為什麼要建立抽象層?#
撰寫程式的本質是解決問題。面對一個高階問題(例如「讓使用者能分享照片」),我們通常會將它拆解成多個較小的子問題(subproblem),例如儲存照片、關聯使用者、顯示照片等。
關鍵不僅在於如何解決這些子問題,更在於如何組織解決方案的程式碼結構。透過建立乾淨的抽象層(layers of abstraction),可以大幅提升程式碼的品質。
以「發送訊息到伺服器」為例,高階程式碼只需要處理四個簡單概念:
- 伺服器 URL
- 建立連線
- 發送訊息字串
- 關閉連線
但實際上背後涉及大量複雜性:字串序列化、HTTP 協定、TCP 連線、WiFi 或行動網路判斷、無線電訊號調變、資料傳輸錯誤修正等。因為其他工程師已經將這些子問題的解決方案包裝成一層層的抽象,我們甚至不需要知道它們的存在。
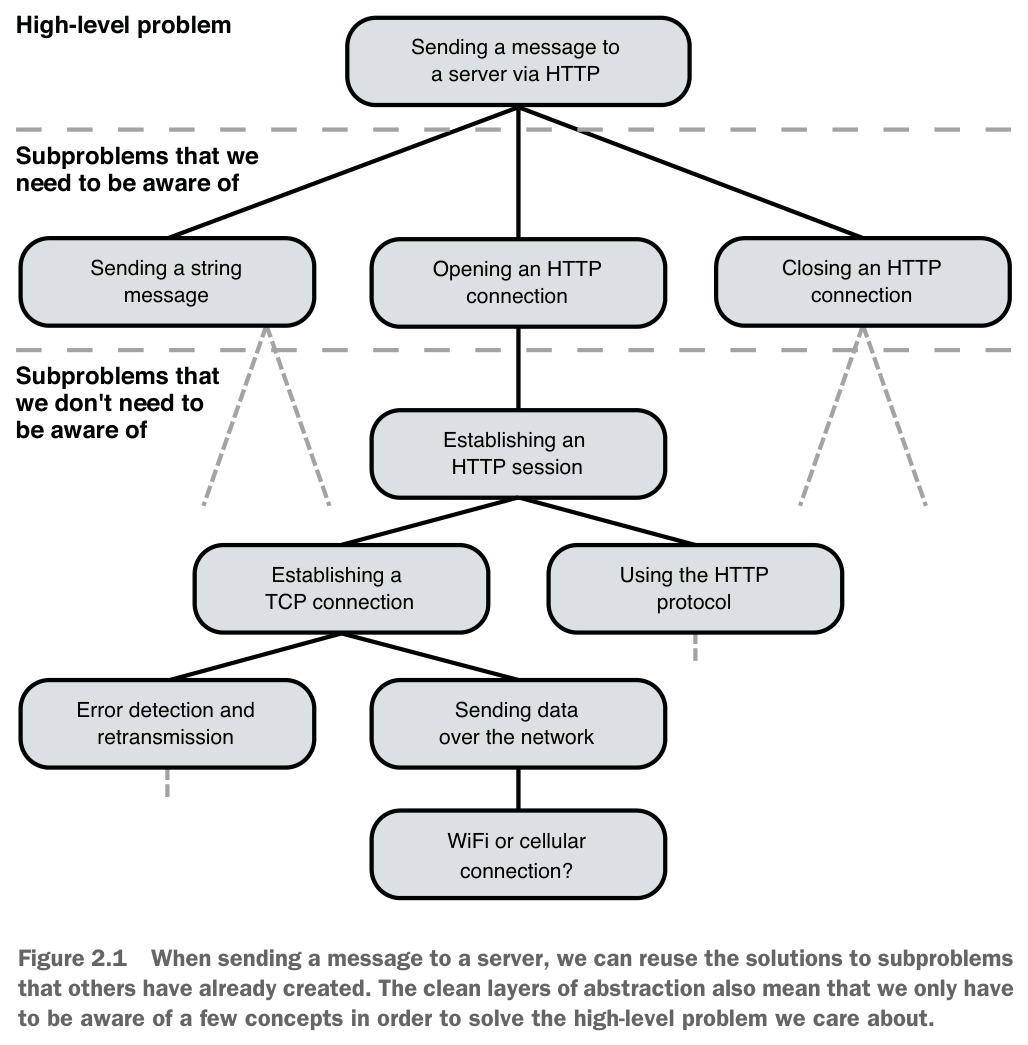
Figure 2.1: When sending a message to a server, we can reuse the solutions to subproblems that others have already created.
