本章摘要: 比較按鍵範圍與按雜湊值兩種分片策略的效能取捨,討論次要索引在分片環境下的實作(本地索引 vs 全域索引)、重新平衡機制,以及請求路由與服務發現的常見做法。
本章探討分片(partitioning / sharding):當資料量或查詢吞吐量成長到單一節點無法負荷時,必須將資料拆分成多個較小的子集,分散到不同節點上處理。分片的核心目標是將資料與查詢負載均勻分佈到多台機器上,避免產生熱點(hot spot)。本章涵蓋分片策略、與次要索引的交互、重新平衡機制,以及請求路由等關鍵議題。
不同系統對「分片」的稱呼不同:MongoDB、Elasticsearch 稱之為 shard;HBase 稱為 region;Bigtable 稱為 tablet;Cassandra 與 Riak 稱為 vnode;Couchbase 稱為 vBucket。本書統一使用 partition 一詞,中文筆記中則使用「分片」。
分片與複製#
分片通常會與複製(replication)搭配使用。每筆資料只屬於一個分片,但該分片可以被複製到多個節點上以提供容錯能力。如果使用 leader-follower 複製模型,每個節點可能同時扮演某些分片的 leader 和其他分片的 follower。
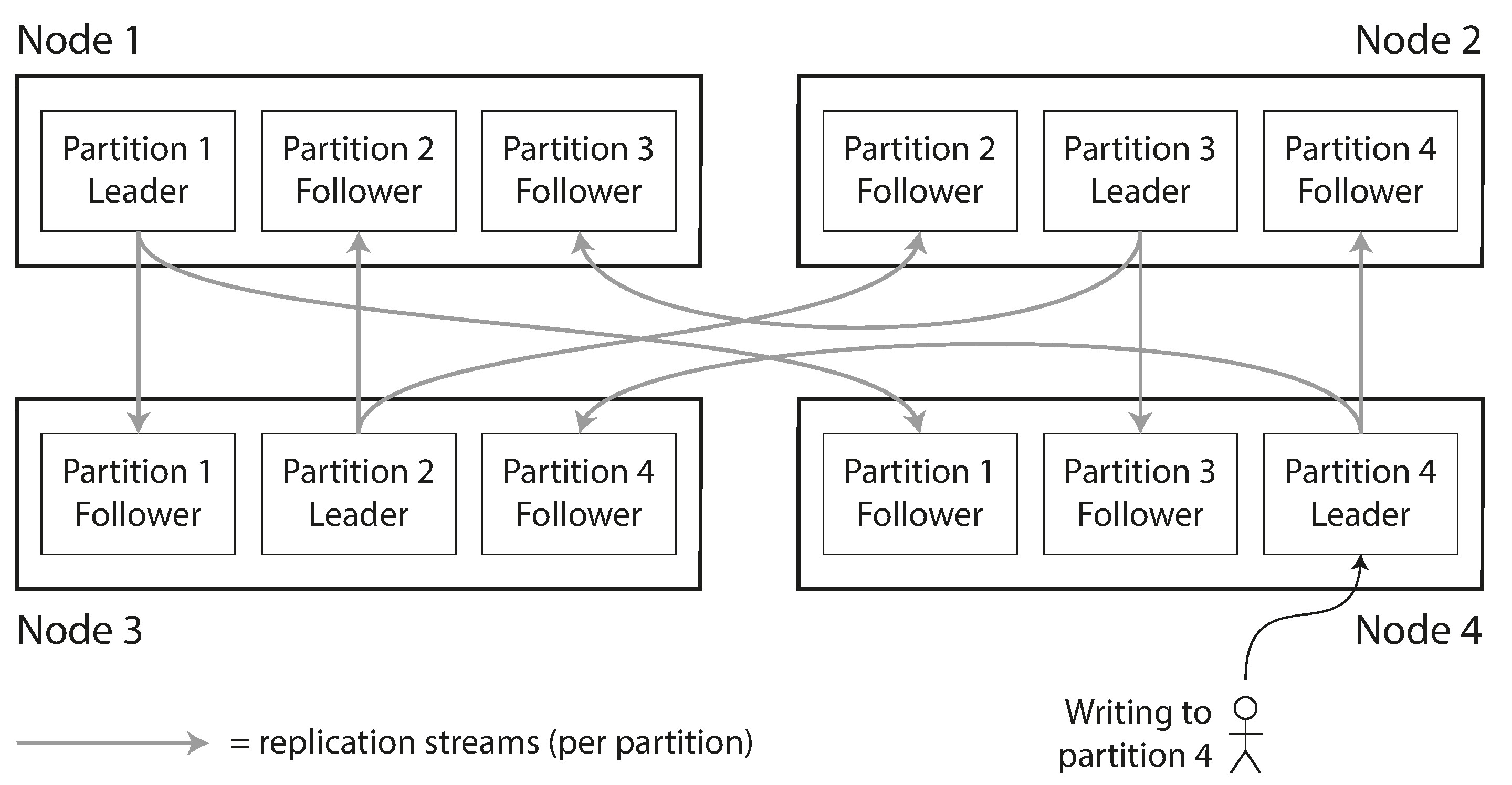
Figure 6-1: 結合複製與分片:每個節點同時是某些分片的 leader 和其他分片的 follower
