本章摘要: 從 Unix 管線的「輸入不可變、輸出供未知程式使用」哲學出發,介紹 MapReduce 與 Spark/Flink 等資料流引擎如何將批處理擴展到分散式環境,並深入 sort-merge join 等 join 演算法的設計取捨。
三類系統#
現代資料系統依據回應特性可分為三類:
| 類型 | 英文 | 特點 | 效能指標 |
|---|---|---|---|
| 線上系統 | Services | 等待客戶端請求,盡快處理並回傳結果,可用性至關重要 | 回應時間(response time) |
| 離線系統 | Batch processing | 接收大量輸入資料,執行一段時間後產出結果,沒有使用者在等待 | 吞吐量(throughput) |
| 近即時系統 | Stream processing | 介於線上與離線之間,在事件發生後不久即處理,相較於批處理擁有更低的延遲 | - |
本章聚焦於批處理。MapReduce 在 2004 年發表後曾被譽為「讓 Google 大規模擴展的演算法」,雖然其重要性已逐漸下降,但理解它有助於掌握批處理為何有用、如何運作。
Unix 工具的批處理哲學#
簡單的日誌分析範例#
假設要從 nginx 存取日誌中找出最熱門的五個頁面,可以用一行 Unix 指令完成:
cat /var/log/nginx/access.log |
awk '{print $7}' |
sort |
uniq -c |
sort -r -n |
head -n 5這條管線依序做了:提取 URL、排序、計數去重、按次數逆序排序、取前五名。看似簡短,卻能在數秒內處理 GB 級的日誌檔。
同樣的邏輯也可以用程式語言實現(例如 Ruby 的 hash table 計數法),但兩者在執行流程上有根本差異。
Sorting vs. In-memory Aggregation#
- In-memory hash table(如 Ruby 範例):適合 distinct URL 數量較少、能放進記憶體的情況。
- Sort-based approach(如 Unix 管線):當工作集超過可用記憶體時,可利用磁碟進行歸併排序(mergesort),具有良好的循序存取模式。GNU
sort會自動處理超出記憶體的資料集,並自動利用多核心平行排序。
Unix 哲學#
Doug McIlroy 在 1964 年提出了 Unix 管線(pipes)的概念。Unix 哲學的四大原則:
- 讓每個程式做好一件事——要做新工作就寫新程式,而非在舊程式上堆疊功能。
- 預期每個程式的輸出都會成為另一個程式的輸入——不要混入多餘資訊,不要要求互動式輸入。
- 儘早設計與建造軟體——不要猶豫丟掉笨拙的部分重新來過。
- 優先使用工具而非人力——即使需要繞道去建造工具。
這些原則與現代的 Agile 和 DevOps 思維驚人地一致。
統一介面與組合性#