核心觀念: 如果我們能妥善地將問題遞迴拆解成子問題,並建立適當的抽象層,那麼任何一段程式碼都不會顯得特別複雜,因為它每次只需處理少量、容易理解的概念。
抽象層與程式碼品質的四大支柱#
建立乾淨且明確的抽象層,能直接促進以下四項程式碼品質支柱:
| 品質支柱 | 抽象層的貢獻 |
|---|---|
| 可讀性(Readability) | 工程師不可能理解程式碼庫中每一個細節,但可以輕鬆理解少數幾個高階抽象概念。乾淨的抽象層讓人每次只需要處理一兩層、少數概念 |
| 模組化(Modularity) | 當抽象層之間不洩漏實作細節時,就能輕鬆替換某一層的實作而不影響其他部分。例如 HttpConnection 底層的實體傳輸模組可以在 WiFi 和行動網路之間切換,高階程式碼完全不需要改動 |
| 可重用性與泛用性(Reusability & Generalizability) | 當子問題的解決方案被呈現為乾淨的抽象層時,就能輕鬆單獨重用它。若問題被拆解得夠抽象,解決方案往往能在多種不同情境下通用 |
| 可測試性(Testability) | 如果程式碼被乾淨地分成多個抽象層,就能更容易全面測試每個子問題的解決方案,而非只能對最外層做粗略驗證 |
程式碼如何對應抽象層#
在實務中,我們透過將程式碼劃分為不同單元來建立抽象層,一個單元依賴另一個單元,形成依賴圖(dependency graph)。大多數程式語言提供以下構造來拆分程式碼:
- 函式(Functions)
- 類別(Classes)(以及 struct、mixin 等類似結構)
- 介面(Interfaces)(或等價的語言結構)
- 套件、命名空間或模組(Packages, Namespaces, Modules)
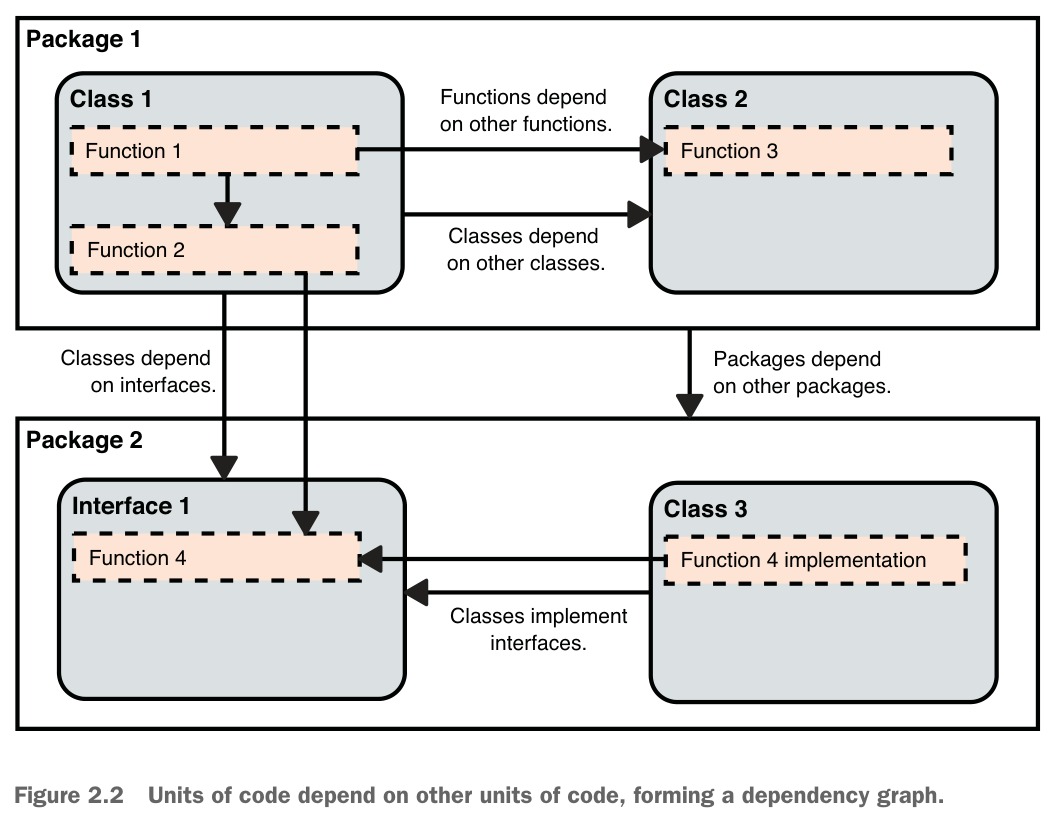
Figure 2.2: Units of code depend on other units of code, forming a dependency graph.
