模組化的定義#
Modularity(模組化)是軟體架構中的核心組織原則。在架構討論中,modularity 泛指程式碼的相關分組——class、function 或任何其他邏輯群組。這不一定代表物理上的分離,而是邏輯上的分離。
Modularity 作為概念,應與特定平台所強制的物理分離區分開來。例如,在 monolithic 應用中把大量 class 放在一起可能很方便,但當需要重構架構時,這種 coupling 會成為障礙。
Namespace 是大多數語言提供的模組化機制,用來為軟體資產提供唯一且完整的名稱,避免命名衝突。
衡量模組化 (Measuring Modularity)#
研究者建立了多種與語言無關的指標來幫助架構師理解模組化,主要聚焦在三個關鍵概念:
- Cohesion(內聚性)
- Coupling(耦合性)
- Connascence(共生性)
內聚性 (Cohesion)#
Cohesion 衡量模組內部各部分之間的關聯程度。理想情況下,一個高內聚的模組應該將所有相關的部分包裝在一起,因為將其拆分只會增加模組間的 coupling 並降低可讀性。
Larry Constantine 名言:「試圖拆分一個高內聚的模組,只會導致更高的耦合和更低的可讀性。」
電腦科學家定義了以下內聚性類型,從最佳到最差排列:
- Functional cohesion(功能內聚)——模組的每個部分都彼此相關,且模組包含該功能所需的一切。這是最理想的內聚類型。
- Sequential cohesion(順序內聚)——兩個模組互動時,一個的輸出成為另一個的輸入。
- Communicational cohesion(通訊內聚)——兩個模組形成通訊鏈,各自對資訊進行操作並貢獻輸出。
- Procedural cohesion(程序內聚)——兩個模組必須按特定順序執行程式碼。
- Temporal cohesion(時間內聚)——模組因時間依賴而關聯,例如系統啟動時必須初始化的一組不相關項目。
- Logical cohesion(邏輯內聚)——模組內的資料在邏輯上相關,但功能上並不相關。例如
StringUtils這類工具類別。 - Coincidental cohesion(巧合內聚)——模組中的元素除了在同一個檔案中之外毫無關聯,這是最差的內聚形式。
LCOM 指標#
LCOM(Lack of Cohesion in Methods)是 Chidamber and Kemerer 指標套件中的一個結構性指標,用於衡量模組(通常是 component)的內聚程度。
- LCOM 衡量「未透過共享欄位連結的方法集合」之總和
- 低 LCOM 分數代表良好的結構內聚
- 高 LCOM 分數表示 class 可能應該拆分為多個 class