分片方案的選擇與複製方案的選擇大致上是彼此獨立的。本章為了簡化討論,主要聚焦於分片本身。
鍵值資料的分片策略#
假設資料是簡單的鍵值模型,總是透過主鍵存取。分片的目標是讓資料與查詢負載均勻分佈到各節點上。如果分佈不均,稱為偏斜(skewed),而負載過度集中的分片就是熱點(hot spot)。
最簡單的方式是隨機分配,但這會導致讀取時不知道資料在哪個節點,必須查詢所有節點。因此需要更聰明的策略。
按鍵範圍分片#
按鍵範圍分片(key range partitioning)為每個分片分配一段連續的鍵範圍。就像百科全書按照字母順序分冊一樣——知道鍵的範圍邊界,就能直接定位到正確的分片。

Figure 6-2: 印刷百科全書按鍵範圍分片
這種方式的關鍵特性:
- 範圍邊界不必均勻分佈:因為資料分佈本身可能不均勻,邊界需要根據實際資料量來調整
- 範圍邊界的選擇可以是手動設定,也可以由資料庫自動決定
- 分片內的鍵可以保持排序,使得範圍查詢(range scan)非常高效
- 採用此策略的系統包括 Bigtable、HBase、RethinkDB,以及 MongoDB 2.4 之前的版本
按鍵範圍分片容易產生熱點。典型案例:如果鍵是時間戳記,所有寫入都會集中到「今天」的分片上。解法是在時間戳記前加上其他前綴(如感測器名稱),先按前綴分片,再按時間排序。
按鍵的雜湊值分片#
