為何需要 Benchmark?#
Benchmark 是一組刻意設計的工作負載,用來對系統施加壓力。它是理解 MySQL 行為最方便且有效的手段。透過 benchmark,你可以:
| 用途 | 說明 |
|---|---|
| 驗證假設 | 確認你對系統的認知是否符合現實 |
| 重現問題 | 再現你想消除的異常行為 |
| 量化現況 | 不知道目前跑多快,就無法判斷改動是否有效 |
| 模擬成長 | 以高於生產環境的負載找出第一個瓶頸 |
| 規劃容量 | 估算未來所需的硬體與網路資源 |
| 驗證硬體 | 新伺服器上線前,用 benchmark 燒機檢查配置與元件是否正常 |
| 測試環境變化的容忍度 | 例如突發的 concurrency 高峰、不同的伺服器配置、不同的資料分布 |
Benchmark 不是真實世界。它的工作負載通常遠比生產環境簡單,且會以最大速率施壓,這會讓系統表現出平時不會出現的行為。做容量規劃時也不應線性外推——資料量、使用者、功能、資料間的關聯都會非線性成長。
Benchmark 策略#
兩種主要策略:
Full-Stack Benchmarking(整體應用測試)#
測試整個應用堆疊,包含 web server、應用程式碼、網路和資料庫。
- 能揭示 MySQL 是否真的是瓶頸
- 反映各層快取的真實互動
- 最接近真實應用行為
Single-Component Benchmarking(單一元件測試)#
只針對 MySQL 單獨施壓。適用於:
- 比較不同 schema 或 query
- 針對特定問題進行隔離測試
- 需要更短的迭代週期
若能取得生產環境資料的快照來測試,結果會更有意義。資料本身和資料集大小都需要真實。
要測量什麼?#
Throughput(吞吐量)#
單位時間內完成的交易數量,通常以 transactions per second (TPS) 或 transactions per minute 表示。這是 OLTP 系統最經典的指標。
Response Time / Latency(回應時間)#
完成一個任務所需的總時間。
- 不要看 maximum——跑越久 max 就越大,且每次結果差異極大
- 用 percentile 取代:例如 95th percentile = 5ms,代表 95% 的請求在 5ms 內完成
- 搭配圖表呈現結果(折線圖或散佈圖)
Concurrency(並行度)#
Concurrency 常被誤解。網站的「同時在線人數」不等於資料庫的並行度。一個有 50,000 使用者的網站,MySQL 同時在執行的查詢可能只有 10-15 個。真正該測量的是 working concurrency——同一時間真正在做事的 thread 數量。可透過
Threads_running狀態變數觀察。
Scalability(可擴展性)#
理想系統在資源加倍時,吞吐量也應加倍。現實中大多數系統都會呈現遞減效益(diminishing returns)。
- 可擴展性測試能揭示只用單一連線做 response time 測試看不到的設計缺陷
- 對容量規劃特別有價值
Benchmark 方法論#
常見陷阱#
以下是常見的 benchmark 錯誤,任何一項都可能讓結果毫無意義:
- 用過小的資料集(1GB 測百 GB 級應用)
- 用均勻分布的假資料(真實資料有 hot spots)
- 用單一使用者測多使用者應用
- 在迴圈中跑完全相同的 query(真實 query 不同,會造成 cache miss)
- 忘記檢查錯誤日誌(你可能只在測 MySQL 回報 syntax error 的速度)
- 忽略冷啟動效應(cache 未暖時的表現截然不同)
- 使用預設伺服器設定
- Benchmark 時間太短
設計與規劃#
- 確認問題與目標:先用問題框架你的 benchmark,例如「這顆 CPU 比那顆快嗎?」
- 選擇或設計 benchmark:標準 benchmark 要選對類型(例如不要用 TPC-H 測 OLTP)
- 準備真實資料:取得生產資料快照,確保每次執行前都能還原
- 記錄查詢:從生產環境的 query log 擷取代表性時段的查詢,用多執行緒重放(不是線性跑)
- 寫下計畫:benchmark 計畫要能被重現——包含測試資料、系統設定、量測方式、warmup 計畫
Benchmark 要跑多久?#
如果你關心的是穩態效能(steady-state performance),就必須等系統真正進入穩態,這可能需要相當長的時間。
