概述#
索引(在 MySQL 中也稱為 “keys”)是儲存引擎用來快速尋找資料列的資料結構。隨著資料量成長,索引的重要性急遽上升——小型資料庫可能不需要索引也能運作良好,但資料集一旦變大,效能可能迅速惡化。
核心觀念: 索引優化可能是提升查詢效能最有力的方式。最佳索引可以比「還不錯」的索引再提升約兩個數量級的效能。建立最佳索引通常需要同時改寫查詢,因此索引策略與查詢優化密不可分。
索引帶來的三大好處:
- 減少伺服器需要檢查的資料量
- 幫助伺服器避免排序和臨時表
- 將隨機 I/O 轉換為循序 I/O
Lahdenmaki 和 Leach 提出的三星評等系統:
- 第一顆星:索引將相關的列放在相鄰位置
- 第二顆星:索引中的列順序與查詢所需排序一致
- 第三顆星:索引包含查詢所需的所有欄位(Covering Index)
索引基礎#
B-Tree 索引#
B-Tree 索引(多數引擎實際使用 B+Tree)是 MySQL 最常見的索引類型。其核心特性:
- 所有值以排序方式儲存,每個 leaf page 與 root 的距離相等
- 儲存引擎從 root node 開始,透過 node page 中的指標導航到 leaf page
- Leaf page 包含指向實際資料的指標(不同儲存引擎的「指標」實作不同)
flowchart TD
A["查詢請求"] --> B["Root Node"]
B -->|"比較鍵值"| C["Internal Node Page"]
C -->|"沿指標導航"| D["Leaf Page"]
D -->|"指標指向"| E["實際資料列"]- MyISAM:使用前綴壓縮(prefix compression)讓索引更小,以實體儲存位置指向資料列
- InnoDB:值不壓縮,以 primary key 值指向資料列
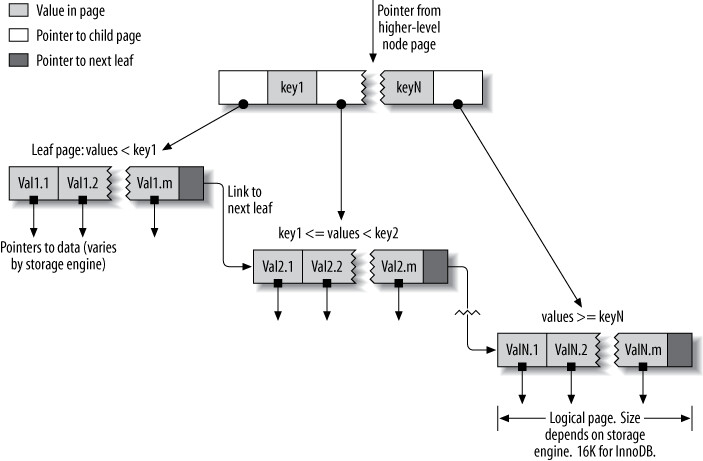
Figure 5.1: An index built on a B-Tree (technically, a B+Tree) structure
以下面的表為例:
CREATE TABLE People (
last_name varchar(50) not null,
first_name varchar(50) not null,
dob date not null,
gender enum('m', 'f') not null,
key(last_name, first_name, dob)
);這個複合索引按照 last_name → first_name → dob 的順序排列資料。
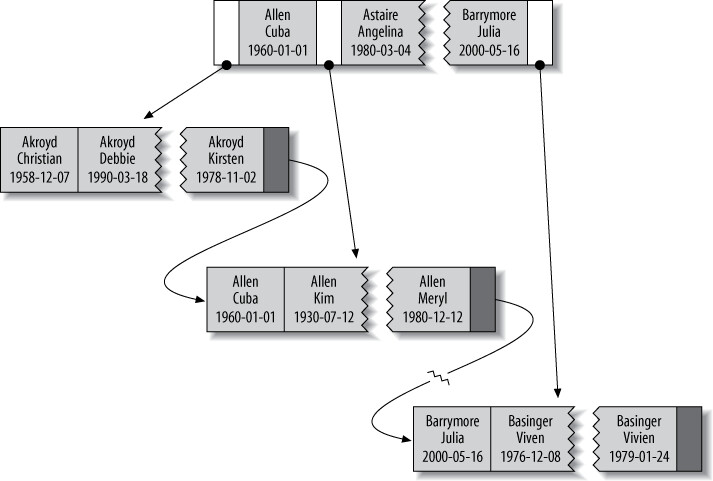
Figure 5.2: Sample entries from a B-Tree (technically, a B+Tree) index
B-Tree 索引可滿足的查詢類型#
| 查詢類型 | 說明 |
|---|---|
| 完全匹配(Match the full value) | 指定索引所有欄位的值,例如找 Cuba Allen, 1960-01-01 |
| 最左前綴匹配(Match a leftmost prefix) | 僅用第一個欄位,例如 WHERE last_name = 'Allen' |
| 欄位前綴匹配(Match a column prefix) | 匹配第一個欄位值的開頭,例如 WHERE last_name LIKE 'J%' |
| 範圍匹配(Match a range of values) | 例如 WHERE last_name BETWEEN 'Allen' AND 'Barrymore' |
| 精確匹配一部分 + 範圍匹配另一部分 | 例如 WHERE last_name = 'Allen' AND first_name LIKE 'K%' |
| Index-only 查詢(Covering Index) | 僅存取索引即可滿足查詢 |
由於樹的節點是排序的,B-Tree 索引同時適用於 查找 和 ORDER BY 操作。
