訊息系統簡介#
設計目標#
設計一個分散式訊息系統(Distributed Messaging System),能夠在不同實體之間可靠地傳輸高吞吐量的訊息。
背景#
分散式系統常見的挑戰之一,是處理來自多個來源的持續資料流入。以一個日誌彙整服務(Log Aggregation Service)為例,它每秒從不同來源接收數百筆日誌條目,需要將這些日誌儲存到共享伺服器的磁碟上,並建立索引以便日後搜尋。這個服務面臨以下挑戰:
- 如何處理訊息高峰? 如果服務能處理(或緩衝)每秒 500 筆訊息,當它開始接收更高數量的訊息時會發生什麼事?如果決定使用多個服務實例,如何分配工作?
- 如何接收來自不同類型來源的訊息? 產生和消費日誌的來源需要約定共同的協定和資料格式,這導致生產者和消費者之間的強耦合架構。
- 當日誌彙整服務停機或一段時間無回應時,日誌訊息會怎樣?
為了有效管理這類情境,分散式系統依賴 訊息系統(Messaging System)。
什麼是訊息系統?#

訊息系統
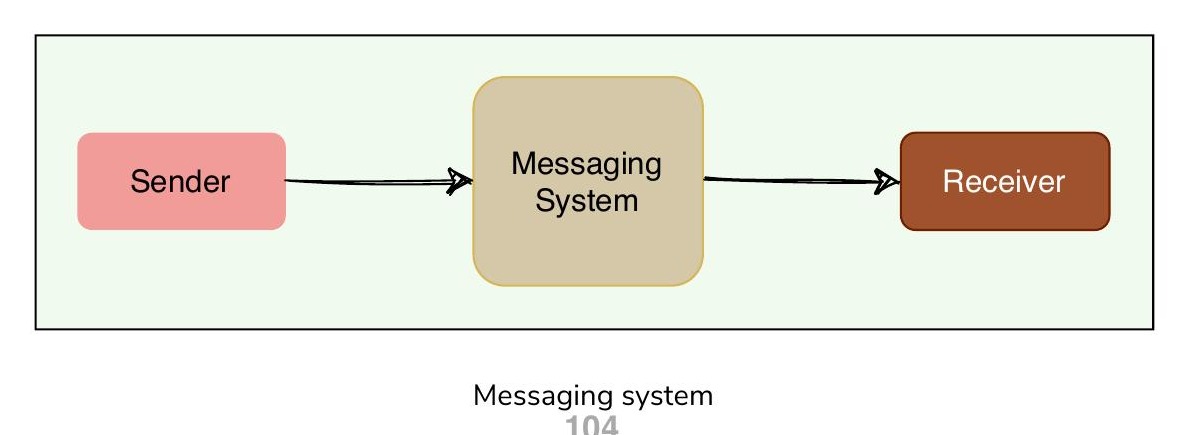
訊息系統負責在服務、應用程式、程序或伺服器之間傳輸資料。它透過提供非同步(Asynchronous)的訊息傳遞方式,幫助解耦分散式系統的不同部分。因此,所有 發送者(Producer) 和 接收者(Consumer) 只需專注於資料本身,無需擔心資料共享的機制。
處理訊息有兩種常見方式:佇列(Queue) 和 發布-訂閱(Publish-Subscribe)。
佇列#
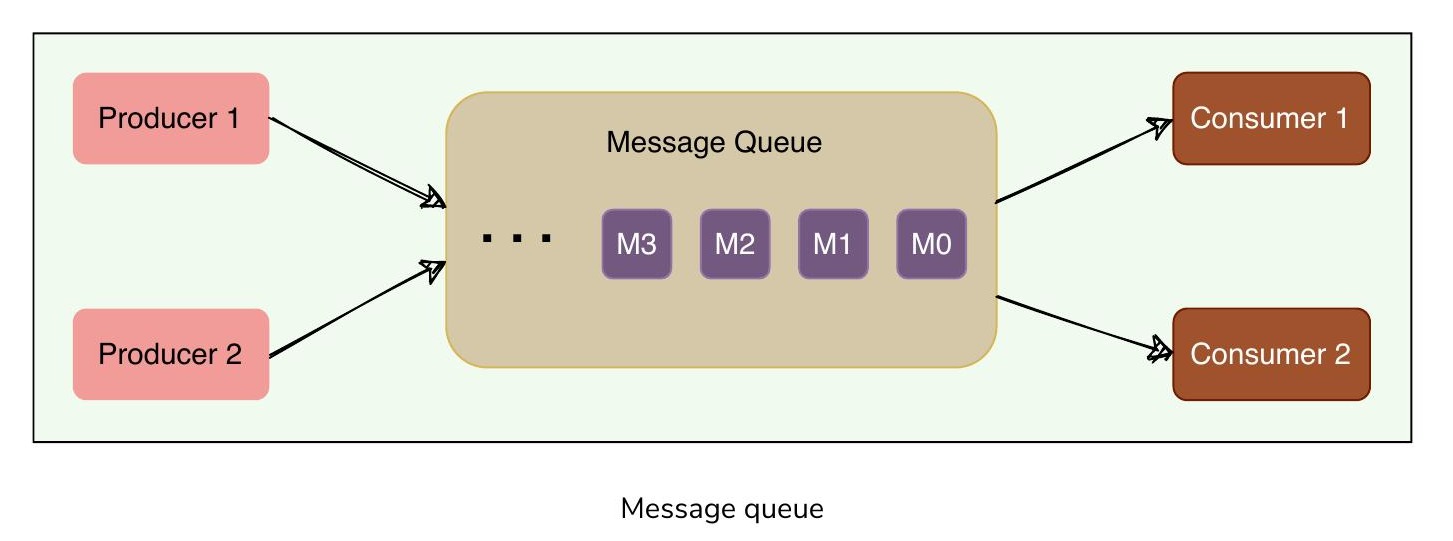
訊息佇列
在佇列模型中,訊息依序儲存在佇列中。生產者將訊息推送到佇列尾端,消費者從佇列前端取出訊息。
- 特定訊息最多只能被一個消費者消費
- 消費者取走訊息後,該訊息會從佇列中移除
- 適合在多個消費者之間分配訊息處理工作
- 限制在於多個消費者無法讀取佇列中的相同訊息
發布-訂閱訊息系統#
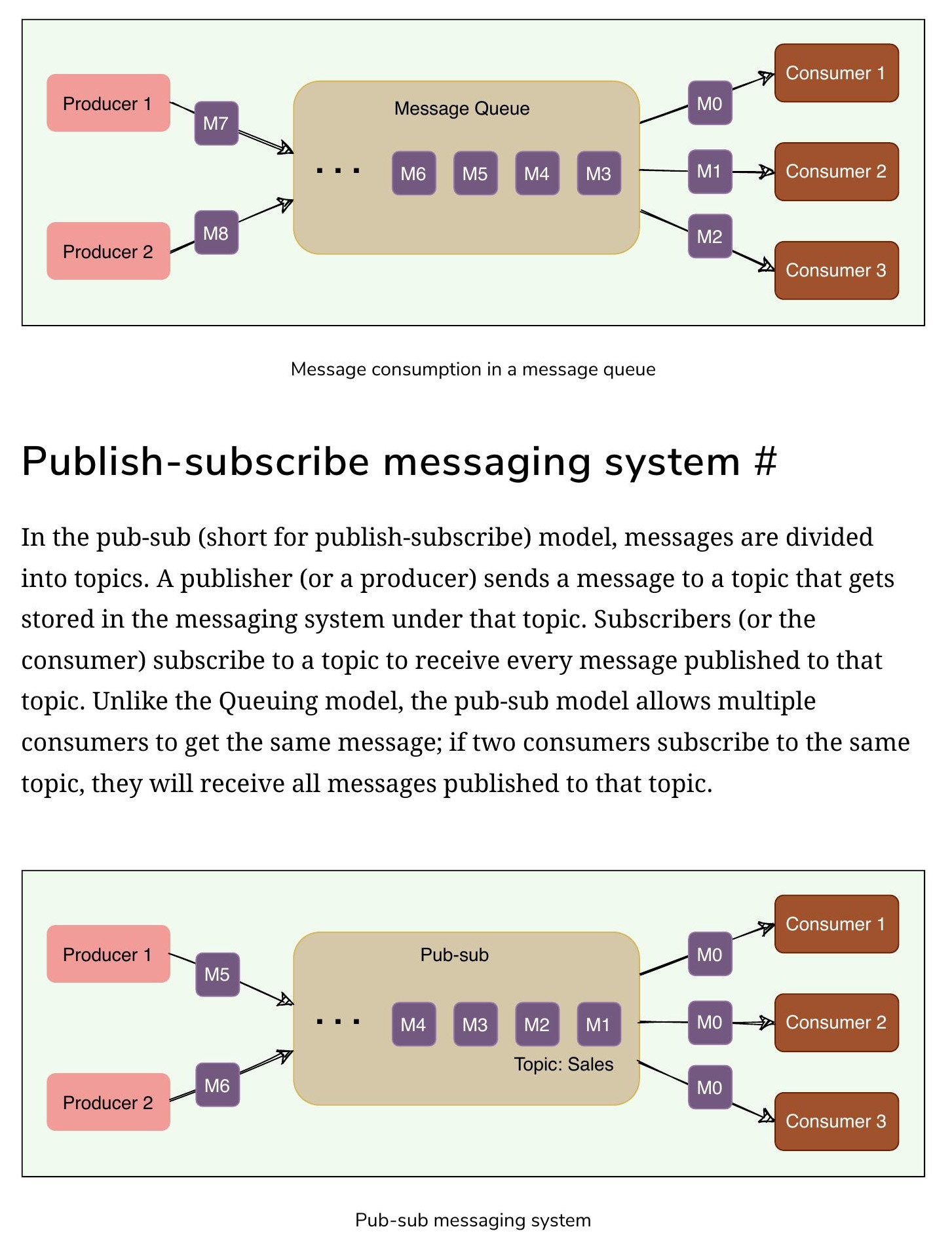
發布-訂閱訊息系統
在發布-訂閱(Pub-Sub)模型中,訊息被劃分為 主題(Topic)。發布者將訊息發送到某個主題,訂閱者訂閱該主題以接收每則發布的訊息。與佇列模型不同,Pub-Sub 模型允許多個消費者取得相同的訊息。
儲存和維護訊息的系統通常稱為 訊息代理(Message Broker)。它在發布者和訂閱者之間提供鬆耦合。
- 訊息代理將發布的訊息儲存在佇列中,訂閱者從中讀取
- 訂閱者和發布者不需要同步,可以以不同速率讀寫訊息
- 訊息系統儲存訊息的能力提供了容錯性(Fault-tolerance),訊息不會在產生和消費之間遺失
為什麼需要訊息系統?#
- 訊息緩衝(Message Buffering):在處理前提供緩衝機制,處理暫時性的訊息高峰,讓系統安全地暫存資料直到準備好處理
- 保證訊息傳遞(Guarantee of Message Delivery):即使消費端無法接收訊息,生產者也能確信訊息最終會被傳遞
- 提供抽象層(Abstraction):在訊息消費者和產生訊息的應用程式之間提供架構上的分離
- 實現擴展(Scale):提供靈活且高度可配置的架構,讓多個生產者能向多個消費者傳遞訊息
Kafka 簡介#
什麼是 Kafka?#
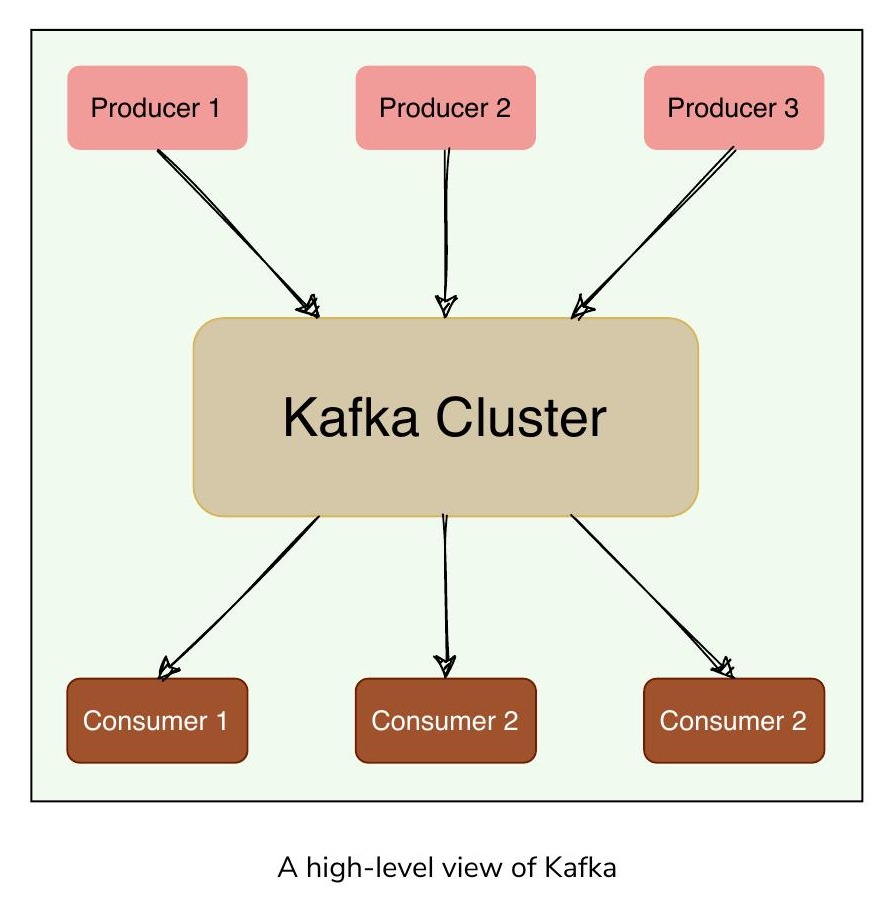
Apache Kafka 是一個開源的、基於發布-訂閱的訊息系統(也可以作為訊息佇列使用)。它具有分散式、持久化、容錯和高度可擴展的設計。本質上,它是一個系統,從被稱為生產者(Producer)的應用程式接收訊息串流,將其可靠地儲存在中央叢集(包含一組 Broker)上,並允許被稱為消費者(Consumer)的應用程式接收和處理這些訊息。
背景#
Kafka 大約在 2010 年由 LinkedIn 創建,用於追蹤各種事件,例如頁面瀏覽、訊息系統的訊息和各服務的日誌。後來它被開源並發展成為一個綜合系統,用於:
- 可靠地儲存大量資料
- 在不同實體之間實現高吞吐量的訊息傳輸
- 串流即時資料
