你剛拿到一份「可能改寫局勢」的資料,但能用嗎?#
當有人遞給你一份新資料、聲稱結合既有資料就能帶來顛覆性洞察時——但沒人能明確告訴你它能不能信任,你該怎麼辦?
真正深思熟慮的經理人採取有層次的態度:
- 部分資料(甚至大多數)是壞的,不能用
- 部分資料是好的,可以放心信任
- 部分資料有瑕疵但可以小心使用——這類資料最值得探究,遊戲規則的改寫常藏在這裡
本章提供一套流程,協助你和資料科學家一起判斷資料能不能信任、能用到什麼程度。
步驟 1:評估資料來源#
黃金標準:資料是按一流資料品質專案產出。
特徵:
- 經理人對資料正確性有明確問責
- 有輸入控制(input control)
- 主動找出並消除錯誤的根本原因
- 有資料品質統計可參考、有專家可問
如果上述條件齊備、對話順暢——直接信任。其他步驟都該以此為校準基準。
步驟 2:自行評估資料品質#
多數資料達不到黃金標準。別被「我們從最新技術的雲端資料倉儲撈出來的」這種話術唬到——關鍵不是怎麼取得,而是最初是在哪裡被產生。
探查資料源頭#
- 哪個組織原始產生這份資料?
- 同事對這個組織的評價如何?品質口碑好嗎?
- 社群媒體上其他人怎麼說?
- 公司內外都做點功課
Friday Afternoon Measurement(週五午後測量法)#
這是一個簡單卻有效的自評技巧,自己或請資料科學家一起做。
操作步驟:
- 在試算表上挑出 100 筆資料 × 10–15 個重要欄位(資料元素)
- 例如客戶購買資料:「客戶名稱」「購買項目」「價格」
- 逐筆逐欄檢視,用紅筆或鮮亮顏色標出明顯錯誤
- 客戶名稱拼錯
- 購買項目是公司不賣的東西
- 價格欄位空白
- 計算「沒有任何錯誤」的紀錄數
| 紅標比例 | 結論 |
|---|---|
| 大量紅 | 不要信任這份資料 |
| < 5% 紀錄有明顯錯誤 | 可小心使用 |
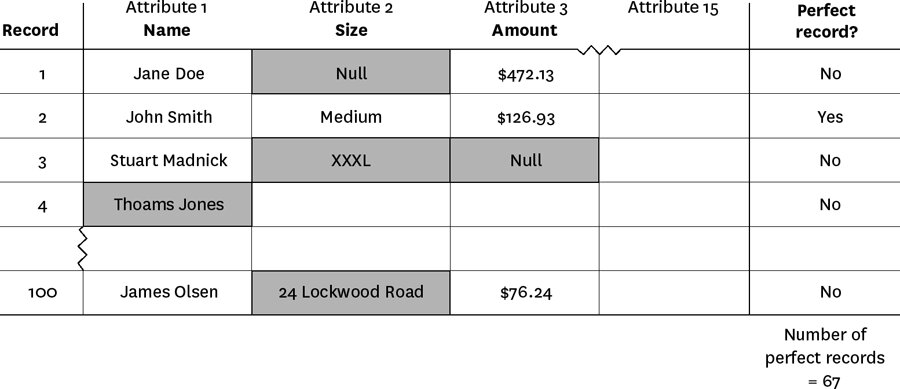
Figure 8-1: Example: Friday afternoon measurement spreadsheet
觀察錯誤模式#
例:總共 25 個錯誤,其中 24 個都集中在「價格」這個欄位——把這個欄位剔除即可,其餘資料若品質尚可,仍可小心使用。
步驟 3:清理資料(rinse, wash, scrub)#
作者把資料清理分為三層次:
- rinse(沖洗):把明顯錯誤替換為「missing value」,或極簡單的更正。
- wash(洗滌):中等深度,常用自動化方法。
- scrub(刷洗):最深,必要時逐筆人工修正。
Scrub:先把小樣本洗到極致#
即使時間有限,也至少對 1,000 筆隨機樣本做最徹底的 scrub。
目標是得到「你絕對信任」的小樣本。
- 無情地刪掉無法修正的錯誤紀錄與欄位
- 對不確定的資料標註「uncertain」
依結果決定後續走向:
| Scrub 結果 | 行動 |
|---|---|
| 結果非常乾淨 | 列為可信任,往下走 |
| 還是不放心 | 列為小心使用 |
| 太多錯誤無法修正(例如價格普遍錯誤) | 整批資料判定為不可信任,停手 |
Wash:對其餘資料做半自動清理#
由真正能幹的資料科學家負責,使用較自動化的方法。例如:
- 用統計方式對缺失值「插補(imputing)」
- 套用 scrub 階段發現的修正演算法
清洗順利的話,這部分資料列為「小心使用」。
步驟 4:高品質的資料整合#
把可信任或小心使用的資料整合進既有資料時,請資料科學家把以下三件事做好:
- 識別(Identification):不同資料集裡的「Courtney Smith」是同一個人嗎?
