Dynamo 簡介#
Dynamo 是由 Amazon 為其內部服務所開發的高可用鍵值儲存系統(Key-Value Store)。Amazon 許多服務(如購物車、暢銷榜、銷售排名、產品目錄等)僅需要透過主鍵(Primary Key)存取資料。對這類服務而言,使用多表關聯式資料庫不僅大材小用,還會限制可擴展性(Scalability)與可用性(Availability)。Dynamo 提供了靈活的設計,讓應用程式可以根據需求選擇所需的可用性與一致性等級。
Dynamo 與 DynamoDB 不同。DynamoDB 是 Amazon 後來受 Dynamo 設計啟發而推出的公開雲端服務。
設計目標#
Dynamo 的核心設計目標是高可用性。以下為其他重要設計目標:
- 可擴展(Scalable):系統應具備高度可擴展性,加入新機器後即可看到效能等比提升。
- 去中心化(Decentralized):為了避免單點故障(Single Point of Failure)與效能瓶頸,系統中不應存在任何中心化或領導者節點。
- 最終一致性(Eventually Consistent):資料可以透過樂觀複製(Optimistic Replication)達到最終一致。這意味著系統不需要在寫入時付出代價來確保全域一致性(Strong Consistency),而是在其他時間點(例如讀取時)解決不一致問題。
背景#
在 CAP 定理(CAP Theorem)中,Dynamo 屬於 AP 系統(可用性 + 分區容錯性),以犧牲強一致性來換取高可用性與分區容錯性。
設計 Dynamo 為高可用系統的主要動機來自一個觀察:系統的可用性與服務的客戶數量直接相關。即使系統存在不完美,只要能持續回應客戶請求,就能帶來更高的客戶滿意度。另一方面,不一致性可以在背景中解決,且大多數時候客戶不會察覺。基於此核心原則,Dynamo 對可用性進行了極致的最佳化。
Dynamo 的設計影響深遠,啟發了許多 NoSQL 資料庫,包括 Cassandra、Riak、Voldemort,以及 Amazon 自家的 DynamoDB。
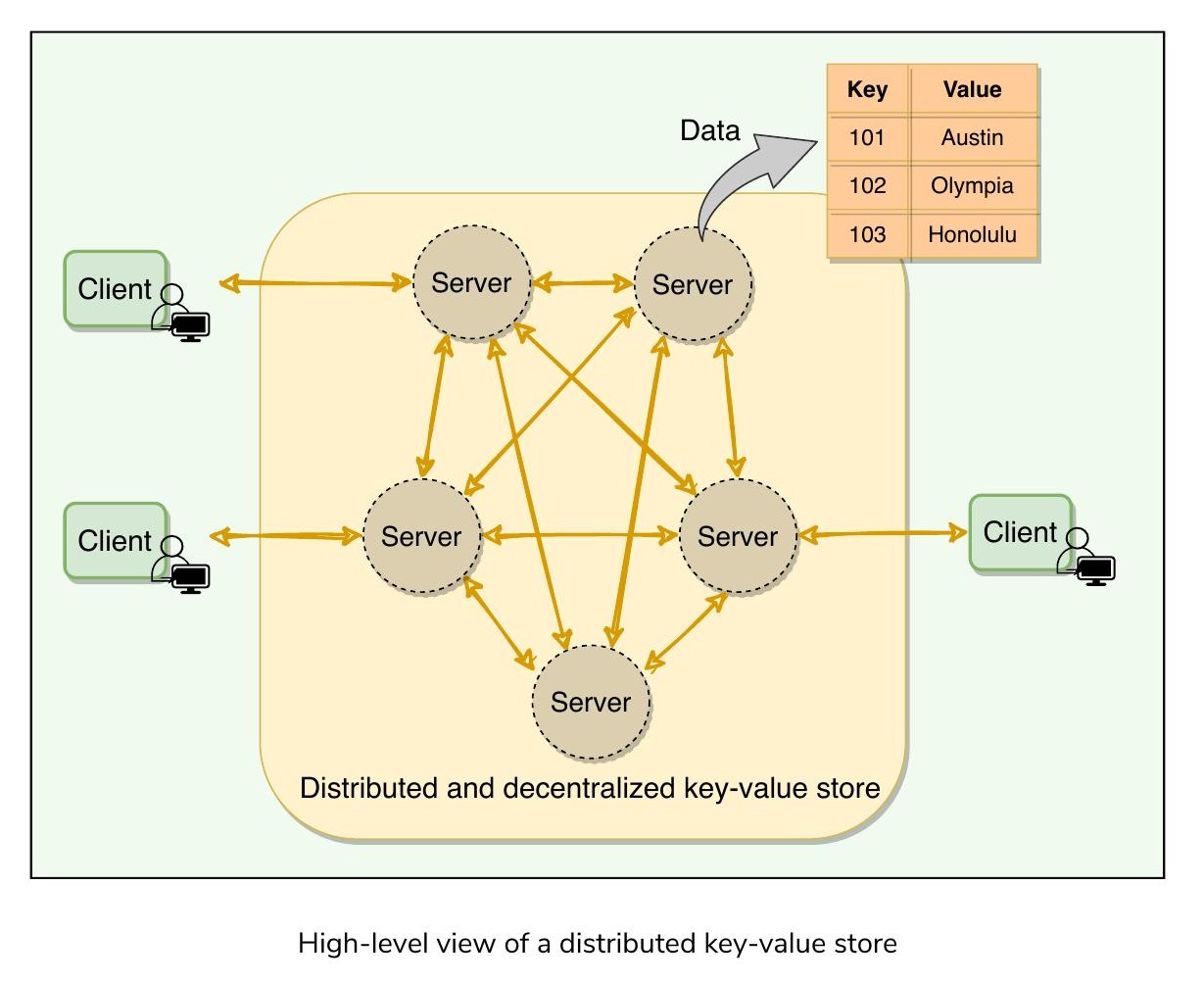
分散式鍵值儲存系統的高層架構
Dynamo 的使用場景#
- Dynamo 預設是最終一致性資料庫,適用於不需要強一致性的應用場景。
- 雖然 Dynamo 可支援強一致性,但會帶來效能影響。
- Amazon 平台上許多服務僅需主鍵存取資料,使用關聯式資料庫會造成效率低落並限制擴展性。Dynamo 提供了簡單的主鍵介面來滿足這些需求。
- Amazon 使用 Dynamo 來管理對可靠性要求極高、且需精細控制可用性、一致性、成本效益與效能之間取捨的服務。
系統 API#
Dynamo 的客戶端使用 put() 和 get() 操作來寫入和讀取資料:
get(key):根據給定的鍵找到儲存物件的節點,回傳單一物件或多個衝突版本的物件列表,並附帶一個上下文(Context)。上下文包含物件的編碼元資料(如版本資訊),對呼叫者而言是不透明的。put(key, context, object):找到應儲存該鍵的節點並寫入物件。上下文是透過get()操作取得後再傳回put()操作的值,用於驗證請求的有效性。
Dynamo 將鍵和值都視為任意的位元組陣列(通常小於 1 MB)。它對鍵套用 MD5 雜湊演算法,產生 128 位元的識別碼,用以決定負責該鍵的儲存節點。
高層架構#
在高層次上,Dynamo 是一個分散式雜湊表(Distributed Hash Table, DHT),透過叢集複製來實現高可用性與容錯能力。
Dynamo 的架構可概述如下:
- 資料分區(Data Distribution):使用一致性雜湊(Consistent Hashing)在節點間分配資料,並使新增或移除節點更加容易。
- 資料複製與一致性(Data Replication and Consistency):資料以樂觀方式複製,提供最終一致性模型。
- 暫時性故障處理(Handling Temporary Failures):使用寬鬆法定人數(Sloppy Quorum)來複製資料,而非嚴格多數法定人數。
- 節點間通訊與故障偵測(Inter-node Communication and Failure Detection):節點使用八卦協定(Gossip Protocol)追蹤叢集狀態。
- 高可用性(High Availability):透過提示交接(Hinted Handoff)使系統「永遠可寫入」。
- 衝突解決與永久性故障處理(Conflict Resolution and Handling Permanent Failures):使用向量時鐘(Vector Clocks)追蹤值的歷史並在讀取時調和分歧;在背景中使用 Merkle 樹(Merkle Trees)處理永久性故障。
資料分區#
什麼是資料分區?#
資料分區(Data Partitioning)是將資料分散到一組節點上的行為。分配資料時面臨兩個挑戰:
- 如何知道某筆資料儲存在哪個節點上?
- 新增或移除節點時,如何得知哪些資料需要遷移?如何將資料遷移量降到最低?
