擴展 API#
確保你的 API 在使用情境與負載兩方面都能擴展,對其成功至關重要。本章涵蓋以下擴展最佳實踐與技巧,協助你打造面向未來的 API:
- 擴展吞吐量(Scaling Throughput)
- 演進 API 設計(Evolving API Design)
- API 分頁(Paginating APIs)
- API 速率限制(Rate-Limiting APIs)
- 開發者 SDK(Developer SDKs)
當你建構一個讓他人依賴的 API 時,可用性(availability)與可靠性(reliability)至關重要。你需要確保 API 不會宕機,並且持續為使用者提供快速的回應。然而,API 可能會突然經歷使用量激增,這可能影響你的服務品質,甚至拖垮你自己的應用程式(如果應用程式也依賴這些 API)。
為了讓 API 支撐更多的呼叫次數,你可以在應用層面做許多事情:
- 資料庫查詢最佳化(Database query optimization)
- 資料庫分片(Sharding databases)
- 補充缺失的索引(Adding missing indexes)
- 利用快取(Utilizing caching)
- 將昂貴的操作非同步執行(Doing expensive operations asynchronously)
- 撰寫高效程式碼(Writing efficient code)
- 調校 Web 伺服器(Tuning web servers)
這些都有助於提升吞吐量、降低延遲。本章第一節僅簡要帶過這些主題,因為它們在其他專門討論 Web 應用效能的書籍中有更深入的介紹。
除了上述最佳化之外,還有另一組經常被忽略、但能顯著幫助 API 擴展的變革——你可以透過改進 API 設計、調整 API 使用政策,或幫助第三方開發者撰寫更高效的程式碼來達成。
你的 API 可能還需要處理越來越大的資料集。分頁(Pagination)是將大型資料集交付給開發者的有效策略。
即使你已經完成了吞吐量擴展、API 設計演進以及分頁處理,開發者仍然有可能以極高的速率發送請求。速率限制(Rate-Limiting)能有效限制開發者的請求頻率,維護整體應用程式的健康。
最後,擴展 API 不僅僅是你的應用程式與 API 內部的機制。開發者 SDK 可以為開發者創建工具,鼓勵他們遵循最佳實踐。
擴展吞吐量(Scaling Throughput)#
隨著 API 使用者數量增長,吞吐量——以每秒 API 呼叫次數衡量——也隨之增加。本節討論各種最佳化 API 以支撐這種成長的方式。
找出瓶頸(Finding the Bottlenecks)#
擴展 API 可能需要對你的應用程式架構和程式碼做出根本性的改變。首先,你需要判斷擴展瓶頸在哪裡;否則你只是在猜測。獲得瓶頸洞察最好的方式之一是透過instrumentation(監測工具)。藉由收集使用資料並監控容量瓶頸,你可以利用數據驅動的洞察來進行最佳化。
一般而言,瓶頸可歸為四大類:
| 瓶頸類型 | 說明 |
|---|---|
| 磁碟 I/O(Disk I/O) | 昂貴的資料庫查詢與本地磁碟存取,常導致磁碟相關的瓶頸 |
| 網路 I/O(Network I/O) | 現代應用中的網路瓶頸,通常是由依賴外部服務、需要跨資料中心進行 API 呼叫所造成 |
| CPU | 低效程式碼執行昂貴的運算,是 CPU 瓶頸的常見原因之一 |
| 記憶體(Memory) | 當系統沒有足夠的 RAM 時,通常會發生記憶體瓶頸 |
大多數雲端服務商都提供衡量這些瓶頸的解決方案。例如,在 AWS 上可以使用 Amazon CloudWatch;Heroku 有 New Relic;在 Google Cloud 上可以使用 Stackdriver 來取得指標並獲得健康狀態、效能和可用性的洞察。
要精確定位特定瓶頸,你可以監控上述類別,聚焦在最頻繁被呼叫的 API 方法上。瓶頸最明顯的症狀之一是回應時間的高延遲。透過測量 API 方法的回應時間及其被呼叫的頻率,你可以縮小需要最佳化的方法範圍。
確定要最佳化哪些 API 方法後,效能分析(Profiling) 是辨別瓶頸的最佳方式之一。雖然效能與擴展不同,但它們是相關的——效能差的 API 難以擴展。
透過分析程式碼,你可以找出哪些是 CPU 密集型或記憶體密集型的函式。在開發環境中進行 profiling 通常能幫你找到應用瓶頸;然而,有時候生產環境的問題是不同的,特別是當生產環境中的活動與事件在開發環境中難以模擬或重現時。如果你對生產環境的小部分流量啟用 profiling,就能進一步洞察效能問題。
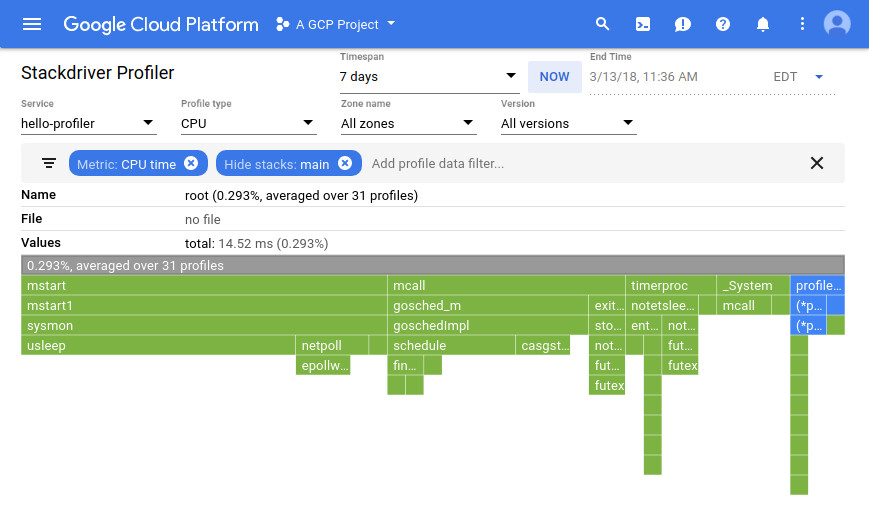
Figure 6.1: Performance flame graph generated by Stackdriver Profiler
除了程式碼 profiling(辨別 CPU 或記憶體密集型函式),資料庫 profiling 能幫你找出與磁碟 I/O 相關的慢查詢。MySQL 提供 slow query log,可記錄執行時間過長的查詢。其他資料庫也提供類似的方案來分析和隔離可能有問題的查詢。
