設計一個類似 Instagram 的照片分享服務,讓使用者可以上傳照片並分享給其他人。
- 類似服務:Flickr、Picasa
- 難度:中等
為什麼要設計 Instagram#
Instagram 是一個社群網路服務,使用者可以上傳、分享照片和影片。分享可以是公開或私人的,也可以同步到 Facebook、Twitter、Flickr、Tumblr 等平台。
在本設計中,我們聚焦於一個簡化版的 Instagram:
- 使用者可以分享照片
- 使用者可以追蹤其他使用者
- 每位使用者的 Timeline 由其追蹤對象的熱門照片組成
系統需求與目標#
功能性需求(Functional Requirements)#
- 使用者可以上傳、下載、檢視照片
- 使用者可以根據照片/影片標題進行搜尋
- 使用者可以追蹤其他使用者
- 系統能產生並顯示使用者的 Timeline,包含所追蹤對象的熱門照片
非功能性需求(Non-functional Requirements)#
- 系統需要高可用性(High Availability)
- Timeline 產生的可接受延遲為 200ms
- 為了可用性,一致性可以妥協 — 使用者短時間內看不到某張照片是可以接受的
- 系統需要高可靠性 — 上傳的照片/影片絕不能遺失
不在範圍內#
為照片加標籤、以標籤搜尋、留言、標記使用者、推薦追蹤等功能。
設計考量#
本系統屬於讀取密集型(Read-heavy),因此設計重點在於快速取回照片。
- 使用者可以上傳大量照片,儲存空間管理至關重要
- 讀取圖片時需要低延遲
- 資料需要 100% 可靠,上傳的圖片絕不能遺失
容量估算與限制#
- 總使用者數:3 億,每日活躍使用者:100 萬
- 每天新增 200 萬張照片,約每秒 23 張
- 平均照片大小:200KB
- 每日所需空間:
2M * 200KB = 400GB - 五年所需空間:
400GB * 365 * 5 ≈ 712TB
High Level Design#
在高層設計上,我們需要支援兩個主要場景:
- 上傳照片
- 檢視/搜尋照片
系統需要 Block Storage 伺服器來儲存照片,以及資料庫伺服器來儲存照片的 metadata。
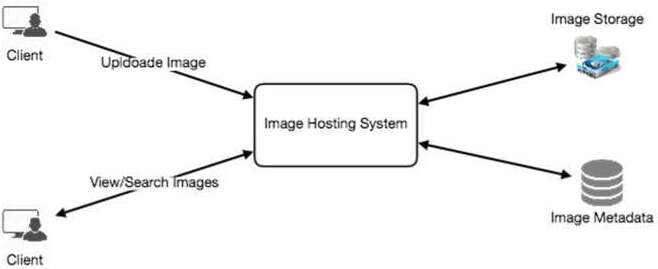
圖 14.1:基本系統架構圖
Database Schema#
在面試早期定義 DB Schema,有助於理解各元件之間的資料流向,並為後續的資料分割(Data Partitioning)提供指引。
我們需要儲存以下資料:
- 使用者資料(Users)
- 上傳的照片資料(Photos)
- 追蹤關係(UserFollow)
Photo 表需要在 (PhotoID, CreationDate) 上建立索引,以便優先取回最新照片。

圖 14.2:資料庫 Schema(Photo 表 + User 表 + UserFollow 表)
儲存方案選擇#
- RDBMS(如 MySQL):支援 JOIN 操作,但在大規模擴展時面臨挑戰(詳見 SQL vs. NoSQL)
- 照片檔案:可儲存於分散式檔案系統,如 HDFS 或 S3
- NoSQL(Key-Value Store):Photo metadata 以
PhotoID為 key,value 為包含 PhotoLocation、UserLocation、CreationTimestamp 等欄位的物件 - Wide-Column Store(如 Cassandra):
UserPhoto表:key 為UserID,value 為該使用者擁有的PhotoID列表UserFollow表:類似結構,記錄追蹤關係
