HDFS 簡介#
設計目標#
設計一個能夠儲存超大檔案(TB 甚至更大)的分散式系統。該系統應具備可擴展性(Scalability)、可靠性(Reliability)與高可用性(High Availability)。
什麼是 HDFS?#
HDFS(Hadoop Distributed File System)是一個分散式檔案系統,專為儲存非結構化資料而設計。它能夠可靠地儲存大量檔案,並以高頻寬串流(Stream)這些檔案至使用者應用程式。
HDFS 是 Google 檔案系統(GFS)的變體與簡化版本,許多架構決策皆受 GFS 設計啟發。HDFS 建立在「一次寫入、多次讀取」(Write-Once, Read-Many)的資料處理模式之上。
HDFS 區塊複製
背景#
Apache Hadoop 是一個軟體框架,提供分散式檔案儲存系統與分散式運算能力,利用 MapReduce 程式設計模型來分析與轉換超大規模資料集。HDFS 是 Hadoop 的預設檔案儲存系統,設計為可擴展、容錯的分散式檔案系統,主要服務於 MapReduce 範式的需求。
HDFS 與 GFS 的共同特性:
- 皆為儲存超大檔案而設計,可擴展至 PB 級儲存
- 皆為處理大規模資料集的批次處理(Batch Processing)而建構
- 皆為資料密集型應用程式(Data-Intensive Applications)設計,而非面向終端使用者
- 皆不符合 POSIX 標準,本身也不是可掛載的檔案系統
- 通常透過 HDFS 客戶端或 Hadoop 函式庫的 API 呼叫來存取
以下類型的應用程式不適合使用 HDFS:
- 低延遲資料存取:HDFS 針對高吞吐量(High Throughput)進行最佳化,可能以延遲為代價。因此需要低延遲資料存取的應用程式不適合 HDFS。
- 大量小檔案:HDFS 有一個稱為 NameNode 的中央伺服器,將所有檔案系統元資料(Metadata)保存在記憶體中。這使得檔案系統中的檔案數量受限於 NameNode 的記憶體容量。儲存數百萬個檔案是可行的,但數十億個檔案則超出目前硬體的能力。
- 不支援並行寫入與任意位置修改:與 GFS 不同,多個寫入者無法同時寫入同一個 HDFS 檔案。此外,寫入操作總是在檔案末尾進行(Append-Only),不支援對檔案中任意偏移量的修改。
API#
HDFS 不提供標準的 POSIX API,而是提供使用者層級的 API。在 HDFS 中,檔案以層級目錄結構組織,並透過路徑名稱來識別。HDFS 支援常見的檔案系統操作,例如建立、刪除、重新命名、移動檔案和目錄,以及建立符號連結。所有讀寫操作皆以 Append-Only 方式進行。
高層架構#
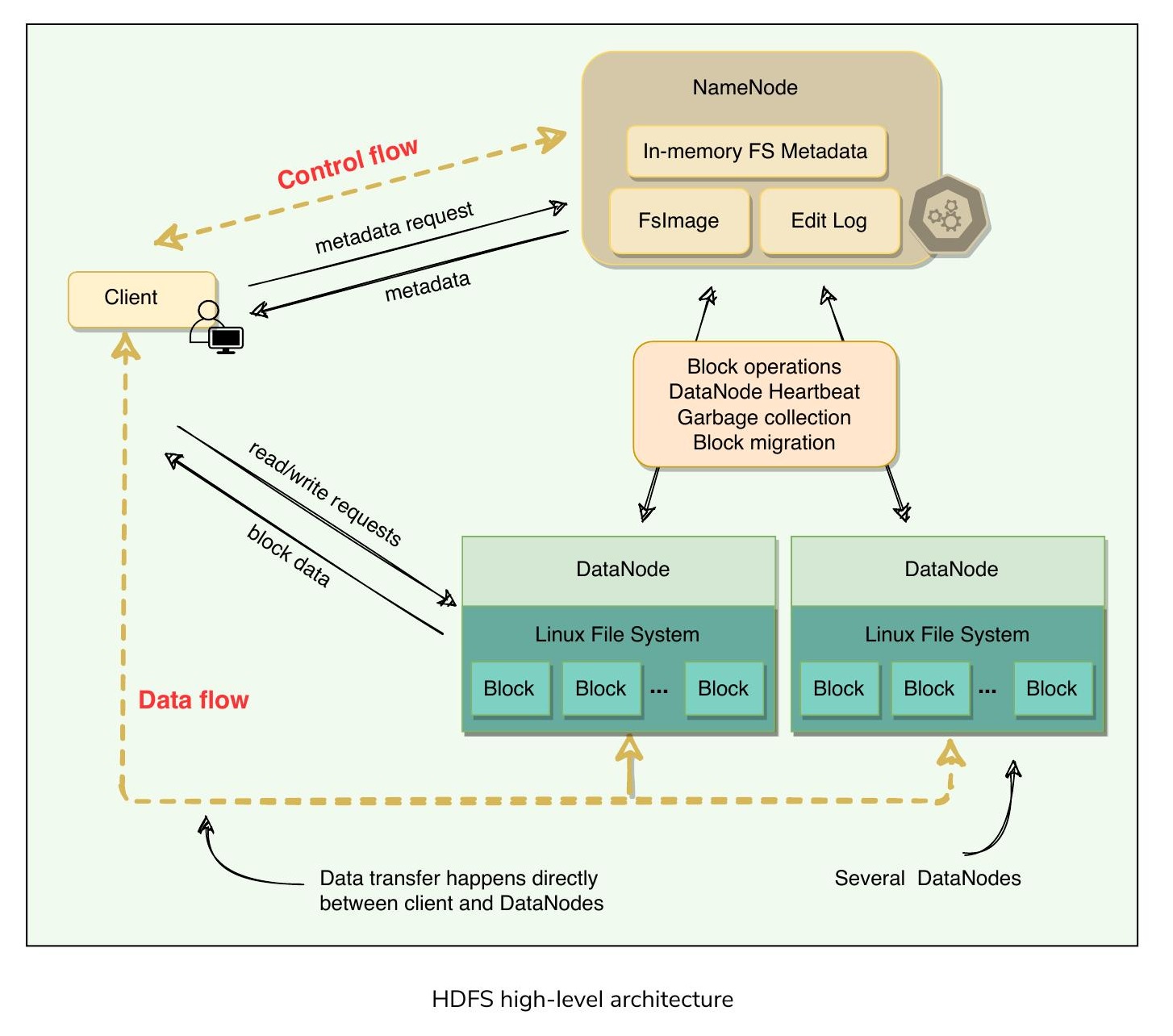
所有儲存在 HDFS 中的檔案都會被切割為多個固定大小的區塊(Block),預設每個區塊為 128 MB(可依檔案個別設定)。每個儲存的檔案包含兩部分:實際的檔案資料,以及元資料(例如檔案有多少區塊、區塊位置、總檔案大小等)。HDFS 叢集主要由管理檔案系統元資料的 NameNode 和儲存實際資料的 DataNode 組成。
HDFS 架構的關鍵要點:
- 同一檔案的所有區塊大小相同,除了最後一個區塊
- HDFS 使用大區塊,因為它專為儲存極大檔案而設計,以便 MapReduce 任務高效處理
- 每個區塊由唯一的 64 位元 ID(BlockID)標識
- 所有讀寫操作在區塊層級進行
- DataNode 將每個區塊存儲為本地檔案系統上的獨立檔案,並提供讀寫存取
- DataNode 啟動時會掃描本地檔案系統,將所管轄的資料區塊清單(稱為 BlockReport)傳送給 NameNode
- NameNode 維護兩個磁碟上的資料結構來儲存檔案系統狀態:FsImage 檔案和 EditLog。FsImage 是某一時間點的檔案系統元資料檢查點(Checkpoint),EditLog 則是自上次建立映像檔以來所有檔案系統元資料異動的日誌
- 使用者應用程式透過 HDFS 客戶端與 HDFS 互動。客戶端與 NameNode 互動以取得元資料,但所有資料傳輸都直接在客戶端與 DataNode 之間進行
- 為實現高可用性,HDFS 會建立資料的多個副本,並將它們分散在叢集中的各個節點上
GFS 與 HDFS 比較#
