概述#
MySQL 最獨特且重要的特性是其 儲存引擎架構(Storage Engine Architecture),將查詢處理(query processing)與資料儲存/檢索分離。這種關注點分離讓使用者可以根據需求選擇資料的儲存方式、效能特性與功能組合。
要充分發揮 MySQL 的效能,必須理解其設計並順勢而為(work with it, not against it)。
MySQL 的邏輯架構#
MySQL 的架構可分為三層:
| 層級 | 名稱 | 職責 |
|---|---|---|
| 第一層 | 連線/服務層 | 連線管理、認證、安全性等,這些是大多數網路型 client/server 工具共有的服務 |
| 第二層 | 核心服務層 | 查詢解析(parsing)、分析、優化(optimization)、快取(caching),以及所有跨儲存引擎的內建功能(日期、數學、加密等)、預存程序(stored procedures)、觸發器(triggers)、視圖(views) |
| 第三層 | 儲存引擎層 | 負責資料的實際儲存與檢索,透過 Storage Engine API 與伺服器溝通 |
flowchart TD
Client["客戶端"] --> L1["第一層:連線/服務層"]
L1 -->|"連線管理、認證、安全性"| L2["第二層:核心服務層"]
L2 -->|"查詢解析、優化、快取"| API["Storage Engine API"]
API --> InnoDB["InnoDB"]
API --> MyISAM["MyISAM"]
API --> Memory["Memory"]
API --> Other["其他引擎..."]
subgraph "第三層:儲存引擎層"
InnoDB
MyISAM
Memory
Other
end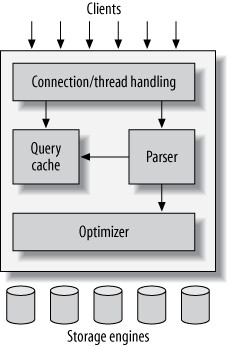
Figure 1.1: A logical view of the MySQL server architecture
儲存引擎不會解析 SQL,也不互相溝通,僅回應伺服器的請求。唯一的例外是 InnoDB 會自行解析外鍵定義,因為 MySQL 伺服器本身尚未實作外鍵。
連線管理與安全#
- 每個 client 連線在伺服器中取得自己的 執行緒(thread),查詢在該執行緒中執行
- 伺服器會 快取執行緒,避免每次連線都建立/銷毀
- MySQL 5.5+ 支援 thread-pooling plugin,讓少量執行緒池服務大量連線
- 認證基於 使用者名稱、來源主機、密碼,也支援 X.509 憑證的 SSL 連線
- 連線後,伺服器會逐一驗證每個查詢的 權限(privileges)
優化與執行#
- MySQL 將查詢解析為 parse tree,再套用各種優化:改寫查詢、決定讀取表的順序、選擇索引等
- 可以透過 optimizer hints 影響優化器決策
- 優化器會向儲存引擎詢問其能力、操作成本和統計資訊
- 查詢執行前會先檢查 Query Cache,若命中則直接回傳結果集,無需解析、優化或執行
flowchart TD
A["接收 SQL 查詢"] --> B{"Query Cache 命中?"}
B -->|命中| C["直接回傳快取結果"]
B -->|未命中| D["解析為 Parse Tree"]
D --> E["預處理器檢查語意"]
E --> F["查詢優化器"]
F -->|"改寫查詢、選擇索引、決定 JOIN 順序"| G["執行引擎"]
G -->|"Storage Engine API"| H["儲存引擎執行"]
H --> I["回傳結果集"]並行控制(Concurrency Control)#
MySQL 在 伺服器層 和 儲存引擎層 兩個層級處理並行控制。
讀寫鎖(Read/Write Locks)#
| 鎖類型 | 英文名稱 | 行為 |
|---|---|---|
| 共享鎖 | Shared Lock / Read Lock | 多個 client 可同時讀取,互不阻塞 |
| 排他鎖 | Exclusive Lock / Write Lock | 獨占資源,阻塞其他讀鎖和寫鎖 |
鎖粒度(Lock Granularity)#
