什麼是 Web Crawler#
Web Crawler 是一種能夠以系統化、自動化方式瀏覽並下載全球資訊網(World Wide Web)內容的軟體程式。它透過遞迴擷取連結的方式,從一組起始頁面開始收集文件。Web Crawler 也被稱為 web spider、robot、worm、walker 或 bot。
- 難度:困難
許多網站(特別是搜尋引擎)透過 Web Crawling 來提供最新資料。搜尋引擎會下載所有頁面並建立索引,以實現更快速的搜尋。
Web Crawler 的其他用途#
- 測試網頁與連結的語法和結構是否有效
- 監控網站的結構或內容變化
- 維護熱門網站的映射站台(mirror site)
- 搜尋版權侵權內容
- 建立特殊用途索引,例如理解網路上多媒體檔案的內容
需求與系統目標#
假設我們需要爬取整個網路。
- 可擴展性(Scalability):系統必須能夠爬取整個 Web,並能擷取數億個網頁文件
- 可擴充性(Extensibility):系統應以模組化方式設計,未來可新增處理新文件類型的功能
設計考量#
在進一步設計之前,需要先釐清幾個問題:
爬取範圍#
只爬取 HTML 頁面,還是也包含其他媒體類型(音訊、圖片、影片等)?
如果是通用型爬蟲,可能需要將解析模組拆分為不同的子模組:HTML、圖片、影片等,各自提取其感興趣的內容。
本設計假設 Crawler 僅處理 HTML,但架構應具備可擴充性,便於日後新增其他媒體類型的支援。
協定支援#
需要處理哪些協定?HTTP?FTP?
本設計假設僅支援 HTTP,但架構設計上應易於擴充至 FTP 等其他協定。
預期爬取規模#
- 假設需要爬取 10 億個網站
- 上限約 150 億個不同的網頁
Robots Exclusion Protocol#
- 禮貌的 Web Crawler 應實作 Robots Exclusion Protocol
- 此協定允許網站管理員宣告其網站的哪些部分禁止爬取
- Crawler 在下載任何實際內容前,必須先擷取並解析 robot.txt 檔案
容量估算與限制#
若要在四週內爬取 150 億個頁面:
15B / (4 weeks * 7 days * 86400 sec) ≈ 6200 pages/sec儲存需求#
- 假設平均頁面大小為 100 KB
- 每頁額外儲存 500 bytes 的 metadata
15B * (100 KB + 500) ≈ 1.5 petabytes以 70% 容量模型計算(不超過總容量的 70%):
1.5 petabytes / 0.7 ≈ 2.14 petabytesHigh Level Design#
Web Crawler 的基本演算法是接受一組 seed URLs 作為輸入,然後反覆執行以下步驟:
- 從未造訪的 URL 列表中取出一個 URL
- 透過 DNS 解析其主機名稱對應的 IP 位址
- 與主機建立連線並下載對應文件
- 解析文件內容以尋找新的 URL
- 將新 URL 加入未造訪的 URL 列表
- 處理已下載的文件(例如儲存或建立索引)
- 回到步驟 1
爬取策略#
- BFS(廣度優先搜尋):通常為主要策略
- DFS(深度優先搜尋):在某些情境下使用,例如已與某網站建立連線時,可對該網站內的所有 URL 進行 DFS,以減少交握(handshaking)開銷
Path-ascending Crawling#
此策略能幫助發現孤立資源或在常規爬取中找不到入站連結的資源。Crawler 會嘗試爬取每個 URL 路徑的所有上層目錄。
例如,給定 seed URL http://foo.com/a/b/page.html,Crawler 會嘗試爬取 /a/b/、/a/ 以及 /。
實作高效 Web Crawler 的挑戰#
Web 的兩個特性使得 Web Crawling 非常困難:
- 網頁數量龐大:Crawler 在任何時刻只能下載一小部分網頁,因此必須具備優先排序下載的能力
- 網頁變化頻繁:當 Crawler 下載完一個網站的最後一頁時,該頁可能已經更新,或網站已新增了新頁面
最基本的元件#
- URL Frontier:儲存待下載的 URL 列表,並負責優先排序
- HTTP Fetcher:從伺服器擷取網頁
- Extractor:從 HTML 文件中提取連結
- Duplicate Eliminator:確保相同內容不會被重複提取
- Datastore:儲存已擷取的頁面、URL 及其他 metadata