HDFS 的架構與 GFS 類似,但術語有所不同。以下為兩者的比較:
GFS 與 HDFS 詳細比較表
| 項目 | GFS | HDFS |
|---|---|---|
| 儲存節點 | ChunkServer | DataNode |
| 檔案分片 | Chunk | Block |
| 分片大小 | 預設 64 MB(可調整) | 預設 128 MB(可調整) |
| 元資料檢查點 | Checkpoint Image | FsImage |
| 預寫日誌 | Operation Log | EditLog |
| 平台 | Linux | 跨平台 |
| 開發語言 | C++ | Java |
| 可用性 | 僅 Google 內部使用 | 開源 |
| 監控 | Master 從 ChunkServer 接收 HeartBeat | NameNode 從 DataNode 接收 HeartBeat |
| 並行存取 | 支援多寫入者與多讀取者 | 不支援多寫入者;遵循一次寫入、多次讀取模型 |
| 檔案操作 | 可 Append 與隨機寫入 | 僅支援 Append |
| 垃圾回收 | 刪除的檔案重新命名至特定資料夾,稍後回收 | 刪除的檔案重新命名為隱藏名稱,稍後回收 |
| 通訊方式 | RPC over TCP 與 Master 通訊;使用 Pipelining 和 Streaming over TCP 傳輸資料 | RPC over TCP 與 NameNode 通訊;使用 Pipelining 和 Streaming over TCP 傳輸資料 |
| 快取管理 | 客戶端快取元資料;ChunkServer 依賴 Linux 緩衝區快取 | HDFS 使用分散式快取;指定路徑可顯式快取於 DataNode 的堆外記憶體(Off-Heap Block Cache) |
| 複製策略 | Chunk 副本分散於不同機架;預設 3 份副本;Master 自動複製 | 自動機架感知複製;預設 3 份副本(同機架 2 份、不同機架 1 份) |
| 檔案系統命名空間 | 檔案以層級目錄結構組織,透過路徑名稱識別 | 支援傳統層級檔案組織;也支援第三方檔案系統(如 Amazon S3、Cloud Store) |
| 資料庫 | BigTable 使用 GFS 作為儲存引擎 | HBase 使用 HDFS 作為儲存引擎 |
深入探討#
叢集拓撲#
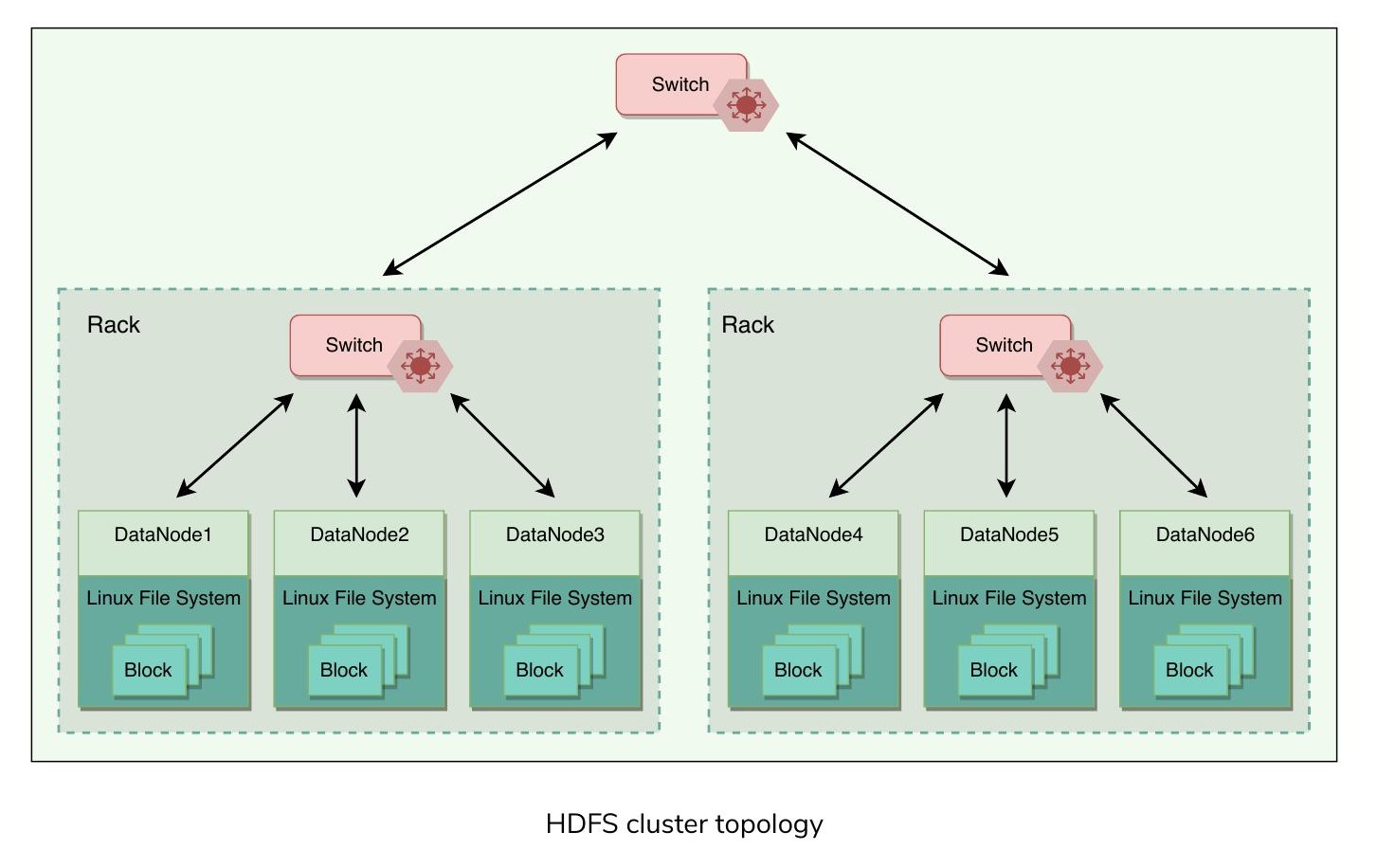
典型的資料中心包含多個透過交換機連接的伺服器機架(Rack)。Hadoop 叢集常見的配置為每個機架約 30 到 40 台伺服器。每個機架有一個專用的 Gigabit 交換機連接所有伺服器,並有一條上行鏈路連接到核心交換機或路由器,其頻寬由資料中心內的多個機架共享。
當 HDFS 部署於叢集上時,每台伺服器都會被配置並映射到特定的機架。網路距離以跳數(Hop) 衡量,一個跳數對應拓撲中的一條鏈路。Hadoop 假設為樹狀拓撲結構,兩台伺服器之間的距離是它們到最近共同祖先的距離之和。
例如:
- 同一節點上的兩個程序之間的距離為零跳
- 同一機架上的兩個節點之間為兩跳
- 不同機架上的兩個節點之間為四跳
機架感知複製#
機架感知複製
副本的放置對 HDFS 的可靠性和效能至關重要。HDFS 採用機架感知複製放置策略(Rack-Aware Replica Placement Policy) 來提升資料可靠性、可用性和網路頻寬利用率。
當複製因子(Replication Factor)為 3 時,HDFS 的放置策略如下:
- 第一個副本:放置在與寫入客戶端相同的節點上(若客戶端不在 HDFS 叢集內,則隨機選擇一個節點)
- 第二個副本:寫入與第一個副本不同機架的節點上(跨機架副本)
- 第三個副本:寫入與第二個副本相同機架上的另一個隨機節點
- 額外副本:寫入叢集中的隨機節點,但系統會盡量避免在同一機架上放置過多副本
HDFS 機架感知複製策略的核心規則:
- 任何 DataNode 上不會存放同一區塊的多個副本
- 若有足夠的機架可用,同一機架上不會存放同一區塊的超過兩個副本
這種機架感知複製的設計理念在於能夠容忍節點和機架故障。例如,當整個機架因電源或網路問題離線時,所請求的區塊仍可從其他機架上找到。遵循此方案會減慢寫入操作速度,因為資料需要複製到不同機架,但這是 HDFS 在可靠性與效能之間刻意做出的權衡。
