追求簡單#
本章(乃至全書)的核心主題是追求簡單(simplicity)。人類的認知容量有限,同一時間只能在腦中保持有限的資訊。兩件事最容易耗盡認知容量:
- 耦合的元件:需要同時記住多個相關元件的行為
- 不變量(invariants):需要持續追蹤才能理解功能
這兩個認知殺手分別對應兩種常見的程式設計活動:泛化(generality) 增加了可能的使用方式,導致更多耦合;優化(optimization) 仰賴不變量,增加了維護時的心智負擔。
追求簡單不代表永遠不能優化或泛化,但必須有確鑿的證據說明其必要性。犧牲簡單時,應採取預防措施將負面影響降到最低。
何時泛化、如何泛化#
用「複製 → 轉換 → 統一」獲得最小泛化#
本書推薦的流程——先複製(duplicate)、再轉換(transform)、最後統一(unify)——在統一步驟中自動產生恰好夠用的泛化程度。但這只在功能本身是最小化的前提下才有效。
只建造需要的東西#
Maximize the amount of work not done. — Kent Beck
如果一開始就建造了超出需求的功能或過度泛化的介面,任何方法都救不了。需求會隨著軟體演進而改變,花在不必要泛化上的實作與維護成本很容易被推翻。作者舉了瑞士刀的比喻:給野外求生者一把瑞士刀是恩賜,但給專業廚師可能不如一把削皮刀實用。設計上為了容納泛化所付出的負擔,可能比泛化帶來的好處更大。
統一穩定性相近的事物#
不要急著將新程式碼與舊程式碼統一。等到兩者達到相近的穩定度再合併,可以避免日後得拆解不必要的泛化。通常第二個實例穩定得比第一個快,第三個更快。
定期排除不必要的泛化#
即使團隊再嚴謹,泛化仍會悄悄滲入。兩個對應的重構模式是 Specialize method 和 Try delete then compile。更有效的做法是監控執行期傳入函式的實際參數——如果某個參數總是傳入相同的值,就可以針對它做特化。
何時優化、如何優化#
效能測試驅動#
程式碼在被證明有問題之前,應視為效能合格。作者建議設定自動化效能測試,只有測試失敗時才啟動優化。常見的三種效能測試:
| 測試類型 | 定義 | 特性 |
|---|---|---|
| 基準測試(Benchmark test) | 「這個方法必須在 14 ms 內完成。」 | 與環境高度耦合,需在接近生產環境中執行 |
| 負載測試(Load test) | 「這個服務每秒需處理 1000 個請求。」 | 對外部因素較有韌性 |
| 效能審核測試(Performance approval test) | 「本次執行不得比上次慢超過 10%。」 | 完全與環境解耦,能偵測意外的效能退化 |
先重構再優化#
重構的目標之一是將不變量局部化(localize invariants)、讓其更清晰。由於優化仰賴不變量,重構良好的程式碼更容易安全地優化。
另一個理由是:編譯器持續進化,對常見慣用寫法(idiomatic code)的優化越來越好。如果我們為了炫技而使用不尋常的位元操作(如用 n & 1 取代 n % 2),反而可能讓編譯器無法辨認我們的意圖,導致程式更慢。寫出良好的慣用程式碼,效能會隨編譯器升級自動改善——這也是延後優化的好理由。
約束理論(Theory of Constraints)#
在並行系統(多執行緒、多服務)中,局部效率的提升通常不會影響全域效率。作者引用 Eliyahu Goldratt 的名著 The Goal 來說明:在從輸入到輸出的串流中,任何時刻都恰好有一個瓶頸工作站(bottleneck)。
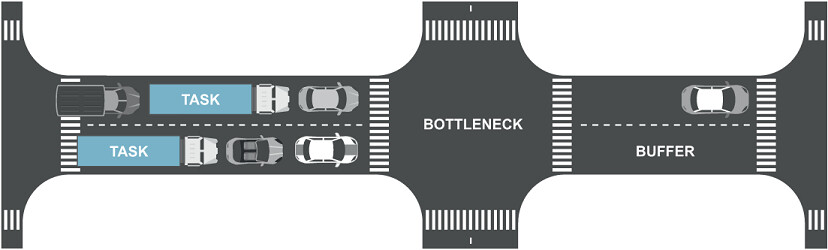
Figure 12.1: Illustration of a system