在高層次上,可以將 Kafka 稱為 分散式提交日誌(Distributed Commit Log)。提交日誌(也稱為 Write-Ahead Log 或 Transaction Log)是一種 僅追加(Append-only) 的資料結構,可以持久地儲存一系列記錄。記錄總是被追加到日誌末端,一旦添加就無法刪除或修改。讀取提交日誌總是從左到右(從舊到新)。
Kafka 作為預寫日誌
Kafka 將所有訊息儲存在磁碟上。由於所有讀寫都是循序進行的,Kafka 利用了循序磁碟讀取(Sequential Disk Read)的優勢。
Kafka 的使用案例#
Kafka 可用於收集大數據和即時分析。以下是一些主要使用案例:
- 指標收集(Metrics):分散式服務可以將不同的運營指標推送到 Kafka 伺服器,然後從 Kafka 拉取以產生彙整統計資料
- 日誌彙整(Log Aggregation):從多個來源收集日誌,以標準格式提供給多個消費者
- 串流處理(Stream Processing):收集的資料在多個階段經歷處理,從主題消費的原始資料被轉換、enriched 或彙整後推送到新主題以供進一步消費
- 提交日誌(Commit Log):作為任何分散式系統的外部提交日誌,分散式服務可以記錄交易以追蹤狀態,這些資料可用於節點間複製和災難恢復
- 網站活動追蹤(Website Activity Tracking):Kafka 最初的使用案例之一,使用者的頁面點擊、搜尋等活動被發布到 Kafka 的不同主題中,可用於即時處理、即時監控或載入 Hadoop 等資料倉儲系統進行離線處理
- 商品推薦(Product Suggestions):追蹤消費者的搜尋查詢、商品點擊、在商品上花費的時間等行為,將這些活動記錄在 Kafka 中,消費者應用程式可以讀取這些訊息以找到相關商品進行即時推薦,或透過批次作業產生推薦電子郵件
高層架構#
Kafka 常見術語#
在深入了解 Kafka 的架構之前,先介紹一些常見術語。
Broker#
訊息代理
Kafka 伺服器也稱為 Broker。Broker 負責可靠地儲存生產者提供的資料,並將其提供給消費者。
Record(記錄)#
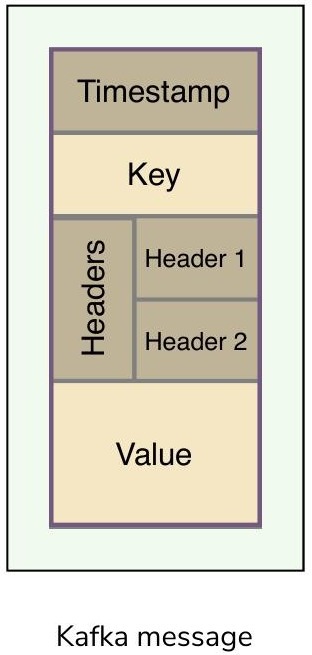
記錄(Record)是儲存在 Kafka 中的訊息或事件,本質上是從生產者經由 Kafka 傳遞到消費者的資料。一筆記錄包含:
- Key(鍵)
- Value(值)
- Timestamp(時間戳記)
- Headers(可選的中繼資料標頭)
Topic(主題)#
Kafka 將訊息劃分為稱為 Topic 的類別。簡單來說,主題就像資料庫中的表,訊息就是表中的列。
- 每則 Kafka 從生產者接收的訊息都與一個主題相關聯
- 消費者可以訂閱主題,以在新訊息添加時獲得通知
- 一個主題可以有多個訂閱者從中讀取訊息
- 在 Kafka 叢集中,主題由名稱識別且必須唯一
與傳統訊息系統不同,Kafka 中的訊息在消費後不會被刪除。Kafka 會保留訊息直到達到可配置的時間限制或儲存大小上限。Kafka 的效能相對於資料大小幾乎是恆定的,因此長時間儲存資料完全沒有問題。
Kafka 主題
Producer(生產者)#
生產者(Producer)是將記錄發布(或寫入)到 Kafka 的應用程式。
Consumer(消費者)#
消費者(Consumer)是訂閱(讀取和處理)Kafka 主題資料的應用程式。消費者訂閱一個或多個主題,透過從 Broker 拉取資料來消費已發布的訊息。
在 Kafka 中,生產者和消費者是完全解耦且彼此不感知的,這是實現 Kafka 高擴展性的關鍵設計要素。例如,生產者不需要等待消費者。
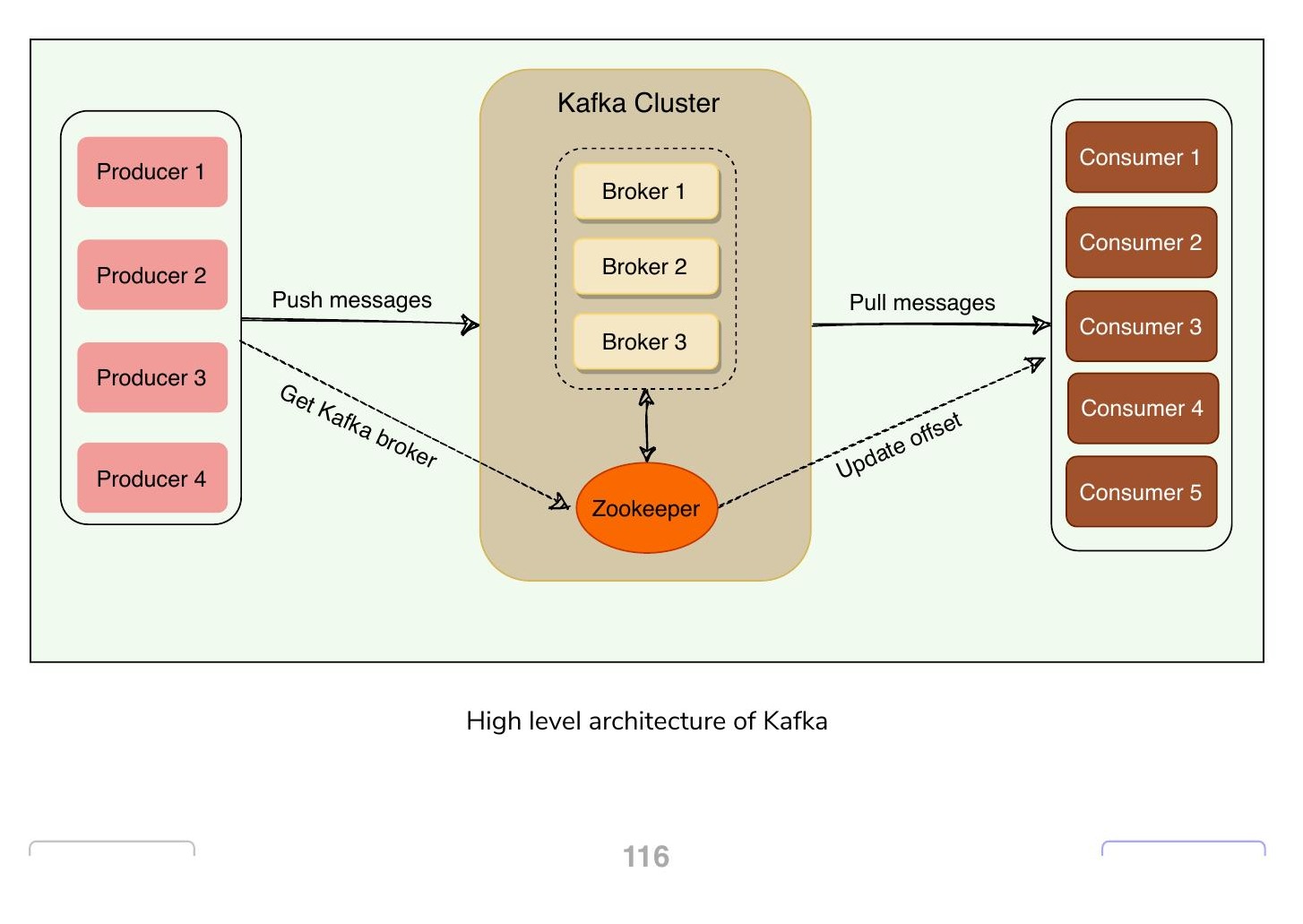
高層架構概覽#
在高層次上,應用程式(生產者)將訊息發送到 Kafka Broker,這些訊息被稱為消費者的其他應用程式讀取。訊息儲存在主題中,消費者訂閱主題以接收新訊息。
Kafka 叢集#
Kafka 作為一個由一台或多台伺服器組成的叢集運行,每台伺服器負責運行一個 Kafka Broker。
ZooKeeper#