按雜湊值分片(hash partitioning)使用雜湊函數將鍵映射到一個數值範圍,再根據雜湊值的範圍分配到不同分片。即使輸入的鍵非常相似,雜湊函數也能讓它們均勻分佈。
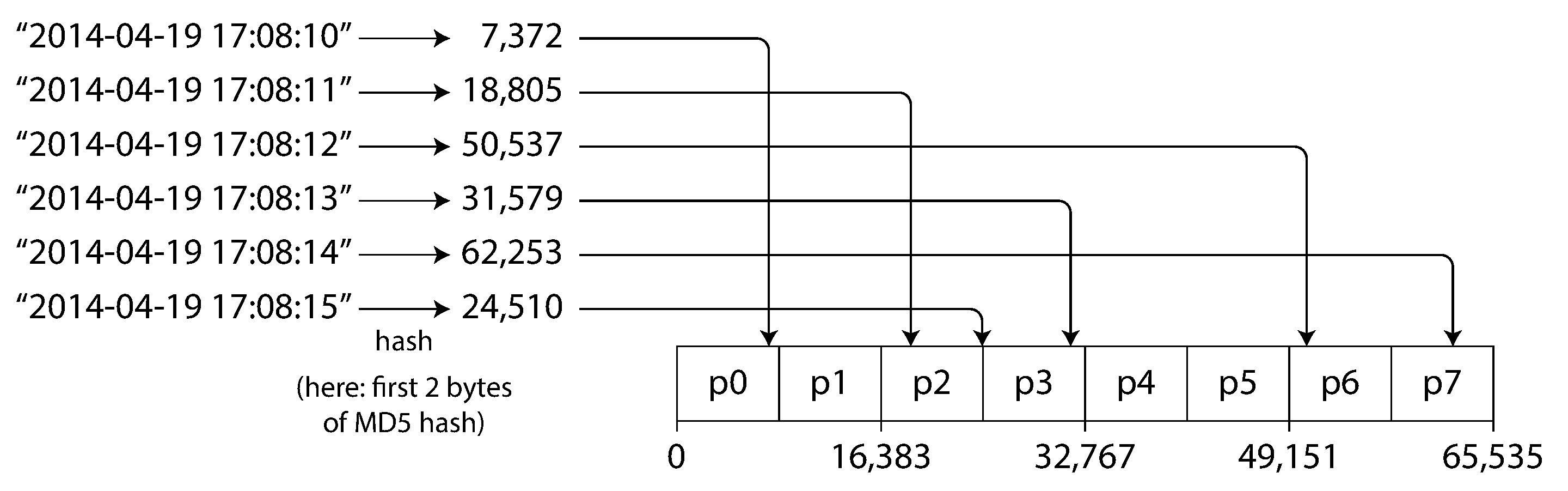
Figure 6-3: 按鍵的雜湊值分片
幾個實務上的注意事項:
- 雜湊函數不需要密碼學等級的強度。Cassandra 和 MongoDB 使用 MD5,Voldemort 使用 Fowler-Noll-Vo 函數
- 不能使用程式語言內建的雜湊函數做分片——例如 Java 的
hashCode()在不同 process 中可能對相同的鍵回傳不同值 - 雜湊分片的代價是失去了範圍查詢的能力。鍵的排序關係被打散,範圍查詢必須送往所有分片
一致性雜湊(consistent hashing)這個名詞常被混用。原始定義是 Karger 等人提出的一種用於 CDN 的負載分散方法。但實際上這種方法對資料庫並不好用,因此多數資料庫採用的是更簡單的雜湊分片策略。為避免混淆,書中建議直接稱之為「雜湊分片」。
Cassandra 的折衷方案#
Cassandra 提供了一個巧妙的折衷做法:使用複合主鍵(compound primary key)。第一部分的鍵用於雜湊分片,決定資料落在哪個分片;其餘部分的鍵則作為排序索引,在分片內部保持有序。
