本章摘要: 將批次處理的概念延伸至無界的即時資料流。比較傳統訊息代理與日誌式代理(如 Kafka)的設計取捨,探討 CDC 與 Event Sourcing 如何連接資料庫與串流,並深入事件時間推理、串流 join 模式與容錯機制等核心挑戰。
在第十章我們討論了批次處理——讀取一組有限的輸入檔案,產生一組新的輸出檔案。然而現實世界中,大量資料是無界的 (unbounded):使用者昨天產生了資料、今天也在產生、明天還會繼續。批次處理必須人為地將資料切成固定時間區段(例如每天、每小時處理一次),導致變更反映到輸出的延遲可能長達數小時甚至一天。
串流處理 (stream processing) 的核心思想是:放棄固定的時間切片,改為在事件發生時立即處理。串流是一種隨時間逐步產生的資料,概念無處不在——Unix 的 stdin/stdout、TCP 連線、音訊視訊串流等。本章將事件串流作為一種資料管理機制來探討:如何表示、儲存、傳輸串流,串流與資料庫的關係,以及如何持續處理串流並建構應用程式。
傳送事件串流#
在批次處理中,輸入輸出是檔案;在串流處理中,基本單位是事件 (event)——一個小型、自包含、不可變的物件,記錄了某個時間點發生的事情(例如使用者行為、感測器讀數、日誌條目)。事件通常包含一個時間戳記。
事件由生產者 (producer) 產生一次,可能被多個消費者 (consumer) 處理。相關事件被歸入同一個主題 (topic) 或串流。原則上,用檔案或資料庫就能連接生產者和消費者(生產者寫入、消費者定期輪詢),但持續低延遲處理下頻繁輪詢的開銷太高,更好的做法是在新事件出現時主動通知消費者。
訊息系統#
通知消費者最常見的方式是訊息系統 (messaging system):生產者發送包含事件的訊息,推送給消費者。不同於 Unix pipe 或 TCP 的一對一連接,訊息系統允許多個生產者寫入同一主題、多個消費者接收訊息。
區分不同訊息系統時,有兩個關鍵問題:
- 生產速度超過消費速度時怎麼辦? 三種策略:丟棄訊息、在佇列中緩衝、或施加背壓 (backpressure) 阻塞生產者。如果選擇緩衝,需考慮佇列增長到超出記憶體時的處理方式
- 節點當機或暫時離線時訊息是否會遺失? 持久性需要寫入磁碟或複製,會帶來效能成本
訊息遺失是否可接受取決於應用場景。感測器定期回報的數據偶爾遺失影響不大,但用於計數的事件若遺失則會導致計數不正確。
直接訊息傳遞#
幾種不經中間節點的直接傳遞方式:
- UDP 多播:金融業的股票行情串流常用此方式追求低延遲,應用層協定負責重傳遺失封包
- 無代理訊息庫 (如 ZeroMQ、nanomsg):在 TCP 或 IP 多播上實作 pub/sub
- StatsD / Brubeck:使用不可靠的 UDP 收集全網路機器的監控指標