鎖定策略是 鎖開銷 與 資料安全 之間的權衡。鎖越細(fine-grained),並行度越高,但管理開銷也越大。
表鎖(Table Locks)
- 最基本的鎖策略,開銷最低
- 寫入時取得寫鎖,阻塞所有其他讀寫操作
READ LOCAL表鎖允許部分並行寫入- 寫鎖優先於讀鎖(寫鎖可插隊到讀鎖前面,反之不行)
- 無論使用哪種儲存引擎,
ALTER TABLE等 DDL 語句都使用伺服器層級的表鎖
行鎖(Row Locks)
- 提供最高並行度,但開銷也最大
- 由 InnoDB / XtraDB 等儲存引擎自行實作,伺服器對此完全不知情
MySQL 的儲存引擎可以實作各自的鎖策略和鎖粒度,這是其架構彈性的核心優勢。選擇適合的儲存引擎就是在選擇鎖策略。
事務(Transactions)#
事務是一組 SQL 查詢的 原子操作單元(atomic unit of work) — 要嘛全部套用,要嘛全部不套用。
START TRANSACTION;
SELECT balance FROM checking WHERE customer_id = 10233276;
UPDATE checking SET balance = balance - 200.00 WHERE customer_id = 10233276;
UPDATE savings SET balance = balance + 200.00 WHERE customer_id = 10233276;
COMMIT;ACID 特性#
| 特性 | 說明 |
|---|---|
| Atomicity(原子性) | 事務不可分割,全部成功或全部回滾 |
| Consistency(一致性) | 資料庫永遠從一個一致狀態轉移到另一個一致狀態 |
| Isolation(隔離性) | 事務的中間結果對其他事務不可見(直到完成) |
| Durability(持久性) | 一旦提交,變更就是永久的,即使系統崩潰也不會遺失 |
ACID 事務需要更多 CPU、記憶體和磁碟空間。若應用不需要事務,可以選用非交易型儲存引擎獲得更高效能,或使用
LOCK TABLES提供基本保護。
隔離等級(Isolation Levels)#
SQL 標準定義四種隔離等級,越低的等級允許越高的並行度和越低的開銷:
| 隔離等級 | Dirty Read | Non-repeatable Read | Phantom Read | Locking Read |
|---|---|---|---|---|
| READ UNCOMMITTED | Yes | Yes | Yes | No |
| READ COMMITTED | No | Yes | Yes | No |
| REPEATABLE READ | No | No | Yes | No |
| SERIALIZABLE | No | No | No | Yes |
- READ UNCOMMITTED — 可讀取未提交的資料(dirty read),實務上很少使用
- READ COMMITTED — 大多數資料庫系統的預設值(但 不是 MySQL 的預設值);同一事務中兩次相同查詢可能看到不同資料(non-repeatable read)
- REPEATABLE READ — MySQL/InnoDB 的預設值;同一事務中重複讀取同一行結果相同。InnoDB 透過 MVCC 解決 phantom read 問題
- SERIALIZABLE — 最高隔離等級,強制事務循序執行,每列讀取都加鎖
MySQL 預設的隔離等級是 REPEATABLE READ,與大多數其他資料庫(使用 READ COMMITTED)不同。這是使用 MySQL 時需要特別注意的差異。
死鎖(Deadlocks)#
- 兩個以上的事務互相持有並請求對方的鎖,形成 循環依賴
- InnoDB 會偵測循環依賴並 立即回滾 持有最少排他行鎖的事務
- 死鎖是交易系統的常態,應用程式 應設計重試機制
-- Transaction #1
START TRANSACTION;
UPDATE StockPrice SET close = 45.50 WHERE stock_id = 4 AND date = '2002-05-01';
UPDATE StockPrice SET close = 19.80 WHERE stock_id = 3 AND date = '2002-05-02';
