概述#
大多數 web 應用遵循相同的請求流程:browser → web server → application server → database。當使用者負載增加時,瓶頸依序出現在 web server 層、application server 層,最終到 database 層。擴展的結果是一個三角形拓樸——web server 最容易擴展,database 最難擴展。
Space-based architecture 專門設計用來解決高可擴展性、高彈性(elasticity)和高並發問題,也適用於使用者量不可預測且波動劇烈的應用。其名稱源自 tuple space 的概念——多個平行處理器透過共享記憶體進行通訊。
核心思想:移除中央資料庫作為同步約束,改用複製的記憶體內資料格(in-memory data grid),從而提供近乎無限的可擴展性。
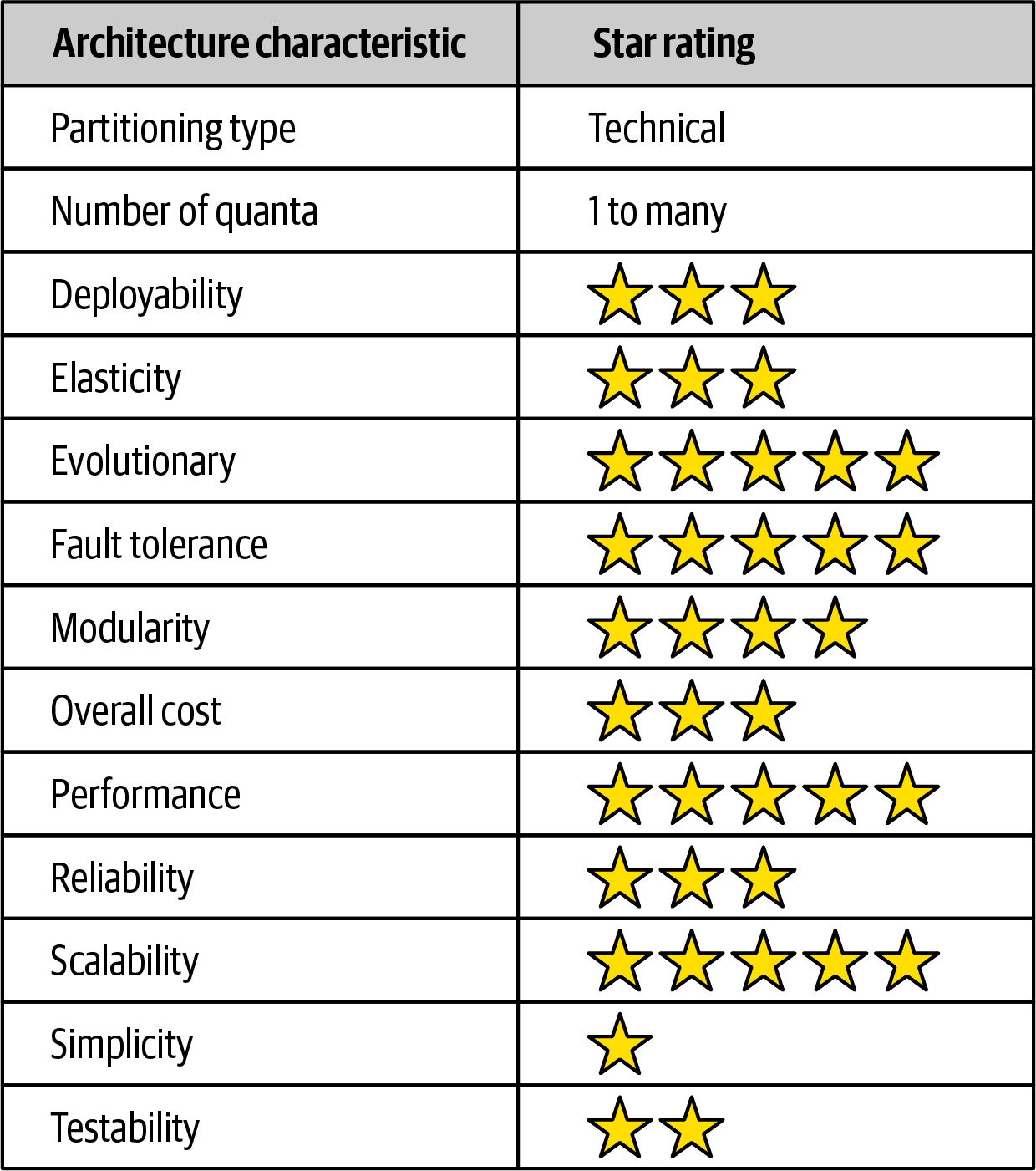
Figure 15.1: Scalability limits within a traditional web-based topology
通用拓樸(General Topology)#
Space-based architecture 由以下主要元件組成:
- Processing unit — 包含應用程式邏輯
- Virtualized middleware — 管理和協調 processing units
- Data pumps — 非同步地將更新資料送至資料庫
- Data writers — 從 data pumps 接收訊息並更新資料庫
- Data readers — 從資料庫讀取資料並送至 processing units
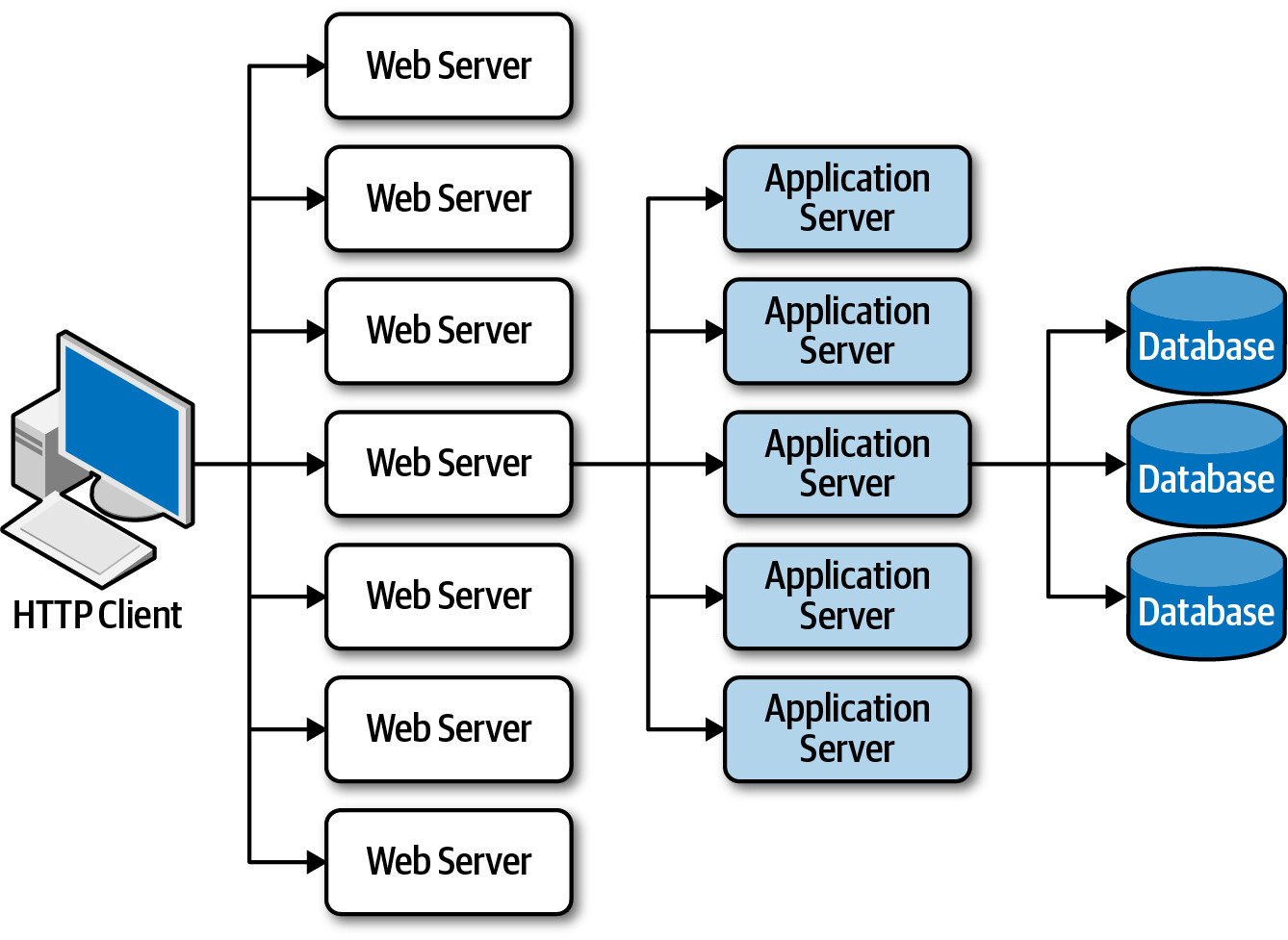
Figure 15.2: Space-based architecture basic topology
Processing Unit(處理單元)#