同步語義#
早期版本的 HDFS 遵循嚴格的不可變語義(Immutable Semantics)。一旦檔案被寫入,就不能再次開啟進行寫入,但仍可刪除。目前版本的 HDFS 支援追加寫入(Append),但仍有相當的限制:已寫入 HDFS 的二進位資料無法就地修改。
這一設計選擇源於 MapReduce 最常見的工作負載遵循「一次寫入、多次讀取」的資料存取模式。MapReduce 是一個具有預定義階段的受限運算模型,Reducer 將獨立的檔案作為輸出寫入 HDFS。HDFS 專注於為多個客戶端同時提供快速的讀取存取。
HDFS 一致性模型#
HDFS 遵循強一致性模型(Strong Consistency Model)。每個寫入 HDFS 的資料區塊都會被複製到多個節點。為確保強一致性,只有當所有副本都成功寫入後,才會宣告寫入成功。這樣,所有客戶端都能看到相同且一致的檔案視圖。由於 HDFS 不允許多個並行寫入者寫入同一檔案,實現強一致性相對容易。
讀取操作剖析#
HDFS 讀取流程#
讀取操作剖析
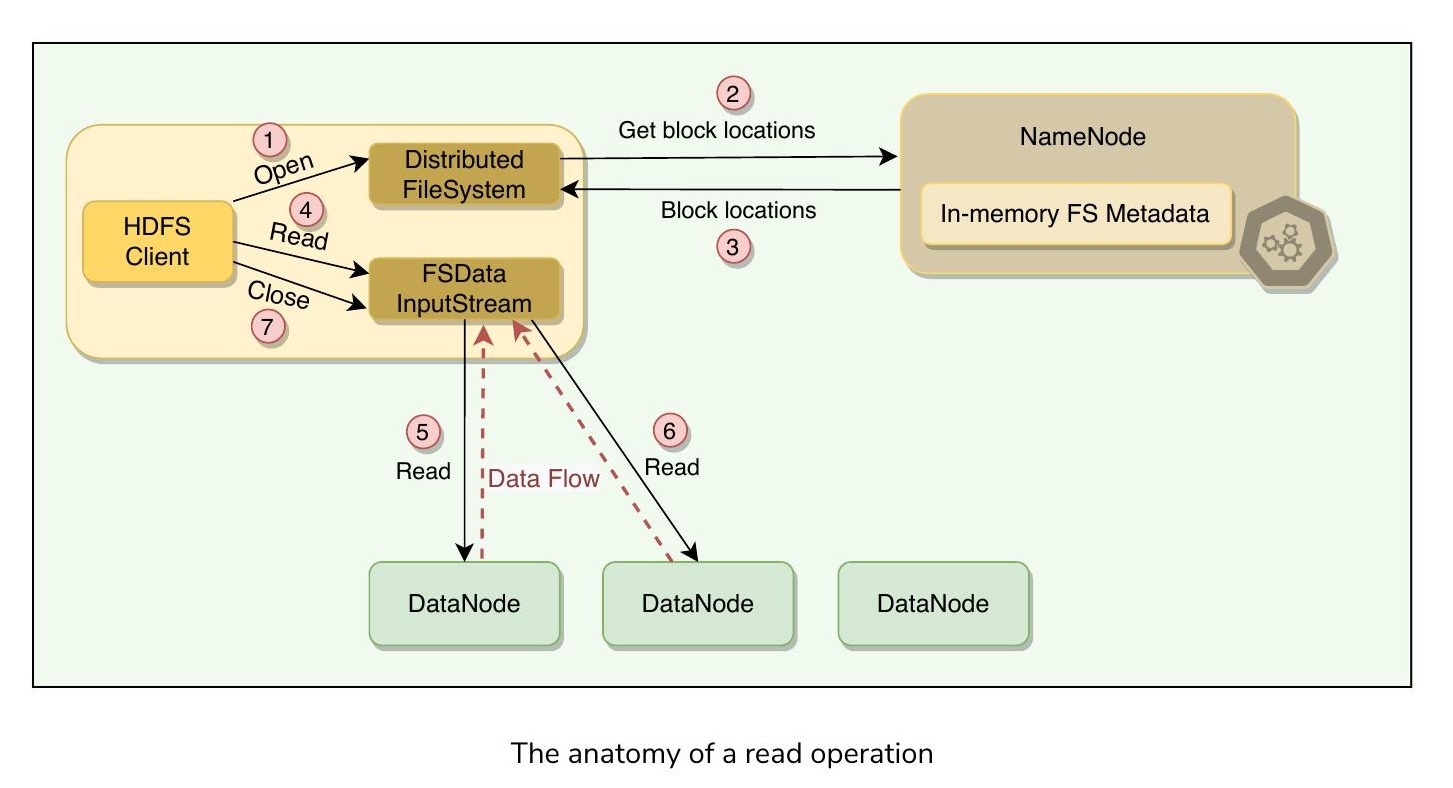
HDFS 讀取流程概述如下:
- 客戶端呼叫 Distributed FileSystem 物件的
open()方法發起讀取請求,指定檔案名稱、起始偏移量和讀取範圍長度 - Distributed FileSystem 物件根據給定的偏移量和範圍長度計算需要讀取的區塊,並向 NameNode 請求區塊位置
- NameNode 擁有所有區塊位置的元資料,提供客戶端區塊清單及每個區塊副本的位置。NameNode 會找到最接近客戶端的副本。最近副本的選擇規則如下:
- 優先選擇與客戶端在同一節點上的區塊
- 其次選擇與客戶端在同一機架上的區塊
- 最後選擇跨機架的區塊
- 客戶端取得區塊位置後,呼叫 FSDataInputStream 的
read()方法,該物件負責與 DataNode 的所有互動。輸入串流物件與持有第一個區塊的最近 DataNode 建立連線 - 資料以串流形式讀取並傳遞給請求的應用程式,因此區塊不必在客戶端應用程式開始處理之前完整傳輸
- FSDataInputStream 接收完一個區塊的所有資料後,關閉連線並轉向連接下一個區塊的 DataNode,重複此過程直到完成所有所需區塊的讀取
- 客戶端完成所有所需區塊的讀取後,呼叫輸入串流物件的
close()方法
短路讀取#
如上所述,客戶端直接從 DataNode 讀取資料,使用 TCP Socket 進行通訊。如果資料和客戶端在同一台機器上,HDFS 可以直接讀取檔案而繞過 DataNode,這種方式稱為短路讀取(Short Circuit Read),效率更高,因為減少了額外的處理開銷和資源消耗。
寫入操作剖析#
HDFS 寫入流程#
HDFS 寫入流程概述如下:
- 客戶端呼叫 Distributed FileSystem 物件的
create()方法發起寫入請求 - Distributed FileSystem 物件向 NameNode 發送檔案建立請求
- NameNode 驗證檔案是否已存在,以及客戶端是否有建立檔案的權限。兩個條件都通過後,NameNode 建立新的檔案記錄並發送確認
- 客戶端使用 FSDataOutputStream 開始寫入檔案
- FSDataOutputStream 將資料寫入本地佇列(稱為 Data Queue),資料在佇列中等待直到累積完整的一個區塊
- 佇列累積完整區塊後,另一個元件 DataStreamer 被通知開始管理資料傳輸到 DataNode
- DataStreamer 首先向 NameNode 請求在 DataNode 上分配新區塊,從而選擇適當的 DataNode 用於複製
- NameNode 提供區塊清單及每個區塊副本的位置
- 收到 NameNode 的區塊位置後,DataStreamer 開始將內部佇列中的區塊傳輸到最近的 DataNode
- 每個區塊寫入第一個 DataNode 後,會透過管線(Pipeline)傳輸到其他 DataNode 以寫入副本。區塊在檔案寫入過程中即完成複製
HDFS 在所有副本都被 DataNode 成功寫入之前,不會向客戶端確認寫入完成。
