本章是 DDD 策略設計的核心章節,探討當大型系統中無法維持單一統一模型時,如何透過明確劃定模型邊界、釐清模型之間的關係,來保持各模型的完整性。Evans 提出了一系列模式,從 Bounded Context 到 Context Map,再到各種 Context 之間的關係策略,形成了一張完整的策略設計導航圖。
Figure 14.1: A navigation map for model integrity patterns
為何需要多重模型#
在大型企業系統中,試圖以單一模型統一所有軟體,存在以下風險:
- 同時替換過多 legacy 系統,導致失敗
- 大型專案因協調開銷過高而停滯
- 有特殊需求的應用被迫使用不完全適合的模型,行為只好放到別處
- 試圖滿足所有人的單一模型變得過於複雜,難以使用
模型的分歧不僅來自技術因素,也來自政治分裂和管理優先順序差異,甚至是團隊組織和開發流程的自然結果。因此,我們需要一種方式來標記不同模型之間的邊界和關係,有意識地選擇策略並一致地執行。
Bounded Context#
Bounded Context 是模型適用範圍的明確邊界。在此邊界內,單一模型保持統一;邊界之外,其他模型適用,術語、概念和規則都可能不同。
模型存在於一個 context 之中。這個 context 可能是某段程式碼、某個團隊的工作範圍、或者一次腦力激盪中的對話。Model context 是一組條件的集合,在這些條件下,模型中的術語才有特定含義。
核心實踐#
- 明確定義模型適用的 context,以團隊組織、應用程式特定部分、程式碼庫和資料庫 schema 等物理表現來設定邊界
- 在邊界內保持模型嚴格一致,不被邊界外的問題分散注意力
- 跨邊界的整合必然涉及某種形式的翻譯(translation)
Bounded Context 不是 Module。 Module 組織的是同一個模型內的元素;Bounded Context 標示的是不同模型之間的分界。Module 在 Bounded Context 內創建的獨立命名空間,反而可能讓意外的模型碎裂更難被發現。
範例:航運公司的 Booking Context#
Evans 以一家航運公司為例,說明如何辨識 Bounded Context 的邊界:
- 在邊界內:模型物件、由模型驅動的資料庫 schema、booking 應用程式
- 在邊界外:legacy 貨物追蹤系統(已決定新模型與 legacy 不同)
- 風險區域:booking 團隊與 voyage scheduling 團隊非正式地共享程式碼,卻沒有意識到他們其實在用不同的模型
定義 Bounded Context 的收益:邊界內的團隊獲得清晰性(clarity),邊界外的團隊獲得自由(freedom)。
辨識 Bounded Context 內的裂痕#
當統一模型開始崩解時,會出現兩類問題:
- Duplicate concepts(重複概念):兩個模型元素實際代表同一概念,每次變更都需更新兩處,最終導致版本分歧
- False cognates(假同源詞):兩人使用相同術語(或實作物件)卻指涉不同事物。如同西班牙語的 “embarazada” 不是 “embarrassed” 而是 “pregnant”
Continuous Integration#
Continuous Integration 在 DDD 中運作於兩個層次:(1) 模型概念的整合,(2) 實作的整合。它是維持 Bounded Context 內模型統一的關鍵流程。
當多人在同一個 Bounded Context 內工作時,模型碎裂的傾向很強。即使只有三四人的小團隊也可能遇到嚴重問題。但將系統拆分成越來越小的 Context,最終會失去寶貴的整合層次和一致性。
有效的 Continuous Integration 流程特徵#
