概述#
查詢優化、索引優化和 schema 優化三者相輔相成。本章從通用查詢設計原則出發,深入探討查詢優化與伺服器內部機制,說明 MySQL 如何執行查詢,以及如何改變查詢執行計畫。
核心觀念: 查詢效能最終都是關於 回應時間(response time)。查詢由多個子任務組成,優化就是消除子任務、減少執行次數、或讓子任務執行得更快。
慢查詢基礎:優化資料存取#
查詢效能不佳最根本的原因是處理了太多資料。分析一個慢查詢可從兩個步驟著手:
- 應用程式是否請求了多餘的資料?(太多列或太多欄)
- MySQL 伺服器是否掃描了過多的列來產出結果?
你是否向資料庫要了不需要的資料?#
常見錯誤包括:
- 取回過多列(rows):應用程式取得完整結果集後只用前 N 筆,解法是加上
LIMIT - 多表 JOIN 時 SELECT *:應只取需要的欄位,例如
SELECT sakila.actor.*而非SELECT * - 取回所有欄位:
SELECT *會阻止 covering index 等優化,增加 I/O、記憶體和 CPU 開銷 - 重複取回相同資料:應在應用層做快取,避免對同一筆資料反覆查詢
MySQL 是否檢查了過多資料?#
評估查詢成本的三個簡單指標:
- 回應時間(Response time):由 service time(實際處理時間)和 queue time(等待時間,如 I/O、鎖等待)組成
- 檢查的列數(Rows examined):理想情況是與回傳列數一致,但實務上通常 1:1 到 10:1 的比率,有時差距會更大
- 回傳的列數(Rows returned)
QUBE 估算法: 檢視查詢執行計畫和涉及的索引,估算需要多少次 sequential 和 random I/O,乘以硬體的 I/O 時間,便可得到一個粗略的回應時間上限。
列的存取類型#
EXPLAIN 輸出的 type 欄位顯示存取方法,從最快到最慢依序為:
| type | 說明 |
|---|---|
| const | 常數查找(unique index) |
| eq_ref | 唯一索引查找 |
| ref | 非唯一索引查找 |
| range | 範圍掃描 |
| index | 索引掃描 |
| ALL | 全表掃描 |
MySQL 套用 WHERE 條件的三種方式(由好到差):
| 優先順序 | 過濾方式 | EXPLAIN 指標 |
|---|---|---|
| 1(最佳) | 在 storage engine 層透過索引過濾 | — |
| 2 | 使用 covering index 在 server 層過濾,不需讀取資料列 | Extra: Using index |
| 3(最差) | 從表中讀取列後再以 WHERE 過濾 | Extra: Using where |
若發現掃描了大量列卻只產出少數結果,可嘗試:使用 covering index、改變 schema(如 summary table)、或改寫查詢讓優化器能更有效執行。
查詢重構策略#
複雜查詢 vs. 多個簡單查詢#
MySQL 對連線/斷線的處理非常高效,在一般硬體上可每秒執行超過 100,000 個簡單查詢。有時將一個複雜查詢拆成多個簡單查詢反而更高效,但也不要走極端——例如逐欄查詢每一列。
拆分查詢(Chopping Up a Query)#
將大型操作分批執行。例如刪除大量過期資料時,不要一次刪完:
-- 不好:一次刪除大量資料,長時間鎖定
DELETE FROM messages WHERE created < DATE_SUB(NOW(), INTERVAL 3 MONTH);
-- 好:每次刪 10,000 筆,分批執行
DELETE FROM messages WHERE created < DATE_SUB(NOW(), INTERVAL 3 MONTH) LIMIT 10000;分批刪除可降低對伺服器的影響、減少 replication lag,並可在批次之間加入 sleep。
JOIN 分解(Join Decomposition)#
將多表 JOIN 拆解為多個單表查詢,在應用層執行 JOIN:
-- 原始 JOIN
SELECT * FROM tag
JOIN tag_post ON tag_post.tag_id = tag.id
JOIN post ON tag_post.post_id = post.id
WHERE tag.tag = 'mysql';
-- 分解後
SELECT * FROM tag WHERE tag = 'mysql';
SELECT * FROM tag_post WHERE tag_id = 1234;
SELECT * FROM post WHERE post.id IN (123, 456, 567, 9098, 8904);這樣做的好處:
| 優點 | 說明 |