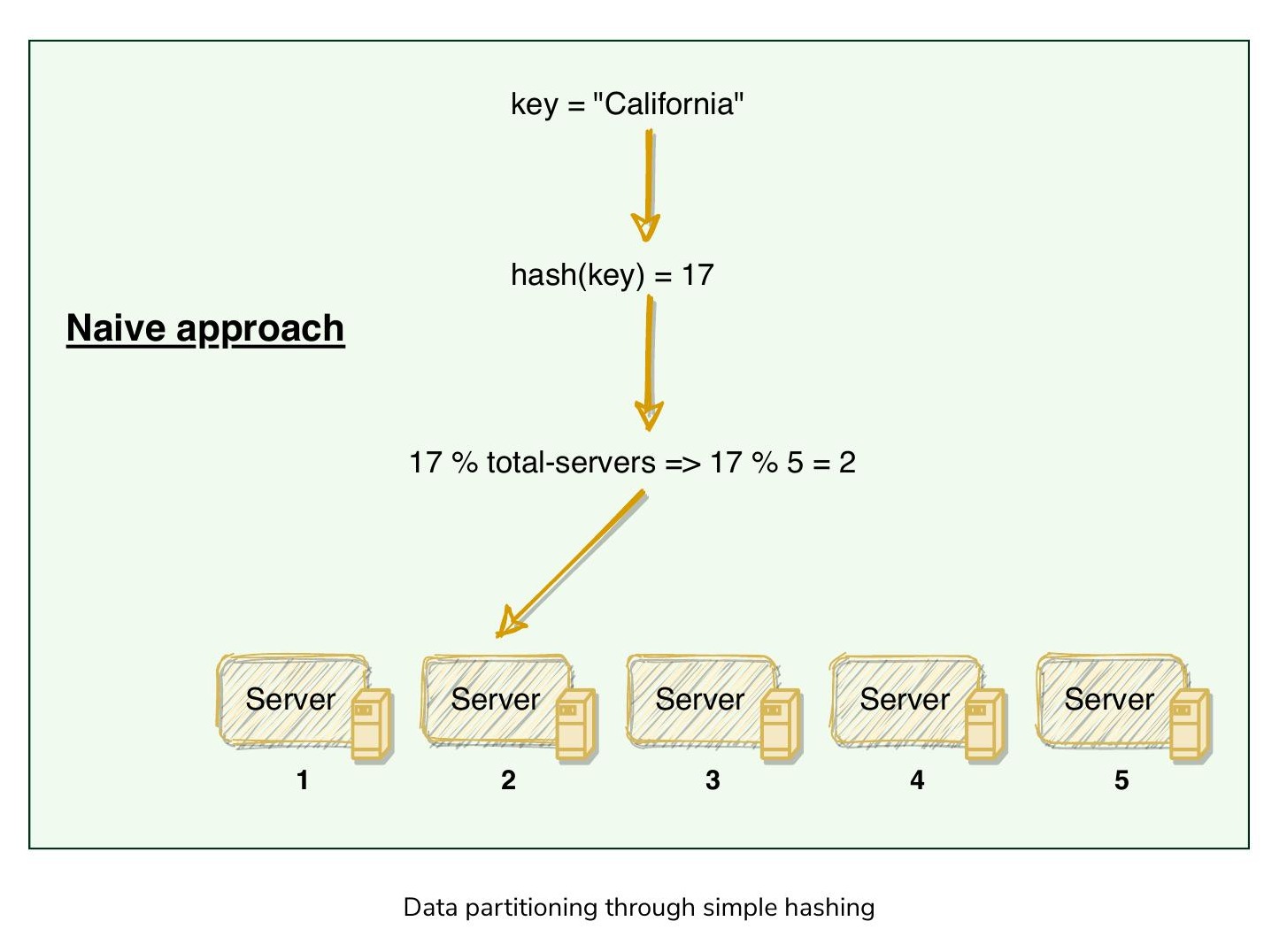
一種簡單的方法是使用雜湊函式將資料鍵映射為數字,再對伺服器總數取餘數(Modulo)。但這種方法的問題在於:當新增或移除伺服器時,需要重新映射所有鍵並遷移資料,代價極高。
Dynamo 使用**一致性雜湊(Consistent Hashing)**來解決這些問題,確保新增或移除伺服器時只有少量的鍵需要遷移。
一致性雜湊:Dynamo 的資料分配方式#
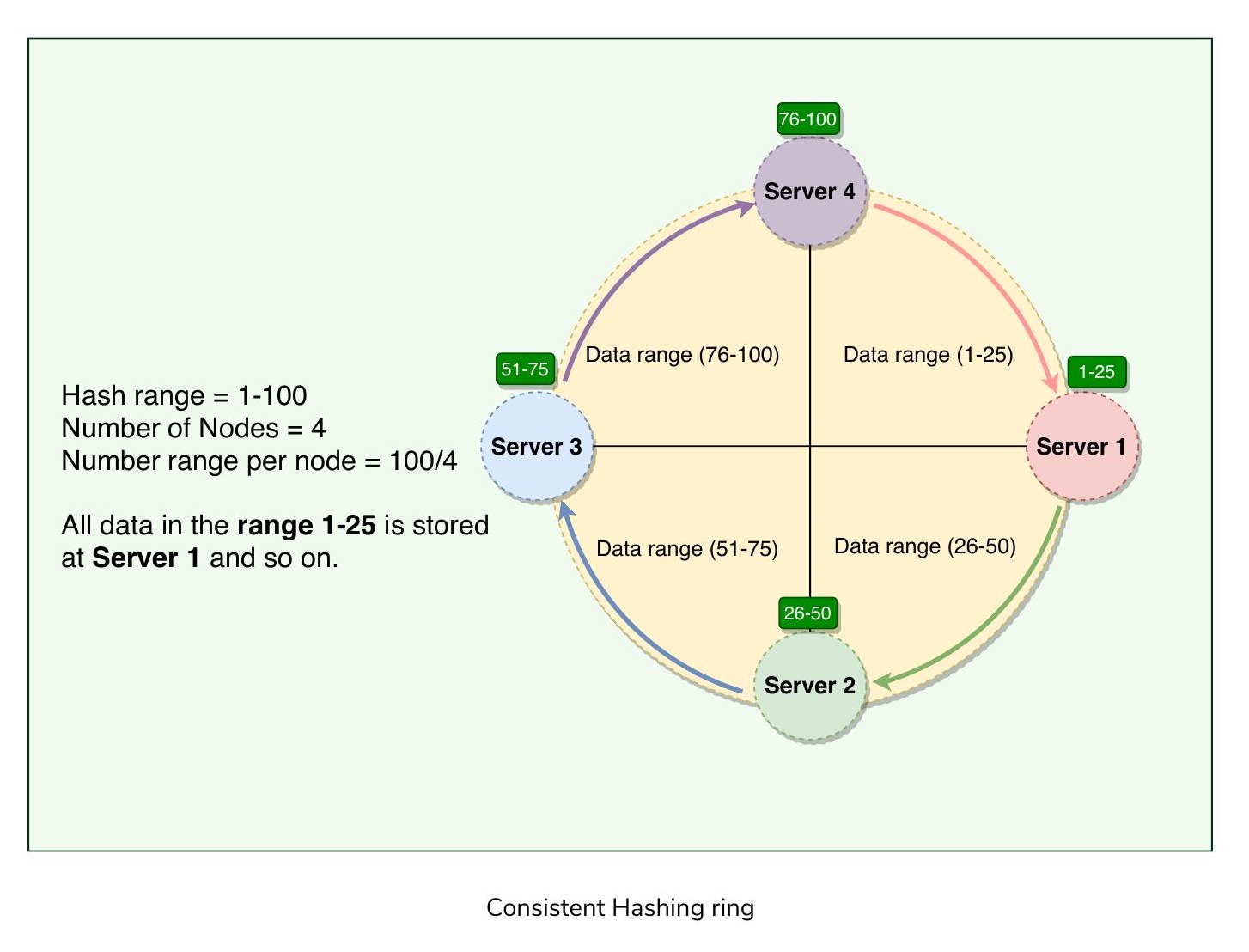
一致性雜湊將叢集管理的資料表示為一個環(Ring)。環上的每個節點被分配一段資料範圍。
一致性雜湊環
環被劃分為多個預定義的範圍,每個節點被分配其中一個範圍。在 Dynamo 的術語中,範圍的起始點稱為權杖(Token)。每個節點的資料範圍計算方式如下:
- 範圍起始:權杖值
- 範圍結束:下一個權杖值 - 1
當 Dynamo 處理 put() 或 get() 請求時,首先對鍵套用 MD5 雜湊演算法,根據輸出結果判斷資料落在哪個範圍,進而確定資料應儲存在哪個節點上。
在一致性雜湊環上分配資料
一致性雜湊在新增或移除節點時運作良好,因為這些場景中只有相鄰節點受影響。例如,當一個節點被移除時,下一個節點會接管該節點的所有鍵。然而,這種方案可能導致資料和負載分布不均勻。Dynamo 透過**虛擬節點(Virtual Nodes)**解決此問題。
虛擬節點#
在分散式系統中,新增和移除節點是常見操作。基本的一致性雜湊演算法為每個實體節點分配單一權杖(即一段連續的雜湊範圍),這種靜態劃分方式存在以下問題:
- 新增或移除節點:需要重新計算權杖,對大型叢集造成顯著的管理開銷。
- 熱點問題(Hotspots):每個節點被分配一大段範圍,若資料分布不均勻,某些節點可能成為熱點。
- 節點重建:由於每個節點的資料僅複製在固定數量的節點上,重建時只有這些副本節點能提供資料,造成壓力集中。
為解決這些問題,Dynamo 引入了虛擬節點(Vnode)機制:將雜湊範圍劃分為多個較小的子範圍,並將多個子範圍分配給每個實體節點。每個子範圍就是一個 Vnode。
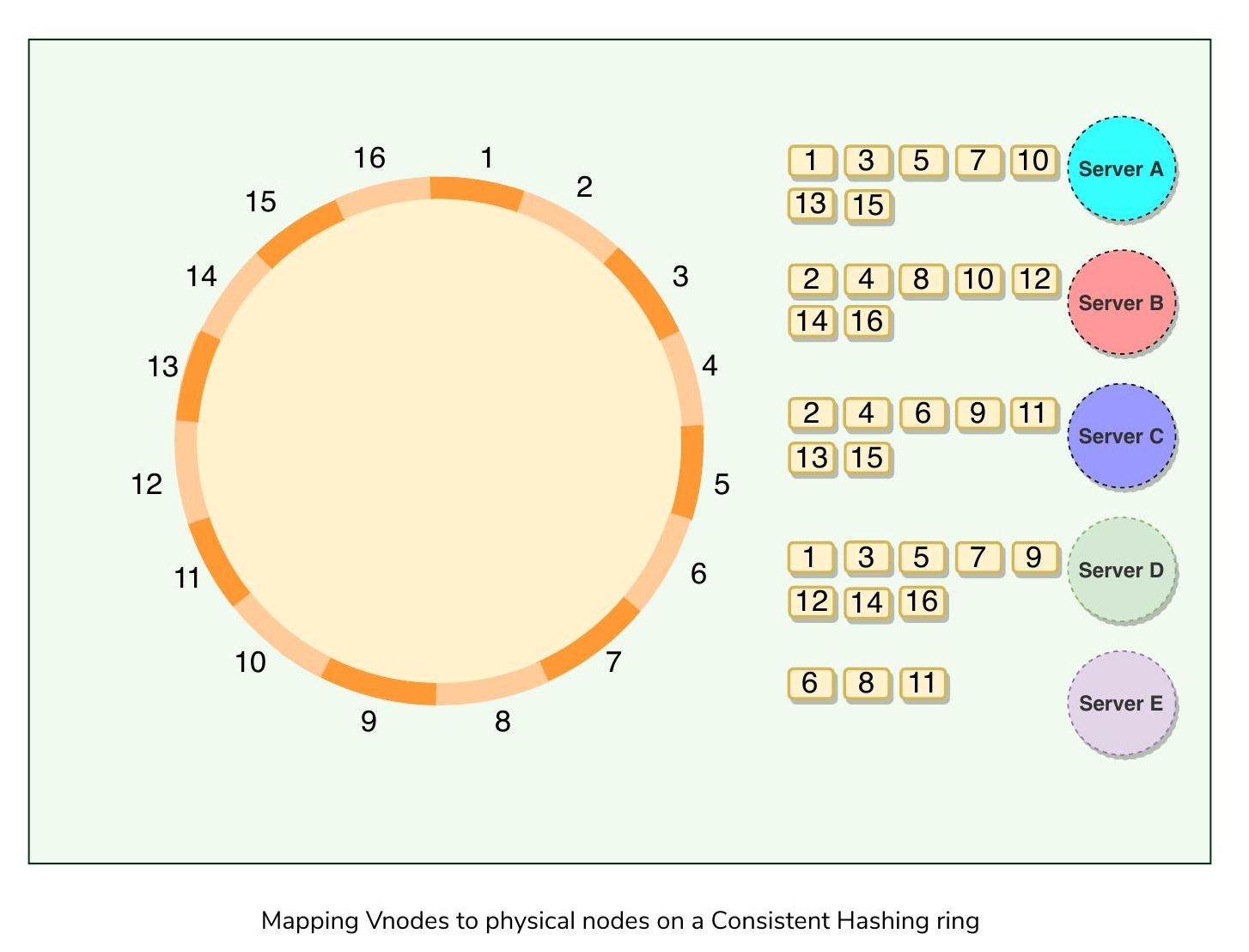
在一致性雜湊環上將虛擬節點映射到實體節點
虛擬節點在叢集中是隨機分布的,且通常不連續,以確保相鄰的虛擬節點不會被分配到同一個實體節點。由於叢集中可能有異質機器,某些伺服器可能持有比其他伺服器更多的虛擬節點。
虛擬節點的優勢#
- 負載更均勻:透過將雜湊範圍劃分為較小的子範圍,在新增或移除節點後能更快速地重新平衡。新節點加入時會從現有節點接收多個虛擬節點;節點需要重建時,多個節點可參與重建過程。
- 支援異質機器:可以為效能較強的伺服器分配較多的範圍,為較弱的伺服器分配較少的範圍。
- 降低熱點機率:每個實體節點被分配較小的範圍,相比基本一致性雜湊方案(每個節點一大段範圍),熱點出現的機率大幅降低。
複製#
什麼是樂觀複製?#
為確保高可用性與持久性,Dynamo 將每筆資料複製到系統中的 N 個節點上,其中 N 為可配置的複製因子(Replication Factor)。
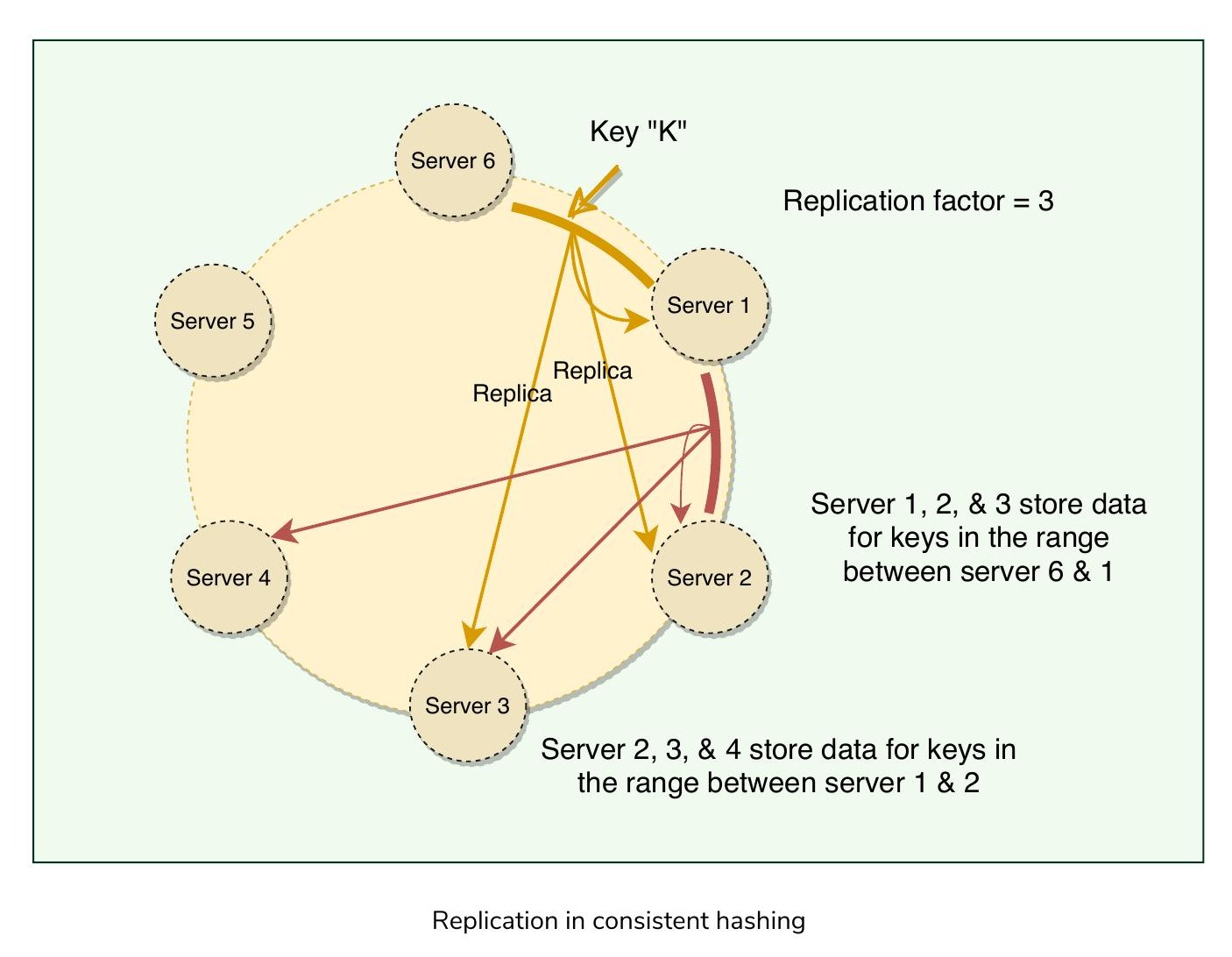
一致性雜湊中的資料複製