Unix 工具之所以能自由組合,關鍵在於 統一介面(uniform interface):一切皆檔案(file descriptor)。檔案是有序的位元組序列,不管是實際檔案、socket、裝置驅動或 TCP 連線,都共用同一介面。按照慣例,多數 Unix 工具以 \n 作為記錄分隔符,讓它們能無縫互通。
邏輯與接線的分離#
Unix 工具善用 stdin / stdout 實現「邏輯與接線的分離」(separation of logic and wiring)。程式不需要知道輸入從哪來、輸出去哪裡,這是一種 鬆耦合(loose coupling) 或 控制反轉(inversion of control) 的形式。
透明性與實驗性#
Unix 工具的成功還來自於:
- 輸入檔案被視為 不可變的(immutable),可以反覆執行而不破壞資料
- 可以在管線中任何一點截斷並檢視中間結果
- 可以將中間結果寫入檔案,從任一階段重新開始
Unix 工具最大的限制是只能在 單一機器 上運行。這正是 Hadoop 等分散式工具登場的背景。
MapReduce 與分散式檔案系統#
MapReduce 就像是分散式版本的 Unix 工具——粗暴但有效。與 Unix 工具一樣,它不修改輸入、輸出以循序方式寫入一次。差別在於 MapReduce 從 分散式檔案系統 讀寫檔案,而非 stdin/stdout。
HDFS(Hadoop Distributed File System)#
HDFS 基於 shared-nothing 原則,每台機器運行一個 daemon process 對外提供檔案存取服務,由中央的 NameNode 追蹤檔案區塊(block)的分布位置。為了容錯,檔案區塊會被 複製到多台機器(或使用 erasure coding 如 Reed-Solomon codes)。最大部署規模達數萬台機器、數百 PB 的儲存容量。
MapReduce 執行流程#
MapReduce 的資料處理模式可對應到 Unix 日誌分析的四個步驟:
- 讀取輸入並拆成記錄(records)
- Mapper:從每筆記錄提取 key-value pair
- 排序:按 key 排序所有 key-value pairs(此步驟隱含在框架中)
- Reducer:遍歷排序後的 key-value pairs,合併相同 key 的值
你只需實作 mapper 和 reducer 兩個 callback function,框架處理其餘一切。
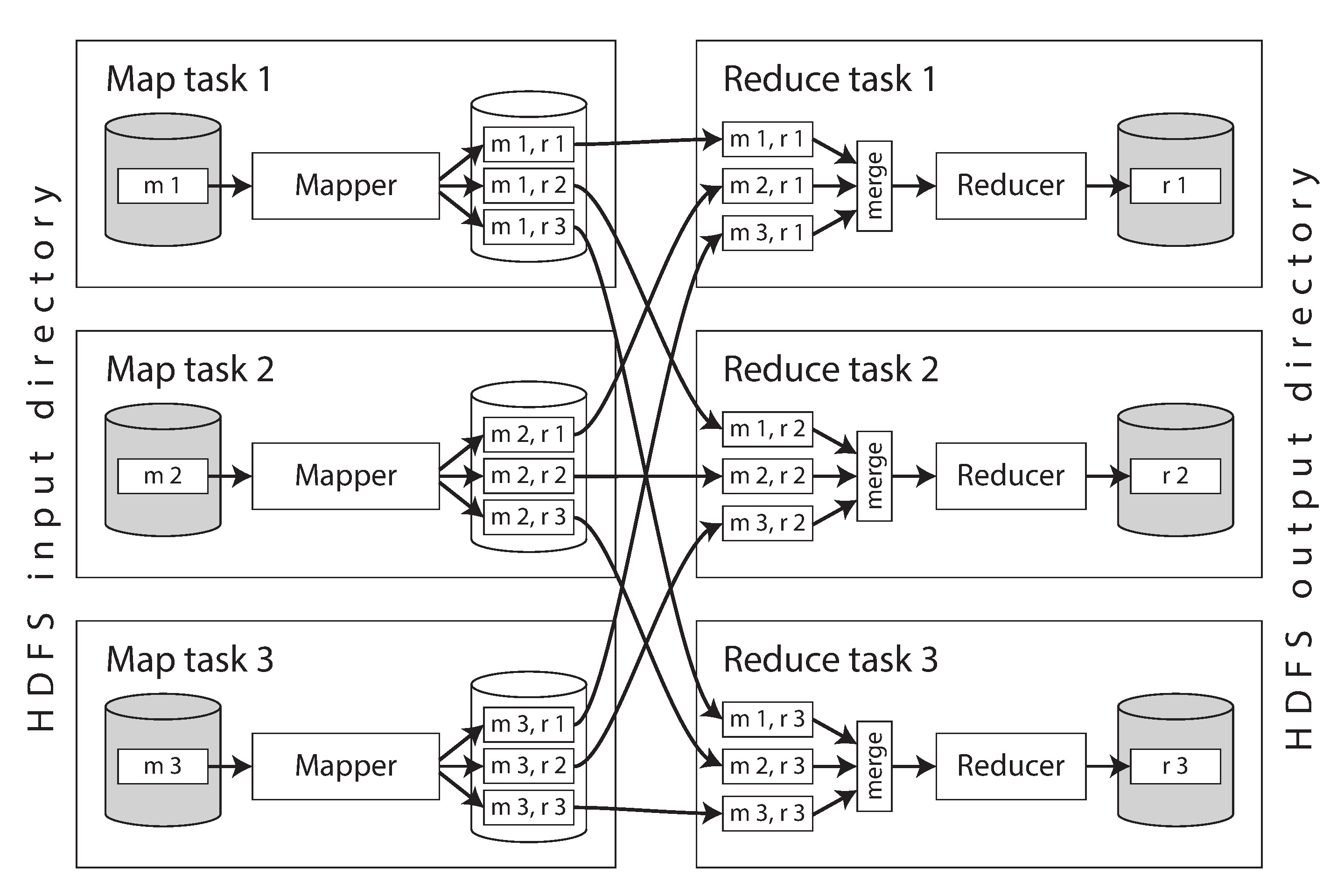
Figure 10-1: 具有三個 mapper 和三個 reducer 的 MapReduce 工作
分散式執行的關鍵細節:
- Map task 的數量由 輸入檔案區塊數 決定;Reduce task 的數量由 使用者配置 決定
