由 Mike Yeomans 所撰。本章把機器學習(machine learning)定位為「為大數據而生的統計學分支」,並說明三個核心技術概念,以及管理者最常踩到的兩個陷阱。
不只是大數據,更是「寬資料」#
企業手中的資料規模帶來新挑戰。**大數據(big data)**確實需要先進的軟硬體來儲存與處理,但機器學習真正關注的是:分析方法本身必須隨資料規模演進。
關鍵在於:大數據不只是「長」,更是「寬」(wide data)。以線上零售商的客戶資料庫為例:
- 每位客戶佔一列(row)→ 客戶多時,資料就變得很長
- 每個變數佔一欄(column)→ 我們能蒐集的客戶資訊(購買史、瀏覽紀錄、滑鼠點擊、評論文字)多到欄數常比列數還多
大多數機器學習工具,都是為了**更有效運用「寬資料」**而設計的——這是它與傳統統計分析的根本差異。
預測,不是因果#
機器學習最常見的應用是預測。商業上的典型場景包括:
- 為顧客做個人化推薦
- 預測長期顧客忠誠度
- 預估員工未來的績效表現
- 評估貸款申請者的信用風險
這些情境的共同特徵:
- 環境複雜,正確決策依賴大量變數(需要寬資料)
- 有可驗證結果的指標(顧客是否點擊、是否再購)
- 涉及一個必須仰賴準確預測的商業決策
機器學習與傳統統計最重要的差別是:你不需要知道「為什麼」。預測模型只需描繪環境,而非解釋因果。
就像帶不帶傘出門:你只要預測天氣,不需要懂雲怎麼形成、傘為什麼防水,更不需要去改變天氣。
個人化推薦也是同理——它預測你的偏好,不解釋你為何喜歡某物,也不能改變你的偏好。記住這層限制,機器學習的價值反而更清晰。
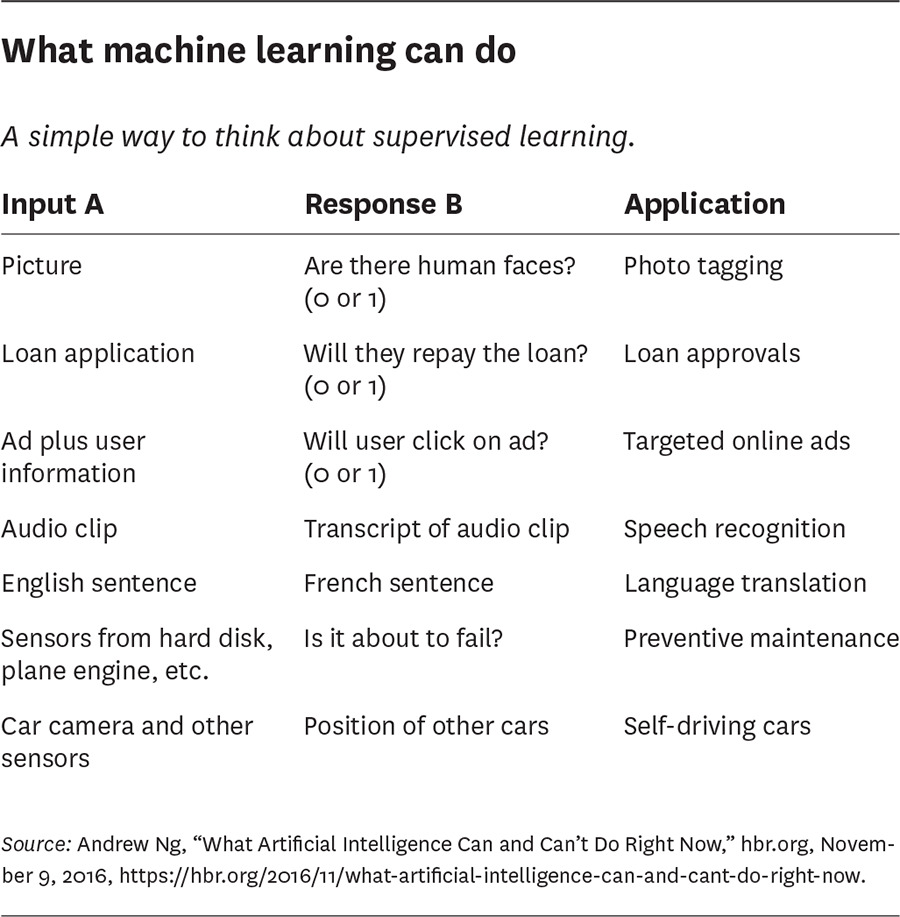
Table 2-1: What machine learning can do(監督式學習的典型應用:輸入 A → 回應 B → 應用場景)
把訊號從雜訊中分離出來#
機器學習演算法底層大致涉及三個概念,目的都是把**訊號(signal,可重複出現的有用關係)從雜訊(noise,不會再現的隨機關聯)**中分離出來。
特徵萃取(Feature Extraction)#
特徵萃取決定模型要使用哪些變數:
- 有時可以直接把所有原始資料丟進去
- 但更多時候,演算法會建立新的「特徵(features)」——把分散在多個原始變數中的訊號匯總起來
範例:
- 臉部辨識:從大量像素中算出鼻長、眼色、膚色等臉部特徵
- 音樂銷售:把所有搖滾專輯的銷售量合併為單一特徵,古典樂另成一個特徵
- 自動分群:找出常被同一群人購買的專輯叢集,從資料中自動學出音樂類型,甚至發現原本不知道的新類型
- 文字資料:根據共同出現的詞彙與片語,自動萃取潛在主題
