預寫式日誌(Write-Ahead Log, WAL)#
背景#
機器隨時都可能故障或重新啟動。如果程式正在執行資料修改的過程中,機器突然斷電,重新啟動後程式需要知道中斷前正在做什麼。根據**原子性(Atomicity)與持久性(Durability)**的需求,程式可能需要決定重做(Redo)、復原(Undo)或完成先前未完成的操作。
定義#
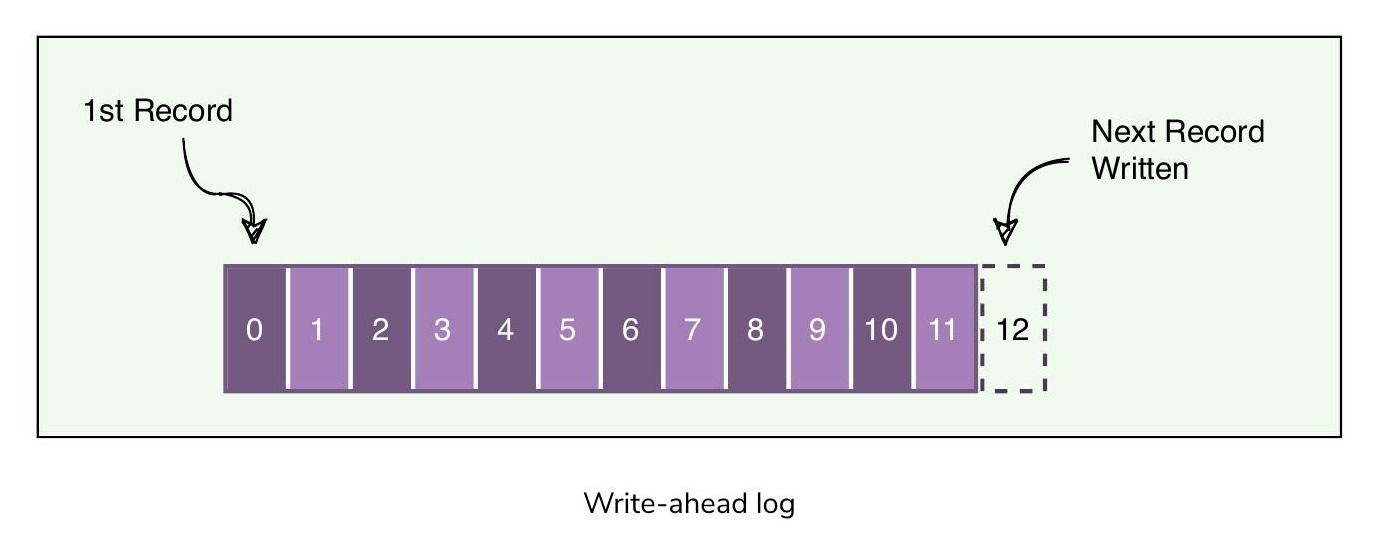
為了保證持久性與資料完整性(Data Integrity),每一次對系統的修改都會先寫入磁碟上的一個僅附加日誌(Append-Only Log)。這個日誌就是預寫式日誌(Write-Ahead Log, WAL),也稱為交易日誌(Transaction Log)或提交日誌(Commit Log)。寫入 WAL 可以保證即使機器當機,系統仍然能夠復原並在必要時重新套用操作。
解決方案#
WAL 的核心思想是:所有修改在套用到系統之前,都必須先寫入磁碟上的日誌檔案。其運作方式如下:
- 每一筆日誌條目(Log Entry)都包含足夠的資訊,可以用來重做或復原該修改
- 每次重新啟動時,系統會讀取日誌,透過重播(Replay)所有日誌條目來恢復先前的狀態
- 使用 WAL 可以顯著減少磁碟寫入次數,因為只需要將日誌檔案刷寫(Flush)到磁碟,而不需要刷寫每個被交易修改的資料檔案
- 在分散式環境中,每個節點(Node)維護自己的日誌
- WAL 永遠以**循序附加(Sequentially Appended)**的方式寫入,簡化了日誌的處理
- 每筆日誌條目都會被賦予一個唯一識別碼(Unique Identifier),這有助於實作日誌分段(Log Segmentation)與日誌清除(Log Purging)等操作
預寫式日誌(Write-Ahead Log)的結構示意圖
範例#
- Cassandra:當節點收到寫入請求時,會立即將資料寫入提交日誌(Commit Log),這就是一種 WAL。Cassandra 在將資料寫入 MemTable 之前,會先寫入提交日誌,以確保在意外關機時的持久性。啟動時,提交日誌中的任何變更都會被套用到 MemTable。
- Kafka:實作了**分散式提交日誌(Distributed Commit Log)**來持久化儲存所有接收到的訊息。