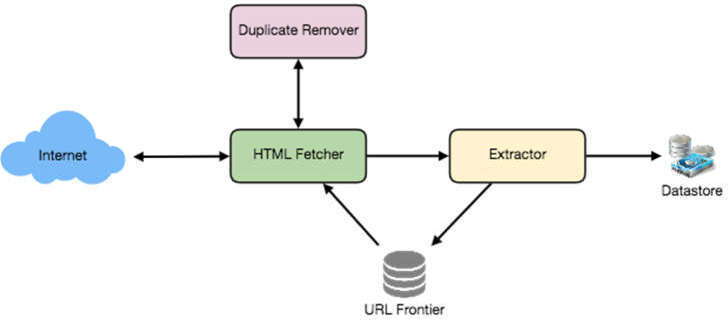
圖 21.1:基本架構(Internet ↔ HTML Fetcher ↔ Duplicate Remover → Extractor → Datastore,含 URL Frontier)
詳細元件設計#
假設 Crawler 運行在一台伺服器上,由多個 worker thread 執行所有的下載與處理工作。每個 worker thread 在迴圈中執行以下步驟:
- 從共享的 URL Frontier 中取出一個絕對 URL
- 根據 URL 的 scheme(如 HTTP),呼叫對應的協定模組下載文件
- 將文件放入 Document Input Stream(DIS),使其他模組能多次讀取文件
- 執行 dedupe 測試,判斷此文件是否已被處理過;若是則跳過
- 根據文件的 MIME type(HTML、Image、Video 等),呼叫對應的處理模組
- HTML 處理模組提取所有連結,將其轉為絕對 URL 並通過 URL filter 過濾
- 通過 URL-seen test 檢查 URL 是否已見過;若為新 URL,則加入 Frontier
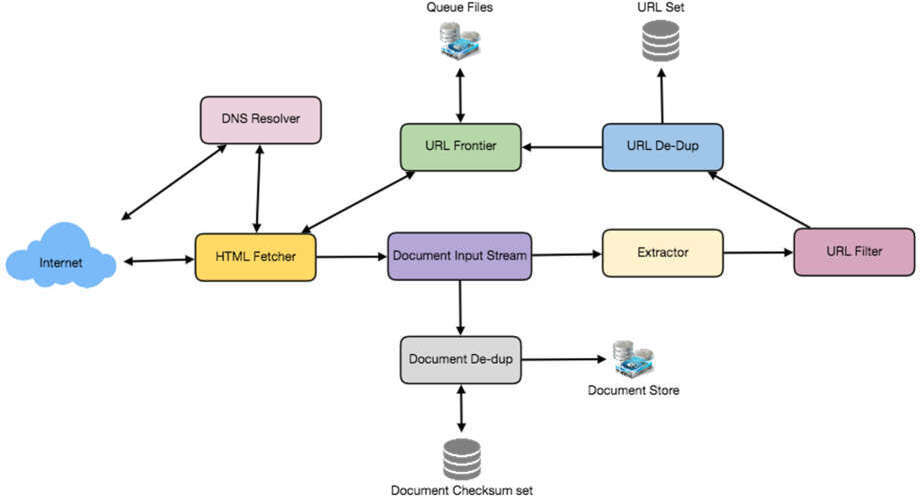
圖 21.2:詳細系統架構(DNS Resolver, URL Frontier, Queue Files, HTML Fetcher, Document Input Stream, Extractor, URL Filter, URL De-Dup, Document De-dup, Document Store, Checksum)
URL Frontier#
URL Frontier 是儲存所有待下載 URL 的資料結構,可透過 FIFO 佇列實作 BFS 遍歷。
分散式設計:
- 將 URL Frontier 分散到多台伺服器
- 每台伺服器上有多個 worker thread 執行爬取任務
- 使用 hash function 將每個 URL 映射到負責爬取的伺服器
禮貌性要求(Politeness):
- 不應對同一伺服器下載過多頁面而造成過載
- 不應有多台機器同時連接同一個 Web Server
實作方式:在每台伺服器上維護多個獨立的 FIFO sub-queue,每個 worker thread 有專屬的 sub-queue。新 URL 依據其 canonical hostname 的 hash 值分配到對應的 sub-queue。這確保了同一 Web Server 最多只由一個 worker thread 下載,且 FIFO 順序避免了過載。
URL Frontier 的大小:
- 規模達數億個 URL,需要儲存到磁碟
- 佇列設計:分離 enqueue buffer 與 dequeue buffer
- Enqueue buffer 滿時寫入磁碟;dequeue buffer 定期從磁碟讀取 URL 填充快取
Fetcher 模組#
- 使用適當的網路協定(如 HTTP)下載文件
- 維護一個固定大小的快取,映射主機名稱到其 robots exclusion rules,避免每次請求都下載 robot.txt
Document Input Stream(DIS)#
DIS 是一個輸入串流,將從網路讀取的文件完整快取於本地,並提供重新讀取的方法。
- 小型文件(64 KB 以下):完全快取在記憶體中
- 大型文件:暫時寫入備份檔案
- 每個 worker thread 有一個關聯的 DIS,在不同文件間重複使用
Document Dedupe Test#
網路上許多文件以不同 URL 存在,或被映射到不同伺服器上。為避免重複處理,需對每份文件進行 dedupe test。
實作方式:
- 對每份已處理文件計算 64-bit checksum(使用 MD5 或 SHA)
- 將 checksum 儲存到資料庫
- 新文件的 checksum 與所有先前的 checksum 比對
Checksum 儲存大小:
15B * 8 bytes = 120 GB雖然 120 GB 可放入現代伺服器記憶體中,若記憶體不足,可在每台伺服器上維護較小的 LRU 快取,搭配持久化儲存。Dedupe test 先查快取,再查後端儲存。
URL Filter#
URL Filter 提供可自訂的機制來控制要下載的 URL 集合,用於將特定網站列入黑名單。可依據網域、前綴或協定類型定義過濾規則。
