN)中使用 XA,考慮用本地佇列加小型交易或 MySQL 複寫來替代。
MySQL 查詢快取 (Query Cache)#
查詢快取儲存完整的 SELECT 結果集。當快取命中時,伺服器可以跳過解析、最佳化和執行步驟,直接返回已儲存的結果。
可擴展性問題: 查詢快取是整個伺服器的單一競爭點,在多核心伺服器上可能導致嚴重的停頓。最佳做法是預設停用查詢快取,只有在確認非常有益時才啟用,且大小不超過幾十 MB。
快取命中的檢查方式#
- 查找鍵是查詢文字本身的雜湊值,加上當前資料庫、客戶端協定版本等
- MySQL 不會正規化或參數化語句:大小寫、空格、註解的任何差異都會阻止命中
- 包含非確定性函數(如
NOW()、CURRENT_DATE())的查詢不會被快取 - 子查詢、視圖內部的查詢和儲存程序中的查詢無法使用查詢快取
-- 不可快取
... DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY)
-- 可快取(將日期作為字面值)
... DATE_SUB('2007-07-14', INTERVAL 1 DAY)查詢快取的開銷#
- 讀取查詢:需要先檢查快取
- 可快取但未命中的查詢:生成結果後需要額外儲存
- 寫入查詢:必須失效相關的快取項目,快取越大或越碎片化,失效成本越高
- InnoDB 交易中修改表會導致該表的所有快取項目失效,且在交易提交前無法被快取
記憶體分配機制#
查詢快取完全在記憶體中管理。伺服器啟動時初始化一整塊記憶體池,之後自行管理區塊分配(不依賴作業系統的 malloc):
- 開始快取結果時,伺服器選擇至少
query_cache_min_res_unit大小的區塊 - 如果區塊滿了,再分配新區塊繼續儲存
- 結果完成後,修剪最後一個區塊的剩餘空間,合併到相鄰的空閒區塊
flowchart TD
A["開始快取查詢結果"] --> B["分配最小區塊"]
B --> C{"區塊已滿?"}
C -->|否| D["繼續填充"]
D --> C
C -->|是| E["分配新區塊"]
E --> D
D -->|"結果完成"| F["修剪最後區塊的剩餘空間"]
F --> G["合併到相鄰空閒區塊"]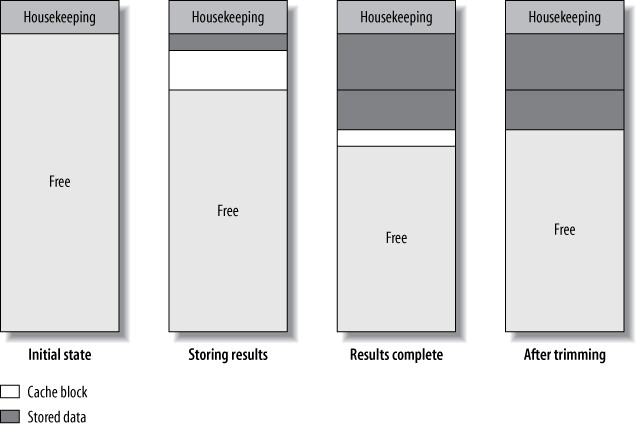
Figure 7.3: How the query cache allocates blocks to store a result
碎片化問題#
當多個結果同時被快取和修剪時,可能在結果之間產生太小而無法重複使用的空閒區塊,這就是碎片化 (fragmentation)。快取失效也會造成碎片化。
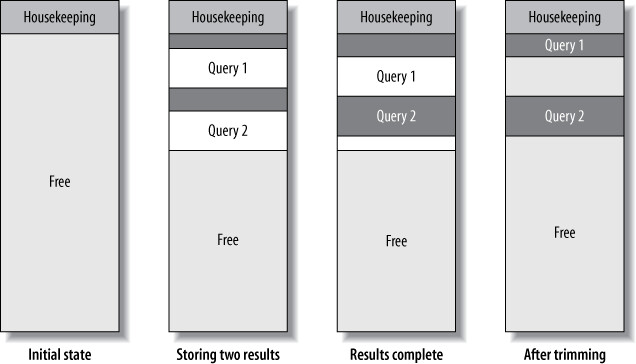
Figure 7.4: Fragmentation caused by storing results in the query cache
判斷查詢快取是否有益#
查詢快取最受益的查詢類型是:產生成本高但結果集小的查詢(如大表的聚合查詢)。
快取命中率 = Qcache_hits / (Qcache_hits + Com_select)
但命中率不容易解讀——即使 30% 的命中率也可能很有價值,取決於被快取的是哪些查詢。更有意義的指標是 hit-to-insert 比率:
Qcache_hits / Qcache_inserts比率至少 3:1 才值得考慮- 10:1 或更高才算真正有益
- 如果達不到,可能應該停用查詢快取
快取失效的原因#
- 查詢不可快取(包含非確定性函數,或結果集太大)
- 伺服器從未見過此查詢