- 框架使用 key 的 hash 來決定每個 key-value pair 送往哪個 reducer(與 Chapter 6 的 partitioning by hash of key 相同)
- 每個 map task 會依 reducer partition 分割並排序輸出,寫入本地磁碟(類似 SSTables 的技術)
- Reducer 從各 mapper 拉取(fetch)對應 partition 的排序檔案,合併(merge) 後依序處理——這個過程稱為 shuffle
- Reducer 的輸出寫入分散式檔案系統
MapReduce Workflows#
單一 MapReduce job 能解決的問題有限,因此通常會將多個 job 串成工作流(workflow)。前一個 job 的輸出目錄即為下一個 job 的輸入目錄。各種 workflow scheduler(如 Oozie、Airflow、Luigi)負責管理 job 間的依賴關係。
與 Unix 管線不同,MapReduce 工作流更像是將每個命令的輸出寫入暫存檔再讀取。這種 中間狀態物化(materialization of intermediate state) 有其優缺點,後面會深入討論。
Reduce-Side Joins 與 Grouping#
MapReduce 沒有索引的概念,它讀取所有輸入檔案的全部內容(相當於 full table scan)。對於需要大量彙總的分析型查詢,平行掃描整個輸入是合理的做法。
範例:使用者活動分析#
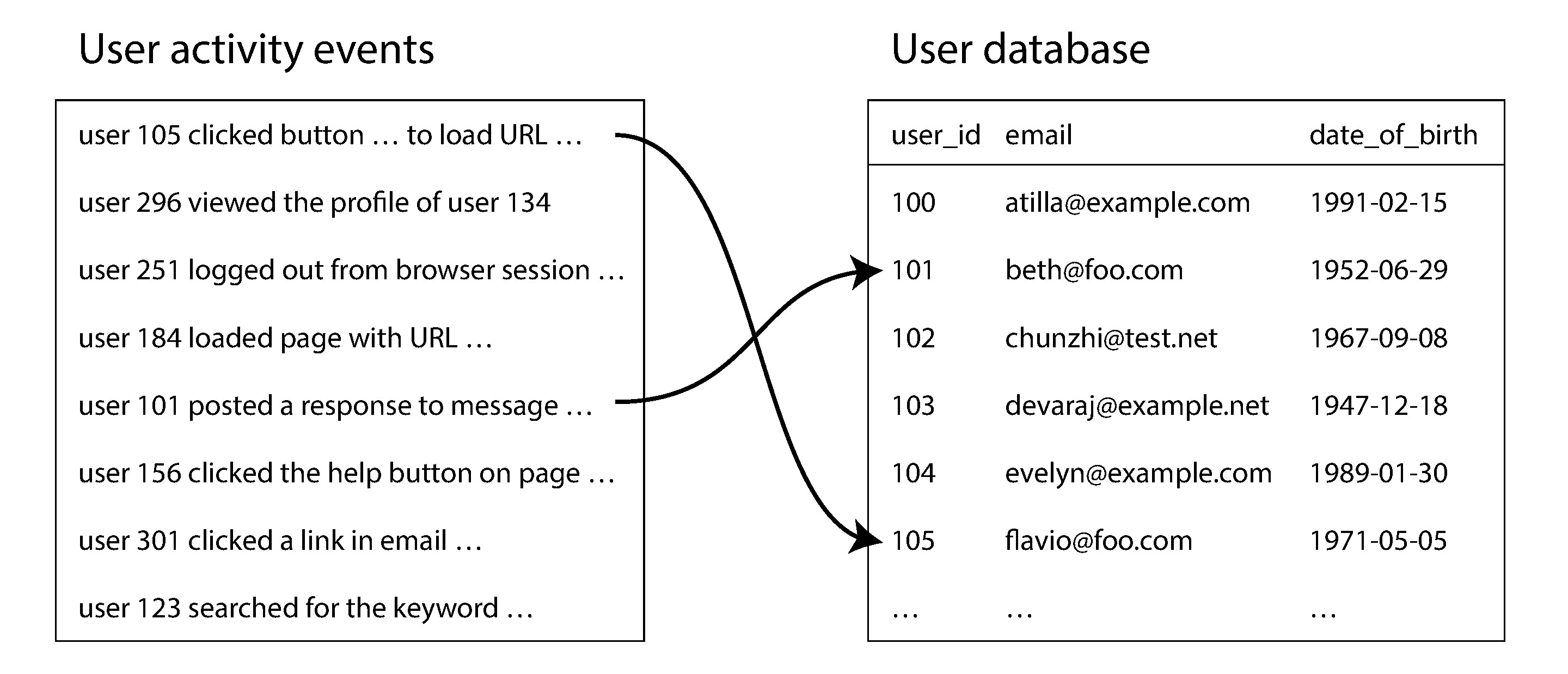
Figure 10-2: 使用者活動事件日誌與使用者個人檔案資料庫的 join
假設要將使用者活動日誌(fact table)與使用者資料庫(dimension table)做 join,以分析各年齡層最常瀏覽的頁面。最簡單的做法是逐筆查詢遠端資料庫——但這會因為 網路往返延遲 而效能極差。
更好的做法是將使用者資料庫的副本放入同一個分散式檔案系統,再透過 MapReduce 讓相關資料在同一處匯合。
Sort-Merge Join#
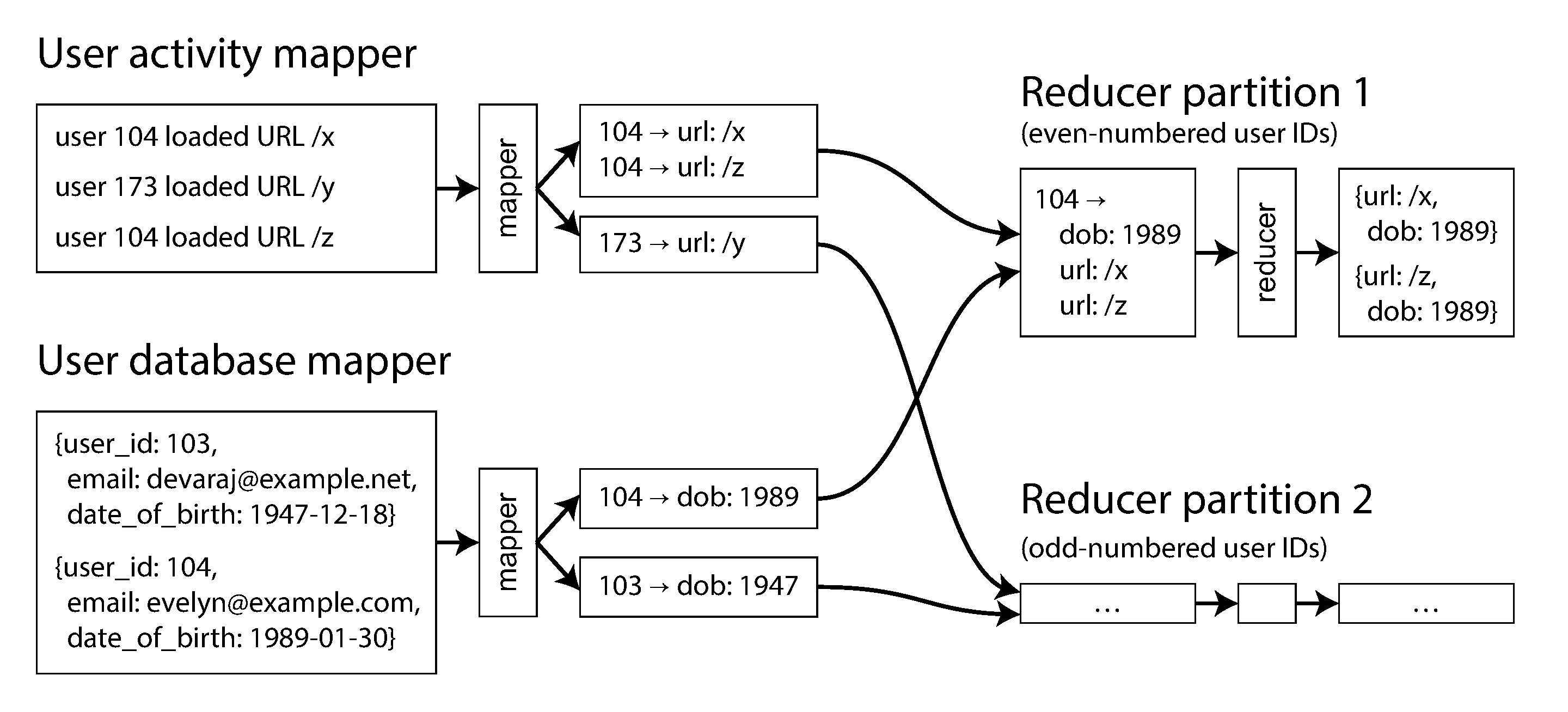
Figure 10-3: 按使用者 ID 進行 reduce-side sort-merge join
Sort-merge join 的運作方式:
- 一組 mapper 處理活動事件(提取 user ID 為 key,活動事件為 value)
- 另一組 mapper 處理使用者資料庫(提取 user ID 為 key,出生日期為 value)
- 框架按 key 排序後,同一 user ID 的所有記錄都會相鄰地送到同一個 reducer
- 透過 secondary sort,reducer 保證先看到使用者資料庫的記錄,再依序看到活動事件
- Reducer 只需在記憶體中保持一筆使用者記錄,即可完成 join——不需要任何網路請求