|---|---|
| 快取更有效率 | 可直接利用物件快取,減少 cache invalidation |
| 減少鎖競爭 | 單表查詢鎖定範圍更小 |
| 更容易水平擴展 | 不同表可放在不同伺服器 |
| IN() list 更高效 | MySQL 對 IN() 使用二分搜尋(O(log n)),有時比 JOIN 更快 |
| 減少冗餘存取 | 應用層 JOIN 每列只讀一次 |
查詢執行基礎#
MySQL 執行查詢的步驟如下:
- Client 將 SQL 語句傳送給 Server
- Server 檢查 Query Cache,命中則直接回傳快取結果
- Server 進行 解析(parse)、預處理(preprocess)、優化(optimize),產生查詢執行計畫
- 查詢執行引擎 依據計畫呼叫 storage engine API 執行
- Server 將結果回傳 Client
flowchart TD
A["Client 發送 SQL"] --> B{"Query Cache 命中?"}
B -->|命中| C["直接回傳結果"]
B -->|未命中| D["Parser 解析"]
D --> E["Preprocessor 語意檢查"]
E --> F["Query Optimizer 最佳化"]
F --> G["執行引擎呼叫 Storage Engine API"]
G --> H["回傳結果給 Client"]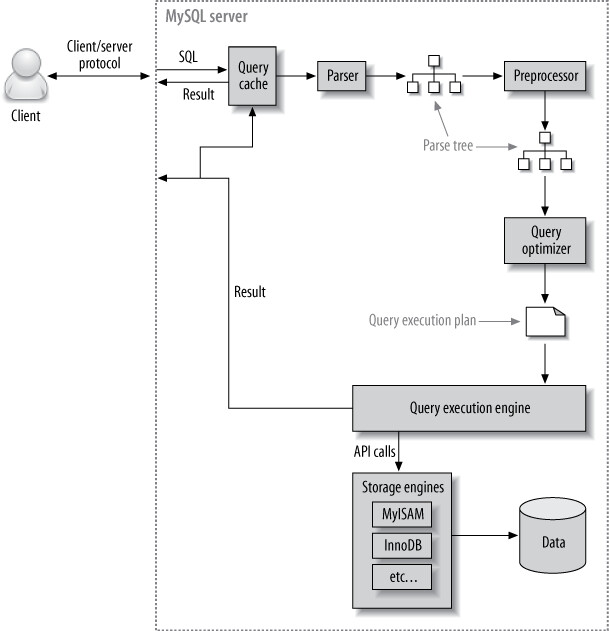
Figure 6.1: Execution path of a query
MySQL Client/Server 協定#
- 使用 半雙工(half-duplex) 協定:任何時刻只能單向傳輸
- Client 以單一封包送出查詢(受
max_allowed_packet限制) - Server 回應由多個封包組成,Client 必須接收完整結果集
- 多數 client library 預設將整個結果集緩衝到記憶體,這可讓 server 更快釋放鎖和資源
- 若結果集很大,可用 unbuffered 模式(如 PHP 的
mysql_unbuffered_query()),但 server 端的鎖和資源會保持開啟
sequenceDiagram
participant C as Client
participant S as MySQL Server
C->>S: 發送查詢(單一封包)
Note over C,S: 半雙工:同一時間只能單向傳輸
S-->>C: 回應封包 1
S-->>C: 回應封包 2
S-->>C: 回應封包 N
Note over C: Client 必須接收完整結果集查詢狀態(Query States)#
透過 SHOW FULL PROCESSLIST 可觀察:
| 狀態 | 說明 |
|---|---|
| Sleep | 等待 client 新查詢 |
| Query | 正在執行查詢或傳送結果 |
| Locked | 等待 server 層的 table lock(MyISAM 常見) |
| Analyzing and statistics | 檢查 storage engine 統計並優化查詢 |
| Copying to tmp table [on disk] | 處理 GROUP BY、filesort 或 UNION |
| Sorting result | 排序結果集 |
| Sending data | 在查詢各階段間傳送資料,或正在產生/回傳結果 |
Query Cache#
- 在解析之前就進行 case-sensitive 雜湊比對
- 即使只差一個位元組也不會命中
- 命中後檢查權限,通過則直接回傳快取結果,跳過所有後續步驟
查詢優化流程#
Parser 與 Preprocessor#
- Parser 將查詢分解為 token,建立 parse tree,驗證語法
- Preprocessor 檢查語意(表和欄位是否存在、名稱別名是否曖昧)、檢查權限
flowchart LR
A["SQL 文字"] --> B["Parser"]
B -->|"Tokenize + 建立 Parse Tree"| C["Preprocessor"]
C -->|"語意檢查 + 權限檢查"| D["Query Optimizer"]
D -->|"產生執行計畫"| E["執行引擎"]Query Optimizer#
MySQL 使用 cost-based optimizer,預測各執行計畫的成本,選擇最低成本者。成本單位最初是單次隨機 4KB 資料頁讀取,現已更為複雜。
-- 查看查詢估算成本
SELECT SQL_NO_CACHE COUNT(*) FROM sakila.film_actor;
SHOW STATUS LIKE 'Last_query_cost';