- Chubby:為了容錯(Fault Tolerance),在領導者當機的情況下,所有資料庫交易都儲存在**交易日誌(Transaction Log)**中,這也是一種 WAL。
分段日誌(Segmented Log)#
背景#
單一日誌檔案可能會變得難以管理。隨著檔案不斷增長,它也會成為效能瓶頸(Performance Bottleneck),特別是在啟動時需要讀取日誌的情況下。較舊的日誌需要定期清理,或在某些情況下進行合併。對一個龐大的單一檔案執行這些操作是非常困難的。
定義#
將日誌拆分為較小的分段(Segment),以便於管理。
解決方案#
單一日誌檔案會被拆分為多個大小相等的日誌分段。系統可以根據**滾動策略(Rolling Policy)**來分段:
- 基於時間:例如每 4 小時產生一個新分段
- 基於大小:例如每 1GB 產生一個新分段
分段日誌(Segmented Log)的運作方式
範例#
- Cassandra:採用分段日誌策略,將提交日誌拆分為多個較小的檔案,而非單一大型檔案。當節點收到寫入操作時,會立即將資料寫入提交日誌。當提交日誌的大小達到閾值時,就會建立新的提交日誌,因此隨著時間推移會產生多個日誌分段。分段日誌減少了寫入磁碟所需的搜尋次數(Seeks)。當 Cassandra 將對應的資料刷寫到 SSTable 後,提交日誌分段就會被截斷。分段可以被封存(Archived)、刪除(Deleted)或回收(Recycled)。
- Kafka:使用日誌分段來實作分區(Partition)的儲存。由於 Kafka 經常需要在磁碟上尋找訊息進行清除,單一長檔案可能成為效能瓶頸且容易出錯。為了更好的管理與效能,分區會被拆分為多個分段。
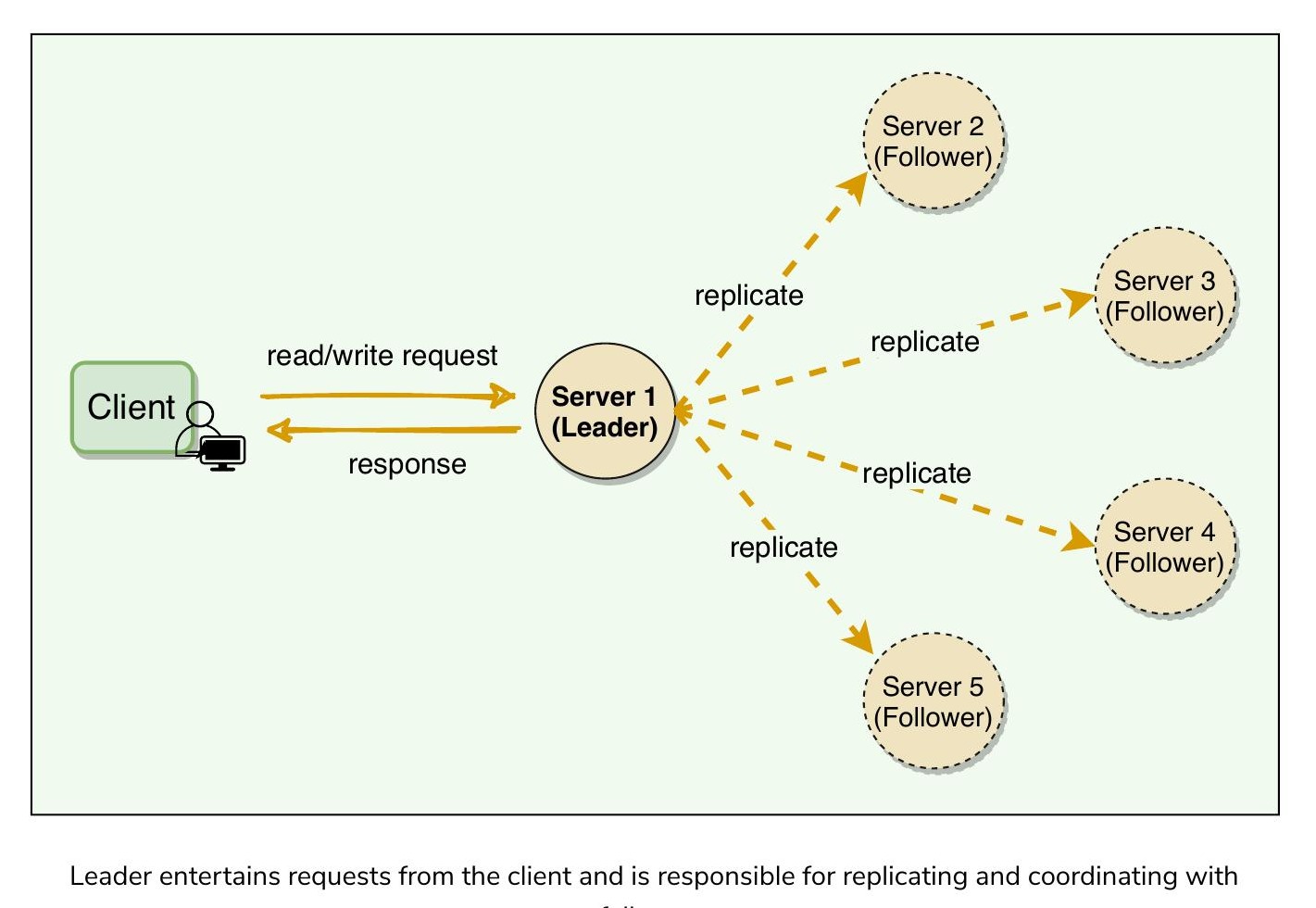
高水位標記(High-Water Mark)#
背景#
在領導者-追隨者(Leader-Follower)架構中,領導者負責處理寫入操作並將其提交到 WAL。資料複寫(Replication)可以是非同步的(Asynchronous),這帶來了以下問題:
- 如果領導者當機,新選出的領導者可能落後於舊領導者
- 舊領導者 WAL 中的交易在其重新上線之前無法被恢復