- DataStreamer 完成所有區塊的寫入後,等待所有 DataNode 的確認
- 收到所有確認後,客戶端呼叫 OutputStream 的
close()方法 - 最後,Distributed FileSystem 聯繫 NameNode 通知檔案寫入操作完成。此時 NameNode 提交檔案建立操作,使檔案可供讀取
如果 NameNode 在步驟 13 之前當機,該檔案將會遺失。
sequenceDiagram
participant C as 客戶端(Client)
participant DFS as DistributedFileSystem
participant NN as NameNode
participant DS as DataStreamer
participant DN1 as DataNode 1
participant DN2 as DataNode 2
participant DN3 as DataNode 3
Note over C,DN3: 階段一:建立檔案
C->>DFS: 1. 呼叫 create()
DFS->>NN: 2. 發送檔案建立請求
NN-->>DFS: 3. 驗證權限,建立記錄,回傳確認
DFS-->>C: 回傳 FSDataOutputStream
Note over C,DN3: 階段二:寫入資料
C->>DFS: 4. 開始寫入資料
DFS->>DS: 5. 資料寫入本地佇列(Data Queue)
DS->>DS: 6. 等待累積完整區塊
Note over C,DN3: 階段三:建立管線與傳輸
DS->>NN: 7. 請求分配新區塊
NN-->>DS: 8. 回傳區塊位置清單
DS->>DN1: 9. 傳輸區塊至最近的 DataNode
DN1->>DN2: 10. 管線傳輸(Pipeline)
DN2->>DN3: 10. 管線傳輸(Pipeline)
Note over C,DN3: 階段四:確認與完成
DN3-->>DN2: 確認(ACK)
DN2-->>DN1: 確認(ACK)
DN1-->>DS: 11. 所有 DataNode 確認寫入完成
C->>DFS: 12. 呼叫 close()
DFS->>NN: 13. 通知檔案寫入完成
NN-->>DFS: 提交檔案(檔案可供讀取)資料完整性與快取#
資料完整性#
資料完整性(Data Integrity) 指確保資料的正確性。當客戶端從 DataNode 取回區塊時,資料可能因儲存裝置故障、網路問題或軟體本身的錯誤而損壞。HDFS 客戶端使用校驗和(Checksum) 來驗證檔案內容:
- 當客戶端將檔案存入 HDFS 時,會計算每個區塊的校驗和,並儲存在同一 HDFS 命名空間中的獨立隱藏檔案中
- 當客戶端取回檔案內容時,會驗證從每個 DataNode 收到的資料是否與對應的校驗和檔案匹配
- 若不匹配,客戶端可以選擇從其他副本取回該區塊
區塊掃描器#
區塊掃描器(Block Scanner) 程序定期在每個 DataNode 上執行,掃描該 DataNode 上儲存的區塊並驗證校驗和是否與區塊資料匹配。此外,當客戶端讀取完整區塊且校驗和驗證成功時,會通知 DataNode,DataNode 將此視為副本的驗證。
當客戶端或區塊掃描器偵測到損壞的區塊時,會通知 NameNode。NameNode 標記該副本為損壞,並啟動建立新的完好副本的流程。
快取#
通常,區塊從磁碟讀取,但對於頻繁存取的檔案,區塊可以顯式快取在 DataNode 的記憶體中的堆外區塊快取(Off-Heap Block Cache)裡。HDFS 提供集中式快取管理方案(Centralized Cache Management),允許使用者指定要快取的路徑。客戶端可以告知 NameNode 要快取哪些檔案,NameNode 再與持有所需區塊的 DataNode 通訊,指示它們快取區塊。
集中式快取管理的優勢:
- 防止頻繁存取資料被驅逐:顯式指定快取區塊可防止頻繁存取的資料從記憶體中被驅逐,這在 HDFS 工作負載通常大於 DataNode 主記憶體的情況下尤為重要
- 改善任務排程:NameNode 管理 DataNode 快取,應用程式可在進行 MapReduce 任務放置決策時查詢已快取區塊的位置,將任務與快取的區塊副本共置可提升讀取效能