- Webhook:消費者暴露 HTTP 端點,生產者以 HTTP/RPC 推送訊息
直接傳遞的共同限制:通常假設生產者和消費者都持續在線。消費者離線期間的訊息可能遺失,生產者當機時緩衝區也會一併消失。
訊息代理#
訊息代理 (message broker) 是一種專為訊息串流最佳化的伺服器。生產者寫訊息到代理,消費者從代理讀取。代理集中管理資料,更容易處理客戶端的來去(連線、斷線、當機),持久性問題也轉移到代理身上。消費者通常是非同步的——生產者只等待代理確認緩衝完成,不等消費者處理。
訊息代理 vs 資料庫#
兩者看似相近,但有重要差異:
- 保留策略:資料庫保留資料直到明確刪除;訊息代理在訊息被成功投遞後自動刪除
- 工作集假設:訊息代理假設佇列較短,大量積壓會降低效能
- 查詢模式:資料庫支援次要索引和搜尋;訊息代理支援按模式訂閱主題子集
- 通知機制:資料庫查詢結果是時間點快照,不主動通知變更;訊息代理主動通知新訊息
傳統訊息代理的代表包括 RabbitMQ、ActiveMQ、IBM MQ 等,遵循 JMS 或 AMQP 標準。
多個消費者的模式#
當多個消費者讀取同一主題時,有兩種主要模式:
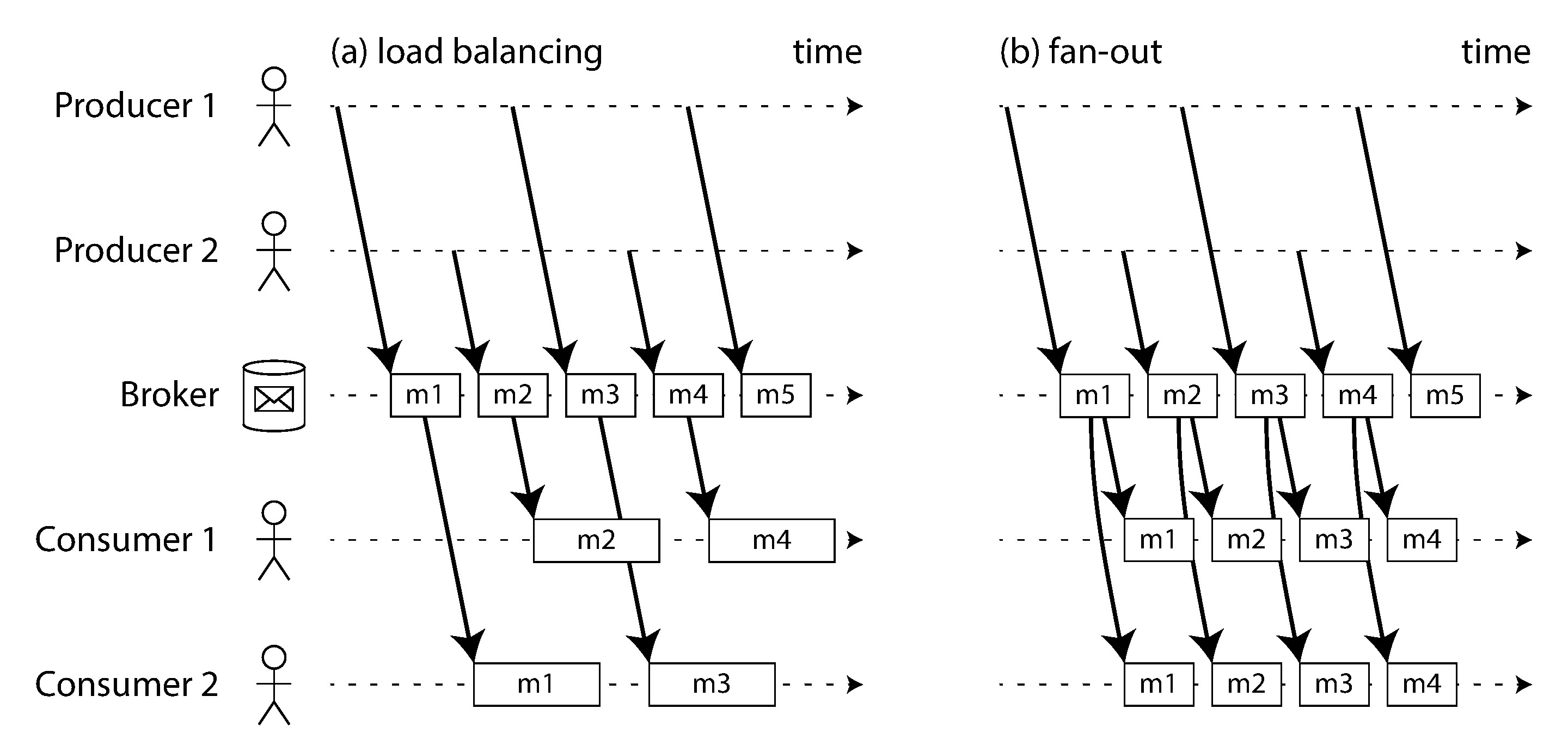
Figure 11-1: (a) 負載平衡:多個消費者分擔主題消費 (b) 扇出:每個消費者獨立接收所有訊息
- 負載平衡 (Load balancing):每則訊息只投遞給其中一個消費者,讓多個消費者分擔處理工作。適用於訊息處理成本高、需要平行化的場景
- 扇出 (Fan-out):每則訊息投遞給所有消費者,各消費者獨立處理。等同於多個批次任務讀取同一輸入檔案
兩種模式可以組合:多個消費者群組各自訂閱同一主題,群組間為扇出,群組內為負載平衡。
確認與重新投遞#
消費者可能在處理訊息途中當機。為確保訊息不遺失,代理使用確認機制 (acknowledgment):消費者明確告知代理已完成處理,代理才將訊息從佇列移除。若連線逾時且未收到確認,代理將訊息重新投遞給另一個消費者。
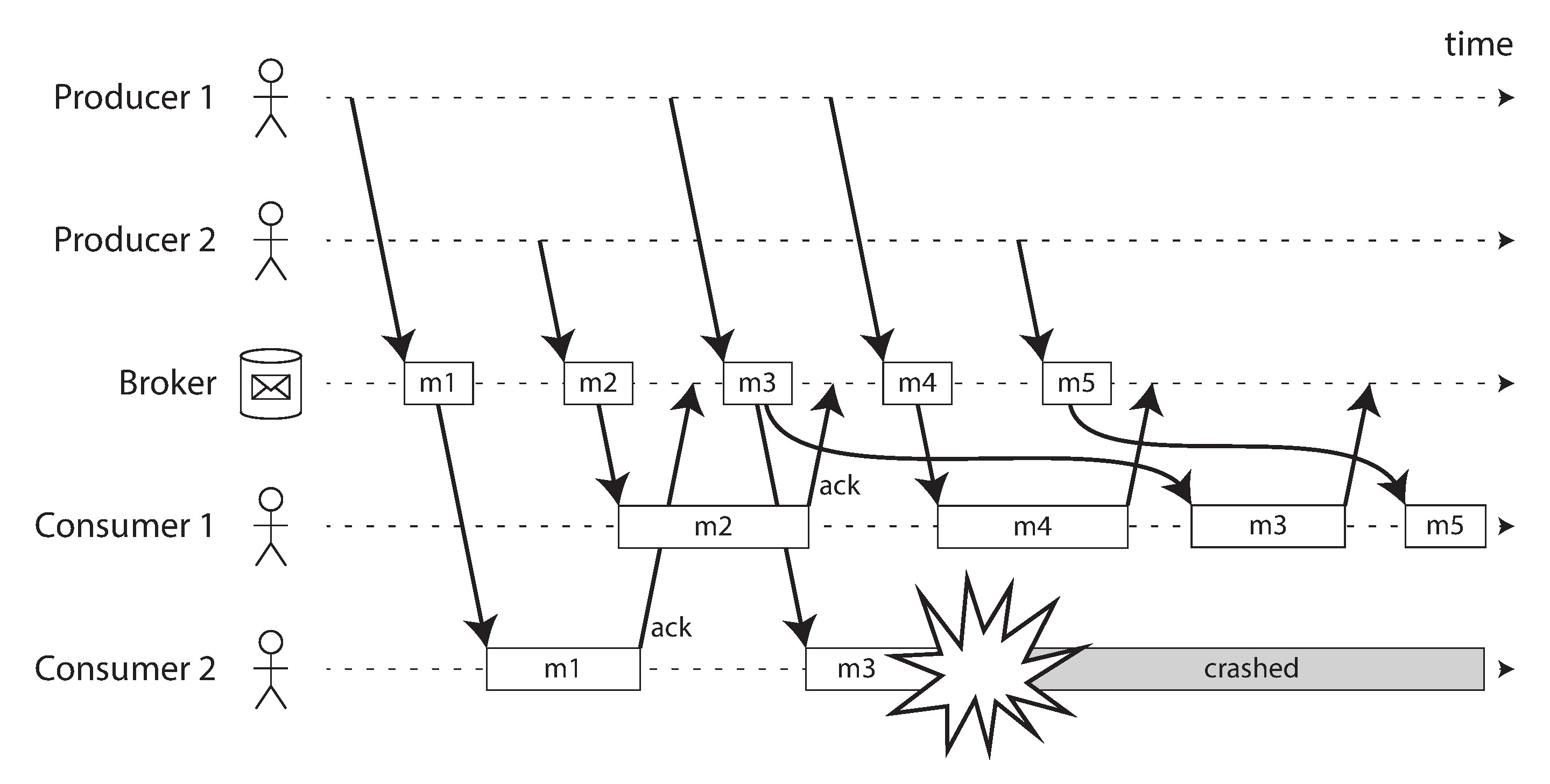
Figure 11-2: Consumer 2 在處理 m3 時當機,訊息重新投遞給 Consumer 1
在負載平衡模式下,重新投遞會導致訊息亂序。例如 consumer 2 在處理 m3 時當機,m4 已被 consumer 1 處理,m3 隨後重新投遞給 consumer 1,結果 consumer 1 的處理順序為 m4、m3、m5。若訊息之間有因果依賴,這會是嚴重問題。
分區日誌#
傳統訊息代理的心智模型是暫態的 (transient):訊息投遞後即刪除。這與資料庫或檔案系統永久記錄的心智模型截然不同。
