Amy Gallo 與 Thomas Redman(《Data Driven》作者、資料品質顧問)對談整理。
什麼是迴歸分析?#
想像你是業務經理,想預測下個月銷售:
- 天氣、競爭對手促銷、即將推出的新版本傳聞……可能影響的因素有幾十、上百個
- 公司裡也常流傳各種理論:「下越多雨我們賣越多」「對手促銷後 6 週銷量會跳起來」
**迴歸分析(regression analysis)**就是用數學方式辨識:
- 哪些因素最重要?
- 哪些可以忽略?
- 它們之間如何交互?
- 最關鍵的——我們對這些結論有多確定?
變數的角色#
- 應變數(dependent variable):你想理解或預測的主要因素,例如月銷售
- 自變數(independent variable):你懷疑會影響應變數的因素
迴歸怎麼跑?#
步驟 1:蒐集資料、畫散布圖#
把過去 3 年的月銷售數字與當月降雨量畫到圖上:
- y 軸(應變數一律放 y 軸):銷售量
- x 軸:降雨量
- 每個點代表某月的「降雨量 + 銷售量」
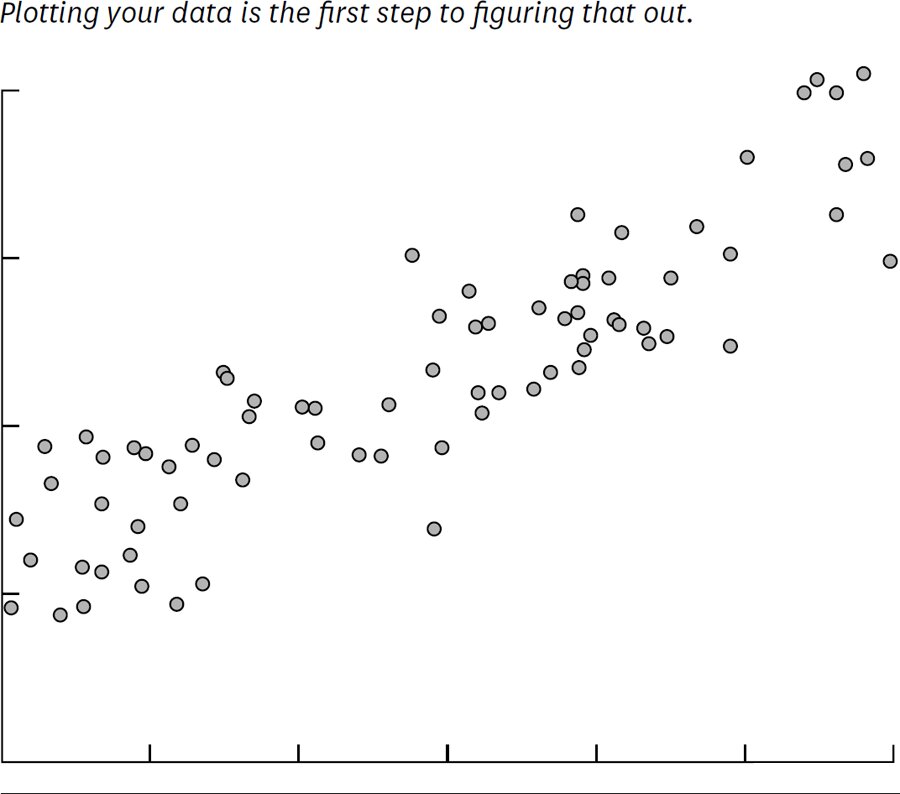
Figure 10-1: Is there a relationship between these two variables?
從圖上你可能看到「雨大時銷售較高」,但到底大多少?下 3 吋雨會賣多少?4 吋呢?
步驟 2:畫一條最佳契合的迴歸線#
由統計軟體(SPSS、STATA,甚至 Excel)畫出穿過資料點中心的線——迴歸線(regression line),它是「自變數與應變數關係的最佳解釋」。
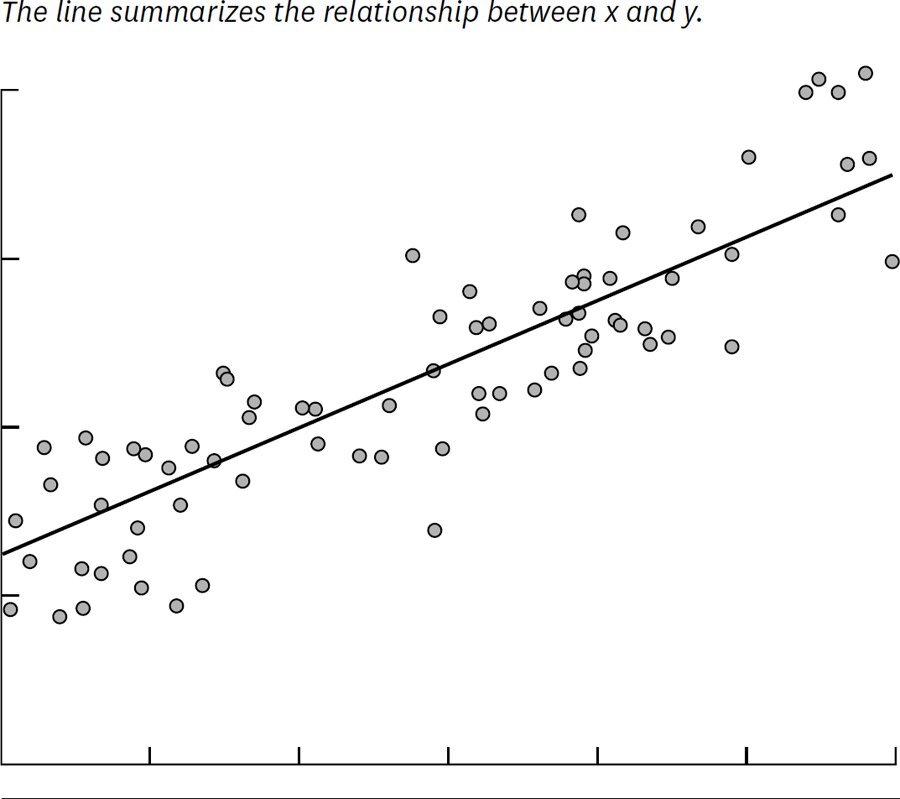
Figure 10-2: Building a regression model
軟體還會輸出公式:
y = 200 + 5x + error term先忽略誤差項,看核心模型 y = 200 + 5x:
- 沒下雨(x = 0)時,平均賣 200
- 雨每多 1 吋,銷售平均多 5
誤差項(error term):你有多確定?#
真實世界裡自變數從不會完美預測應變數,迴歸線只是估計。誤差項告訴你這條公式的可信度——誤差越大,可信度越低。
只用一個變數 → 誤差項通常很大。所以實務上:
- 同時放入多個自變數(雨量、競爭對手促銷……)
- 持續迭代,直到誤差項變得很小
同時考慮多個變數,是迴歸分析最強大的能力之一。但變數放太多也有風險,需有經驗的分析師控制。
公司怎麼用迴歸?#
Redman 形容迴歸是「分析的首選方法」。多數公司用它來:
- 解釋現象:為什麼上個月客服電話下降?
- 預測未來:未來 6 個月銷售會怎樣?
- 決定行動:該選 A 促銷還是 B 促銷?
相關 ≠ 因果(critical reminder)#
看到迴歸結果有相關,不要直接認定有因果。
雨量和銷售有相關,可以;但「雨導致銷售上升」是另一回事——除非你賣的是雨傘,否則很難證明因果。