ZooKeeper 是一個分散式鍵值存儲(Key-Value Store),用於協調和儲存配置資訊。它針對讀取操作進行了高度最佳化。Kafka 使用 ZooKeeper 在 Kafka Broker 之間進行協調;ZooKeeper 維護有關 Kafka 叢集的中繼資料資訊。
Kafka 高層架構
Kafka 深入探討#
Kafka 本質上是主題的集合。由於主題可能變得非常大,它們被分割成較小的 分區(Partition) 以獲得更好的效能和可擴展性。
主題分區(Topic Partition)#
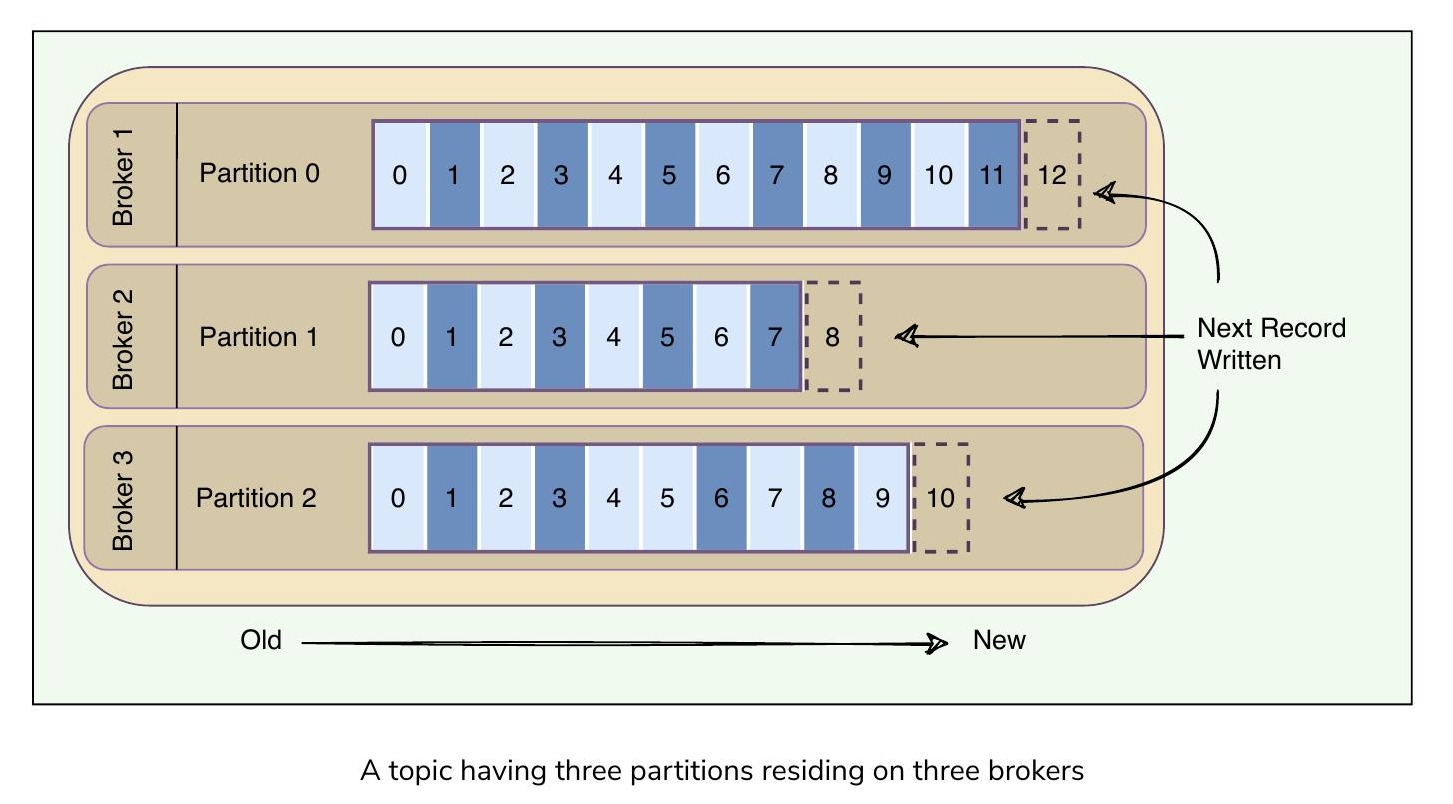
一個主題的三個分區分布在三個 Broker 上
Kafka 主題被分區,意味著主題分布在多個「片段」上。每個分區可以放置在不同的 Kafka Broker 上。當新訊息發布到主題時,它會被追加到主題的其中一個分區。生產者根據資料控制將訊息發布到哪個分區。
分區的關鍵特性:
- 分區本質上是一個有序的訊息序列,生產者持續將新訊息追加到分區中
- Kafka 保證分區內的所有訊息按照到達順序儲存
- 訊息排序僅在分區層級維護,而非跨整個主題
- 每條進入分區的訊息都會被分配一個稱為 偏移量(Offset) 的唯一序號,用於識別訊息在分區中的順序位置
- Offset 序號僅在每個分區內唯一,這表示要定位特定訊息,需要知道 Topic、Partition 和 Offset
- 如果不需要分區內的排序,可以使用輪詢(Round-robin)策略將記錄均勻分配到各分區
- 將每個分區放在不同的 Kafka Broker 上,使多個消費者能夠平行讀取同一主題
- 將主題的每個分區放在不同的 Broker 上,也使主題能夠容納超過單一伺服器容量的資料
- 寫入分區的訊息是 不可變的(Immutable),無法更新
- 生產者可以在訊息中加入「Key」,Kafka 保證具有相同 Key 的訊息會寫入同一分區
- 每個 Broker 管理屬於不同主題的一組分區
Kafka 遵循「笨代理、聰明消費者(Dumb Broker, Smart Consumer)」的原則。Kafka 不追蹤消費者讀取了哪些記錄,而是由消費者自行向 Kafka 輪詢新訊息並指定想讀取的記錄。消費者可以隨意遞增或遞減偏移量,從而能夠重播和重新處理訊息。消費者也可以在任何時間點加入叢集。
每個主題都可以被複製到多個 Kafka Broker 上,以實現資料的容錯和高可用性。每個主題分區有一個 Leader Broker 和多個 Replica(Follower)Broker。
Leader#
Leader 是負責處理給定分區所有讀寫操作的節點。每個分區有一個 Kafka Broker 充當 Leader。
Follower#
為了處理單點故障(Single Point of Failure),Kafka 可以複製分區並將它們分佈在多個稱為 Follower 的 Broker 伺服器上。每個 Follower 的職責是複製 Leader 的資料以作為「備份」分區。這也意味著任何 Follower 都可以在 Leader 宕機時接管領導權。
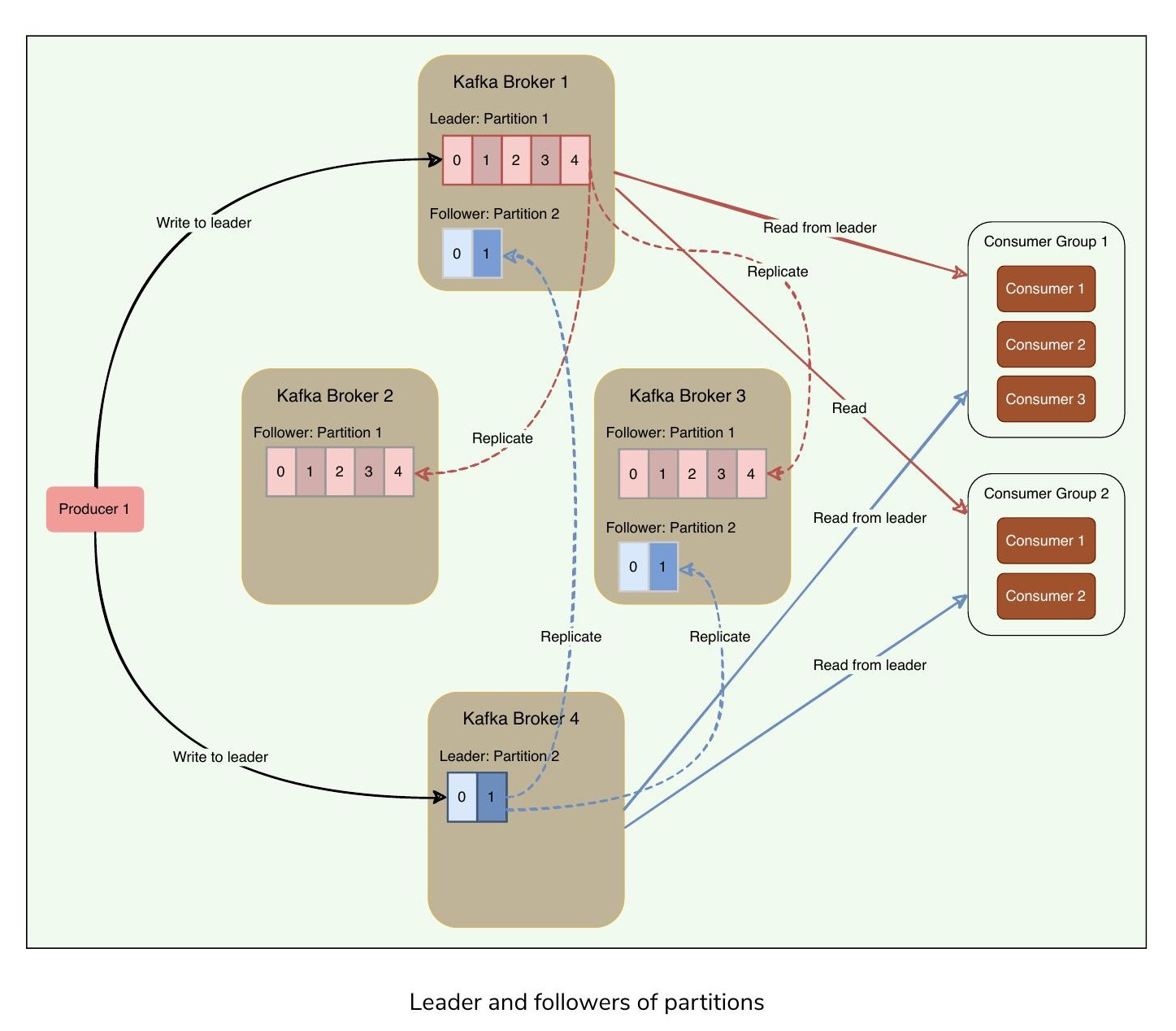
分區的 Leader 和 Follower
Kafka 在 ZooKeeper 中儲存每個分區 Leader 的位置。由於所有寫入和讀取都發生在 Leader 上,生產者和消費者會直接與 ZooKeeper 通訊以找到分區 Leader。
同步副本(In-Sync Replica, ISR)#
同步副本(ISR) 是擁有給定分區最新資料的 Broker。
- Leader 始終是同步副本
- Follower 只有在完全跟上它所跟隨的分區時,才是同步副本
- ISR 不能落後於給定分區的最新記錄
- 只有 ISR 有資格成為分區 Leader
- Kafka 可以設定資料對消費者可讀之前所需的最少 ISR 數量
高水位標記(High-Water Mark)#
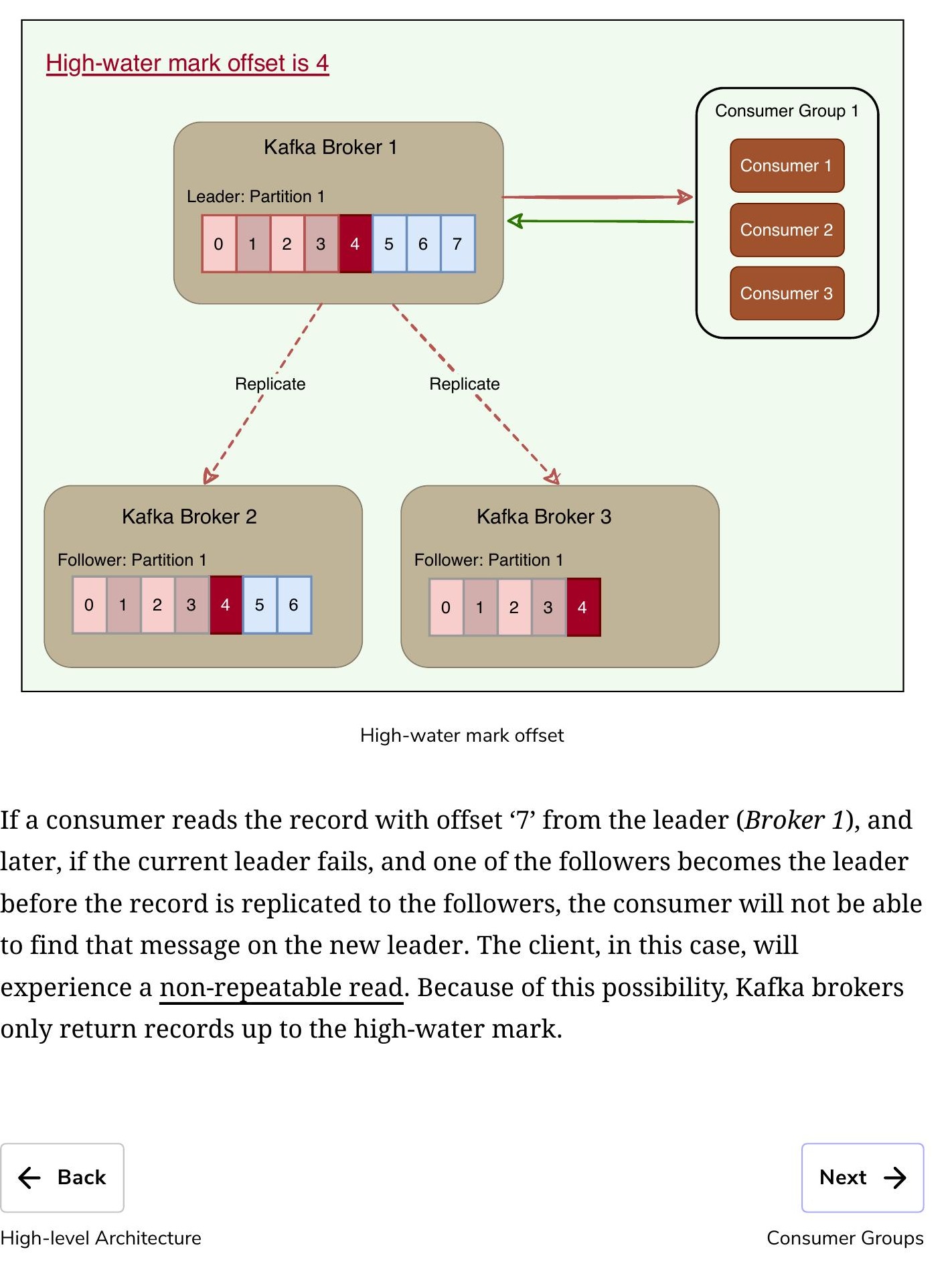
高水位標記偏移量