Cassandra 等 Key-Value Store 會維護一定數量的副本以確保可靠性。刪除操作不會立即生效,資料會保留數天(支援反刪除)後才被永久移除。
Component Design#
讀寫分離的必要性#
- 寫入(上傳照片) 較慢,因為需要寫入磁碟
- 讀取 較快,尤其是從快取提供服務時
如果上傳操作佔滿所有連線,讀取請求就無法被處理。假設一台 Web Server 最多支援 500 個同時連線,這意味著上傳和讀取會互相競爭連線資源。
解決方案:將讀取和寫入拆分為獨立的服務,使上傳不會拖累整個系統。這也讓我們可以獨立擴展和最佳化讀取與寫入。
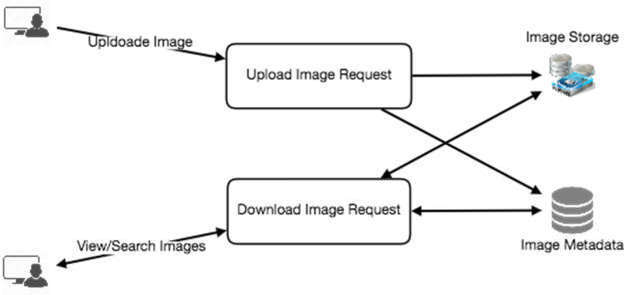
圖 14.3:上傳/下載分離架構圖
Reliability and Redundancy#
遺失檔案在本服務中是不可接受的。因此,我們會儲存每個檔案的多份副本,當一台儲存伺服器故障時,可以從另一台取回圖片。
同樣的原則適用於系統的其他元件:
- 運行多個服務副本,即使部分服務故障,系統仍可正常運作
- 冗餘機制可以消除單點故障(Single Point of Failure)
- 如果某服務只需一個實例運行,可以維護一個備用副本,在主服務故障時透過 Failover 接管
Failover 可以是自動的或需要人工介入的。冗餘設計在危機時提供備援功能。
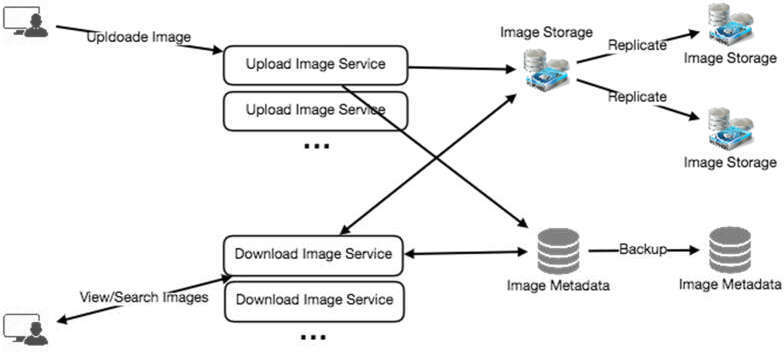
圖 14.4:可靠性與冗餘架構圖
Data Sharding#
方案 A:基於 UserID 分片#
- 假設以
UserID分片,同一使用者的所有照片存放在同一個 Shard - 若每個 DB Shard 為 4TB,則
712TB / 4TB = 178個 Shard,預留成長空間取 200 個 Shard - 分片公式:
UserID % 200 - PhotoID 生成:每個 Shard 可使用自己的 auto-increment 序列,加上 ShardID 前綴即可全域唯一
此方案的問題:
- 熱門使用者問題 — 被大量追蹤的使用者,其照片會產生不成比例的流量
- 儲存不均 — 部分使用者照片數量遠多於其他人
- 單一 Shard 容量限制 — 若無法將某使用者所有照片存於同一 Shard,分散儲存可能導致高延遲
- 可用性風險 — 若該 Shard 故障,該使用者的所有資料都會無法存取
方案 B:基於 PhotoID 分片#
- 先生成全域唯一的
PhotoID,再以PhotoID % 200決定 Shard - 不需要附加 ShardID,因為 PhotoID 本身即為全域唯一
PhotoID 生成方式:
- 使用一個專用資料庫實例來生成 auto-increment ID
- 定義一張僅含 64-bit ID 欄位的表格
如何避免單點故障:
- 使用兩台 Key-Generating Server
- Server 1:產生奇數 ID(
auto-increment-offset = 1) - Server 2:產生偶數 ID(
auto-increment-offset = 2) - 兩者的
auto-increment-increment = 2
- Server 1:產生奇數 ID(
- 前方放置 Load Balancer,以 Round Robin 方式分配請求
也可以採用類似 TinyURL 設計中討論的 Key Generation Scheme。
規劃未來成長#
- 建立大量的邏輯分區(Logical Partition),初期多個邏輯分區可共用同一台實體資料庫伺服器
- 當某台伺服器資料量過大時,可將部分邏輯分區遷移到其他伺服器