每個鍵被指派到一個協調者節點(Coordinator Node)(即雜湊環上第一個落在該範圍的節點)。協調者先將資料儲存在本地,再將其複製到環上順時針方向的 N-1 個後繼節點。這種複製是非同步進行的,Dynamo 提供的是最終一致性模型。
這種複製技術稱為樂觀複製(Optimistic Replication),意味著副本不保證在所有時間點都完全相同。
偏好列表#
偏好列表(Preference List) 是負責儲存特定鍵的節點清單。Dynamo 的設計使系統中的每個節點都能判斷任何鍵的偏好列表應包含哪些節點。此列表包含超過 N 個節點,以因應故障情況,並跳過環上的虛擬節點以確保列表只包含不同的實體節點。
寬鬆法定人數與暫時性故障處理#
傳統的法定人數(Quorum)方式在伺服器故障或網路分區時會導致系統不可用。為提升可用性,Dynamo 不強制嚴格的法定人數要求,而是使用寬鬆法定人數(Sloppy Quorum)。透過此方式,所有讀寫操作都在偏好列表中前 N 個健康節點上執行,這些節點不一定是環上順時針遇到的前 N 個節點。
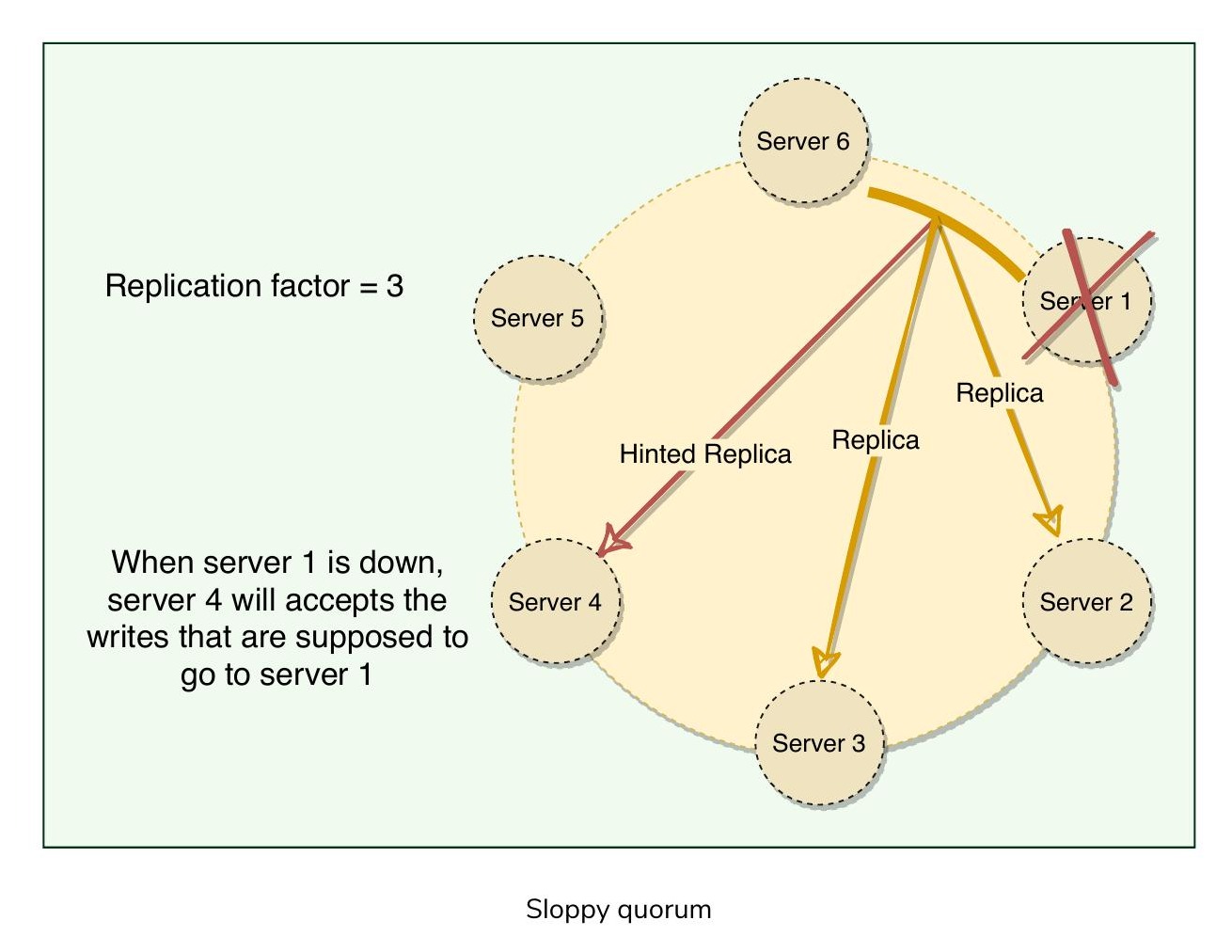
寬鬆法定人數
以複製因子 N=3 為例:如果 Server 1 在寫入操作期間暫時不可用,其資料會被儲存到 Server 4。副本的元資料中會包含一個提示(Hint),標記原本的目標接收者是 Server 1。Server 4 會定期掃描本地資料庫,一旦偵測到 Server 1 恢復,便嘗試將副本傳送回 Server 1。傳送成功後,Server 4 可以刪除該副本,且系統中的總副本數不會減少。
提示交接#
上述提升可用性的技巧稱為提示交接(Hinted Handoff):當一個節點不可達時,另一個節點可以代替它接受寫入。寫入先保存在本地緩衝區,待目標節點恢復後再發送。這使 Dynamo 成為「永遠可寫入」的系統。即使在極端情況下只有單一節點存活,寫入請求仍會被接受並最終處理。
由於寬鬆法定人數不是嚴格多數,資料可能會出現分歧。同一個鍵的兩個併發寫入可能被不重疊的節點集合接受,導致系統中存在多個衝突版本。Dynamo 允許此情況發生,並透過**向量時鐘(Vector Clocks)**來解決衝突。
向量時鐘與衝突資料#
什麼是時鐘偏差?#
在單一機器上,我們只需要知道絕對時鐘(Wall Clock)時間:對鍵 k 以時間戳 t1 寫入,再以時間戳 t2 寫入,由於 t2 > t1,第二次寫入必定比第一次新,資料庫可以安全地覆蓋原始值。
在分散式系統中,這個假設不成立。問題在於時鐘偏差(Clock Skew):不同的時鐘運行速率不同,因此無法假設節點 A 上的時間 t 一定發生在節點 B 上的時間 t+1 之前。即使使用 NTP 等時鐘同步技術,也無法保證分散式系統中所有時鐘始終同步。沒有 GPS 單元和原子鐘等特殊硬體,僅使用絕對時鐘時間戳是不夠的。
什麼是向量時鐘?#
Dynamo 使用向量時鐘(Vector Clock)來捕捉同一物件不同版本之間的因果關係。向量時鐘實質上是一個(節點, 計數器)對。每個儲存在 Dynamo 中的物件版本都關聯一個向量時鐘。
透過比較向量時鐘,可以判斷兩個版本是處於平行分支還是具有因果順序:
- 如果第一個物件的時鐘計數器在所有節點上都小於或等於第二個物件的時鐘,則第一個是第二個的祖先,可以丟棄。
- 否則,兩個變更被視為衝突,需要調和。
Dynamo 在讀取時解決這些衝突。以下範例說明此過程:
- Server A 處理對鍵 k1 的寫入,值為