為了確保資料一致性,Leader Broker 永遠不會回傳尚未複製到最少 ISR 集合的訊息。為此,Broker 追蹤 高水位標記(High-Water Mark),即特定分區所有 ISR 共享的最高偏移量。Leader 只公開到高水位標記偏移量的資料,並將高水位標記偏移量傳播給所有 Follower。
如果消費者從 Leader 讀取了高水位標記以上的記錄,而當前 Leader 在 Follower 複製該記錄之前崩潰,新 Leader 上將找不到該訊息。這會導致消費者經歷不可重複讀取(Non-repeatable Read)。因此,Kafka Broker 只回傳到高水位標記為止的記錄。
消費者群組(Consumer Group)#
什麼是消費者群組?#
消費者群組是一組一個或多個消費者,共同平行消費主題分區中的訊息。訊息在群組的所有消費者之間均勻分配,沒有兩個消費者會接收到相同的訊息。
分區如何分配給消費者群組中的消費者#
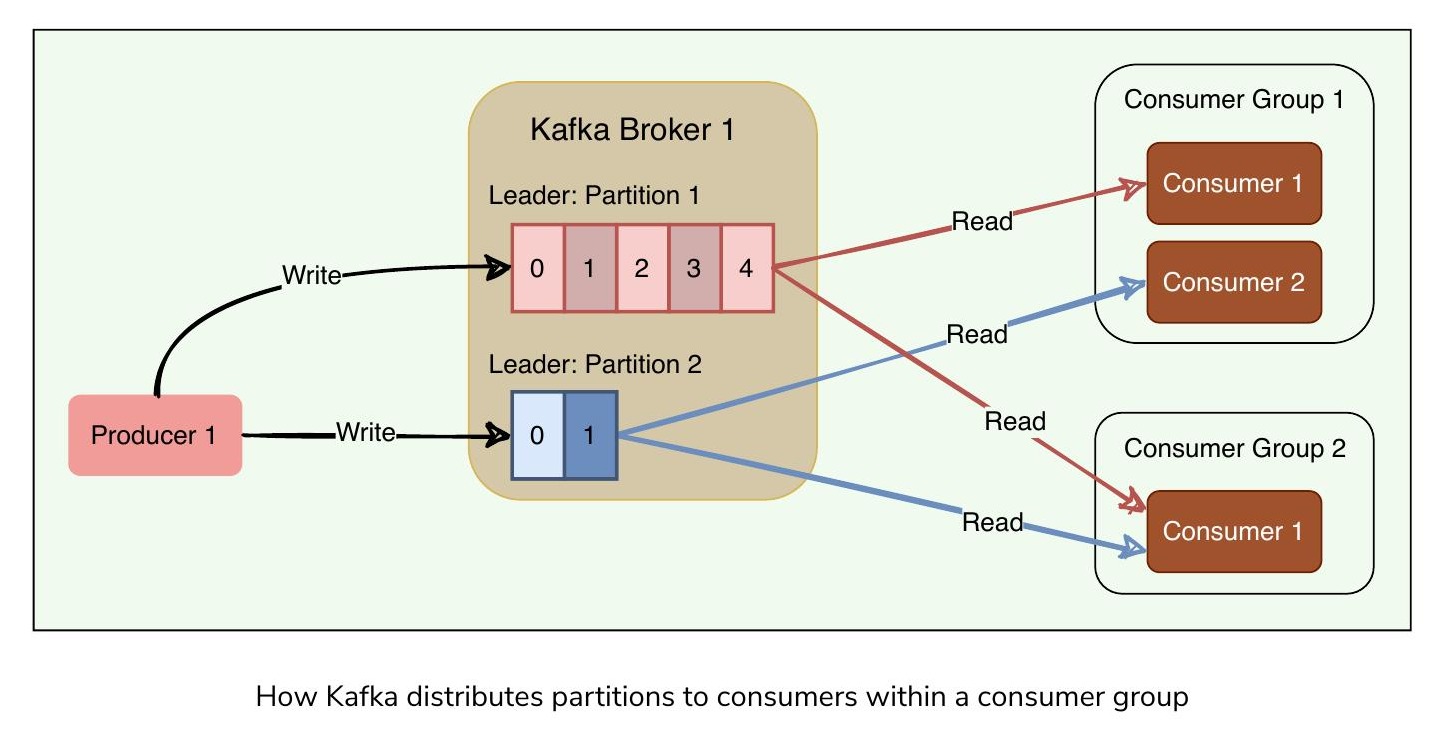
Kafka 如何將分區分配給消費者群組中的消費者
Kafka 確保在消費者群組中,只有一個消費者讀取任何分區的訊息。換句話說,主題分區是平行處理的單位 – 在消費者群組中,同一時間只有一個消費者可以處理一個分區。
- 如果消費者停止運行,Kafka 會將分區分配給同一群組中的其餘消費者
- 每次消費者被添加到群組或從群組中移除時,消費會在群組內重新平衡(Rebalance)
- 不同消費者可以負責不同的分區,支援非常高的訊息處理吞吐量
- 分區的數量影響消費者的最大平行度,因為消費者數量不能超過分區數量
Kafka 為每個消費者群組、每個主題、每個分區儲存當前偏移量。當消費者數量超過主題中的分區數量時,所有新消費者會處於閒置狀態,直到現有消費者取消訂閱該分區。
消費者群組中分區分配的摘要:
- 消費者數量 = 分區數量:每個消費者消費一個分區
- 消費者數量 > 分區數量:部分消費者將處於閒置狀態
- 消費者數量 < 分區數量:部分消費者將消費多於一個分區
Kafka 工作流程#
Kafka 以快速、可靠、持久化、容錯和零停機的方式,同時提供 Pub-Sub 和基於佇列的訊息系統。在兩種情況下,生產者只需將訊息發送到主題,消費者可以根據需求選擇任一種訊息系統。
Kafka 作為 Pub-Sub 訊息的工作流程#
以下是 Pub-Sub 訊息的逐步工作流程:
- 生產者將訊息發布到主題上
- Kafka Broker 將訊息儲存在為該主題配置的分區中。如果生產者未指定分區,Broker 確保訊息均勻分配到各分區
- 消費者訂閱特定主題
- 一旦消費者訂閱主題,Kafka 會提供該主題的當前偏移量給消費者,並將該偏移量儲存在 ZooKeeper 中
- 消費者定期向 Kafka 請求新訊息
- Kafka 收到生產者的訊息後,將這些訊息轉發給消費者
- 消費者接收並處理訊息
- 訊息處理完成後,消費者向 Kafka Broker 發送確認(Acknowledgment)
- 收到確認後,Kafka 遞增偏移量並在 ZooKeeper 中更新。由於偏移量維護在 ZooKeeper 中,即使在 Broker 中斷期間消費者也能正確讀取下一則訊息
- 消費者可以隨時倒退或跳到主題的任何偏移量,讀取所有後續訊息
sequenceDiagram
participant P as 生產者 (Producer)
participant B as Broker (主題 T1)
participant ZK as ZooKeeper
participant C as 消費者 (Consumer)
Note over P, C: Pub-Sub 訊息工作流程
P->>B: 1. 發布訊息到主題 T1
B->>B: 2. 儲存訊息到分區 (Partition)
C->>B: 3. 訂閱主題 T1
B->>C: 4. 提供當前偏移量 (Offset)
B->>ZK: 4. 儲存偏移量到 ZooKeeper
C->>B: 5. 定期請求新訊息 (Poll)
P->>B: 6. 生產者持續發送新訊息
B->>C: 6. 轉發新訊息給消費者
C->>C: 7. 接收並處理訊息
C->>B: 8. 發送確認 (Acknowledgment)