B-Tree 索引的限制#
- 必須從最左欄位開始:無法用此索引找
WHERE first_name = 'Bill'或WHERE dob = '...' - 不能跳過欄位:無法用
WHERE last_name = 'Smith' AND dob = '...'跳過first_name - 第一個範圍條件之後的欄位無法使用索引:
WHERE last_name = 'Smith' AND first_name LIKE 'J%' AND dob = '...'只能用到前兩個欄位
欄位順序至關重要。 上述所有限制都與欄位排列順序相關。為了最佳效能,可能需要對相同欄位建立不同順序的索引來滿足不同查詢。
Hash 索引#
Hash 索引建立在 hash table 之上,只適用於精確查找(使用索引中的所有欄位)。MySQL 中只有 Memory 引擎 支援明確的 hash 索引。
Hash 索引的限制:
| 限制 | 說明 |
|---|---|
| 無法用於排序 | 不按順序存放資料 |
| 不支援部分鍵匹配 | 索引 (A, B),只用 WHERE A = ? 無效 |
| 僅支援等值比較 | =, IN(), <=>,不支援範圍查詢 |
| Hash 碰撞多時效能下降 | 碰撞越多,逐一比較的成本越高 |
InnoDB 的 Adaptive Hash Index:InnoDB 會自動偵測頻繁存取的索引值,在 B-Tree 索引之上建立記憶體中的 hash 索引,無需手動控制。
自建 Hash 索引#
適用於 URL 等長字串欄位的場景:在 B-Tree 索引上使用 hash 值做查找。
-- 建立 CRC32 欄位
SELECT id FROM url
WHERE url = "http://www.mysql.com"
AND url_crc = CRC32("http://www.mysql.com");處理碰撞: WHERE 子句中必須同時包含 hash 值和原始值,否則碰撞時會回傳錯誤的列。CRC32 是 32 位元整數,約 93,000 筆資料就有 1% 的碰撞機率(Birthday Paradox)。不要用 SHA1/MD5——它們回傳長字串,浪費空間且比較慢。可用 trigger 自動維護 hash 欄位。
其他索引類型#
| 索引類型 | 用途 |
|---|---|
| Spatial (R-Tree) 索引 | MyISAM 支援,用於 GIS 空間資料,不需要最左前綴 |
| Full-text 索引 | 用於關鍵字搜尋(MATCH AGAINST),與 WHERE 子句無關 |
| Fractal Tree 索引 | TokuDB 使用,兼具 B-Tree 優點且避免部分缺點 |
高效能索引策略#
隔離欄位(Isolating the Column)#
MySQL 通常無法對參與表達式或函式的欄位使用索引。
-- 無法使用索引(欄位在表達式中)
SELECT actor_id FROM sakila.actor WHERE actor_id + 1 = 5;
-- 正確寫法:隔離欄位
SELECT actor_id FROM sakila.actor WHERE actor_id = 4;
-- 錯誤:欄位在函式中
SELECT ... WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(date_col) <= 10;前綴索引與索引選擇性(Prefix Indexes and Index Selectivity)#
當需要索引很長的字元欄位時,可以只索引前幾個字元。索引選擇性(Index Selectivity)= 不同索引值的數量 / 總列數,範圍從 1/#T 到 1。
決定前綴長度的方法:
-- 1. 先看完整欄位的選擇性
SELECT COUNT(DISTINCT city)/COUNT(*) FROM sakila.city_demo;
-- 結果:0.0312
-- 2. 比較不同前綴長度的選擇性
SELECT COUNT(DISTINCT LEFT(city, 3))/COUNT(*) AS sel3,
