為什麼需要 URL 縮短服務#
URL 縮短服務為長網址建立較短的別名(Alias)。當使用者存取這些短網址時,會被重導向到原始網址。短網址在以下場景中特別有用:
- 節省空間:在列印、推文(有字數限制)等場合大幅縮減 URL 長度
- 連結追蹤:跨裝置最佳化連結,分析受眾與活動成效
- 隱藏原始 URL:隱藏聯盟行銷等附屬連結
例如,透過 TinyURL 縮短一個教學頁面的網址,縮短後的 URL 大約只有原始 URL 的 三分之一 大小。
如果你尚未使用過 tinyurl.com,建議先試著建立一個短網址,並瀏覽其提供的各種選項,這有助於更深入理解本章內容。
需求與目標#
在面試開始時務必釐清需求,並提問以確定面試官心中的系統範圍。
功能性需求(Functional Requirements)#
- 給定一個 URL,服務應產生一個較短且唯一的別名
- 當使用者存取短網址時,服務應將其重導向到原始連結
- 使用者可選擇為其 URL 指定自訂別名(Custom Alias)
- 連結在指定時間後自動過期;使用者也可自行設定過期時間
非功能性需求(Non-Functional Requirements)#
- 高可用性(High Availability):服務停機將導致所有 URL 重導向失敗
- 低延遲:URL 重導向應即時發生,延遲最小化
- 不可預測性:縮短後的連結不應被猜測或預測
擴展需求(Extended Requirements)#
- 分析功能:統計重導向發生了多少次
- 服務應可透過 REST API 供其他服務存取
容量估算與限制#
系統屬於讀取密集型(Read-heavy),重導向請求遠多於新 URL 縮短請求。假設讀寫比為 100:1。
流量估算#
- 假設每月 5 億 次新 URL 縮短
- 每月重導向次數:100 x 5 億 = 500 億
每秒查詢數(QPS):
- 新 URL 縮短:
500M / (30 * 24 * 3600) ≈ 200 URLs/s - URL 重導向:
50B / (30 * 24 * 3600) ≈ 19K/s
儲存估算#
- 每月 5 億筆新 URL,保留 5 年
- 總物件數:
500M * 5 * 12 = 300 億 - 假設每筆物件約 500 bytes
- 總儲存量:
300 億 * 500 bytes = 15 TB
頻寬估算#
- 寫入:
200 * 500 bytes = 100 KB/s - 讀取:
19K * 500 bytes ≈ 9 MB/s
記憶體估算(快取)#
依照 80-20 法則(20% 的 URL 產生 80% 的流量),快取這 20% 的熱門 URL:
- 每日請求數:
19K * 3600 * 24 ≈ 17 億 - 快取 20%:
0.2 * 17 億 * 500 bytes ≈ 170 GB
高層級估算總覽#
| 指標 | 數值 |
|---|---|
| 新 URL 縮短 | 200/s |
| URL 重導向 | 19K/s |
| 傳入資料 | 100 KB/s |
| 傳出資料 | 9 MB/s |
| 5 年儲存量 | 15 TB |
| 快取記憶體 | 170 GB |
系統 API#
確定需求後,定義系統 API 是個好做法,能明確表述系統的預期行為。
可使用 SOAP 或 REST API 來公開服務功能。以下為建立和刪除 URL 的 API 定義:
createURL#
createURL(api_dev_key, original_url, custom_alias=None, user_name=None, expire_date=None)參數:
- api_dev_key(string):已註冊帳號的 API 開發者金鑰,可用於依配額限流(Throttle)使用者
- original_url(string):要縮短的原始 URL
- custom_alias(string):選填,URL 的自訂短碼
- user_name(string):選填,用於編碼的使用者名稱
- expire_date(string):選填,短網址的過期日期
回傳值: 成功插入時回傳縮短後的 URL,否則回傳錯誤碼。
deleteURL#
deleteURL(api_dev_key, url_key)- url_key(string):代表要刪除的短網址
- 成功刪除時回傳
URL Removed
如何偵測與防止濫用#
任何服務都可能透過消耗所有 key 來癱瘓系統。解決方式是透過 api_dev_key 限制每個使用者在特定時間內可建立或存取的 URL 數量。
資料庫設計#
在面試初期定義 DB Schema,有助於理解資料在各元件之間的流動方式,並為後續的資料分區提供指引。
資料特性觀察#
- 需要儲存數十億筆記錄
- 每筆物件很小(小於 1K)
- 記錄之間無關聯(除了追蹤哪個使用者建立了哪個 URL)
- 系統為讀取密集型
Database Schema#
需要兩張表:一張儲存 URL 對應資訊,一張儲存使用者資料。

圖 13.1:資料庫 Schema(URL 表 + User 表,含欄位定義)
資料庫選擇#
由於需要儲存數十億筆記錄且物件間不需要關聯,NoSQL 鍵值儲存(如 DynamoDB 或 Cassandra)是更好的選擇,且更易於擴展。
若選擇 NoSQL,則無法在 URL 表中儲存 UserID(因 NoSQL 無外鍵概念),需要額外的第三張表來儲存 URL 與使用者的對應關係。
基本系統設計與演算法#
核心問題是為給定的 URL 產生一個簡短且唯一的 key。例如 http://tinyurl.com/jlg8zpc 中,最後六個字元就是要產生的短碼。以下探討兩種方案。
方案 a:編碼實際 URL(Encoding Actual URL)#
可對給定 URL 計算唯一雜湊(如 MD5 或 SHA256),再進行編碼以供顯示。編碼方式可以是:
- Base36:
[a-z, 0-9] - Base62:
[A-Z, a-z, 0-9] - Base64:加上
-和.
