設計一個類似 Dropbox 或 Google Drive 的檔案託管服務。雲端檔案儲存讓使用者可以將資料存放在遠端伺服器上,這些伺服器通常由雲端儲存供應商維護,並透過網路(通常是網際網路)提供給使用者。
- 類似服務:OneDrive、Google Drive
- 難度:中等
為什麼需要雲端儲存#
雲端檔案儲存服務近年來非常普及,因為它大幅簡化了在多裝置間儲存和交換數位資源的過程。從使用單一個人電腦轉變為使用多種裝置(智慧型手機、平板)與不同平台,加上隨時隨地的可攜式存取需求,是推動雲端儲存服務廣受歡迎的主因。
雲端儲存的核心優勢#
- 可用性(Availability) — 隨時隨地在任何裝置存取檔案和照片
- 可靠性與耐久性(Reliability & Durability) — 透過在不同地理位置的伺服器保存多份副本,確保使用者永遠不會遺失資料
- 可擴展性(Scalability) — 使用者不需擔心儲存空間不足,只要願意付費,就有無限儲存空間
如果你尚未使用過 Dropbox,建議先建立帳號、上傳/編輯檔案,並瀏覽其服務選項。這將有助於更好地理解本章內容。
系統需求與目標#
在面試初期務必釐清需求,並提問以確定面試官心中的系統範圍。
功能性需求#
- 使用者可以從任何裝置上傳和下載檔案/照片
- 使用者可以與其他人分享檔案或資料夾
- 服務需支援裝置間的自動同步 — 在一台裝置上更新檔案後,所有裝置都要同步
- 系統需支援儲存最大 1GB 的大型檔案
- 所有檔案操作需保證 ACID 特性(Atomicity、Consistency、Isolation、Durability)
- 系統需支援離線編輯 — 使用者可以在離線時新增/刪除/修改檔案,上線後自動同步至遠端伺服器及其他裝置
延伸需求#
- 支援資料快照(Snapshotting),讓使用者可以回到任何歷史版本
設計考量#
- 預期會有大量的讀寫流量
- 讀寫比例預期大致相等
- 檔案可以在內部拆分為小區塊(Chunk),例如 4MB,帶來以下好處:
- 失敗操作只需重試較小的區塊
- 只傳輸被修改的區塊,減少資料交換量
- 移除重複區塊可節省儲存空間和頻寬
- 在客戶端保存本地 metadata 副本(檔名、大小等),可減少與伺服器的往返次數
- 對於小幅修改,客戶端可以智慧地只上傳 diff 而非整個區塊
容量估算與限制#
- 總使用者數:5 億,每日活躍使用者(DAU):1 億
- 平均每位使用者從 3 台不同裝置連線
- 平均每位使用者有 200 個檔案/照片 → 總計 1000 億個檔案
- 平均檔案大小:100KB → 總儲存量:
100B * 100KB = 10PB - 每分鐘約 100 萬個活躍連線
High Level Design#
使用者在裝置上指定一個資料夾作為工作區(Workspace),放入此資料夾的任何檔案/照片/子資料夾都會上傳至雲端。檔案被修改或刪除時,雲端儲存也會同步反映。使用者可以在所有裝置上設定相似的工作區,任何一台裝置上的修改都會傳播到所有其他裝置。
在高層設計上,我們需要:
- Block Server — 協助客戶端上傳/下載檔案到雲端儲存
- Metadata Server — 在 SQL 或 NoSQL 資料庫中維護檔案的 metadata
- Synchronization Server — 處理通知所有客戶端各種變更以進行同步的工作流程