COUNT(DISTINCT LEFT(city, 4))/COUNT(*) AS sel4,
COUNT(DISTINCT LEFT(city, 5))/COUNT(*) AS sel5,
COUNT(DISTINCT LEFT(city, 6))/COUNT(*) AS sel6,
COUNT(DISTINCT LEFT(city, 7))/COUNT(*) AS sel7
FROM sakila.city_demo;
-- 結果:0.0239 | 0.0293 | 0.0305 | 0.0309 | 0.0310
-- 3. 建立前綴索引
ALTER TABLE sakila.city_demo ADD KEY (city(7));注意最壞情況的選擇性。 平均選擇性可能看起來不錯,但以 “San” 開頭的城市名非常多,四個字元的前綴索引對這些值的選擇性很差。務必檢查最常出現的前綴分佈。
前綴索引的限制:無法用於 ORDER BY 或 GROUP BY,也無法作為 covering index。
多欄索引(Multicolumn Indexes)#
常見錯誤:對每個欄位各建一個獨立索引,而非建立一個多欄複合索引。
-- 常見錯誤:分別建立單欄索引
CREATE TABLE t (
c1 INT, c2 INT, c3 INT,
KEY(c1), KEY(c2), KEY(c3)
);Index Merge(MySQL 5.0+):允許查詢同時使用多個單欄索引,但通常表示索引設計不佳:
- 交集(intersection, AND):應改為建立包含所有相關欄位的單一索引
- 聯集(union, OR):可能消耗大量 CPU 和記憶體
- 看到 index merge 時,應重新檢視查詢與表結構
欄位順序的選擇(Choosing a Good Column Order)#
多欄 B-Tree 索引的排序規則:先按最左欄位排序,再按下一個欄位排序,依此類推。
經驗法則: 將選擇性最高的欄位放在最前面。但這通常不如避免隨機 I/O 和排序來得重要。實際上排序、分組、以及範圍條件的位置往往影響更大。
以實際查詢為例:
SELECT * FROM payment WHERE staff_id = 2 AND customer_id = 584;
-- 檢查各欄位的選擇性
SELECT COUNT(DISTINCT staff_id)/COUNT(*) AS staff_id_selectivity,
COUNT(DISTINCT customer_id)/COUNT(*) AS customer_id_selectivity
FROM payment;
-- staff_id: 0.0001, customer_id: 0.0373
-- → customer_id 選擇性更高,應放在索引前面
ALTER TABLE payment ADD KEY(customer_id, staff_id);注意離群值(Outliers)。 「未登入」的 guest 帳號、系統管理帳號等特殊值可能造成極端的效能問題。規則和啟發式方法很有用,但不能假設平均情況能代表特殊情況。
Clustered Index(叢集索引)#
Clustered index 不是一種獨立的索引類型,而是一種資料儲存方式。InnoDB 的 clustered index 將 B-Tree 索引和資料列儲存在同一個結構中。
- 一張表只能有一個 clustered index(因為資料不能同時存在兩個地方)
- InnoDB 用 primary key 做為 clustered index
- 若沒有定義 primary key,InnoDB 會嘗試用 unique not-null index;若都沒有,則建立隱藏的 primary key
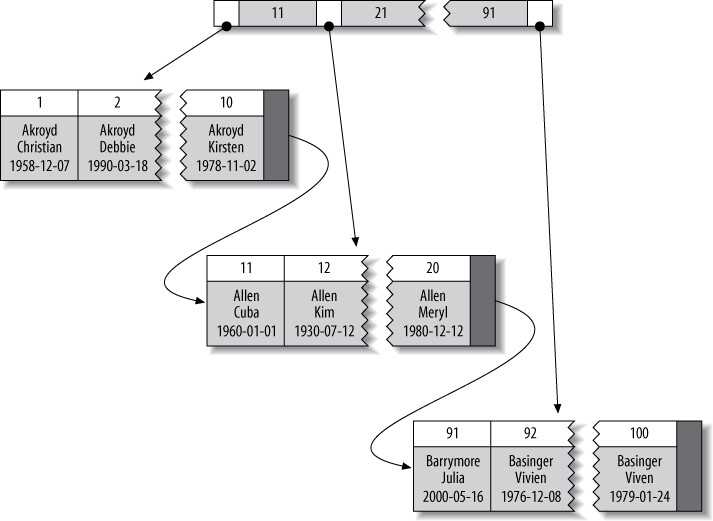
Figure 5.3: Clustered index data layout
Clustered Index 的優缺點:
| 類別 | 項目 |
|---|---|
