設計一個 Facebook 的 Newsfeed 系統,讓使用者可以看到其追蹤對象的最新動態。
系統需求#
功能性需求(Functional Requirements)#
- Newsfeed 根據使用者追蹤的人、粉絲專頁和社團的貼文來產生
- 使用者可能有大量好友,並追蹤許多粉絲專頁/社團
- Feed 內容可包含圖片、影片或純文字
- 當有新貼文產生時,系統應能將其即時附加到所有活躍使用者的 Newsfeed 中
非功能性需求(Non-functional Requirements)#
- 系統應能即時產生任何使用者的 Newsfeed,最大延遲不超過 2 秒
- 一則新貼文從發布到出現在使用者的 Feed 中,不應超過 5 秒(假設使用者發出新的 Newsfeed 請求)
容量估算與限制#
假設平均每位使用者有 300 位好友,追蹤 200 個粉絲專頁。
流量估算#
- 每日活躍使用者:3 億
- 每位使用者每天平均擷取 Timeline 5 次
- 每日 Newsfeed 請求量:15 億次
- 約每秒 17,500 個請求
儲存估算#
- 每位使用者的 Feed 保留 500 則貼文於記憶體中以供快速讀取
- 每則貼文平均大小:1KB
- 每位使用者約需 500KB 的儲存空間
- 所有活躍使用者的記憶體需求:
300M * 500KB = 150TB - 若每台伺服器可容納 100GB,則需要約 1,500 台機器
System APIs#
在確定需求後,定義系統 API 是一個好做法,可以明確指出系統的預期行為。
我們可以使用 SOAP 或 REST API 來公開服務功能。以下是取得 Newsfeed 的 API 定義:
getUserFeed(api_dev_key, user_id, since_id, count, max_id, exclude_replies)參數說明#
- api_dev_key(string):已註冊帳號的 API 開發者金鑰,可用於根據配額進行流量限制
- user_id(number):要產生 Newsfeed 的使用者 ID
- since_id(number):選填;回傳 ID 大於(即比指定 ID 更新的)貼文
- count(number):選填;指定要擷取的 Feed 項目數量,每次請求最多 200 則
- max_id(number):選填;回傳 ID 小於或等於(即比指定 ID 更舊的)貼文
- exclude_replies(boolean):選填;設為 true 時排除回覆內容
回傳值:JSON 物件,包含一組 Feed 項目的列表。
Database Design#
系統有三個基本物件:User、Entity(如粉絲專頁、社團等)和 FeedItem(即貼文)。
資料關係#
- 使用者可以追蹤 Entity 並與其他使用者成為好友
- 使用者和 Entity 都可以發布 FeedItem,內容可包含文字、圖片或影片
- 每則 FeedItem 都有一個 UserID 指向其建立者(簡化假設:只有使用者可以建立 FeedItem)
- 每則 FeedItem 可選擇性地包含一個 EntityID,指向該貼文所屬的粉絲專頁或社團
資料表設計#
若使用關聯式資料庫,需要建立以下關係:
- UserFollow 表:記錄使用者的追蹤關係,其中
Type欄位標識被追蹤的對象是 User 或 Entity - FeedMedia 表:記錄 FeedItem 與其媒體檔案的關聯
High Level Design#
在高層架構上,此問題可分為兩大部分:Feed 產生(Feed Generation) 和 Feed 發布(Feed Publishing)。
Feed Generation#
當系統收到為某位使用者(例如 Jane)產生 Feed 的請求時,執行以下步驟:
- 取得 Jane 追蹤的所有使用者和 Entity 的 ID
- 取得這些 ID 的最新、最熱門且最相關的貼文,這些是 Jane 的候選 Feed 項目
- 根據與 Jane 的相關性進行排名,形成 Jane 的當前 Feed
- 將此 Feed 儲存於快取中,並回傳前 20 則貼文供前端渲染
- 當 Jane 滑到 Feed 底部時,可以向伺服器擷取下一批 20 則貼文
Feed 產生一次後就儲存在快取中。對於 Jane 追蹤對象的新貼文,可以定期(例如每五分鐘)重新排名並將新貼文加入 Feed,然後通知 Jane 有新內容可供擷取。
Feed Publishing#
當 Jane 載入 Newsfeed 頁面時,需要從伺服器請求並拉取 Feed 項目。滑到底部時可繼續拉取更多資料。對於新項目,伺服器可以通知 Jane 後由她拉取,或由伺服器主動推送。
系統元件#
- Web Servers:維護與使用者的連線,用於在使用者和伺服器間傳輸資料
- Application Servers:執行將新貼文存入資料庫的工作流程,同時負責擷取並推送 Newsfeed
- Metadata Database and Cache:儲存 User、Page、Group 的 metadata
- Posts Database and Cache:儲存貼文的 metadata 和內容
- Video and Photo Storage, and Cache:Blob 儲存,存放貼文中的所有媒體檔案
- Newsfeed Generation Service:彙整並排名使用者相關的所有貼文以產生 Newsfeed,並將結果儲存於快取中。此服務也接收即時更新,將新 Feed 項目加入使用者的 Timeline
