每個 Domain Object 都有生命週期:從建立(creation)開始,經歷使用中的各種狀態變化,最終被歸檔或刪除。在這段旅程中,有三大挑戰需要面對:
- 維護整體性(integrity)——物件在整個生命週期中必須維持 invariant
- 管理複雜的建立過程——建立一個含有複雜內部結構的物件不應汙染該物件本身的職責
- 處理持久化技術的干擾——存取資料庫的機制不應淹沒 Domain Model
本章提出三個 Pattern 來分別應對這些挑戰:Aggregate 定義所有權與一致性邊界;Factory 封裝建立與重組的複雜度;Repository 封裝持久化存取的機制。
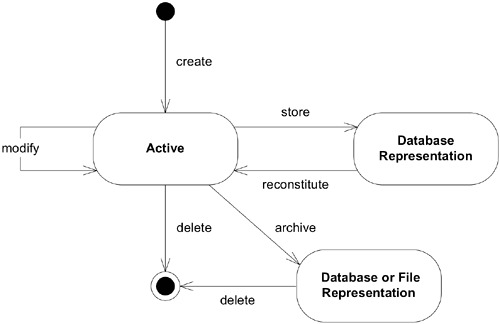
Figure 6.1: The life cycle of a domain object
雖然 Factory 和 Repository 本身不源自 Domain,但它們在 Domain Design 中扮演有意義的角色——為我們提供操作 Model Object 的可用把手(accessible handles)。
flowchart LR
Creation[建立] --> Active[使用中]
Active --> |狀態變化| Active
Active --> Archive[歸檔/刪除]
Creation -.- C1["挑戰2:管理建立複雜度(Factory)"]
Active -.- C2["挑戰1:維護整體性(Aggregate)"]
Archive -.- C3["挑戰3:處理持久化(Repository)"]Aggregate#
問題:物件網絡沒有明確邊界#
即便透過精簡化 association 來控制複雜度,大多數商業領域仍然高度互聯。物件之間的參考路徑又長又深,導致以下問題:
- 刪除困難——刪除一個 Person 物件時,附帶的 Name、Birth Date 可以一起刪除,但 Address 可能被其他 Person 共用。刪了會造成 dangling reference,不刪會累積垃圾資料
- 變更影響範圍不明——即使在單一 transaction 中,物件模型中的關聯網絡也無法清楚界定一個修改可能波及的範圍
- 並行存取衝突——多個使用者同時修改互相依賴的物件時,鎖定範圍的拿捏至關重要。範圍太小會違反 invariant;範圍太大會造成 contention 甚至 deadlock
這些問題表面上看起來是技術層面的資料庫 transaction 問題,但根源在於模型缺乏定義好的邊界。從模型出發的解決方案,會讓模型更容易理解、設計更容易溝通。
Aggregate 的定義#
Aggregate 是一群相關物件的叢集,作為資料變更的單位來看待。每個 Aggregate 有:
- Root——一個特定的 Entity,是 Aggregate 中唯一允許外部持有參考的成員
- Boundary——定義 Aggregate 內包含哪些物件
以汽車修理廠的軟體為例:Car 是擁有全域 identity(車輛識別號碼)的 Entity,Tire 是擁有區域 identity 的 Entity(只需在該 Car 的脈絡下區分)。因此 Car 是 Aggregate Root,Tire 包含在同一 Aggregate 內。反之,Engine Block 有獨立追蹤的序號,在某些應用中可能是自己 Aggregate 的 Root。
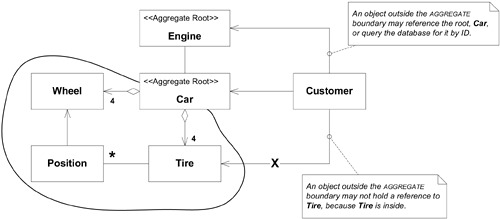
Figure 6.2: Local versus global identity and object references
Invariant 的範圍#