API 與實作細節#
撰寫程式碼時,需要思考兩個面向:
呼叫者會看到的東西(即公開 API):
- 公開的類別、介面、函式
- 名稱、輸入參數、回傳型別所傳達的概念
- 呼叫者正確使用程式碼所需的額外資訊(例如呼叫順序)
呼叫者不會看到的東西(即實作細節,implementation details):
- 私有函式或變數
- 類別的依賴關係
- 函式內部的程式碼邏輯(即使是公開函式)
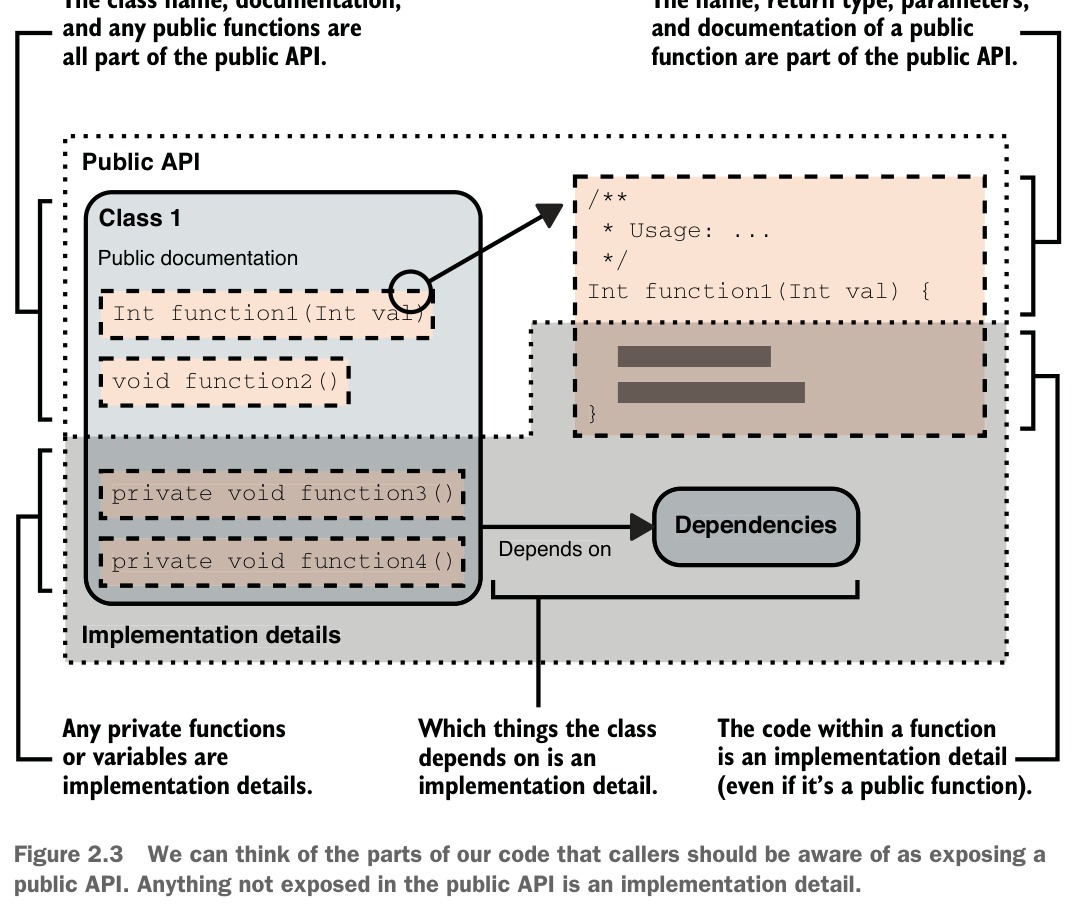
Figure 2.3: We can think of the parts of our code that callers should be aware of as exposing a public API. Anything not exposed in the public API is an implementation detail.