COMMIT;
-- Transaction #2
START TRANSACTION;
UPDATE StockPrice SET high = 20.12 WHERE stock_id = 3 AND date = '2002-05-02';
UPDATE StockPrice SET high = 47.20 WHERE stock_id = 4 AND date = '2002-05-01';
COMMIT;
-- 兩個事務以不同順序鎖定同樣的資源 → 死鎖sequenceDiagram
participant T1 as Transaction 1
participant DB as InnoDB
participant T2 as Transaction 2
T1->>DB: UPDATE ... WHERE stock_id = 4(取得鎖)
T2->>DB: UPDATE ... WHERE stock_id = 3(取得鎖)
T1->>DB: UPDATE ... WHERE stock_id = 3(等待 T2 釋放)
T2->>DB: UPDATE ... WHERE stock_id = 4(等待 T1 釋放)
Note over T1,T2: 循環依賴形成 → 死鎖偵測
DB-->>T2: 回滾較小的事務
DB-->>T1: 取得鎖,繼續執行事務日誌(Transaction Logging)#
- 儲存引擎先修改 記憶體中的資料副本(很快),再將變更記錄寫入 事務日誌(循序 I/O,也很快)
- 稍後再由背景程序將變更寫入磁碟上的資料檔案
- 這種技術稱為 Write-Ahead Logging (WAL),變更實際上會被寫入磁碟兩次
- 若崩潰發生在日誌寫入後、資料檔案更新前,儲存引擎可在重啟時從日誌恢復
flowchart TD
A["修改記憶體中的資料副本"] --> B["寫入事務日誌(循序 I/O)"]
B --> C["回傳提交成功"]
C --> D["背景程序寫入磁碟資料檔"]
B -.->|"崩潰發生"| E["重啟後從事務日誌恢復"]
E --> DMySQL 中的事務#
AUTOCOMMIT
- MySQL 預設啟用
AUTOCOMMIT,每個查詢自動包裝在獨立事務中 - 設定
AUTOCOMMIT = 0時,你始終處於事務中,直到COMMIT或ROLLBACK - DDL 語句(如
ALTER TABLE)和LOCK TABLES會強制提交當前事務
-- 查看及設定 AUTOCOMMIT
SHOW VARIABLES LIKE 'AUTOCOMMIT';
SET AUTOCOMMIT = 1;
-- 設定隔離等級
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;不要在同一事務中混用不同儲存引擎的表。 若混用 InnoDB 和 MyISAM,回滾時 MyISAM 表的變更無法撤銷,導致資料庫處於不一致狀態。MySQL 通常 不會 對此發出警告。
隱式與顯式鎖定
- InnoDB 使用 兩階段鎖定協議(two-phase locking):事務期間隨時可取得鎖,但僅在
COMMIT/ROLLBACK時一次釋放所有鎖 - InnoDB 額外支援顯式鎖定(SQL 標準未定義):
SELECT ... LOCK IN SHARE MODESELECT ... FOR UPDATE
LOCK TABLES/UNLOCK TABLES在伺服器層實作,不是儲存引擎的替代品
從 MyISAM 轉換到 InnoDB 後,不要繼續使用
LOCK TABLES。InnoDB 的行鎖已取代其功能,而LOCK TABLES會造成嚴重的效能問題。若必須使用,確保在事務中且已停用AUTOCOMMIT。
多版本並行控制(MVCC)#
MVCC(Multiversion Concurrency Control) 是行鎖的進階變體,在許多情況下完全避免加鎖,開銷更低。Oracle、PostgreSQL 等資料庫也使用 MVCC,但各自實作不同。
InnoDB 的 MVCC 實作#
InnoDB 為每列儲存兩個隱藏值:
- 建立版本號 — 列被建立時的系統版本號
- 刪除版本號 — 列被刪除時的系統版本號
系統版本號在每次事務開始時遞增,每個事務記錄開始時的版本號。