B->>ZK: 9. 遞增偏移量並更新 ZooKeeper
Note over C: 10. 消費者可隨時倒退或跳到任意偏移量Kafka 消費者群組的工作流程#
消費者群組中的一組消費者訂閱一個主題,訊息在它們之間共享:
- 生產者將訊息發布到主題上
- Kafka 將所有訊息儲存在為該主題配置的分區中
- 單一消費者以某個 Group ID 訂閱特定主題
- Kafka 以 Pub-Sub 的方式與消費者互動,直到有新消費者以相同的 Group ID 訂閱同一主題
- 新消費者到達後,Kafka 切換到共享模式,每則訊息只傳遞給消費者群組中的一個訂閱者。這類似於基於佇列的訊息傳遞,但訊息不會在消費後被移除
- 訊息傳遞可以持續進行,直到消費者數量達到該主題配置的分區數量
- 一旦消費者數量超過分區數量,新消費者將不會收到任何訊息,直到現有消費者取消訂閱
sequenceDiagram
participant P as 生產者 (Producer)
participant B as Broker (主題 T1)
participant C1 as 消費者 C1 (Group G1)
participant C2 as 消費者 C2 (Group G1)
Note over P, C2: 消費者群組 (Consumer Group) 工作流程
P->>B: 1. 發布訊息到主題 T1
B->>B: 2. 儲存訊息到分區 (Partition)
C1->>B: 3. 以 Group ID = G1 訂閱主題 T1
B->>C1: 4. 以 Pub-Sub 方式傳遞訊息給 C1
C2->>B: 5. 新消費者 C2 以相同 Group ID = G1 訂閱
Note over B: 切換為共享模式 (Queue Mode)
B->>C1: 6a. 訊息分配給 C1 (分區 P0)
B->>C2: 6b. 訊息分配給 C2 (分區 P1)
Note over C1, C2: 每則訊息只傳遞給群組中的一個消費者
Note over B: 7. 消費者數量超過分區數量時,<br/>新消費者將處於閒置狀態ZooKeeper 的角色#
什麼是 ZooKeeper?#
Apache Kafka 的一個關鍵依賴是 Apache ZooKeeper,它是一個分散式配置和同步服務。ZooKeeper 作為 Kafka Broker、生產者和消費者之間的協調介面。Kafka 在 ZooKeeper 中儲存基本的中繼資料,例如 Broker、主題、分區、分區 Leader/Follower、消費者偏移量等資訊。
ZooKeeper 作為中央協調者#
Kafka Broker 是無狀態的(Stateless),它們依賴 ZooKeeper 來維護和協調 Broker,例如:
- 通知消費者和生產者新 Broker 的到達或現有 Broker 的故障
- 將所有請求路由到分區 Leader
ZooKeeper 用於儲存有關 Kafka 叢集的各種中繼資料:
- 維護每個消費者群組在每個分區的最後偏移量位置,以便消費者在故障時能從最後的位置快速恢復(現代客戶端將偏移量儲存在單獨的 Kafka 主題中)
- 追蹤主題、分配給主題的分區數量,以及每個分區中 Leader 和 Follower 的位置
- 管理叢集中不同主題的存取控制清單(ACL),用於執行存取或授權控制
生產者或消費者如何找到分區的 Leader?#
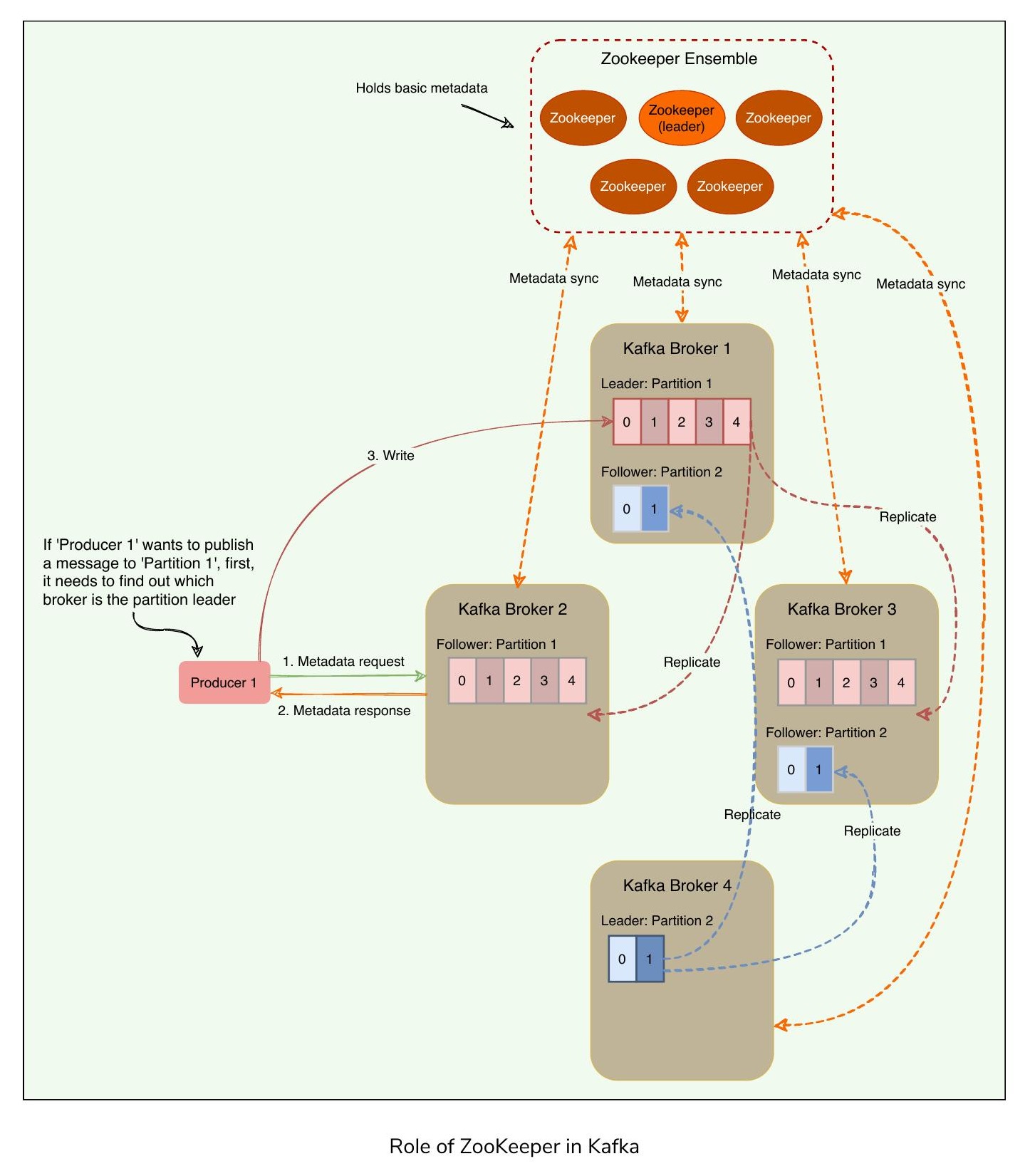
ZooKeeper 在 Kafka 中的角色
在較舊版本的 Kafka 中,所有客戶端(生產者和消費者)直接與 ZooKeeper 通訊以找到分區 Leader。Kafka 已經擺脫了這種耦合,在最新版本中,客戶端直接從 Kafka Broker 獲取中繼資料資訊;Broker 與 ZooKeeper 通訊以獲取最新的中繼資料。
生產者在發布訊息之前經歷以下步驟:
- 生產者連接到任何 Broker 並詢問某分區的 Leader 是誰
- Broker 回應負責該分區的 Leader Broker 的識別資訊
- 生產者連接到 Leader Broker 以發布訊息
sequenceDiagram