舉例來說,社群媒體中的更新動態可以使用 (user_id, update_timestamp) 作為主鍵。user_id 決定分片位置,而同一使用者的所有更新動態則在該分片內按 update_timestamp 排序。這樣既能均勻分佈不同使用者的資料,又能對單一使用者進行高效的時間範圍查詢。
偏斜的工作負載與熱點緩解#
即使使用雜湊分片,也無法完全避免熱點。極端案例如名人效應:某位擁有百萬粉絲的名人發了一則動態,所有對該動態的讀寫都指向同一個鍵,集中在同一個分片上。
目前多數系統無法自動處理這類高度偏斜的工作負載,需要由應用層來緩解。常見技巧是在熱門鍵的開頭或結尾附加隨機數字(例如兩位數的隨機數),將寫入分散到 100 個不同的鍵上。但代價是讀取時必須從這 100 個鍵彙整資料,且需要額外的簿記機制來追蹤哪些鍵需要拆分。
分片與次要索引#
前述的分片策略都基於鍵值模型——透過主鍵直接定位分片。但當涉及次要索引(secondary index)時,情況變得更加複雜。次要索引不是用來唯一標識一筆記錄,而是用來搜尋特定值的出現(例如:查詢所有紅色的車、查詢某個使用者的所有操作)。
次要索引是關聯式資料庫和搜尋引擎(如 Elasticsearch、Solr)的核心功能,但它無法自然地對應到分片結構。處理方式有兩種:按文件分片和按詞彙分片。
按文件分片的次要索引(本地索引)#
在這種方式中,每個分片獨立維護自己的次要索引,只涵蓋該分片內的文件。
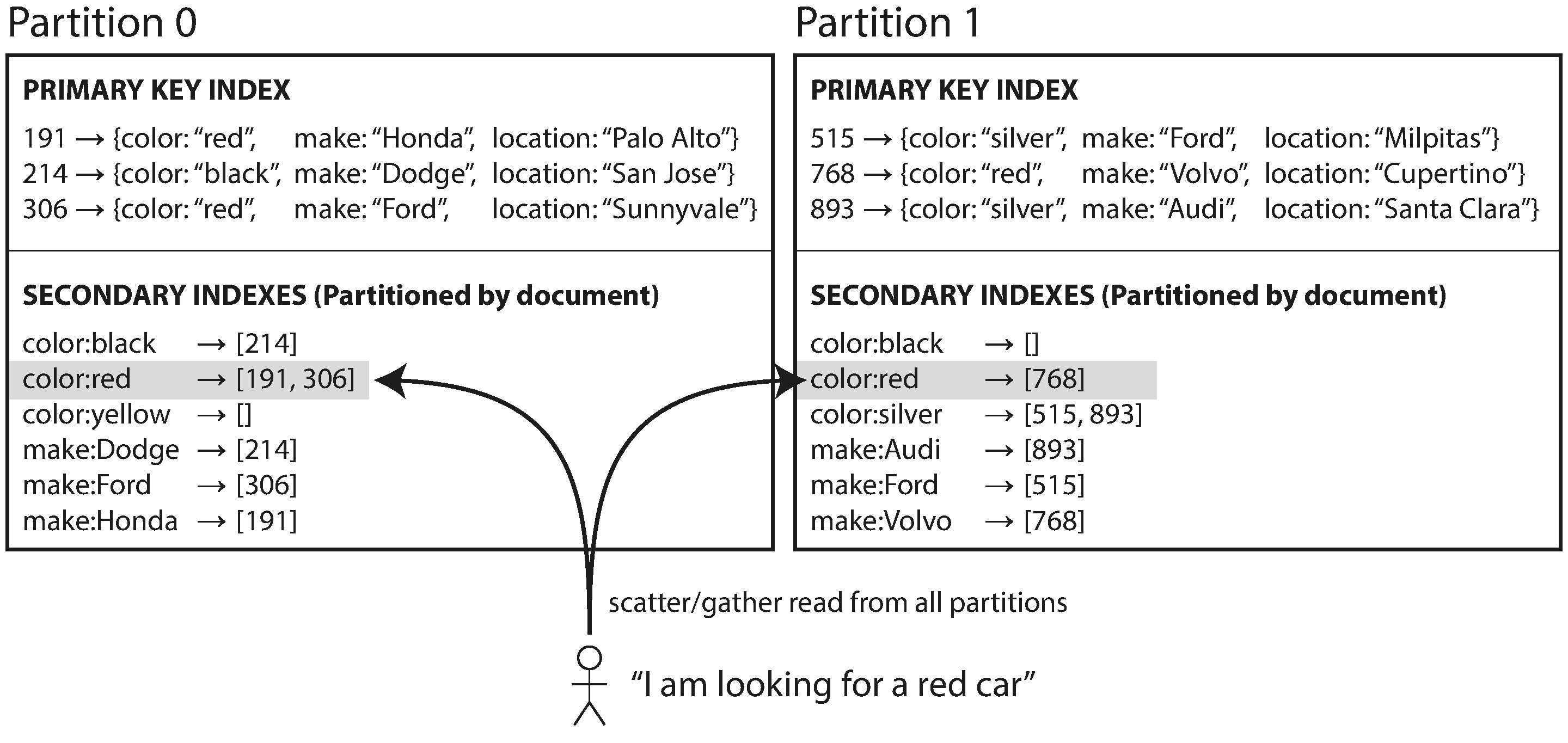