foo,分配版本[A:1]。此寫入被複製到 Server B。 - Server A 處理對鍵 k1 的寫入,值為
bar,分配版本[A:2]。此寫入也被複製到 Server B。 - 發生網路分區,A 和 B 無法通訊。
- Server A 處理對鍵 k1 的寫入,值為
baz,分配版本[A:3]。無法複製到 Server B,但儲存在另一個伺服器的提示交接緩衝區中。 - Server B 看到對鍵 k1 的寫入,值為
bax,分配版本[B:1]。無法複製到 Server A,但儲存在另一個伺服器的提示交接緩衝區中。 - 網路恢復,A 和 B 可以再次通訊。
- 任一伺服器收到對鍵 k1 的讀取請求時,看到同一鍵有不同版本
[A:3]和[A:2][B:1],但無法判斷哪個較新。系統回傳兩個版本,讓客戶端自行判斷並將較新版本寫回系統。
sequenceDiagram
participant C as 客戶端 (Client)
participant A as 伺服器 A (Server A)
participant B as 伺服器 B (Server B)
Note over A,B: 階段一:正常複製
C->>A: 寫入 k1 = foo
A->>A: 分配版本 [A:1]
A->>B: 複製 [A:1]
C->>A: 寫入 k1 = bar
A->>A: 分配版本 [A:2]
A->>B: 複製 [A:2]
Note over A,B: 階段二:網路分區 (Network Partition)
rect rgb(255, 230, 230)
C->>A: 寫入 k1 = baz
A->>A: 分配版本 [A:3]
A--xB: 無法複製
C->>B: 寫入 k1 = bax
B->>B: 分配版本 [A:2][B:1]
B--xA: 無法複製
end
Note over A,B: 階段三:網路恢復,偵測到衝突
C->>A: 讀取 k1
A->>C: 回傳兩個衝突版本:[A:3] 與 [A:2][B:1]
Note over C: 客戶端執行語義調和<br/>(Semantic Reconciliation)
C->>A: 寫入調和後的版本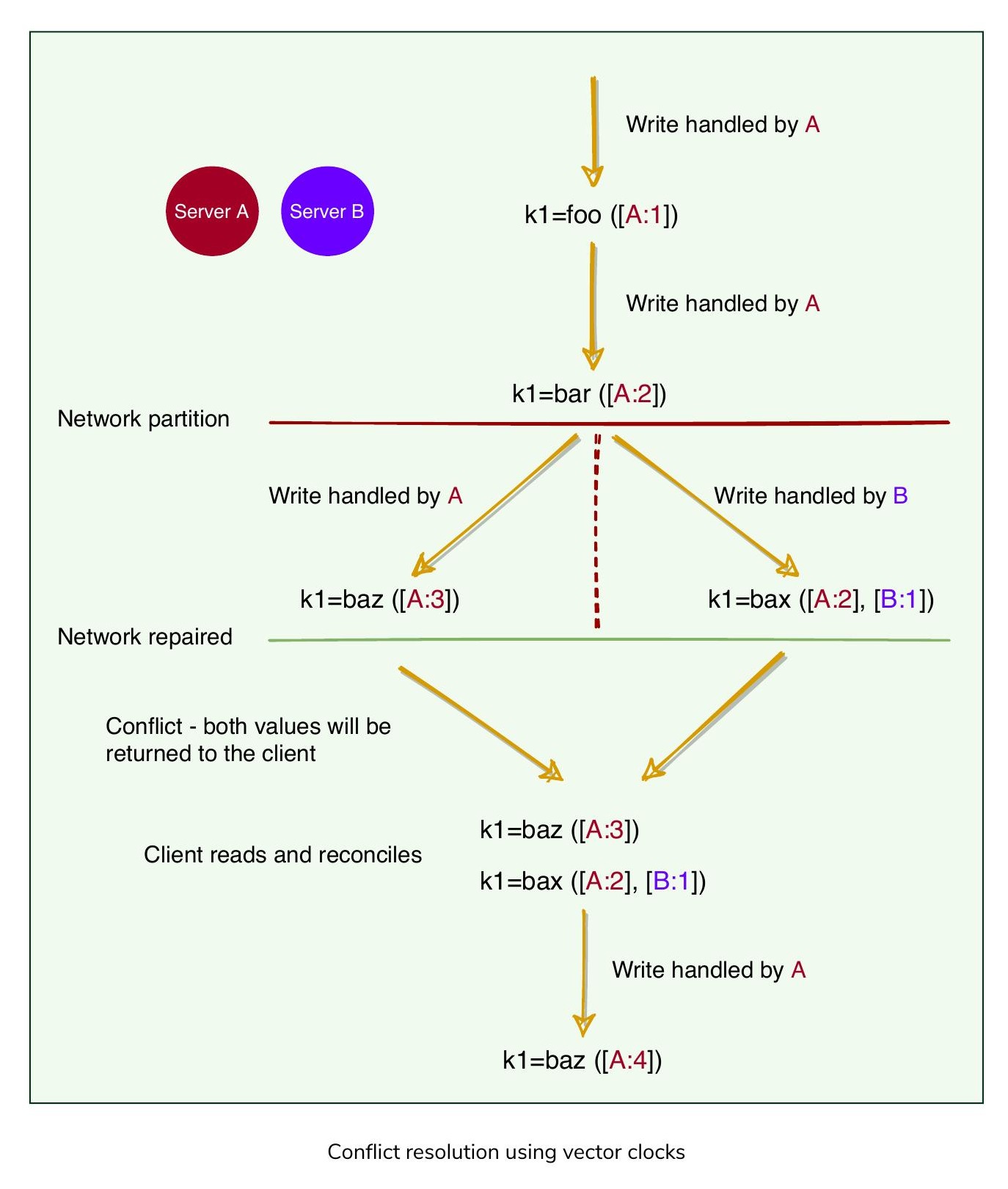
使用向量時鐘解決衝突
大多數情況下,新版本會取代舊版本,系統可以自動判斷正確版本(例如 [A:2] 比 [A:1] 新)。但在故障與併發更新同時發生時,可能出現版本分支,系統無法自行調和,需由客戶端執行語義調和(Semantic Reconciliation),將多個分支合併回一個。
解決衝突的方式類似 Git 的運作方式。如果 Git 可以自動合併不同版本,就會自動完成。否則,客戶端(即開發者)需要手動調和衝突。
一個典型的例子是合併不同版本的購物車。透過此機制,新增商品的操作永遠不會遺失,但已刪除的商品可能會重新出現。
Dynamo 在向量時鐘過大時會截斷(從最舊的開始)。如果被刪除的舊向量時鐘是調和物件狀態所必需的,Dynamo 將無法達成最終一致性。Dynamo 的作者指出這是一個潛在問題,但在其生產系統中尚未發生。
無衝突複製資料型別(CRDTs)#
一種更直接的衝突處理方式是使用無衝突複製資料型別(Conflict-free Replicated Data Types, CRDTs)。使用 CRDTs 時,需要將資料建模成併發變更可以以任意順序套用且產生相同最終結果的形式,系統便不需要擔心順序保證。
