設計一個類似 Yelp 的服務,讓使用者可以搜尋附近的餐廳、電影院、購物中心等地點,並能新增/檢視地點的評價。
- 類似服務:Proximity Server
- 難度:困難
為什麼要設計 Yelp 或 Proximity Server#
Proximity Server 用於發現附近的景點、活動等。本章設計一個類似 Yelp 的服務,讓使用者可以搜尋附近的地點。
系統需求與目標#
我們的服務將儲存不同地點的資訊,讓使用者可以進行搜尋。查詢時,服務會回傳使用者附近的地點列表。
功能性需求(Functional Requirements)#
- 使用者可以新增/刪除/更新 Place
- 給定使用者的位置(經緯度),可以找到指定半徑內的所有附近地點
- 使用者可以為地點新增評價/回饋,包含圖片、文字和評分
非功能性需求(Non-functional Requirements)#
- 使用者應擁有即時搜尋體驗,延遲最小化
- 系統應支援高搜尋負載 — 搜尋請求量遠高於新增地點的請求量
規模估算#
- 地點總數:5 億
- 查詢量:每秒 10 萬次(QPS)
- 每年地點數量和 QPS 的成長率:20%
Database Schema#
Location 表#
每個地點包含以下欄位:
| 欄位 | 大小 | 說明 |
|---|---|---|
| LocationID | 8 bytes | 唯一識別碼 |
| Name | 256 bytes | 地點名稱 |
| Latitude | 8 bytes | 緯度 |
| Longitude | 8 bytes | 經度 |
| Description | 512 bytes | 描述 |
| Category | 1 byte | 類別(咖啡店、餐廳、電影院等) |
- 總大小:
8 + 256 + 8 + 8 + 512 + 1 = 793 bytes - 雖然 4 bytes 足以識別 5 億個地點,考慮未來成長使用 8 bytes
Review 表#
| 欄位 | 大小 | 說明 |
|---|---|---|
| LocationID | 8 bytes | 所屬地點 |
| ReviewID | 4 bytes | 唯一識別碼(假設單一地點不超過 2^32 則評價) |
| ReviewText | 512 bytes | 評價內容 |
| Rating | 1 byte | 評分(滿分十顆星) |
另外可以有獨立的表格儲存地點和評價的照片。
System APIs#
可以使用 SOAP 或 REST API 公開服務功能。搜尋 API 定義如下:
search(api_dev_key, search_terms, user_location, radius_filter,
maximum_results_to_return, category_filter, sort, page_token)參數說明#
- api_dev_key(string):已註冊帳號的 API 開發者金鑰,可用於根據配額進行流量限制
- search_terms(string):搜尋關鍵字
- user_location(string):執行搜尋的使用者位置
- radius_filter(number):選填;搜尋半徑(公尺)
- maximum_results_to_return(number):要回傳的搜尋結果數量
- category_filter(string):選填;過濾類別(如 Restaurants、Shopping Centers 等)
- sort(number):選填;排序模式 —
0最佳匹配(預設)、1最短距離、2最高評分 - page_token(string):指定結果集中要回傳的頁面
回傳值:JSON 物件,包含符合條件的商家列表,每筆結果包含商家名稱、地址、類別、評分和縮圖。
基本系統設計與演算法#
在高層架構上,我們需要儲存並索引上述資料集(地點、評價等)。為了讓使用者能即時查詢這個大型資料庫,索引必須具備高效的讀取效能。
由於地點的位置不常變動,我們不需擔心頻繁的資料更新。如果要建構物件位置頻繁變動的服務(如人或計程車),設計會截然不同。
SQL 方案#
最簡單的方式是將所有資料儲存在 MySQL 等資料庫中:
- 每個地點以 LocationID 唯一識別,存為獨立的一列
- 經度和緯度分別儲存,並在這兩個欄位上建立索引
查詢指定位置 (X, Y) 半徑 D 內的所有地點:
SELECT * FROM Places
WHERE Latitude BETWEEN X-D AND X+D
AND Longitude BETWEEN Y-D AND Y+D效能問題:
- 5 億筆地點資料中,兩個獨立索引各自可能返回大量結果