Aggregate 內部的 invariant 必須在每一筆 transaction 完成時被滿足。跨越 Aggregate 的規則則不需要隨時保持最新——可以透過 event processing、batch processing 或其他機制在指定時間內解決。
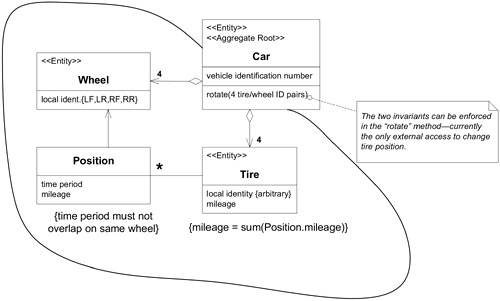
Figure 6.3: AGGREGATE invariants
Aggregate 的實作規則#
- Root Entity 擁有全域 identity,負責檢查 invariant
- 邊界內的 Entity 擁有區域 identity,只在 Aggregate 內部需要唯一
- 外部物件不得持有 Aggregate 內部成員的參考(Root 除外)。Root 可以將內部 Entity 的參考暫時交出,但接收者只能在單一操作中使用,不可長期持有。Root 可以交出 Value Object 的副本
- 只有 Aggregate Root 可以透過資料庫查詢直接取得,其他物件必須透過 traversal 取得
- Aggregate 內部物件可以持有其他 Aggregate Root 的參考
- 刪除操作必須一次移除 Aggregate 邊界內的所有東西
- 當 Aggregate 邊界內的任何物件被 commit 時,整個 Aggregate 的所有 invariant 都必須被滿足
範例:Purchase Order 的完整性#
考慮一個採購訂單(PO)系統,PO 拆分為多個 Line Item,invariant 規則是所有 Line Item 的總和不能超過 PO 的核准上限。
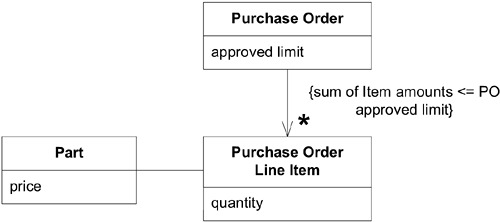
Figure 6.4: A model for a purchase order system
問題一:鎖定粒度太細
如果只鎖定單一 Line Item,兩個使用者可以同時修改同一 PO 的不同 Line Item,結果加總超過上限卻沒人發現。
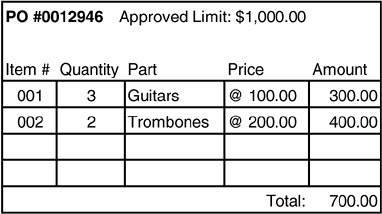
Figure 6.5: The initial condition of the PO stored in the database
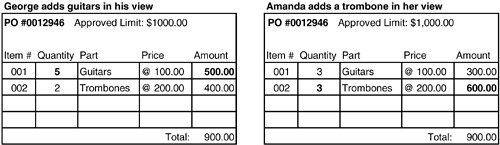
Figure 6.6: Simultaneous edits in distinct transactions
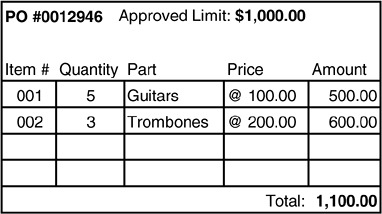
Figure 6.7: The resulting PO violates the approval limit (broken invariant).
問題二:鎖定整個 PO 可以保護 invariant,但可能不夠
鎖定整個 PO 能防止 invariant 被違反,但如果有人同時修改了 Part 的價格呢?
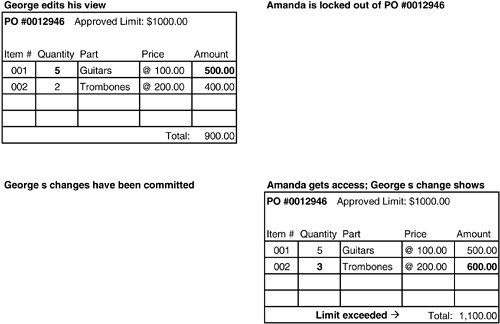
Figure 6.8: Locking the entire PO allows the invariant to be enforced.
問題三:鎖定 Part 會造成嚴重 contention
如果連 Part 也一起鎖定,因為 Part 被很多 PO 共用,會產生大量等待甚至 deadlock。
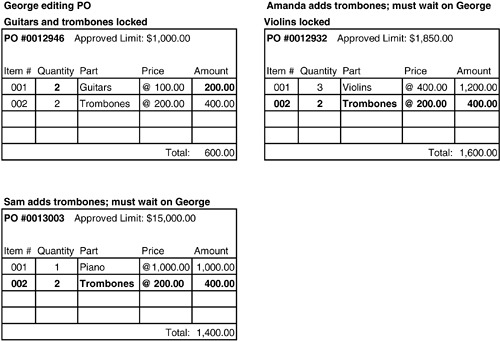
Figure 6.9: Over-cautious locking is interfering with people's work.