思考方式: 將每段程式碼視為對外暴露一個迷你 API。如果某個應屬實作細節的東西洩漏到 API 中(透過輸入參數、回傳型別或公開函式),就代表抽象層不夠乾淨。
函式:保持短小精悍#
函式內部的程式碼理想上應該讀起來像一個簡短、清晰的句子。將邏輯拆分為新函式的門檻通常很低。
一個好的策略是限制每個函式只做以下其中一件事:
- 執行單一任務
- 透過呼叫其他命名良好的函式來組合更複雜的行為
以 sendOwnerALetter() 為例,若函式包含查找車主地址的所有底層邏輯,加上寄信的邏輯,翻譯成句子會變成:「查找車主地址(若車輛已報廢則用廢車場地址、若未售出則用展示間地址、若有買家則用買家地址),若找到地址就寄信。」這個句子冗長難懂。
改善方式是將查找地址的邏輯抽取為獨立的 getOwnersAddress() 函式,讓主函式翻譯成:「查找車主地址(細節見下方函式),若找到就寄信。」
附帶好處: 拆分出來的
getOwnersAddress()函式現在可以被其他場景重用,例如未來需要只顯示車主地址而不寄信的功能。
類別:每個類別一個概念#
工程師經常爭論單一類別的理想大小。常見的準則包括:
- 行數限制 — 例如「類別不應超過 300 行」。但這只是警告信號,不代表少於 300 行就一定沒問題。
- 內聚性(Cohesion) — 衡量類別內部的東西是否「屬於一起」。包括:
- 順序內聚(Sequential cohesion):一個東西的輸出是另一個東西的輸入
- 功能內聚(Functional cohesion):一組東西共同完成單一任務
- 關注點分離(Separation of Concerns) — 系統應拆分為各自處理不同問題的獨立元件。就像遊戲主機和電視分開一樣,可以獨立升級、自由配置。
常見陷阱: 許多工程師都同意「類別應該只關注一件事」,但仍然寫出過大的類別。這通常發生在沒有仔細思考引入了多少不同概念、或哪些邏輯適合被重用或重新配置的時候。類別不僅在最初撰寫時可能過大,也可能隨時間有機成長而變得過大。
以 TextSummarizer 為例,若將摘要文字、計算重要性分數、提取重要名詞/動詞/形容詞、分段等所有邏輯都塞進同一個類別,會導致:
- 不夠可讀 — 多個不同概念混在一起,難以快速理解
- 不夠模組化 — 無法輕鬆替換例如重要性評分演算法
- 不可重用 — 無法單獨重用分段邏輯(將
splitIntoParagraphs()設為公開會污染 API) - 不夠泛用 — 若要處理 HTML 而非純文字,無法只替換分段邏輯
- 難以正確測試 — 只能透過
summarizeText()做粗略測試,無法針對重要性評分等子問題做精確測試
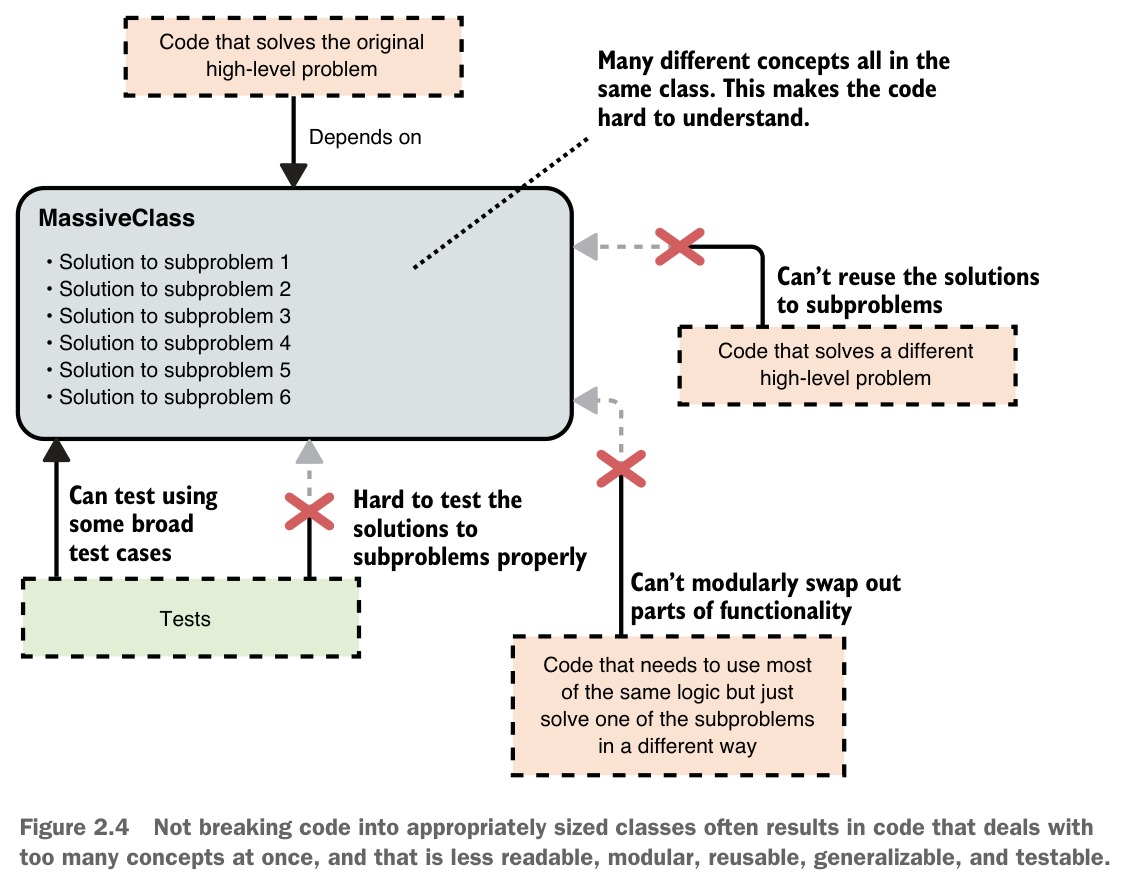
Figure 2.4: Not breaking code into appropriately sized classes often results in code that deals with too many concepts at once.