- 逐步、可重複的 merge/build 技術
- 自動化測試套件
- 為未整合變更的存續時間設定合理上限
- 在討論模型和應用時持續運用 Ubiquitous Language
Evans 強調,Continuous Integration 僅在單一 Bounded Context 內是必要的。涉及相鄰 Context 的設計問題(包括翻譯)不需要以同樣的節奏處理。
Context Map#
Context Map 是專案管理與軟體設計的交集。它描繪專案中所有 Bounded Context 的全局視圖,以及它們之間的關係。
人們在不同團隊上工作時,會自然地分裂成不同的 context。物理辦公空間也有影響——在建築物兩端甚至不同城市的團隊成員,若沒有額外的整合努力,很可能會分歧。
核心實踐#
- 識別專案中每個正在運作的模型並定義其 Bounded Context(包括非物件導向子系統的隱含模型)
- 命名每個 Bounded Context,使名稱成為 Ubiquitous Language 的一部分
- 描述模型之間的接觸點,明確標示翻譯機制和共享內容
- 先描繪現有地形,之後再進行轉換
不要說「George 的團隊的東西在改,所以我們跟它溝通的東西也要改。」要說:「Transport Network 模型在改,所以我們需要更新 Booking context 的 translator。」
範例:航運應用中的兩個 Context#
在航運系統中,自動路線規劃功能需要高效的網路遍歷演算法。團隊因此建立了兩個 Bounded Context:Booking Context 和 Network Traversal Context。
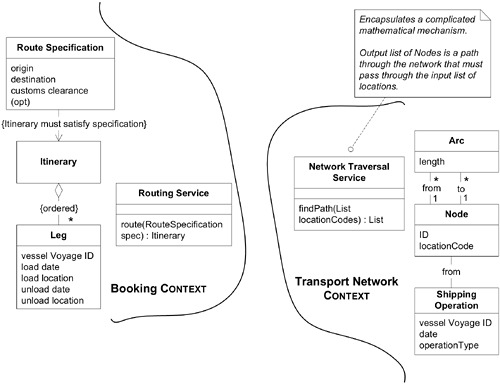
Figure 14.3: Two BOUNDED CONTEXTS formed to allow efficient routing algorithms to be applied
兩個 Context 之間只需要兩個特定的翻譯:
Route Specification→List of location codes(查詢翻譯)List of Node IDs→Itinerary(結果翻譯)
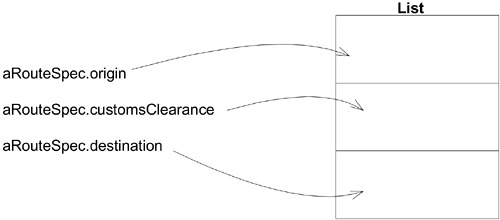
Figure 14.4: Translation of a query to the Network Traversal Service
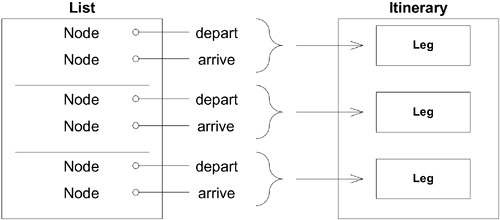
Figure 14.5: Translation of a route found by the Network Traversal Service
翻譯器(Translator)是兩個團隊都需要共同維護的唯一物件。設計上應易於單元測試,兩個團隊最好合作撰寫測試套件。
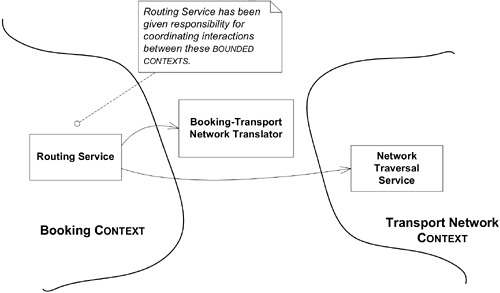
Figure 14.6: A two-way translator
在 Context 邊界進行測試#
與其他 Bounded Context 的接觸點是特別重要的測試對象。測試能補償翻譯的微妙之處,以及邊界上通常較低的溝通水平。正如 Reagan 在核裁軍談判時說的:「Trust, but verify.」
Bounded Context 之間的關係模式#
以下模式涵蓋了一系列策略,從高度合作到完全獨立。主要的考量變數包括:對另一個模型的控制程度、團隊之間的合作層次與類型、以及功能和資料的整合程度。
Shared Kernel#
Shared Kernel 是兩個團隊同意共享的領域模型子集,包含相關的程式碼和資料庫設計。這些共享的部分具有特殊地位,不應在未諮詢對方團隊的情況下變更。
當完全同步整個模型和程式碼庫的開銷太高時,精心選擇的子集可以用較低的成本提供大部分好處。