在 REPEATABLE READ 隔離等級下:
| 操作 | MVCC 行為 |
|---|---|
| SELECT | 只回傳建立版本 <= 事務版本,且刪除版本未定義或 > 事務版本的列 |
| INSERT | 以當前系統版本號記錄新列的建立版本 |
| DELETE | 以當前系統版本號記錄該列的刪除版本 |
| UPDATE | 寫入新副本(新建立版本),並將舊列標記刪除版本 |
sequenceDiagram
participant TA as "事務 A(版本 5)"
participant Data as 資料列
participant TB as "事務 B(版本 10)"
TA->>Data: INSERT(建立版本 = 5)
Note over Data: 列存在,建立版本 = 5
TB->>Data: SELECT(版本 10 > 5,可見)
TB->>Data: DELETE(刪除版本 = 10)
Note over Data: 建立版本 = 5,刪除版本 = 10
TA->>Data: SELECT(刪除版本 10 > 5,仍可見)
Note over TA,TB: 事務 A 看不到事務 B 的刪除MVCC 的最大好處是 大多數讀取操作不需要取得鎖,直接讀取符合版本條件的資料即可。代價是儲存引擎需要儲存更多資料並做更多檢查。
- MVCC 僅適用於 REPEATABLE READ 和 READ COMMITTED
- READ UNCOMMITTED 不相容(直接讀最新版本)
- SERIALIZABLE 不相容(讀取時會鎖定每列)
儲存引擎#
MySQL 將每個資料庫存為檔案系統中的子目錄,每張表的定義存在 .frm 檔案中。各儲存引擎以不同方式儲存資料與索引。
InnoDB#
InnoDB 是 MySQL 的 預設交易型儲存引擎(自 5.5 起),也是最重要、最通用的引擎。
核心特性:
- 設計用於 短期事務(通常完成而非回滾),也適用於非交易型需求
- 支援 MVCC 與全部四種 SQL 標準隔離等級,預設 REPEATABLE READ
- 使用 next-key locking 防止 phantom reads(鎖定索引間隙)
- 基於 聚簇索引(clustered index),主鍵查詢非常快
- 次要索引(secondary index)包含主鍵欄位 — 若主鍵很大,所有索引都會變大
- 內部優化:predictive read-ahead、adaptive hash index、insert buffer
- 支援真正的 熱備份(hot online backup)(如 Percona XtraBackup)
- 自動崩潰恢復(crash recovery)
如果你使用 MySQL 5.1,請確保使用 InnoDB plugin 而非舊版 InnoDB。新版在效能和可擴展性方面有巨大改善。
InnoDB 的歷史演進:
- 2008 年:Oracle 發布 InnoDB plugin for MySQL 5.1(新一代 InnoDB)
- MySQL 5.5:InnoDB plugin 成為預設、編譯內建
- 效能擴展性從第二版書中的 4 核心上限,提升到 24 核心甚至 32+ 核心
- Google、Percona、Facebook 等皆有重大貢獻
MyISAM#
MyISAM 是 MySQL 5.1 及更早版本的 預設儲存引擎。
特性:
- 支援 全文索引(full-text indexing)、壓縮、空間(GIS)函式
- 不支援事務,不支援行鎖
- 使用 表鎖(readers 取得共享鎖,writers 取得排他鎖),支援有限的並行插入
- 每張表存為兩個檔案:
.MYD(資料)和.MYI(索引) - 支援手動和自動的表 檢查與修復(
CHECK TABLE/REPAIR TABLE/myisamchk) - 壓縮表(Compressed MyISAM):用
myisampack壓縮,唯讀但佔用空間更小 DELAY_KEY_WRITE選項延遲索引寫入以提升效能,但崩潰後索引必定損壞
MyISAM 不是 crash-safe 的。它只是把資料寫入記憶體,假設作業系統稍後會刷到磁碟。不要因為「MyISAM 比 InnoDB 快」的迷思而使用它作為預設引擎 — 這並非在所有場景下都成立。請使用 InnoDB。
其他內建引擎#