Figure 6-4: 按文件分片的次要索引
以二手車網站為例,資料庫按文件 ID 分片,每個分片都各自建立 color 和 make 的次要索引。寫入時只需更新該文件所在分片的索引,因此也稱為本地索引(local index)。
但讀取時就麻煩了:紅色的車可能散佈在任何分片上。要查詢所有紅色的車,必須向所有分片發送查詢,再彙整結果。這種模式稱為 scatter/gather,效能上容易受到尾端延遲放大(tail latency amplification)的影響。
儘管如此,scatter/gather 是實務中最廣泛使用的做法。MongoDB、Riak、Cassandra、Elasticsearch、SolrCloud、VoltDB 都採用按文件分片的次要索引。
按詞彙分片的次要索引(全域索引)#
另一種做法是建構跨所有分片的全域索引(global index),但全域索引本身也需要分片——只是分片方式與主鍵的分片不同。
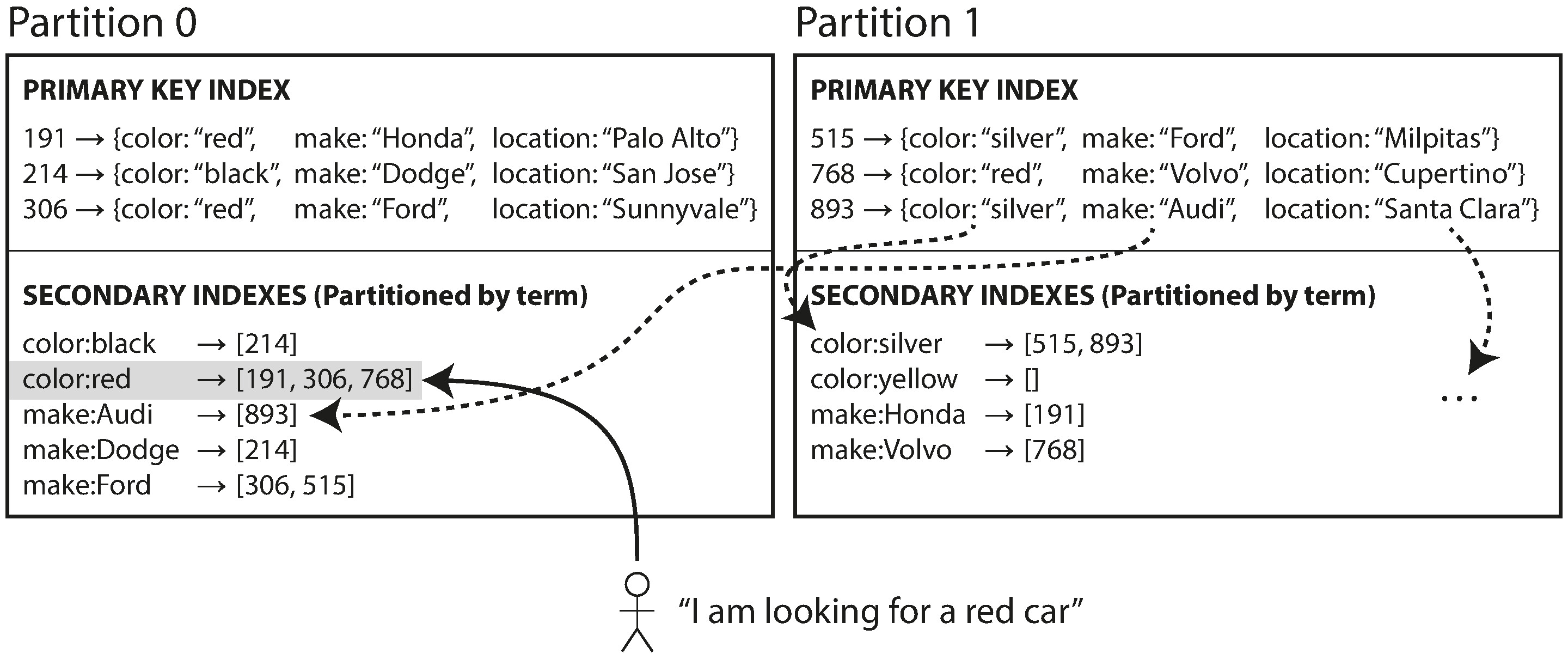
Figure 6-5: 按詞彙分片的次要索引
舉例來說,顏色索引中 a 到 r 開頭的顏色放在分片 0,s 到 z 開頭的顏色放在分片 1。所有分片中的紅色車都會出現在 color:red 這個索引項目下,而這個索引項目只存在於特定的索引分片中。