- 許多系統有 buffer 機制能吸收短期尖峰,但長時間壓力下會飽和
- 經驗法則:等到系統看起來穩定的時間,至少要等於初始 warmup 所花的時間
- 60 秒的短 benchmark 幾乎不能說明任何事
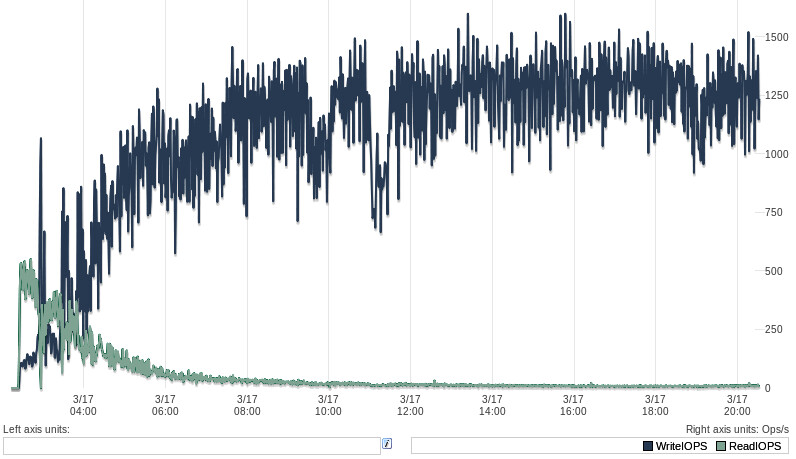
Figure 2.1: I/O performance during an extended benchmark
上圖顯示一個長時間 benchmark 的 I/O 活動。讀取在 3-4 小時後穩定,但寫入持續波動超過 8 小時。最終此 benchmark 跑了 72 小時才確認系統展現典型的長期行為。如果只跑 60 秒,完全無法看到這些模式。
擷取系統效能與狀態#
Benchmark 執行時應盡可能收集完整的系統資訊:
- CPU 使用率、磁碟 I/O、網路流量
SHOW GLOBAL STATUS計數器SHOW ENGINE INNODB STATUSSHOW FULL PROCESSLIST
#!/bin/sh
INTERVAL=5
PREFIX=$INTERVAL-sec-status
RUNFILE=/home/benchmarks/running
mysql -e 'SHOW GLOBAL VARIABLES' >> mysql-variables
while test -e $RUNFILE; do
file=$(date +%F_%I)
sleep=$(date +%s.%N | awk "{print $INTERVAL - (\$1 % $INTERVAL)}")
sleep $sleep
ts="$(date +"TS %s.%N %F %T")"
loadavg="$(uptime)"
echo "$ts $loadavg" >> $PREFIX-${file}-status
mysql -e 'SHOW GLOBAL STATUS' >> $PREFIX-${file}-status &
echo "$ts $loadavg" >> $PREFIX-${file}-innodbstatus
mysql -e 'SHOW ENGINE INNODB STATUS\G' >> $PREFIX-${file}-innodbstatus &
echo "$ts $loadavg" >> $PREFIX-${file}-processlist
mysql -e 'SHOW FULL PROCESSLIST\G' >> $PREFIX-${file}-processlist &
echo $ts
done此腳本的精妙之處:迴圈對齊到 clock tick(每 5 秒整除),方便跨系統資料對照;以日期和小時命名檔案,長時間 benchmark 時可逐檔管理;收集原始資料不做預處理,事後再分析。
取得準確結果#
- 每次執行前確保系統狀態一致——重要的 benchmark 應在每輪之間重開機
- 若需在暖機狀態測試,warmup 必須夠長且可重現
- 若 benchmark 會修改資料,每輪前用新快照重置
- 注意外部負載:cron job、RAID 卡的 Patrol Read、共享 SAN
- 每次只改一個參數,逐步迭代而非大幅跳躍
跨平台遷移的 benchmark(如 Oracle 到 MySQL)通常有問題。MySQL 擅長的 query 類型與 Oracle 截然不同,你通常需要為 MySQL 重新設計 schema 和 query。用預設 MySQL 設定跑 benchmark 再跟其他 RDBMS 比較,結果毫無意義。
執行 Benchmark 與分析結果#
- 自動化:用 Makefile 或腳本自動化整個流程(載入資料、warmup、執行、記錄),避免遺漏步驟或手動誤差
- 多次執行:常見做法是跑五次、取三次最佳值的平均
- 結果要能回答你的問題:理想的結論形式如「升級到 4 顆 CPU 在相同 response time 下提升 50% throughput」
分析腳本範例——將 SHOW GLOBAL STATUS 輸出轉換為時間序列格式:
#!/bin/sh
awk '
BEGIN {
printf "#ts date time load QPS";
fmt = " %.2f";
}
/^TS/ {
ts = substr($2, 1, index($2, ".") - 1);
load = NF - 2;
diff = ts - prev_ts;
prev_ts = ts;