-- 結果:1040.599000(約 1040 次隨機頁面讀取)優化器不一定選擇最佳計畫的原因:
- 統計資料可能不準確(InnoDB 因 MVCC 不維護精確列數)
- 成本模型不等同真實成本(不考慮快取中的頁面)
- MySQL 追求最小成本而非最快時間
- 不考慮併發查詢的影響
- 有時遵循規則而非成本(如 FULLTEXT MATCH() 一定用 FULLTEXT index)
- 不納入 stored function / UDF 的成本
靜態優化 vs. 動態優化#
- 靜態優化(Compile-time):檢查 parse tree 即可執行,如代數變換。執行一次即永久有效
- 動態優化(Runtime):依賴上下文(如 WHERE 值、索引列數),每次執行都需重新評估
優化器知道的技巧#
| 優化技巧 | 說明 |
|---|---|
| 重排 JOIN 順序 | 選擇掃描最少列的順序 |
| OUTER JOIN 轉 INNER JOIN | 當 WHERE 和 schema 允許時 |
| 代數等價變換 | (5=5 AND a>5) → a>5 |
| COUNT() / MIN() / MAX() 優化 | B-Tree 索引可直接讀取第一/最後一列 |
| 常數表達式求值與折疊 | 編譯時計算常數表達式 |
| Covering index | 只從索引取資料,不讀表 |
| 子查詢優化 | 轉換為索引查找 |
| 提前終止 | LIMIT、不可能條件(Impossible WHERE)、NOT EXISTS 等 |
| 等值傳播 | JOIN 條件中的等值關係自動傳播到 WHERE |
| IN() list 用二分搜尋 | O(log n),比等價的多個 OR(O(n))更快 |
不要試圖比優化器聰明。 大多數情況下讓優化器自行決定即可。只有當你確定優化器不正確,且知道原因時,才考慮用 hint、改寫查詢、調整 schema 或加索引來介入。
MySQL 的 JOIN 執行策略#
MySQL 將所有查詢都視為 JOIN——包括單表查詢、子查詢、UNION 等。
核心演算法是 Nested-Loop Join:
outer_iter = iterator over tbl1 where col1 IN(5,6)
outer_row = outer_iter.next
while outer_row
inner_iter = iterator over tbl2 where col3 = outer_row.col3
inner_row = inner_iter.next
while inner_row
output [ outer_row.col1, inner_row.col2 ]
inner_row = inner_iter.next
end
outer_row = outer_iter.next
end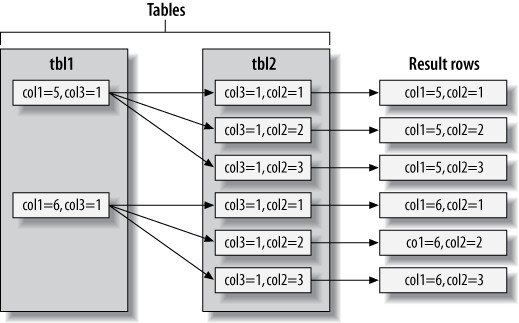
Figure 6.2: Swim-lane diagram illustrating retrieving rows using a join
- MySQL 不產生 byte-code,而是用一棵指令樹作為執行計畫
- 所有多表查詢都是 left-deep tree(依序從一張表開始逐一查找匹配列)
- FROM 子句中的子查詢先執行成臨時表(derived table,無索引)
- UNION 也透過臨時表實現
- MySQL 不支援 FULL OUTER JOIN(因為 nested-loop 無法處理)
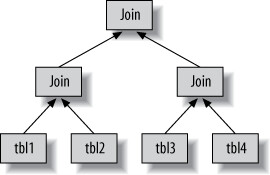
Figure 6.3: One way to join multiple tables
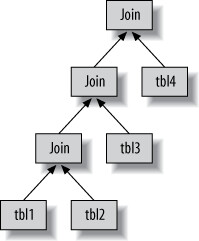
Figure 6.4: How MySQL joins multiple tables
JOIN 優化器#
JOIN 優化器估算不同 JOIN 順序的成本,選擇最低成本者。例如:
SELECT film.film_id, film.title, film.release_year,
actor.actor_id, actor.first_name, actor.last_name
FROM sakila.film
INNER JOIN sakila.film_actor USING(film_id)
INNER JOIN sakila.actor USING(actor_id);MySQL 會選擇從 actor(200 列)開始而非 film(951 列),因為這樣後續索引查找次數更少。可用 STRAIGHT_JOIN 強制指定順序,但通常 JOIN 優化器做得比人好。