這就是 sort-merge join 的精髓:mapper 的輸出按 key 排序,reducer 將兩邊的排序列表合併。
將相關資料帶到同一處#
可以把 mapper 看作「向 reducer 發送訊息」——key 就像目的地地址,所有相同 key 的 value 都會被投遞到同一個 reducer。MapReduce 模型將 物理網路通訊 與 應用邏輯 分離,並透明地處理部分失敗(partial failures)。
GROUP BY 與 Sessionization#
GROUP BY 的實作方式與 join 非常相似:mapper 產出以分組 key 為 key 的 pair,排序後送入 reducer 進行聚合(COUNT、SUM 等)。
一個常見的應用是 sessionization(會話分析):以 session cookie 或 user ID 為 grouping key,將散落在各伺服器日誌中的同一使用者事件匯集,分析其行為序列(例如 A/B testing)。
處理資料傾斜(Handling Skew)#
當某些 key 對應的資料量極大(例如名人的社群活動),會造成 hot spots——某個 reducer 負載遠超其他。處理策略包括:
- Pig 的 skewed join:先取樣找出 hot key,隨機分散到多個 reducer,另一側的資料複製到所有對應 reducer
- Hive 的 skewed join optimization:在 metadata 中標記 hot key,對其使用 map-side join
- 兩階段聚合:第一階段隨機分散做局部聚合,第二階段合併局部結果
Map-Side Joins#
Reduce-side join 不需對輸入資料做任何假設,但排序、複製和合併的代價很高。若能對輸入做某些假設,map-side join 可以大幅加速——它是一種「砍掉」reducer 和 sorting 的精簡 MapReduce job。
Broadcast Hash Join#
當一個大資料集與一個 小到能放進記憶體 的資料集做 join 時:
- 每個 mapper 啟動時先將小資料集載入 in-memory hash table
- 然後掃描大資料集的每筆記錄,直接在 hash table 中查找
稱為 broadcast hash join:「broadcast」指小資料集被廣播到所有 partition,「hash」指使用 hash table。在 Pig 中稱為 replicated join,在 Hive 中稱為 MapJoin。
Partitioned Hash Join#
若兩側輸入以 相同方式分區(相同 key、相同 hash function、相同 partition 數),則每個 mapper 只需載入對應 partition 的小資料集到 hash table,大幅減少記憶體需求。在 Hive 中稱為 bucketed map join。