- 維護一個 Config 檔案(或獨立資料庫)來映射邏輯分區與實體伺服器的關係,遷移時只需更新此配置
Ranking and Timeline Generation#
Timeline 產生流程#
為任意使用者產生 Timeline 時,需要取得其追蹤對象中最新、最熱門、最相關的照片。
簡化假設:取每位使用者 Timeline 中的 Top 100 張照片。
- Application Server 取得使用者追蹤的人員列表
- 從每位追蹤對象取得最新 100 張照片的 metadata
- 將所有照片送入 Ranking 演算法,根據時效性、喜好度等指標選出 Top 100
潛在問題:需要查詢多張表並進行排序/合併/排名,延遲較高。
Pre-generating Timeline#
- 使用專用伺服器持續產生使用者的 Timeline,並儲存於
UserTimeline表 - 使用者需要最新照片時,直接查詢此表即可
- 伺服器在產生 Timeline 時,先檢查上次產生時間,再從該時間點之後生成新資料
資料推送方式#
- Pull 模式 — 客戶端定期或手動向伺服器拉取
- 缺點:新資料可能延遲顯示;大多數請求可能得到空回應
- Push 模式 — 伺服器在有新資料時主動推送,客戶端透過 Long Poll 維持連線
- 缺點:若使用者追蹤大量對象,或名人有數百萬粉絲,伺服器需頻繁推送
- Hybrid 模式 — 結合兩者
- 高追蹤量的使用者改用 Pull 模式
- 低追蹤量的使用者維持 Push 模式
- 或設定推送頻率上限,讓高追蹤量的使用者自行拉取
關於 Timeline 生成的詳細討論,請參考 Designing Facebook’s Newsfeed 章節。
Timeline Creation with Sharded Data#
將建立時間編入 PhotoID#
為了從所有追蹤對象中高效取得最新照片,可以將照片建立時間編入 PhotoID。由於 PhotoID 為主索引,查詢最新的 PhotoID 會非常快速。
PhotoID 結構#
- 前半部分:Epoch 秒數
- 後半部分:Auto-increment 序列
取得新 PhotoID 時,以當前 Epoch 時間加上 Key-Generating DB 的 auto-increment ID,再以 PhotoID % 200 決定 Shard。
PhotoID 大小估算#
- 未來 50 年的秒數:
86400 * 365 * 50 ≈ 16 億秒 - 需要 31 bits 儲存秒數
- 平均每秒 23 張新照片,分配 9 bits 給 auto-increment 序列(每秒最多
2^9 = 512張) - Auto-increment 序列每秒重置
更多關於此技術的細節,請參考 Designing Twitter 的 Data Sharding 章節。
Cache and Load Balancing#
CDN 與全球分發#
為了服務全球使用者,系統需要大規模的照片傳遞基礎設施:
- 使用大量地理分散的快取伺服器
- 利用 CDN 將內容推近使用者端
Metadata 快取#
- 為 Metadata Server 引入快取,快取熱門資料庫列
- 使用 Memcache 儲存快取資料
- Application Server 在查詢資料庫前先檢查快取
- 快取淘汰策略:LRU(Least Recently Used)— 優先淘汰最久未被檢視的資料列
更智慧的快取策略#
根據 80-20 法則:每日 20% 的照片讀取量產生 80% 的流量。因此可以嘗試快取每日 20% 的照片讀取量及其 metadata。