什麼是 Twitter Search#
Twitter 的使用者可以隨時更新自己的狀態(status),每則狀態由純文字組成。我們的目標是設計一個系統,讓使用者能夠搜尋所有已發佈的狀態訊息。
- 相似問題:Tweet Search
- 難度:中等
需求與系統目標#
- Twitter 共有 15 億總使用者,其中每日活躍使用者為 8 億
- 平均每天產生 4 億則狀態更新
- 每則狀態的平均大小為 300 bytes
- 預計每天約有 5 億次搜尋請求
- 搜尋查詢由多個單字組合,支援 AND/OR 邏輯
我們需要設計一個能夠高效儲存並查詢使用者狀態訊息的系統。
容量估算與限制#
儲存容量#
每天新增 4 億則狀態,每則平均 300 bytes:
400M * 300 = 112 GB/day每秒的儲存量:
112 GB / 86400 sec ≈ 1.3 MB/sec系統 API#
可以使用 SOAP 或 REST API 對外提供搜尋功能,以下為搜尋 API 的定義:
search(api_dev_key, search_terms, maximum_results_to_return, sort, page_token)參數說明#
| 參數 | 類型 | 說明 |
|---|---|---|
api_dev_key | string | 已註冊帳號的 API 開發者金鑰,可用於依據配額進行流量限制(throttle) |
search_terms | string | 包含搜尋關鍵字的字串 |
maximum_results_to_return | number | 要回傳的狀態訊息筆數 |
sort | number | 選填的排序模式:Latest first(0,預設)、Best matched(1)、Most liked(2) |
page_token | string | 指定要回傳的結果集頁面 |
回傳值#
回傳 JSON 格式,包含符合搜尋條件的狀態訊息列表。每筆結果可包含使用者 ID 與名稱、狀態文字、狀態 ID、建立時間、按讚數等資訊。
High Level Design#
在高層設計中,我們需要:
- 將所有狀態訊息儲存到資料庫
- 建立一個索引(index),追蹤每個單字出現在哪些狀態中
這個索引能幫助我們快速找到使用者想搜尋的狀態訊息。
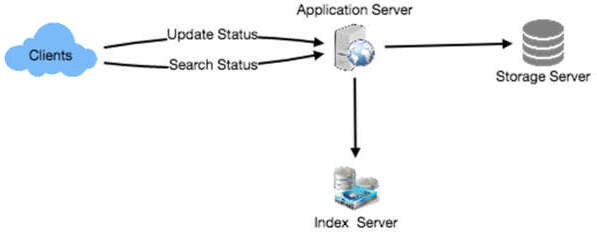
圖 20.1:簡易架構圖(Clients → Application Server → Storage Server + Index Server)
詳細元件設計#
儲存(Storage)#
每天需要儲存 112 GB 的新資料,因此需要一個**資料分區方案(data partitioning scheme)**來有效分散到多台伺服器。
五年的儲存規劃:
112 GB * 365 days * 5 years ≈ 200 TB- 若不希望使用率超過 80%,則需要 240 TB
- 加上一份容錯備份(fault tolerance copy),總需求為 480 TB
- 以每台伺服器 4 TB 計算,需要 120 台伺服器
資料庫設計:
- 使用 MySQL 資料庫,建立一張包含
StatusID與StatusText兩個欄位的表 - 根據
StatusID進行分區(partition) - 使用 hash function 將 StatusID 映射到對應的儲存伺服器
StatusID 的唯一性:
400M * 365 days * 5 years = 730 billion需要 5 bytes 的數字來唯一識別每個 StatusID。假設有一個服務能夠在需要時產生唯一的 StatusID,我們將 StatusID 傳給 hash function 來決定儲存位置。
索引(Index)#
索引需要記錄每個單字出現在哪些狀態訊息中。
索引大小估算:
- 約 300K 英文單字 + 200K 專有名詞 = 500K 個單字
- 平均單字長度 5 字元:
500K * 5 = 2.5 MB
StatusID 儲存需求(過去兩年的資料):
- 兩年內約有 292B 則狀態訊息
- 每個 StatusID 為 5 bytes:
292B * 5 = 1460 GB
索引的結構為一個大型的分散式雜湊表(distributed hash table):
- Key:單字