- 單位與定義對齊(Alignment of units of measure and data definitions):A 集是「pallets / dollars」,B 集是「units / euros」,能對得上嗎?
- 去重(De-duplication):「Courtney Smith」是否重複以「C. Smith」「Courtney E. Smith」等形式出現?
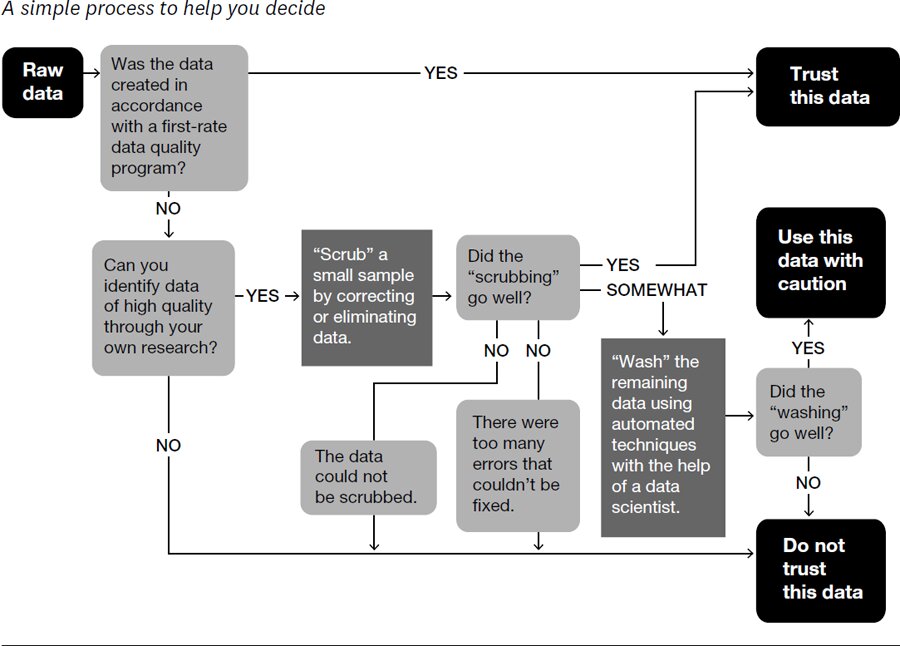
Figure 8-2: Should you trust your data?
步驟 5:分析、並對結果保持懷疑#
當「小心使用」與「完全信任」兩類資料給出不同結果時:
此處同時是「最大洞察」與「最大陷阱」之所在。
當結果看起來有趣,回頭把那批資料隔離出來、重跑前面所有步驟,做更細緻的測量、更深的 scrub、更聰明的 wash——一邊做,一邊培養出對資料可信度的「手感」。
結語:資料不必完美,但你必須清楚瑕疵在哪#
資料不必完美才能產生洞察,但必須謹慎:
- 知道瑕疵在哪
- 設法繞開錯誤
- 持續清理
- 當資料品質真的不足,就果斷退場