這種差異影響了衍生資料的建立方式。批次處理可以反覆執行而不損害輸入(輸入是唯讀的),但 AMQP/JMS 式的訊息消費是破壞性的——確認後訊息就被刪除,無法重新執行同一消費者獲得相同結果。新加入的消費者也無法讀取歷史訊息。
日誌式訊息代理 (log-based message broker) 結合了資料庫的持久儲存與訊息系統的低延遲通知:
- 生產者將訊息追加到日誌末尾
- 消費者循序讀取日誌;到達末尾時等待新訊息的通知
- 日誌可以分區 (partition) 以提升吞吐量,分區分布在不同機器上
- 每個分區內,代理為每則訊息分配單調遞增的偏移量 (offset)
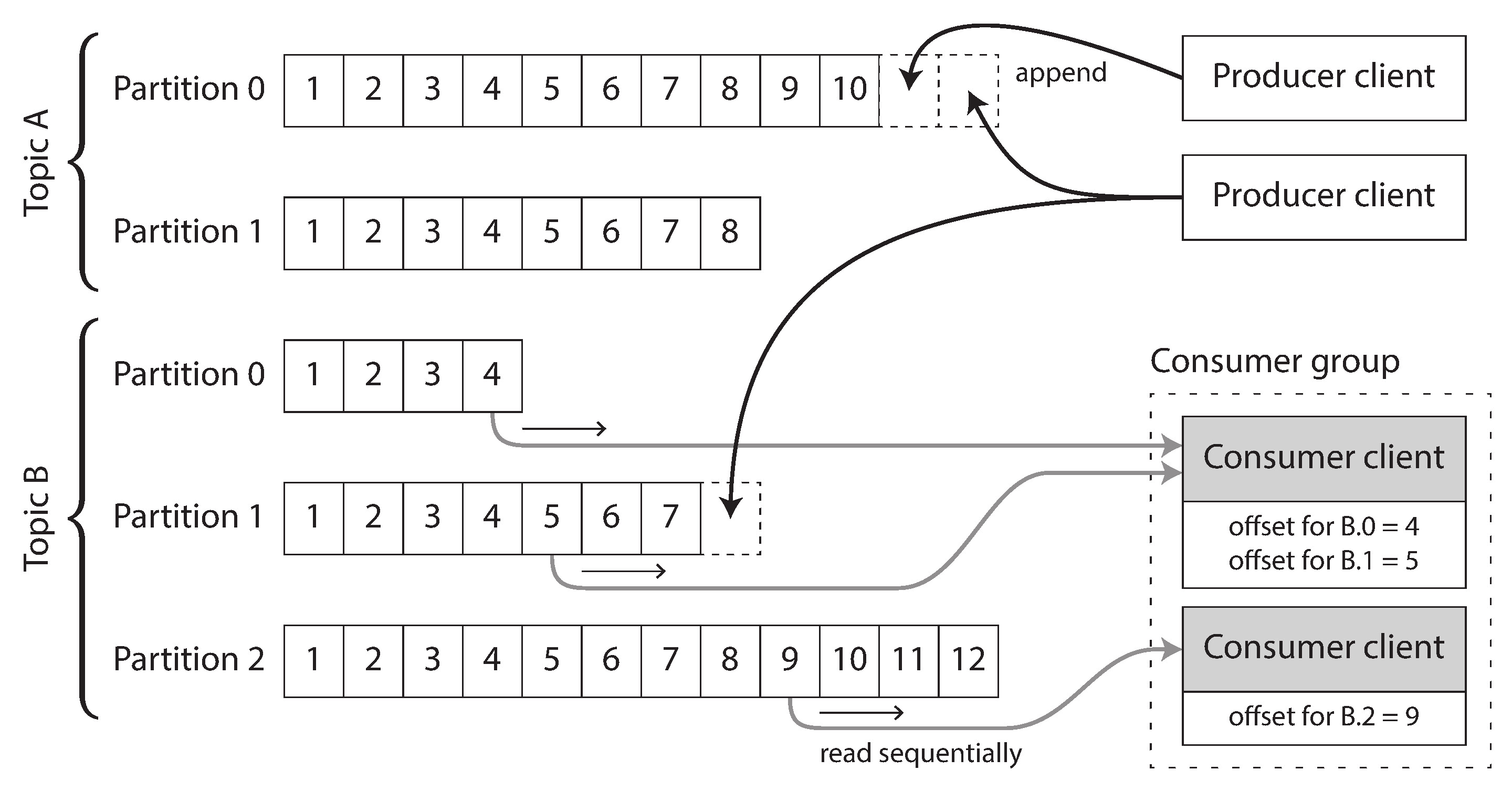
Figure 11-3: 生產者將訊息追加到分區檔案,消費者依序讀取
Apache Kafka、Amazon Kinesis Streams、Twitter DistributedLog 都是這類日誌式訊息代理。它們透過跨機器分區達到每秒數百萬訊息的吞吐量,並透過複製實現容錯。
日誌式 vs 傳統訊息模型#
日誌式方法天然支援扇出——多個消費者可以獨立讀取日誌而互不影響,讀取訊息不會將其從日誌中刪除。負載平衡的實作方式則不同於傳統模型:代理將整個分區分配給消費者群組中的某個節點,而非逐則訊息分配。每個消費者依序讀取所分配分區中的所有訊息,通常以單執行緒方式處理。
這種粗粒度的負載平衡有些限制:
- 消費者數量最多等於分區數量(同一分區的訊息必須由同一節點處理)
- 單一慢訊息會阻塞同分區後續訊息的處理(隊頭阻塞,head-of-line blocking)
因此,訊息處理昂貴且需要逐則平行化、順序不重要時,JMS/AMQP 模型更適合;高吞吐、快速處理且需要有序的場景,日誌式模型更佳。如需更高的平行度,可以增加分區數量而非消費者數量。
消費者偏移量#
循序消費使追蹤進度變得簡單:偏移量以下的訊息已處理完畢,以上的尚未處理。代理只需定期記錄消費者偏移量,無需追蹤每則訊息的確認。這與資料庫複製中的日誌序號 (log sequence number) 原理相同——代理像 leader,消費者像 follower。
磁碟空間使用#
日誌實際上被切分為段,舊段定期刪除或歸檔。這形成一個有界的環形緩衝區。以 6 TB 硬碟、150 MB/s 循序寫入速度計算,填滿硬碟約需 11 小時。實務上很少用滿全部寫入頻寬,日誌通常可保留數天甚至數週的訊息。
資料庫與串流#
訊息代理與資料庫看似不同類別的工具,但它們之間的連結比表面上更為根本。資料庫的複製日誌 (replication log) 本質上就是一種寫入事件的串流。狀態機複製原理告訴我們:如果每個副本以相同順序處理相同事件,最終會達到相同狀態——這正是事件串流的應用。