搜尋空間問題: n 張表的 JOIN 有 n! 種排列。當表數過多時,優化器會使用「貪婪搜尋」等捷徑,由
optimizer_search_depth變數控制深度。
排序優化#
當 MySQL 無法用索引排序時,會執行 filesort(不一定使用檔案)。兩種演算法:
| 演算法 | 運作方式 | 優點 | 缺點 |
|---|---|---|---|
| Two-pass(舊) | 先排序列指標和排序欄位,再重新讀取列 | 排序時資料量小 | 隨機 I/O 多 |
| Single-pass(新) | 一次讀取所有需要的欄位後排序 | 避免二次讀取 | 佔用更多排序緩衝區 |
當 ORDER BY 只參考 JOIN 第一張表的欄位時,MySQL 可先排序該表再 JOIN(Extra: Using filesort)。否則必須 JOIN 完存入臨時表後再排序(Extra: Using temporary; Using filesort)。
查詢執行引擎#
- 接收優化階段輸出的執行計畫(指令樹),依序呼叫 storage engine 的 handler API
- 每張表由一個 handler instance 代表
- 核心操作只有十幾個「building block」(如讀取索引第一列、讀取下一列等)
回傳結果給 Client#
- 即使不回傳資料的查詢也會回傳影響列數等資訊
- 結果可被放入 Query Cache
- 結果是增量回傳的:一產生一列就立即送出,不需等整個結果集完成
- 讓 server 無需在記憶體中保留列,client 也能更早開始處理
MySQL 查詢優化器的限制#
關聯子查詢(Correlated Subqueries)#
MySQL 對 IN() 子查詢的處理有時非常差。例如:
-- 你期望的執行方式:先執行子查詢,得到 IN list
SELECT * FROM sakila.film
WHERE film_id IN(
SELECT film_id FROM sakila.film_actor WHERE actor_id = 1);
-- MySQL 實際的改寫:變成 DEPENDENT SUBQUERY,對外表每一列都執行子查詢
SELECT * FROM sakila.film
WHERE EXISTS (
SELECT * FROM sakila.film_actor WHERE actor_id = 1
AND film_actor.film_id = film.film_id);解決方案:
-- 改寫為 JOIN
SELECT film.* FROM sakila.film
INNER JOIN sakila.film_actor USING(film_id)
WHERE actor_id = 1;不要盲目聽從「永遠避免子查詢」的建議。 有時 correlated subquery 反而是最佳或合理的方式。例如
NOT EXISTS搭配LEFT OUTER JOIN的比較中,兩者效能可能接近。務必實測,不要假設。MySQL 5.6 及 MariaDB 對子查詢有顯著改進。
UNION 的限制#
MySQL 無法將外層條件「推入」UNION 內部。應在每個 SELECT 內部重複加上 LIMIT 和 ORDER BY:
-- 不好:兩邊共 799 列存入臨時表,再取 20 筆
(SELECT first_name, last_name FROM sakila.actor ORDER BY last_name)
UNION ALL
(SELECT first_name, last_name FROM sakila.customer ORDER BY last_name)
LIMIT 20;
-- 好:每邊各限 20 筆,臨時表只有 40 列
(SELECT first_name, last_name FROM sakila.actor ORDER BY last_name LIMIT 20)
UNION ALL
(SELECT first_name, last_name FROM sakila.customer ORDER BY last_name LIMIT 20)
LIMIT 20;其他限制#
- 等值傳播的副作用:大型
IN()list 會被複製到所有等值關聯的欄位,可能拖慢優化和執行 - 無平行執行:MySQL 無法在多 CPU 上平行執行單一查詢
- 無 Hash Join:一切都是 nested-loop join(MariaDB 支援 hash join)
- Loose Index Scan 受限:MySQL 傳統上無法掃描不連續的索引範圍
Loose Index Scan#
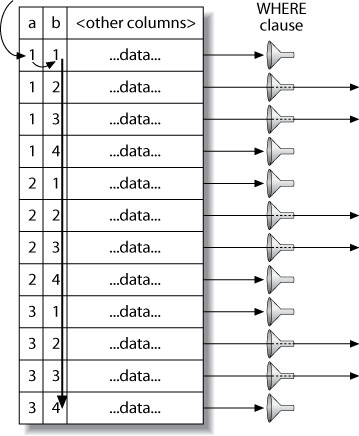
Figure 6.5: MySQL scans the entire table to find rows