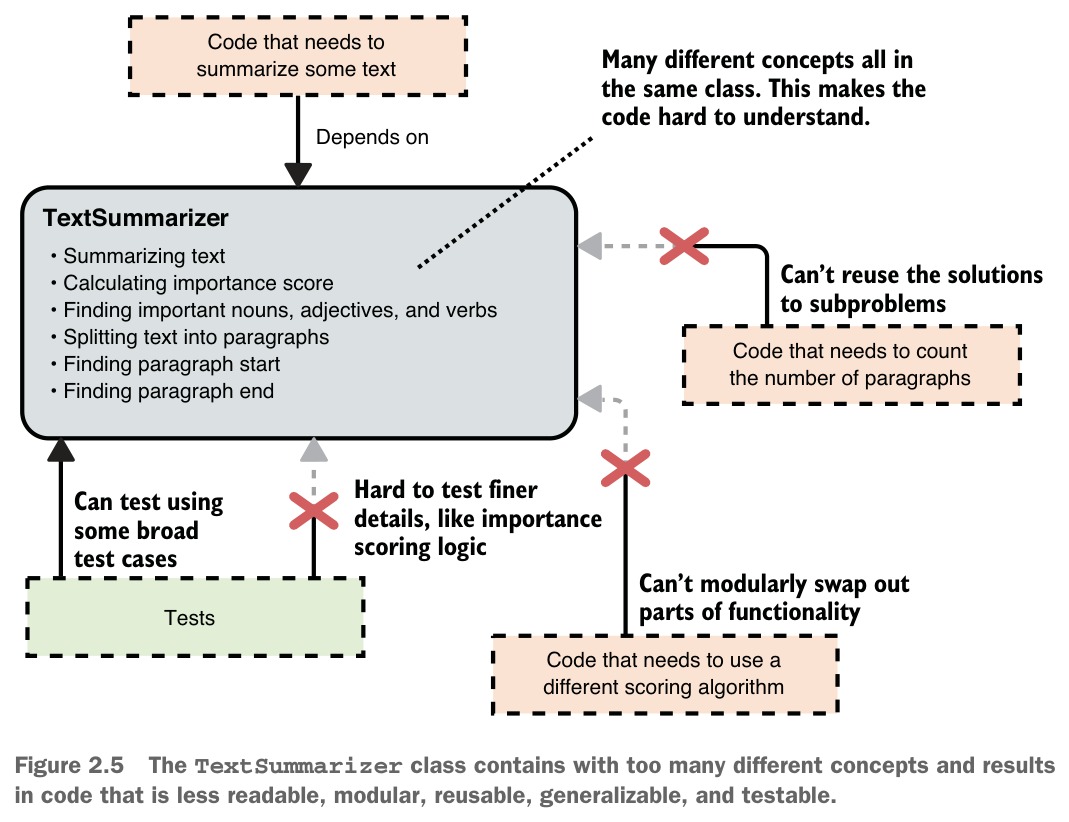
Figure 2.5: The TextSummarizer class contains too many different concepts and results in code that is less readable, modular, reusable, generalizable, and testable.
改善方式: 將每個子問題的解決方案拆分為獨立的類別,並透過建構式注入依賴(dependency injection):
TextSummarizer— 只負責高階邏輯:找段落、過濾不重要的、合併ParagraphFinder— 負責將文字拆分為段落TextImportanceScorer— 負責計算文字重要性分數