- 零拷貝讀取 API:當 DataNode 已快取某個區塊時,客戶端可使用更高效的零拷貝讀取 API(Zero-Copy Read API)。由於區塊已在記憶體中且校驗和驗證已由 DataNode 完成,客戶端使用此 API 幾乎不產生額外開銷
- 提升叢集記憶體利用率:依賴每個 DataNode 的作業系統緩衝區快取時,重複讀取同一區塊會導致所有 n 個副本都被拉入緩衝區快取。透過集中式快取管理,使用者可只顯式快取 n 個副本中的 m 個,節省 n-m 份記憶體
容錯機制#
HDFS 如何處理 DataNode 故障?#
複製#
當 DataNode 故障時,其所有資料將變得不可用。HDFS 透過複製(Replication) 處理此問題。每個寫入 HDFS 的區塊都會複製到多個 DataNode(預設三個),因此即使一個 DataNode 不可存取,其資料仍可從其他副本讀取。
心跳機制#
NameNode 透過心跳機制(Heartbeat) 追蹤 DataNode 的狀態。每個 DataNode 每隔數秒向 NameNode 發送心跳訊息。若 DataNode 故障,心跳會停止,NameNode 會偵測到該 DataNode 已失效,並將其標記為已死亡,不再向該 DataNode 轉發任何讀寫請求。
由於複製機制,儲存在該 DataNode 上的區塊在其他 DataNode 上仍有額外的副本。NameNode 會定期檢查檔案系統狀態,發現副本不足的區塊,並執行叢集重新平衡流程,複製副本數量不足的區塊。
NameNode 故障處理#
FsImage 與 EditLog#
NameNode 是單點故障(Single Point of Failure, SPOF)。NameNode 故障將導致整個檔案系統停擺。NameNode 在內部維護兩個磁碟上的資料結構來儲存檔案系統狀態:
- FsImage:某一時間點的檔案系統元資料檢查點(Checkpoint)
- EditLog:自上次建立映像檔以來所有檔案系統元資料異動的日誌
所有對檔案系統元資料的變更都會寫入 EditLog。在定期的間隔中,EditLog 和 FsImage 檔案會被合併以建立新的映像檔快照,然後清空 EditLog。
元資料備份#
NameNode 故障時元資料將不可用,而 NameNode 的磁碟故障將會是災難性的,因為檔案元資料會遺失,無法從 DataNode 上的區塊重建檔案。因此,使 NameNode 能夠抵禦故障至關重要。HDFS 提供兩種機制:
備份 FsImage 與 EditLog:NameNode 可配置為維護多份 FsImage 和 EditLog 的副本。任何對 FsImage 或 EditLog 的更新都會同步且原子地更新所有副本。常見配置是在本地磁碟上保留一份,在遠端網路檔案系統(NFS)掛載點上保留一份。這種同步更新可能會降低 NameNode 每秒可支援的命名空間交易速率,但由於 HDFS 應用程式是資料密集型而非元資料密集型,這種降低是可接受的。
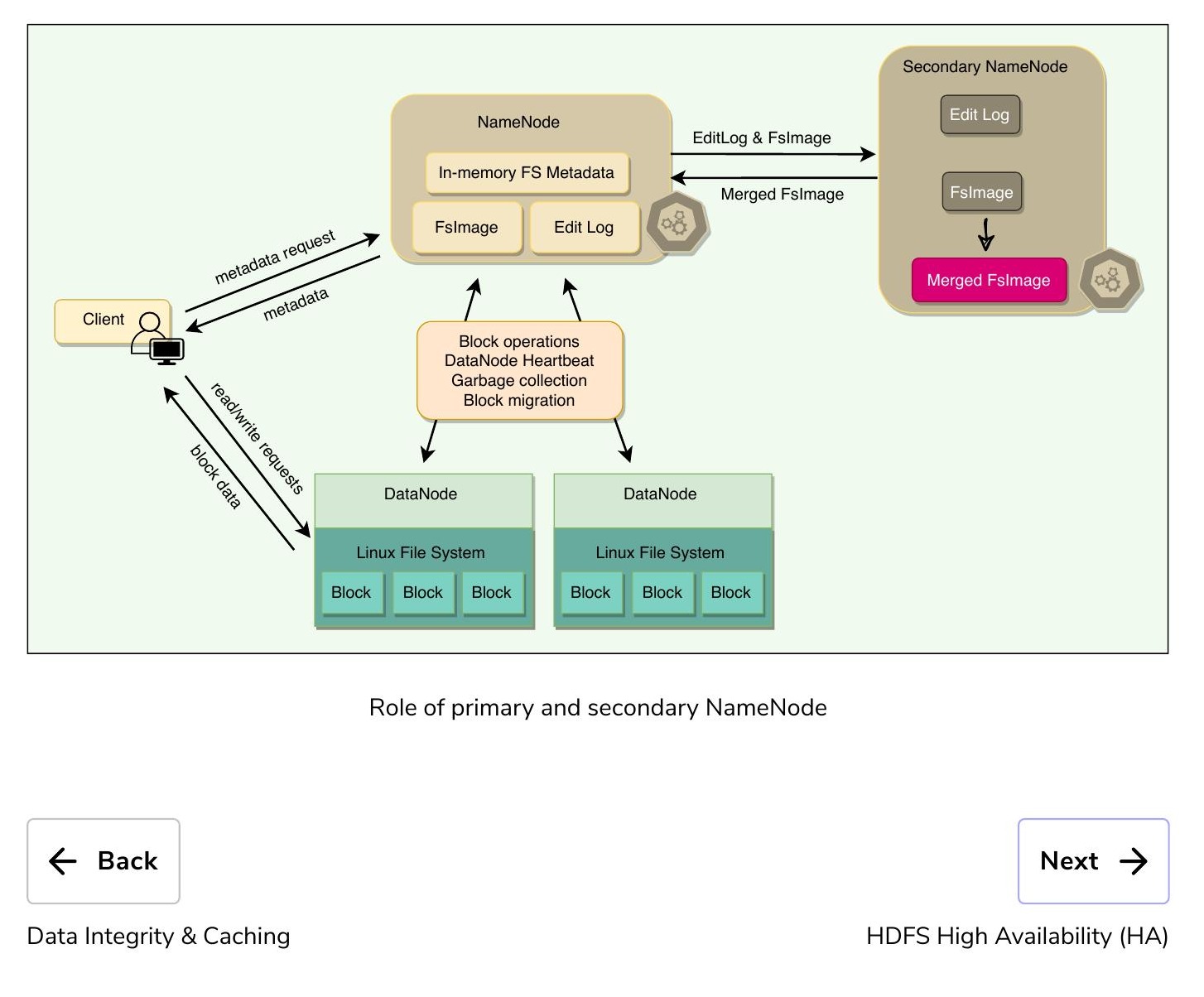
次要 NameNode(Secondary NameNode):儘管名稱如此,次要 NameNode 並非備份 NameNode。它的主要角色是協助主要 NameNode 進行檔案系統的檢查點操作。次要 NameNode 定期合併命名空間映像與 EditLog,以防止 EditLog 變得過大。它在獨立的實體機器上運行(因為需要大量 CPU 和與 NameNode 同等的記憶體來執行合併),並保留合併後的命名空間映像副本。然而,次要 NameNode 的狀態落後於主要 NameNode,因此在主要 NameNode 完全故障時,資料遺失幾乎不可避免。通常的做法是將 NFS 上的 NameNode 元資料檔案複製到次要 NameNode,然後將其作為新的主要 NameNode 啟動。
主要與次要 NameNode 的角色
HDFS 高可用性#
高可用性架構#
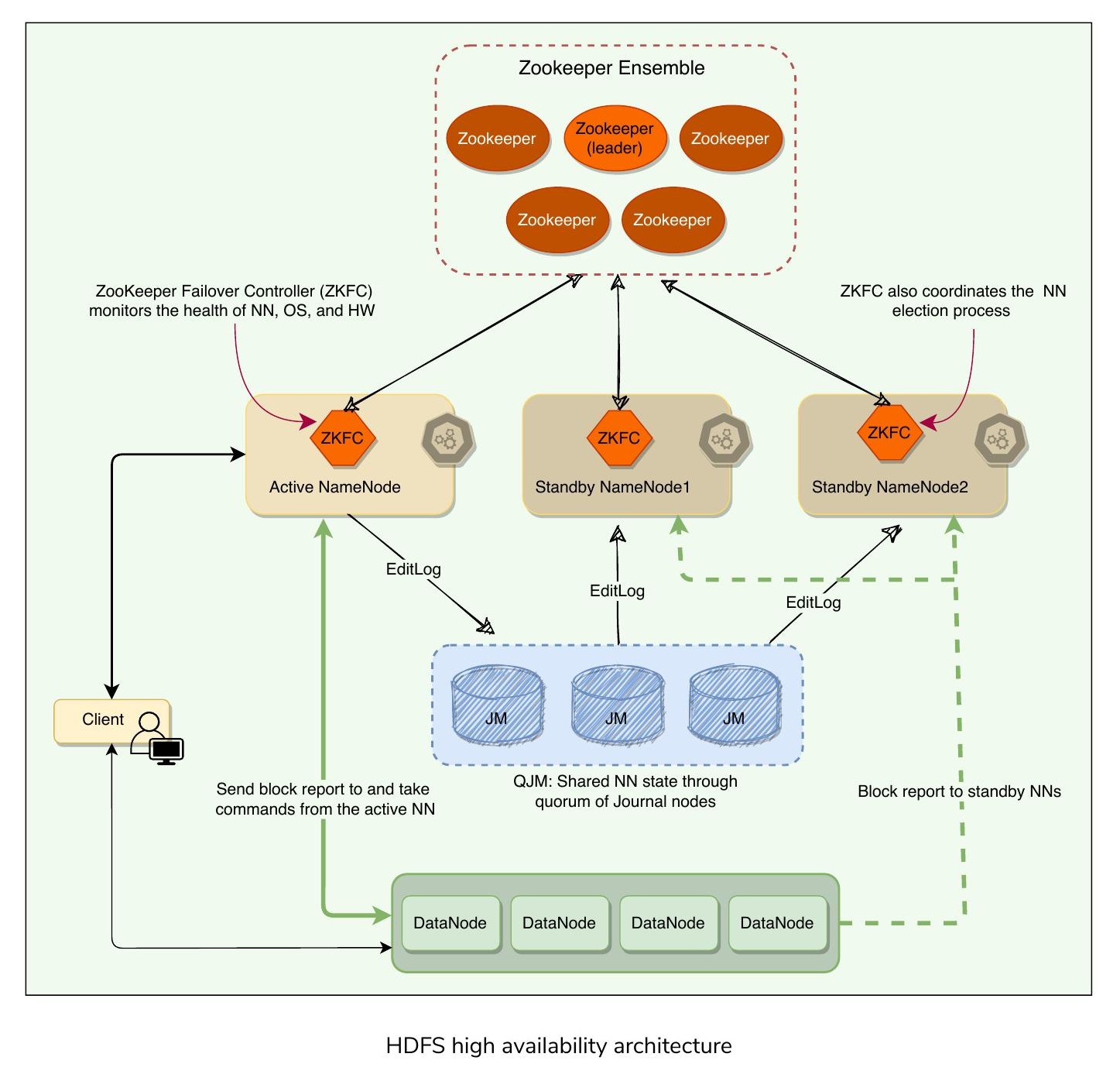
HDFS 高可用性架構
雖然 NameNode 的元資料會被複製到多個檔案系統以防止資料遺失,但這仍無法提供檔案系統的高可用性。如果 NameNode 故障,客戶端將無法讀取、寫入或列出檔案,因為 NameNode 是元資料和檔案到區塊映射的唯一儲存庫。此時整個 Hadoop 系統實際上將停止服務,直到新的 NameNode 上線。