Processing unit 包含應用程式邏輯(或其部分),通常包括:
- Web 元件和後端商業邏輯
- In-memory data grid — 記憶體內的資料快取
- Data replication engine — 負責在 processing units 之間同步資料
較小的應用可部署為單一 processing unit,較大的應用可按功能區域拆分為多個 processing units。Processing unit 也可以包含小型、單一目的的服務(類似 microservices)。
In-memory data grid 和 replication engine 通常透過 Hazelcast、Apache Ignite 或 Oracle Coherence 等產品實作。
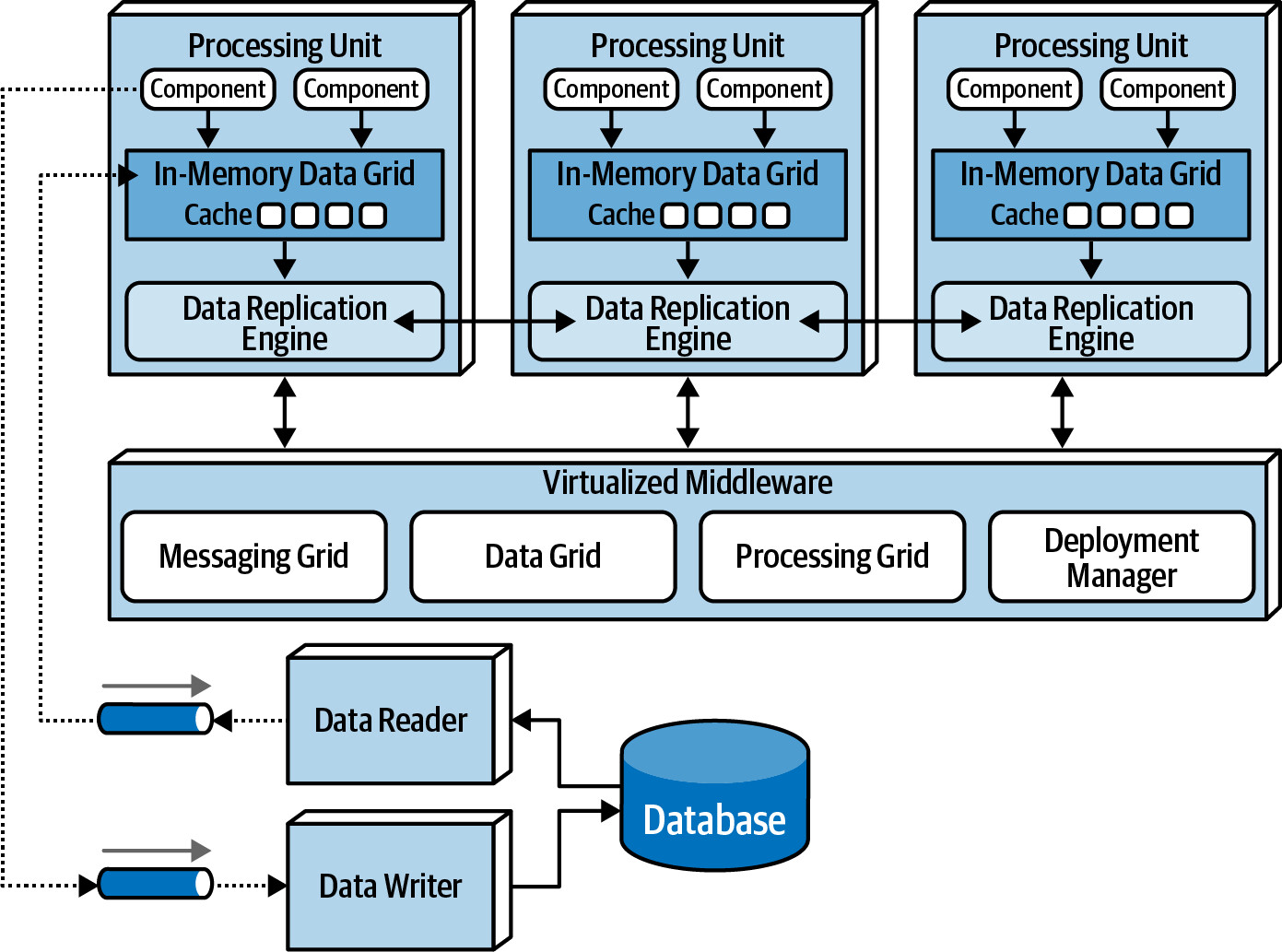
Figure 15.3: Processing unit
Virtualized Middleware(虛擬化中介層)#
處理基礎設施層面的資料同步和請求處理,由四個元件組成:
Messaging Grid(訊息格)#
- 管理輸入請求和 session 狀態
- 決定將請求轉發至哪個可用的 processing unit
- 通常以 HA Proxy 或 Nginx 等負載平衡 web server 實作
- 複雜度從簡單的 round-robin 到追蹤請求分配的進階演算法不等
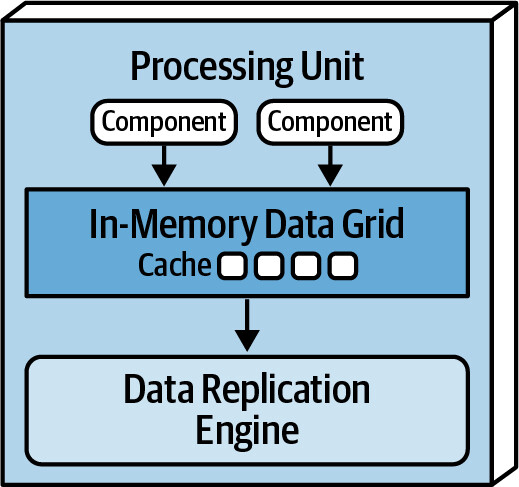
Figure 15.4: Messaging grid
Data Grid(資料格)#
- 此架構中最重要且關鍵的元件
- 在大多數現代實作中,data grid 完全在 processing units 內部以 replicated cache 方式實作
- 每個 processing unit 必須包含完全相同的資料
- 資料同步雖然看起來是同步的,實際上是非同步完成的,通常在 100 毫秒以內