Amazon 的購物車是 CRDTs 的絕佳範例:當用戶將兩個商品(A 和 B)加入購物車時,這兩個操作可以在任何節點、以任何順序執行,最終結果都是兩個商品被加入購物車。(從購物車移除被建模為「負向新增」。)
任何兩個接收到相同更新集合的節點將看到相同的最終結果,這種特性稱為強最終一致性(Strong Eventual Consistency)。
最後寫入者勝出(LWW)#
將資料建模為 CRDTs 並非總是容易的,很多情況下需要大量的工程努力。因此,搭配客戶端解決方案的向量時鐘被認為是足夠好的方案。
除了向量時鐘之外,Dynamo 也提供在伺服器端自動解決衝突的方式。Dynamo(和 Apache Cassandra)常使用一種簡單的衝突解決策略:最後寫入者勝出(Last-Write-Wins, LWW),基於絕對時鐘時間戳。LWW 容易導致資料遺失。例如,如果兩個衝突寫入同時發生,等同於用擲硬幣來決定丟棄哪個寫入。
put() 與 get() 操作的生命週期#
選擇協調者節點的策略#
Dynamo 客戶端可以使用以下兩種策略之一來選擇處理請求的節點:
- 透過通用負載平衡器路由:客戶端不需要感知 Dynamo 環的結構,有利於擴展性和鬆耦合架構。但負載平衡器可能將請求轉發到不在偏好列表中的節點,導致額外的一跳(Extra Hop)。
- 使用分區感知客戶端程式庫:客戶端維護一份環的副本,直接將請求轉發到偏好列表中的適當節點,實現較低的延遲。因此 Dynamo 也被稱為零跳 DHT(Zero-hop DHT)。但這種情況下 Dynamo 對負載分配和請求處理的控制較少。
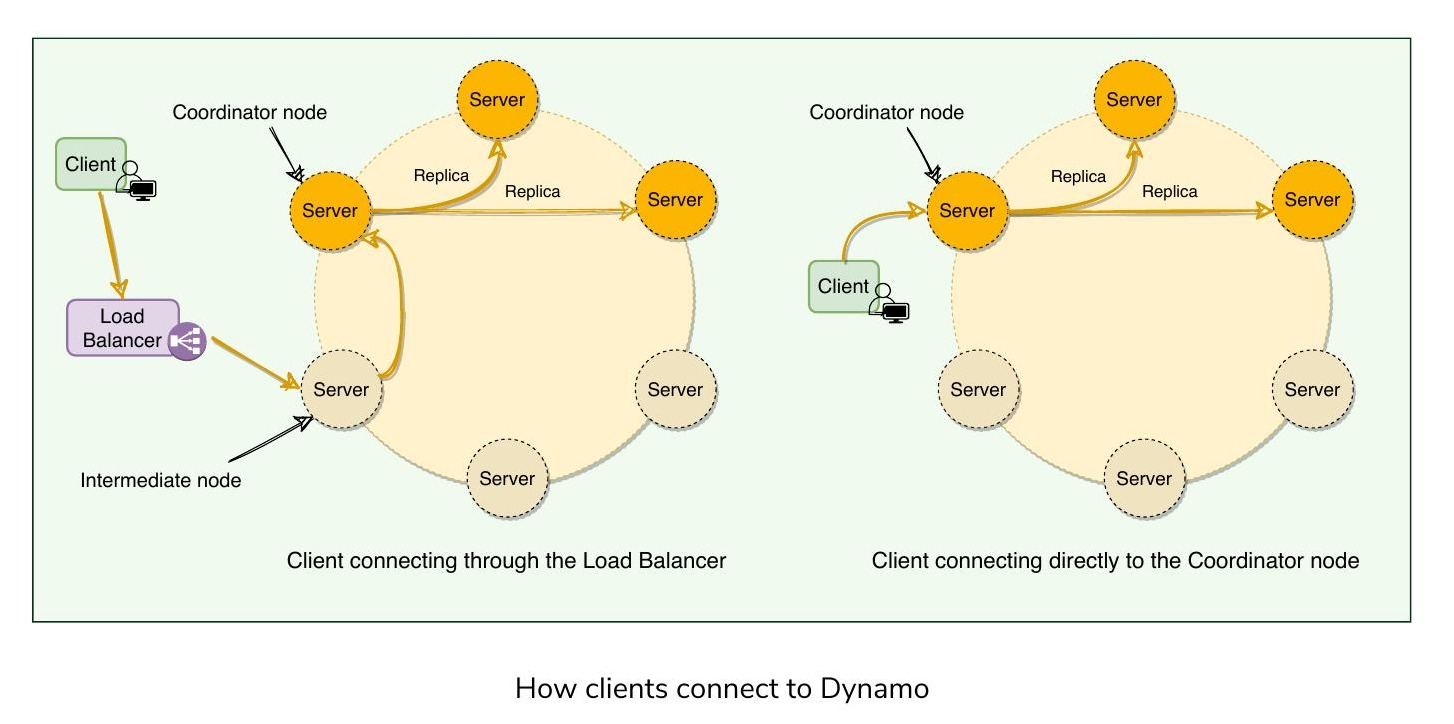
客戶端如何連接到 Dynamo
一致性協定#
Dynamo 使用類似法定人數系統(Quorum System)的一致性協定。設 R/W 分別為讀取/寫入操作必須參與的最少節點數:
- R + W > N 可產生類似法定人數的系統。
- 常見的 (N, R, W) 配置為 (3, 2, 2)。
- (3, 3, 1):快速寫入、慢速讀取、持久性較低。
- (3, 1, 3):快速讀取、慢速寫入、持久性較高。
get()或put()操作的延遲取決於最慢的副本。因此 R 和 W 通常配置為小於 N 以獲得更好的延遲。低 W 和 R 值會增加不一致的風險,因為寫入請求即使多數副本尚未處理也會回傳成功。
put() 流程#
- 協調者產生新的資料版本和向量時鐘元件。
- 在本地儲存新資料。
- 將寫入請求發送到偏好列表中排名最高的 N-1 個健康節點。
- 收到 W-1 個確認後,
put()操作被視為成功。
sequenceDiagram
participant C as 客戶端 (Client)
participant Co as 協調者 (Coordinator)
participant N1 as 節點 1 (Node 1)
participant N2 as 節點 2 (Node 2)
participant N3 as 節點 3 (Node 3)
C->>Co: put(key, context, object)
Co->>Co: 產生新版本的向量時鐘 (Vector Clock)
Co->>Co: 儲存新資料至本地
par 並行發送寫入請求
Co->>N1: 寫入請求 (Write Request)
Co->>N2: 寫入請求 (Write Request)