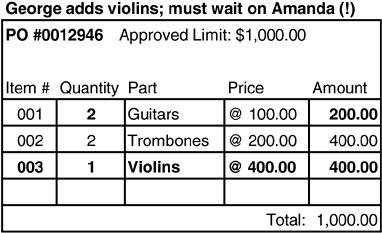
Figure 6.10: Deadlock
解決:運用領域知識重新建模
分析商業實務後發現:
- Part 被許多 PO 使用(高 contention)
- Part 的變更頻率遠低於 PO
- Part 價格的變更不一定需要立即反映到既有 PO(例如已歸檔的 PO 應保留當時價格)
因此,將 Part 的 Price 複製到 Line Item 中,切斷即時依賴。PO 與其 Line Item 構成一個 Aggregate,Part 則獨立於外。跨 Aggregate 的一致性(如價格過期通知)可以用其他方式處理,不必是即時 invariant。
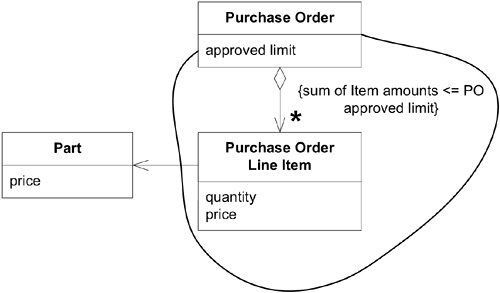
Figure 6.11: Price is copied into Line Item. AGGREGATE invariant can now be enforced.
找到平衡方案的關鍵在於深入理解領域——包括變更頻率、contention 程度等因素。讓高 contention 的關聯更鬆、讓嚴格的 invariant 更緊。
Factory#
問題:物件不該負責自己的建立#
物件在「使用中」已經有足夠的職責,不應再承擔複雜的建立邏輯。就像引擎的職責是轉動曲軸,而非自行組裝——組裝的工作交給機器人或技師,它們只在製造階段發揮作用。
如果讓 client 負責組裝 Domain Object,client 就必須了解物件的內部結構與規則,這會:
- 使 client 變得不必要地複雜
- 破壞 Domain Object 和 Aggregate 的封裝
- 若 client 屬於 Application Layer,職責就洩漏到了 Domain Layer 之外
Factory 的定義#
Factory 是一個專門負責建立其他物件的程式元素。它封裝建立複雜物件或 Aggregate 所需的知識,提供反映 client 目標的介面。
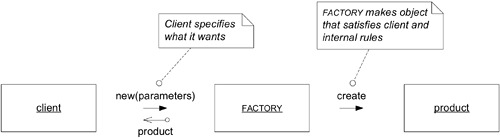
Figure 6.12: Basic interactions with a FACTORY
Factory 的兩個基本要求:
- 每個建立方法是 atomic 的,並強制所建立物件或 Aggregate 的所有 invariant。對 Entity 來說,這意味著建立完整的 Aggregate 並滿足所有 invariant;對 immutable Value Object 來說,所有屬性必須初始化到正確的最終狀態
- Factory 應抽象到所需的型別,而非具體的實作類別
選擇 Factory 的形式與位置#
Factory 的放置取決於你想在哪裡掌握控制權,通常圍繞 Aggregate 來決定。
Factory Method 在 Aggregate Root 上——當需要在既有 Aggregate 內新增元素時,Root 上的 Factory Method 隱藏內部結構,同時確保 Aggregate 的完整性。
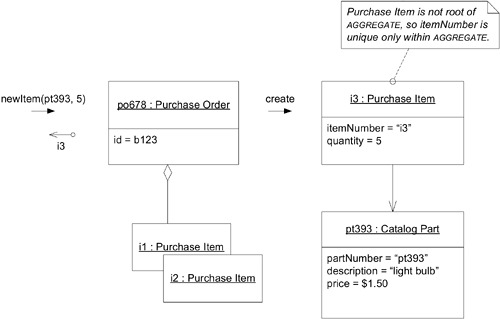
Figure 6.13: A FACTORY METHOD encapsulates expansion of an AGGREGATE.