即使萃取過程可自動化,領域專家在「建議特徵」與「詮釋叢集」上仍非常有價值。
不以預測為目標、僅用來組織資料的這類做法,稱為非監督式學習(unsupervised learning)。
正則化(Regularization)#
如何確認所萃取的特徵真是訊號而非雜訊?這就是正則化的作用——告訴模型「保守一點,不要太快下結論」。相關詞彙包含 pruning、shrinkage、variable selection。
兩個極端比較:
- 最保守的模型:對所有人做同樣預測(永遠推薦最熱門專輯)→ 既忽略雜訊也忽略訊號
- 最複雜的模型:迎合每位顧客的所有怪癖 → 連雜訊都學進去,發生過擬合(overfitting),未來表現甚至比保守模型更差
正則化通常透過「對複雜度加上懲罰」來折衷,產生兩種效果:
- 選擇(selection):只聚焦少數最具訊號的特徵,丟棄其他
- 收縮(shrinkage):降低每個特徵的影響力,避免預測過度依賴單一特徵
交叉驗證(Cross-Validation)#
模型建好後,如何確認預測準確?最關鍵的測試是**樣本外(out of sample)**準確度——亦即模型對它從未見過的資料的預測表現。
實地測試昂貴,因此機器學習常用交叉驗證模擬此測試:
- 將 10,000 筆歷史顧客資料隨機切成兩份
- 訓練集(9,000 筆)→ 用於建立模型
- 測試集(1,000 筆)→ 暫時擱置,僅在模型完成後用來驗證
模型建立過程中,絕對不能讓它看到測試集的結果,否則會高估模型實際表現——這是非常昂貴的錯誤。
使用機器學習時要避免的錯誤#
陷阱一:把預測模型誤當成因果模型#
人類天生會思考「如何改變環境以製造某個效果」,但在預測問題中,因果並非優先目標。預測模型是用來在穩定環境下優化決策——環境越穩定,預測模型越有用。
陷阱二:混淆「樣本外」與「情境外」#
- 樣本外(out of sample):在同樣環境蒐集的新資料上,模型仍能準確預測
- 情境外(out of context):換到不同環境後,模型不一定還有用
範例:用線上購物資料建立的模型,即使商品線完全相同,也未必適用於實體店面顧客。
不要以為「資料量足夠大」就能解決情境外問題。演算法的強項來自「拿新案例與資料庫中相似的舊案例比對」——換到不同情境後,相似性消失,原本的優勢就變成了負擔。
情境外模型仍可能優於「沒有模型」,前提是清楚意識到它的限制。
結語#
模型建立的某些步驟看似自動,但判斷一個模型在哪裡有用,仍需要大量人類判斷;運用正則化與交叉驗證等內建保護機制,也需要嚴謹的批判思考。
別忘了——純人類判斷本身也帶有偏見與錯誤。技術能力與人類判斷的恰當組合,才能讓機器學習成為決策者面對寬資料時真正有用的新工具。