怎麼追究因果?#
- 不要靠資料下結論,要走出辦公室觀察
- 看顧客怎麼在雨天買你的產品,跟他們聊
- 找出是什麼物理機制造成這個關係
Redman 警告:「很多人省略這一步,因為懶。但分析的目標不是搞清楚資料裡發生什麼,而是搞清楚世界裡發生什麼——你必須走出去、實地走訪。」
Redman 的個人例子#
他注意到自己出差時吃得多、運動少,體重就上升。但出差不是體重增加的原因——可能是因為到陌生環境會緊張,於是吃得多。資料只是引導下一步實驗的工具,不是用來下因果結論的終點。
經理人最常犯的錯#
錯誤 1:請分析師「自己看看是什麼影響了銷售」#
大多數分析翻車,是因為經理人沒先收斂焦點。
- 經理人的職責是指出懷疑的因素請分析師檢驗
- 對分析師說「去做釣魚遠征(fishing expedition)、找出我不知道的事」,很容易得到根本不存在的關係
- 同樣道理:丟硬幣丟夠多次,總會看到連續正面的「有趣模式」
錯誤 2:忽略「自己能否影響該變數」#
天氣、對手促銷你都改變不了。先問自己:拿到這個結果,我會做什麼決定、採取什麼行動?
錯誤 3:忽視資料品質#
「分析對壞資料極為敏感。」
- 資料不必完美,要看後續決策影響多大
- 影響不大時,有點漏的資料也能用
- 如果是「要蓋 8 個還是 10 個、每個成本 100 萬美元」這種決定,資料品質就是大事
錯誤 4:忽略誤差項#
迴歸的本質是量化「這件事會發生的可能性」,不是給你一個確定答案。
- 如果迴歸解釋 90% 變異 → 很好
- 如果只解釋 10%、卻當 90% 用 → 災難
錯誤 5:讓資料取代直覺#
永遠把直覺疊在資料之上。
- 結果合理嗎?
- 不合理時,是資料錯,還是誤差項其實很大?
- 找更資深的經理或其他分析交叉驗證
「最好的科學家與經理人,會同時看資料與真實世界。」
警惕「虛假相關(spurious correlations)」#
「相關不等於因果」我們都知道,但看到圖表共動、線條一起上升,腦袋還是忍不住要找原因。
Tyler Vigen(Harvard 法學院學生、《Spurious Correlations》作者)的網站專門展示荒謬的相關,例如「美國人均人造奶油消費量 vs. 緬因州離婚率」「iPhone 越多,從樓梯摔死的人越多」「為球隊歡呼可以減肥」。
日常工作裡你不會看到這麼荒誕的圖,但會碰到「設計過、看似可信」的圖表,三種類型要警惕:
- 蘋果比橘子(Apples and Oranges):兩條 y 軸量的是不同的東西,曲線看似一致但其實毫無關聯——最好分開畫。
- 歪斜的軸(Skewed Scales):兩條 y 軸量同類,但用不同範圍與比例,硬把線拉到一起——拿掉第二條 y 軸就能看出歪斜。
- 如果 / 那麼(Ifs and Thens):把毫不相關的兩個資料集放在同張圖裡,創造「Pandora 虧損變少 → 更多音樂取得版權」這類純屬巧合的敘事。