Factory Method 在密切相關的物件上——即使產出物件不屬於同一 Aggregate,也可以在密切相關的物件上放 Factory Method。例如 Brokerage Account 建立 Trade Order:Account 持有會嵌入 Order 的資訊(包括 Account 本身的 identity),也持有控制哪些交易被允許的規則。

Figure 6.14: A FACTORY METHOD spawns an ENTITY that is not part of the same AGGREGATE.
Standalone Factory——當沒有自然的宿主物件時,建立獨立的 Factory 物件或 Service。Standalone Factory 通常產出整個 Aggregate,交出 Root 的參考,並確保產品的 invariant。
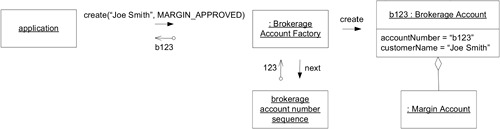
Figure 6.15: A standalone FACTORY builds AGGREGATE.
flowchart TD
Start{建立新物件的情境?} -->|加入既有 Aggregate| AGRoot[Aggregate Root 的 Factory Method]
Start -->|從相關物件衍生| Related[相關物件的 Factory Method]
Start -->|無自然宿主| Standalone[獨立 Factory]
AGRoot --> Ex1["例:Purchase Order\n新增 Line Item"]
Related --> Ex2["例:Trade 產生\nBrokerage Account"]
Standalone --> Ex3["例:複雜 Aggregate\n需要完整組裝"]何時直接使用 Constructor#
在以下情況下,直接使用 constructor 比 Factory 更好:
- 類別本身就是型別,不涉及多型或介面實作
- Client 在意具體實作(例如選擇 Strategy)
- 物件的所有屬性對 client 都是可用的,建構過程中沒有巢狀物件建立
- 建構過程不複雜
即使使用 constructor,也必須遵守與 Factory 相同的規則:必須是 atomic 操作,且滿足所建立物件的所有 invariant。避免在 constructor 內部呼叫其他類別的 constructor。
設計 Factory 的介面#
- 每個操作必須是 atomic 的——在單一互動中傳入建立完整產品所需的一切,並決定建立失敗時的行為(拋出 exception 或回傳 null)
- 謹慎選擇參數以避免耦合——最安全的參數來自較低的設計層。在同一層內,選擇與產品在模型中有密切關聯的物件,這樣不會引入新的依賴
- 使用參數的抽象型別,而非具體類別
Invariant 邏輯放在哪裡#
一般原則是 invariant 應留在物件本身內部。但 Factory 與產品有特殊關係——它已經知道產品的內部結構。以下情況適合將 invariant 放在 Factory 中:
- Aggregate 規則(跨多個物件的 invariant)——放在 Factory 中可減少產品的雜亂
- 建立後永遠不會再被觸發的 invariant(例如 Entity 的 identity 指派規則,建立後 identity 不可變;Value Object 完全不可變)——Factory 是放置這些邏輯的合理位置
Entity Factory vs. Value Object Factory#
| 面向 | Entity Factory | Value Object Factory |
|---|---|---|
| 完整度 | 只需 essential attributes,細節可稍後補充 | 必須提供完整描述,因為產品是 immutable |
| Identity | 可由程式自動指派(Factory 是控制 ID 產生的好位置),或從外部傳入 | 不涉及 identity 指派 |
重組(Reconstitution)已存物件#
Factory 不僅在物件生命之初發揮作用——當物件從資料庫取出或透過網路傳輸時,需要將扁平化的資料重新組裝成活的物件,這也是 Factory 的工作。
用於重組的 Factory 與用於新建的 Factory 有兩個關鍵差異:
- 不指派新的 tracking ID——必須保持與先前化身的連續性,因此 identifying attributes 必須作為輸入參數
- 處理 invariant 違反的方式不同——新建時 Factory 應直接拒絕,但重組時物件已存在於系統某處,不能忽視其存在,也不能忽視規則違反,需要某種修復策略
