自指與自複製的對話#

Figure 77: 〈陰影〉,馬格利特(René Magritte,1966)

Figure 78: 〈恩典狀態〉,馬格利特(1959)
本章把**自我指涉(self-reference, self-ref)與自我複製(self-reproduction, self-rep)**這兩個機制並置比對。看似不同的現象其實有許多深刻的平行。
隱式與顯式的自指句#

Figure 83: 『句子指向自身』的雙層詮釋
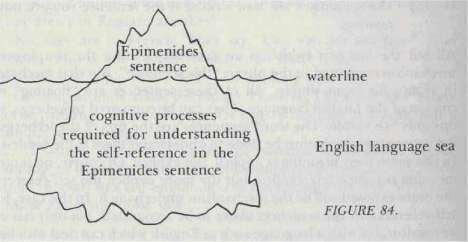
Figure 84: 冰山隱喻——自指句子的可見/不可見部分
幾個常被當作自指範例的英文句子:
- (1) This sentence contains five words.
- (2) This sentence is meaningless because it is self-referential.
- (3) This sentence no verb.
- (4) This sentence is false.(埃皮米尼德斯悖論)
- (5) The sentence I am now writing is the sentence you are now reading.
除最後一例外,這些句子都依賴「this sentence」這個指示詞——表面簡單,實則暗含冰山般的處理機制:使用者必須具備足夠的英文能力來辨識「this sentence」的指涉對象。
對首次接觸悖論的兒童來說,「哪一個句子是錯的?」會困惑很久——這證明這種看似簡單的指涉機制其實一點也不簡單。
不靠「this sentence」的自指#
可以嘗試把句子整個放進引號內:
The sentence "The sentence contains five words" contains five words.但任何有限長度的句子都不能完整引述自己——引號內必須比外面短。
同理,哥德爾字串 G 不能直接包含「自己的哥德爾數的 numeral」——因為這個 numeral 一定比 G 本身長。
解法是讓 G 透過
SUB與arithmoquinification來描述自己的哥德爾數,而不是直接寫出。
Quine 的方法#
Quine 句(「Yields falsehood when preceded by its quotation」preceded by its quotation. yields falsehood)的結構:
- 一個指令部分告訴你如何構造一個短語
- 一個樣板部分作為構造材料
兩者組合產生的字串恰好同構於 Quine 句本身——這比 “this sentence” 更顯式、處理更直接,類似漂在水面的肥皂。
自我複製的程式#
Figure 81: 十二個自我吞食的電視螢幕

Figure 82: 〈空氣與歌〉,馬格利特(1964)
以下用類 BlooP 的語言寫一個自我複製程式:
DEFINE PROCEDURE "ENIUQ" [TEMPLATE]:
PRINT [TEMPLATE, LEFT-BRACKET, QUOTE-MARK, TEMPLATE,
QUOTE-MARK, RIGHT-BRACKET, PERIOD].
ENIUQ
['DEFINE PROCEDURE "ENIUQ" [TEMPLATE]:
PRINT [TEMPLATE, LEFT-BRACKET, QUOTE-MARK, TEMPLATE,
QUOTE-MARK, RIGHT-BRACKET, PERIOD]. ENIUQ'].秘訣:同一個字串在程式中扮演兩種角色——上半部當作程式執行(沒有引號),下半部當作資料代入 TEMPLATE(被引號包住)。
「自我複製分子」(如 DNA)的奧秘也在於此。
越來越精簡的自我複製#
若語言內建 ENIUQ 操作:
ENIUQ ['ENIUQ'].若語言約定「以星號開頭的程式自動先複製一份」:
*不過後者類似於用「I」當作自我指涉範例——它把所有「自我」的繁複都丟給處理器,等於作弊。
什麼算是「複本」?#