- 之前的快取結果已被移除(記憶體不足、被失效、或手動清除)
配置參數#
| 參數 | 說明 |
|---|---|
query_cache_type | OFF / ON / DEMAND(DEMAND 模式只快取帶 SQL_CACHE 提示的查詢) |
query_cache_size | 分配給查詢快取的總記憶體,必須是 1024 的倍數 |
query_cache_min_res_unit | 分配區塊的最小大小 |
query_cache_limit | 最大可快取的結果集大小 |
query_cache_wlock_invalidate | 是否允許讀取被其他連線鎖定的表的快取結果 |
減少碎片化#
- 適當設定
query_cache_min_res_unit:太小會增加分配次數,太大會浪費記憶體 - 監控
Qcache_free_blocks:如果接近Qcache_total_blocks / 2,表示嚴重碎片化 - 使用
FLUSH QUERY CACHE整理碎片(會短暫鎖定整個伺服器) - 使用
RESET QUERY CACHE清空快取
改善快取使用率#
如果 Qcache_lowmem_prunes 快速增長:
- 如果有很多空閒區塊 → 碎片化問題
- 如果空閒區塊很少 → 可能需要增加
query_cache_size
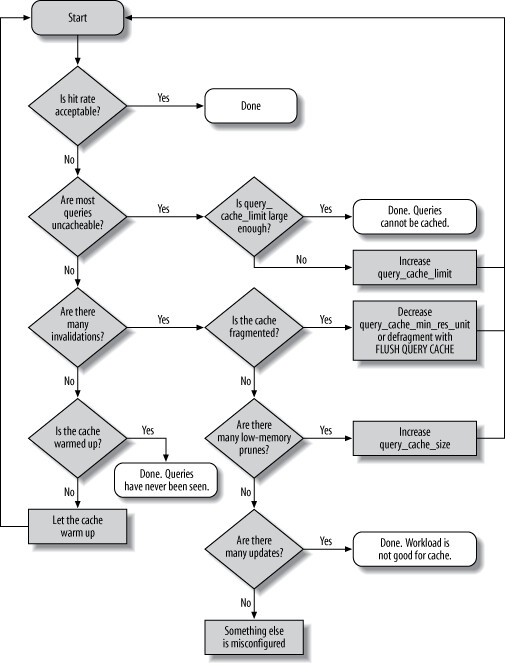
Figure 7.5: How to analyze and configure the query cache
InnoDB 與查詢快取的互動#
InnoDB 透過 MVCC 與查詢快取互動更加複雜:
- 每張表有一個交易 ID 計數器,ID 小於計數器值的交易無法讀寫查詢快取
- 對表加鎖也會使涉及該表的查詢不可快取
- 交易提交時,計數器更新為系統交易 ID(非該交易自身 ID),可能導致其他交易被排除在查詢快取外
- InnoDB 可以明確告訴伺服器失效特定表的查詢(如外鍵的
ON DELETE CASCADE)
通用最佳化建議#
- 使用多個小表比一個大表更有利於快取失效的精細控制
- 批次寫入比逐條寫入更高效(只觸發一次失效)
- 寫入密集的應用,考慮完全停用查詢快取(設定
query_cache_size = 0) - 高併發讀取應用也可能因快取 mutex 競爭而受益於停用快取
- 使用
DEMAND模式 +SQL_CACHE提示進行精細控制
替代方案: 如果需要高效能快取,查詢快取不是最佳選擇。考慮使用 memcached 或其他外部快取解決方案(詳見第 14 章),可以完全跳過與資料庫的通訊。
本章重點摘要#
| 主題 | 核心建議 |
|---|---|
| 分區表 | 作為粗粒度索引使用,限制 150 個分區以內,監控 per-row 和 per-query 的開銷 |
| 視圖 | 避免使用 TEMPTABLE 的視圖,因為 WHERE 不會下推且無索引 |
| 外鍵 | 確保系統完整性的好功能,但高效能場景下多數人選擇不使用 |
| 儲存程式碼 | 適合減少網路往返的場景,但與基於語句的複寫有大量問題 |
| 預備語句 | 適合重複執行的查詢,二進位協定更高效 |
| 字元集 | 確保從客戶端到伺服器的字元集配置一致,UTF-8 會增加記憶體和儲存成本 |
| 全文搜尋 | 只有 MyISAM 支援,大規模場景建議使用 Sphinx 等外部方案 |
| XA 交易 | 不要關閉 innodb_support_xa,它對崩潰恢復至關重要 |
| 查詢快取 | 預設停用,只在確認有益時小量啟用,hit-to-insert 比率 10:1 以上才值得 |