| 優點 | 相關資料存放在一起(例如同一用戶的所有郵件),減少磁碟 I/O |
| 優點 | 資料存取快速:索引和資料在同一個 B-Tree 中 |
| 優點 | Covering index 查詢可以直接使用 leaf node 中的 primary key 值 |
| 缺點 | 若資料能全部放入記憶體,clustering 的好處不大 |
| 缺點 | 插入速度高度依賴插入順序(按 primary key 順序插入最快) |
| 缺點 | 更新 clustered index 欄位代價昂貴(需移動整列資料) |
| 缺點 | 插入新列或更新 primary key 時可能發生 page split(頁面分裂),增加磁碟空間使用 |
| 缺點 | Full table scan 可能較慢(因 page split 導致資料不密集或不連續) |
| 缺點 | Secondary index 較大:leaf node 儲存的是 primary key 值而非實體位置指標 |
| 缺點 | Secondary index 查找需要兩次索引查找:先在 secondary index 找到 primary key,再到 clustered index 找資料列 |
flowchart LR
A["查詢請求"] --> B["Secondary Index"]
B -->|"找到 Primary Key 值"| C["Clustered Index"]
C -->|"用 PK 查找"| D["實際資料列"]
style B fill:#f9f,stroke:#333
style C fill:#bbf,stroke:#333InnoDB vs MyISAM 資料佈局比較#
以下面的表為例:
CREATE TABLE layout_test (
col1 int NOT NULL,
col2 int NOT NULL,
PRIMARY KEY(col1),
KEY(col2)
);MyISAM vs InnoDB 資料佈局比較:
| 特性 | MyISAM | InnoDB |
|---|---|---|
| 資料儲存方式 | 資料列按插入順序儲存在磁碟上 | Clustered index「就是」table 本身——沒有分開的資料列儲存區 |
| Leaf node 內容 | 存放的是列號(row number) | 包含 primary key 值、transaction ID、rollback pointer、其餘欄位 |
| Primary key vs Secondary index | 在結構上沒有差異 | Secondary index 的 leaf node 存放的是primary key 值(而非 row pointer),列移動時不需更新指標 |
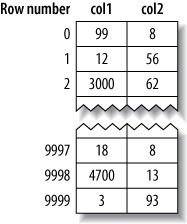
Figure 5.4: MyISAM data layout for the layout_test table
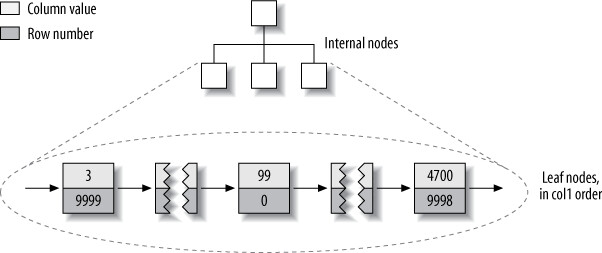
Figure 5.5: MyISAM primary key layout for the layout_test table
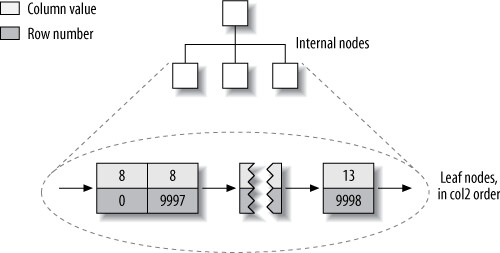
Figure 5.6: MyISAM col2 index layout for the layout_test table
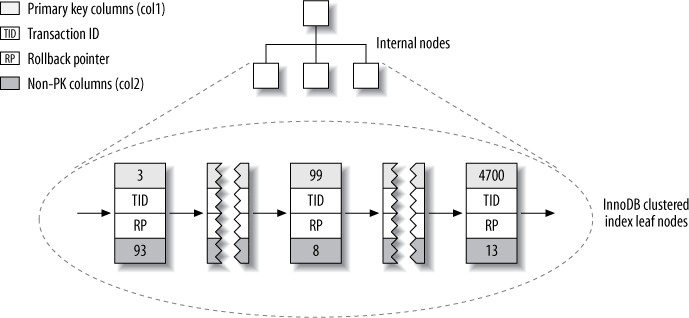
Figure 5.7: InnoDB primary key layout for the layout_test table
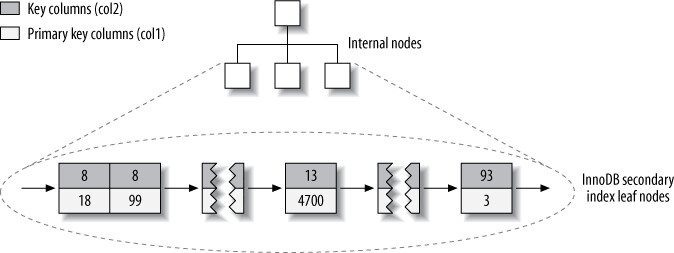
Figure 5.8: InnoDB secondary index layout for the layout_test table
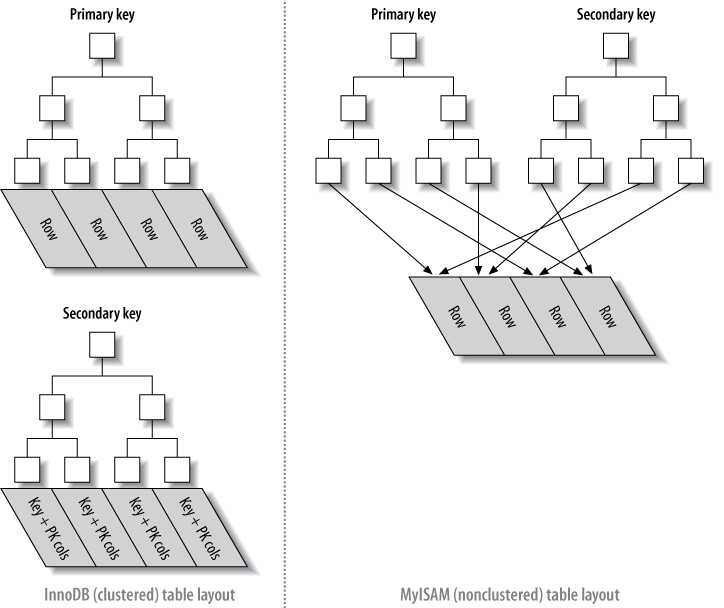