Map-Side Merge Join#
若兩側輸入不僅以相同方式分區,還按 相同 key 排序,mapper 可以像 reducer 一樣做 merge 操作——按升序增量讀取兩個輸入檔,匹配相同 key 的記錄。不要求資料能放進記憶體。
Map-Side Join 對工作流的影響#
Reduce-side join 的輸出按 join key 分區和排序,map-side join 的輸出則按 大輸入 的方式分區和排序。了解資料集的物理佈局對於優化 join 策略非常重要,在 Hadoop 生態系統中,這類 metadata 由 HCatalog 和 Hive metastore 維護。
批處理工作流的輸出#
批處理產出的不是報表,而是某種 結構化資料。常見的輸出用途包括:
建立搜尋索引#
Google 最初使用 MapReduce 就是為了建立搜尋索引。Mapper 將文件集按需分區,每個 reducer 為其 partition 建立索引檔並寫入分散式檔案系統。這種 document-partitioned index 天然適合平行化。文件集變更時,可定期重跑整個索引工作流,以新索引檔整批替換舊索引檔。
Key-Value Store 作為批處理輸出#
批處理常用於建立機器學習模型或推薦系統的資料庫。不要 在 mapper/reducer 中直接寫入線上資料庫——這既慢又可能壓垮資料庫、且破壞 all-or-nothing 保證。
正確做法是在批處理 job 中建立全新的 唯讀資料庫檔案,寫入分散式檔案系統,再批次載入到查詢服務中。伺服器在複製完新檔案後 原子性地切換 到新資料,失敗時可回退。
批處理輸出的哲學#
與 Unix 哲學一脈相承:輸入不可變、輸出完整替換、無副作用。這帶來:
- 可回滾性:程式碼有 bug 時,修正後重跑即可恢復正確輸出
- 快速迭代:最小化不可逆操作,有利於 Agile 開發
- 自動重試:因為輸入不可變,失敗的 task 可安全重新執行
- 可監控:同一組輸入檔可被多個 job 使用,包括計算指標的監控 job
Hadoop 與分散式資料庫的比較#
MapReduce 本質上是一個分散式版的 Unix——HDFS 是檔案系統,MapReduce 是在 map 和 reduce 之間強制排序的處理器。它與 MPP(Massively Parallel Processing)資料庫 的差異體現在幾個面向:
儲存的多樣性#
MPP 資料庫要求資料事先建模、匯入專有格式;HDFS 上的檔案可以是任何格式。Hadoop 奉行 「先收集,後整理」 的策略——資料先以原始形式傾倒入 HDFS(即 data lake),之後再決定如何處理。這種 schema-on-read 方式讓資料收集更快速。
處理模型的多樣性#