- 對兩個列表取交集的效率很差
X-D到X+D和Y-D到Y+D之間可能有太多地點
Grid 方案#
將整個地圖劃分為較小的網格(Grid),將地點歸組到較小的集合中。每個網格儲存特定經緯度範圍內的所有地點。
- 假設 GridID 以 4 bytes 唯一識別
- 網格大小設定為與搜尋距離相同,只需搜尋包含目標位置的網格及相鄰的 8 個網格
- 由於網格是靜態定義的,可以輕鬆計算任何位置的網格編號及其鄰近網格
改進後的查詢:
SELECT * FROM Places
WHERE Latitude BETWEEN X-D AND X+D
AND Longitude BETWEEN Y-D AND Y+D
AND GridID IN (GridID, GridID1, GridID2, ..., GridID8)
圖 23.1:二維網格地圖(Grid of two dimensional data - 世界地圖上的經緯度網格系統)
記憶體中的索引#
將索引保留在記憶體中可以提升效能,使用 Hash Table:
- Key:GridID
- Value:該網格中所有地點的列表
記憶體需求#
- 搜尋半徑:10 英里
- 地球總面積約 2 億平方英里
- 網格總數:2,000 萬個
- 每個 GridID 需要 4 bytes,LocationID 需要 8 bytes
- 總記憶體需求:
(4 * 20M) + (8 * 500M) ≈ 4GB
Grid 方案的問題#
地點分布不均勻 — 市中心等密集區域的網格可能包含大量地點,而海洋等稀疏區域的網格幾乎沒有地點。如果能動態調整網格大小,就能在密集區域使用更小的網格。
Dynamic Size Grids — QuadTree#
假設我們不希望單一網格中超過 500 個地點。每當網格達到此上限,就將其分裂為四個等大的子網格,並重新分配其中的地點。
- 密集區域(如舊金山市中心)會有很多小網格
- 稀疏區域(如太平洋)會有很大的網格
QuadTree 資料結構#
使用一種每個節點有四個子節點的樹狀結構:
- 每個節點代表一個網格,包含該網格內所有地點的資訊
- 當節點達到 500 個地點的上限時,分裂為四個子節點並分配地點
- 所有葉節點代表無法再細分的網格,保存地點列表
建構 QuadTree#
- 從代表整個世界的單一根節點開始
- 由於根節點超過 500 個地點,分裂為四個子節點並分配地點
- 對每個子節點遞迴重複此過程,直到所有節點都不超過 500 個地點
搜尋指定位置的網格#
- 從根節點開始向下搜尋
- 若當前節點有子節點,移動到包含目標位置的子節點
- 若當前節點沒有子節點,即為目標網格
尋找鄰近網格#
有兩種方式:
- Doubly Linked List:將所有葉節點以雙向鏈結串列連接,可以前後迭代找到鄰近地點
- Parent Pointer:每個節點保留指向父節點的指標,透過父節點存取其所有子節點來找到兄弟節點,並可向上展開搜尋更多鄰近網格
找到鄰近的 LocationID 後,查詢後端資料庫取得地點詳細資訊。
搜尋流程#
- 找到包含使用者位置的節點
- 若該節點有足夠的目標地點,直接回傳
- 若不足,持續向鄰近節點擴展,直到找到所需數量或達到最大搜尋半徑
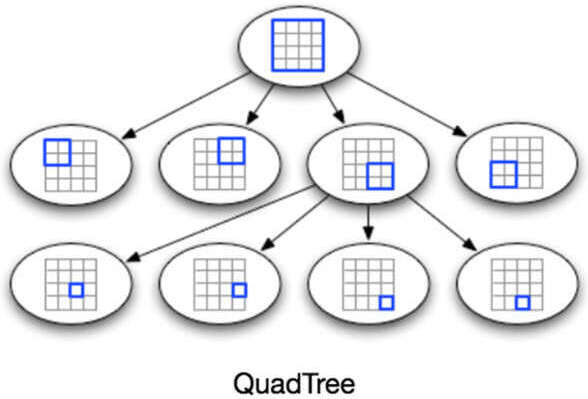
圖 23.2:QuadTree 結構圖(展示遞迴空間劃分,根節點 → 4 子節點 → 更細劃分)
QuadTree 記憶體需求#
- 每個地點快取 LocationID + Lat/Long:
24 * 500M = 12GB - 每個網格最多 500 個地點,共 5 億個地點,因此約有
500M / 500 = 1M個葉節點 - QuadTree 的 1M 個葉節點約有 1/3 的內部節點,每個內部節點有 4 個指標(各 8 bytes)
- 內部節點記憶體:
1M * 1/3 * 4 * 8 = 10MB - 總記憶體需求約 12.01GB,可輕鬆放入一台現代伺服器
新增地點#
當使用者新增一個 Place 時,需要同時寫入資料庫和 QuadTree:
- 若 QuadTree 在單一伺服器上,直接新增即可
- 若 QuadTree 分散在多台伺服器上,需先找到對應的網格/伺服器再新增
Data Partitioning#
當索引無法放入單一機器的記憶體時(以每年 20% 的成長率,終會達到上限),且單一伺服器無法處理所有讀取流量時,就需要分割 QuadTree。
方案 A:基於 Region 分片#
將地點依區域(如郵遞區號)劃分,同一區域的所有地點儲存在固定節點上。
問題:
- 熱點區域(Hot Region):某些區域查詢量特別大,導致該伺服器效能下降