短碼長度分析:
- 6 字元(Base64):
64^6 ≈ 687 億種可能字串 - 8 字元(Base64):
64^8 ≈ 281 兆種可能字串
以 687 億個唯一字串來看,6 個字元的 key 足以滿足需求。
若使用 MD5 演算法,會產生 128 位元的雜湊值。Base64 編碼後字串超過 20 個字元,因此可取前 6(或 8)個字元作為 key。這可能導致 key 重複,此時可選用編碼字串中的其他字元,或交換部分字元。
此方案的問題:
- 相同 URL 產生相同短碼:多個使用者輸入相同 URL 時會得到相同的短網址,這不可接受
- URL 編碼問題:
http://www.example.com/page?id=design和http://www.example.com/page%3Fid%3Ddesign實際上是同一個 URL,但會產生不同雜湊
解決方法:
- 在每個輸入 URL 後附加遞增序號以確保唯一性,再計算雜湊。但序號可能溢位,且會影響效能
- 附加 User ID(本身唯一)到輸入 URL。若使用者未登入,可要求選擇一個唯一性金鑰。若仍有衝突,則持續產生新 key 直到唯一為止
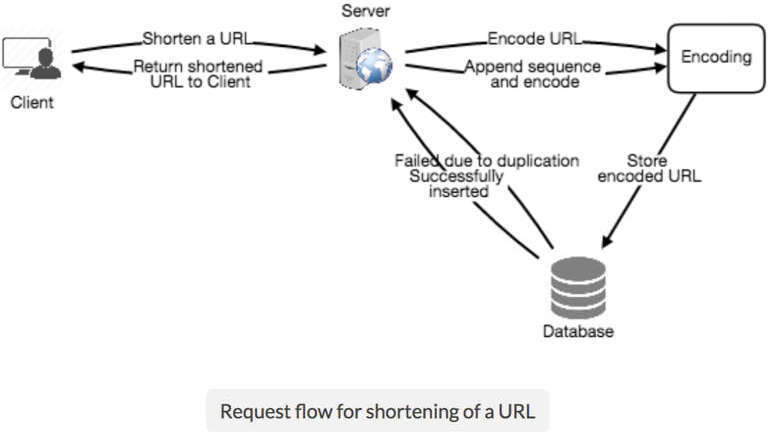
圖 13.2:URL 縮短請求流程圖
方案 b:離線產生 Key(Generating Keys Offline)#
可建立獨立的 Key Generation Service(KGS),預先產生隨機六字元字串並存入資料庫(key-DB)。每次需要縮短 URL 時,直接取用已產生的 key。此方案大幅簡化流程,因為不需要即時編碼 URL 或擔心重複和碰撞問題。KGS 確保插入 key-DB 的所有 key 都是唯一的。
並行(Concurrency)問題處理:
- 一旦 key 被使用,應立即在資料庫中標記,避免重複使用
- KGS 可使用兩張表:一張存未使用的 key,一張存已使用的 key
- KGS 將 key 發給伺服器後,立即移至已使用表
- KGS 可在記憶體中保留一批 key,以便快速提供
- 發放 key 前必須加鎖(synchronize)以避免多台伺服器取得相同 key
key-DB 大小估算:
- Base64 編碼可產生 687 億個唯一六字元 key
- 每個字元 1 byte:
6 * 687 億 ≈ 412 GB
KGS 是否為單點故障?