這種索引稱為詞彙分片索引(term-partitioned index),因為是由查詢的詞彙(term)來決定要查哪個索引分片。索引分片的方式可以按詞彙本身(有利於範圍查詢)或按詞彙的雜湊值(負載更均勻)。
讀取效率較高:只需查詢包含目標詞彙的那個索引分片,不需要 scatter/gather。但寫入較慢且複雜:寫入一筆文件可能需要更新多個索引分片(因為文件中的不同詞彙可能分佈在不同索引分片上)。
在實務中,全域次要索引的更新通常是非同步的。例如 Amazon DynamoDB 的全域次要索引在正常情況下幾分之一秒內更新,但在基礎設施故障時可能有較長的延遲。
重新平衡分片#
隨著時間推移,資料庫叢集會面臨各種變化:查詢吞吐量增加需要更多 CPU、資料量增加需要更多磁碟與記憶體、機器故障需要其他節點接手。這些情境都需要將資料和請求從一個節點搬移到另一個節點,這個過程稱為重新平衡(rebalancing)。
重新平衡應滿足的基本要求:
- 平衡後,負載應在各節點間公平分配
- 重新平衡過程中,資料庫應持續接受讀寫
- 搬移的資料量應盡可能少,以降低網路與磁碟 I/O 負擔
錯誤示範:hash mod N#
直覺上可能會想用 hash(key) mod N 來分配資料(N 為節點數),但這是個糟糕的做法。當 N 改變時,幾乎所有的鍵都需要搬移。例如 hash(key) = 123456:10 個節點時在節點 6、11 個節點時在節點 3、12 個節點時在節點 0。大量的資料搬移讓這種方式完全不可行。