LCOM 只能發現結構性的內聚缺失,無法從邏輯上判斷各部分是否真正屬於同一模組。這呼應了軟體架構第二定律:偏好 why 而非 how。
耦合性 (Coupling)#
基於圖論(graph theory),我們可以透過分析 call graph 來衡量耦合。Edward Yourdon 和 Larry Constantine 在 1979 年的著作 Structured Design 中定義了兩個核心耦合指標:
- Afferent coupling (Ca)——傳入連結的數量,即有多少外部程式碼依賴此模組
- Efferent coupling (Ce)——傳出連結的數量,即此模組依賴了多少外部程式碼
記憶技巧:字母 a 在 e 之前,對應 incoming 在 outgoing 之前;efferent 的 e 與 exit 的首字母相同,代表傳出連結。
抽象性、不穩定性與主序列距離#
這些衍生指標由 Robert Martin 提出,雖然原為 C++ 設計,但廣泛適用於物件導向語言。
Abstractness(抽象性)#
A = Ma / (Ma + Mc)
- Ma = 模組中的抽象元素數量(interface、abstract class)
- Mc = 具體元素數量(非抽象 class)
- 衡量程式碼中抽象化的比例
Instability(不穩定性)#
I = Ce / (Ce + Ca)
- 衡量程式碼的易變性(volatility)
- 高 instability 表示因高 coupling 而容易因變更而崩潰
Distance from the Main Sequence(主序列距離)#
D = |A + I - 1|
此指標描繪了 abstractness 與 instability 之間的理想平衡關係:
- Main Sequence(主序列)是一條從 (0, 1) 到 (1, 0) 的理想線,代表抽象性與不穩定性的最佳平衡
- 越接近這條線,class 的平衡越好
- 落在右上角的區域稱為 Zone of Uselessness(無用區)——過度抽象,難以使用
- 落在左下角的區域稱為 Zone of Pain(痛苦區)——過多實作、缺乏抽象,脆弱且難以維護
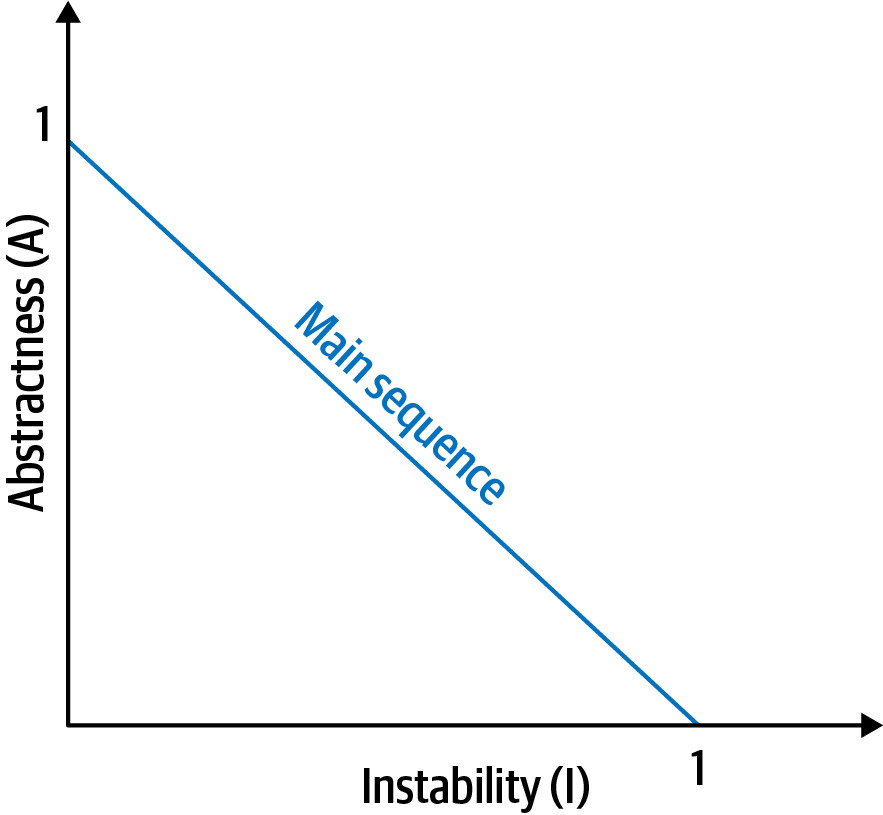
Figure 3.2: The main sequence defines the ideal relationship between abstractness and instability
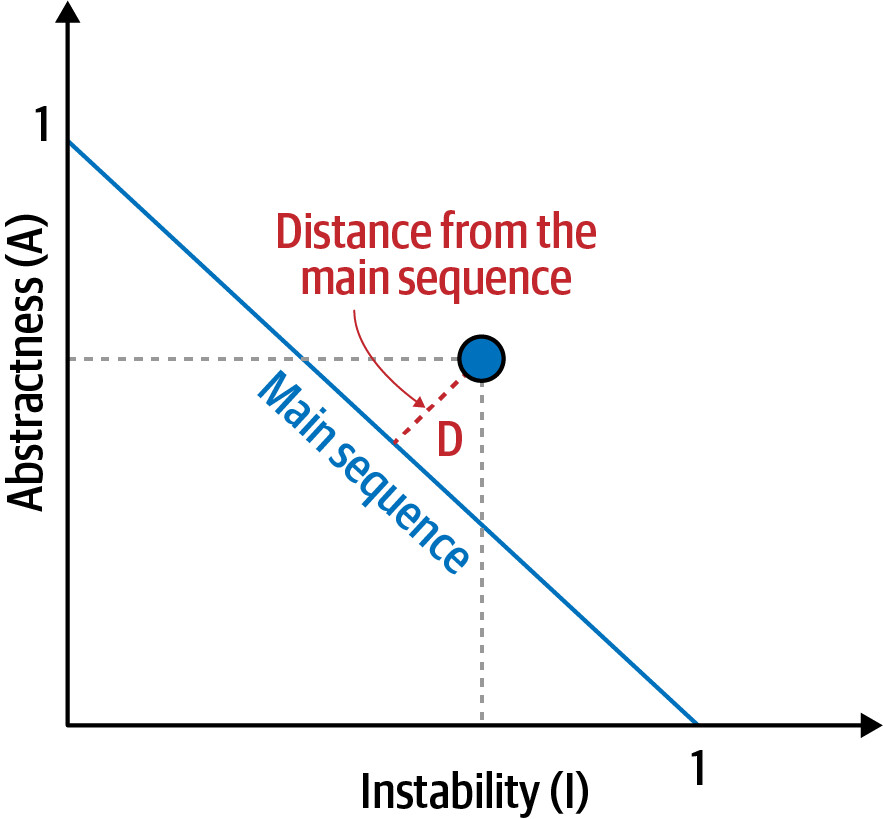
Figure 3.4: Zones of Uselessness and Pain