從故障 NameNode 恢復時,管理員需要啟動新的主要 NameNode(使用檔案系統元資料副本之一),並重新配置 DataNode 和客戶端使用新的 NameNode。新的 NameNode 在以下操作完成前無法處理請求:
- 將命名空間映像載入記憶體
- 重播 EditLog
- 從 DataNode 接收足夠的區塊報告
在擁有大量檔案和區塊的大型叢集上,NameNode 的冷啟動可能需要半小時或更長時間。此外,由於 NameNode 意外故障實際上相當罕見,計畫性停機的情境在實務上反而更為重要。
Active-Standby 架構#
為解決此問題,Hadoop 2.0 版本新增了 HDFS 高可用性(HA)支援。在此實作中,有兩個(或更多)NameNode 以 Active-Standby 配置運作。在任何時間點,恰好一個 NameNode 處於 Active 狀態,其餘處於 Standby 狀態。Active NameNode 負責叢集中的所有客戶端操作,而 Standby 節點作為 Active 的跟隨者,維護足夠的狀態以在需要時提供快速容錯移轉(Failover)。
為使 Standby 節點與 Active 節點保持狀態同步,HDFS 做了以下架構調整:
- 共享 EditLog:NameNode 必須使用高可用的共享儲存來共享 EditLog(例如 NFS 掛載或 NAS)
- Standby 同步:當 Standby NameNode 啟動時,它讀取共享 EditLog 至末尾以同步狀態,然後持續讀取 Active NameNode 寫入的新條目
- 區塊報告:DataNode 必須向所有 NameNode 發送區塊報告,因為區塊映射儲存在 NameNode 的記憶體中而非磁碟上
- 客戶端容錯移轉:客戶端必須配置為處理 NameNode 容錯移轉。HDFS URI 使用邏輯主機名稱(Logical Hostname),映射到多個 NameNode 位址,客戶端程式庫會逐一嘗試每個 NameNode 位址直到操作成功
共享儲存有兩種選擇:NFS 或法定日誌管理器(Quorum Journal Manager, QJM)。
QJM#
QJM 的唯一目的是提供高可用的 EditLog。QJM 以一組日誌節點(Journal Node)的形式運行,每次編輯都必須寫入法定人數(多數)的日誌節點。通常有三個日誌節點,因此系統可以容忍其中一個的失效。這種安排類似於 ZooKeeper 的運作方式,但 QJM 的實作並不使用 ZooKeeper。
HDFS 高可用性確實使用 ZooKeeper 來選舉 Active NameNode。QJM 程序在所有 NameNode 上運行,並使用 RPC 將所有 EditLog 變更傳達給日誌節點。
由於 Standby NameNode 的記憶體中保有最新狀態(包含最新的 EditLog 和最新的區塊映射),任何 Standby 都可以在 Active NameNode 故障時非常快速地接管(幾秒內)。然而,實際的容錯移轉時間會更長(大約一分鐘左右),因為系統需要保守地確認 Active NameNode 確實已失效。
ZooKeeper 與容錯移轉#
ZKFailoverController(ZKFC) 是一個運行在每個 NameNode 上的 ZooKeeper 客戶端,負責與 ZooKeeper 協調,並監控和管理 NameNode 的狀態。
容錯移轉控制器(Failover Controller) 管理從 Active NameNode 到 Standby 的轉換。預設實作使用 ZooKeeper 來確保任何時候只有一個 NameNode 處於 Active 狀態。容錯移轉控制器在每個 NameNode 上作為輕量級程序運行,使用心跳監控 NameNode 的故障,並在 Active NameNode 失效時觸發容錯移轉。
兩種容錯移轉類型:
- 優雅容錯移轉(Graceful Failover):管理員手動發起的容錯移轉,用於例行維護。容錯移轉控制器安排從 Active NameNode 到 Standby 的有序轉換。
- 非優雅容錯移轉(Ungraceful Failover):無法確定故障的 NameNode 是否已停止運行。例如,緩慢的網路或網路分區可能觸發容錯移轉轉換,即使先前的 Active NameNode 仍在運行且認為自己仍是 Active。