固定分片數#
較好的做法是一開始就建立遠多於節點數量的分片,然後把多個分片分配給每個節點。例如 10 個節點的叢集可以建立 1,000 個分片,每個節點約負責 100 個分片。
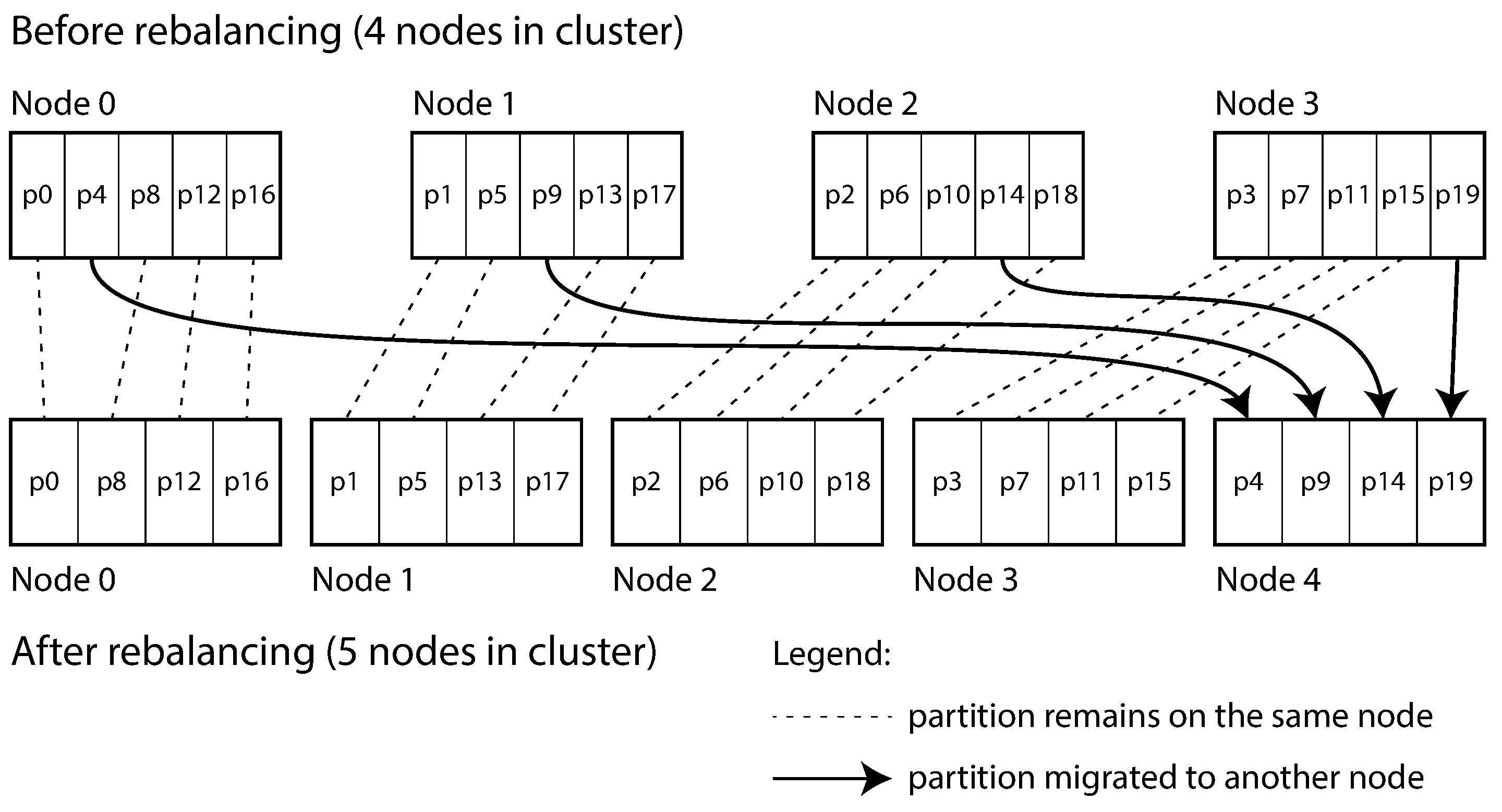
Figure 6-6: 新增節點到具有多分片的資料庫叢集
新增節點時,從現有節點「偷取」一些分片;移除節點時反向操作。關鍵在於:分片數量不變,鍵到分片的對應不變,改變的只是分片到節點的分配。Riak、Elasticsearch、Couchbase、Voldemort 都採用這種做法。
固定分片數的挑戰在於需要在初始化時選好分片數量。分片太少,日後無法支撐更多節點;分片太多,管理開銷過大。當資料集大小變化劇烈時,很難找到「剛剛好」的數量。
動態分片#
對於按鍵範圍分片的資料庫,固定分片數加上固定邊界會非常不方便。因此 HBase、RethinkDB 等系統採用動態分片:
- 當分片成長超過設定的大小(HBase 預設 10 GB),自動分裂為兩個分片
- 當分片因刪除而縮小到閾值以下,自動與相鄰分片合併
- 分片數量會隨資料量自動調節
動態分片的注意事項:空資料庫一開始只有一個分片,所有寫入都集中在單一節點。為解決此問題,HBase 和 MongoDB 允許設定預分片(pre-splitting),在空資料庫上預先建立多個分片。
