本章涵蓋三個系統設計模式:布隆過濾器(Bloom Filter)、一致性雜湊(Consistent Hashing) 與 梅克爾樹(Merkle Tree)。
布隆過濾器(Bloom Filter)#
背景#
如果我們有大量結構化資料儲存在資料檔案中,最有效率的方式來判斷哪個檔案可能包含我們需要的資料是什麼?在索引檔案上進行二元搜尋(Binary Search) 是一種選擇。但我們能做得更好嗎?
定義#
使用布隆過濾器(Bloom Filter) 來快速判斷一個元素是否可能存在於集合中。
解決方案#
布隆過濾器能告訴我們一個元素可能在集合中,或者絕對不在集合中。唯一可能發生的錯誤是偽陽性(False Positive)。
一個空的布隆過濾器是一個由 m 個位元(bit) 組成的位元陣列(bit-array),所有位元初始值皆為 0。另外需要 k 個不同的雜湊函式(hash function),每個雜湊函式將元素映射到 m 個位元位置中的其中一個。
運作方式如下:
- 新增元素:將元素餵入 k 個雜湊函式,取得 k 個位元位置,將這些位置的位元設為 1。
- 測試元素:將元素餵入 k 個雜湊函式,取得 k 個位元位置。如果任何一個位元為 0,則該元素絕對不在集合中。如果所有位元皆為 1,則該元素可能在集合中。
flowchart TD
Start([開始]) --> Op{操作類型?}
Op -->|新增元素(Insert)| H1[將元素輸入 k 個雜湊函式\nHash Functions]
H1 --> Set[取得 k 個位元位置]
Set --> Write[將對應位元設為 1]
Write --> Done1([新增完成])
Op -->|查詢元素(Lookup)| H2[將元素輸入 k 個雜湊函式\nHash Functions]
H2 --> Check[檢查 k 個位元位置]
Check --> AllOne{所有位元\n皆為 1?}
AllOne -->|是| Maybe([可能在集合中\nPossibly In Set])
AllOne -->|否,任一位元為 0| No([絕對不在集合中\nDefinitely Not In Set])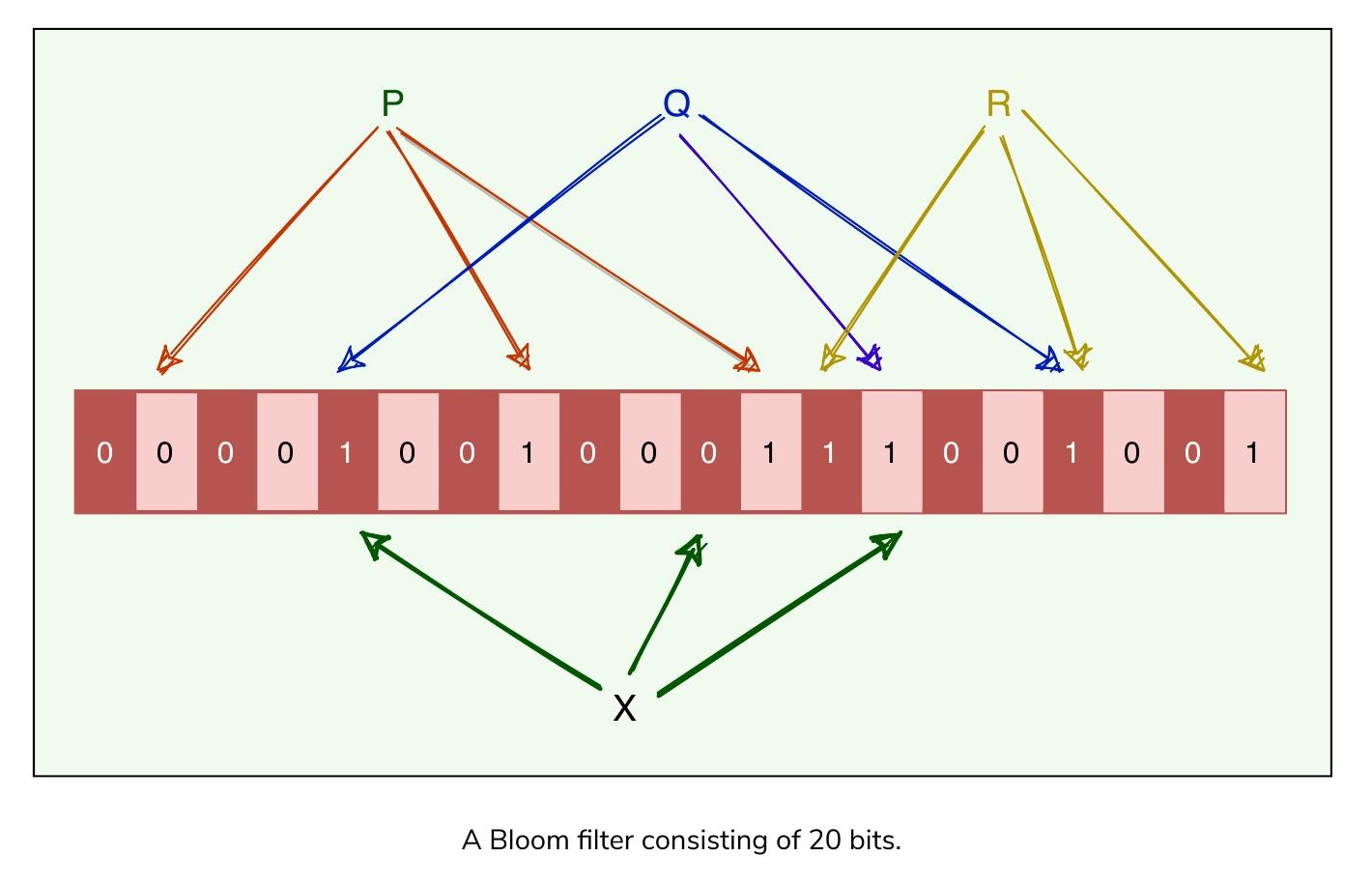
由 20 個位元組成的布隆過濾器
在固定的錯誤率下,新增和測試操作的時間複雜度為常數時間(constant time)。一個能容納 n 個元素的布隆過濾器需要 O(n) 的空間。
實際應用#
BigTable 和 Cassandra 使用布隆過濾器來減少對 SSTable 的磁碟存取次數。布隆過濾器能預測某個 SSTable 是否可能包含特定列(row)與欄(column)配對的資料,從而避免不必要的磁碟讀取。
一致性雜湊(Consistent Hashing)#
背景#
資料分區(Data Partitioning) 是將資料分散到多個節點上的技術。這帶來兩個挑戰:
- 如何知道哪個節點儲存了某筆資料?