participant P as 生產者 (Producer)
participant B as 任意 Broker
participant ZK as ZooKeeper
participant L as Leader Broker
Note over P, L: 尋找分區 Leader (Finding Partition Leader)
P->>B: 1. 發送中繼資料請求 (Metadata Request):<br/>「分區 P0 的 Leader 是誰?」
B->>ZK: 查詢分區中繼資料
ZK-->>B: 回傳 Leader 資訊
B->>P: 2. 回應分區 Leader Broker 的識別資訊
P->>L: 3. 連接到 Leader Broker 發布訊息
L->>L: 儲存訊息到分區所有關鍵資訊都儲存在 ZooKeeper 中,並在其叢集間複製。因此,Kafka Broker(或 ZooKeeper 本身)的故障不會影響 Kafka 叢集的狀態。ZooKeeper 故障後,Kafka 總是能在 ZooKeeper 重啟後恢復狀態。ZooKeeper 還負責在 Leader 故障時協調 Kafka Broker 之間的分區 Leader 選舉。
控制器 Broker(Controller Broker)#
什麼是控制器 Broker?#
在 Kafka 叢集中,一個 Broker 被選舉為 控制器(Controller)。控制器 Broker 負責管理操作,例如:
- 建立或刪除主題
- 添加分區
- 為分區分配 Leader
- 監控 Broker 故障
此外,控制器會定期檢查系統中其他 Broker 的健康狀態。如果未收到特定 Broker 的回應,它會執行故障轉移(Failover)到另一個 Broker。它還會將分區 Leader 選舉的結果通知系統中的其他 Broker。
腦裂(Split Brain)#
當控制器 Broker 宕機時,Kafka 會選舉新的控制器。問題在於我們無法確切知道 Leader 是永久停止,還是只是經歷了間歇性故障(例如 Stop-the-World GC 暫停或臨時網路中斷)。然而叢集必須繼續運行並選擇新的控制器。
如果原始控制器只是間歇性故障,叢集最終會出現所謂的 殭屍控制器(Zombie Controller) – 一個先前被叢集判定為已死亡但又重新上線的控制器節點。另一個 Broker 已取代了它的位置,但殭屍控制器可能還不知道這件事。這種分散式系統中有兩個或更多活躍控制器的常見情境稱為 腦裂(Split Brain)。
世代時鐘(Generation Clock)#
腦裂通常透過 世代時鐘(Generation Clock) 來解決,它是一個單調遞增的數字,用於表示伺服器的世代。在 Kafka 中,世代時鐘透過 Epoch 編號 實現。
- 如果舊的 Leader 的 Epoch 編號為「1」,新的 Leader 將為「2」
- 這個 Epoch 包含在控制器發送給其他 Broker 的每個請求中
- Broker 可以透過信任具有最高編號的控制器來輕鬆區分真正的控制器
- 具有最高編號的控制器無疑是最新的,因為 Epoch 編號總是遞增的
- 此 Epoch 編號儲存在 ZooKeeper 中
sequenceDiagram
participant C1 as 舊控制器 (Controller Epoch=1)
participant ZK as ZooKeeper
participant C2 as 新控制器 (Controller Epoch=2)
participant B as Broker
Note over C1, B: 腦裂場景 (Split Brain Scenario)
C1->>B: 正常運作:發送指令 (Epoch=1)
B->>B: 接受指令 (Epoch=1)
Note over C1: 控制器暫時失去回應<br/>(GC 暫停 / 網路中斷)
ZK->>ZK: 偵測到控制器失效
ZK->>C2: 選舉新控制器 (Epoch=2)
C2->>B: 發送指令 (Epoch=2)
B->>B: 接受指令,更新已知最高 Epoch=2