Processing Grid#
- 可選元件,用於管理需要多個 processing unit 類型協調的請求
- 例如:一個訂單 processing unit 和一個付款 processing unit 需要協作時,由 processing grid 協調
Deployment Manager#
- 管理 processing unit 的動態啟動和關閉
- 持續監控回應時間和使用者負載
- 負載增加時啟動新實例,負載減少時關閉實例
- 是實現彈性(elasticity)的關鍵元件
Data Pumps(資料幫浦)#
- 將 processing unit 的快取更新非同步地送往資料庫
- Processing units 不直接讀寫資料庫
- 通常使用 messaging(如 message queue)實作,支援非同步通訊、guaranteed delivery 和 FIFO 排序
- 每個 data pump 通常專用於特定領域或子領域(如 CustomerProfile、CustomerWishlist 等)
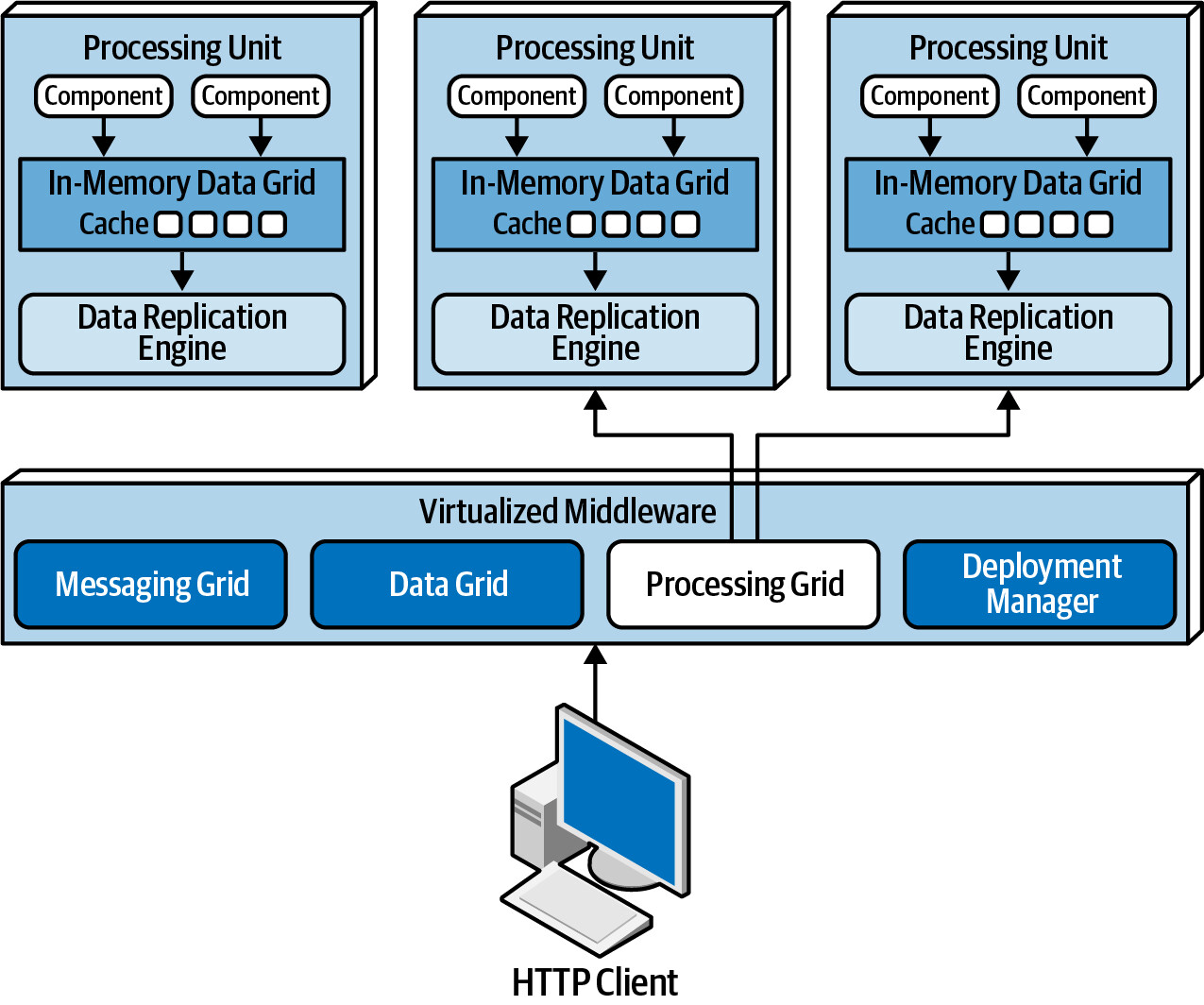
Figure 15.7: Data pump used to send data to a database
Data pumps 使用 contracts(JSON schema、XML schema、object 或 value-driven message)來傳遞資料。更新時通常只傳送新值(而非完整物件)。
Data Writers(資料寫入器)#
- 從 data pump 接收訊息,將資料更新至資料庫
- 可實作為 service、application 或 data hub
- 粒度有兩種模式:
- Domain-based — 一個 data writer 處理同一領域的所有 data pumps(如 Customer data writer 接收 Profile、Wishlist、Wallet、Preferences 四個 data pumps)