這樣每個類別只需處理少數概念,讀者可以在幾秒內理解每個類別的作用。
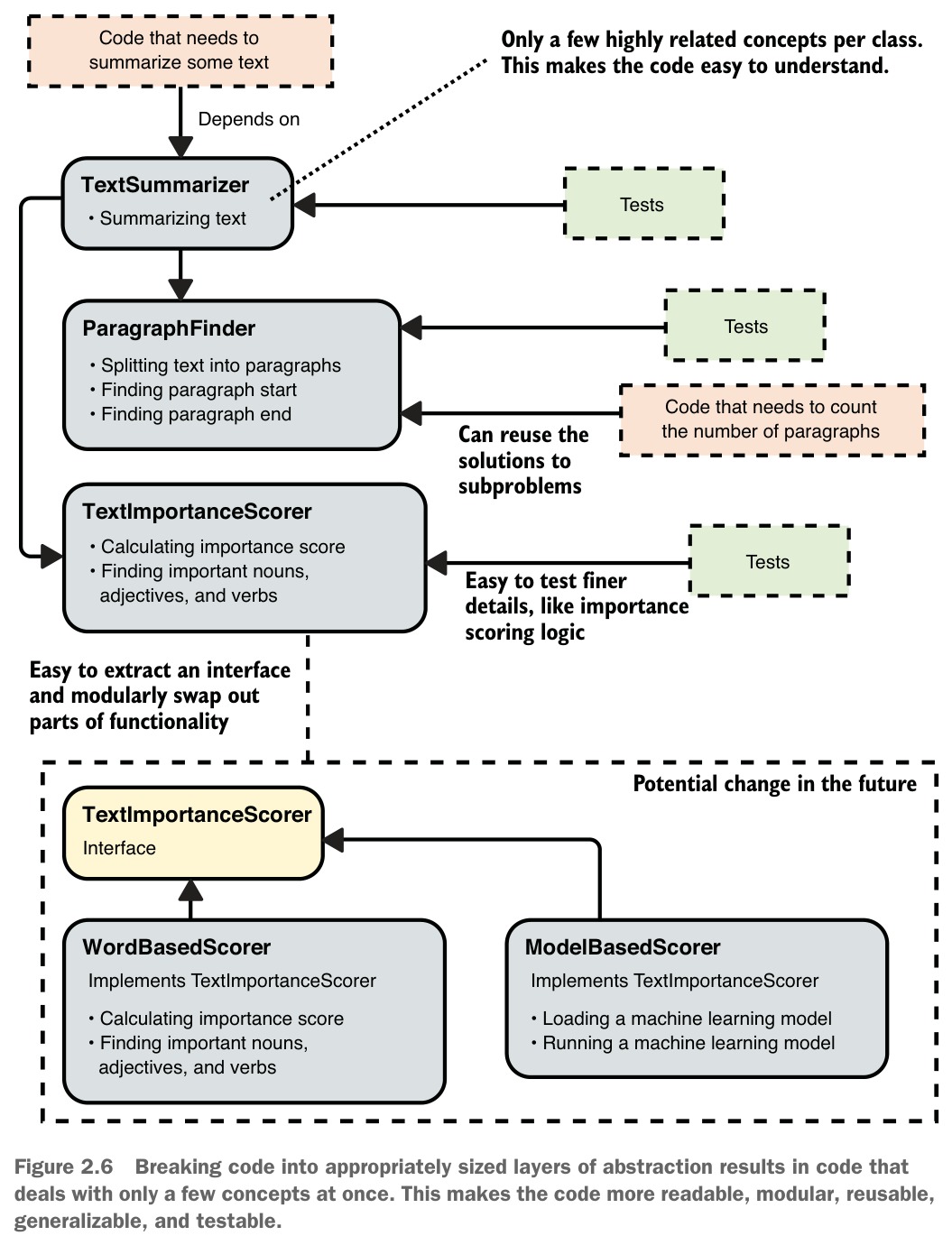
Figure 2.6: Breaking code into appropriately sized layers of abstraction results in code that deals with only a few concepts at once.
介面:何時使用#
當某個抽象層有超過一種實作,或預期未來會新增更多實作時,通常應該定義介面(interface)。