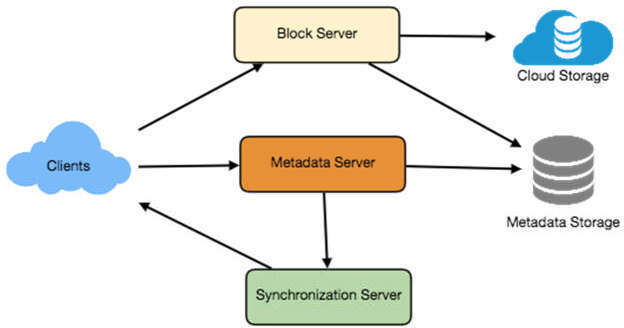
圖 15.1:高層級架構圖
Component Design#
Client#
Client Application 監控使用者機器上的工作區資料夾,並與遠端雲端儲存同步所有檔案/資料夾。
Client 的主要操作:
- 上傳和下載檔案
- 偵測工作區資料夾中的檔案變更
- 處理衝突 — 離線或並行更新時的衝突處理
高效檔案傳輸#
將每個檔案拆分為固定大小(如 4MB)的區塊,只傳輸被修改的區塊。最佳區塊大小可根據以下因素計算:
- 雲端儲存裝置的空間利用率與 IOPS
- 網路頻寬
- 儲存中的平均檔案大小
在 metadata 中需要記錄每個檔案及其組成的區塊。
客戶端保存 Metadata 副本#
在客戶端保存本地 metadata 副本,不僅可以支援離線更新,還能節省大量遠端 metadata 更新的往返次數。
客戶端如何偵測其他客戶端的變更#
- 輪詢方式的問題:變更反映延遲、大部分請求會得到空回應、浪費頻寬、不具擴展性
- HTTP Long Polling:客戶端發出請求後,伺服器若無新資料則保持連線開啟,直到有新資訊可用時才回傳。客戶端收到回應後立即發出下一個請求
客戶端的四大元件#
I. Internal Metadata Database — 追蹤所有檔案、區塊、版本及其在檔案系統中的位置
II. Chunker — 將檔案拆分為較小的區塊(Chunk),也負責從區塊重建檔案。Chunking 演算法會偵測被使用者修改的部分,只傳輸那些部分,以節省頻寬和同步時間
III. Watcher — 監控本地工作區資料夾,通知 Indexer 使用者執行的任何操作(建立、刪除、更新)。也監聽 Synchronization Service 廣播的其他客戶端變更
IV. Indexer — 處理來自 Watcher 的事件,更新 Internal Metadata Database 中的區塊資訊。區塊成功提交/下載後,與遠端 Synchronization Service 溝通以廣播變更並更新遠端 metadata
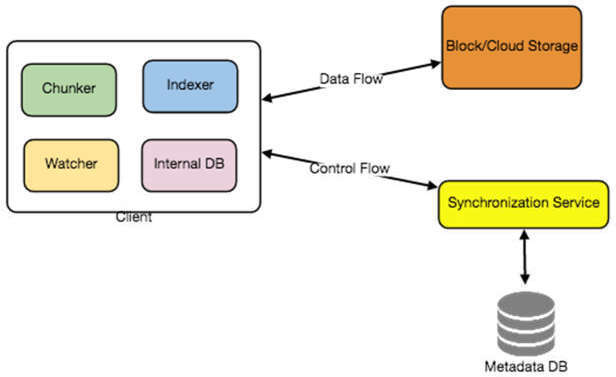
圖 15.2:Client 元件架構圖
客戶端設計補充#
- 慢速伺服器處理 — 客戶端應使用指數退避(Exponential Back-off),當伺服器忙碌/無回應時,逐步增加重試延遲
- 行動裝置同步 — 不同於桌面或網頁客戶端會定期檢查變更,行動客戶端通常按需同步以節省頻寬和空間
Metadata Database#
Metadata Database 負責維護檔案/區塊的版本資訊、metadata、使用者資訊和工作區資訊。
- 可以是 RDBMS(如 MySQL)或 NoSQL(如 DynamoDB)
- Synchronization Service 需要提供一致性的檔案檢視,尤其是多位使用者同時操作同一檔案時
- NoSQL 不原生支援 ACID,若選用則需在 Synchronization Service 的邏輯中程式化實作 ACID 支援
- RDBMS 原生支援 ACID,可簡化 Synchronization Service 的實作
Metadata Database 儲存的物件:
- Chunks(區塊)
- Files(檔案)
- User(使用者)
- Devices(裝置)