- 是的。解決方式是建立 KGS 的備援副本(Standby Replica),主伺服器故障時由備援接手
App Server 能否快取部分 key?
- 可以,這能加速處理。即使 App Server 在消耗完所有 key 前故障而損失部分 key,考量到 687 億個可用 key,這是可接受的
如何執行 key 查詢?
- 在資料庫或鍵值儲存中查找 key 以取得完整 URL
- 若存在:回傳 HTTP 302 Redirect,並在
Location欄位中傳回儲存的 URL - 若不存在:回傳 HTTP 404 Not Found,或將使用者重導向至首頁
自訂別名的長度限制:
- 為維持一致的 URL 資料庫,應對自訂別名施加長度限制
- 假設使用者最多可指定 16 個字元的自訂 key
高層級系統設計#
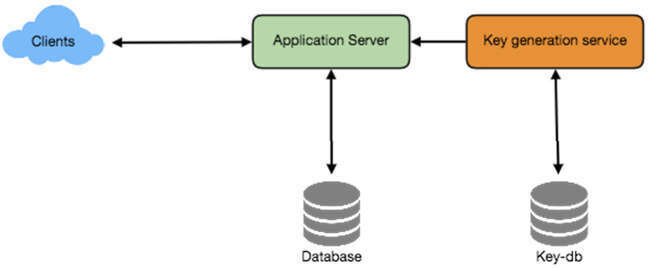
圖 13.3:高層級系統架構圖
資料分區與複製(Data Partitioning and Replication)#
為了擴展資料庫以儲存數十億筆 URL,需要進行分區,將資料分散儲存到不同的 DB 伺服器。
Range Based Partitioning(基於範圍的分區)#
根據 URL 或 Hash Key 的首字母將 URL 存入不同分區。例如所有以字母 ‘A’ 開頭的 URL 存在一個分區,以 ‘B’ 開頭的存在另一個分區。也可將出現頻率較低的字母合併到同一分區。
此方案的主要問題是可能導致伺服器不平衡。例如以字母 ‘E’ 開頭的 URL 過多,超出單一分區的容量。
Hash-Based Partitioning(基於雜湊的分區)#
對儲存物件取雜湊值,根據雜湊結果決定應存入哪個 DB 分區。例如雜湊函式可將任何 key 對應到 [1…256] 之間的數字,該數字即代表目標分區。
此方案仍可能導致分區過載,可透過 Consistent Hashing 解決。
快取(Cache)#
可快取頻繁存取的 URL。使用現成方案如 Memcached,儲存完整 URL 及其對應的雜湊值。Application Server 在存取後端儲存之前,先檢查快取中是否已有目標 URL。
快取容量#
- 從每日流量的 20% 開始,再依據使用者使用模式調整
- 如前估算,快取 20% 的每日流量需要 170 GB 記憶體
- 現代伺服器可配備 256 GB 記憶體,單台機器即可容納所有快取,或使用幾台較小的伺服器
快取淘汰策略#
採用 LRU(Least Recently Used) 策略:當快取已滿時,淘汰最久未被存取的 URL。可使用 Linked Hash Map 或類似資料結構來儲存 URL 和雜湊值,同時追蹤最近存取的 URL。
為進一步提升效率,可複製快取伺服器以分散負載。
快取副本更新機制#
- 每當發生 Cache Miss 時,伺服器會查詢後端資料庫