| 引擎 | 用途與特性 |
|---|---|
| Archive | 僅支援 INSERT/SELECT,zlib 壓縮,適合日誌和資料擷取 |
| Blackhole | 不儲存任何資料,但寫入會記錄到日誌,用於特殊複製架構 |
| CSV | 將 CSV 檔案視為表,不支援索引,適合資料交換 |
| Federated | 代理到其他 MySQL 伺服器,問題多,預設停用 |
| Memory | 資料全部存在記憶體中,重啟後遺失,支援 HASH 索引,適合暫存/快取。使用表鎖,不支援 TEXT/BLOB,VARCHAR 實際以 CHAR 儲存 |
| Merge | 多個相同 MyISAM 表的虛擬合併,已被 partitioning 取代 |
| NDB Cluster | 分散式、shared-nothing、高可用的叢集儲存引擎 |
MySQL 內部在處理查詢時會使用 Memory 引擎 作為暫存表。若中間結果過大或包含 TEXT/BLOB 欄位,會轉換為磁碟上的 MyISAM 表。注意不要混淆 Memory 表與
CREATE TEMPORARY TABLE建立的臨時表 — 後者可使用任何儲存引擎。
第三方儲存引擎#
| 引擎 | 特性與適用場景 |
|---|---|
| XtraDB(Percona) | InnoDB 的改進版,可直接替換,專注效能與可觀測性 |
| PBXT | 支援引擎級複製和外鍵,針對 SSD 和大型值優化 |
| TokuDB | 使用 Fractal Tree 索引,高壓縮率,適合大數據和高插入率的分析型場景 |
| Infobright | 列式儲存(column-oriented),適合數十 TB 級資料倉儲,使用區塊壓縮與後設資料跳過 |
| InfiniDB | 列式儲存,支援跨叢集分散查詢 |
選擇正確的儲存引擎#
預設使用 InnoDB,除非你需要它不提供的特定功能,且沒有好的替代方案。不要無故混用不同儲存引擎 — 這會讓備份、設定和除錯變得更複雜。
選擇引擎時需考慮的因素:
| 考量因素 | 建議 |
|---|---|
| 事務 | 需要事務就用 InnoDB/XtraDB |
| 備份 | 需要線上熱備份就用 InnoDB |
| 崩潰恢復 | MyISAM 表更容易損壞且恢復時間更長 |
| 特殊功能 | 如聚簇索引優化(InnoDB)、地理空間搜尋(MyISAM)、全文搜尋(可用 InnoDB + Sphinx 替代) |
應用場景對照#
| 場景 | 建議引擎 | 原因 |
|---|---|---|
| 日誌記錄 | MyISAM / Archive | 低開銷、高插入速度 |
| 唯讀/讀多寫少 | InnoDB | MyISAM 崩潰風險太高 |
| 訂單處理 | InnoDB | 事務是必須的 |
| 討論區/論壇 | InnoDB | 高並行讀寫,MyISAM 的表鎖會成為瓶頸 |
| CD-ROM 發行 | 壓縮 MyISAM | 唯讀、體積小 |
| 大型資料(3-5+ TB) | InnoDB | 崩潰恢復可靠 |
| 超大資料倉儲(數十 TB) | Infobright / TokuDB | 列式儲存、高壓縮率 |
在測試環境中對真實負載進行模擬,然後直接拔掉電源線。親身體驗崩潰恢復的過程是無價的,能避免日後的意外。
表格轉換方式#
將表格從一種引擎轉換到另一種的三種方法:
1. ALTER TABLE
ALTER TABLE mytable ENGINE = InnoDB;- 最簡單但最慢,逐列複製,原始表讀鎖定
- 轉換過程中會遺失引擎特定功能(如 InnoDB 的外鍵)
2. Dump and Import
- 用
mysqldump匯出後編輯CREATE TABLE語句 - 需注意修改表名和引擎類型,避免覆蓋原始資料
3. CREATE and SELECT
CREATE TABLE innodb_table LIKE myisam_table;
ALTER TABLE innodb_table ENGINE = InnoDB;
INSERT INTO innodb_table SELECT * FROM myisam_table;- 大資料量時建議分批插入,避免 undo log 過大:
START TRANSACTION;