printf "\n%s %s %s %s", ts, $3, $4, substr($load, 1, length($load)-1);
}
/Queries/ {
printf fmt, ($2-Queries)/diff;
Queries=$2
}
' "$@"繪圖的重要性#
平均值是無用的,因為它隱藏了真實發生的事情。你應該把效能指標畫成時間序列圖來觀察。圖表上一秒就能看到的問題,在原始數據中可能難以發現。
用 gnuplot 繪製 QPS 時間序列:
gnuplot> plot "QPS-per-5-seconds" using 5 w lines title "QPS"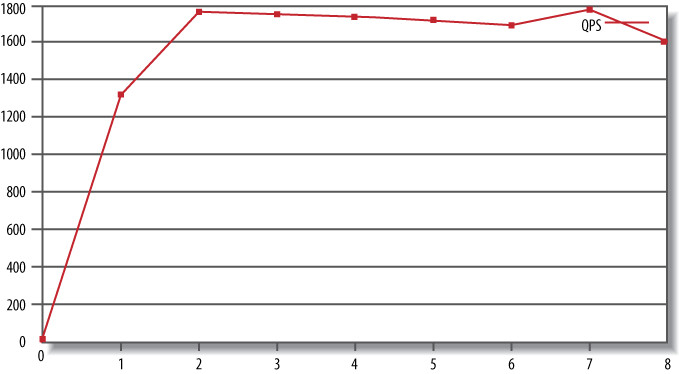
Figure 2.2: Plotting the benchmark's QPS
例如,系統可能因為 furious flushing(checkpoint 落後導致阻塞所有活動直到趕上進度)而出現吞吐量驟降。95th percentile 和平均 response time 都不會顯示這些驟降,但圖表上會看到明顯的週期性凹陷。
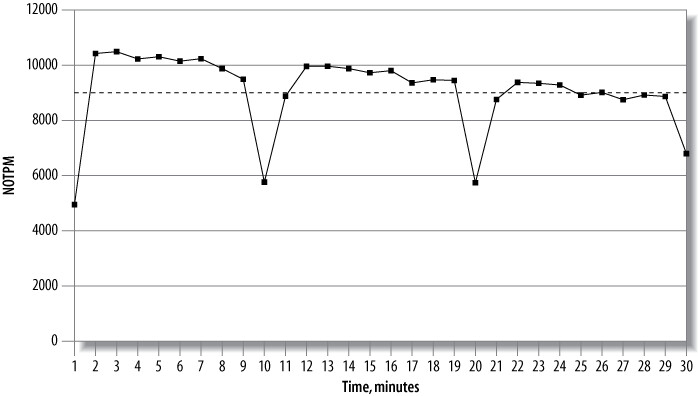
Figure 2.3: Results from a 30-minute dbt2 benchmark run
上圖的 dbt2 結果中,NOTPM(new-order transactions per minute)曲線出現顯著下降:第一次因為 cache 尚冷,後續因為伺服器在密集 flush dirty pages。整體平均線(虛線)完全掩蓋了這些異常。看到尖峰行為時,要回去檢查
SHOW ENGINE INNODB STATUS和SHOW FULL PROCESSLIST的詳細資料。
Benchmark 工具#
Full-Stack 工具#
| 工具 | 特性 |
|---|---|
| ab | Apache HTTP benchmarking tool。簡單地對單一 URL 全速發送請求,適合快速測試 |
| http_load | 比 ab 更彈性,可從檔案讀取多個 URL 隨機選取,支援定速模式 |
| JMeter | Java 應用,功能最完整。支援 ramp-up time、圖形化介面、錄製/重播、JDBC 查詢 |
Single-Component 工具#
| 工具 | 特性 |
|---|---|
| mysqlslap | MySQL 5.1 內建,模擬並行連線,可自動從 schema 產生 SELECT |
| MySQL Benchmark Suite (sql-bench) | MySQL 自帶的 Perl 測試套件,單執行緒,適合快速比較不同 storage engine 或設定 |
| Super Smack | 支援 MySQL/PostgreSQL,可用 smack 檔案定義 client、table、query |
| Database Test Suite (dbt2) | TPC-C OLTP 的免費實作(非官方認證) |
| Percona’s TPCC-MySQL | 書籍作者打造的 TPC-C-like 工具,專為大規模 MySQL benchmark 設計 |
| sysbench | 最推薦的全方位工具。多執行緒,支援 Lua 腳本,可測 CPU/fileio/memory/threads/mutex/OLTP |
sysbench 詳解#
sysbench 是作者最常用的 benchmark 工具,涵蓋多種測試模式:
CPU benchmark——計算質數,比較不同 CPU 的運算速度:
sysbench --test=cpu --cpu-max-prime=20000 runFile I/O benchmark——模擬類似 InnoDB 的磁碟存取模式(比 iozone、bonnie++ 更貼近 MySQL 使用情境):
# 準備測試檔案(必須遠大於記憶體以避免 OS cache)
sysbench --test=fileio --file-total-size=150G prepare
# 執行隨機讀寫測試
sysbench --test=fileio --file-total-size=150G --file-test-mode=rndrw \
--init-rng=on --max-time=300 --max-requests=0 run