關鍵實踐:
- 較低頻率地整合功能系統(例如團隊內部每日整合,Shared Kernel 每週整合)
- 整合時需運行兩個團隊的所有測試
- Shared Kernel 通常是 Core Domain、某些 Generic Subdomain,或兩者兼具
- 目標是減少重複(但不是消除,那是單一 Bounded Context 才做的事)
Customer/Supplier Development Teams#
Customer/Supplier 模式適用於一個子系統本質上餵養另一個子系統的情境——「下游」元件進行分析或其他功能,所有依賴都是單向的。
上游團隊的自由開發可能因下游團隊的否決權而受限,同時下游團隊也可能因上游的優先順序而束手無策。
核心實踐:
- 在規劃會議中,讓下游團隊扮演客戶角色,與其他客戶代表協商任務的取捨
- 共同開發自動化驗收測試來驗證預期的介面
- 將這些測試加入上游團隊的測試套件,作為 Continuous Integration 的一部分
兩個關鍵要素:
- 關係必須是客戶與供應商的關係,意味著客戶的需求是最重要的(不是下游團隊來「乞求」上游團隊的「窮親戚」關係)
- 必須有自動化測試套件,讓上游團隊能放心修改程式碼,下游團隊能專注自己的工作
Conformist#
當上下游關係中的上游團隊沒有動力為下游提供服務時,下游團隊面臨三條路:Separate Ways(切斷依賴)、Anticorruption Layer(上游設計難以使用時)、或 Conformist(上游設計品質尚可時)。
Conformist 的選擇意味著:
- 消除 Bounded Context 之間的翻譯複雜性,完全遵從上游團隊的模型
- 雖然限制了下游設計師的風格,但大幅簡化了整合
- 與上游供應商共享 Ubiquitous Language,便於溝通
- 功能只能做純粹的加法擴展,不能修改現有模型
遵從並非總是壞事。 使用具有大型介面的現成元件時,通常應該 CONFORM 到該元件隱含的模型。如果元件夠好而有價值,其設計中很可能蘊含了知識淬鍊的成果。
Conformist 與 Shared Kernel 的差異在於決策和開發流程:Shared Kernel 是兩個團隊緊密協調的合作;Conformist 則是在對方不感興趣合作時的應對之道。
Anticorruption Layer#
Anticorruption Layer 是一個隔離層,以客戶端自己的領域模型術語提供功能。它透過另一個系統的現有介面與之對話,內部在兩個模型之間雙向翻譯。
新系統幾乎總是需要與 legacy 或其他系統整合。當邊界的另一邊開始滲透進來時,翻譯層就必須採取更具防禦性的姿態。
設計考量:
- 公開介面通常是一組 Services(偶爾是 Entity)
- 內部結構由 Facade(簡化對外部系統的存取)、Adapter(轉換協定)和 Translator(轉換概念物件和資料)組成
- Facade 屬於另一個系統的 Bounded Context,只是呈現一個針對你的需求特製的友善介面
- Adapter 的任務是知道如何發出請求;Translator 的任務是執行概念物件或資料的實際轉換
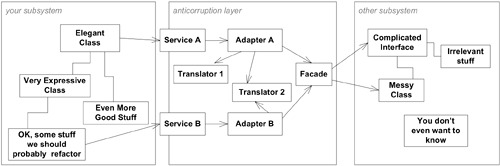
Figure 14.8: The structure of an ANTICORRUPTION LAYER
其他考量:
- Anticorruption Layer 可以是雙向的,在兩端的介面上各定義 Services
- 通訊連結的放置位置(Facade 與外部系統之間、Adapter 與 Facade 之間等)是實務和部署決策,與 Anticorruption Layer 的概念角色無關
- 當整合需求廣泛時,翻譯成本會大幅上升,可能需要在系統設計的模型中做出讓步,使其更接近外部系統,以簡化翻譯