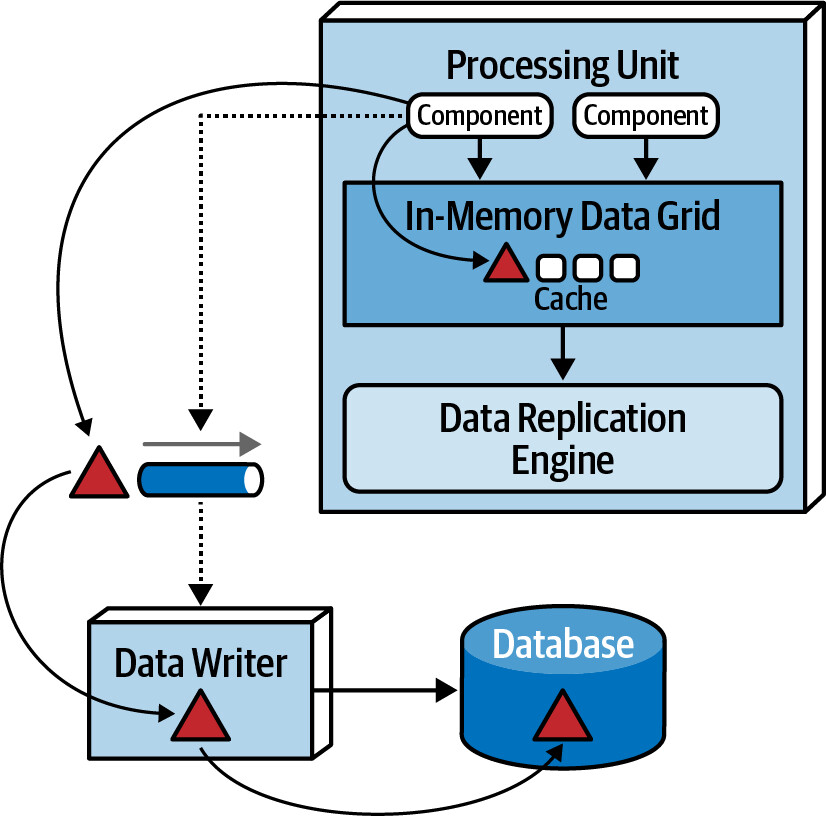
Figure 15.8: Domain-based data writer
- Dedicated — 每個 data pump 各有專屬 data writer,提供更好的可擴展性和敏捷性
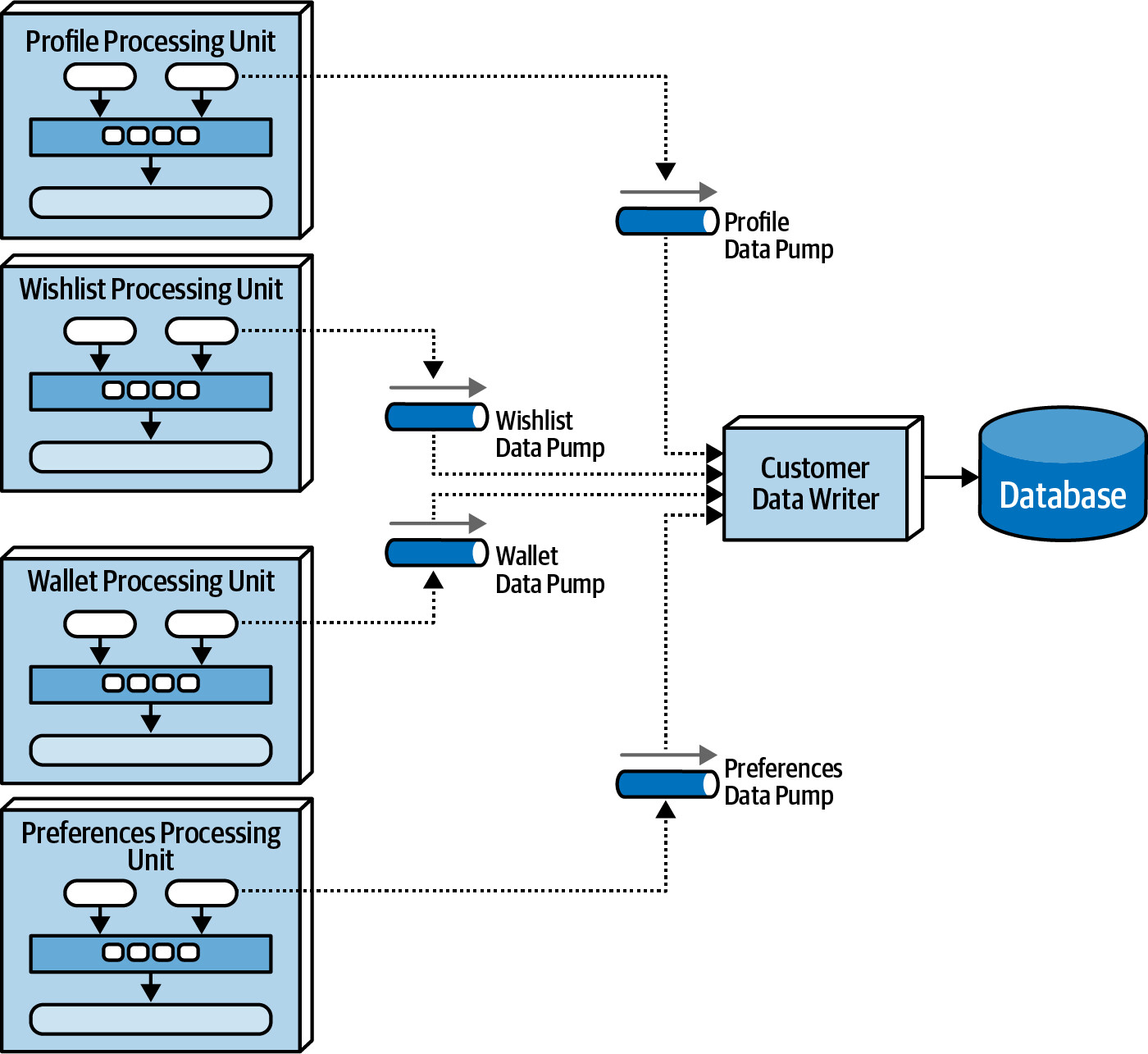
Figure 15.9: Dedicated data writers for each data pump
Data Readers(資料讀取器)#
- 負責從資料庫讀取資料並送至 processing units(透過 reverse data pump)
- 只在以下三種情況下被觸發:
- 同一 named cache 的所有 processing unit 實例全部 crash
- 同一 named cache 的所有 processing units 重新部署
- 需要取得未包含在 replicated cache 中的歸檔資料
當所有實例重新啟動時,第一個取得 cache lock 的實例成為暫時的 cache owner,負責向 data reader 請求資料並載入快取,完成後釋放 lock,其他實例再同步資料。
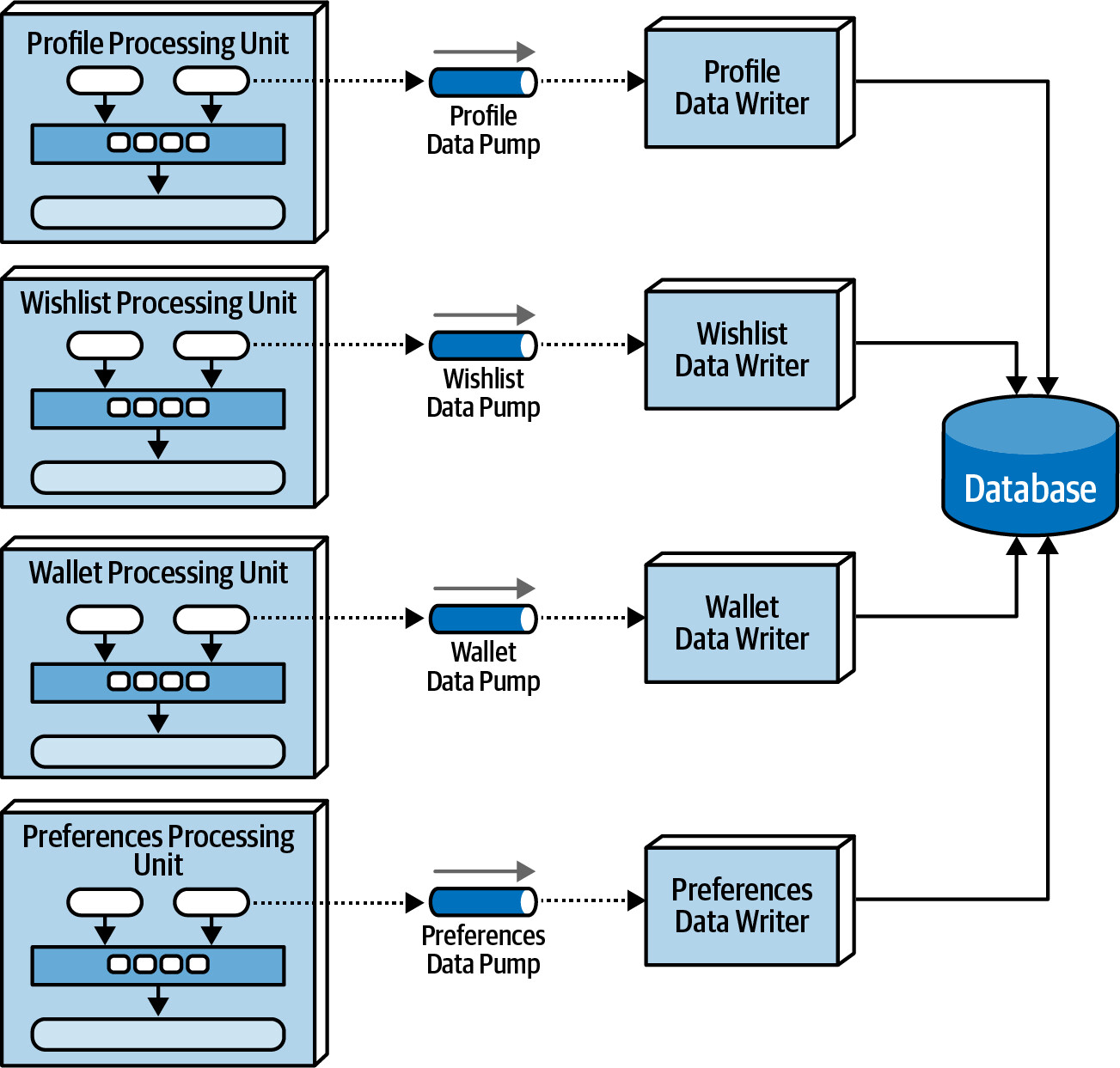
Figure 15.10: Data reader with reverse data pump
Data writers 和 data readers 共同形成一個 data abstraction layer(或 data access layer),使 processing units 與底層資料庫結構解耦。這允許資料庫結構增量變更而不影響 processing units。
Data Collisions(資料碰撞)#