至於網路 I/O 瓶頸,負載測試(Load Testing) 是另一個常用技術,用來判斷 API 在預期峰值負載下的行為。負載測試有助於識別系統的最大運作容量,以及在高負載下可能導致服務降級的瓶頸。一些公司會使用負載測試,在已知的即將到來的流量高峰前進行內部演練。特別是電商公司,會提前準備和規劃,以應對重大購物活動(如美國的黑色星期五)期間高達 5 倍流量和交易量的激增。
增加運算資源(Adding Computing Resources)#
簡單地增加更多運算資源就能幫助擴展應用程式。有兩種方式:
- 垂直擴展(Vertical Scaling):透過為現有伺服器增加更多能力(如 CPU、RAM 和磁碟儲存)來達成
- 水平擴展(Horizontal Scaling):透過向資源池中增加更多伺服器實例,使負載可以分散到多台伺服器上
典型的大型 Web 應用架構中,Web 伺服器前方有一個負載平衡器(Load Balancer),將請求分配到各伺服器。為了水平擴展資料庫,資料通常會被分區,使得資料庫表的不同列儲存在不同伺服器上——每台伺服器只包含部分資料。這也稱為資料庫分片(Database Sharding)。除了分片之外,資料庫複寫(Database Replication) 用來分散資料庫上的負載,有助於改善效能、可靠性與可擴展性。
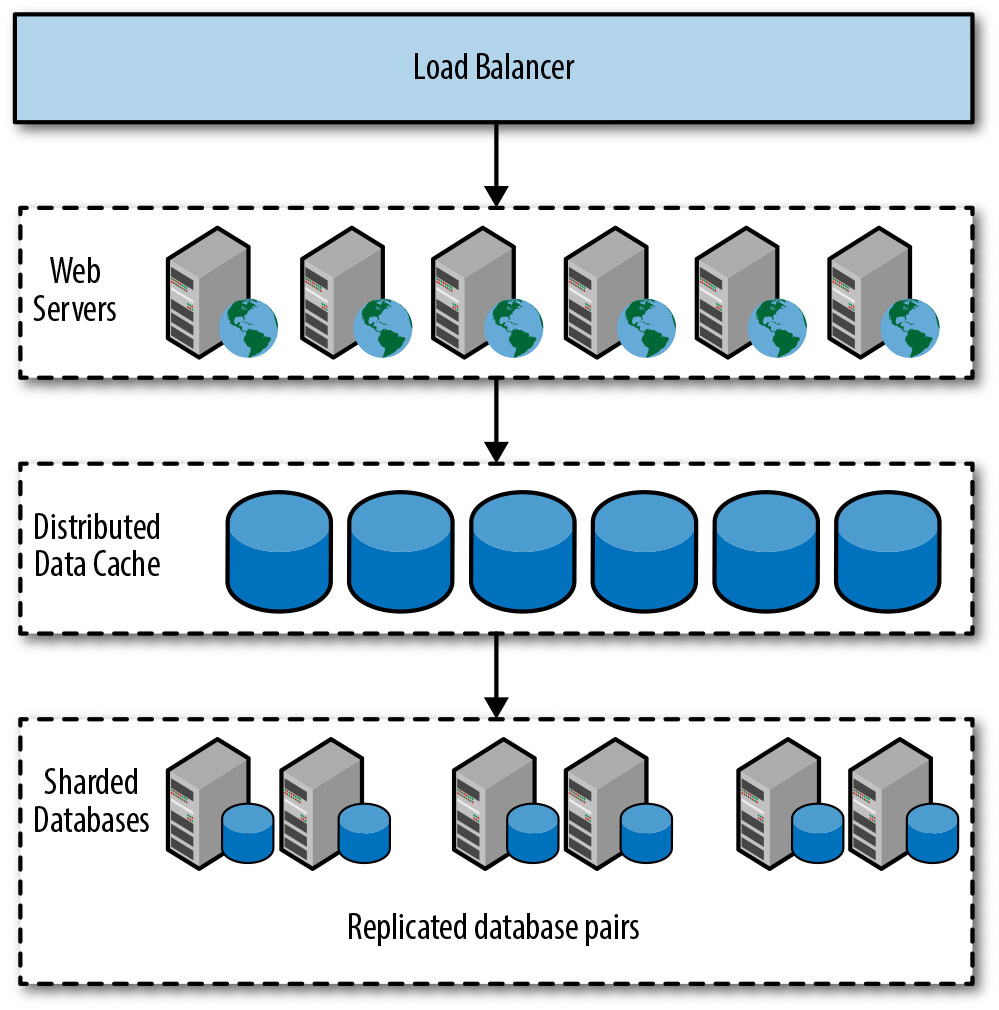
Figure 6.2: Architecture of a typical large-scale web application
資料庫索引(Database Indexes)#
索引(Indexing)是一種最佳化資料庫表資料檢索操作效能的方式。索引能幫助資料庫在不需比對資料庫表中每一列的情況下,定位要返回的列——透過額外儲存索引資料結構來實現。
例如,如果你經常在 users 表中透過 email 地址查找使用者,在 email 欄位上建立索引將加速這些查詢。沒有索引的話,資料庫需要檢查每一列。
索引並非越多越好。每個索引都需要額外的儲存空間,而且每次新增、更新或刪除列時都會有效能損耗,因為相應的索引也需要更新。通常,你需要在
WHERE、ORDER BY和GROUP BY子句中常用的欄位上建立索引。
快取(Caching)#
快取是 Web 應用中最受歡迎且最簡單的擴展技術之一。像 Memcached 這類快取解決方案將資料儲存在記憶體中而非磁碟上,因為從記憶體讀取要快得多。
快取常用於儲存資料庫查詢的回應。透過分析資料庫日誌,你可以找出執行時間長且最頻繁的查詢。使用快取時,當你需要查詢資料,先檢查快取中是否可用:
- 如果找到資料,直接返回
- 否則,執行資料庫查詢找到結果,並將結果儲存在快取中供未來查詢使用,然後再返回回應
實作快取時,一個重要的事項是快取失效(cache invalidation)。通常你會希望在對應資料更新時刪除快取。在其他時候,當你可以容忍資料更新延遲時,可以讓快取自行過期。
雖然應用層級的 API 快取通常與 Web 伺服器一起實作,但將 API 結果快取在更靠近終端使用者的位置,可以實現更高的吞吐量和效能。這稱為邊緣快取(Edge Caching)。
案例故事:Slack 的 Flannel——應用層級的邊緣快取
在 Slack 的早期,Slack 客戶端使用了與後來截然不同的 API 設計。這裡的客戶端是指任何用來顯示 Slack 訊息和其他功能的應用程式,包括瀏覽器和原生桌面與行動應用。當 Slack 主要被小型團隊使用時,每個客戶端在啟動時會發出一個 API 請求來載入所有內容——這對於一次取得所有頻道、使用者和機器人很有用。
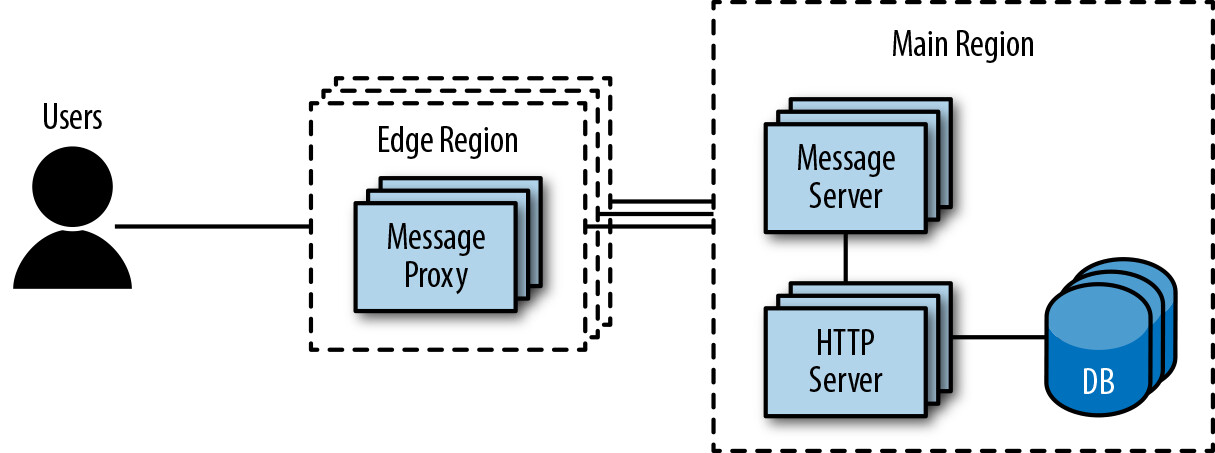
Figure 6.3: Slack's pre-Flannel architecture
然而,隨著團隊規模越來越大,請求整個應用狀態變得越來越慢。對小型團隊有效的做法,對大型團隊不再適用:
- 啟動連線時間過長
- 客戶端記憶體佔用過大
- 重新連線 Slack 的成本很高
- 重連風暴(reconnection storms)消耗大量資源
因此,Slack 花了數個月重新設計客戶端請求和管理狀態的 API,這個 API 被稱為 Flannel。Flannel 是一個延遲載入快取服務(lazy-loading cache service),提供查詢 API 讓客戶端按需取得資料。之前客戶端在啟動時會收到整個應用狀態,現在它們使用 Flannel 只請求建立合理使用者介面所需的資料,然後發出後續請求來更新本地狀態。
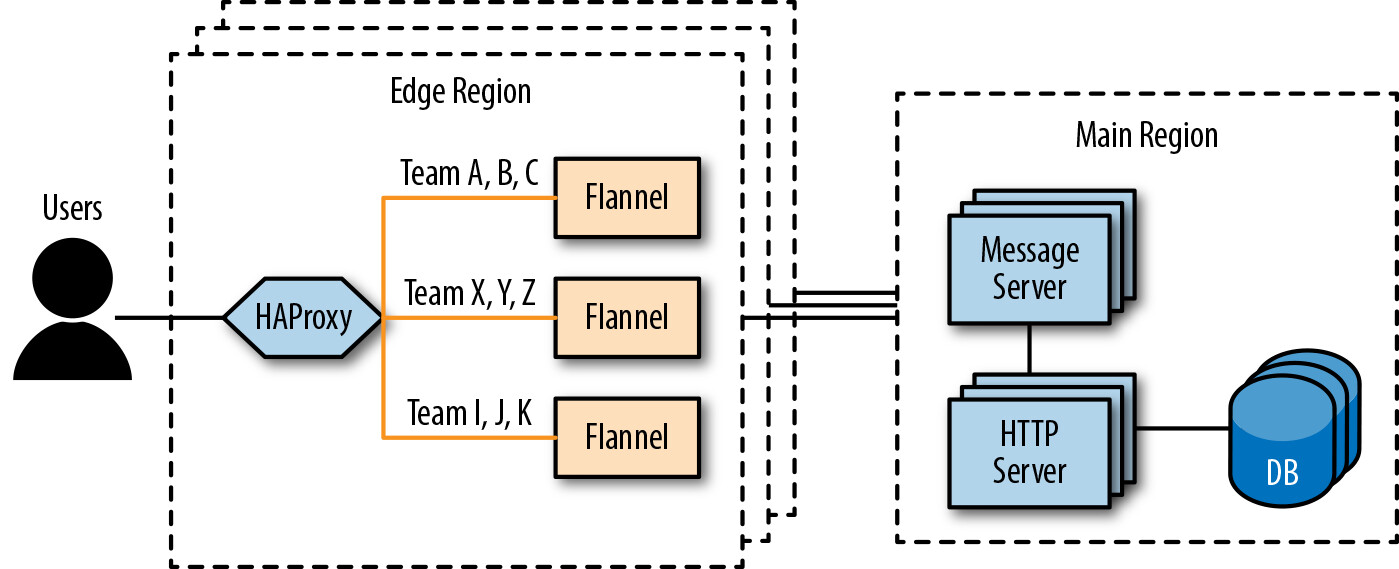
Figure 6.4: Slack's architecture with Flannel
整個團隊花了數個月的工作才將這個新快取部署到位以擴展 API,但結果非常驚人:
- 中型團隊的客戶端啟動資料量減少了 7 倍
- 大型團隊則減少了 44 倍
將昂貴操作非同步執行#
如果你的某些 API 請求需要很長時間才能執行,你可以考慮在請求之外(非同步地)執行昂貴的操作。這樣你就能更快地回傳回應。
例如,如果你有一個系統允許使用者儲存和搜尋檔案,當檔案上傳時,你不需要在同一個請求中將其加入搜尋索引。檔案可以作為一個離線工作的一部分,以近乎即時的方式非同步加入索引。