延續 TextSummarizer 的例子:原本基於關鍵字的評分方式(WordBasedScorer)較為簡樸,若想實驗以機器學習模型進行評分(ModelBasedScorer),可以將 TextImportanceScorer 提取為介面,兩種實作各自獨立。TextSummarizer 只依賴介面,不直接依賴任何具體實作類別。
透過工廠函式(factory function),可以輕鬆配置使用哪種評分策略。
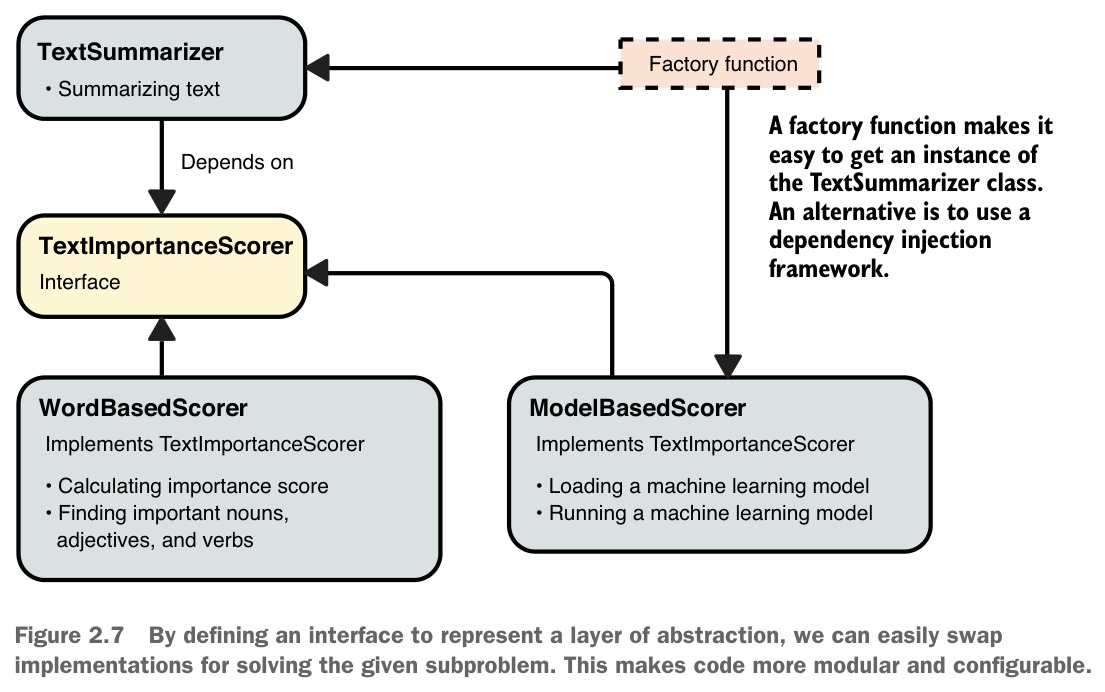
Figure 2.7: By defining an interface to represent a layer of abstraction, we can easily swap implementations for solving the given subproblem.