Figure 5.9: Clustered and nonclustered tables side-by-side
按 Primary Key 順序插入(InnoDB)#
建議使用 surrogate key(如 AUTO_INCREMENT)作為 InnoDB 的 primary key,確保列按順序插入。
應避免使用 UUID 作為 primary key——這會讓 clustered index 的插入變成隨機寫入,是最糟糕的情境。
| 表格 | 列數 | 時間 (sec) | 索引大小 (MB) |
|---|---|---|---|
| userinfo (INT auto_increment) | 1,000,000 | 137 | 342 |
| userinfo_uuid (UUID) | 1,000,000 | 180 | 544 |
| userinfo (INT auto_increment) | 3,000,000 | 1233 | 1036 |
| userinfo_uuid (UUID) | 3,000,000 | 4525 | 1707 |
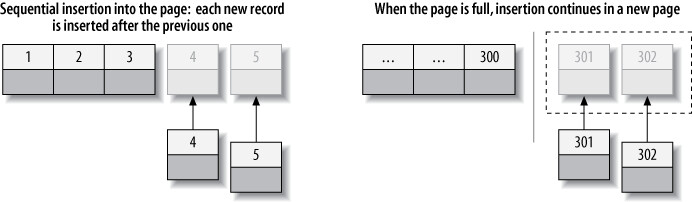
Figure 5.10: Inserting sequential index values into a clustered index
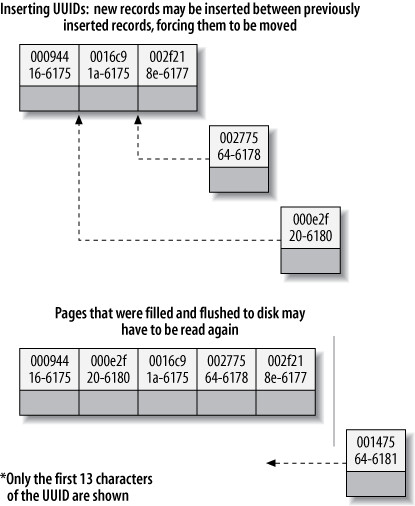
Figure 5.11: Inserting nonsequential values into a clustered index
UUID 造成效能問題的原因:
- 目標 page 可能已被 flush 到磁碟或不在 cache 中,導致大量隨機 I/O
- 頻繁的 page split:需要移動大量資料,至少修改三個 page
- Page 因分裂變得稀疏且不規則填充,最終資料碎片化
flowchart TD
A["UUID 作為 Primary Key"] --> B["隨機插入位置"]
B --> C["目標 Page 不在 Buffer Pool"]
C --> D["大量隨機 I/O"]
D --> E["頻繁 Page Split"]
E --> F["移動大量資料、修改多個 Page"]
F --> G["Page 變得稀疏"]
G --> H["資料碎片化"]高併發例外: 在高併發工作負載下,按 primary key 順序插入反而可能造成 hot spot 競爭(所有插入都集中在索引末端)。可透過
innodb_autoinc_lock_mode設定來緩解 AUTO_INCREMENT 鎖定機制的問題。
Covering Index(涵蓋索引)#
Covering index 是指包含查詢所需所有欄位的索引,讓 MySQL 不需要回表讀取資料列。
-- 索引 (store_id, film_id) 可以覆蓋此查詢
EXPLAIN SELECT store_id, film_id FROM sakila.inventory\G
-- Extra: Using index ← 表示使用了 covering index「Using index」vs「index」: EXPLAIN 輸出中 Extra 欄的
Using index表示使用了 covering index;type 欄的index則表示存取方式,兩者意義完全不同。
Covering index 的優勢:
- 索引通常比完整的 row 小很多,存取的資料量顯著減少
- 索引按值排序,範圍存取的 I/O 更少
- InnoDB 的 secondary index leaf node 包含 primary key 值,因此可以「免費」覆蓋 primary key 欄位
Deferred Join 技巧: 當無法直接使用 covering index 時,可以用子查詢先透過 covering index 取得 primary key,再 JOIN 回原表取完整資料。
-- 原始查詢(無法用 covering index)
