從遞迴回到資料結構#
到目前為止,函式式編程似乎還算簡單:不要重新賦值,改用遞迴把新值當參數傳給下一次呼叫。但真實程式中的資料元素很少這麼簡單。
本章用一個略複雜的例子——埃拉托斯特尼篩法(Sieve of Eratosthenes)——來檢視這個問題。
篩法的命令式版本#
下面是一個典型的 Java 命令式版本:
public class Sieve {
boolean[] isComposite;
static List<Integer> primesUpTo(int upTo) {
return new Sieve(upTo).getPrimes();
}
private Sieve(int upTo) {
if (upTo < 1) upTo = 1;
isComposite = new boolean[upTo + 1];
Arrays.fill(isComposite, false);
isComposite[0] = isComposite[1] = true;
for (int i = 0; i < isComposite.length; i++)
if (!isComposite[i])
for (int c = i + i; c < isComposite.length; c += i)
isComposite[c] = true;
}
public List<Integer> getPrimes() {
ArrayList<Integer> primes = new ArrayList<>();
for (int i = 0; i < isComposite.length; i++)
if (!isComposite[i]) primes.add(i);
return primes;
}
}這支程式內部充滿賦值與變數,看起來絕不函式式。
但若把目光抬高一點:頂層的靜態方法 Sieve.primesUpTo 本身就是真正的數學函式——傳同一個 n,永遠回傳同一組質數。
我們可以「作弊」地說:雖然底層演算法用了變數,但呈現給外界的結果是函式式的。
關於「作弊」#
我們的電腦本質上是有限的圖靈機(finite Turing machine),不是 λ 演算的執行器。Church–Turing 論題告訴我們兩者等價,但「等價」不代表「容易翻譯」。
函式式程式是「看起來像 λ 演算、但跑在有限圖靈機上」的程式——這必然牽涉某種程度的作弊。
我們已經看過第一個作弊:
- TCO:表面上沒有變數,實際上 TCO 在底層偷偷覆寫堆疊框
- 從圖靈機的角度看,那些「常數」全都是變數
更進一步推:
- 篩法版本的所有變動其實都集中在建構子內,看起來只是「初始化」——而初始化不是賦值
- 我們可以一路推到極端:「跑在這台電腦上的所有程式都是函式式」——只要把整台電腦的記憶體都視為輸入和輸出
但若把作弊推到那麼上層,函式式程式設計就失去研究意義了。所以我們要把作弊往下推——推到實在無法迴避的最底層為止。
實務上不可能避免的作弊只有 TCO:我們沒有無限堆疊,不能讓函式式程式吃掉幾 GB 才崩潰。
用「複製」取代修改#
回到篩法:能不能把作弊推得比 TCO 更低?也就是寫一個完全不使用賦值述句的版本?
主要問題是:
- 兩個
for迴圈必須改成遞迴 - 兩個陣列必須避免就地修改——若每次需要改一個元素,就複製出新陣列
public class Sieve {
static List<Integer> primesUpTo(int upTo) {
return getPrimes(
computeSieve(makeSieve(Math.max(upTo, 1)), 0),
new ArrayList<>(), 0);
}
private static boolean[] makeSieve(int upTo) {
boolean[] sieve = new boolean[upTo + 1];
Arrays.fill(sieve, false);
sieve[0] = sieve[1] = true;
return sieve;
}
private static boolean[] computeSieve(boolean[] sieve, int n) {
if (n >= sieve.length) return sieve;
else if (!sieve[n]) return computeSieve(markMultiples(sieve, n, 2), n + 1);
else return computeSieve(sieve, n + 1);
}
private static boolean[] markMultiples(boolean[] sieve, int prime, int m) {
int multiple = prime * m;
if (multiple >= sieve.length) return sieve;
else {
var markedSieve = Arrays.copyOf(sieve, sieve.length);
markedSieve[multiple] = true;
return markMultiples(markedSieve, prime, m + 1);
}
}
public static List<Integer> getPrimes(boolean[] sieve, List<Integer> primes, int n) {
if (n >= sieve.length) return primes;
else if (!sieve[n]) {
var newPrimes = new ArrayList<>(primes);
newPrimes.add(n);
return getPrimes(sieve, newPrimes, n + 1);
} else {
return getPrimes(sieve, primes, n + 1);
}
}
}雖然不漂亮,但夠函式式了:
- 所有具有意義的賦值都被消滅
- 所有命名的實體都是常數
- 堆疊(若 TCO 未消除)會保留每次遞迴的歷史
代價極高。 每次修改陣列都得整個複製一份,要找出 100,000 以內的所有質數,會產生大量篩子陣列與質數陣列;複製的時間與記憶體成本都讓人卻步。
那麼,這就是函式式編程必須付出的代價嗎?我們真的必須容忍如此鋪張的記憶體與時間消耗嗎?