隔離機制#
HA 實作使用隔離機制(Fencing) 來防止「腦裂」(Split-Brain)情境,確保先前的 Active NameNode 不會造成損害和資料損壞。
隔離的核心概念是在先前的 Active NameNode 周圍建立圍欄,使其無法存取叢集資源,從而停止處理任何讀寫請求。兩種隔離技術:
- 資源隔離(Resource Fencing):阻止先前的 Active NameNode 存取執行關鍵任務所需的資源。例如,撤銷其對共享儲存目錄的存取權限(通常使用供應商特定的 NFS 命令),或透過遠端管理命令停用其網路埠。
- 節點隔離(Node Fencing):阻止先前的 Active NameNode 存取所有資源。常見做法是關閉電源或重設節點。此技術也稱為 STONITH(Shoot The Other Node In The Head)。
stateDiagram-v2
[*] --> Standby: NameNode 啟動
state "待命狀態(Standby)" as Standby {
direction LR
state "ZKFC 健康監控中" as SHealth
state "同步 EditLog" as SSync
SHealth --> SSync: 持續同步
SSync --> SHealth
}
state "活躍狀態(Active)" as Active {
direction LR
state "ZKFC 健康監控中" as AHealth
state "處理客戶端請求" as AServe
AHealth --> AServe: 正常運作
AServe --> AHealth
}
state "故障狀態(Failed)" as Failed
Standby --> Active: ZKFC 取得 ZooKeeper 鎖\n(ZK Lock)且無其他 Active
Active --> Failed: ZKFC 偵測到\n健康檢查失敗
Failed --> Standby: NameNode 恢復後\n重新加入為 Standby
state "容錯移轉流程(Failover)" as Failover {
direction TB
state "ZKFC 偵測 Active 故障" as F1
state "隔離舊 Active(Fencing)" as F2
state "取得 ZooKeeper 鎖" as F3
state "提升 Standby 為 Active" as F4
F1 --> F2
F2 --> F3
F3 --> F4
}
Active --> Failover: Active NameNode\n心跳停止
Failover --> Active: Standby 晉升完成
note right of Active
ZKFC 透過 ZooKeeper
確保僅一個 Active
end note
note right of Failed
隔離機制防止
腦裂(Split-Brain)
end noteHDFS 特性#
安全性與權限#
HDFS 提供與 POSIX 類似的檔案和目錄權限模型。每個檔案和目錄都與一個擁有者(Owner)和群組(Group)關聯。檔案或目錄分別為擁有者、群組成員和其他使用者設定權限。三種權限類型:
| 權限 | 檔案 | 目錄 |
|---|---|---|
| 讀取(r) | 讀取檔案內容 | 列出目錄內容 |
| 寫入(w) | 寫入或追加檔案 | 建立或刪除其中的檔案或目錄 |
| 執行(x) | 被忽略(無法在 HDFS 上執行檔案) | 存取目錄的子項 |
HDFS 還提供可選的 POSIX ACL(Access Control Lists)支援,以更細粒度的規則為特定使用者或群組擴充檔案權限。
HDFS 聯邦#
NameNode 將整個命名空間的元資料保存在記憶體中,這意味著在擁有大量檔案的超大叢集上,記憶體會成為擴展的限制因素。更嚴重的問題是,單一 NameNode 處理所有元資料請求可能成為效能瓶頸。
為解決這些問題,Hadoop 2.x 版本引入了 HDFS 聯邦(HDFS Federation),允許叢集透過新增 NameNode 來擴展,每個 NameNode 管理檔案系統命名空間的一部分。例如,一個 NameNode 管理 /user 下的所有檔案,另一個 NameNode 處理 /share 下的檔案。