INSERT INTO innodb_table SELECT * FROM myisam_table
WHERE id BETWEEN x AND y;
COMMIT;- 工具推薦:Percona Toolkit 的
pt-online-schema-change
MySQL 版本時間線#
| 版本 | 年份 | 重要里程碑 |
|---|---|---|
| 3.23 | 2001 | MySQL 正式進入主流;引入 MyISAM、全文索引、複製 |
| 4.0 | 2003 | UNION、多表 DELETE;InnoDB 成為標準組件;Query Cache |
| 4.1 | 2005 | 子查詢、INSERT ON DUPLICATE KEY UPDATE、UTF-8、prepared statements |
| 5.0 | 2006 | 視圖、觸發器、預存程序、預存函式;ISAM 移除 |
| 5.1 | 2008 | 分區(partitioning)、row-based replication、pluggable storage engine API;InnoDB plugin 發布 |
| 5.5 | 2010 | Oracle 接手後首版;InnoDB 成為預設引擎;PERFORMANCE_SCHEMA;半同步複製;重大效能改善 |
| 5.6 | 開發中 | 查詢優化器大幅改善;更多 plugin API;複製改善;InnoDB 大量新功能 |
timeline
title MySQL 版本演進
2001 : MySQL 3.23 — MyISAM、全文索引、複製
2003 : MySQL 4.0 — 查詢快取、UNION、SSL
2004 : MySQL 4.1 — 子查詢、UTF-8、二進位協定
2005 : MySQL 5.0 — 預存程序、視圖、觸發器、遊標
2008 : MySQL 5.1 — 分區、事件排程器、行複製
2010 : MySQL 5.5 — InnoDB 成為預設引擎、半同步複製
開發中 : MySQL 5.6 — GTID、線上 DDL、全文索引改進效能基準測試#
書中使用 SysBench 唯讀工作負載對多個 MySQL 版本進行基準測試(InnoDB,資料完全在記憶體中,CPU-bound):
| 執行緒數 | MySQL 4.1 | MySQL 5.0 | MySQL 5.1 | 5.1 + InnoDB plugin | MySQL 5.5 | MySQL 5.6 |
|---|---|---|---|---|---|---|
| 1 | 686 | 640 | 596 | 594 | 531 | 526 |
| 8 | 3,879 | 3,746 | 3,606 | 3,681 | 3,523 | 3,320 |
| 16 | 4,374 | 4,527 | 4,393 | 6,131 | 5,881 | 5,573 |
| 32 | 4,591 | 4,864 | 4,698 | 7,762 | 7,549 | 7,139 |
| 64 | 4,688 | 5,078 | 4,910 | 7,536 | 7,269 | 6,994 |
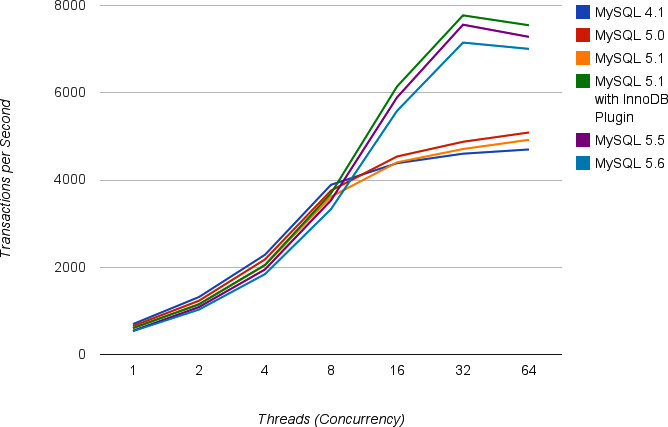
Figure 1.2: Readonly benchmarks of several MySQL versions
兩個關鍵趨勢:
- 包含 InnoDB plugin 的版本在高並行時效能顯著更好(可擴展性更佳)
- 新版本在單執行緒簡單查詢上反而較慢 — 因為 SQL 語法更複雜、功能更多,對簡單查詢而言是額外開銷
在更複雜的讀寫工作負載、更高並行度和更大資料集下,新版本普遍有更好且更穩定的效能表現。
重點摘要#
- MySQL 的 分層架構 將伺服器服務、查詢執行與儲存引擎分離
- Storage Engine API 是最重要的 plugin API — 理解 MySQL 透過此 API 來回傳遞列資料,就掌握了核心架構
- MySQL 圍繞 ISAM/MyISAM 建構,事務和多儲存引擎是後來加入的 — 許多伺服器特性反映了這個歷史遺留
- InnoDB 適用於約 95% 的使用場景 — 除非有明確理由,否則不要選擇其他引擎
- Oracle 同時擁有 InnoDB 和 MySQL 後,兩者的整合開發使效能和品質大幅提升