- Feed Notification Service:通知使用者有新的 Newsfeed 項目可供讀取
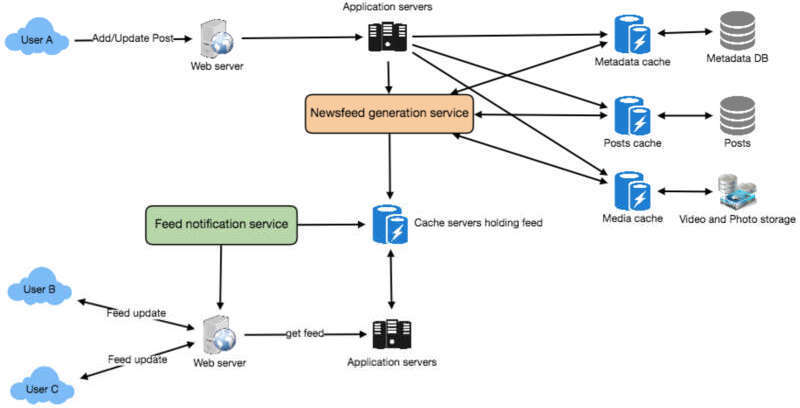
圖 22.1:系統架構圖(User A → Web Server → Application Servers → Newsfeed Generation Service → Metadata/Posts Cache/DB;Feed Notification Service → Cache Servers → User B/C 讀取 Feed)
Detailed Component Design#
Feed Generation 的問題與優化#
以最簡單的方式為 Jane 產生 Feed — 從她追蹤的所有使用者和 Entity 取得最新貼文 — 會遇到以下問題:
- 對於追蹤大量好友/粉絲專頁的使用者,需要對大量貼文進行排序/合併/排名,速度極慢
- 在使用者載入頁面時才產生 Timeline,會導致高延遲
- 即時更新時,每則新貼文都需更新所有追蹤者的 Feed,導致 Newsfeed Generation Service 的積壓量過大
- 伺服器推送新貼文給使用者的負載極高,尤其是追蹤者眾多的名人帳號
Offline Generation#
為了改善效率,可以使用專用伺服器持續預先產生使用者的 Newsfeed 並儲存於記憶體中。當使用者請求新的 Feed 時,直接從預先產生的位置提供服務。
- 使用者的 Newsfeed 不在載入時編譯,而是定期預先產生
- 伺服器在產生 Feed 時,先查詢該使用者的上次產生時間,從該時間點開始產生新 Feed 資料
儲存結構#
可以使用 Hash Table 儲存 Feed 資料:
- Key:
UserID - Value:包含以下欄位的 Struct
FeedItemIDs:使用 Linked HashMap 儲存,可快速跳轉到任意 FeedItem 並輕鬆迭代- 上次產生 Feed 的時間戳
當使用者要擷取更多 Feed 項目時,可發送目前最後一則 FeedItemID,伺服器在 Linked HashMap 中跳轉到該項目,返回下一批 Feed 項目。
儲存數量決策#
- 初始設計為每位使用者儲存 500 則 Feed 項目
- 若假設每頁 20 則貼文,大多數使用者不會瀏覽超過 10 頁,可減少為 200 則
- 需要更多貼文的使用者可隨時查詢後端伺服器
是否為所有使用者預先產生 Newsfeed#
不常登入的使用者數量很大,可採用以下策略:
- LRU 快取:將長時間未存取 Newsfeed 的使用者從記憶體中移除
- 智慧預測:根據使用者的登入模式(每天何時活躍、每週哪幾天使用等)來決定是否預先產生
Feed Publishing#
將貼文推送給所有追蹤者的過程稱為 Fanout。Push 方式稱為 Fan-out-on-write,Pull 方式稱為 Fan-out-on-load。
Pull 模式(Fan-out-on-load)#
- 將最新的 Feed 資料保留在記憶體中,使用者定期或手動拉取
- 問題:
- 新資料在使用者主動拉取前不會顯示
- 難以找到合適的拉取頻率,大多數請求可能返回空結果,造成資源浪費
Push 模式(Fan-out-on-write)#
- 使用者發布貼文後,立即推送給所有追蹤者
- 優點:擷取 Feed 時不需遍歷好友列表並取得各自的 Feed,大幅減少讀取操作
- 使用者透過 Long Poll 維持與伺服器的連線以接收更新
- 問題:當使用者有數百萬追蹤者(名人帳號)時,伺服器需推送大量更新
Hybrid 模式#
- 對追蹤者數量多的名人帳號停止推送,改由追蹤者自行拉取
- 對追蹤者數量少(數百或數千)的使用者維持推送模式
- 也可限制 Fanout 只推送給在線好友
- 結合 Push 通知 + Pull 提供服務是最具彈性的做法
每次請求的 Feed 項目數量#
- 設定最大限制(例如 20 則)
- 允許客戶端指定數量,因為不同裝置(手機 vs 桌面)可能需要不同數量
新貼文通知策略#
- 桌面端:有新資料時通知使用者
- 行動端:考慮到資料傳輸成本,可選擇不主動推送,讓使用者透過 Pull to Refresh 手動擷取
Feed Ranking#
最直接的排名方式是依據貼文的建立時間。但現代排名演算法遠比這複雜,確保「重要」的貼文排在更前面。
排名流程#
- 選擇能反映貼文重要性的關鍵 Signals(信號)
- 結合這些信號計算最終的排名分數
相關 Signals#
- 按讚數、留言數、分享數
- 貼文時間
- 是否包含圖片/影片
- 其他能提升使用者黏著度、留存率、廣告收入的因素
良好的排名系統應不斷評估指標(使用者黏著度、留存率、廣告收入等),並持續自我優化。
Data Partitioning#
Sharding Posts and Metadata#
由於每天有大量新貼文且讀取負載極高,需要將資料分散到多台機器上。分片策略可參考 Designing Twitter 的設計。
Sharding Feed Data#
對於儲存在記憶體中的 Feed 資料,可基於 UserID 進行分片:
- 將同一使用者的所有資料儲存在同一台伺服器上
- 透過 Hash Function 將 UserID 映射到對應的快取伺服器
- 每位使用者最多存 500 則 FeedItemID,不會超出單一伺服器的容量
- 取得使用者的 Feed 時,只需查詢一台伺服器
- 為了未來擴展和複製,必須使用 Consistent Hashing