- Value:包含該單字的所有 StatusID 列表
假設每則狀態平均有 40 個單字,扣除介系詞等小詞後約需索引 15 個單字。因此每個 StatusID 會被儲存 15 次:
(1460 * 15) + 2.5 MB ≈ 21 TB以每台伺服器 144 GB 記憶體計算,需要 152 台伺服器。
分片策略#
資料可以基於兩種方式進行分片(sharding):
基於單字的分片(Sharding based on Words):
- 建立索引時,對每個單字計算 hash 值以決定儲存的伺服器
- 查詢時只需查詢持有該單字的伺服器
此方法有兩個問題:
- 熱門單字問題:某個單字如果變成熱門詞彙,持有該單字的伺服器會承受大量查詢,影響效能
- 分佈不均:隨時間推移,某些單字會累積大量 StatusID,難以維持均勻分佈
解決方案:重新分區(repartition) 或使用 Consistent Hashing。
基於狀態物件的分片(Sharding based on Status Object):
- 儲存時,將 StatusID 傳給 hash function 決定伺服器,在該伺服器上索引該狀態的所有單字
- 查詢時需要查詢所有伺服器,每台伺服器回傳一組 StatusID
- 由一個集中式伺服器(centralized server) 彙整結果後回傳給使用者
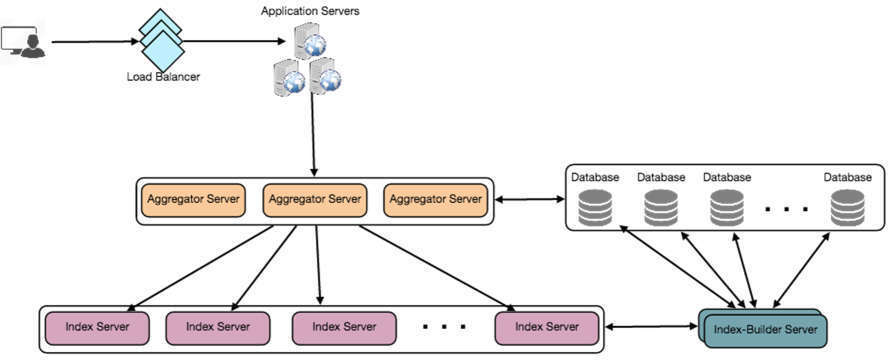
圖 20.2:詳細系統架構圖(Users → Load Balancer → Application Servers → Aggregator Servers → Index Servers,含 Index-Builder Server 從 Database 建立索引)
容錯(Fault Tolerance)#
索引伺服器故障時的處理:
- 為每台伺服器配置一個次要副本(secondary replica)
- 主伺服器故障時,由次要副本接管(failover)
- 主要與次要伺服器持有相同的索引副本
主要與次要伺服器同時故障:
- 需要分配新伺服器並重建索引
- 若使用「基於狀態物件的分片」,暴力解法是遍歷整個資料庫,用 hash function 過濾出該伺服器應儲存的 StatusID
- 此方法效率低且重建期間無法回應查詢
更好的解決方案:建立一個反向索引(reverse index),將所有 StatusID 映射到對應的索引伺服器。由 Index-Builder Server 維護一個 Hashtable:
- Key:索引伺服器編號
- Value:該伺服器上所有 StatusID 的 HashSet
當索引伺服器需要重建時,只需向 Index-Builder Server 請求其負責的所有狀態資料,即可快速重建索引。Index-Builder Server 也應配置副本以確保容錯。
快取(Cache)#
- 針對熱門狀態物件,在資料庫前方引入快取層
- 可使用 Memcache 將熱門狀態物件儲存在記憶體中
- Application Server 在查詢後端資料庫前,先檢查快取
- 可根據使用者的使用模式調整快取伺服器數量
- 快取淘汰策略:採用 LRU(Least Recently Used)
負載均衡(Load Balancing)#
可在系統的兩個位置加入 Load Balancer:
- Clients 與 Application Servers 之間
- Application Servers 與 Backend Servers 之間
初始策略:採用 Round Robin 方式,將傳入的請求均勻分配到後端伺服器。
- 優點:實作簡單、無額外負擔;當伺服器失效時,LB 會自動將其從輪替中移除
- 缺點:不考慮伺服器的實際負載,若某台伺服器過載或回應緩慢,仍會持續分配請求
更智慧的做法是部署能定期查詢後端伺服器負載的 Load Balancer,根據負載狀況動態調整流量分配。
排序(Ranking)#
若希望根據社交關係距離、熱門度、相關性等因素對搜尋結果進行排序:
- 排序演算法計算一個熱門度分數(popularity number)(例如根據按讚數),並將其儲存在索引中
- 每個分區在回傳結果前,先依據熱門度分數排序
- Aggregator Server 合併所有分區的結果,再依熱門度分數排序後,將排名最高的結果回傳給使用者