Evans 引用長城的故事作為警示:隔離策略的好處必須與其成本相平衡。長城的建設耗盡了至少一個朝代的國力。任何形式的整合都有開銷,從 Continuous Integration、Shared Kernel、Customer/Supplier,到 Conformist 和 Anticorruption Layer 皆然。
Separate Ways#
如果兩組功能之間沒有不可或缺的關係,就可以將它們完全切斷。宣告一個 Bounded Context 與其他 Context 完全沒有連結,讓開發者在這個小範圍內找到簡單、專門的解決方案。
適用時機:
- 整合沒有提供顯著好處
- 兩個功能部分不調用彼此的功能、不需要物件交互、也不在操作中共享資料
- 功能可以在 middleware 或 UI 層組織,但不共享邏輯,資料轉移降到最低(最好完全沒有)
代價: 走 Separate Ways 會封閉某些選項。完全隔離發展的模型日後要合併是很困難的,屆時翻譯層可能會很複雜。
Open Host Service#
當一個子系統需要與許多其他系統整合時,為每個系統各自定製 translator 會讓團隊負擔過重。Open Host Service 定義一個協定,以一組 Services 的形式開放存取子系統的資源。
核心實踐:
- 開放協定讓所有需要整合的人都能使用
- 根據新的整合需求擴展協定
- 當單一團隊有特殊需求時,使用一次性的 translator 來補充,讓共享協定保持簡單和一致
Published Language#
Published Language 是一種有良好文件記錄的共享語言,可以作為通用的溝通媒介,表達必要的領域資訊。各系統按需翻譯進出這種語言。
為何不直接使用既有的領域模型作為交換格式?
- 領域模型是為了解決使用者問題而開發的,可能包含不必要地複雜化跨系統溝通的特性
- 如果底層的模型被用作溝通媒介,它就不能自由變更以滿足新需求,必須非常穩定
Evans 以 Chemical Markup Language (CML) 為例:這是一種 XML 方言,作為化學領域的通用交換語言。CML 的出現讓過去因各程式使用不同領域模型而困難重重的資料交換變得可行,並催生了原本不值得開發的工具(如 JUMBO Browser)。CML 因基於 XML(一種「已發布的元語言」)而獲得雙重優勢:人們對 XML 的熟悉降低了學習曲線,現成的解析器等工具簡化了實作。
統一大象的寓言#
Evans 引用 John Godfrey Saxe 的「盲人摸象」寓言,生動說明了模型統一的挑戰。六個盲人各自觸摸大象的不同部位,得出了「牆壁」、「蛇」、「樹」、「繩子」等截然不同的模型。
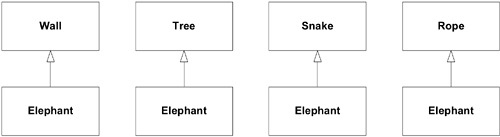
Figure 14.9: Four contexts: no integration
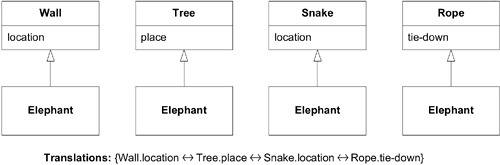
Figure 14.10: Four contexts: minimal integration
如果不需要整合,模型不統一並不重要。但當需要共享更多資訊時,統一模型的價值就上升了。統一多個模型幾乎總是意味著創建一個新模型。
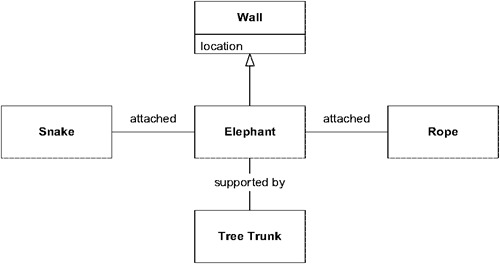
Figure 14.11: One context: crude integration
第一階段的整合可能只需要弄清楚各部分如何相關——把大象視為「一面由樹幹支撐的牆,一端有繩子,另一端有蛇」。雖然粗糙,但可能足以滿足某些需求。
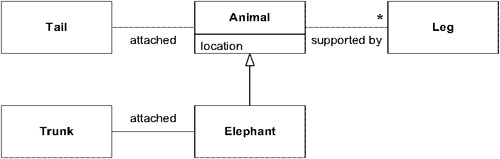
Figure 14.12: One context: deeper model