要進行非同步操作,你可以使用各雲端服務商提供的任務佇列服務(如 Amazon 和 Google),也可以使用開源的任務佇列如 Celery。
擴展吞吐量最佳實踐#
以下是幫助你的應用程式擴展到高負載的一些最佳實踐:
- 在開始進行擴展變更之前,先測量並找到瓶頸。資料庫是現代應用中最常見的瓶頸
- 避免過早最佳化(premature optimization)。擴展最佳化通常有成本,其中一些可能會增加應用程式的開發時間。除非你有擴展問題,否則不要增加那些複雜性
- 優先選擇水平擴展而非垂直擴展
- 了解資料庫索引是解決慢資料庫查詢的最佳方式之一
- 確定你頻繁使用的資料,並將其快取
- 如果添加了快取,別忘了添加快取失效機制
- 考慮將昂貴操作非同步執行
- 避免撰寫低效的程式碼,例如在單一 API 請求中於 for 迴圈裡執行資料庫查詢
演進 API 設計(Evolving Your API Design)#
在現實世界中,你的初始 API 設計可能無法隨著使用者群的成長或 API 採用率和使用量的增加而擴展。要獲得瓶頸的洞察並減少 API 呼叫數量,重要的是判斷開發者使用 API 的主要原因以及問題所在:
- 開發者是否以你未預料的方式使用 API?
- 輪詢(polling)是否是個問題?
- API 是否回傳了太多資料?
雖然沒有銀彈能解決所有擴展問題,但你可以考慮以下解決方案。
專家建議:與你的使用者一起成長和合作。與開發者/使用者保持良好且開放的溝通管道。獲取回饋並調校 API 以解決他們的主要痛點。——Ido Green,Google 開發者倡議者
引入新的資料存取模式#
隨著 API 變得受歡迎,開發者可能開始以你未預期的方式使用它。為了應對擴展挑戰,你可能需要考慮分享資料的替代方式。以下是四家進行了重大 API 設計變更以實現擴展的公司案例:
Zapier — 如果輪詢是你的 API 擴展問題之一,而你只有 REST API,你應該探索像 WebSockets 和 WebHooks 這樣的選項。開發者不需要輪詢變更,而是等待新資料被即時推送。2013 年 Zapier 的一項研究發現,只有大約 1.5% 的輪詢 API 呼叫返回了新資料。透過支援 WebHooks,他們估計伺服器負載可以減少 66 倍。
Twitter — 過去,Twitter 應用只能透過頻繁輪詢 Twitter API 來近乎即時地接收新推文,這增加了 REST API 的流量,加劇了現有的擴展挑戰。為了解決這個問題,Twitter 引入了串流 API(Streaming API),能推送新資料並減少輪詢。使用串流 API,開發者可以訂閱選定的關鍵字或使用者,並透過長連線接收新推文。
GitHub — GitHub 發現其回應過於臃腫,發送了太多資料——但即使有龐大的 payload,仍未包含開發者需要的所有資料。開發者需要發出多個呼叫來組裝資源的完整視圖。為解決這些可擴展性挑戰,GitHub 推出了 GraphQL API。使用 GraphQL,開發者可以將多個 API 呼叫批次合併為單一呼叫,且只取得他們需要的項目,幫助減少 API 呼叫數量和不需要欄位的計算成本。
Slack — Slack 最初有一個 Real-Time Messaging(RTM)API,讓開發者建構能即時回應 Slack 活動的應用程式和機器人。該 API 透過 WebSocket 從 Slack 推送事件。隨著時間推移,Slack 發現即使 RTM API 對自家客戶端很好用,但對開發者來說提供了太多資料且難以妥善處理。此外,對 Slack 和開發者而言都難以擴展——擁有多個使用者的開發者必須處理許多並行的開放 HTTP 連線(每位使用者至少一個)。Slack 作為 API 提供者也需要管理同等數量的連線。2016 年,為解決這些問題,Slack 引入了 Events API,這是基於 WebHook 的,讓開發者可以透過 HTTP 建立機器人。開發者只需訂閱他們關心的事件,而非接收包含所有事件的無盡資料流或不斷輪詢 Slack 的 RPC API。
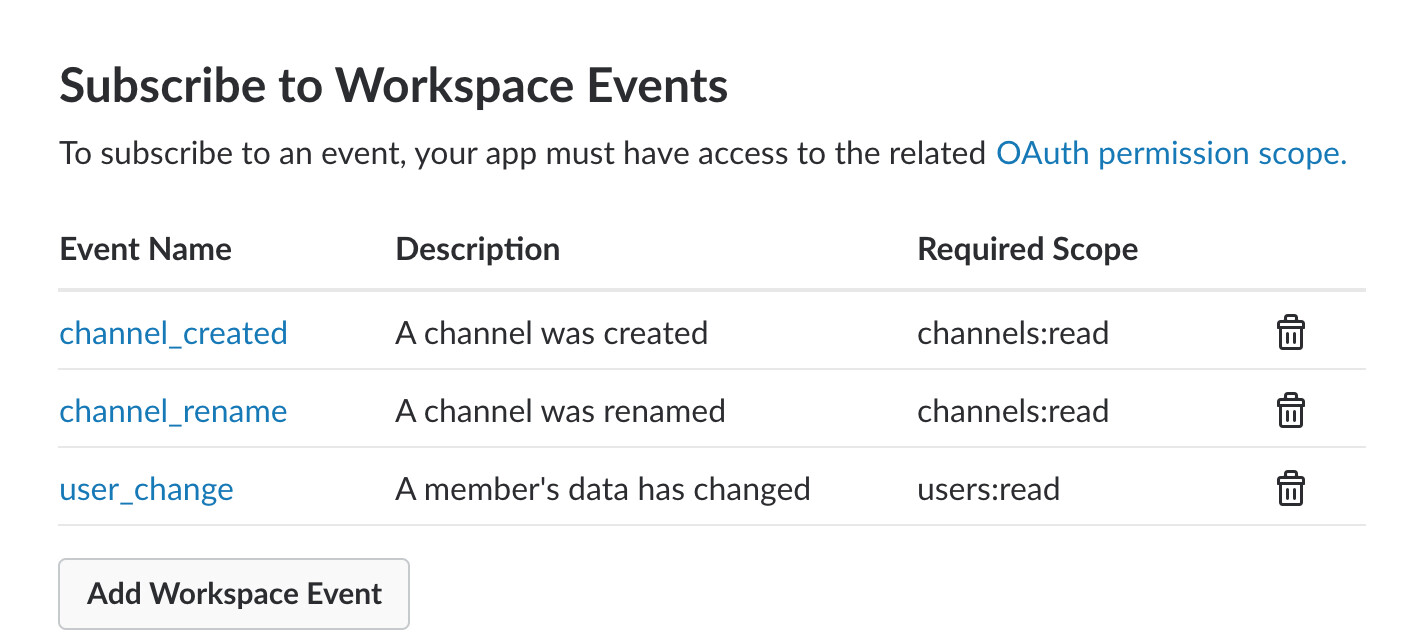
Figure 6.5: Slack's WebHook-based event subscription interface
添加新的 API 方法#
解決可擴展性和效能問題的另一種方式是添加新的 API 方法。如果你有一些昂貴的 API,你可能需要深入了解它們服務的使用情境。有時開發者可能只需要 API 回應中的一小部分資料;或者像 GitHub 的案例那樣,開發者可能費力地組裝現有 API 不容易取得的資料。如果開發者只能選擇「全部請求」或「什麼都不請求」,他們最終可能會收到完整回應卻忽略大部分 payload。那些他們不需要的資料可能正是你計算成本高昂的部分。
修改或移除已在使用中的 API 很困難,但添加新方法很容易。新方法可以提供開發者需要的資料,同時解決現有 API 的效能與擴展問題。
案例:Slack 的 rtm.connect 與 Conversations API
Slack 隨時間引入了多個新 API 來應對擴展挑戰:
rtm.connect 的誕生:Slack 的熱門 API 方法 rtm.start 變得極為昂貴。這個方法會啟動 RTM session 並回傳大量關於團隊、頻道和成員的資料。最初為小型團隊設計,這個方法會回傳完整的應用狀態外加 WebSocket 連線的 session URL。隨著團隊規模增長,payload 變得笨重龐大——高達數 MB——對開發者來說處理成本很高。儘管少數開發者會使用這些資料,大多數開發者只想連接 WebSocket。因此,Slack 推出了新的 API 方法 rtm.connect,只回傳 RTM WebSocket API session URL,不包含其他資料。
Conversations API:Slack 也推出了 Conversations API,解決效能、可擴展性問題以及各種開發者痛點。之前,開發者需要根據頻道類型,從多個「家族樹」中使用不同方法來完成相同的事情。例如,列出私有頻道用 groups.list,公開頻道用 channels.list。這導致開發者需要處理許多不同的物件——而這些物件本質上都代表同一種訊息時間線容器。
Conversations API 為這些 payload 帶來了一致性,並進行了各種效能改進,讓開發者可以擴展他們的應用程式:
- 回傳大型物件列表的 API 端點全部支援分頁
- Slack 停止在 payload 中回傳巨大的巢狀列表,改為建立獨立端點來取得額外資訊
- 例如,新的 API 端點
conversations.members回傳對話中成員的分頁列表
Slack 的開發者報告說,透過這個新的變更,他們移除了大量程式碼。
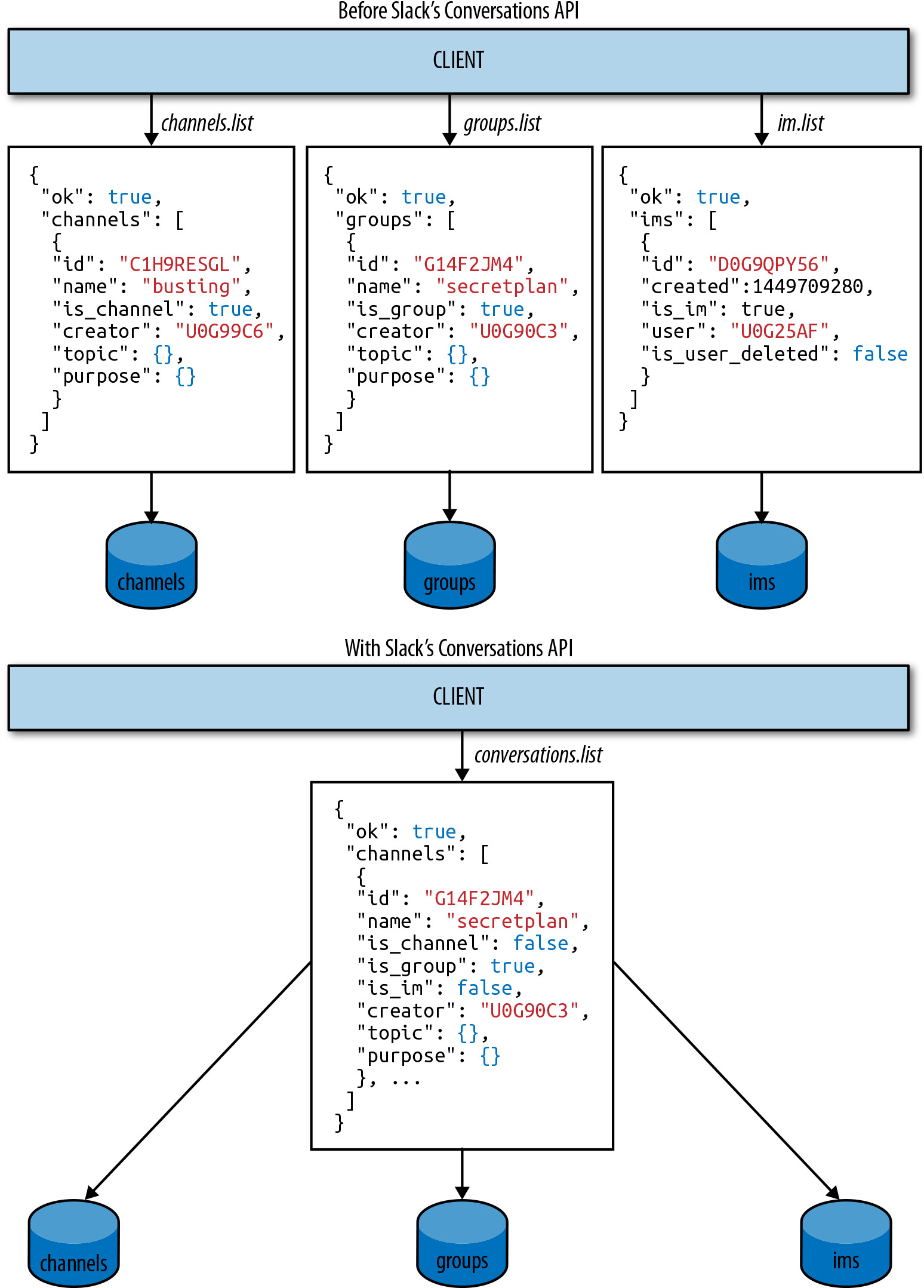
Figure 6.6: Slack's Conversations API consolidated multiple endpoints into one
另一個 Conversations API 幫助開發者完成的使用案例是找出某個使用者所屬的對話。之前,開發者需要發出多個請求來查詢每個對話的成員,然後過濾特定使用者。透過釋出 users.conversations API 方法,Slack 減少了開發者需要發出的呼叫數量——在單一請求中,開發者可以取得最多 1,000 個使用者所屬的對話。之前,這可能需要 1,001 個 API 呼叫。
支援批量端點(Bulk Endpoints)#
有時開發者需要對多個項目執行相同的操作,例如查詢或更新多個使用者。這通常需要多個個別的 API 呼叫。支援批量端點讓開發者能以更少的 API 呼叫完成這些操作,有助於擴展。批量端點更為高效,因為它們需要更少的 HTTP 來回,甚至有助於減少資料庫負載。
例如,Slack 原本要邀請多位使用者到單一頻道,開發者必須為每位使用者呼叫一次 channels.invite API 方法。Slack 新增了在單一 API 呼叫中邀請多位使用者的支援:
POST /api/conversations.invite
HOST slack.com
Content-Type: application/json
Authorization: Bearer xoxp-165018607-jqf4sbdaq2a
{
"channel":"C0GEV71UG",
"users":["W1234567890","U2345678901", "U3456789012"]
}多家 API 供應商如 Zendesk 和 Salesforce 也支援批量操作端點和請求批次處理。
添加新的篩選選項#
當你的 API 開始回傳大量物件時,重要的是提供篩選結果的選項。這樣,開發者可以將回傳的物件限制為他們實際需要的,使 API 更具可擴展性。常見的篩選選項包括:
| 篩選類型 | 說明 | 範例 |
|---|---|---|
| 搜尋篩選器(Search Filter) | 開發者可以使用相似詞彙、正規表示式或字串匹配來特定請求所需的結果 | 缺少此篩選器時,開發者可能會請求和解析比實際需要多得多的結果 |
| 日期篩選器(Date Filter) | 開發者通常只需要自上次請求以來的新結果,可以只回傳指定時間戳記之後或之前的結果 | Twitter 時間線、Facebook 動態消息和 Slack 訊息歷史 API 都支援此類篩選器 |
| 排序篩選器(Order Filter) | 讓開發者按照特定屬性排序結果集,減少需要請求和處理的結果數量 | Amazon 產品廣告 API 支援按人氣、價格和商品狀態排序 |
| 欄位篩選(Field Selection) | API 回應中某些欄位的計算成本可能遠高於其他欄位,不必要的欄位也會顯著增加 payload 大小 | Twitter 時間線 API 提供修剪使用者物件和不回傳推文的篩選器 |
演進 API 設計最佳實踐#
以下是演進 API 設計以幫助擴展的四項最佳實踐:
- 持續演進 API 時,確保不引入令人意外的破壞性變更
- 分析 API 使用情況和模式,找出需要最佳化的部分
- 與開發者和合作夥伴交流。這會給你關於問題和潛在解決方案的良好洞察
- 在向所有人推出新的 API 模式之前,先與少數開發者和合作夥伴試用。這樣你可以根據他們的回饋迭代設計,然後再正式推出
