設計一個即時建議服務(Typeahead Suggestion),在使用者輸入搜尋文字時自動推薦相關詞彙。
- 類似服務:Auto-suggestions、Typeahead Search
- 難度:中等
什麼是 Typeahead Suggestion#
Typeahead Suggestion 讓使用者能搜尋已知且經常被搜尋的詞彙。當使用者在搜尋框中輸入文字時,系統會根據已輸入的字元預測查詢內容,並提供建議清單來協助完成查詢。
Typeahead Suggestion 的目的不是加速搜尋過程,而是引導使用者更好地組織搜尋查詢。
系統需求與目標#
功能性需求#
- 當使用者輸入查詢時,服務應建議以使用者輸入內容為開頭的前 10 個詞彙
非功能性需求#
- 建議應即時呈現,使用者應在 200ms 內看到建議結果
基本系統設計與演算法#
問題定義#
我們需要儲存大量字串,使使用者可以搜尋任何前綴(prefix)。例如,若資料庫包含 cap、cat、captain、capital,當使用者輸入 cap 時,系統應建議 cap、captain 和 capital。
由於需要以最低延遲處理大量查詢,我們需要將索引儲存在記憶體中的高效資料結構裡,而非依賴資料庫。
Trie 資料結構#
最適合的資料結構是 Trie(前綴樹),一種樹狀結構,用於儲存字串,每個節點依序儲存字串中的一個字元。
例如,若需儲存 cap、cat、caption、captain、capital,當使用者輸入 cap 時,服務可以遍歷 Trie 到節點 P,找到所有以此前綴開頭的詞彙(如 cap-tion、cap-ital 等)。
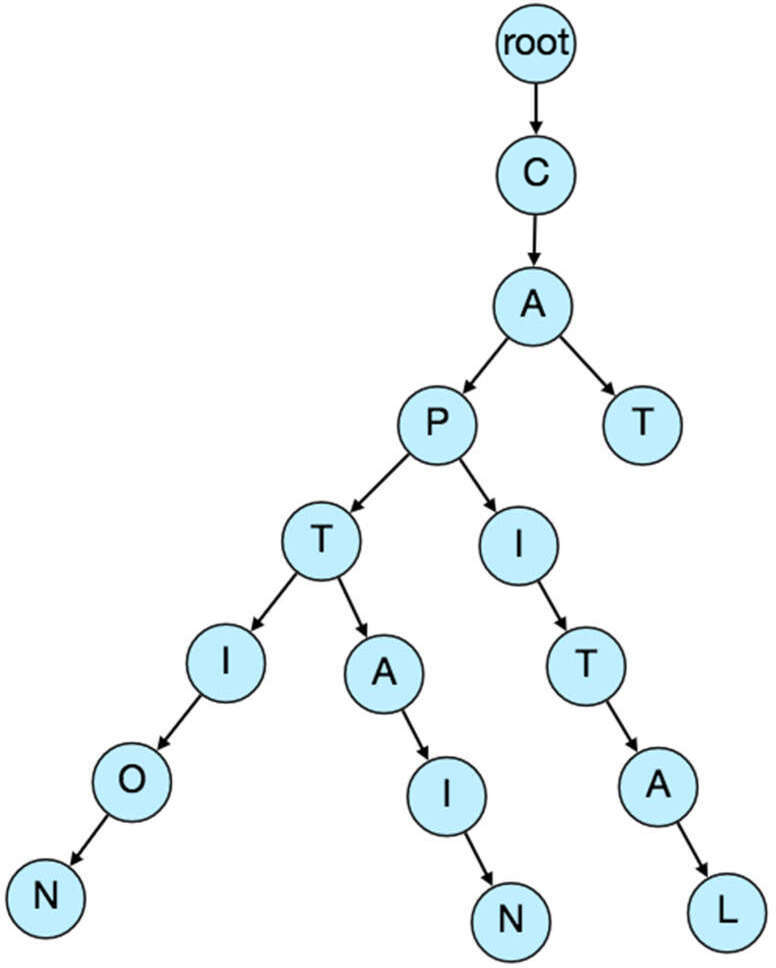
圖 19.1:基本 Trie 結構圖(字串前綴樹)
壓縮 Trie(Compressed Trie)#
我們可以合併只有單一分支的節點以節省儲存空間。
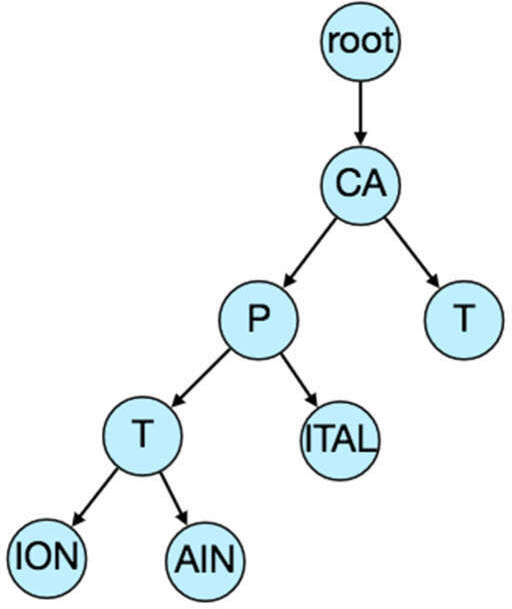
圖 19.2:壓縮 Trie(Radix Tree)結構圖
為簡化設計,假設資料為大小寫不敏感(case insensitive)。
如何找到最佳建議#
在每個節點儲存搜尋次數。例如,若 CAPTAIN 被搜尋了 100 次、CAPTION 被搜尋了 500 次,可將此計數儲存於詞彙最後一個字元的節點。當使用者輸入 CAP 時,就能知道前綴 CAP 下最常被搜尋的詞彙是 CAPTION。
遍歷效能問題#
考慮到索引的資料量,Trie 可能非常龐大。遍歷子樹可能耗時過長(例如 system design interview questions 有 30 層深度),無法滿足嚴格的延遲需求。
預存 Top 建議#
- 在每個節點儲存 Top 10 建議,可大幅加速搜尋,但需要額外儲存空間
- 可只儲存終端節點的參考(reference) 而非完整字串,以優化儲存
- 每個參考需附帶出現頻率以追蹤排名
如何建構 Trie#
可以由下而上(bottom-up) 高效建構 Trie:
- 每個父節點遞迴呼叫所有子節點計算其 Top 建議與計數
- 父節點合併所有子節點的 Top 建議來決定自身的 Top 建議
如何更新 Trie#
假設每天有 50 億次搜尋(約 60K QPS),若為每次查詢都更新 Trie,將極度耗費資源且影響讀取請求。
解決方案:離線更新,在特定間隔後更新 Trie。