第二輪的模型整合傾向於去除各個模型中偶然或不正確的面向,創造新的概念——例如「動物」,有「軀幹」、「腿」、「身體」和「尾巴」等部分。成功的模型統一很大程度上取決於最小主義:大象的鼻子既多於蛇也少於蛇,但「少」可能比「多」更重要——寧可缺少噴水能力,也不要有不正確的毒牙特徵。
選擇 Model Context 策略#
權衡大小 Context 的考量#
| 偏好較大 Bounded Context | 偏好較小 Bounded Context |
|---|---|
| 統一模型處理更多使用者任務時,流程更順暢 | 開發者之間的溝通開銷減少 |
| 理解一個一致的模型比理解兩個模型加上映射更容易 | 較小的團隊和程式碼庫更容易進行 Continuous Integration |
| 兩個模型之間的翻譯可能困難(有時不可能) | 較大的 context 可能需要更通用的抽象模型,需要稀缺的技能 |
| 共享語言促進團隊清晰溝通 | 不同的模型可以服務特殊需求或包含專業使用者群體的行話 |
面對外部系統#
- 先考慮 Separate Ways——真的確定需要整合嗎?
- 如果你的應用只是現有系統的擴展,且介面很大,考慮 Conformist
- 當功能更複雜、介面較小、或對方系統設計很差時,建立 Anticorruption Layer
設計中的系統#
- 10 人以下團隊且功能高度相關:單一 Bounded Context
- 團隊增長時:用 Shared Kernel 拆分相對獨立的功能
- 若依賴單向:設立 Customer/Supplier Development Teams
- 若兩組人的思維方式差異太大:讓模型走 Separate Ways,用翻譯層作為唯一的 Continuous Integration 點
一般而言,一個團隊對應一個 Bounded Context。一個團隊可以維護多個 Bounded Context,但多個團隊要在同一個 Context 上合作是困難的(雖然並非不可能)。
flowchart TD
Start{"整合對象?"} -->|外部系統| External{"需要整合嗎?"}
External -->|不確定| SW["Separate Ways"]
External -->|"是,大介面"| Conf{"你控制上游嗎?"}
Conf -->|"否,可接受其模型"| Conformist["Conformist"]
Conf -->|"否,需要保護"| ACL["Anticorruption Layer"]
Start -->|內部團隊| Internal{"團隊規模?"}
Internal -->|"≤10 人,相關功能"| Single["單一 Bounded Context + CI"]
Internal -->|成長中| SK["Shared Kernel"]
Internal -->|單向依賴| CS["Customer/Supplier"]
Internal -->|思維差異大| SW2["Separate Ways + 翻譯層"]部署考量#
- Customer/Supplier Teams 部署新版本時需要協調,確保經過測試的版本組合
- Shared Kernel 在部署上施加更大的協調負擔
- Separate Ways 讓部署更簡單
- 部署計畫的可行性應該回饋到 Context 邊界的劃定
整體權衡#
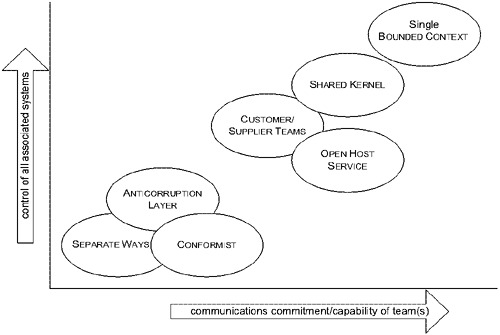
Figure 14.13: The relative demands of CONTEXT relationship patterns
一般而言,你在無縫整合功能的好處與額外的協調和溝通努力之間取捨。你用更獨立的行動換取更順暢的溝通。更有雄心的統一需要對相關子系統設計的控制權。
轉換(Transformations)#