# 清理
sysbench --test=fileio --file-total-size=150G cleanup支援的 I/O 模式:seqwr、seqrewr、seqrd、rndrd、rndwr、rndrw
OLTP benchmark——模擬簡單交易處理,是最常用的資料庫測試:
# 準備百萬列測試表
sysbench --test=oltp --oltp-table-size=1000000 --mysql-db=test \
--mysql-user=root prepare
# 8 執行緒唯讀模式跑 60 秒
sysbench --test=oltp --oltp-table-size=1000000 --mysql-db=test \
--mysql-user=root --max-time=60 --oltp-read-only=on \
--max-requests=0 --num-threads=8 runsysbench v5(從 Launchpad 原始碼編譯)支援多表測試,並可每隔固定間隔(如 10 秒)輸出 throughput 和 response time,對理解系統行為非常關鍵。
其他子測試:memory(循序記憶體讀寫)、threads(thread scheduler 效能)、mutex(mutex 效能)、seqwr(循序寫入——可檢驗 RAID 控制器 cache 是否正常工作)。
dbt2 TPC-C#
dbt2 是 TPC-C 的免費實作,報告 NOTPM(new-order transactions per minute) 和 Price/tpmC。
# 1. 產生 10 個 warehouse 的資料(約 700MB)
src/datagen -w 10 -d /mnt/data/dbt2-w10
# 2. 載入 MySQL
scripts/mysql/mysql_load_db.sh -d dbt2w10 -f /mnt/data/dbt2-w10/ \
-s /var/lib/mysql/mysql.sock
# 3. 執行(10 連線、10 warehouse、300 秒)
run_mysql.sh -c 10 -w 10 -t 300 -n dbt2w10 \
-u root -o /var/lib/mysql/mysql.sock -e關鍵參數:-c(連線數,測並行擴展)、-e(zero-delay 模式,全速壓測)、-t(持續時間——I/O bound 不宜太短,CPU bound 不宜太長)。
Percona’s TPCC-MySQL#
作者為解決 dbt2 的不足而開發,適合大規模 benchmark:
# 載入 5 個 warehouse 的資料
./tpcc_load localhost tpcc5 username p4ssword 5
# 5 threads、5 warehouses、warmup 30s、benchmark 30s
./tpcc_start localhost tpcc5 username p4ssword 5 5 30 30最終結果為 TpmC(transactions per minute)。若看到異常的 rollback 或 constraint check 失敗,需進一步調查。
MySQL 的 BENCHMARK() 函式#
SET @input := 'hello world';
SELECT BENCHMARK(1000000, MD5(@input)); -- 2.78 sec
SELECT BENCHMARK(1000000, SHA1(@input)); -- 3.50 sec
BENCHMARK()只測量伺服器執行表達式的速度,不包含 parsing 和 optimization 開銷。且若不使用 user variable,第二次以後可能是 cache hit。不適合用於正式 benchmark。
重點回顧#
- Benchmark 是學習 MySQL 行為最有效的方式,但必須正確設計與執行
- 至少要熟悉 sysbench 的
oltp和fileio測試 - 磁碟 benchmark 能揭露硬體問題——單顆轉盤硬碟只能做幾百 IOPS,若結果顯示 14,000 random reads/sec,代表測試有誤或配置有問題
- 自動化一切:benchmark 執行、資料收集、結果分析
- 畫圖,畫圖,再畫圖——用 gnuplot 或 R,不要用試算表。你的眼睛比任何腳本都更擅長發現異常
- 如果沒時間把 benchmark 做對,花的時間就是浪費;不如信任別人的結果