- Workspace(同步資料夾)
Synchronization Service#
Synchronization Service 是系統架構中最重要的元件,負責:
- 處理客戶端的檔案更新,並將變更套用到其他已訂閱的客戶端
- 將客戶端的本地資料庫與遠端 Metadata DB 同步
- 若客戶端曾離線,上線後立即向系統輪詢新的更新
- 收到更新請求時,先與 Metadata Database 進行一致性檢查,再執行更新
- 更新完成後,通知所有已訂閱的使用者或裝置
減少資料傳輸的策略:
- 使用 Differencing Algorithm,只傳輸兩個版本之間的差異
- 將檔案分為 4MB 區塊,只傳輸被修改的區塊
- 伺服器與客戶端可計算 Hash(如 SHA-256) 來判斷是否需要更新本地副本
- 若伺服器已有相同 Hash 的區塊(即使來自其他使用者),無需建立另一份副本(詳見後續 Data Deduplication)
通訊中介層(Communication Middleware):
- 在客戶端與 Synchronization Service 之間使用訊息中介層
- 提供可擴展的訊息佇列和變更通知
- 支援 Pull 或 Push 策略
- 多個 Synchronization Service 實例可從全域 Request Queue 接收請求,中介層負責負載平衡
Message Queuing Service#
Message Queuing Service 支援客戶端與 Synchronization Service 實例之間的非同步、鬆耦合通訊,能在高可用、可靠且可擴展的佇列中高效儲存大量訊息。
系統中有兩種佇列:
- Request Queue(全域佇列) — 所有客戶端共用,客戶端更新 Metadata Database 的請求會先送到此佇列,再由 Synchronization Service 處理
- Response Queue(個別佇列) — 每個已訂閱的客戶端各有一個,負責傳遞更新訊息。由於訊息在客戶端接收後會從佇列中刪除,因此需要為每個客戶端建立獨立的 Response Queue
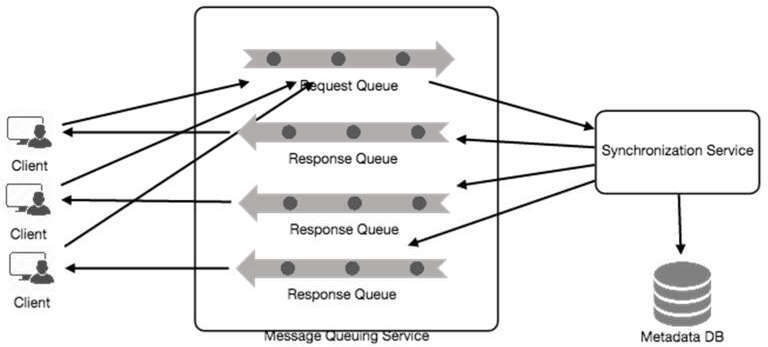
圖 15.3:訊息佇列架構圖
Cloud/Block Storage#
Cloud/Block Storage 儲存使用者上傳的檔案區塊。客戶端直接與儲存互動以發送和接收物件。將 metadata 與儲存分離,讓我們可以使用任何儲存方案 — 無論是雲端還是自建。
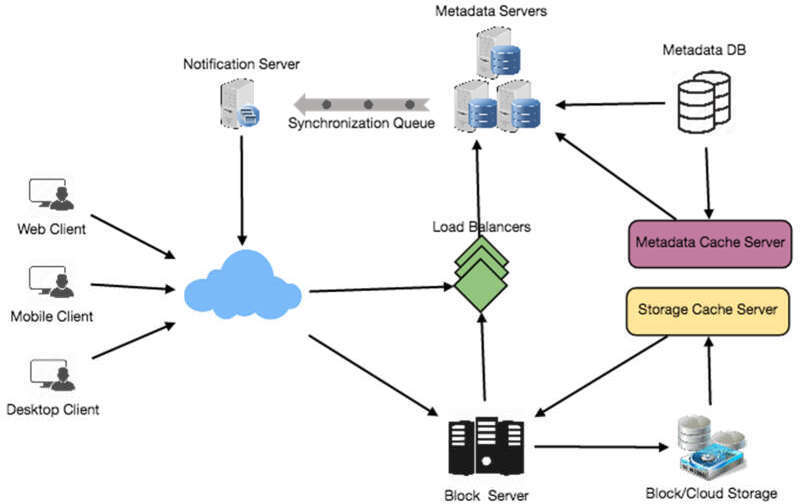
圖 15.4:完整系統架構圖
File Processing Workflow#
以下流程描述 Client A 更新一個與 Client B 和 C 共享的檔案時的互動:
- Client A 將區塊上傳至 Cloud Storage
- Client A 更新 metadata 並提交變更
- Client A 收到確認,並向 Client B 和 C 發送變更通知
- Client B 和 C 接收 metadata 變更並下載更新後的區塊
如果其他客戶端在更新時不在線上,Message Queuing Service 會將更新通知保存在各自的 Response Queue 中,直到它們稍後上線。
Data Deduplication#