Co->>N3: 寫入請求 (Write Request)
end
N1-->>Co: 寫入確認 (ACK)
N2-->>Co: 寫入確認 (ACK)
Note over Co: 收到 W-1 個確認,寫入成功
Co-->>C: put() 成功回應
N3-->>Co: 寫入確認 (ACK)(額外回應)get() 流程#
- 協調者向偏好列表中排名最高的 N-1 個健康節點請求資料版本。
- 等待 R-1 個回覆。
- 協調者透過向量時鐘處理因果資料版本。
- 將所有相關的資料版本回傳給呼叫者。
sequenceDiagram
participant C as 客戶端 (Client)
participant Co as 協調者 (Coordinator)
participant N1 as 節點 1 (Node 1)
participant N2 as 節點 2 (Node 2)
participant N3 as 節點 3 (Node 3)
C->>Co: get(key)
par 並行發送讀取請求
Co->>N1: 讀取請求 (Read Request)
Co->>N2: 讀取請求 (Read Request)
Co->>N3: 讀取請求 (Read Request)
end
N1-->>Co: 回傳版本 D1 [A:2]
N2-->>Co: 回傳版本 D2 [A:2][B:1]
Note over Co: 收到 R-1 個回應,開始處理
Co->>Co: 透過向量時鐘比較版本 (Vector Clock Comparison)
alt 可判定因果順序
Co-->>C: 回傳最新版本
else 版本衝突(併發更新)
Co-->>C: 回傳所有衝突版本 + 上下文 (Context)
Note over C: 客戶端執行調和 (Reconciliation)
C->>Co: put(key, reconciled_context, merged_object)
end
N3-->>Co: 回傳版本(額外回應)
Note over Co: 若發現過期版本,觸發讀取修復 (Read Repair)透過狀態機處理請求#
每個客戶端請求會在接收到請求的節點上建立一個狀態機(State Machine)。狀態機包含所有邏輯:識別負責該鍵的節點、發送請求、等待回應、執行重試、處理回覆、封裝回應給客戶端。每個狀態機實例精確處理一個客戶端請求。
以讀取操作為例,狀態機執行以下步驟:
- 向節點發送讀取請求。
- 等待最少數量的必要回應。
- 若在給定時間限制內收到的回覆太少,則請求失敗。
- 否則,收集所有資料版本並確定要回傳的版本。
- 若啟用了版本控制,執行語法調和(Syntactic Reconciliation)並產生一個不透明的寫入上下文,包含涵蓋所有剩餘版本的向量時鐘。
讀取回應回傳給呼叫者後,狀態機會短暫等待以接收任何尚未到達的回應。如果任何回應中回傳了過期版本,協調者會用最新版本更新那些節點。此過程稱為讀取修復(Read Repair),用於修復錯過近期更新的副本。
flowchart TD
A[接收客戶端請求<br/>Receive Client Request] --> B[建立狀態機實例<br/>Create State Machine Instance]
B --> C[識別負責該鍵的節點<br/>Identify Responsible Nodes]
C --> D[向目標節點發送請求<br/>Send Requests to Target Nodes]