Note over C1: 舊控制器恢復 (殭屍控制器 Zombie)
C1->>B: 發送指令 (Epoch=1)
B--xC1: 拒絕!Epoch=1 < 已知最高 Epoch=2
Note over B: Broker 只信任最高 Epoch 的控制器
C2->>B: 發送指令 (Epoch=2)
B->>B: 接受指令 (Epoch=2)Kafka 傳遞語義(Delivery Semantics)#
生產者傳遞語義#
生產者只向 Leader Broker 寫入,Follower 非同步複製資料。Kafka 提供三種選項來表示在生產者認為寫入成功之前必須收到記錄的 Broker 數量:
非同步(Async):生產者發送訊息後不等待確認。寫入在請求發出的那一刻就被視為成功。這種「發送即忘」的方式提供最佳效能,可以以網路速度寫入 Kafka,但無法保證伺服器已收到記錄。
Leader 已提交(Committed to Leader):生產者等待 Leader 的確認。確保資料在 Leader 上被提交,比非同步選項慢。Leader 不等待 Follower 的確認就回應。如果 Leader 在確認生產者後、Follower 複製之前崩潰,記錄將會遺失。
Leader 和 Quorum 已提交(Committed to Leader and Quorum):生產者等待 Leader 和 Quorum 的確認。Leader 會等待全部同步副本確認記錄。這是最慢的寫入方式,但保證只要至少有一個同步副本存活,記錄就不會遺失。這是最強的可用保證。
如果希望確保記錄安全地儲存在 Kafka 中,應選擇最後一個選項「Leader 和 Quorum 已提交」。如果更重視延遲和吞吐量而非持久性,可以選擇前兩個選項,它們有更大的訊息遺失機會但速度和吞吐量更好。
消費者傳遞語義#
消費者只能讀取已寫入同步副本集的訊息。有三種方式為消費者提供一致性:
至多一次(At-most-once):訊息可能遺失但不會被重複傳遞。消費者收到訊息後立即提交偏移量。如果消費者在完全消費訊息前崩潰,該訊息將遺失,因為重啟後消費者將從最後提交的偏移量接收下一則訊息。
至少一次(At-least-once):訊息不會遺失但可能被重複傳遞。消費者收到訊息後不立即提交偏移量,而是等到完成處理。如果消費者在處理後、提交偏移量前崩潰,它必須在重啟時重新讀取訊息,因此可能發生重複訊息傳遞。
恰好一次(Exactly-once):每則訊息恰好傳遞一次。除非消費者使用交易系統,否則很難實現。消費者將訊息處理和偏移量遞增放在一個交易(Transaction)中。如果消費者在處理時崩潰,交易會被回滾,偏移量不會遞增。此選項不會導致資料重複或遺失,但可能降低吞吐量。
Kafka 特性#
訊息儲存到磁碟#
Kafka 將訊息寫入本機磁碟,不在 RAM 中保留任何內容。磁碟儲存對持久性很重要,確保系統重啟後訊息不會消失。
隨機區塊存取和循序存取之間存在巨大的效能差異。隨機區塊存取因大量磁碟尋址(Disk Seek)而較慢,而循序寫入或讀取使磁碟操作比隨機存取快數千倍。由於 Kafka 的所有寫入和讀取都是循序進行的,所以具有非常高的吞吐量。
作業系統透過以下技術對循序讀寫進行最佳化:
- 預讀取(Read-ahead):預取大區塊的資料
- 延遲寫入(Write-behind):將小的邏輯寫入組合成大的物理寫入
此外,現代作業系統會將磁碟快取在空閒的 RAM 中,這稱為 頁面快取(Pagecache)。由於 Kafka 在整個流程(生產者到 Broker 到消費者)中以不變的標準二進位格式儲存訊息,它可以利用 零拷貝(Zero-copy) 最佳化 – 作業系統直接從 Pagecache 將資料複製到 Socket,完全繞過 Kafka Broker 應用程式。
Kafka 還有一個將訊息分組的協定,允許網路請求將訊息組合在一起,減少網路開銷。伺服器一次持久化整組訊息,消費者一次獲取大量的線性區塊。
這些最佳化使 Kafka 能夠以接近網路速度的速率傳遞訊息。
Kafka 中的記錄保留#
預設情況下,Kafka 會保留記錄直到磁碟空間用盡。可以設定以下保留策略:
- 基於時間的限制:可配置的保留期間(例如三天、兩週、一個月等)