- 此時可更新快取,並將新項目傳遞給所有快取副本
- 每個副本收到新項目後加入快取;若已存在該項目,則忽略
負載均衡器(Load Balancer)#
可在系統中的三個位置加入 Load Balancer:
- Client 與 Application Server 之間
- Application Server 與 Database Server 之間
- Application Server 與 Cache Server 之間
初始可採用簡單的 Round Robin 方式,將傳入請求平均分配到後端伺服器。此方式實作簡單且不引入額外負擔。若伺服器故障,LB 會將其從輪替中移除,不再發送流量。
Round Robin 的缺點是不考慮伺服器負載。若伺服器過載或回應緩慢,LB 仍會持續發送新請求。可部署更智慧的 LB 方案,定期查詢後端伺服器的負載狀況並據此調整流量分配。
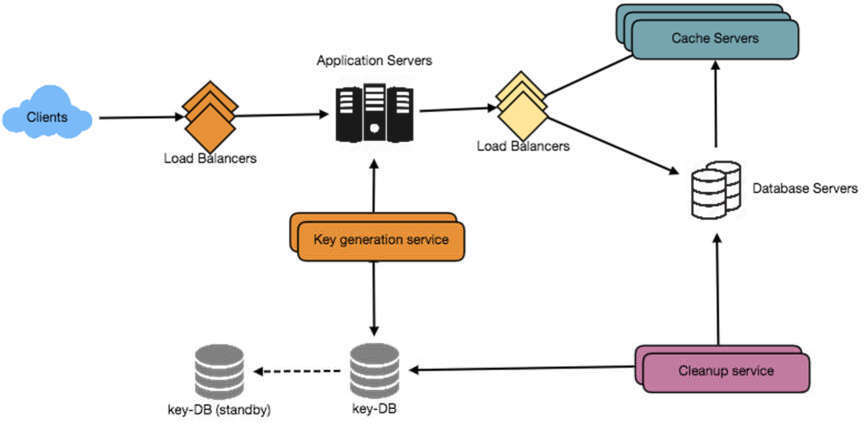
圖 13.5:完整系統架構圖
清除與資料庫清理(Purging or DB Cleanup)#
資料項目是否應永久保留?當使用者指定的過期時間到達時,連結應如何處理?主動搜尋過期連結並移除會對資料庫造成很大壓力。可採用惰性清理(Lazy Cleanup)策略:
- 使用者存取時清理:當使用者嘗試存取過期連結時,刪除該連結並回傳錯誤
- 定期清理服務:獨立的 Cleanup Service 定期執行,從儲存和快取中移除過期連結。此服務應非常輕量,排程在使用者流量預期較低時執行
- 預設過期時間:每個連結設定預設過期時間,例如兩年
- 回收 key:移除過期連結後,將 key 放回 key-DB 供重新使用
- 長期未存取的連結:是否應移除例如六個月未被存取的連結?由於儲存成本持續降低,可考慮永久保留
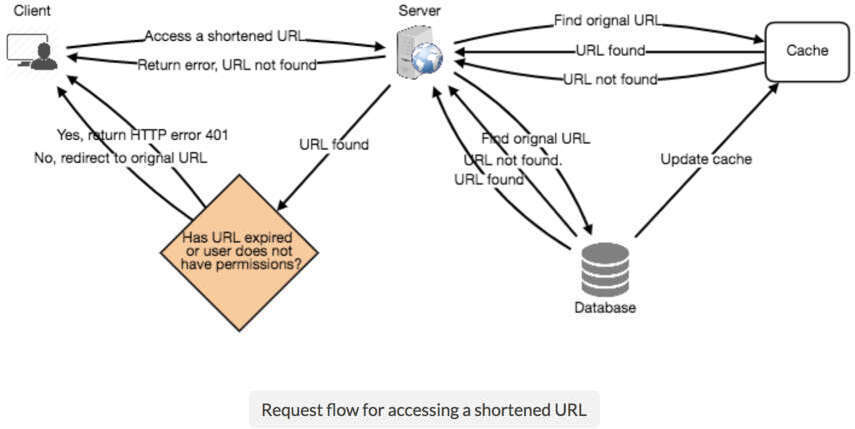
圖 13.4:URL 存取/重導向請求流程圖
遙測(Telemetry)#
短網址被使用了多少次?使用者的地理位置為何?如何儲存這些統計資料?
若統計資料是 DB 中每次瀏覽都會更新的欄位,當熱門 URL 遭受大量並行請求時,會造成效能問題。
可收集的統計資料包括:
- 訪客國家
- 存取日期和時間
- 來源網頁(Referrer)
- 瀏覽器或平台
安全性與權限(Security and Permissions)#
使用者能否建立私有 URL,或只允許特定使用者存取某個 URL?
- 可在資料庫中為每個 URL 儲存權限層級(public/private)
- 可建立獨立的表格儲存有權存取特定 URL 的 UserID
- 若使用者無權限卻嘗試存取 URL,回傳 HTTP 401 錯誤
若使用 NoSQL 寬列資料庫(如 Cassandra),權限表的 key 為 Hash(或 KGS 產生的 key),欄位則儲存有權存取該 URL 的 UserID。