D --> E{等待回應<br/>Wait for Responses}
E -->|逾時且回應不足| F[請求失敗<br/>Request Failed]
F --> K[回傳錯誤給客戶端<br/>Return Error to Client]
E -->|收到足夠回應| G{操作類型?}
G -->|寫入操作 put| H[收到 W-1 個確認<br/>W-1 ACKs Received]
H --> L[回傳成功給客戶端<br/>Return Success to Client]
G -->|讀取操作 get| I[收集所有資料版本<br/>Collect All Data Versions]
I --> J{版本是否衝突?<br/>Version Conflict?}
J -->|否:可判定因果順序| M[回傳最新版本<br/>Return Latest Version]
J -->|是:併發更新| N[執行語法調和<br/>Syntactic Reconciliation]
N --> O[產生寫入上下文<br/>Generate Write Context<br/>含合併的向量時鐘]
O --> P[回傳所有版本與上下文<br/>Return All Versions + Context]
M --> Q[短暫等待額外回應<br/>Brief Wait for Late Responses]
P --> Q
Q --> R{是否有過期版本?<br/>Stale Versions Found?}
R -->|是| S[觸發讀取修復<br/>Trigger Read Repair]
R -->|否| T[狀態機結束<br/>State Machine Complete]
S --> T為避免寫入操作集中在偏好列表的第一個節點而造成負載不均,Dynamo 允許偏好列表前 N 個節點中的任何一個協調寫入。特別地,寫入操作的協調者會選擇對前一次讀取回應最快的節點,以提升「讀己所寫(Read-your-writes)」一致性的機會。
透過 Merkle 樹實現反熵#
若副本嚴重落後於其他副本,僅透過向量時鐘解決衝突可能需要很長的時間。因此需要一種機制能在背景中自動解決部分衝突,快速比較不同副本上的資料範圍並找出確切的差異部分。
什麼是 Merkle 樹?#
副本可能包含大量資料,直接對整個資料範圍進行校驗碼比對不可行。因此 Dynamo 使用 Merkle 樹(Merkle Tree) 來比較副本。
Merkle 樹是一種二元雜湊樹(Binary Tree of Hashes):每個內部節點是其兩個子節點的雜湊值,每個葉節點是原始資料一部分的雜湊值。
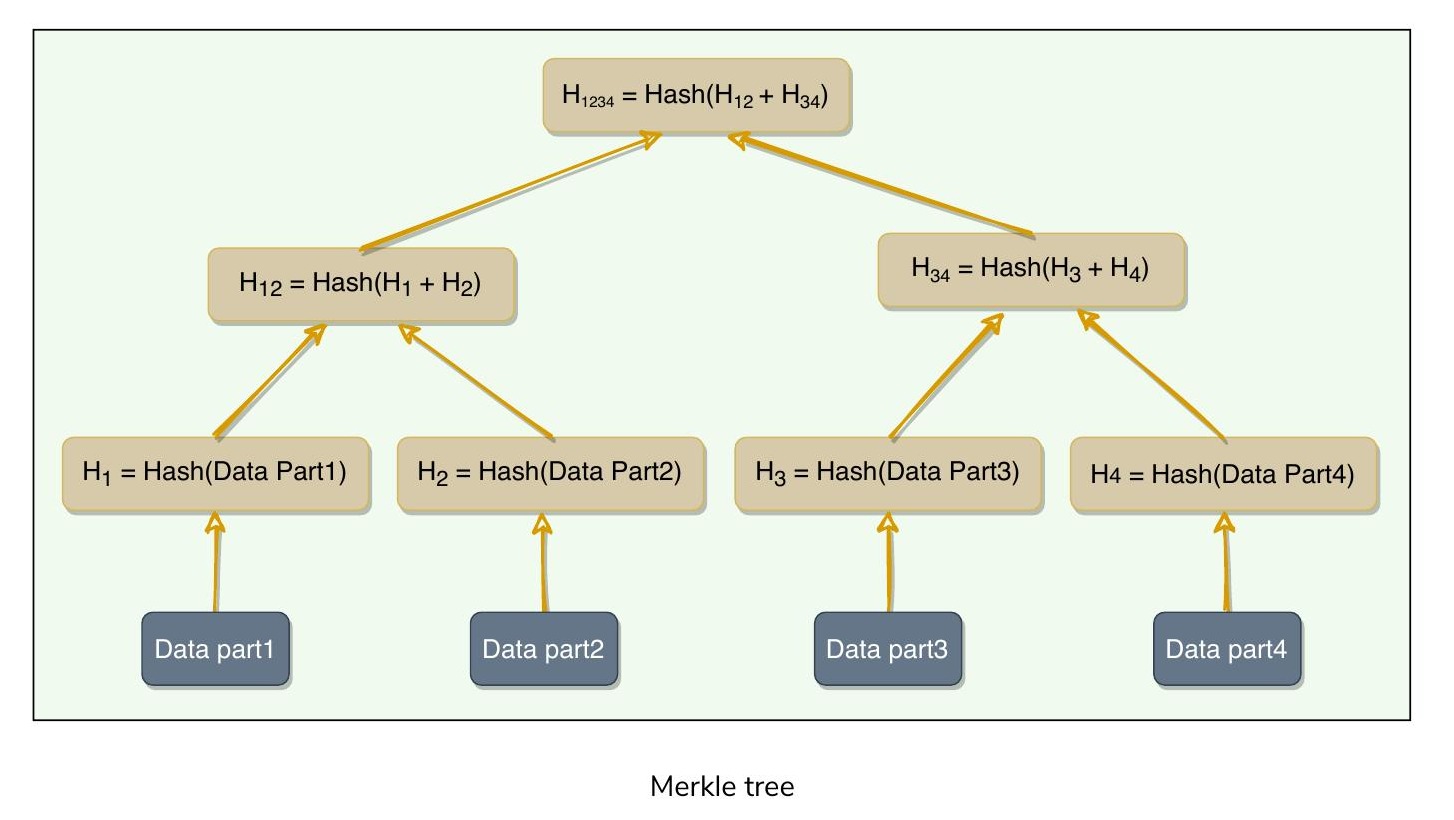
Merkle 樹
比較 Merkle 樹的步驟:
- 比較兩棵樹的根雜湊值。
- 如果相等,停止。
- 對左右子樹遞迴比較。
透過此方式,副本可以精確知道哪些部分的範圍不同,交換的資料量被降到最低。
Merkle 樹的優缺點#
優點:
- 每個分支可以獨立檢查,不需要下載整棵樹或完整資料集。
- 最小化同步所需傳輸的資料量,減少反熵過程中的磁碟讀取次數。
缺點:
- 當節點加入或離開時,許多鍵範圍會改變,樹需要重新計算。
八卦協定#
什麼是八卦協定?#
在 Dynamo 叢集中,由於沒有中央節點追蹤所有節點的狀態,節點如何得知其他節點的當前狀態?