- 用戶端可能會看到不一致的資料
- 不同的追隨者可能擁有不同的日誌條目
定義#
追蹤領導者上最後一筆已成功複寫到法定人數(Quorum)追隨者的日誌條目。這個索引就是高水位標記索引(High-Water Mark Index)。領導者只會對外公開此索引以下的資料。
解決方案#
高水位標記的運作流程如下:
- 領導者將變更(Mutation)附加到自己的 WAL,然後傳送給所有追隨者
- 追隨者將變更附加到各自的 WAL,並回傳確認(Acknowledge)
- 領導者追蹤每個追隨者已複寫的索引
- 高水位標記等於已在法定人數追隨者上複寫完成的最高索引
- 高水位標記透過**心跳(Heartbeat)**機制傳播給追隨者
- 用戶端只能讀取到高水位標記為止的資料
sequenceDiagram
participant C as 用戶端(Client)
participant L as 領導者(Leader)
participant F1 as 追隨者1(Follower1)
participant F2 as 追隨者2(Follower2)
C->>L: 1. 發送寫入請求(Write Request)
L->>L: 2. 附加到本地 WAL
par 複寫到追隨者
L->>F1: 3. 傳送日誌條目(Log Entry)
L->>F2: 3. 傳送日誌條目(Log Entry)
end
F1->>F1: 附加到本地 WAL
F2->>F2: 附加到本地 WAL
F1-->>L: 4. 回傳確認(ACK)
F2-->>L: 4. 回傳確認(ACK)
L->>L: 5. 多數確認後推進高水位標記(High-Water Mark)
Note over L,F2: 6. 所有節點僅提供高水位標記以下的讀取服務
L-->>C: 確認寫入完成透過高水位標記機制,即使在領導者故障轉移(Leader Failover)期間,系統也能保證用戶端讀取到的資料是一致的。
範例#
- Kafka:Broker 會追蹤高水位標記,其定義為所有**同步副本集(In-Sync Replicas, ISR)**共享的最大偏移量(Offset)。消費者(Consumer)只能看到高水位標記以下的訊息,確保消費者不會讀取到可能因領導者故障而遺失的未複寫資料。