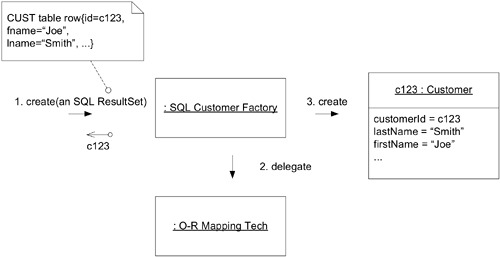
Figure 6.16: Reconstituting an ENTITY retrieved from a relational database
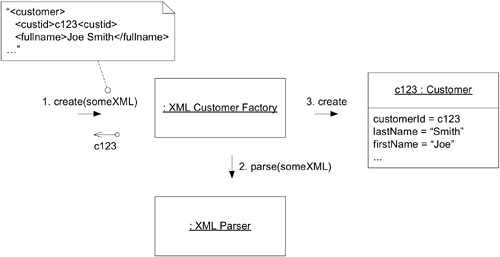
Figure 6.17: Reconstituting an ENTITY transmitted as XML
Repository#
問題:持久化機制淹沒了 Domain Model#
要對物件做任何事,你需要持有它的參考。取得參考有三種方式:
- 建立物件——建立操作會回傳新物件的參考
- 走訪關聯——從已知物件出發,請求相關聯的物件
- 查詢資料庫——根據屬性搜尋
當開發者直接面對 SQL 查詢、result set 轉換、infrastructure 機制時,模型的焦點就消失了。物件退化為資料容器,Domain 規則滲入查詢程式碼或直接遺失。
縮小存取範圍#
並非所有物件都需要全域搜尋存取:
- 暫態物件(通常是 Value Object)——短暫存在,用完即棄
- 透過 traversal 更方便取得的持久物件——例如 Person 的 Address
- Aggregate 內部的物件——禁止從外部直接存取,必須透過 Root traversal
需要全域存取的是 Aggregate Root,通常是 Entity,偶爾是結構複雜的 Value Object 或 enumerated Value。
Repository 的定義#
Repository 將特定型別的所有物件表示為一個概念上的集合(conceptual set),像是一個擁有更精緻查詢能力的 collection。物件被加入或移除,背後的機制處理實際的資料庫插入或刪除。
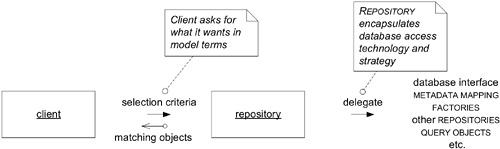
Figure 6.18: A REPOSITORY doing a search for a client
Repository 讓 client 與一個簡單、意圖明確的介面對話,用模型的語言表達需求。
只為真正需要直接存取的 Aggregate Root 提供 Repository。讓 client 專注於模型,將所有物件儲存與存取委託給 Repository。
Repository 的優勢#
- 為 client 提供取得持久物件與管理生命週期的簡單模型
- 將 Application 和 Domain Design 與持久化技術解耦(可替換多種 database strategy 或多個 data source)
- 傳達關於物件存取的設計決策
- 便於用 dummy 實作(in-memory collection)進行測試替換
查詢 Repository#
Repository 查詢介面有不同層次的設計:
Hard-coded queries——最簡單的方式,用特定參數寫死查詢。包括根據 identity 取得 Entity、根據特定屬性值篩選 collection、根據值的範圍(如日期範圍)選取物件、甚至回傳計算摘要(如 count 或數值屬性的加總)。

Figure 6.19: Hard-coded queries in a simple REPOSITORY
Specification-based queries——更靈活的方式,讓 client 描述它想要什麼(specify),不需關心如何取得。這個 Pattern 在第 9 章會深入討論。

Figure 6.20: A flexible, declarative SPECIFICATION of search criteria in a sophisticated REPOSITORY
即使採用了彈性查詢框架,也應允許加入特製的 hard-coded queries 作為 convenience method。不允許此彈性的框架往往會扭曲 Domain Design 或被開發者繞過。
Client 忽略實作,開發者不能#
封裝讓 client 程式碼簡單且與實作解耦,但開發者必須理解底層運作的效能意涵。書中舉例:一個製造業應用在 production 上市後數小時就記憶體耗盡——因為開發者用了 “all objects” 查詢將整個資料庫載入記憶體,而測試環境資料量小所以沒發現。
實作 Repository#
實作因持久化技術而異,但基本特徵是封裝儲存、取回與查詢的機制。
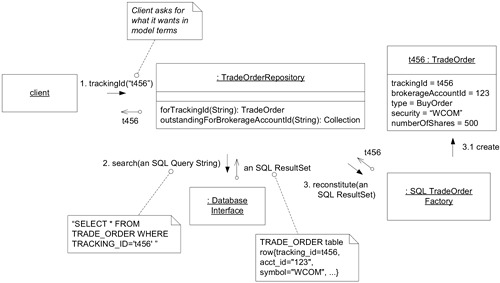
Figure 6.21: The REPOSITORY encapsulates the underlying data store.