最簡單的方法是讓每個節點與其他所有節點維持心跳(Heartbeat),但這樣每次心跳需要發送 O(N^2) 條訊息,對大型叢集而言不可行。
Dynamo 使用八卦協定(Gossip Protocol),使每個節點能追蹤叢集中其他節點的狀態資訊(如哪些節點可達、負責哪些鍵範圍等,本質上是雜湊環的副本)。八卦協定是一種點對點通訊機制,節點定期交換自身及所知的其他節點的狀態資訊。每個節點每秒發起一輪八卦,與一個隨機選擇的節點交換狀態資訊。這意味著任何新事件最終會傳播到整個系統,所有節點會快速得知叢集中所有其他節點的狀態。
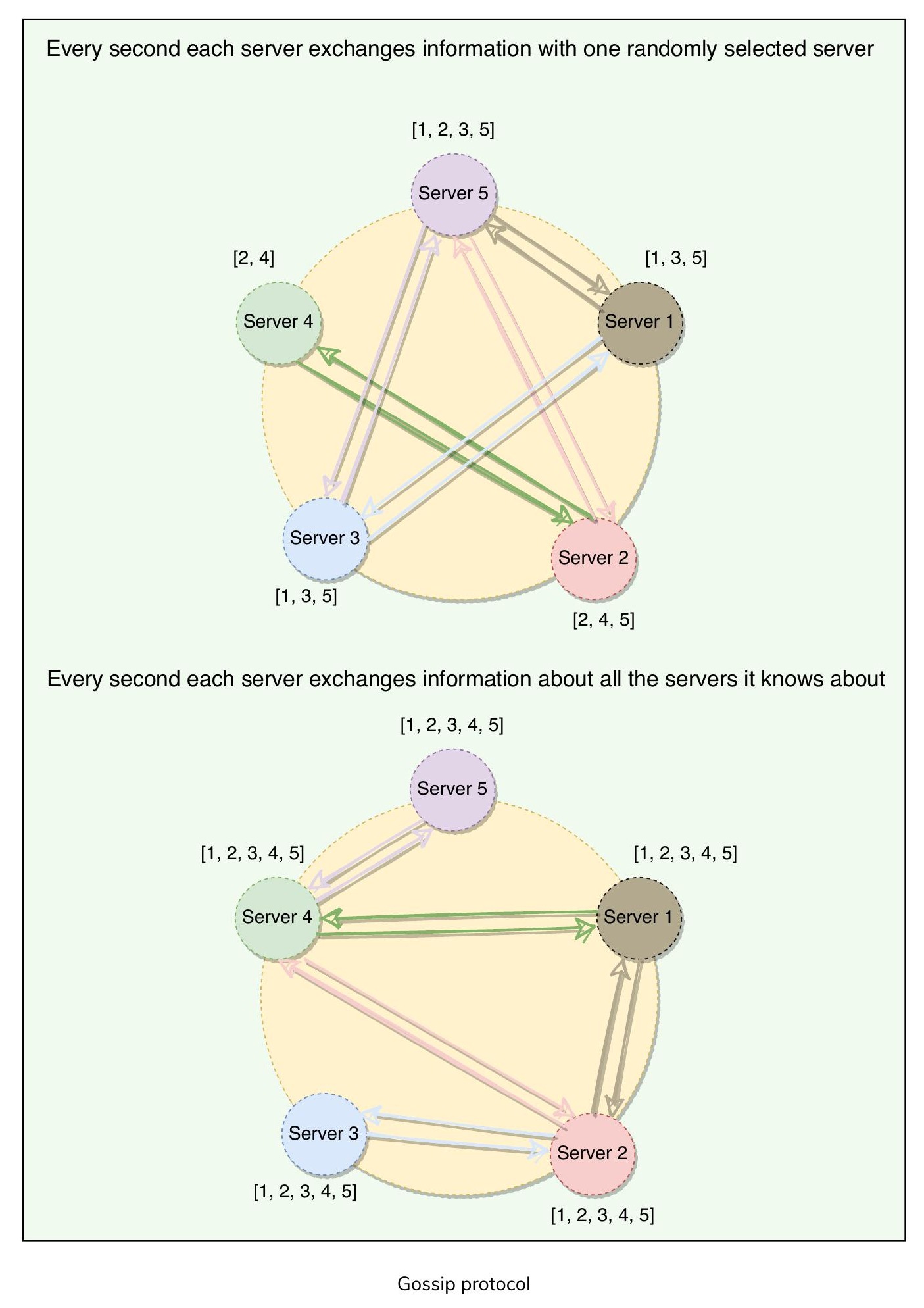
八卦協定
透過種子節點進行外部發現#
八卦協定可能在特定場景下導致叢集的邏輯分區。例如:管理員先將節點 A 加入環,再將節點 B 加入環。A 和 B 各自認為自己是環的一部分,但彼此不會立即感知對方。
為防止這種邏輯分區,Dynamo 引入了**種子節點(Seed Nodes)**的概念。種子節點是功能完整的節點,可從靜態配置或配置服務取得。所有節點都知道種子節點的存在,並透過八卦協定與種子節點通訊來調和成員變更,因此邏輯分區極不可能發生。
Dynamo 的特性與批評#
Dynamo 節點的職責#
由於 Dynamo 完全去中心化,不依賴中央或領導者伺服器,每個節點承擔三種功能:
- 管理 get() 和 put() 請求:節點可作為協調者管理特定鍵的所有操作,或將請求轉發到適當的節點。
- 追蹤成員資格與偵測故障:每個節點透過八卦協定追蹤系統中其他節點及其關聯的雜湊範圍。
- 本地持久化儲存:每個節點負責作為特定值範圍的主要或副本儲存。鍵值對使用不同的儲存系統存放,取決於應用需求,例如:
- BerkeleyDB 交易式資料存放區
- MySQL(用於大型物件)
- 記憶體緩衝區(最佳效能)搭配持久化儲存
Dynamo 的特性#
| 特性 | 說明 |
|---|---|
| 分散式(Distributed) | 可在大量機器上運行 |
| 去中心化(Decentralized) | 不需要中央協調者,所有節點相同且可執行 Dynamo 的所有功能 |
| 可擴展(Scalable) | 透過新增節點即可輕鬆水平擴展,無需手動介入或重新平衡 |
| 高可用性(Highly Available) | 即使一個或多個節點或資料中心故障,資料仍然可用 |
| 容錯與可靠(Fault-tolerant) | 資料複製到多個節點,容錯能力高 |
| 可調整一致性(Tunable Consistency) | 可透過配置複製因子和一致性等級來調整可用性與一致性之間的取捨 |
| 持久性(Durable) | 資料永久儲存 |
| 最終一致性(Eventually Consistent) | 以犧牲強一致性來換取高可用性 |
對 Dynamo 的批評#
- 每個 Dynamo 節點包含完整的路由表,隨著節點增加,路由表會越來越大,可能影響系統的可擴展性。
- Dynamo 聲稱追求對稱性(每個節點擁有相同的角色與職責),但又指定某些節點為種子節點。種子節點是可被外部發現的特殊節點,用於防止邏輯分區,這似乎違反了 Dynamo 的對稱性原則。
- 雖然安全性不是關注點(Dynamo 僅為內部使用而建),但 DHT 可能容易受到多種攻擊。即使 Amazon 可以假設受信任的環境,有時有 Bug 的軟體也可能表現得像惡意行為者。
- Dynamo 的設計可被描述為一種「洩漏抽象(Leaky Abstraction)」,客戶端應用程式經常被要求管理不一致性,使用者體驗並非 100% 無縫。例如,購物車中的不一致可能讓使用者認為網站有 Bug 或不可靠。
基於 Dynamo 原則開發的資料儲存系統#
Dynamo 並非開源,且僅為 Amazon 內部服務而建。兩個最知名的基於 Dynamo 原則建構的資料儲存系統是 Riak 和 Cassandra:
- Riak:分散式 NoSQL 鍵值資料存放區,具備高可用性、可擴展性、容錯能力且易於操作。
- Cassandra:分散式、去中心化、可擴展且高可用的 NoSQL 寬欄資料庫(Wide-column Database)。
以下為它們對 Dynamo 技術的採用情況:
| 技術 | Apache Cassandra | Riak |
|---|---|---|
| 一致性雜湊搭配虛擬節點 | 有 | 有 |
| 提示交接(Hinted Handoff) | 有 | 有 |
| Merkle 樹反熵(手動修復) | 有 | 有 |
| 向量時鐘 | 無(使用最後寫入者勝出) | 有 |
| 基於八卦的協定 | 有 | 有 |
總結#
- Dynamo 是 Amazon 為內部使用而開發的高可用鍵值儲存系統。
- Dynamo 展示了業務需求如何驅動系統設計:Amazon 基於業務需求選擇犧牲強一致性以獲得更高的可用性。
- Dynamo 的設計理解到系統硬體故障是會且必定會發生的。
- Dynamo 是一個點對點分散式系統,即沒有任何領導者或追隨者節點。所有節點平等且擁有相同的角色與職責,這也意味著沒有單點故障。
- Dynamo 使用一致性雜湊演算法自動在叢集的節點間分配資料。
- 資料跨節點複製以實現容錯和冗餘。
- Dynamo 將寫入複製到寬鬆法定人數的其他節點,而非嚴格多數法定人數。
- 為了反熵和解決衝突,Dynamo 使用 Merkle 樹。
- 不同的儲存引擎可以插入 Dynamo 的本地儲存。
- Dynamo 使用八卦協定進行節點間通訊。
- Dynamo 透過提示交接使系統「永遠可寫入」。
- Dynamo 的設計哲學是永遠允許寫入。為支援此設計,Dynamo 允許併發寫入,可由不同伺服器併發執行,產生同一物件的多個版本。
- Dynamo 嘗試使用向量時鐘追蹤和調和這些變更。當 Dynamo 無法從向量時鐘調和物件狀態時,會將其傳送給客戶端應用程式進行調和,因為客戶端對物件有更多的語義資訊,可能更有能力調和它。
- Dynamo 成功地將多種分散式技術(如一致性雜湊、點對點八卦、向量時鐘和法定人數)結合成一個複雜的系統。
- Amazon 僅為內部使用而建造 Dynamo,因此未考慮安全相關問題。
系統設計模式#
以下為 Dynamo 中使用的系統設計模式:
| 模式 | 在 Dynamo 中的應用 |
|---|---|
| 一致性雜湊(Consistent Hashing) | 在節點間分配資料 |
| 法定人數(Quorum) | 寫入至少法定人數的副本節點後才視為成功 |
| 八卦協定(Gossip Protocol) | 每個節點追蹤叢集中其他節點的狀態資訊 |
| 提示交接(Hinted Handoff) | 記住故障節點的寫入操作 |
| 讀取修復(Read Repair) | 將最新版本的資料推送到擁有較舊版本的節點 |
| 向量時鐘(Vector Clocks) | 調和物件的併發更新 |
| Merkle 樹(Merkle Trees) | 反熵和在背景中解決衝突 |