使用 replicated caching(active/active 模式)時,由於 replication latency,可能發生 data collision——兩個 cache 實例同時更新同一筆資料,導致兩個快取都不正確。
碰撞率公式#
CollisionRate = N * UR^2 * S * RL- N = 使用相同 named cache 的服務實例數
- UR = 更新率(毫秒,取平方)
- S = 快取大小(行數)
- RL = replication latency
影響因素#
- Replication latency — 影響最大。從 100ms 降至 1ms,碰撞率可從每小時 14.4 次降至 0.1 次
- Instance 數量 — 從 5 個減至 2 個,碰撞率從 14.4 降至 5.8
- Cache 大小 — 唯一與碰撞率成反比的因素。從 50,000 行減至 10,000 行,碰撞率反而從 14.4 增至 72
使用碰撞率公式計算峰值使用期間的最大更新率,以及最小、正常和峰值碰撞率,有助於評估 replicated caching 的可行性。
Cloud vs. On-Premises 部署#
Space-based architecture 提供獨特的部署選項:
- 全雲端 — 所有元件部署在雲端
- 全地端 — 所有元件部署在 on-premises
- 混合模式 — Processing units 和 virtualized middleware 部署在雲端,database、data readers 和 data writers 保留在地端
混合模式利用了非同步 data pumps 和 eventual consistency 模型的優勢,允許交易處理在動態的雲端環境中進行,同時將資料管理、報表和分析保留在安全的地端環境。
Replicated vs. Distributed Caching#
Space-based architecture 主要依賴 replicated caching,但也可使用 distributed caching。
Replicated Caching#