Figure 80: 〈美麗的俘虜〉,馬格利特(1947)
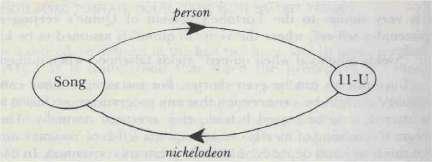
Figure 86: 自我複製的歌(點唱機循環)
幾個邊界案例:
- 自我複製的歌:投幣式點唱機聽到
11-U就播放唱著11-U的歌——但11-U只是觸發器,主要資訊仍在機器中 - 倒過來印出自己的程式:是否為自我複製?多數人會接受,因為倒序的解碼器很「普世」
- 印出自己的翻譯版(如英譯法):類似於跨調卡農
- 印出自己的哥德爾數:BlooP 的 OUTPUT 只能是數字,於是把自己編碼為長整數——這就是 G 的精神
G 是透過翻譯實現自指——TNT 不能直接談論 TNT 字串,但可透過哥德爾編號這個同構,間接地談論。
自我複製的多種變體#
- 加倍卡農(augmentation canon):印出自己,但帶有不同的執行速度參數——下一代會更慢
- 生物物種:父代與子代並不一模一樣,但保留物種特徵的同構
- Kim 式自我複製:故意輸入會引發特定錯誤訊息的「程式」,使編譯器吐出與輸入相同的錯誤訊息——利用系統的不同層次
什麼是「原本」?#
- 程式 P 被某直譯器 I 在處理器 H 上執行,印出自己——自我複製者是程式?還是 P+I 的組合?還是 P+I+H?
在最有趣的自我複製範例中,資料、程式、直譯器、處理器全都纏繞在一起,自我複製意味著一次性複製所有這些。
Typogenetics:印刷遺傳學#
Figure 79: 菸草鑲嵌病毒
作者構造一個玩具系統 Typogenetics,用排版方式模擬分子遺傳學的核心思想——克里克(Francis Crick)的「中心法則」:
DNA → RNA → 蛋白質鏈、鹼基、酶#
四個字母:
A C G T任意序列稱為鏈(strand),例如:
GGGG
ATTACCA
CATCATCATCAT「STRAND」反過來開頭是「DNA」——很合適。
字母也稱為鹼基:
- 嘌呤(purines):A, G
- 嘧啶(pyrimidines):C, T
操作鏈的程式稱為酶(typoenzyme),依序執行若干指令。
15 種氨基酸(指令)#
cut 切斷鏈
del 刪除當前鹼基
swi 切換到對偶鏈
mvr 向右移動一格
mvl 向左移動一格
cop 開啟複製模式
off 關閉複製模式
ina/inc/ing/int 在右側插入 A/C/G/T
rpy 向右搜尋最近的嘧啶
rpu 向右搜尋最近的嘌呤
lpy 向左搜尋最近的嘧啶
lpu 向左搜尋最近的嘌呤每個酶由一串氨基酸構成。
複製模式與互補配對#
A ↔ T G ↔ C複製模式開啟時,酶經過的位置會在「上方」生成互補鹼基(顛倒寫)。最後切斷時,這條互補鏈會分離出來成為新鏈。
「Achilles 配 Tortoise,Crab 配 Genes」——剛好對應 A-T, C-G 的記憶法。
印刷遺傳密碼#
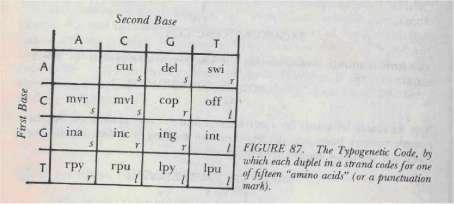
Figure 87: 印刷遺傳碼:雙聯體 → 氨基酸對應表
兩個鹼基構成「雙聯體(duplet)」,共 16 種可能。每種雙聯體翻譯為一個氨基酸(除了 AA 作為「終止標點」):
A C G T
A [punc] cut s del s swi r
C mvr s mvl s cop r off l
G ina s inc r ing r int l
T rpy r rpu l lpy l lpu l每個氨基酸下方還有 s/l/r 標記(直、左折、右折)。
三級結構與綁定偏好#

Figure 88: 印刷酶(typoenzyme)的三級結構(折疊)

Figure 89: 折疊後初末段方位決定酶的綁定偏好
酶有初級結構(氨基酸序列)與三級結構(依 s/l/r 折疊出的二維形狀)。酶的綁定偏好——它會綁定哪種鹼基(A/C/G/T)——由其折疊後第一段與最後一段的相對方位決定。
若折疊後第一段向右、最後一段朝向:
- 向右(同向)→ 偏好 A
- 向上 → 偏好 C
- 向左(反向)→ 偏好 G
- 向下 → 偏好 T翻譯方向#
鏈可被翻譯為酶(透過印刷遺傳密碼),但酶不能被翻譯回鏈——這方向是不可逆的,正如真實生物中蛋白質無法直接被反向轉錄為 DNA。
印刷遺傳學的中心法則#
translation
鏈 ─────────────→ 酶
↑ │
│ 作用於鏈 │
└─────────────────┘- 鏈同時扮演程式(編碼酶)與資料(被酶操作)
- 對比 MIU 系統:那裡規則與字串嚴格分層;這裡兩者糾纏
Typogenetics 的玩家扮演「ribosome(核醣體)」與「processor(處理器)」的角色。
謎題:能設計一條 Typogenetics 鏈,使其經過酶作用後最終產生兩份自身的副本嗎?這正是「自我複製生命」的最低限度玩具版。
與真實遺傳學的對應#