聯邦架構的特性:
- 所有 NameNode 獨立運作,NameNode 之間不需要協調
- DataNode 作為所有 NameNode 的共同儲存
- 一個 NameNode 故障不會影響其他 NameNode 管理的命名空間的可用性
- 客戶端使用客戶端掛載表(Client-Side Mount Table)將檔案路徑映射到 NameNode
多個獨立運行的 NameNode 可能為其區塊生成相同的 64 位元 Block ID。為避免此問題,每個命名空間使用一個或多個區塊池(Block Pool),每個區塊池在叢集中由唯一 ID 標識。區塊池屬於單一命名空間,不會跨越命名空間邊界。在 HDFS 聯邦中使用擴展區塊 ID(Block Pool ID, Block ID)的元組來識別區塊。
糾刪編碼#
預設情況下,HDFS 儲存每個區塊的三份副本,導致 200% 的儲存開銷。相比之下,糾刪編碼(Erasure Coding, EC) 是近年來 HDFS 最大的變化之一。EC 以更少的儲存空間提供相同等級的容錯能力。在典型的 EC 設定中,儲存開銷不超過 50%,從根本上將儲存空間容量翻倍,將複製因子從 3 倍降至 1.5 倍。
在 EC 模式下,資料被分解為片段,擴展並以冗餘資料編碼,然後儲存在不同的 DataNode 上。如果某個 DataNode 上的資料因損壞等原因遺失,可以從其他 DataNode 上儲存的片段重建。雖然 EC 比較消耗 CPU 資源,但大幅減少了可靠儲存大型資料集所需的儲存空間。
HDFS 實務應用#
雖然 HDFS 最初設計用於支援 Hadoop MapReduce 任務,但 HDFS 已被許多大數據工具廣泛使用,包括 Apache Pig、Hive、HBase 和 Giraph 等建立在 Hadoop 框架上的專案,以及 GraphLab 等其他專案。
主要優勢:
- MapReduce 工作負載的高頻寬:大型 Hadoop 叢集(數千台機器)能使用 HDFS 持續寫入高達每秒 1 TB 的資料
- 高可靠性:容錯是 HDFS 的首要設計目標。HDFS 複製提供高可靠性與可用性,特別是在磁碟和伺服器故障機率顯著增加的大型叢集中
- 每位元組低成本:與 SAN 等專用共享磁碟方案相比,HDFS 每 GB 成本更低,因為儲存與運算伺服器共置。HDFS 設計為使用商用硬體運行,冗餘由軟體管理
- 可擴展性:HDFS 允許在運行中的叢集中新增 DataNode,並提供手動重新平衡資料區塊的工具,無需關閉檔案系統
主要劣勢:
- 小檔案效率低:HDFS 設計用於大區塊(128 MB 及以上),將大檔案切割為區塊供 MapReduce 任務並行處理。當實際檔案很小時(KB 等級),HDFS 效率低下。大量小檔案會對維護所有檔案元資料的 NameNode 造成額外壓力。通常使用者會將小檔案合併為較大的檔案(如 Sequence File)
- 不符合 POSIX 標準:HDFS 不是 POSIX 相容的可掛載檔案系統,應用程式需要從頭編寫或修改以使用 HDFS 客戶端。雖然可透過 FUSE 驅動程式掛載 HDFS,但檔案系統語義不允許在檔案關閉後進行寫入
- 一次寫入模型:對於需要並行寫入同一檔案的應用程式,一次寫入模型是潛在的缺點。不過,最新版本的 HDFS 已支援檔案追加
總結而言,HDFS 適合作為遵循 MapReduce 模型或專門為 HDFS 編寫的分散式應用程式的儲存後端。HDFS 在處理少量大檔案時效率高,不適合處理大量小檔案。
總結#
系統設計模式#
以下為 HDFS 中使用的系統設計模式摘要:
- 預寫日誌(Write-Ahead Log):為了容錯和 NameNode 故障恢復,所有元資料變更都寫入磁碟上的 EditLog
- 心跳(Heartbeat):HDFS NameNode 定期與每個 DataNode 以心跳訊息通訊,傳遞指令並收集狀態
- 腦裂防護(Split-Brain):ZooKeeper 用於確保任何時候只有一個 NameNode 處於 Active 狀態。隔離機制用於防止先前的 Active NameNode 存取叢集資源
- 校驗和(Checksum):每個 DataNode 使用校驗和來偵測儲存資料的損壞