結構共享:用樹表達陣列#
幸運的是不必。存在一些資料結構,行為上像陣列,又能高效保留所有歷史版本——它們是 n 元樹(n-ary tree)。n 越大,效率越高;為了好懂,先用二元樹(binary tree)說明。
考慮一個整數陣列 [1..8]:
- 用一棵二元樹表示
- 葉子節點順序排列就是陣列本身
- 分支只是用來「以特定順序走訪」每個葉子
- 那個「順序」恰好就是陣列的索引
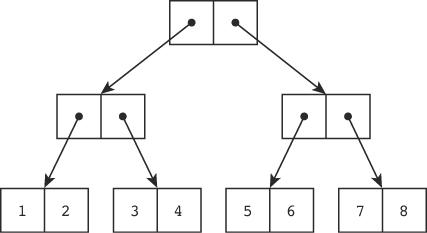
Figure 2.1: 用二元樹表達整數陣列 [1..8]
要存取索引 0 的元素,每一層都走最左分支;要存取索引 1,最後一層走右、其他走左——以此類推。
在尾端附加新值#
現在要把 42 接到陣列尾端,同時保留原陣列。樹會多出一個新的根節點:
- 左上角的舊根仍然代表
[1..8] - 右上角的新根代表
[1..8, 42] - 舊樹的大部分節點被兩個版本共用
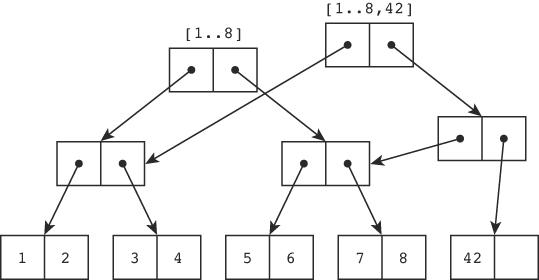
Figure 2.2: 在尾端附加 42、保留原 [1..8] 陣列的二元樹(結構共享)
這個關鍵設計叫結構共享(structural sharing):用樹來表達線性陣列,可以表達新增、插入、刪除等操作,同時保留所有歷史版本,而不需大量複製。
當然還是會有少量複製——可能要複製一個葉節點或幾個分支節點,視操作而定。但相比「整份陣列複製」,所需的記憶體與時間少得多。
將樹的分支因子提高#
實務上會用更大的分支因子。考慮 32 元樹:
- 100 萬個元素的陣列,樹的深度只有約 4 到 5 層
- 每次修改只要複製 5 個 32 元素的節點,遠勝複製 100 萬個元素
- 成本雖然不為零,但對絕大多數應用來說可忽略不計
我們因此得到一種「可索引、可版本化、保留全部歷史版本」的線性陣列,這個性質叫做持久性(persistence)。
此處的「持久性」不要與資料庫上下文中的「持久化儲存」混淆。資料結構的持久性指的是:可以變動,但記得每一個過往版本。
從陣列到所有資料結構#
那高階資料結構呢——雜湊表(hash map)、集合(set)、堆疊(stack)、佇列(queue)?
- 它們全都可以用可索引的陣列實作
- 既然電腦記憶體本身就是一條巨大的可索引線性陣列,那麼任何能在電腦中表達的資料結構,都能用持久性陣列來表達
本章開頭的「複製成本」問題就此被擱置。函式式編程在記憶體與週期上的代價,不應再成為阻止我們深入學習的理由。
從下一章起,所有範例都會以 Clojure 撰寫——這個語言原生支援持久性資料結構。