實作時的考量:
- 抽象化型別——Repository 不一定對應到每個 class,type 可以是 abstract superclass、interface 或 concrete class
- 善用與 client 的解耦——可自由優化效能(變更查詢技術、快取記憶體中的物件、隨時切換持久化策略),也便於提供 in-memory dummy 進行測試
- 將 transaction 控制權留給 client——Repository 只負責 insert 和 delete,不自行 commit。Client 擁有正確起始與 commit 工作單元的脈絡
與 Framework 共處#
在實作 Repository 之前,審慎思考你承諾使用的 infrastructure 和 architectural framework。框架可能提供便利的服務,也可能與你的設計對抗。不要與框架硬拚——尋找 DDD 概念與框架概念之間的親和性。
Repository 與 Factory 的關係#
- Factory 處理生命之初——建立新的物件
- Repository 管理中段與末段——找到既有物件並提供存取
從技術角度看,Repository 從資料庫重組物件時確實在「建立」物件。但從概念角度看,這是同一個物件的重組(reconstitution),不是建立新的概念物件。
這兩種觀點可以透過讓 Repository 委託 Factory 進行物件重組來調和。Factory 專注於實例化,Repository 專注於封裝持久化。
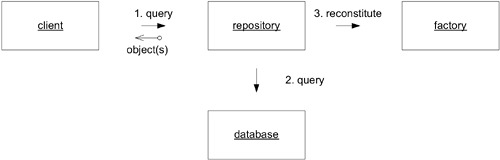
Figure 6.22: A REPOSITORY uses a FACTORY to reconstitute a preexisting object.
當 client 透過 Factory 建立新物件後,可以將它加入 Repository,由 Repository 封裝實際的資料庫儲存。
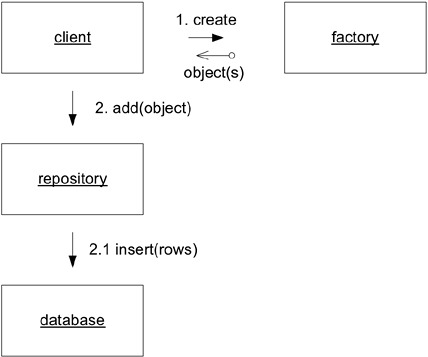
Figure 6.23: A client uses a REPOSITORY to store a new object.
應避免「find or create」功能——如果找不到就自動建立。這混淆了新物件與既有物件之間通常在領域中很重要的區別。需要 Value Object 的 client 可以直接向 Factory 請求一個新的。
為 Relational Database 設計物件#
當 relational database 作為 object-oriented domain 的持久化形式時,有三種常見情境:
- 資料庫主要作為物件的 repository
- 資料庫為其他系統設計(legacy/external)
- 資料庫為本系統設計但同時服務其他角色
資料庫作為物件儲存時的原則#
- 不要讓 data model 和 object model 偏離太遠——mapping tool 再強大也不值得維護兩套重疊的模型
- Table row 應包含一個物件(可能連同 Aggregate 內的附屬物件)
- Foreign key 應對應到另一個 Entity 物件的參考
- Ubiquitous Language 要串聯 object 和 relational 兩端——物件中的名稱與關聯應與 relational table 精確對應
- 外部 process 不應直接存取 object store——可能違反物件強制的 invariant,也會鎖死 data model 使重構困難
- mapping 必須透明,易於透過檢查程式碼或 mapping tool 條目來理解
Object world 中日益盛行的 refactoring 傳統尚未真正影響 relational database design。嚴肅的資料遷移問題阻礙了頻繁變更,這可能對 object model 的重構造成拖累。但如果兩者開始偏離,透明性會迅速喪失。