API 分頁(Paginating APIs)#
API 經常需要處理大型資料集。一個 API 呼叫可能回傳數千筆項目。回傳過多項目可能會使 Web 應用後端超載,甚至拖慢無法處理大型資料集的客戶端。因此,分頁大型結果集非常重要——這能將長列表的資料分割成較小的區塊、最小化請求的回應時間,並使回應更容易處理。
基於偏移量的分頁(Offset-Based Pagination)#
使用 limit 和 offset 通常是實作分頁最簡單的方式,也是最廣泛使用的分頁技術。
客戶端提供一個頁面大小(定義最大回傳項目數)和一個頁碼(指示列表中的起始位置)。基於這些值,伺服器可以輕鬆建構 SQL 查詢來取得結果。例如,要取得第五頁、每頁 10 筆項目:
SELECT * FROM `items`
ORDER BY `id` asc
LIMIT 10 OFFSET 40;GitHub 等 API 支援這種分頁方式。客戶端只需在 URL 中指定 page 和 per_page 參數:
https://api.github.com/user/repos?page=5&per_page=10優點:
- 實作極為簡單,對客戶端和伺服器皆然
- 在使用者體驗上有優勢——允許使用者跳到任意頁面,而非強制逐頁捲動

Figure 6.7: Pagination links in a UI
缺點:
- 對大型資料集效率低:帶有大偏移量的 SQL 查詢相當昂貴,資料庫必須計數並跳過偏移值之前的所有列
- 列表頻繁變動時不可靠:客戶端分頁時若有新增項目,可能導致同一項目顯示兩次;若有刪除項目,可能跳過某些項目
- 在分散式系統中可能棘手:對於大偏移量,你可能需要掃描多個分片才能取得目標項目
基於偏移量的分頁在分頁深度有限、且客戶端可以容忍重複或遺漏項目的情境下,仍然是很好的選擇。
基於游標的分頁(Cursor-Based Pagination)#
為解決基於偏移量分頁的問題,許多 API 採用了基於游標的分頁。使用此技術時:
- 客戶端先發送請求,只傳遞期望的項目數量
- 伺服器回傳請求的項目數量(或支援的最大數量),加上一個 next cursor
- 在後續請求中,客戶端連同項目數量一起傳遞此游標,指示下一批項目的起始位置
基於游標分頁的實作與基於偏移量的分頁沒有很大差異,但效率高得多。假設伺服器回傳最後一筆記錄的 Unix 時間戳記作為游標,要取得比該游標更舊的結果頁面:
SELECT * FROM items
WHERE created_at < 1507876861
ORDER BY created_at
LIMIT 10;在 created_at 欄位上建立索引能讓查詢非常快速。
多個現代 API,包括 Slack、Stripe、Twitter 和 Facebook,都提供基於游標的分頁。以 Twitter API 為例,開發者要取得使用者追蹤者的 ID 列表:
GET https://api.twitter.com/1.1/followers/ids.json?screen_name=saurabhsahni&count=50回應中包含 next_cursor 值,開發者使用它來請求下一頁結果。當最終收到 "next_cursor": 0 時,表示已到達整個分頁結果集的末尾。
優點:
- 效能:使用游標欄位的索引,即使掃描大型表的查詢也很快
- 一致性:項目的新增或刪除不影響頁面的結果集,伺服器在分頁時只回傳每個項目一次
缺點:
- 客戶端無法跳到指定頁面,必須逐頁遍歷整個結果集
- 結果必須按唯一且連續的資料庫欄位排序,用於游標值。不應允許在列表的隨機位置添加記錄
- 實作比基於偏移量的分頁稍複雜,特別是對客戶端而言——客戶端通常需要儲存游標值以用於後續請求
選擇游標的內容#
常見的游標選項包括:
- ID 作為游標:API 供應商經常選擇唯一 ID 作為游標值。例如,Twitter 時間線 API 支援推文 ID 作為游標。要取得時間線中較舊的推文,開發者可以傳遞第一批結果中收到的最小 ID 作為
max_id參數 - 時間戳記(Timestamp):回傳基於時間資料(如動態消息)的 API 常用時間戳記作為游標。Facebook API 支援
until和since參數,接受 Unix 時間戳記 - 不透明字串(Opaque Strings):使用不透明字串作為游標正日益成為 API 供應商的首選。雖然它們看似隨機字元集,但通常是編碼後的值。其關鍵優勢是能在單一游標中編碼額外資訊。大規模應用可以在游標值中編碼多個 ID 或 ID 加資料庫分片指標的組合。包括 Slack、Facebook、GitHub 和 Twitter 在內的多個 API 的現代版本都使用不透明字串作為游標
基於游標的分頁最適合高流量應用,其中客戶端需要掃描大型資料集。
分頁最佳實踐#
設計 API 分頁時應牢記的最佳實踐:
- 實作分頁時,別忘了設定合理的預設值和最大值作為頁面大小
- 如果客戶端會執行大偏移量的查詢,避免使用基於偏移量的分頁
- 分頁時,將資料排序為較新的項目先返回有時更好,這樣客戶端若只對較新的項目感興趣,就不需分頁到最後
- 如果你的 API 目前不支援分頁,之後引入時要以保持向後相容的方式進行