- 分布不均:隨著時間推移,部分區域的地點數量可能遠多於其他區域,難以維持均勻分布
解決方案:重新分區或使用 Consistent Hashing。
方案 B:基於 LocationID 分片#
- Hash Function 將每個 LocationID 映射到對應的伺服器
- 建構 QuadTree 時,遍歷所有地點並計算 LocationID 的 Hash 值以決定儲存位置
- 搜尋附近地點時,需查詢所有伺服器,每台伺服器回傳一組附近地點
- 由集中式伺服器彙整結果後回傳給使用者
不同分區上的 QuadTree 結構可能不同,因為無法保證每個分區在任意網格中都有相同數量的地點。但這不會造成問題,因為搜尋時會在所有分區的鄰近網格中進行查詢。
本章後續假設採用基於 LocationID 的分片方案。
Replication and Fault Tolerance#
QuadTree 伺服器的副本可以作為資料分區的替代方案,用於分散讀取流量。
Master-Slave 架構#
- Slave(副本)僅處理讀取流量
- 所有寫入先到 Master,再同步到 Slave
- Slave 可能有幾毫秒的延遲(缺少最新新增的地點),但這是可接受的
故障處理#
- 單一伺服器故障:每台伺服器都有一個 Secondary Replica,主伺服器故障時由副本透過 Failover 接管,兩者擁有相同的 QuadTree 結構
- 主副本同時故障:需分配新伺服器並重建 QuadTree。暴力解法是遍歷整個資料庫,用 Hash Function 過濾出屬於該伺服器的 LocationID,但這個過程緩慢且期間無法提供服務
QuadTree Index Server#
建立一個反向索引,將所有地點映射到對應的 QuadTree 伺服器:
- 使用 HashMap:Key 為 QuadTree Server 編號,Value 為該伺服器上所有地點的 HashSet(包含 LocationID 和 Lat/Long)
- 使用 HashSet 可以快速新增/移除地點
- 當 QuadTree 伺服器需要重建時,直接向 QuadTree Index Server 請求所需的所有地點資料
- QuadTree Index Server 本身也應有副本以確保容錯性
- 若 QuadTree Index Server 故障,可從資料庫重建索引
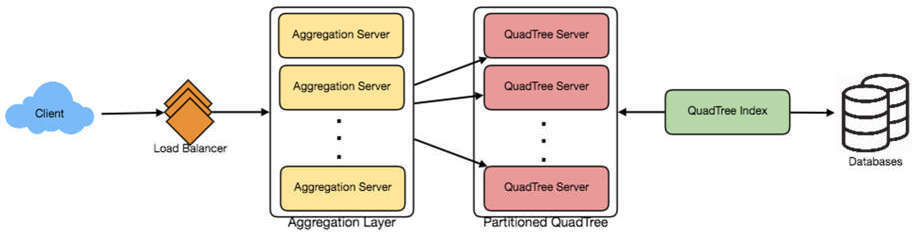
圖 23.3:系統架構圖(Client → Load Balancer → Aggregation Layer → Partitioned QuadTree Servers → QuadTree Index + Databases)
Cache#
為了處理熱門地點,在資料庫前方引入快取層:
- 使用 Memcache 等現成方案儲存熱門地點的所有資料
- Application Server 在查詢資料庫前先檢查快取
- 根據客戶端使用模式調整快取伺服器數量
- 快取淘汰策略:LRU(Least Recently Used)
Load Balancing#
在系統中的兩個層級加入 Load Balancer:
- Client 與 Application Server 之間
- Application Server 與 Backend Server 之間
Round Robin 方式#
- 初始可採用 Round Robin,將所有請求平均分配到後端伺服器
- 實作簡單,無額外負擔
- 若伺服器故障,Load Balancer 將其移出輪替,停止發送流量
智慧 Load Balancing#
- Round Robin 的缺點是不考慮伺服器負載 — 若某伺服器超載或緩慢,仍會持續接收新請求
- 更好的方案是定期查詢後端伺服器的負載,根據負載動態調整流量分配
Ranking#
除了依距離排名外,也可以根據熱門度或相關性排名搜尋結果。
熱門地點排名#
- 追蹤每個地點的整體熱門度(例如平均評分,滿分十顆星)
- 將此數值儲存在資料庫和 QuadTree 中
- 搜尋指定半徑內的前 100 個地點時,每個分區的 QuadTree 回傳各自的前 100 個最熱門地點
- 由 Aggregator Server 從所有分區的結果中選出最終的前 100 名
更新熱門度#
- 本系統並非設計來頻繁更新地點資料
- 直接在 QuadTree 中搜尋並更新某地點的熱門度會消耗大量資源,影響搜尋效能
- 假設熱門度不需在幾小時內立即反映,可決定每天更新一到兩次,選擇系統負載最低的時段執行
下一章「Designing Uber Backend」會詳細討論 QuadTree 的動態更新機制。