每個類別都需要介面嗎?#
若只有一個實作且不預期新增更多,是否定義介面取決於團隊偏好。定義介面的好處:
- 公開 API 更清晰 — 不會意外暴露不該公開的函式
- 預防猜錯 — 最初以為不需要第二個實作,後來可能被推翻
- 更容易測試 — 可用 mock 或 fake 替換
- 同一類別可解決多個子問題 — 例如
LinkedList可同時實作List和Queue介面
定義介面的缺點:
- 需要多寫一些程式碼
- 增加導覽程式碼的複雜度(從介面到具體實作需要多跳一步)
務實建議: 不必極端地為每個類別都定義介面,那樣往往會使程式碼過度複雜。在確實有好處時使用介面,而非為了做而做。但即使不定義介面,仍應仔細思考類別暴露哪些公開函式,確保不洩漏實作細節,並讓類別在未來需要時能輕鬆抽取介面。
當抽象層太薄#
儘管拆分有諸多好處,也有一些成本:
- 更多程式碼行數(類別定義、匯入依賴的樣板程式碼)
- 追蹤邏輯時需在檔案或類別之間切換
- 若使用介面,需更多心力找出實際使用的實作
例如將 ParagraphFinder 中的段落起始/結束偵測再拆分為 ParagraphStartOffsetDetector 和 ParagraphEndOffsetDetector,層可能就太薄了——很難想像這些類別會被 ParagraphFinder 以外的地方使用。
層的厚度原則: 層太厚的問題通常比層太薄更嚴重。如果拿不定主意,寧可偏向讓層薄一些。決定適當的層厚度需要判斷力,並考慮程式碼是否滿足可讀、可重用、可泛用、模組化、可測試等品質要求。即使是資深工程師,在提交程式碼之前也常需要幾次迭代才能找到正確的抽象層劃分。
Microservices 與抽象層#
在微服務架構(microservices architecture)中,個別問題的解決方案被部署為獨立服務。有人認為使用微服務後,程式碼內部的結構和抽象層就不重要了,因為微服務本身就提供了乾淨的抽象層。
但這種觀點忽略了一個事實:微服務通常有足夠的規模和範圍,內部仍然需要妥善思考抽象層的劃分。例如一個管理庫存的微服務,名義上只做「管理庫存」一件事,但實際上需要解決多個子問題:物品概念、不同倉庫位置、跨國庫存判斷、資料庫介面、資料格式解析等。
結論: 微服務是分解系統、增強模組化的極佳方式,但不改變一個事實——實作服務時仍需解決多個子問題,建立正確的抽象和程式碼分層依然重要。
本章摘要#
- 將程式碼拆分為乾淨且明確的抽象層,能使其更可讀、模組化、可重用、可泛用、可測試
- 可使用函式、類別、介面(以及其他語言特性)來建立抽象層
- 如何劃分抽象層需要運用判斷力和對所解決問題的理解
- 層太厚的問題通常比層太薄更嚴重;若不確定,寧可偏薄