- 每個 processing unit 擁有自己的 in-memory data grid
- 透過非同步專有協定在所有 processing units 間同步
- 優點:極快速、高容錯(無單點故障)
- 限制:cache 超過 100 MB 時可能影響彈性和可擴展性;高更新率可能超過 data grid 的同步能力
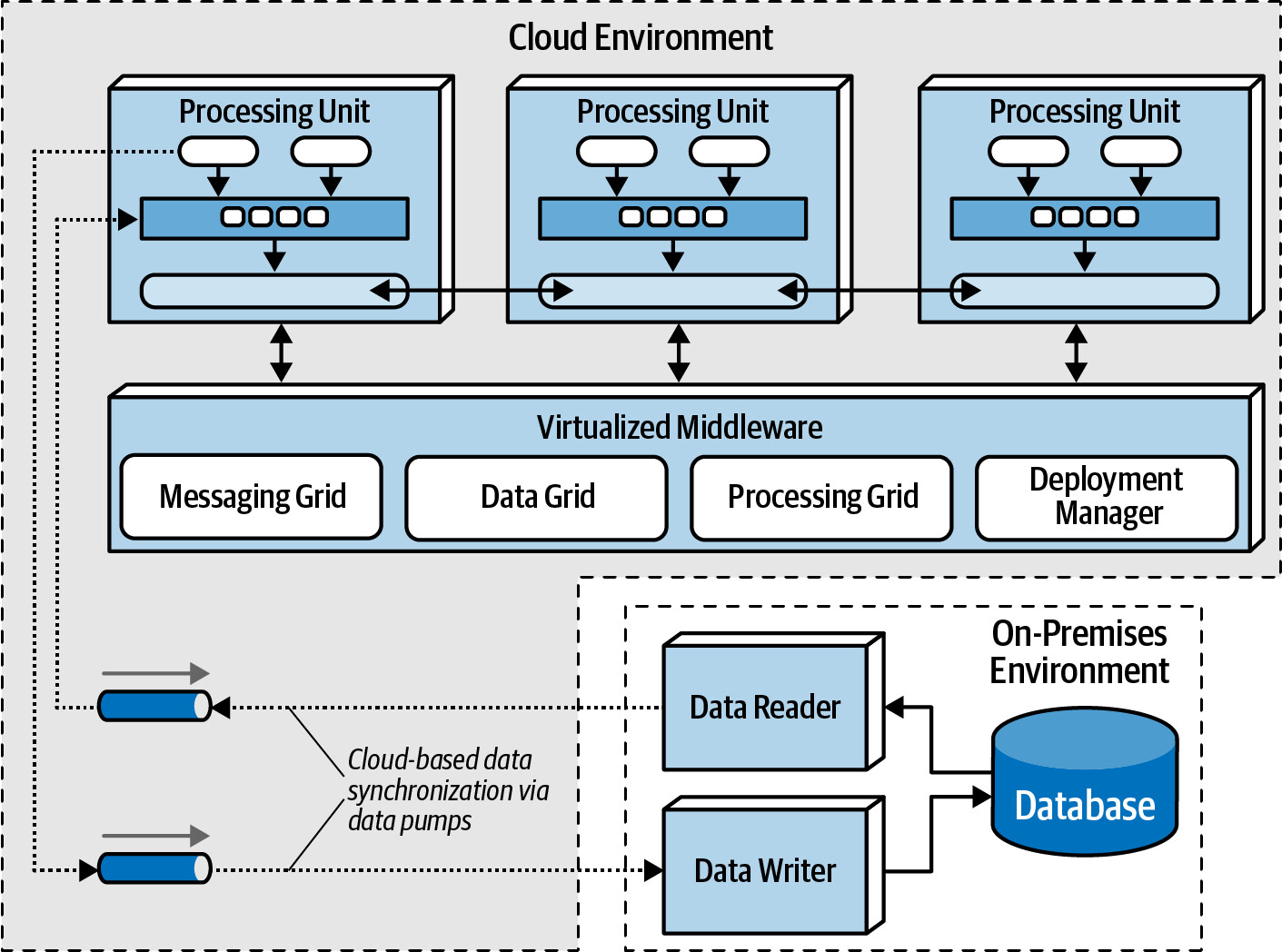
Figure 15.13: Distributed caching between processing units
Distributed Caching#
- 使用外部的集中式 caching server
- Processing units 不在記憶體中存儲資料,透過專有協定存取中央 cache
- 優點:高資料一致性(資料只在一處)
- 缺點:效能較低(需遠端存取)、容錯較差(cache server 當機影響所有 processing units)
選擇指南#
| 決策標準 | Replicated cache | Distributed cache |
|---|---|---|
| Optimization | Performance | Consistency |
| Cache size | 小(< 100 MB) | 大(> 500 MB) |
| Type of data | 相對靜態 | 高度動態 |
| Update frequency | 相對低 | 高更新率 |
| Fault tolerance | 高 | 低 |
在大多數應用中,兩種模型都會同時使用。根據資料性質選擇:庫存等高一致性需求的資料使用 distributed cache;參考資料(如產品描述、代碼對照)等不常變更的資料使用 replicated cache。
Near-Cache 考量#