- 實作分頁時,回傳 next page URL 指向後續結果頁面。空或 null 的 next page 值可以表示列表結尾。透過鼓勵客戶端遵循 next page URL,你可以隨時間改變分頁策略而不破壞客戶端
- 不要在游標中編碼敏感資訊。客戶端通常可以解碼它們
API 速率限制(Rate-Limiting APIs)#
API 供應商常常是以慘痛的方式發現速率限制的必要性。當 API 變得受歡迎且突然遭遇流量激增、可能影響應用可用性時,API 開發者才開始探索速率限制的選項。API 應實施速率限制有兩大關鍵原因:
- 保護基礎設施,提升應用的可靠性與可用性:你不希望單一行為不當的開發者或使用者透過阻斷服務攻擊(DoS attack)拖垮你的應用
- 保護你的產品:防止產品濫用,例如大量註冊使用者或建立大量垃圾內容
速率限制透過使應用更可靠來幫助處理流量激增或垃圾請求。藉由保護基礎設施和產品,速率限制也在保護開發者——如果整個系統可以透過 API 被拖垮,那就沒有 API 或資料可供任何人使用。
什麼是速率限制?#
速率限制系統控制網路介面上發送或接收流量的速率。對 Web API 而言,速率限制系統用來控制應用程式或客戶端在給定時間間隔內可以呼叫 API 的次數。流量在指定速率內被允許,超過該速率的流量可能被拒絕。例如,GitHub 的 API 允許開發者每小時最多發出 5,000 個請求。
設計速率限制政策時,除了保護基礎設施和產品外,良好的政策應具備以下特性:
- 容易理解、解釋和使用
- 確保開發者在正常使用情境下不會被速率限制
制定速率限制政策時需考慮的事項:
- 細粒度速率限制 vs. 全域速率限制:許多 API 選擇跨所有 API 端點的單一全域速率限制,這對你和開發者都容易實作。然而,如果某些端點消耗的資源顯著多於其他端點,你可能需要按端點定義速率限制。Twitter API 按 API 端點定義速率限制,而 GitHub 和 Facebook 定義單一全域速率限制
- 按使用者、應用程式或客戶端 IP 衡量流量:要速率限制的實體通常取決於 API 要求的驗證方法。需要使用者驗證的 API 通常按使用者進行速率限制;需要應用程式驗證的 API 通常按應用程式進行速率限制;未經驗證的 API 呼叫常按 IP 位址進行速率限制
- 是否支援偶爾的流量爆發:某些 API(特別是企業開發者使用的)支援超出持續速率限制的流量爆發。如果你選擇支援偶爾的流量爆發,你可能會使用 token bucket 演算法來實作速率限制
- 允許例外:你不需要對所有開發者套用單一的速率限制政策或配額。某些受信任的開發者或合作夥伴可能需要更高的速率限制。在授予例外之前,你應該:
- 確保開發者的使用案例有效且有益於客戶
- 驗證在現有 API 和限制下是否有更好的方式達成相同結果
- 確認你的基礎設施是否能支撐所請求的速率限制
另一種確保合理使用 API 的方式是透過**服務條款(ToS)**協議文件。這些文件向開發者詳述 API 的允許用途,包括速率限制。以高於 ToS 中指定速率存取 API 的開發者,可能面臨 API token 失效或其他你認為必要的處置。
實作策略#
建構速率限制系統時,確保系統不會拖慢 API 回應時間。為了保證高效能和水平擴展的能力,大多數 API 服務使用記憶體內資料儲存(如 Redis 和 Memcached)來實作速率限制器。Redis 和 Memcached 都提供快速的讀寫操作,常被 API 供應商用來追蹤收到的 API 請求數量。
常見的速率限制演算法有三種:
- Token Bucket
- Fixed-Window Counter
- Sliding-Window Counter
Token Bucket 演算法#
Token Bucket 演算法允許維持穩定的流量速率上限,同時允許偶爾的爆發。該演算法以一個容量有限的桶來比喻——token 以固定速率加入桶中,但桶不能無限裝滿。如果 token 到達時桶已滿,該 token 被丟棄。每次請求時,從桶中移除 n 個 token。如果桶中少於 n 個 token,請求被拒絕。
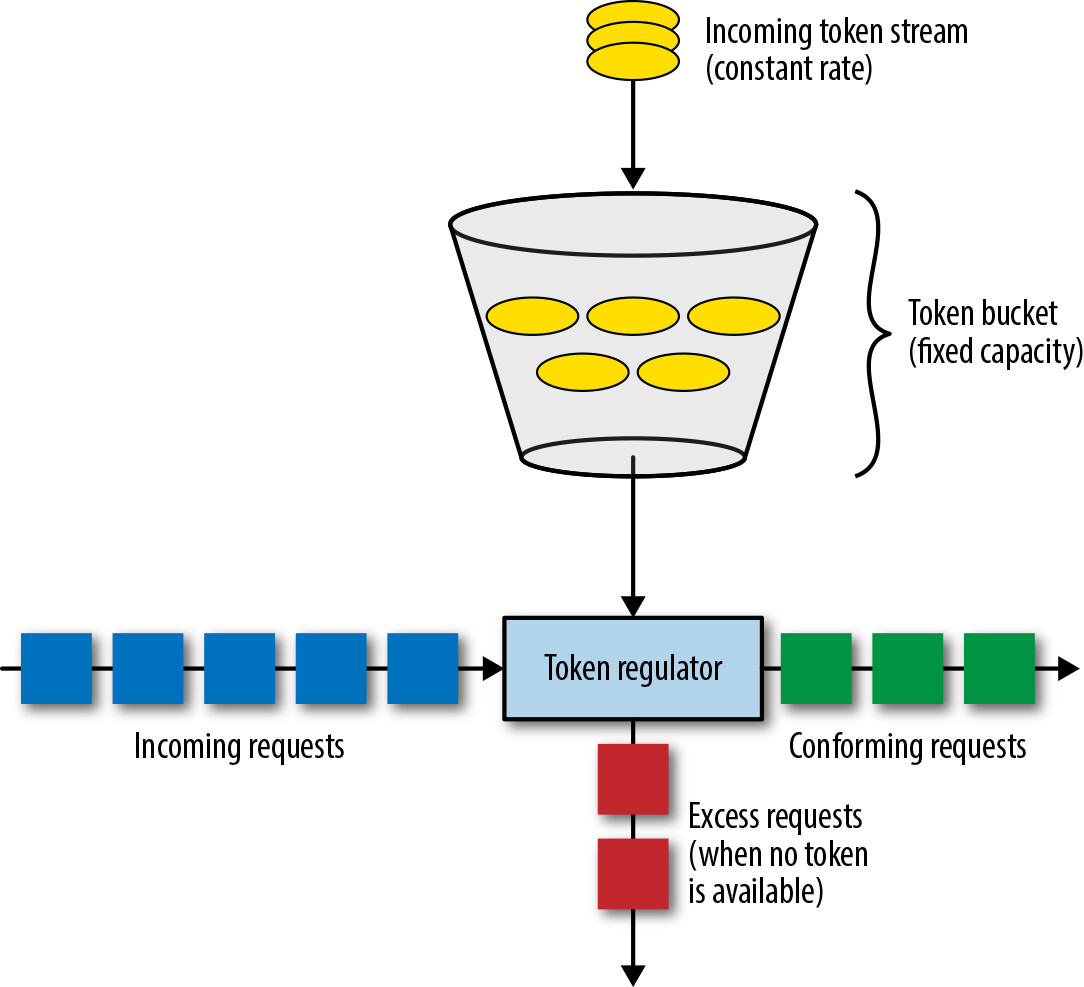
Figure 6.8: Token bucket algorithm
使用記憶體內鍵值資料儲存來實作此演算法很容易。假設你想將 API 請求限制為每位使用者每分鐘 20 個請求,同時允許偶爾爆發至 50 個請求。實作方式如下:
- 在使用者的第一個請求時,初始化一個容量為 50 個 token 的桶。將請求時間戳記和 token 計數儲存在資料儲存中,以使用者識別碼作為 key
- 在後續請求時,根據定義的固定速率和自上次請求以來經過的時間,向桶中補充新 token
- 然後,從桶中移除一個 token,並將時間戳記更新為當前時間
- 最後,如果可用 token 數降至零,拒絕請求
Token Bucket 演算法易於實作,被多家 API 供應商使用,包括 Slack、Stripe 和 Heroku。如果你想對「爆發性」流量較為寬容,這是一個很好的選擇。
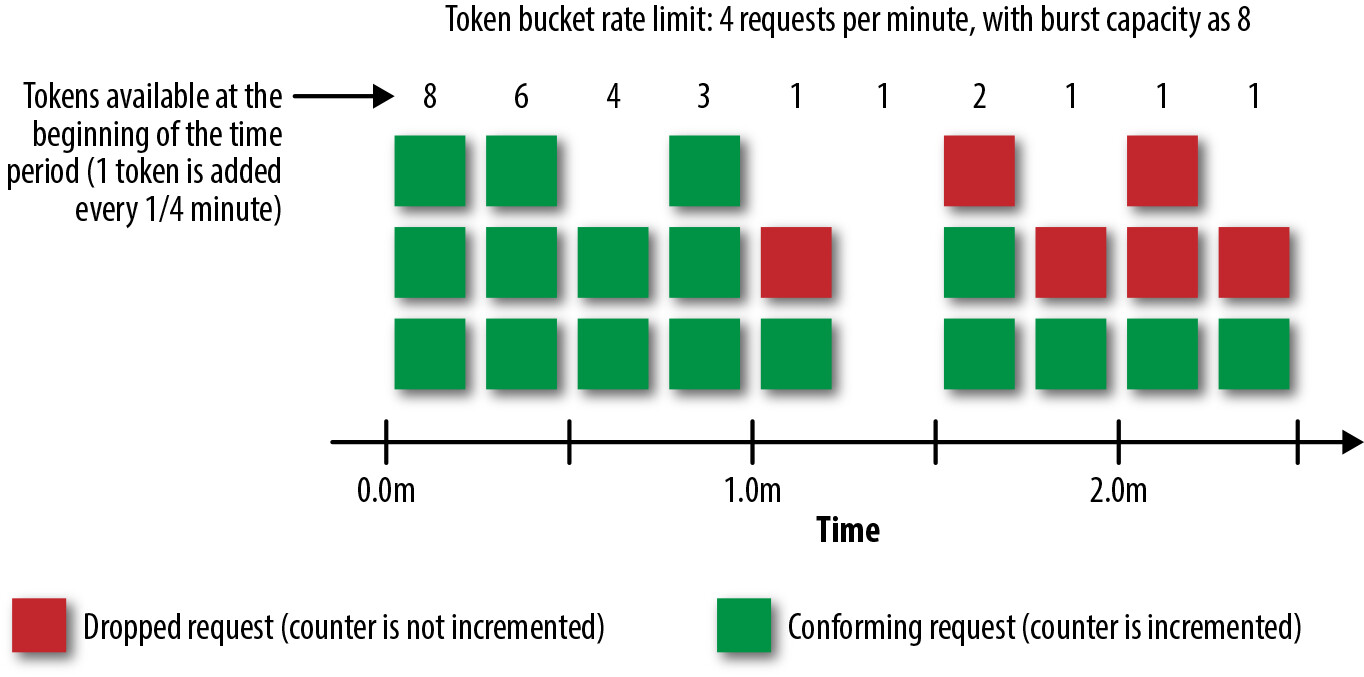