SELECT * FROM products WHERE actor='SEAN CARREY'
AND title LIKE '%APOLLO%';
-- 優化:deferred join
SELECT * FROM products
JOIN (
SELECT prod_id FROM products
WHERE actor='SEAN CARREY' AND title LIKE '%APOLLO%'
) AS t1 ON (t1.prod_id = products.prod_id);Index Condition Pushdown (ICP)#
MySQL 5.5 及更早版本的 storage engine API 限制:只允許索引中的簡單比較(等值、不等、大於),無法在索引層級執行 LIKE 等操作。MySQL 5.6 引入了 Index Condition Pushdown (ICP),允許將過濾條件下推到儲存引擎層,減少回表次數,大幅改善這類查詢的效能。
使用索引做排序(Using Index Scans for Sorts)#
MySQL 產生排序結果的兩種方式:sort 操作 或 按索引順序掃描。
使用索引排序的條件:
- ORDER BY 子句的欄位順序必須與索引完全一致,且排序方向一致
- 多表 JOIN 時,ORDER BY 的欄位必須全部來自第一張表
- 需要形成索引的最左前綴(但 WHERE 子句中的等值條件可以「填補」前綴的間隔)
-- 索引:(rental_date, inventory_id, customer_id)
-- 可以用索引排序:WHERE 等值 + ORDER BY 後續欄位
... WHERE rental_date = '2005-05-25'
ORDER BY inventory_id, customer_id;
-- 可以用索引排序:ORDER BY 形成前綴
... WHERE rental_date > '2005-05-25'
ORDER BY rental_date, inventory_id;
-- 無法用索引排序:混合排序方向
... WHERE rental_date = '2005-05-25'
ORDER BY inventory_id DESC, customer_id ASC;
-- 無法用索引排序:跳過欄位
... WHERE rental_date = '2005-05-25'
ORDER BY customer_id;
-- 無法用索引排序:第一個欄位是範圍條件
... WHERE rental_date > '2005-05-25'
ORDER BY inventory_id, customer_id;
-- 無法用索引排序:IN() 等同於範圍
... WHERE rental_date = '2005-05-25'
AND inventory_id IN(1,2)
ORDER BY customer_id;壓縮(Packed / Prefix-Compressed)索引#
MyISAM 使用前綴壓縮來減小索引大小。例如第一個值 “perform”,第二個值 “performance” 會被存成 “7,ance”。
- 優點:索引可以縮小到約 1/10 的大小
- 缺點:無法做二元搜尋,必須從區塊開頭依序掃描;反向掃描(
ORDER BY DESC)更慢 - 適合 I/O 密集型工作負載,不適合 CPU 密集型
可用 CREATE TABLE 的 PACK_KEYS 選項控制。
冗餘與重複索引#
重複索引(Duplicate Indexes)#
相同類型、相同欄位、相同順序的索引就是重複索引。MySQL 不會阻止你建立重複索引。
-- 建立了三個重複索引!
CREATE TABLE test (
ID INT NOT NULL PRIMARY KEY,
A INT NOT NULL,
B INT NOT NULL,
UNIQUE(ID),
INDEX(ID)
) ENGINE=InnoDB;冗餘索引(Redundant Indexes)#
索引 (A, B) 已包含索引 (A) 的功能——(A) 是 (A, B) 的最左前綴。但 (B, A) 或 (B) 不是冗餘的。