Near-cache 是一種混合模型,結合 distributed cache(作為 full backing cache)和每個 processing unit 內的小型 in-memory data grid(作為 front cache)。
- Front cache 使用 eviction policy(如 MRU、MFU 或 random replacement)管理容量
- Front cache 與 full backing cache 保持同步
- 但 front cache 之間不互相同步,導致不同 processing unit 可能看到不同的資料
由於 front cache 之間不同步,會造成 processing units 之間的效能和回應性不一致。因此不建議在 space-based architecture 中使用 near-cache 模型。
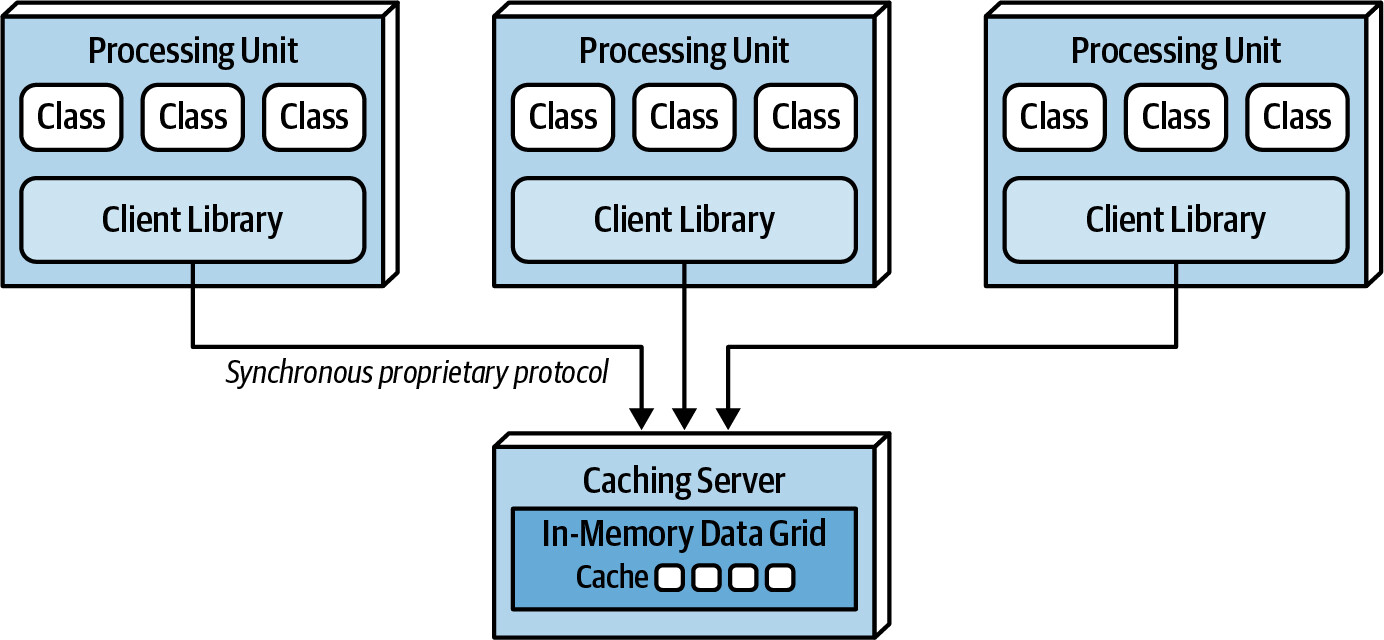
Figure 15.14: Near-cache topology
實作範例(Implementation Examples)#
演唱會售票系統(Concert Ticketing System)#
- 使用者量在演唱會開賣前很低,開賣後瞬間暴增至數千甚至數萬
- 需要高 elasticity、即時更新座位可用性、處理高並發
- Deployment manager 可預先在開賣前啟動大量 processing units 待命
線上拍賣系統(Online Auction System)#
- 拍賣開始時使用者和出價量不可預測
- 需要高效能和高彈性
- 個別 processing unit 可專門服務各拍賣,確保出價資料一致性
- 出價資料透過非同步 data pumps 送至其他處理(如出價歷史、分析、審計),降低延遲
架構特性評分(Architecture Characteristics Ratings)#
| 架構特性 | 評分 |
|---|---|
| Partitioning type | Domain and technical |
| Number of quanta | 1 to many |
| Deployability | ★★★ |
| Elasticity | ★★★★★ |
| Evolutionary | ★★★ |
| Fault tolerance | ★★★ |
| Modularity | ★★★ |
| Overall cost | ★★ |
| Performance | ★★★★★ |
| Reliability | ★★★★ |
| Scalability | ★★★★★ |
| Simplicity | ★ |
| Testability | ★ |
Figure 15.15: Space-based architecture characteristics ratings
評分解析#
- Elasticity / Scalability / Performance(5 星) — 透過 in-memory data caching 移除資料庫瓶頸,可處理數百萬並發使用者
- Simplicity / Testability(1 星) — 使用快取和 eventual consistency 使架構非常複雜;模擬數十萬並發使用者進行測試非常困難且昂貴,大多數高負載測試只能在生產環境中進行
- Overall cost(2 星) — 快取產品授權費用高,加上雲端和地端系統的高資源利用率
- Partitioning type(Domain and technical) — 同時具有 domain partitioning(processing units 可如 domain services 般運作)和 technical partitioning(processing units、data pumps、data readers/writers、database 形成技術分層)
- Quanta 由 UI 與 processing units 的關聯決定。由於 processing units 不直接與資料庫同步通訊,資料庫不屬於 quantum 的一部分