當查詢的 WHERE 條件不包含複合索引的第一個欄位時,MySQL 只能做全表掃描。理論上可以在索引中跳躍式掃描(loose index scan),但 MySQL 只在有限情境支援:
-- MySQL 5.0+ 支援的 loose index scan:GROUP BY 中的 MAX/MIN
EXPLAIN SELECT actor_id, MAX(film_id)
FROM sakila.film_actor
GROUP BY actor_id;
-- Extra: Using index for group-by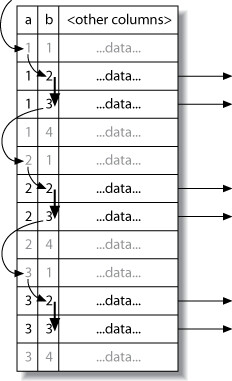
Figure 6.6: A loose index scan
MySQL 5.6 的 Index Condition Pushdown 可改善部分限制。
MIN() 和 MAX() 的優化限制#
-- MySQL 無法優化:會全表掃描
SELECT MIN(actor_id) FROM sakila.actor WHERE first_name = 'PENELOPE';
-- 改寫:利用主鍵排序 + LIMIT
SELECT actor_id FROM sakila.actor USE INDEX(PRIMARY)
WHERE first_name = 'PENELOPE' LIMIT 1;同一表的 SELECT 與 UPDATE#
MySQL 不允許同時對同一張表 SELECT 和 UPDATE。解法是用 derived table(臨時表):
UPDATE tbl
INNER JOIN (
SELECT type, COUNT(*) AS cnt FROM tbl GROUP BY type
) AS der USING(type)
SET tbl.cnt = der.cnt;查詢優化器 Hints#
| Hint | 用途 |
|---|---|
HIGH_PRIORITY / LOW_PRIORITY | 調整語句相對優先級(table-level locking 有效) |
DELAYED | INSERT/REPLACE 立即返回,列緩衝批次寫入 |
STRAIGHT_JOIN | 強制按語句中的順序 JOIN |
SQL_SMALL_RESULT / SQL_BIG_RESULT | 提示 GROUP BY/DISTINCT 使用臨時表或排序 |
SQL_BUFFER_RESULT | 將結果存入臨時表,儘快釋放表鎖 |
SQL_CACHE / SQL_NO_CACHE | 控制查詢快取行為 |
SQL_CALC_FOUND_ROWS | 計算完整結果集大小(即使有 LIMIT),慎用 |
FOR UPDATE / LOCK IN SHARE MODE | 列級鎖定(InnoDB),會停用 covering index,盡量避免 |
USE INDEX / IGNORE INDEX / FORCE INDEX | 指定或排除索引 |
相關設定變數:
optimizer_search_depth:控制部分計畫探索深度optimizer_prune_level:允許跳過某些計畫optimizer_switch:啟用/停用特定優化功能
升級 MySQL 時要小心 hint。 舊版的 hint 可能阻止新版優化器策略生效。使用 Percona Toolkit 的
pt-upgrade來驗證查詢在新版本上的行為。
優化特定類型的查詢#
優化 COUNT() 查詢#
COUNT() 的兩種行為:
COUNT(expr):計算表達式非 NULL 的次數COUNT(*):計算列數(不展開*,直接計數)
MyISAM 的 COUNT(*) 只有在沒有 WHERE 條件時才特別快(因為 storage engine 直接維護列數)。有 WHERE 時並沒有魔法。
實用技巧:
-- 利用 MyISAM 的特性做反向計數
-- 原始:掃描 4,079 列
SELECT COUNT(*) FROM world.City WHERE ID > 5;
-- 改寫:只掃描 5 列(子查詢被優化為常數)
SELECT (SELECT COUNT(*) FROM world.City) - COUNT(*)
FROM world.City WHERE ID <= 5;-- 在同一查詢中計算多個值的計數
SELECT SUM(IF(color = 'blue', 1, 0)) AS blue,
SUM(IF(color = 'red', 1, 0)) AS red
FROM items;
-- 或用 COUNT + OR NULL
SELECT COUNT(color = 'blue' OR NULL) AS blue,
COUNT(color = 'red' OR NULL) AS red