Domain Name Resolution#
- Crawler 在聯繫 Web Server 前,必須透過 DNS 將主機名稱解析為 IP 位址
- DNS 解析是 Crawler 的重大瓶頸
- 解決方案:建立本地 DNS 伺服器快取 DNS 結果,避免重複請求
URL Dedupe Test#
提取連結時,Crawler 會遇到多個指向同一文件的連結。為避免重複下載,需在每個提取的連結加入 URL Frontier 前執行 URL dedupe test。
實作方式:
- 將所有已見 URL 以 canonical form 儲存為固定大小的 checksum
- 在每台主機上維護熱門 URL 的記憶體快取,供所有 thread 共享,以提高命中率
URL 儲存大小:
15B * 2 bytes = 30 GBBloom Filter 是一種機率型資料結構,可用於集合成員測試,但可能產生 false positive。使用大型 bit vector 表示集合,透過 n 個 hash function 設定對應位元。
用於 URL dedupe 的缺點是:每個 false positive 會導致 URL 不被加入 Frontier,該文件永遠不會被下載。可透過增大 bit vector 來降低 false positive 機率。
Checkpointing#
- 爬取整個 Web 需要數週時間
- Crawler 應定期將其狀態快照寫入磁碟
- 中斷或終止的爬取可以從最新的 checkpoint 輕鬆重啟
容錯(Fault Tolerance)#
- 使用 Consistent Hashing 在爬取伺服器間分配工作
- Extended Hashing 不僅能替換故障主機,還能在爬取伺服器間分散負載
- 所有爬取伺服器定期執行 checkpointing,將 FIFO 佇列儲存到磁碟
- 伺服器故障時可進行替換,同時 Extended Hashing 會將負載轉移到其他伺服器
資料分區(Data Partitioning)#
Crawler 處理三種資料:
- 待造訪的 URL
- URL checksum(用於 URL dedupe)
- Document checksum(用於 Document dedupe)
由於我們依據主機名稱分配 URL,因此這三種資料可以儲存在同一台主機上。每台主機儲存:
- 其負責的待造訪 URL
- 所有先前已造訪 URL 的 checksum
- 所有已下載文件的 checksum
使用 Extended Hashing 時,過載主機的 URL 會被重新分配。每台主機定期執行 checkpointing,將所有資料的快照寫入遠端伺服器。若伺服器故障,新伺服器可從最新快照取回資料進行替換。
Crawler Traps#
網路上存在許多 crawler trap、垃圾網站和隱藏內容。Crawler trap 是一組會導致 Crawler 無限爬取的 URL。
- 非故意的 trap:例如檔案系統中的符號連結(symbolic link)造成迴圈
- 故意的 trap:動態產生無限網頁文件的網站,目的可能是反垃圾郵件或提升搜尋排名
AOPIC 演算法#
AOPIC(Adaptive Online Page Importance Computation) 使用信用系統來緩解常見的 bot-trap 問題:
- 從 N 個 seed 頁面開始
- 爬取開始前,為每個頁面分配固定的 X 額度信用
- 選擇信用最高的頁面 P(若全部相同則隨機選擇)
- 爬取頁面 P(假設 P 有 100 credits)
- 從頁面 P 提取所有連結(假設有 10 個)
- 將 P 的信用設為 0
- 扣除 10% 的稅額,分配給 Lambda 頁面
- 將剩餘信用平均分配給 P 上找到的每個連結:
(100 - 10) / 10 = 9 credits/link - 從步驟 3 重複
為什麼 AOPIC 能有效對抗 bot-trap?
Lambda 頁面持續累積稅收,最終成為信用最高的頁面而被「爬取」。爬取 Lambda 頁面時,會將其信用平均分配給資料庫中所有頁面。
Bot-trap 頁面只有內部連結帶來的信用,很少從外部獲得信用,因此會不斷因稅收而流失信用給 Lambda 頁面。經過多次循環後,bot-trap 頁面的信用會低到幾乎不再被爬取。而正常頁面由於經常從其他頁面的反向連結獲得信用,不會受到此影響。