- 基於大小的限制:根據大小配置
- 壓縮(Compaction):使用 Key 保留記錄的最新版本
客戶端配額(Client Quota)#
Kafka 的生產者和消費者可能產生或消費大量資料,或以非常高的速率產生請求,從而獨佔 Broker 資源、導致網路飽和,並對其他客戶端造成服務拒絕。配額可以防止這些問題,在大型多租戶叢集中尤其重要。
- 在 Kafka 中,配額是根據 Client-ID 定義的位元組速率閾值
- Client-ID 在邏輯上識別一個發出請求的應用程式
- 單一 Client-ID 可以跨越多個生產者和消費者實例,配額作為單一實體應用於所有實例
- 當客戶端超過配額時,Broker 不會回傳錯誤,而是透過延遲客戶端的回應來減慢客戶端速度,使配額違規對客戶端透明
Kafka 效能#
以下是 Kafka 高效能的幾個原因:
可擴展性(Scalability):
- Kafka 叢集可以在運行中且不停機的情況下輕鬆擴展或縮減(添加或移除 Broker)
- Kafka 主題可以擴展為包含更多分區。由於分區無法跨越多個 Broker,其容量受限於 Broker 磁碟空間,但可以增加分區數量和 Broker 數量,使單一主題的資料儲存沒有上限
容錯性和可靠性(Fault-tolerance and Reliability):Kafka 設計為 Broker 故障可被 ZooKeeper 和叢集中的其他 Broker 偵測到。由於每個主題可以在多個 Broker 上複製,叢集可以從 Broker 故障中恢復並繼續正常運作
高吞吐量(Throughput):透過消費者群組,消費者可以平行化,多個消費者可以從主題的多個分區讀取,實現非常高的訊息處理吞吐量
低延遲(Low Latency):99.99% 的時間,資料從磁碟快取和 RAM 中讀取,極少數情況才會命中磁碟
總結#
- Kafka 提供低延遲、高吞吐量、容錯的發布和訂閱管線,可以處理巨大的持續事件串流
- Kafka 可以同時作為訊息佇列和發布-訂閱系統
- 在高層次上,Kafka 作為分散式提交日誌運作
- Kafka 伺服器也稱為 Broker,Kafka 叢集可以有一個或多個 Broker
- Kafka 主題是訊息的邏輯聚合
- Kafka 透過將主題分割成多個分區來解決訊息系統的擴展問題
- 每個主題分區都會被複製以實現容錯和冗餘
- 一個分區有一個 Leader 副本和零個或多個 Follower 副本
- 分區 Leader 負責所有讀寫操作,每個 Follower 的職責是複製 Leader 的資料以作為備份分區
- 訊息排序僅在每個分區的基礎上保持,而非跨主題的分區
- 每個分區副本需要位於一個 Broker 上,分區無法分割在多個 Broker 上
- 每個 Broker 可以有一個或多個 Leader,涵蓋不同的分區和主題
- Kafka 透過啟用消費者群組來支援單一佇列模式和多讀取者模式
- Kafka 透過允許消費者訂閱主題來支援發布-訂閱模式
- ZooKeeper 作為集中式配置管理服務
系統設計模式#
以下是 Kafka 中使用的系統設計模式摘要:
高水位標記(High-Water Mark):為了處理不可重複讀取並確保資料一致性,Broker 追蹤高水位標記,即特定分區所有 ISR 共享的最大偏移量。消費者只能看到到高水位標記為止的訊息。
Leader 和 Follower:每個 Kafka 分區都有一個指定的 Leader 負責所有讀寫操作。每個 Follower 的職責是複製 Leader 的資料以作為備份分區。
腦裂(Split Brain):為了處理有多個活躍控制器 Broker 的腦裂問題,Kafka 使用「Epoch 編號」,這是一個單調遞增的數字來表示伺服器的世代。Broker 透過信任具有最高編號的控制器來區分真正的控制器。此 Epoch 編號儲存在 ZooKeeper 中。
分段日誌(Segmented Log):Kafka 使用日誌分段來實現其分區的儲存。由於 Kafka 經常需要在磁碟上查找訊息以進行清除,單一的長檔案可能成為效能瓶頸且容易出錯。為了更容易管理和獲得更好的效能,分區被分割成段(Segment)。