什麼是 Twitter#
Twitter 是一個線上社群網路服務,使用者可以發佈和閱讀 140 字元的短訊息(稱為「tweets」)。已註冊的使用者可以發佈和閱讀推文,未註冊使用者只能閱讀。使用者透過網頁介面、SMS 或行動 App 存取 Twitter。
需求與目標#
功能性需求#
- 使用者可以發佈新推文
- 使用者可以追蹤其他使用者
- 使用者可以將推文標記為最愛(favorite)
- 系統能建立並顯示使用者的 Timeline,包含所追蹤使用者的熱門推文
- 推文可以包含照片和影片
非功能性需求#
- 高可用性:系統需要高度可用
- 低延遲:Timeline 產生的可接受延遲為 200ms
- 最終一致性:為了可用性可以犧牲一致性——使用者暫時看不到某則推文是可以接受的
延伸需求#
- 搜尋推文
- 回覆推文
- 熱門話題(Trending Topics)
- 標記其他使用者
- 推文通知
- 推薦追蹤對象
- Moments
容量估算與限制#
假設總使用者數為 10 億,每日活躍使用者(DAU)為 2 億,每天有 1 億則新推文,平均每位使用者追蹤 200 人。
每日互動量#
- 每日收藏數:
2 億使用者 * 5 次收藏 = 10 億次/天 - 每日推文瀏覽數:假設每位使用者每天瀏覽 Timeline 2 次、瀏覽 5 個其他人的頁面,每頁顯示 20 則推文
2 億 * (2 + 5) * 20 = 280 億次/天
儲存估算#
- 每則推文 140 字元,每個字元 2 bytes,加上 30 bytes metadata
- 每日文字儲存:
1 億 * (280 + 30) bytes = 30 GB/天 - 假設每 5 則推文有 1 張照片(200 KB),每 10 則有 1 部影片(2 MB)
- 每日媒體儲存:
(1 億/5 * 200 KB) + (1 億/10 * 2 MB) ≈ 24 TB/天
頻寬估算#
- 傳入:每日 24 TB,換算為 290 MB/s
- 傳出(考慮 280 億次推文瀏覽):
- 文字:
(280 億 * 280 bytes) / 86400s ≈ 93 MB/s - 照片:
(280 億/5 * 200 KB) / 86400s ≈ 13 GB/s - 影片(假設使用者觀看每 3 部中的 1 部):
(280 億/10/3 * 2 MB) / 86400s ≈ 22 GB/s - 總傳出頻寬 ≈ 35 GB/s
- 文字:
系統 API#
在確定需求後,定義系統 API 是很好的做法,能明確說明系統預期提供的功能。
可以使用 SOAP 或 REST API 來公開服務功能。發佈推文的 API 定義如下:
tweet(api_dev_key, tweet_data, tweet_location, user_location, media_ids, maximum_results_to_return)參數說明:
- api_dev_key(string):API 開發者金鑰,用於配額限制(throttling)
- tweet_data(string):推文文字內容,最多 140 字元
- tweet_location(string):選填,推文相關的地理位置(經度、緯度)
- user_location(string):選填,發佈推文的使用者位置
- media_ids(number[]):選填,與推文關聯的媒體 ID 列表(照片、影片等需單獨上傳)
回傳值:成功時回傳該推文的存取 URL;失敗時回傳對應的 HTTP 錯誤碼。
高層級系統設計#
系統需要高效儲存所有新推文並支援大量讀取:
- 寫入負載:
1 億 / 86400s ≈ 1,150 推文/秒 - 讀取負載:
280 億 / 86400s ≈ 325K 推文/秒
這是一個**讀取密集型(read-heavy)**系統。流量在一天中分佈不均,尖峰時段寫入可能達到數千筆/秒,讀取可能達到 100 萬筆/秒。
在高層級架構中,需要:
- 多台 Application Server 處理請求