保持系統同步#
在異質資料系統中(同時使用 OLTP 資料庫、快取、全文搜尋索引、資料倉儲),需要讓多個系統保持同步。雙重寫入 (dual writes)——應用程式同時寫入多個系統——有嚴重問題:
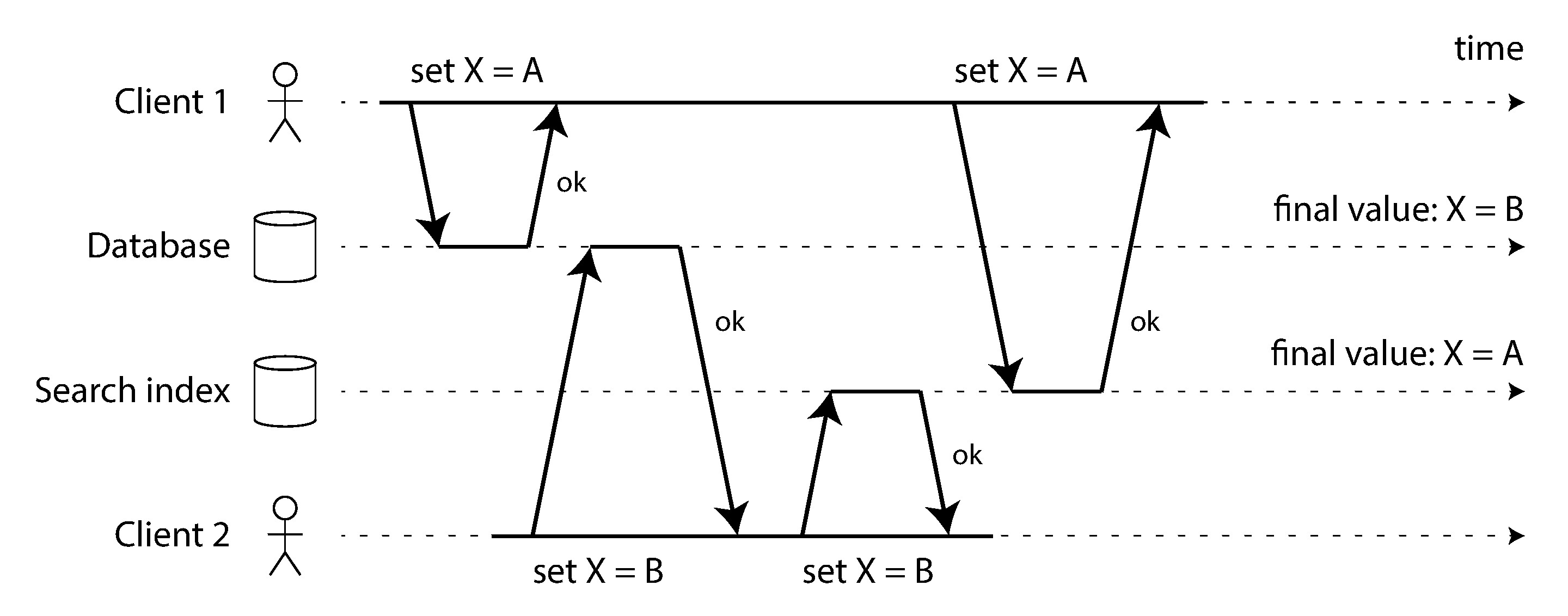
Figure 11-4: 資料庫與搜尋索引的寫入順序不一致
- 競態條件:兩個客戶端同時更新,由於請求交錯,資料庫最終值為 B,但搜尋索引最終值為 A,兩個系統永久不一致
- 部分失敗:其中一個寫入成功、另一個失敗,導致不一致。確保兩者同時成功或同時失敗是原子提交問題,解決成本高昂
如果只有一個 leader 資料庫,由它決定寫入順序,就能避免上述問題。真正的解法是讓一個系統作為唯一的 leader,其他系統作為 follower 從 leader 衍生資料。
Change Data Capture (CDC)#
變更資料捕獲 (Change Data Capture, CDC) 是觀察資料庫所有寫入變更、提取為可複製到其他系統的形式的過程。CDC 將這些變更作為串流即時提供。
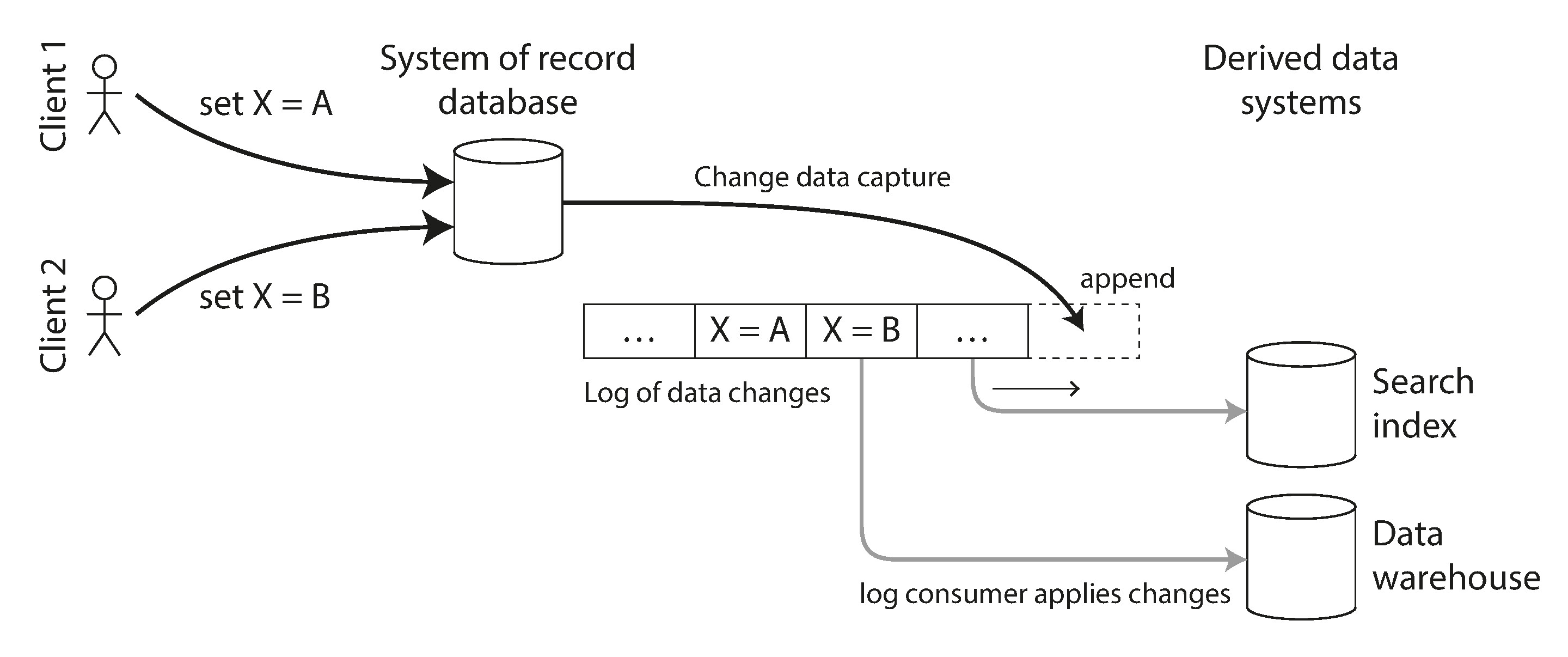
Figure 11-5: 按寫入順序從一個資料庫提取變更,套用到其他系統
CDC 本質上是讓一個資料庫成為 leader,將其他系統變成 follower。日誌式訊息代理非常適合傳輸這些變更事件,因為它保持訊息的順序。
實作方式:
- 資料庫觸發器:可行但脆弱且效能開銷大
- 解析複製日誌:更穩健的做法。LinkedIn 的 Databus、Facebook 的 Wormhole、Yahoo 的 Sherpa 都採用此方式。開源工具如 Bottled Water(解析 PostgreSQL WAL)、Maxwell 和 Debezium(解析 MySQL binlog)、Mongoriver(解析 MongoDB oplog)皆可用
初始快照:建構衍生系統的完整副本不可能保留完整的變更歷史,通常需要先取得資料庫的一致性快照(對應已知的變更日誌位置),再從該位置開始消費變更。
日誌壓縮 (log compaction):讓日誌式代理以合理磁碟空間容納資料庫完整內容的做法——只保留每個鍵的最新值,丟棄被覆蓋的舊值。建構新的衍生系統時,從壓縮後的日誌主題的 offset 0 開始消費,即可重建完整資料集。Kafka 支援此功能。
越來越多資料庫開始原生支援變更串流作為一級介面:RethinkDB 的查詢訂閱、Firebase 和 CouchDB 的 change feed、Meteor 使用 MongoDB oplog、VoltDB 的串流匯出。Kafka Connect 則致力於整合各種資料庫系統的 CDC 工具。