擴展而非新增: 通常應擴展現有索引(如從
(A)擴展為(A, B)),而非新增索引。但要注意擴展索引可能影響 ORDER BY(例如(A)擴展為(A, B)後,WHERE A=5 ORDER BY ID查詢可能開始用 filesort)。InnoDB 的 secondary index 實際包含 primary key,因此(A)實際等同於(A, ID)。
工具建議:使用 pt-duplicate-key-checker(Percona Toolkit)找出重複和冗餘索引。
未使用的索引#
未使用的索引是純粹的負擔,應考慮刪除。偵測工具:
- Percona Server / MariaDB:
INFORMATION_SCHEMA.INDEX_STATISTICS(需啟用userstats) - pt-index-usage(Percona Toolkit):分析查詢日誌,報告索引使用情況
某些索引雖然查詢不使用,但作為 UNIQUE 約束 防止重複值,刪除前要確認。
索引與鎖(Indexes and Locking)#
索引讓查詢鎖定更少的列,降低鎖定開銷和競爭,提高併發性。
- InnoDB 只在存取資料列時才鎖定,索引可以減少需要存取的列數
- 如果索引無法在儲存引擎層過濾不需要的列,MySQL server 必須在取回資料後再用 WHERE 過濾——但此時列已經被鎖定
- MySQL 5.1+ 可以在 server 過濾後解鎖不需要的列
-- actor_id < 5 AND actor_id <> 1
-- 實際上鎖定了 row 1~4(因為 range scan 從索引開頭掃到 actor_id < 5 為止)
SELECT actor_id FROM sakila.actor
WHERE actor_id < 5 AND actor_id <> 1 FOR UPDATE;InnoDB 鎖定細節: Secondary index 可以使用 shared (read) lock,但 exclusive (write) lock 需要存取 primary key。這使得
SELECT FOR UPDATE無法使用 covering index,可能比LOCK IN SHARE MODE慢很多。如果沒有索引可用,MySQL 會做 full table scan 並鎖定所有列。
索引案例研究:線上交友網站#
設計思路#
假設需要支援依 country、state、city、sex、age、eye color 等組合搜尋使用者。
第一個決策: 是否需要基於索引的排序?如果查詢在 WHERE 子句中使用了範圍條件,就無法同時用同一個索引做排序。
支援多種篩選#
策略:以 (sex, country, ...) 為前綴建立一系列索引。
IN() 技巧: 即使查詢不篩選 sex,可以加上 AND sex IN('m', 'f') 來讓 MySQL 使用更長的索引前綴。同理,不指定 country 時可以加入所有國家的 IN() 清單。
-- 建議的索引
(sex, country, age)
(sex, country, region, age)
(sex, country, region, city, age)age 放在索引最後面。 因為 age 幾乎一定是範圍條件(
BETWEEN 18 AND 25),而範圍條件會使 MySQL 忽略索引中後續的欄位。將範圍條件放在索引最後,才能讓最多的欄位被用到。
避免多重範圍條件#
WHERE eye_color IN('brown','blue','hazel')
AND hair_color IN('black','red','blonde','brown')
AND sex IN('M','F')
AND last_online > DATE_SUB(NOW(), INTERVAL 7 DAY)
AND age BETWEEN 18 AND 25MySQL 無法同時對 last_online 和 age 兩個範圍條件使用索引。解法:增加預先計算的 active 欄位(定期 job 維護),將範圍條件轉化為等值比較。