MPP 資料庫是整合度高的單體系統,專為 SQL 分析查詢而優化。但並非所有處理都能表達為 SQL(如機器學習、全文搜尋、影像分析)。Hadoop 的開放平台允許在同一叢集上執行多種處理模型——MapReduce、HBase(OLTP)、Impala(分析)等共存共用 HDFS。
容錯設計的差異#
- MPP 資料庫:某節點當機時中止整個查詢並重跑。查詢通常只需數秒到數分鐘,重跑代價可接受。傾向將資料保持在記憶體中。
- MapReduce:以 task 為粒度 進行容錯——個別 task 失敗只需重跑該 task。頻繁寫入磁碟。
MapReduce 之所以設計為頻繁容錯,不是因為硬體特別不可靠,而是因為 Google 的混合使用資料中心允許高優先級任務 搶占(preempt) 低優先級批處理任務的資源。在 Google,一個運行一小時的 MapReduce task 有約 5% 的機率被終止。這種設計讓批處理能利用叢集的「剩餘資源」。
超越 MapReduce#
MapReduce 是一個清晰的抽象,但直接使用其 API 非常繁瑣。更重要的是,MapReduce 執行模型本身有幾個根本性問題。
中間狀態物化的問題#
MapReduce 將每個 job 的輸出完整寫入分散式檔案系統(物化),與 Unix 管線的增量串流形成對比。這導致:
- 必須等前一個 job 的所有 task 完成 才能開始下一個 job(straggler 問題放大)
- Mapper 常是多餘的——只是讀取前一個 reducer 的輸出再重新分區排序
- 中間狀態被複製到多個節點——對臨時資料而言是過度設計
資料流引擎(Dataflow Engines)#
為解決上述問題,Spark、Tez、Flink 等資料流引擎應運而生。它們的共同特點是將整個工作流視為 一個 job,而非多個獨立 job。
這些引擎中的處理函式稱為 operator,可以更靈活地組合(不必嚴格交替 map 和 reduce)。連接 operator 輸出到輸入的方式包括:
- Repartition and sort(如同 MapReduce 的 shuffle)
- Repartition without sorting(適用於 partitioned hash join)
- Broadcast(適用於 broadcast hash join)
相較於 MapReduce 的優勢:
- 排序 只在需要時才執行
- 沒有不必要的 mapper 階段
- Scheduler 能做 locality optimization——盡量讓消費者與生產者在同一台機器上
- 中間狀態可保持在 記憶體或本地磁碟,無需寫入 HDFS
- Operator 在輸入就緒時 立即開始執行
- 可 重用 JVM process 執行新 operator
資料流引擎的容錯#
MapReduce 靠中間狀態寫入 HDFS 來容錯。資料流引擎則避免寫入 HDFS,改以 重新計算 的方式容錯:
- Spark 使用 RDD(Resilient Distributed Dataset) 追蹤資料的血統(lineage)——記錄每筆資料是從哪些輸入、經過哪些 operator 計算而來
- Flink 使用 operator state checkpointing,允許從失敗點恢復執行
重新計算的前提是 確定性(determinism):給定相同輸入,operator 必須產出相同輸出。非確定性行為(hash table 迭代順序、隨機數、系統時鐘等)需要被消除。
若中間資料遠小於源資料,或計算非常 CPU 密集,將中間資料物化到檔案可能比重新計算更經濟。這是一個需要權衡的設計決策。
物化的討論#
用 Unix 的類比:MapReduce 像是把每個命令的輸出寫入暫存檔,資料流引擎則更像 Unix 管線。Flink 尤其以 pipelined execution 為核心——增量地將 operator 輸出傳遞給下游,不必等待輸入完成。
最終,資料流引擎的輸入和輸出仍然是 HDFS 上的物化資料集(不可變輸入、完整替換輸出),改善之處在於省去了中間狀態的物化。
圖處理(Graph Processing)#
在批處理場景中,目標是對 整個圖(entire graph) 進行離線分析,例如 PageRank 演算法。許多圖演算法需要反覆遍歷邊、在頂點間傳播資訊,直到某個條件收斂——這種「重複直到完成」的模式無法用單次 MapReduce pass 表達。
Pregel 模型(BSP)#
Pregel 是 Google 提出的圖處理模型,基於 Bulk Synchronous Parallel(BSP) 計算模型。其核心思想:
- 每個頂點(vertex)可以向其他頂點(通常沿著邊)發送訊息
- 每次迭代,框架對每個頂點呼叫一個函式,傳入上一輪發送給它的所有訊息
- 與 MapReduce 不同,頂點在迭代間 保持狀態於記憶體中——只需處理新收到的訊息
- 若圖的某部分沒有訊息傳遞,就不需要做任何工作
這有點類似 Actor 模型,但頂點狀態和訊息是持久且容錯的,通訊按固定輪次進行。
容錯與平行執行#
Pregel 透過定期 checkpoint 所有頂點狀態來實現容錯。若節點失敗,回滾整個圖計算到上一個 checkpoint。在平行執行方面,框架負責圖的分區和訊息路由,但找到最佳分區很困難,實務上通常以 vertex ID 任意分配,導致大量 跨機器通訊開銷。
如果你的圖能放進單台機器的記憶體,單機演算法很可能比分散式批處理更快。即使圖超出記憶體但能放進單機磁碟,GraphChi 等框架仍是可行選項。只有當圖大到無法放進單機時,分散式的 Pregel 才有必要。
高階 API 與宣告式查詢優化#
隨著分散式批處理基礎設施的成熟,焦點轉向改善 程式設計模型 和 處理效率。
高階語言與 API#