- Load Balancer 進行流量分配
- 高效的資料庫儲存推文並支援大量讀取
- File Storage 儲存照片和影片
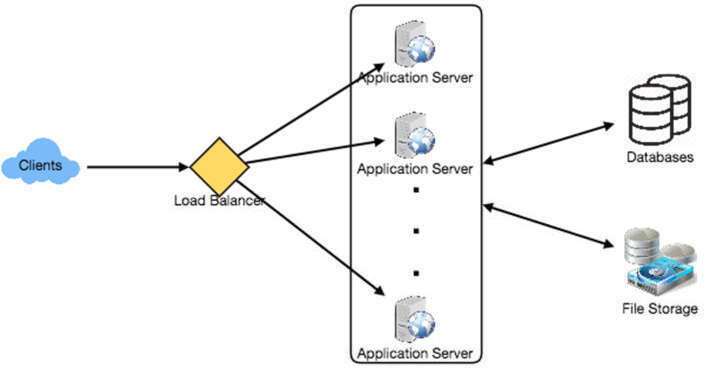
圖 17.1:高層級架構圖(Clients → Load Balancer → Application Servers → Databases + File Storage)
資料庫 Schema#
需要儲存以下資料:使用者資訊、推文、收藏的推文、以及追蹤關係。
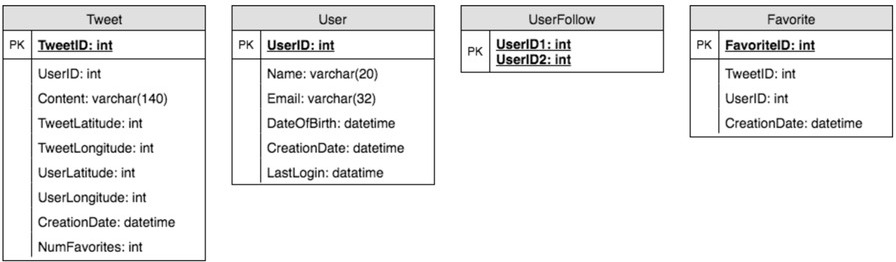
圖 17.2:資料庫 Schema(Tweet, User, UserFollow, Favorite 四張表)
關於 SQL 與 NoSQL 資料庫的選擇,可以參考 Designing Instagram 章節中的「Database Schema」討論。
資料分片#
每天有大量新推文且讀取負載極高,需要將資料分散到多台機器上。
基於 UserID 的分片#
將同一使用者的所有資料存放在一台伺服器上。透過 Hash 函式將 UserID 對應到資料庫伺服器,儲存該使用者的推文、收藏、追蹤等資料。
存在的問題:
- 熱門使用者:某位使用者成為熱點時,持有其資料的伺服器會承受大量查詢,影響效能
- 資料不均勻:部分使用者的推文或追蹤數量遠超其他人,難以維持均勻分佈
要從上述問題中恢復,需要進行資料重新分區/重新分配,或使用 Consistent Hashing。
基於 TweetID 的分片#
Hash 函式將每個 TweetID 對應到隨機伺服器。搜尋推文時需要查詢所有伺服器,由集中式伺服器彙整結果。
Timeline 產生的步驟:
- Application Server 找出使用者追蹤的所有人
- 向所有資料庫伺服器查詢這些人的推文
- 每台資料庫伺服器找出推文,依時間排序並回傳最新推文
- Application Server 合併所有結果,再次排序後回傳給使用者
此方案解決了熱門使用者的問題,但需要查詢所有分區,可能導致較高延遲。可以在資料庫前方引入 Cache 來改善效能。
基於推文建立時間的分片#
按時間儲存推文可以快速擷取最新推文,只需查詢極少數伺服器。但問題是流量分佈不均——所有新推文都寫入同一台伺服器,其餘伺服器閒置;讀取時,持有最新資料的伺服器負載過高。
結合 TweetID 與建立時間#
若不單獨儲存建立時間,而是將時間資訊編碼到 TweetID 中,就能兼得兩種方案的優點。
設計方式:TweetID 由兩部分組成:
- 前半部分:Epoch 秒數
- 後半部分:自動遞增序號
計算所需位元數:
- 未來 50 年的秒數:
86400 * 365 * 50 ≈ 16 億,需要 31 bits - 平均每秒 1,150 則新推文,分配 17 bits 給自動遞增序號(每秒可儲存 2^17 = 130K 則推文)
- TweetID 總長度:48 bits

圖 17.3:TweetID 位元結構圖(48-bit ID = 31 bits epoch seconds + 17 bits auto incrementing sequence)
範例(假設當前 epoch 秒數為 1483228800):
1483228800 000001
1483228800 000002
1483228800 000003
1483228800 000004
...為了容錯與效能,可以使用兩台資料庫伺服器產生自動遞增 Key——一台產生偶數、另一台產生奇數。若將 TweetID 擴展為 64 bits(8 bytes),可以輕鬆儲存未來 100 年的推文,且支援毫秒級精度。
快取#
在資料庫伺服器前方引入快取,儲存熱門推文和使用者資料。可以使用 Memcached 之類的現成方案來快取完整的推文物件。
快取淘汰策略#
當快取已滿時,使用 **LRU(Least Recently Used)**策略——淘汰最久未被瀏覽的推文。