- 當新增或移除節點時,如何最小化資料搬移量?
最簡單的方法是使用 hash(key) % total_servers,但問題在於當伺服器數量變化時,所有的鍵(key)都需要重新映射,這在大規模系統中代價非常高昂。
定義#
使用一致性雜湊(Consistent Hashing) 來分散資料。它將資料映射到實體節點,並確保在伺服器新增或移除時,只有少量的鍵需要搬移。
解決方案#
資料儲存在一個環(ring) 結構中。每個節點被分配一個範圍,令牌(token) 是範圍的起始點。範圍根據令牌值來分配。使用 MD5 雜湊 來決定資料屬於哪個範圍和節點。
當節點被新增或移除時,只有下一個節點受到影響,大幅減少了資料搬移的需求。
虛擬節點(Virtual Nodes / Vnodes)#
固定令牌分配方式存在以下問題:
- 重新平衡代價昂貴
- 容易產生熱點(hotspot)
- 節點重建壓力大
取而代之的是,將雜湊範圍劃分為多個較小的子範圍,每個實體節點被分配到數個虛擬節點(Vnode)。這些虛擬節點是隨機分布且不連續的。
虛擬節點的優勢:
- 更均勻的負載分配,重新平衡速度更快
- 更容易管理異質機器(heterogeneous machines),效能較強的機器可以分配更多虛擬節點
- 降低熱點發生的機率
實際應用#
Dynamo 和 Cassandra 使用一致性雜湊來實現資料分區與複製。
梅克爾樹(Merkle Tree)#
背景#
在分散式系統中,資料通常會有多個副本(replica)。我們需要一種方式來快速比較兩份副本,精確找出哪些部分不同。如果將整個範圍拆分後逐一比較校驗和(checksum),會傳輸過多的資料。
定義#
一個副本可能包含大量資料。使用梅克爾樹(Merkle Tree) 可以有效率地比較範圍的副本。
解決方案#
梅克爾樹是一棵雜湊的二元樹(binary tree of hashes),其中:
- 每個葉節點(leaf node) 是原始資料某個部分的雜湊值
- 每個內部節點(internal node) 是其兩個子節點的雜湊值
比較兩棵梅克爾樹的方式非常簡單:
- 比較兩棵樹的根雜湊值(root hash)
- 如果相等,表示兩份副本一致,停止比較
- 如果不相等,遞迴比較左子樹和右子樹
flowchart TD
Start([開始比較兩棵梅克爾樹]) --> CompRoot{比較根雜湊值\nRoot Hash}
CompRoot -->|相等| Same([兩份副本一致\n無需同步])
CompRoot -->|不相等| CompChild{遞迴比較\n左右子節點雜湊值}
CompChild -->|左子樹雜湊不同| GoLeft[繼續比較左子樹\nLeft Subtree]
CompChild -->|右子樹雜湊不同| GoRight[繼續比較右子樹\nRight Subtree]
CompChild -->|兩者皆不同| GoBoth[同時比較兩棵子樹]
GoLeft --> IsLeafL{是否為葉節點\nLeaf Node?}
GoRight --> IsLeafR{是否為葉節點\nLeaf Node?}
GoBoth --> IsLeafL
GoBoth --> IsLeafR
IsLeafL -->|是| FoundL[找到差異的資料範圍]
IsLeafL -->|否| CompChild
IsLeafR -->|是| FoundR[找到差異的資料範圍]
IsLeafR -->|否| CompChild
FoundL --> Sync[僅同步差異的資料範圍\nMinimal Data Transfer]
FoundR --> Sync
Sync --> Done([同步完成])透過這種方式,副本可以精確知道哪些部分不同,最小化同步所需傳輸的資料量,同時也減少了磁碟讀取次數。
梅克爾樹的缺點是,當節點加入或離開時,許多鍵的範圍可能會改變,導致需要重新計算整棵樹。
實際應用#
Dynamo 使用梅克爾樹來進行反熵處理(anti-entropy) 和背景衝突解決,確保副本之間的資料一致性。