- 記錄新查詢及其頻率(可採用取樣,如每 1000 次搜尋記錄一次)
- 使用 MapReduce 定期(如每小時)處理日誌資料,計算所有搜尋詞彙的頻率
- 取得 Trie 的當前快照,以新詞彙與頻率更新
更新策略(二擇一):
- 在每台伺服器上複製一份 Trie 進行離線更新,完成後切換使用新版本,丟棄舊版本
- 採用 Master-Slave 架構:更新 Slave,Master 繼續服務。更新完成後將 Slave 升為 Master,之後再更新舊 Master
如何更新建議頻率#
- 僅更新頻率的差值,而非重新計算所有搜尋詞彙
- 若追蹤最近 10 天的資料,需減去不再包含的時間段計數,並加入新時間段的計數
- 可使用 EMA(Exponential Moving Average,指數移動平均),給予最新資料更高權重
具體流程:
- 插入新詞彙後,前往終端節點並增加其頻率
- 從該節點往上遍歷到根節點
- 對每個父節點,檢查當前查詢是否在 Top 10 中
- 若在,更新對應頻率;若不在,檢查頻率是否高到足以進入 Top 10
- 若是,插入新詞彙並移除頻率最低的詞彙
如何從 Trie 移除詞彙#
因法律問題、仇恨言論或侵權等原因需移除特定詞彙時:
- 在定期更新時從 Trie 中完全移除
- 同時在每台伺服器上加入過濾層(filtering layer),在回傳建議前先過濾掉這些詞彙
其他排名標準#
除了簡單的搜尋次數外,排名還應考慮其他因素:
- 新鮮度(Freshness)
- 使用者地理位置
- 語言
- 人口統計資料
- 個人搜尋歷史
永久儲存 Trie#
如何將 Trie 儲存至檔案#
可定期對 Trie 進行快照(snapshot) 並儲存至檔案,以便在伺服器重啟時重建 Trie。
儲存方式:
- 從根節點開始,逐層儲存
- 每個節點記錄其包含的字元與子節點數量
- 每個節點之後緊跟其所有子節點
例如,Trie 可被序列化為:"C2,A2,R1,T,P,O1,D",從中可以輕鬆重建 Trie。
此儲存方式不包含 Top 建議與計數,因為 Trie 是由上而下儲存的,子節點尚未建立前無法儲存其參考。Top 建議需在建構 Trie 時重新計算:每個節點計算其 Top 建議並傳遞給父節點,父節點合併所有子節點的結果。
規模估算#
流量估算#
- 假設與 Google 同等規模,每天 50 億次搜尋,約 60K QPS
- 50 億次查詢中有大量重複,假設只有 20% 為唯一查詢
- 若只索引 Top 50% 的搜尋詞彙,可排除大量低頻查詢
- 假設有 1 億個唯一詞彙需要建立索引
儲存估算#
- 平均每個查詢包含 3 個單字,每個單字平均 5 個字元,即平均查詢長度為 15 個字元
- 每個字元需 2 bytes,平均查詢需 30 bytes
- 總儲存需求:
100M * 30 bytes ≈ 3 GB - 假設每天有 2% 的新查詢,且維護最近一年的索引
- 總儲存預估:
3 GB + (0.02 * 3 GB * 365) ≈ 25 GB
資料分區(Data Partition)#
雖然索引可以放在單一伺服器上,但為了更高效率與更低延遲,仍需進行分區。
基於範圍的分區(Range Based Partitioning)#
根據詞彙的首字母將資料存放在不同分區中(如所有 A 開頭的存一個分區,B 開頭的存另一個)。可將較少出現的字母合併到同一分區。