Event Sourcing#
事件溯源 (Event Sourcing) 源自領域驅動設計 (DDD) 社群,與 CDC 有相似之處,但在不同的抽象層次上運作:
- CDC:應用程式以可變方式使用資料庫,變更日誌從資料庫的底層提取(如解析複製日誌),應用程式不需要知道 CDC 的存在
- Event Sourcing:應用程式邏輯明確建構在不可變事件日誌之上。事件反映應用層的行為,而非底層的狀態變化。例如「學生取消選課」而非「從選課表刪除一筆記錄並新增一筆退課記錄」
Event Sourcing 的事件表達的是使用者意圖,而非狀態更新的細節。例如「學生取消選課」比「從選課表刪除一筆記錄並新增退課記錄」包含更多語意資訊。這讓後續新增的功能(如「將名額遞補給候補名單上的下一位」)可以輕鬆地從既有事件衍生出新的副作用。Event Sourcing 與時序資料模型 (chronicle data model) 和星型模式中的事實表有相似之處。
從事件日誌衍生當前狀態:使用者通常想看到系統的當前狀態,而非變更歷史。因此需要將事件日誌轉換為適合查詢的應用狀態,這個轉換應該是確定性的 (deterministic)。與 CDC 不同,Event Sourcing 的事件通常不會互相覆蓋(因為表達的是意圖而非狀態),所以需要完整的事件歷史來重建狀態,日誌壓縮不適用。實務上會使用快照 (snapshot) 加速讀取和恢復。
命令 vs 事件:使用者的請求最初是命令 (command),可能通過或被拒絕(例如座位已被預訂)。驗證通過後才成為不可變的事件 (event)。事件一旦寫入日誌就是既定事實,消費者不能拒絕事件。因此驗證必須在命令轉為事件之前同步完成。
狀態、串流與不可變性#
我們通常認為資料庫儲存的是「當前狀態」,但狀態只是事件隨時間累積的結果。帳戶餘額是借貸事件的結果,可用座位數是預訂事件的結果。
可變狀態與不可變事件日誌並不矛盾:它們是同一枚硬幣的兩面。用數學類比來說,應用狀態是事件串流對時間的積分 (integration),而變更串流是狀態對時間的微分 (differentiation)。
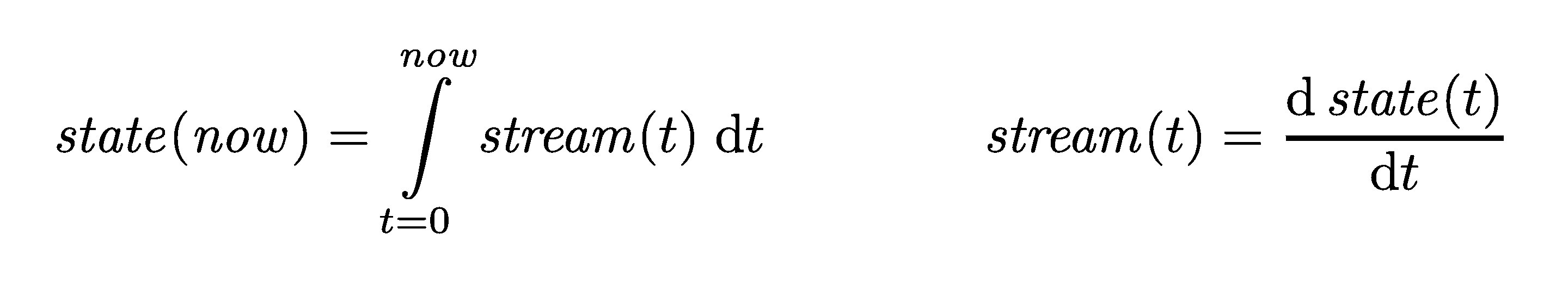
Figure 11-6: 當前應用狀態與事件日誌的關係
如果將事件日誌視為系統記錄 (system of record),可變狀態只是從中衍生出來的快取,那麼資料流的推理會變得更加清晰。Pat Helland 如此描述:「交易日誌記錄了資料庫的所有變更。從這個角度看,資料庫的內容只是日誌中最新記錄值的快取。真相是日誌,資料庫是日誌子集的快取。」
不可變事件的優勢:
- 可審計性:如同會計數百年來使用的做法——帳本是追加式的,錯誤不是擦除而是新增一筆更正交易(沖正)。不可變日誌讓診斷問題和從 bug 中恢復更容易。如果部署了有 bug 的程式碼寫入了錯誤資料,若允許破壞性覆寫則恢復困難重重;有了不可變日誌則容易得多
- 捕獲更多資訊:使用者將商品加入購物車後又移除——從訂單履行角度兩者抵消,但對分析而言這是寶貴的購買意圖資訊。只記錄最終狀態的資料庫會遺失這些資訊
- 多重視圖:從同一份事件日誌可以衍生多個讀取最佳化的視圖(搜尋索引、分析資料庫、快取等)。新功能可以從事件日誌重新建構全新的視圖,與既有系統並行運行,無需修改既有系統。舊系統不再需要時直接關閉即可
這種將寫入形式與讀取形式分離的設計稱為 CQRS (Command Query Responsibility Segregation)。它讓正規化與反正規化的爭論變得不再重要——讀取視圖可以自由反正規化,因為從事件日誌到視圖的轉換過程保證了一致性。Twitter 的 home timeline 就是一個高度反正規化的讀取最佳化狀態:每條推文被複製到所有追蹤者的時間軸中,fan-out 服務負責保持這些重複狀態的同步。
並行控制:Event Sourcing 和 CDC 的消費者通常是非同步的,使用者寫入後讀取可能還看不到自己的寫入(參見「讀取自己的寫入」一致性問題)。但從另一個角度看,將使用者動作設計為自包含的事件,只需寫入一處(追加到日誌),這大大簡化了並行控制。如果事件日誌與應用狀態以相同方式分區,單執行緒的日誌消費者甚至不需要寫入的並行控制。
不可變性的限制:更新率高且資料集較小的工作負載下,不可變歷史可能膨脹得過大。此外,隱私法規可能要求真正刪除使用者資料,而非僅追加一條「標記為刪除」的事件。Datomic 的 excision 和 Fossil 的 shunning 就是為此而生的功能。真正刪除資料出人意料地困難——副本可能存在於儲存引擎、檔案系統、SSD 和備份中的多處。
處理串流#
有了串流之後,可以做三件事:
- 寫入儲存系統(資料庫、快取、搜尋索引)供其他客戶端查詢——等同於批次處理的輸出
- 推送給使用者(email 通知、即時儀表板)——人類是最終消費者
- 處理一或多個輸入串流,產生新的輸出串流——串流可以經過多個這樣的處理階段
第三種情況中的處理程式稱為運算子 (operator) 或任務。模式類似 MapReduce:以唯讀方式消費輸入串流,以追加方式寫入輸出。分區和平行化的模式也與第十章的資料流引擎相似,基本的映射與過濾操作同樣適用。
關鍵差異在於串流永不結束,這帶來重大影響:無界資料集不能排序,因此無法使用 sort-merge join;容錯機制也必須改變——批次任務運行幾分鐘後失敗可以從頭重來,但已運行數年的串流任務不可能從頭重來。
串流處理的用途#