Hive、Pig、Cascading、Crunch 等高階工具基於關聯式風格的建構區塊——join、group by、filter、aggregate——讓批處理程式撰寫更簡潔。它們還能無縫切換底層執行引擎(從 MapReduce 到 Tez 或 Spark),無需修改程式碼。
走向宣告式查詢#
以 宣告式(declarative) 方式指定 join,讓框架的 cost-based query optimizer 自動選擇最佳 join 演算法。Hive、Spark、Flink 都具備這樣的優化器,甚至能重新排列 join 順序以最小化中間狀態。
同時,資料流引擎也融合更多宣告式特性:對簡單 filter/map 操作避免逐筆呼叫 callback 的 CPU 開銷、利用 column-oriented storage 只讀取所需欄位、使用 vectorized execution 在 CPU cache 友好的緊湊迴圈中迭代資料(Spark 生成 JVM bytecode,Impala 使用 LLVM 生成 native code)。如此一來,批處理框架在效能上開始接近 MPP 資料庫,同時保有執行任意程式碼的彈性。
各領域的特化#
除了商業智慧分析,批處理也廣泛應用於機器學習(Mahout、MADlib)、空間演算法(k-nearest neighbors)、基因組分析等。隨著批處理系統獲得更多內建功能和高階宣告式運算子,MPP 資料庫也變得更具可程式性和彈性——兩者正日漸趨同。
本章總結#
批處理的核心設計原則承襲自 Unix:輸入不可變、輸出供未知程式使用、透過組合小工具解決複雜問題。分散式批處理框架需要解決兩大問題:
分區(Partitioning):
- MapReduce 中,mapper 按輸入檔案區塊分區,輸出經重新分區、排序、合併送入 reducer
- 後 MapReduce 的資料流引擎盡量避免不必要的排序
容錯(Fault Tolerance):
- MapReduce 頻繁寫入磁碟——容易恢復但在無故障時較慢
- 資料流引擎將更多狀態保持在記憶體中——故障時需要重新計算更多資料
三種 Join 演算法的比較:
| 演算法 | 說明 |
|---|---|
| Sort-merge join | 兩邊輸入都經由 mapper 提取 join key,排序後在 reducer 中合併 |
| Broadcast hash join | 小資料集載入 hash table 廣播給所有 mapper |
| Partitioned hash join | 兩邊以相同方式分區,每個 partition 獨立做 hash join |
批處理 job 的關鍵特徵是輸入 有界(bounded)——大小已知且固定,job 知道何時讀完所有輸入,最終會完成。下一章將轉向 串流處理(stream processing),其輸入是 無界的(unbounded)——job 永遠不會結束。