Figure 91: DNA 的四種鹼基
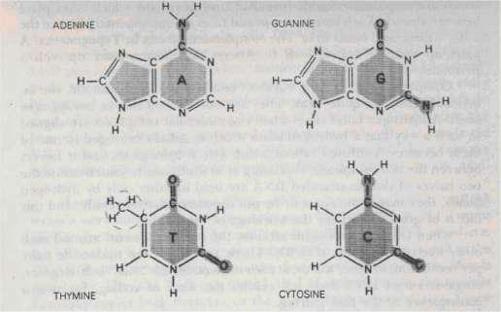
Figure 92: DNA 雙螺旋的階梯結構
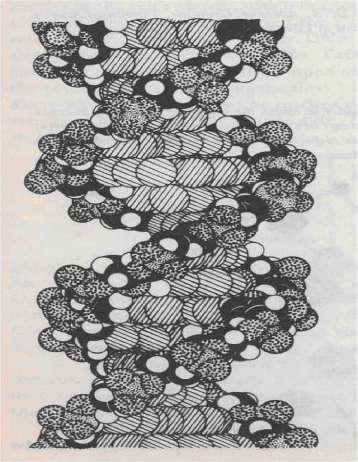
Figure 93: DNA 雙螺旋分子模型
- DNA:脫氧核糖核酸;由四種核苷酸(A, T, G, C)構成的長鏈
- 雙螺旋:兩條互補鏈以氫鍵連接(A=T 兩鍵、G≡C 三鍵),每十個核苷酸一圈
- 核醣體(ribosome):細胞質中的酶製造設施
- mRNA:把 DNA 中的編碼從細胞核搬到細胞質,稱為「DNA Rapid Transit Service」
Figure 94: 遺傳密碼:三聯體編碼 20 種氨基酸
真實的遺傳密碼使用三鹼基「密碼子(codon)」對應 20 種氨基酸(而非 Typogenetics 的 2 鹼基對應 15 種氨基酸)。
自指與自複製:兩個世界的同構#
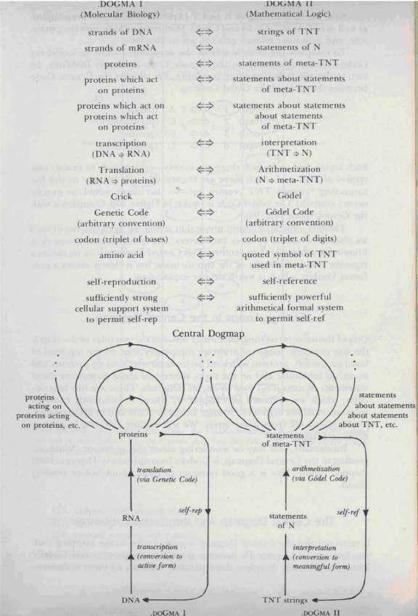
Figure 99: Central Dogmap:分子生物學與 TNT 的糾纏層級對照
把 TNT 中「字串與其後設陳述」的關係,與分子生物學中「DNA 與其產生的蛋白質」的關係並置:
TNT 中:
- 字串可在系統內談論其他字串(透過哥德爾編號)
- G 字串能說「我不是定理」——產生自指
分子生物學中:
- DNA 編碼蛋白質
- 某些蛋白質(如 DNA 聚合酶)負責複製 DNA 本身——產生自複製兩個系統的核心精神都是糾纏層級(tangled hierarchy):
- 一邊是符號 / 字串 / 公式
- 另一邊是規則 / 酶 / 蛋白質
兩者由翻譯機制連接,並在某個臨界點上回頭作用於自身。
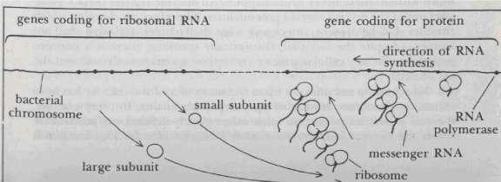
Figure 98: Ribosome:多條 mRNA 同步轉錄翻譯

Figure 100: TNT 哥德爾密碼表
預告:奇怪的迴圈#
第 17 章將進一步討論 Church-Turing 論題、Tarski 真理不可定義定理,以及這些結果對人工智慧、心智的隱含意義。