IN() 組合爆炸注意:
4 * 3 * 2 = 24種組合尚可接受,但若接近數千種組合,查詢優化的成本可能超過執行成本。較新的 MySQL 版本會在組合數過大時停止評估。
排序優化#
-- 索引 (sex, rating) 可用於此查詢
SELECT <cols> FROM profiles WHERE sex='M' ORDER BY rating LIMIT 10;
-- 高 offset 的分頁查詢非常慢
SELECT <cols> FROM profiles WHERE sex='M' ORDER BY rating LIMIT 100000, 10;高 offset 分頁的解法:
- 限制使用者可瀏覽的頁數
- 使用 deferred join:先透過 covering index 取得 primary key,再 JOIN 回原表
SELECT <cols> FROM profiles INNER JOIN (
SELECT <primary key cols> FROM profiles
WHERE x.sex='M' ORDER BY rating LIMIT 100000, 10
) AS x USING(<primary key cols>);索引與表的維護#
找出並修復損壞#
- 使用
CHECK TABLE檢查表是否損壞 - 使用
REPAIR TABLE修復(不是所有引擎都支援) - InnoDB 替代方案:
ALTER TABLE innodb_tbl ENGINE=INNODB(no-op ALTER)
InnoDB 不應該損壞。 如果 InnoDB 資料損壞,通常是硬體問題(記憶體、磁碟)或管理員錯誤(如用 rsync 做備份)。絕對不是因為你執行了某個查詢——如果是的話,那是 InnoDB 的 bug。
更新索引統計資訊#
MySQL 的 cost-based optimizer 依賴索引統計資訊做決策。過時的統計資訊可能導致糟糕的查詢計畫。
- 使用
ANALYZE TABLE重新產生統計資訊 - MyISAM:做完整索引掃描,過程中鎖定整張表
- InnoDB:透過隨機取樣頁面來估算(
innodb_stats_sample_pages控制取樣數) - InnoDB 在表開啟、
ANALYZE TABLE、或表大小顯著變化時重新計算統計資訊
停用自動更新統計: Percona Server 的
innodb_stats_auto_update選項可凍結統計資訊,避免不穩定的查詢計畫。MySQL 5.6+ 支援innodb_analyze_is_persistent將統計資訊持久化到系統表中。
減少碎片化#
三種資料碎片化類型:
| 碎片化類型 | 說明 |
|---|---|
| Row fragmentation | 單一列儲存在多個位置 |
| Intra-row fragmentation | 邏輯上連續的頁面或列在磁碟上不連續 |
| Free space fragmentation | 資料頁面中有大量空間浪費 |
處理方式:OPTIMIZE TABLE 或 dump and reload。InnoDB 較新版本支援 online drop/recreate 索引來做碎片整理。
總結#
三大核心原則:
- 避免單列存取(Single-row access is slow):利用索引建立 locality of reference
- 按順序存取範圍最快(Accessing ranges in order is fast):循序 I/O 不需 disk seek,且不需額外排序
- Index-only 存取最快(Index-only access is fast):covering index 避免回表查找
設計索引時,不要依賴經驗法則(如「將選擇性最高的欄位放前面」或「索引所有 WHERE 子句欄位」),而是根據查詢的實際存取模式來推理最佳索引方案。找出回應時間過長或負載過高的查詢,檢查是否掃描過多資料列、是否需要回表排序、是否產生臨時表、是否存在隨機 I/O,然後對症下藥。