FROM items;若不需精確計數,可用 EXPLAIN 的估算列數作為近似值。對於複雜計數,考慮使用 summary table 或外部快取(如 memcached)。
優化 JOIN 查詢#
- 確保
ON/USING欄位有索引。考慮 JOIN 順序——通常只需在 第二張表 加索引 GROUP BY或ORDER BY盡量只參考單一表的欄位,讓 MySQL 能用索引- 升級 MySQL 時注意 JOIN 語法和運算子優先級的變化
優化子查詢#
在 MySQL 5.5 及之前,通常建議改寫為 JOIN。但 MySQL 5.6+ 和 MariaDB 對子查詢有大幅改進,需實測判斷。
優化 GROUP BY 和 DISTINCT#
- 兩者在內部常互相轉換,都受益於索引
- 沒有索引時,MySQL 用臨時表或 filesort 分組
- 以 lookup table 的 ID 而非值 做 GROUP BY 更高效:
-- 較慢:以字串分組
GROUP BY actor.first_name, actor.last_name;
-- 較快:以 ID 分組
GROUP BY film_actor.actor_id;- 避免在 GROUP BY 查詢中 SELECT 非分組欄位(結果不確定),建議設定
SQL_MODE包含ONLY_FULL_GROUP_BY - 若不需要排序,加上
ORDER BY NULL可避免 MySQL 自動對 GROUP BY 結果排序 - WITH ROLLUP 的超聚合功能可能不夠優化,考慮在應用層實作
優化 LIMIT 和 OFFSET#
高 OFFSET 的查詢非常昂貴——LIMIT 10000, 20 實際產生 10,020 列再丟棄前 10,000 筆。
Deferred Join 技巧:
-- 原始:大表上很慢
SELECT film_id, description FROM sakila.film ORDER BY title LIMIT 50, 5;
-- 改寫:先在索引上定位,再 JOIN 回完整列
SELECT film.film_id, film.description
FROM sakila.film
INNER JOIN (
SELECT film_id FROM sakila.film ORDER BY title LIMIT 50, 5
) AS lim USING(film_id);書籤法(Bookmark):記住上一頁最後一筆的位置,避免使用 OFFSET:
-- 第一頁
SELECT * FROM sakila.rental ORDER BY rental_id DESC LIMIT 20;
-- 結果:16049 ~ 16030
-- 下一頁:從上次位置繼續
SELECT * FROM sakila.rental
WHERE rental_id < 16030
ORDER BY rental_id DESC LIMIT 20;優化 SQL_CALC_FOUND_ROWS#
SQL_CALC_FOUND_ROWS 會讓 server 產生並丟棄整個結果集,非常昂貴。替代方案:
- 取 N+1 筆(如取 21 筆但顯示 20 筆),有第 21 筆就顯示「下一頁」連結
- 快取多於需要的列數(如 1,000 筆),後續頁從快取取
- 用
EXPLAIN的列數估算 - 用獨立的
COUNT(*)查詢(若有 covering index 會更快)
優化 UNION#
- 永遠使用
UNION ALL,除非確實需要去重。UNION(不加 ALL)會對臨時表做 DISTINCT,以完整列判斷唯一性,非常昂貴 - 手動將
WHERE、LIMIT、ORDER BY推入每個 SELECT 子句中 - MySQL 總是將 UNION 結果存入臨時表
使用者自定義變數(User-Defined Variables)#
自定義變數是連線層級的臨時值容器,可實現程序式與關聯式邏輯的混合。
SET @one := 1;
SET @min_actor := (SELECT MIN(actor_id) FROM sakila.actor);
SET @last_week := CURRENT_DATE - INTERVAL 1 WEEK;注意事項:
- 會停用 Query Cache
- 不能用於表名、欄名或 LIMIT 子句
- 連線綁定,無法跨連線共享
- 賦值順序可能不確定,取決於查詢計畫
:=運算子優先級最低,需注意括號
排名查詢範例:
SET @curr_cnt := 0, @prev_cnt := 0, @rank := 0;
SELECT actor_id,
@curr_cnt := cnt AS cnt,
@rank := IF(@prev_cnt <> @curr_cnt, @rank + 1, @rank) AS rank,
@prev_cnt := @curr_cnt AS dummy
FROM (