Data Deduplication 是一種消除重複資料副本的技術,用於提升儲存利用率,也可應用於網路傳輸以減少傳輸的位元組數。對於每個新進的區塊,可以計算其 Hash 並與所有現有區塊的 Hash 比對,以判斷是否已存在相同的區塊。
Post-process Deduplication#
新區塊先儲存到儲存裝置,之後由獨立的程序分析資料並尋找重複。
- 優點:客戶端無需等待 Hash 計算或查詢完成,不影響儲存效能
- 缺點:
- 暫時會儲存重複資料
- 重複資料的傳輸會消耗頻寬
In-line Deduplication#
在客戶端輸入資料時即時進行 Hash 計算。若系統識別出已存在的區塊,只會在 metadata 中新增對現有區塊的參考,而非完整副本。
- 優點:達到最佳的網路和儲存使用率
Metadata Partitioning#
為了擴展 Metadata DB 以儲存數百萬使用者和數十億檔案/區塊的資訊,需要進行分區。
Vertical Partitioning#
將與特定功能相關的表格儲存在同一台伺服器上。例如,使用者相關表格在一台資料庫,檔案/區塊相關表格在另一台。
- 問題:
- 若有數兆個區塊需要儲存,單一資料庫可能無法承受
- 跨資料庫 JOIN 可能導致效能和一致性問題
Range Based Partitioning#
根據檔案路徑的首字母儲存到不同分區(如所有 ‘A’ 開頭的檔案在一個分區)。可以將出現頻率較低的字母合併到同一個分區。
- 問題:可能導致伺服器負載不均。例如以 ‘E’ 開頭的檔案可能過多,單一分區無法容納。
Hash-Based Partitioning#
對儲存物件(如 FileID)取 Hash,根據 Hash 值決定存放的分區。Hash 函數會將 ID 隨機映射到 [1...256] 之間的某個分區。
- 問題:仍可能出現過載分區,可透過 Consistent Hashing 解決。
Caching#
系統中可以有兩種快取:
Block Storage 快取#
- 使用 Memcache 等現成方案快取熱門檔案/區塊
- Block Server 在存取 Block Storage 前先檢查快取
- 高階商用伺服器可有 144GB 記憶體,可快取約 36K 個區塊
快取淘汰策略#
- LRU(Least Recently Used)— 當快取滿時,優先淘汰最久未使用的區塊
Metadata DB 快取#
同樣可以為 Metadata DB 建立快取層。
Load Balancer#
可以在系統的兩個位置加入 Load Balancer:
- 客戶端與 Block Server 之間
- 客戶端與 Metadata Server 之間
初期可以採用 Round Robin 方式,將請求均勻分配到後端伺服器:
- 優點:實作簡單、無額外開銷;若伺服器故障,LB 會自動將其移出輪替
- 缺點:不考慮伺服器負載 — 即使伺服器過載或緩慢,仍會繼續分配請求
更智慧的做法:LB 定期查詢後端伺服器的負載狀況,根據負載動態調整流量分配。
Security, Permissions and File Sharing#
使用者在雲端儲存檔案時,最關注的是隱私和安全性。在我們的系統中,使用者可以將檔案分享給其他人,甚至公開分享。
為此,我們在 Metadata DB 中儲存每個檔案的權限資訊,以反映哪些檔案對哪些使用者是可見或可修改的。