此方法可能導致伺服器負載不均。例如,以字母
E開頭的詞彙可能過多,無法放入單一分區。任何靜態定義的方案都無法預先計算每個分區是否能容納在單一伺服器上。
基於伺服器最大容量的分區#
根據伺服器的最大記憶體容量進行分區:
- 持續在伺服器上儲存資料直到記憶體用盡
- 當子樹無法放入一台伺服器時,在該處切分並分配給下一台伺服器
範例:
- Server 1:
A~AABC - Server 2:
AABD~BXA - Server 3:
BXB~CDA
當使用者輸入 A 時需查詢 Server 1 和 2;輸入 AAA 時只需查詢 Server 1。
可在 Trie 伺服器前設置 Load Balancer 儲存此對應關係並導向流量。若從多台伺服器查詢,需要一個 Aggregator 層來彙總結果並回傳 Top 結果給客戶端。
基於最大容量的分區仍可能產生熱點(hotspot),例如大量查詢以
cap開頭時,持有該範圍的伺服器負載會較高。
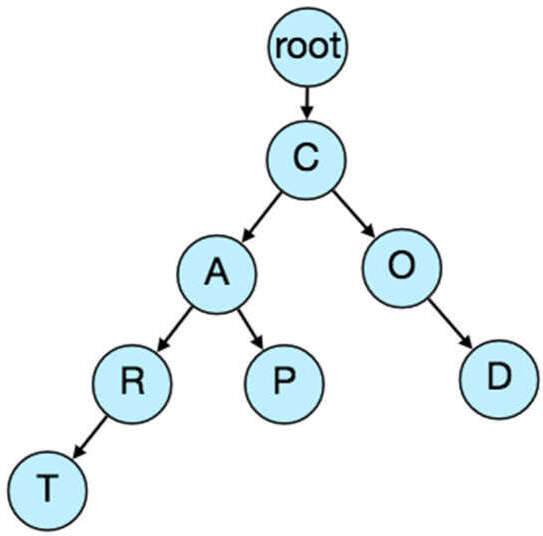
圖 19.3:資料分區 Trie 圖(展示分區概念)
基於詞彙 Hash 的分區#
- 每個詞彙經過 Hash Function 產生伺服器編號,儲存於該伺服器
- 使詞彙分佈隨機化,最小化熱點
- 查詢 Typeahead 建議時需詢問所有伺服器再彙總結果
- 使用 Consistent Hashing 實現容錯與負載分佈
快取(Cache)#
- 快取最常被搜尋的詞彙對服務非常有幫助,少數查詢佔了大部分流量
- 在 Trie 伺服器前設置獨立快取伺服器,儲存最常搜尋的詞彙及其 Typeahead 建議
- Application Server 在存取 Trie 伺服器前,先檢查快取伺服器
可建構簡單的 ML 模型,根據計數、個人化或趨勢資料等預測每個建議的參與度,並快取這些詞彙。
複製與負載平衡(Replication and Load Balancer)#
- Trie 伺服器應有副本(Replica),用於負載平衡與容錯
- 需要一個 Load Balancer 追蹤資料分區方案,並根據前綴導向流量
容錯(Fault Tolerance)#
當 Trie 伺服器故障時:
- 可使用 Master-Slave 架構,Master 故障時由 Slave 透過 Failover 接管
- 恢復的伺服器可根據最後的快照重建 Trie
Typeahead 客戶端最佳化#
可在客戶端進行以下最佳化以提升使用者體驗:
- 使用者停止輸入 50ms 後才向伺服器發送請求
- 使用者持續輸入時,客戶端可取消進行中的請求
- 初始階段可等待使用者輸入幾個字元後再發送請求
- 客戶端可從伺服器預先擷取(pre-fetch) 部分資料以減少未來請求
- 客戶端可在本地儲存最近的建議歷史記錄,這些紀錄有很高的重複使用率
- 使用者開啟搜尋引擎網站時,客戶端可立即建立與伺服器的連線,避免輸入第一個字元時才開始建立連線
- 伺服器可將部分快取推送至 CDN 和 ISP 以提升效率
個人化(Personalization)#
- 使用者會根據其搜尋歷史、地理位置、語言等收到個人化的 Typeahead 建議
- 每位使用者的個人歷史記錄可獨立儲存於伺服器上,並快取於客戶端
- 伺服器在回傳建議前,將個人化詞彙加入最終結果集
- 個人化搜尋建議應排在其他建議之前