共生性 (Connascence)#
1996 年 Meilir Page-Jones 在 What Every Programmer Should Know About Object-Oriented Design 中提出了 connascence 的概念,將 afferent 和 efferent coupling 精煉為更適合物件導向語言的形式。
定義:兩個元件是 connascent 的,如果其中一個的變更需要另一個也跟著修改,以維持系統的整體正確性。
Static Connascence(靜態共生性)#
靜態 connascence 指的是原始碼層級的耦合,可透過靜態分析發現:
- Connascence of Name (CoN)——多個元件必須對某實體的名稱達成一致。這是最常見且最理想的耦合形式。
- Connascence of Type (CoT)——多個元件必須對某實體的型別達成一致。
- Connascence of Meaning (CoM)——多個元件必須對特定值的意義達成一致。例如 hard-coded 的 magic number。
- Connascence of Position (CoP)——多個實體必須對值的順序達成一致。例如函式參數的順序。
- Connascence of Algorithm (CoA)——多個元件必須對特定演算法達成一致。例如 client 與 server 端必須使用相同的 hashing 演算法。
Dynamic Connascence(動態共生性)#
動態 connascence 分析執行期的呼叫行為,較難以工具偵測:
- Connascence of Execution (CoE)——多個元件的執行順序很重要。例如必須先設定 email 的屬性才能呼叫
send()。 - Connascence of Timing (CoT)——多個元件的執行時機很重要。典型案例是 race condition。
- Connascence of Values (CoV)——多個值彼此關聯且必須一起變更。例如分散式系統中跨資料庫的交易。
- Connascence of Identity (CoI)——多個元件必須參照同一個實體。例如兩個獨立元件共享同一個 distributed queue。
Connascence 的屬性#
架構師在使用 connascence 時應考慮三個屬性:
Strength(強度)
- 不同類型的 connascence 有不同的重構難度
- 應優先選擇 static connascence 而非 dynamic connascence