Figure 6.9: Token bucket rate-limiting in practice
Fixed-Window Counter 演算法#
Fixed-Window Counter 演算法允許在指定時間間隔內通過固定數量的請求。你可以使用記憶體內鍵值資料儲存輕鬆實作。實作每位使用者每分鐘 20 個請求的速率限制:
- 在第一個請求時,將請求計數儲存為 1,key 代表使用者和四捨五入到當前分鐘的時間戳記。此 key 可在當前分鐘結束後過期
- 在每個後續請求時,將上述請求計數 key 加一
- 如果請求計數超過速率限制,拒絕請求
雖然實作容易,但此演算法可能在一分鐘的視窗內允許高達兩倍於指定數量的請求。例如,如果使用者在上午 11:01:40 發出 20 個請求,客戶端可以在 11:02:05 再發出 20 個請求。
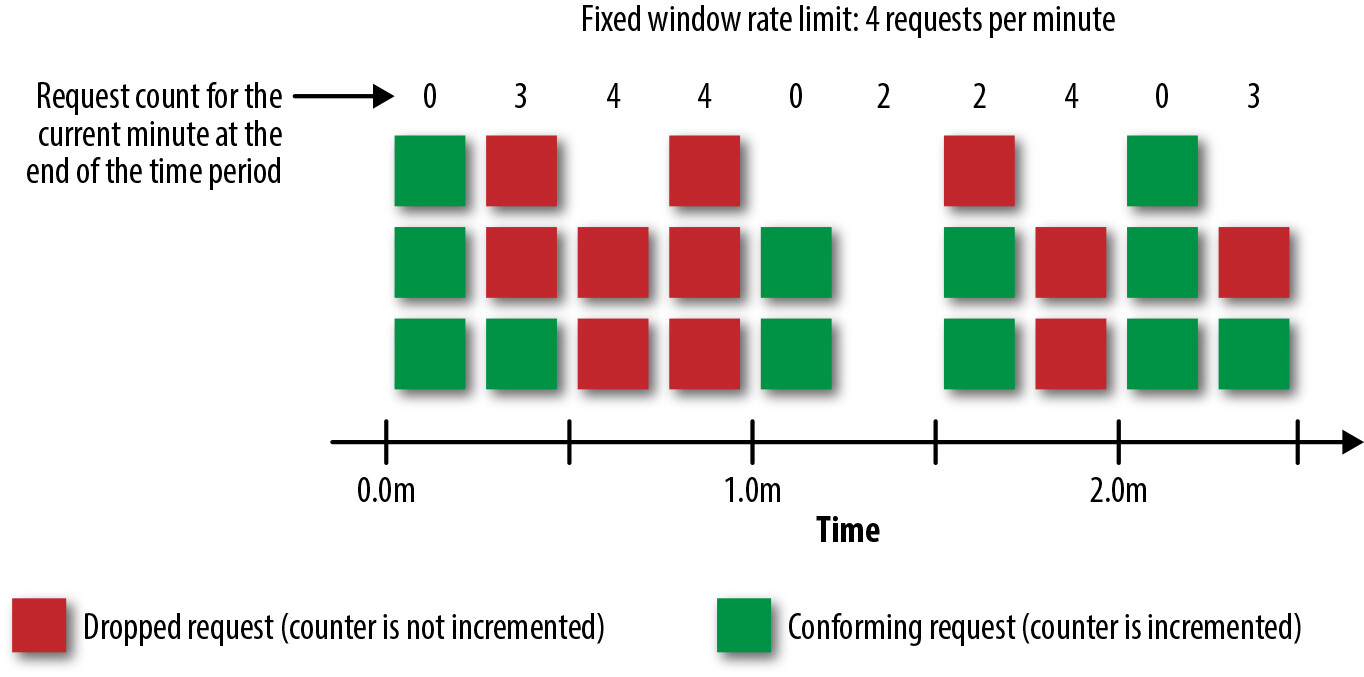
Figure 6.10: Fixed-window counter rate-limiting in practice
如果你的 API 能容忍這類爆發,Fixed-Window Counter 演算法可能適合你。Twitter 等 API 供應商使用此演算法。
Sliding-Window Counter 演算法#
Sliding-Window Counter 演算法讓你追蹤滑動時間視窗中的流量,確保 API 能拒絕 Token Bucket 和 Fixed-Window Counter 演算法可能允許的「爆發性」流量。
要實作滑動視窗演算法,僅遞增單一計數器是不夠的。我們需要將速率限制視窗分割為個別的時間桶。例如,要實作每分鐘 20 個請求的速率限制,我們可以將 1 分鐘的視窗分成 60 個桶,為每秒維護一個計數器。這些桶可在一分鐘後自動過期。在每個請求時,加總最後一分鐘記錄的計數器。如果總數超過速率限制,則拒絕請求。
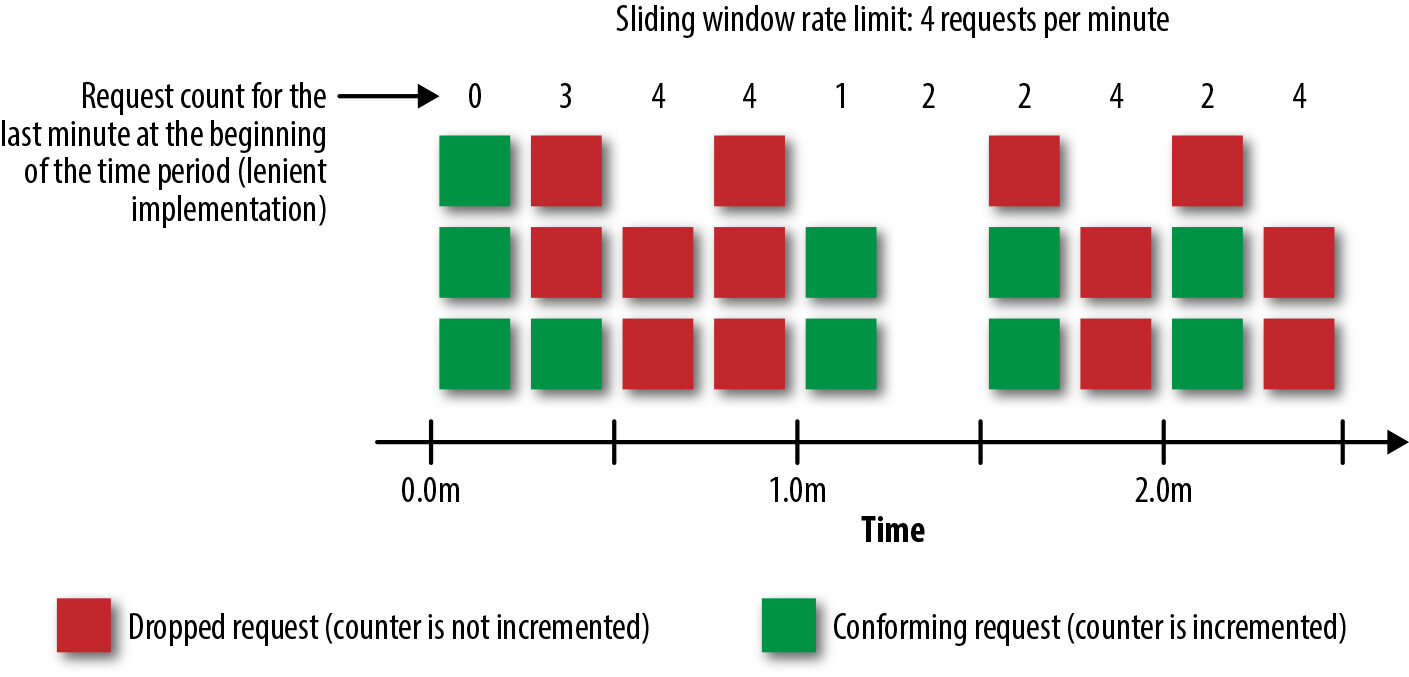
Figure 6.11: Sliding-window counter rate-limiting in practice
Instagram 使用 Sliding-Window Counter 演算法來速率限制其 API。如果你想確保來自每個開發者的 API 流量保持穩定,Sliding-Window Counter 可能適合你。
在推出新的速率限制政策或演算法之前,先進行暗測試(dark launch)以了解它會阻擋多少流量以及哪些流量。使用日誌記錄來分析有多少請求會被拒絕,但不實際拒絕任何請求。你可能需要根據了解到的影響來調整閾值。
速率限制與開發者#
速率限制是開發者最討厭的事情之一。速率限制常迫使開發者編寫額外的程式碼,或只是讓他們困惑為什麼請求被拒絕。如果你實作了速率限制系統,你可能需要做一些額外的事情來改善開發者體驗。
回傳適當的 HTTP 狀態碼:當開發者觸及速率限制時,回傳 HTTP 429 狀態碼,表示使用者在給定時間內發送了過多請求。同時設定 retry-after header 讓開發者可以程式化地重試請求:
$ curl -I https://slack.com/api/rtm.connect
HTTP/2 429
Date: Sun, 17 Jun 2018 14:43:38 GMT
retry-after: 36速率限制自訂回應 header:除了狀態碼,你應包含自訂回應 header 來說明速率限制,幫助開發者以程式化方式決定何時重試 API 呼叫:
X-RateLimit-Limit:開發者在給定時間內呼叫此端點的最大速率X-RateLimit-Remaining:開發者在當前時間間隔內可用的請求數。如果使用 Token Bucket 演算法,這可以表示桶中剩餘的 token 數X-RateLimit-Reset:當前速率限制視窗重置的時間(UTC epoch 秒數)
$ curl -I https://api.github.com/users/saurabhsahni
HTTP/1.1 200 OK
X-RateLimit-Limit: 60
X-RateLimit-Remaining: 59
X-RateLimit-Reset: 1510378642速率限制狀態 API:如果你有不同端點的不同速率限制,開發者可能希望有一個 API 來查詢各端點的速率限制狀態,以程式化方式追蹤每個端點的可用請求數。
記錄速率限制文件:透過記錄你的速率限制值,幫助開發者做出正確的架構選擇。大多數熱門 API 都清楚記錄速率限制,讓開發者在實際遇到速率限制錯誤之前就能了解。除了速率限制值,也應考慮記錄開發者可遵循的最佳實踐以避免觸及速率限制。
案例:Slack 速率限制的經驗教訓
2018 年 3 月,Slack 推出了演進過的速率限制系統。在此之前,Slack API 方法的速率限制相當模糊且經常未被執行。在缺乏文件記錄的速率限制下,使用 Slack API 建構應用的開發者常假設他們不會被速率限制。然而,當他們的應用程式被大型企業客戶安裝時,這個假設有時會適得其反。
為了引入新的速率限制閾值,Slack:
- 分析每個 API 的使用案例,定義確保大多數常見使用案例不會被速率限制的閾值