SELECT actor_id, COUNT(*) AS cnt
FROM sakila.film_actor
GROUP BY actor_id
ORDER BY cnt DESC
LIMIT 10
) AS der;將賦值放在
LEAST()等函數內可隱藏回傳值,避免產生多餘欄位或影響排序結果。GREATEST()、COALESCE()、IF()等函數也適用。
Lazy UNION 技巧: 利用變數讓 UNION 的第二個分支只在第一個無結果時才執行:
SELECT GREATEST(@found := -1, id) AS id, 'users' AS which_tbl
FROM users WHERE id = 1
UNION ALL
SELECT id, 'users_archived'
FROM users_archived WHERE id = 1 AND @found IS NULL
UNION ALL
SELECT 1, 'reset' FROM DUAL WHERE (@found := NULL) IS NOT NULL;案例研究#
建立佇列表(Queue Table)#
佇列表的常見問題:表會越來越大,且 polling + locking 造成競爭。
關鍵設計:
CREATE TABLE unsent_emails (
id INT NOT NULL PRIMARY KEY AUTO_INCREMENT,
status ENUM('unsent', 'claimed', 'sent'),
owner INT UNSIGNED NOT NULL DEFAULT 0,
ts TIMESTAMP,
KEY (owner, status, ts)
);不要用 SELECT FOR UPDATE,改用 UPDATE 直接認領:
-- 不好:SELECT FOR UPDATE 造成鎖競爭
BEGIN;
SELECT id FROM unsent_emails
WHERE owner = 0 AND status = 'unsent' LIMIT 10 FOR UPDATE;
UPDATE unsent_emails SET status = 'claimed', owner = CONNECTION_ID()
WHERE id IN(123, 456, 789);
COMMIT;
-- 好:直接 UPDATE 認領,事務更短,鎖更少
SET AUTOCOMMIT = 1;
COMMIT;
UPDATE unsent_emails
SET status = 'claimed', owner = CONNECTION_ID()
WHERE owner = 0 AND status = 'unsent' LIMIT 10;
SET AUTOCOMMIT = 0;
SELECT id FROM unsent_emails
WHERE owner = CONNECTION_ID() AND status = 'claimed';sequenceDiagram
participant W as Worker
participant DB as Database
rect rgb(255, 230, 230)
Note over W,DB: 差的做法(長事務、多鎖競爭)
W->>DB: BEGIN
W->>DB: SELECT ... FOR UPDATE(取得鎖)
W->>DB: UPDATE ... SET owner = me
W->>DB: COMMIT(釋放鎖)
end
rect rgb(230, 255, 230)
Note over W,DB: 好的做法(短事務、少鎖)
W->>DB: UPDATE ... SET owner = me LIMIT 1(原子認領)
W->>DB: SELECT ... WHERE owner = me(讀取已認領項目)
end考慮將佇列移出資料庫:Redis、RabbitMQ、Gearman 都是好選擇。
計算地理距離#
使用大圓公式(Haversine)計算距離非常耗 CPU。優化策略:
- 降低精度需求:平面近似取代球面三角
- 用正方形取代圓形:
BETWEEN條件過濾 - 輔助整數欄位 + IN() list:先粗篩(
lat_floor IN(36,37,38,39,40)),再用精確公式後過濾 - 三角函數放在應用層計算,不要讓 MySQL 執行
總結#
優化三原則:
- 停止不必要的工作(Stop doing things)
- 減少執行次數(Do them fewer times)
- 加速執行(Do them more quickly)
查詢優化是 schema、索引和查詢設計拼圖中的最後一塊。最終仍關乎回應時間——理解查詢如何執行,才能推理出時間消耗在哪裡。查詢、表和索引之間的交互作用是:MySQL 如何根據從一個表/索引中找到的資料來存取另一個表/索引。