- 重構方向:從強的 connascence 轉向弱的(例如將 connascence of meaning 重構為 connascence of name)
Locality(局部性)
- 衡量 connascent 的模組在程式碼中的距離
- 同一模組內較強的 connascence 尚可接受
- 跨模組的強 connascence 則代表 code smell
Degree(程度)
- 衡量 connascence 影響的範圍大小——是少數幾個 class 還是很多?
- 影響範圍越小,問題越小
Page-Jones 的三條準則#
- 透過將系統拆分為封裝元素來最小化整體 connascence
- 最小化跨封裝邊界的 connascence
- 最大化封裝邊界內的 connascence
Jim Weirich 的兩條規則#
- Rule of Degree:將強形式的 connascence 轉換為弱形式
- Rule of Locality:隨著軟體元素之間距離增加,使用更弱的 connascence 形式
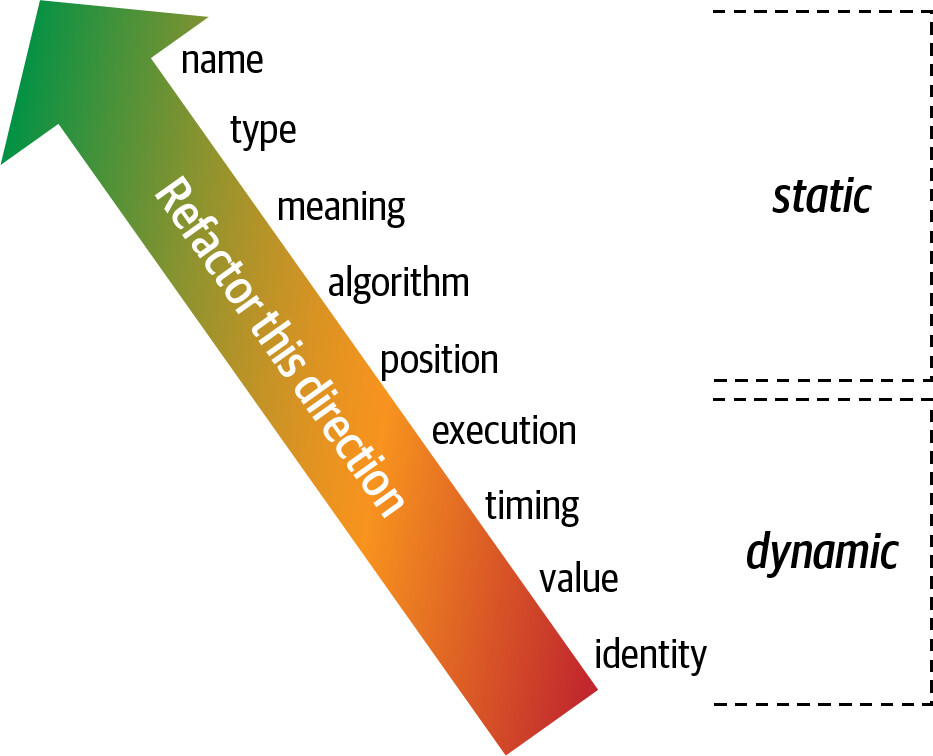
Figure 3.5: The strength of connascence provides a good refactoring guide
統一 Coupling 與 Connascence#
Structured programming 的 coupling 概念與 connascence 概念有重疊之處。Static connascence 本質上是 afferent 或 efferent coupling 的細化程度。Structured programming 只關心連結的方向(傳入或傳出),而 connascence 關心的是耦合的方式。
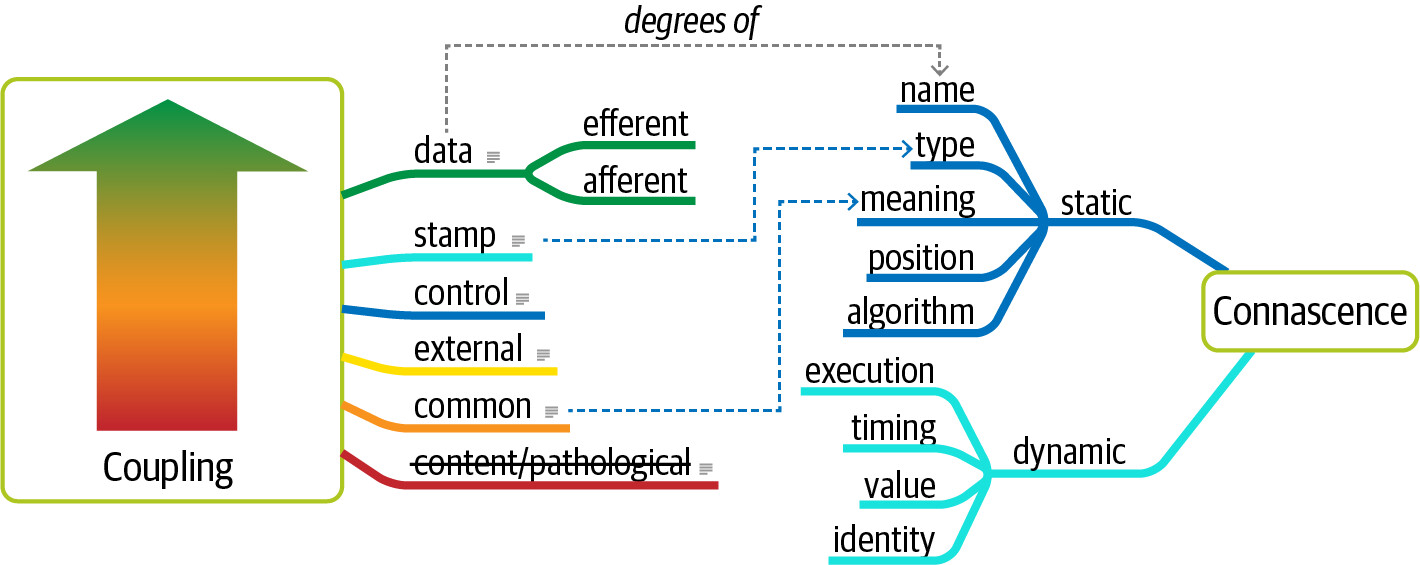
Figure 3.6: Unifying coupling and connascence
1990 年代的 connascence 概念有兩個主要問題:
- 這些指標聚焦於低層級的程式碼品質,而非架構結構。架構師更關心模組如何耦合,而非耦合的程度。
- 它未能真正解決現代架構師面臨的同步 vs. 非同步通訊的根本決策。
從模組到元件 (From Modules to Components)#
本章使用 module 作為相關程式碼的通用術語,但大多數平台都支援某種形式的 component——軟體架構師的關鍵建構單元。元件的概念與分析(邏輯或物理分離)自電腦科學早期就已存在,但開發者和架構師在實現良好的元件化設計方面仍面臨挑戰。
元件的推導將在第 8 章進一步討論,但在此之前,需要先理解架構特性(architecture characteristics)及其範圍。