| 優化位置 | 效果 |
|---|---|
| 瓶頸上游的工作站 | 只會讓瓶頸入口的 buffer 堆積 |
| 瓶頸下游的工作站 | 下游根本拿不到足夠的輸入,毫無效果 |
| 瓶頸本身 | 唯一能提升整體效能的位置 |
資源池化(Resource Pooling) 是軟體中對付瓶頸的利器。將所有可用的處理資源放入共用池,讓瓶頸自動獲得最大可用容量。外部可透過 load balancer 實現,內部可透過 thread pool 實現。資源池化不需理解各階段的執行細節,系統會自動調度。
用 Profiling 指引優化方向#
如果資源池化後仍不滿足效能需求,就需要在瓶頸內部尋找熱點(hot spots)——執行緒花費最多時間的方法。只有透過 profiling 才能可靠地找出熱點。
不要僅憑漸近分析(big O notation)做決策。切換到漸近複雜度更優的演算法,在實務中可能因為 cache miss 等因素反而更慢。多數程式庫的排序函式對小資料使用 O(n^2) 的 insertion sort,而非漸近更優的 quick sort,就是這個道理。效能必須透過量測來驗證。
選擇適當的演算法與資料結構#
最安全的優化方式是替換具有等價介面的資料結構。領域程式碼不需修改就能適應新結構,引入的不變量僅限於使用方式——如果違反了,效能測試會立即捕捉到。
一個進階技巧是局部切換資料結構:在熱點外部先將資料轉換為更適合的結構。例如,linked list 的 sort 方法可以先轉成 array、排序後再轉回 linked list,因為 array 對 cache 更友善。
善用快取(Caching)#
快取的核心概念是:與其重複計算,不如計算一次、儲存結果、重複使用。依安全程度由高到低:
| 函式類型 | 特性 | 快取策略 |
|---|---|---|
| 冪等函式(Idempotent function) | 相同參數永遠產生相同結果 | 可安全地做外部快取 |
| 暫時冪等(Temporarily idempotent) | 結果在一段時間內不變(如商品價格) | 加上過期時間的快取 |
| 非冪等 | 結果隨時可能改變 | 只能做內部快取(如 total 欄位),必須在類別的整個生命週期中維護不變量,風險最高 |
隔離最佳化的程式碼#
當演算法、並行性與快取仍不夠時,最後手段是效能調校(performance tuning / micro-optimization)。作者以 Quake III Arena 中的 inverse square root 函式為例——其中包含 0x5f3759df 這個 magic bit pattern 和「what the fuck?」的原始註解——說明調校過的程式碼幾乎無法被不理解原理的人修改。
因此必須:
- 用方法或類別將調校的程式碼隔離,最小化被鎖定的範圍
- 確保方法或類別命名良好、文件完善、品質嚴格把關
- 將所有調校過的程式碼放進專屬的 package / namespace(作者推薦命名為
magic),在 import 時自然顯示警示,避免未來開發者浪費時間鑽研
本章重點#
- 簡單性就是降低程式碼所需的認知負擔
- 泛化增加耦合風險;透過「複製 → 轉換 → 統一」搭配最小化建造,避免不必要的泛化
- 只統一穩定性相近的事物,定期監控並移除多餘的泛化
- 所有優化都應由效能測試驅動,避免在日常開發中追求優化
- 先重構再優化——重構讓不變量局部化,優化仰賴不變量
- 資源池化可在不增加領域程式碼脆弱性的前提下優化系統
- 選擇適當的演算法與資料結構是最安全的優化方式
- 快取是成本低、引入不變量少的優化手段
- 效能調校必須隔離,避免未來開發者浪費認知資源