智慧快取策略#
根據 80-20 法則,20% 的推文產生 80% 的讀取流量,因此可以嘗試快取每個 Shard 每日讀取量的 20%。
快取最新資料#
假設 80% 的使用者只瀏覽最近三天的推文:
- 每天約 1 億則新推文 / 30 GB(不含媒體)
- 三天的推文約需 不到 100 GB 的記憶體
- 可以輕鬆放入一台伺服器,但應複製到多台伺服器以分散讀取流量
快取結構為 Hash Table:
- Key:OwnerID
- Value:雙向連結串列(Doubly Linked List),包含該使用者過去三天的所有推文
- 新推文插入串列頭部,舊推文從尾部移除以騰出空間
Timeline 產生#
關於 Timeline 產生的詳細討論,請參閱 Designing Facebook’s Newsfeed 章節。
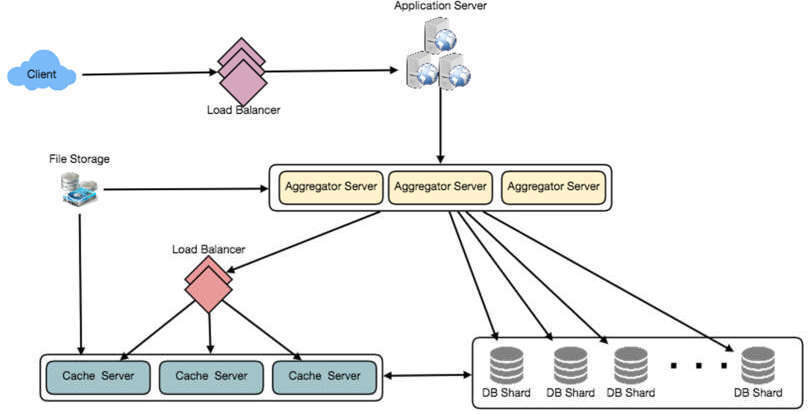
圖 17.4:詳細系統架構圖(含 Aggregator Server、Cache Server、DB Shard 等)
副本與容錯#
由於系統是讀取密集型的,每個 DB 分區可以設置多台 Secondary Database Server 專門處理讀取流量。所有寫入先到 Primary Server,再複製到 Secondary Server。當 Primary Server 故障時,可以**容錯切換(failover)**到 Secondary Server。
負載平衡#
可以在系統的三個層級加入 Load Balancer:
- 客戶端與 Application Server 之間
- Application Server 與資料庫副本伺服器之間
- Aggregation Server 與 Cache Server 之間
初期可採用 Round Robin 方式——將請求平均分配到各伺服器。此方法簡單且無額外開銷,且能自動將故障伺服器從輪替中移除。
Round Robin 不考慮伺服器負載。若某台伺服器過載或變慢,Load Balancer 仍會繼續傳送請求。更智慧的解決方案是定期查詢後端伺服器的負載狀況,並據此調整流量分配。
監控#
持續收集資料以即時掌握系統狀況至關重要。應監控以下指標:
- 每日/每秒新推文數,以及每日尖峰值
- Timeline 送達統計:系統每日/每秒送達多少推文
- 使用者重新整理 Timeline 的平均延遲
透過監控這些指標,可以判斷是否需要更多的副本、負載平衡或快取。
延伸需求#
動態牆(Feed)產生#
- 取得使用者追蹤的所有人的最新推文,按時間合併排序
- 使用**分頁(pagination)**來擷取和顯示推文
- 只從追蹤對象中擷取 Top N 則推文(N 取決於客戶端視窗大小——行動端顯示較少)
- 可以預先快取下一頁的推文以加速載入
- 也可以預先產生動態牆來提升效率
轉推(Retweet)#
在資料庫的 Tweet 物件中儲存原始推文的 ID,轉推物件本身不儲存內容。
熱門話題(Trending Topics)#
- 快取最近 N 秒內出現最頻繁的 Hashtag 或搜尋查詢
- 每 M 秒更新一次
- 根據推文頻率、搜尋次數、轉推數、按讚數進行排名
- 對曝光度更高的話題給予更大權重
推薦追蹤對象#
- 推薦使用者追蹤的人的朋友(可深入二到三層)
- 優先推薦追蹤者較多的使用者
- 使用 Machine Learning 進行排序與重新優先化,ML 信號包括:最近追蹤數增長的使用者、共同追蹤者、共同地點或興趣等
Moments#
- 從不同網站取得過去 1-2 小時的熱門新聞
- 找出相關推文並排序
- 使用 ML(監督式學習或分群)進行分類(新聞、客服、金融、娛樂等)
- 將這些文章呈現為 Moments 中的熱門話題
搜尋#
搜尋涉及索引(Indexing)、排名(Ranking)和擷取(Retrieval)。類似的解決方案在 Design Twitter Search 章節中有討論。