- 複雜事件處理 (Complex Event Processing, CEP):以類似正則表達式匹配字串的方式,在串流中搜尋事件模式。CEP 將「查詢」與「資料」的關係反轉——查詢是長期儲存的,事件持續流過查詢。代表工具:Esper、IBM InfoSphere Streams
- 串流分析 (Stream Analytics):偏重聚合與統計指標(事件頻率、滾動平均、趨勢偵測),而非尋找特定事件序列。通常在固定時間視窗上計算。框架包括 Apache Storm、Spark Streaming、Flink、Kafka Streams,以及 Google Cloud Dataflow、Azure Stream Analytics 等託管服務
- 維護物化視圖:從變更串流持續更新衍生資料系統。與分析不同,物化視圖可能需要追溯到「時間起點」的所有事件
- 串流上的搜尋:預先定義搜尋查詢,讓文件串流不斷通過查詢進行比對。Elasticsearch 的 percolator 功能即是此類實作
- 訊息傳遞與 RPC:Actor 框架也基於訊息和事件,但與串流處理的關注點不同——actor 側重並行管理,通訊是短暫且一對一的;串流處理側重資料管理,事件日誌是持久且多訂閱者的
時間推理#
串流處理中的時間問題比看起來更棘手。批次處理使用事件中嵌入的時間戳記,不會參考處理機器的系統時鐘。但許多串流處理框架使用處理時間 (processing time) 來決定視窗——當事件創建與處理之間的延遲可忽略時還算合理,但一旦有明顯延遲就會出問題。
事件時間 vs 處理時間:延遲的原因很多——佇列積壓、網路故障、效能問題導致的競爭、串流消費者重啟、為了修復 bug 而重新處理歷史事件等。訊息延遲也可能導致不可預測的順序:使用者先發出請求 A(由伺服器 A 處理),再發出請求 B(由伺服器 B 處理),但 B 的事件可能先到達訊息代理。
書中以星際大戰電影的上映順序為類比:Episode IV 在 1977 年上映,但按故事時間線它不是第一部。如果按上映順序觀看,觀看順序(處理時間)與故事時間線(事件時間)不一致。人類可以應對這種不連續性,但串流處理演算法必須特別設計來處理。
如果用處理時間衡量請求頻率,消費者重啟後處理積壓事件時會產生虛假的流量尖峰,而實際的請求頻率是平穩的。
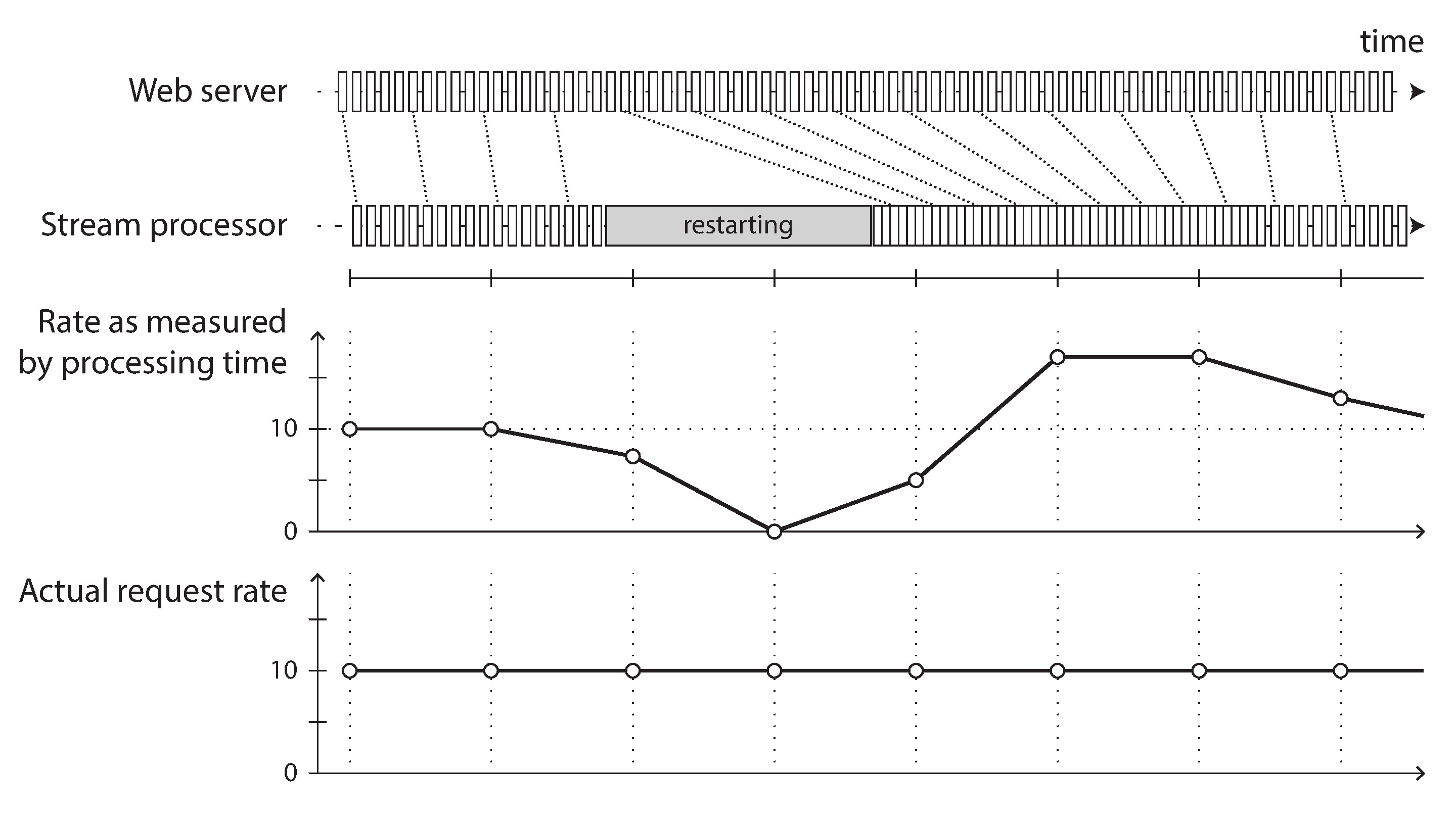
Figure 11-7: 按處理時間分窗會因延遲變化產生偏差
何時宣告視窗完成? 使用事件時間定義視窗時,永遠無法確定是否已收到某個視窗的所有事件。例如你正在按分鐘計數事件,第 37 分鐘的事件已經在減少、大部分新事件屬於第 38 和 39 分鐘——什麼時候可以宣告第 37 分鐘的視窗完成並輸出計數值?