Context 邊界的決策並非不可撤銷。拆分 Context 相對容易,但合併或改變關係是有挑戰性的。
Separate Ways → Shared Kernel#
- 確認兩個 Context 各自內部已經統一
- 建立流程:決定程式碼共享方式、命名慣例,至少每週整合 Shared Kernel 程式碼,並準備好測試套件
- 從一個小型、簡單、不在 Core Domain 的子領域開始——重複存在於兩個 Context 中的東西
- 組成 2-4 人的跨團隊小組,共同設計共享模型
- 實作或調整現有程式碼
- 各團隊分別整合到新的 Shared Kernel
- 移除不再需要的翻譯
Shared Kernel → Continuous Integration#
- 確保兩個團隊各自已有 Continuous Integration 流程,並統一做法
- 開始輪調團隊成員,建立理解雙方模型的人才庫
- 分別釐清各模型的 distillation(見第 15 章)
- 開始將 Core Domain 合併到 Shared Kernel(這是高開銷、容易出錯的階段,應盡量縮短)
- 隨著 Shared Kernel 擴大,提升整合頻率到每日,最終達到 Continuous Integration
- 最終形成一個大團隊或兩個共享程式碼庫、持續整合並頻繁交換成員的小團隊
淘汰 Legacy 系統#
透過 Anticorruption Layer 與 legacy 系統整合後,在每個迭代中:
- 識別可在單一迭代內轉移到新系統的特定 legacy 功能
- 識別 Anticorruption Layer 所需的增補
- 實作
- 部署
- 移除不再需要的 Anticorruption Layer 部分
- 考慮從 legacy 系統中移除已不再使用的模組
Open Host Service → Published Language#
- 如有行業標準語言,評估並盡可能使用
- 若無現成標準,先提煉作為 host 的系統的 Core Domain
- 以 Core Domain 為基礎建立交換語言(盡可能使用如 XML 等標準交換範式)
- 發布給所有相關合作方
- 為每個合作系統建立翻譯層
- 切換上線
Published Language 必須穩定,但你仍然需要自由地變更 host 的模型。因此不要將交換語言等同於 host 的模型。保持兩者接近可以降低翻譯開銷,但保留在需要時發散的權利。
flowchart LR
SeparateWays["Separate Ways"] -->|"建立共享子集"| SharedKernel["Shared Kernel"]
SharedKernel -->|"擴大共享、統一流程"| CI["Continuous Integration"]
Legacy["Legacy System"] -->|"逐步取代"| ModernContext["現代化\nBounded Context"]
OHS["Open Host Service"] -->|"形式化協議"| PL["Published Language"]本章總結#
模型完整性的維護不是自然發生的,它需要有意識的設計決策和特定的流程。本章的核心訊息是:
- 先描繪現實:用 Context Map 如實反映當前狀況,而非理想組織
- 然後改善:根據成本效益權衡,有意識地選擇 Context 邊界和關係策略
- 務實前進:每次小步改變,選擇以最少努力和干擾帶來最大價值的變更
如果大型 Bounded Context 能滿足迫切的整合需求,且除了模型本身的複雜性外在組織上可行,那麼拆分 Context 可能不是最佳答案。下兩章將聚焦於在大型模型內管理複雜性的兩個更廣泛的原則:Distillation(蒸餾)和 Large-Scale Structure(大規模結構)。