- 在推出新閾值前進行暗測試,找出哪些應用程式會在新系統中被速率限制
- 在某些情況下調整速率限制閾值;在其他情況下,明確判定開發者的實作效率不佳
Slack 團隊本可以不發出任何警告就推出新的閾值,但團隊成員認為這對那些可能因新閾值而被速率限制的開發者來說是一個破壞性變更。為了確保這些開發者和客戶的最佳體驗,他們給予那些受影響的應用程式一個短暫的寬限期來調整實作。新的文件記錄的速率限制幫助開發者在建構應用時做出更好的架構決策,並減少生產環境中的速率限制意外。
速率限制最佳實踐#
添加 API 速率限制時應考慮的最佳實踐:
- 根據你想支援的流量模式選擇速率限制演算法。通常付費服務對流量爆發較為寬容,選擇 Token Bucket 演算法;其他則選擇 Fixed Window 或 Sliding Window
- 選擇速率限制閾值,確保常見 API 使用案例不會被速率限制
- 向外部開發者提供清晰的指引,說明速率限制閾值以及如何請求額外配額
- 在授予開發者額外配額之前,了解他們為何需要超出速率限制、使用案例是什麼、當前使用模式如何。如果你的基礎設施能支撐且沒有更好的替代方案,可以考慮給予例外
- 從較低的速率限制閾值開始。提高閾值比降低閾值容易,因為降低可能對活躍的開發者應用造成負面影響
- 在客戶端 SDK 中實作指數退避(exponential back-off),並向開發者提供範例程式碼。這樣開發者在被速率限制時較不可能持續存取你的 API
- 使用速率限制在事故期間大幅限制非關鍵流量,以減少事故影響
開發者 SDK(Developer SDKs)#
開發者軟體開發套件(SDK) 是一組工具,讓開發者能在特定平台上建立應用程式。透過提供 SDK,你不僅簡化了整合所需的工作,還幫助開發者遵循與你的 API 合作的最佳實踐。當開發者能遵循最佳實踐,反過來會為你的 API 創造更優的使用模式,幫助你擴展。
以下描述建立 SDK 以幫助 API 擴展時應考慮的幾個面向。
速率限制支援#
開發者不想為了配合你的速率限制而撰寫額外的程式碼。如果你提供 SDK,應確保它們能良好地配合速率限制運作:
- SDK 程式碼應解析 API 回應中的速率限制 header,並在必要時降低請求速率
- SDK 應優雅地處理 429 錯誤,只在速率限制 header 指示的時間之後才重試
分頁支援#
取得跨多頁的結果通常很困難,在迴圈中請求多頁時尤其容易觸及速率限制。透過在 SDK 中添加分頁 API 的支援,你可以確保速率限制和錯誤被優雅地處理。同時,你可能需要支援取得頁面數量的某些上限。
使用 gzip#
在 SDK 中使用 gzip 壓縮是減少每次 API 呼叫所需頻寬的簡單有效方式。雖然壓縮和解壓縮內容會消耗額外的 CPU 資源,但這通常是減少網路成本的很好折衷。
快取常用資料#
你可以在 SDK 中添加支援,將 API 回應或常用資料本地儲存在快取中。這有助於減少你收到的 API 呼叫數量。如果你對客戶端可以儲存哪些資料有顧慮或政策,確保快取在幾小時後自動過期可以有所幫助。
錯誤處理與指數退避#
錯誤常被開發者處理得不好。開發者在開發期間難以重現所有可能的錯誤,因此他們可能不會撰寫程式碼來優雅地處理這些錯誤。
建構 SDK 時:
- 首先,實作本地檢查以在無效請求時回傳錯誤。例如,如果 API 方法缺少必要參數,SDK 可以在本地拒絕 API 呼叫,防止無效請求打到你的伺服器
- 建構對請求失敗時客戶端應採取行動的支援。某些失敗(如授權錯誤)無法透過重試解決,SDK 應為這些失敗向開發者顯示適當的錯誤
- 對於其他錯誤,SDK 最好能自動重試 API 呼叫
- SDK 應實作指數退避(exponential back-off)——這是一種標準的錯誤處理策略,客戶端應用會以遞增的時間間隔定期重試失敗的請求。這有助於減少伺服器收到的請求數量,並幫助 Web 應用從中斷中優雅恢復
SDK 最佳實踐#
以下是建構 SDK 以幫助 API 擴展的最佳實踐:
- SDK 的穩定性、安全性和可靠性至關重要。SDK 中的任何 bug 可能需要多位開發者進行更新。徹底測試 SDK 後再發布是強烈推薦的
- 如果你建構的是行動 SDK,需要進一步最佳化大小、記憶體使用、CPU 使用、網路互動和電池效能
- 在 SDK 中實作複雜的 API 操作(如 OAuth),有助於加速開發者的上手體驗
- 優雅處理速率限制和錯誤。在 SDK 中建構保護機制,避免對 API 伺服器發出過多並行呼叫
- 透過向開發者顯示錯誤並允許他們開啟日誌記錄,使故障排除變得容易
- SDK 的打包方式影響採用率。使用適當的平台(如 npm、CocoaPods、RubyGems 或 pip)來分發 SDK
結語#
擴展 API 不僅僅是支援每秒更多的請求。還有其他創造性的方式來支撐不斷增長的客戶數量。重要的是理解你遇到了什麼可擴展性問題以及為什麼:
- 開發者是否真的需要發出他們目前發出的 API 呼叫數量?
- API 設計的變更是否有助於減少呼叫量?
- 開發者能否更高效地使用你的 API?
回答這些問題,加上開發者的回饋,將幫助你更成功地擴展 API。
當你改進 API 設計、政策和工具時,這些變更有時會影響你的開發者。在下一章中,你將學習如何在推出這些變更的同時保持開發者的知情。