對於遲到的落後者事件 (straggler events),有兩種做法:
- 忽略它(追蹤丟棄比例作為監控指標,若丟棄量異常則告警)
- 發布修正值,更新之前已輸出的視窗結果,可能需要撤回 (retract) 之前的輸出
某些情況下可以使用特殊訊息標記「從現在起不會再有時間戳記早於 t 的訊息」來觸發視窗關閉,但如果有多個生產者在不同機器上產生事件,每個生產者的最小時間戳記閾值需要分別追蹤。
該用誰的時鐘? 行動裝置在離線時緩衝事件,上線後才傳送,對消費者而言是極端延遲的落後者。裝置時鐘可能不準確,伺服器時鐘則較可靠但意義不同。解決方案是記錄三個時間戳記:
- 事件發生時的裝置時鐘
- 事件發送到伺服器時的裝置時鐘
- 伺服器收到事件時的伺服器時鐘
第二和第三個時間戳記的差值可估算裝置時鐘偏移,用來修正事件時間戳記。
視窗類型#
確定時間戳記的處理方式後,需要定義視窗。常見的四種類型:
| 類型 | 英文 | 說明 |
|---|---|---|
| 滾動視窗 | Tumbling window | 固定長度,每個事件恰好屬於一個視窗。例如 1 分鐘滾動視窗將事件時間戳記捨入到最近的分鐘 |
| 跳躍視窗 | Hopping window | 固定長度但允許重疊。例如 5 分鐘視窗、1 分鐘跳躍間隔——先計算 1 分鐘滾動視窗,再聚合相鄰的多個視窗 |
| 滑動視窗 | Sliding window | 包含彼此在指定間隔內的所有事件。例如 5 分鐘滑動視窗會將間隔不到 5 分鐘的事件放在同一視窗中,即使它們跨越了滾動視窗的邊界 |
| 會話視窗 | Session window | 沒有固定時長,按同一使用者的連續活動分組,使用者閒置超過一定時間(如 30 分鐘)則視窗結束。常用於網站分析 |
串流 Join#
批次處理中的 join 是重要的資料管線操作,串流處理同樣需要 join,但因為新事件隨時到來,難度更高。三種類型:
Stream-stream join(視窗 join):兩個輸入串流都是活動事件,join 運算子在某個時間視窗內搜尋相關事件。例如搜尋事件與點擊事件的關聯——使用者搜尋後可能在幾秒到幾週後才點擊結果(甚至可能永遠不點擊)。注意不能將搜尋詳情嵌入點擊事件中,因為那樣只能看到有點擊的搜尋,無法計算真正的點擊率。
串流處理器需維護狀態(例如過去一小時的所有事件,按 session ID 索引),每當新事件到達就檢查另一個索引是否有匹配。匹配到就發出「搜尋結果被點擊」的事件;搜尋事件過期而未匹配到點擊則發出「搜尋結果未被點擊」的事件。
Stream-table join(串流增強):一個輸入是活動事件串流,另一個是資料庫。例如將使用者 ID 增強為含有完整使用者檔案的事件。可以在串流處理器中載入資料庫的本地副本(記憶體雜湊表或本地磁碟索引),並透過 CDC 訂閱資料庫的 changelog 保持本地副本同步。本質上是兩個串流的 join——活動事件與 profile 更新事件。
Table-table join(物化視圖維護):兩個輸入串流都是資料庫的 changelog。以 Twitter 時間軸為例:需要維護每個使用者的時間軸快取,涉及四種事件——發推文、刪推文、追蹤、取消追蹤。串流處理器需要維護追蹤者關係的資料庫,以便在新推文到來時知道要更新哪些使用者的時間軸。
這等同於維護 tweets 表與 follows 表 join 結果的物化視圖——從數學角度看,若串流是表的微分,join 是兩個表的乘積,那麼 join 結果的變更串流遵循乘積法則:(u*v)’ = u’v + uv’,即 tweets 的任何變更與當前 followers join,followers 的任何變更與當前 tweets join。
Join 的時間依賴性:三種 join 都需要處理器維護狀態,且事件順序很重要。跨不同串流或分區的事件順序是不確定的,這使得 join 可能變成非確定性的 (nondeterministic)——相同輸入重新執行可能得到不同結果。在資料倉儲中,這稱為緩慢變化維度 (Slowly Changing Dimension, SCD),常見做法是為每個版本的記錄分配唯一識別碼,但這會讓日誌壓縮不可行。
容錯#
批次處理的容錯相對簡單:任務失敗就重啟,輸出只在任務完成時才可見。這提供了恰好一次語義 (exactly-once semantics)——輸出看起來就像每筆輸入恰好被處理了一次。但串流永不結束,無法等到「完成」才讓輸出可見。
微批次與檢查點:
- 微批次 (Microbatching):Spark Streaming 的做法——將串流切成小批次(通常約一秒),每批像微型批次任務處理。批次大小是延遲與排程開銷的取捨
- 檢查點 (Checkpointing):Apache Flink 的做法——定期產生狀態的滾動檢查點寫入持久儲存。串流中的 barrier 觸發檢查點,不強制特定視窗大小
微批次和檢查點在框架內部提供恰好一次語義,但一旦輸出離開框架(寫入外部資料庫、發送 email),失敗重試會導致外部副作用重複執行。
原子提交:確保事件處理的所有輸出和副作用(下游運算子訊息、資料庫寫入、狀態變更、輸入確認)要麼全部生效、要麼全部不生效。Google Cloud Dataflow 和 VoltDB 實作了高效的內部原子提交機制,Kafka 也有類似計畫。與 XA 不同,這些實作不嘗試跨異質技術的交易,而是在串流處理框架內部管理狀態變更和訊息傳遞。
冪等性 (Idempotence):另一種達到恰好一次效果的方式。冪等操作可以執行多次而效果不變。即使操作本身不是冪等的,也可以透過額外的中繼資料實現——例如在寫入外部資料庫時附上觸發該寫入的 Kafka 訊息偏移量,藉此判斷更新是否已被套用。前提是:失敗重啟時必須以相同順序重放相同訊息、處理必須是確定性的、不能有其他節點同時更新相同的值。
失敗後重建狀態:需要狀態的串流處理(視窗聚合、join 用的表和索引)必須確保故障後能恢復狀態。選項包括:
- 將狀態存在遠端資料儲存並複製(查詢延遲較高)
- 在串流處理器本地保存狀態並定期複製。Flink 將快照寫入 HDFS;Samza 和 Kafka Streams 透過專用的 Kafka 主題複製狀態變更
- VoltDB 在多個節點上冗餘處理每則輸入訊息
- 某些情況下可從輸入串流重建狀態(例如短視窗的聚合直接重放事件、CDC 衍生的資料庫副本從壓縮日誌重建)
小結#
本章探討了事件串流的傳輸與處理。訊息代理和事件日誌是串流處理中等同於檔案系統的角色。兩類訊息代理各有所長:AMQP/JMS 式適合任務佇列風格的非同步 RPC;日誌式(如 Kafka)適合需要保序、可重讀歷史訊息的串流處理場景。
資料庫的寫入可以視為串流(透過 CDC 或 Event Sourcing),由此開啟了強大的系統整合能力——持續更新搜尋索引、快取、分析系統,甚至從頭重建全新的衍生視圖。
串流處理的核心挑戰包括時間推理(事件時間 vs 處理時間、落後者事件的處理)、三種 join 模式(stream-stream、stream-table、table-table),以及容錯機制(微批次、檢查點、原子提交、冪等寫入)。與批次處理一樣,目標是讓輸出看起來像每筆記錄恰好被處理了一次,但在持續運行的串流中實現這一點需要更細粒度的恢復機制。