動態分片不僅適用於鍵範圍分片,也適用於雜湊分片。MongoDB 自 2.4 版起同時支援這兩種分片策略的動態分片。
按節點比例分片#
第三種策略是讓分片數量與節點數量成正比,即每個節點持有固定數量的分片。Cassandra 預設為每個節點 256 個分片。
- 資料量成長但節點數不變時,每個分片會變大
- 新增節點時,隨機選擇現有分片進行分裂,取走一半的資料,分片隨之變小
- 隨機分裂可能不夠均勻,但在大量分片的平均效果下趨於公平
這種策略需要搭配雜湊分片使用,因為分裂邊界是從雜湊值的數值範圍中隨機挑選的。
自動 vs 手動重新平衡#
重新平衡可以是全自動的,也可以是手動的,實務上多數系統採取半自動做法:系統自動產生建議的分片分配方案,但需要管理員確認後才生效(如 Couchbase、Riak、Voldemort)。
全自動重新平衡與自動故障偵測結合時可能造成危險。例如某個節點暫時過載而回應緩慢,其他節點誤判它已失效並啟動重新平衡,結果把更多負載加到已經超載的節點與網路上,引發連鎖故障(cascading failure)。因此,讓人類參與重新平衡的決策流程是有價值的。
請求路由#
資料分散在多個節點上之後,客戶端如何知道要連接哪個節點?這是服務發現(service discovery)的一個具體案例。有三種主要做法:
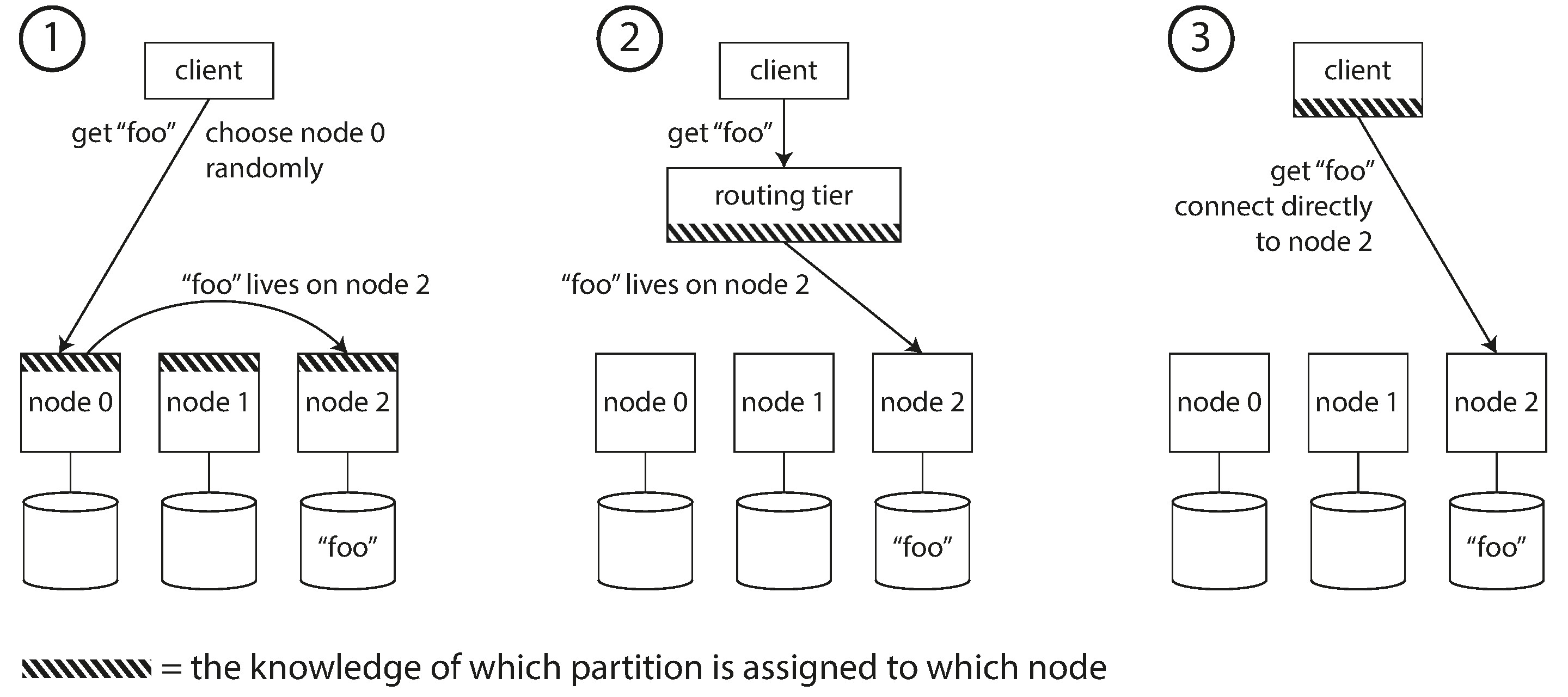
Figure 6-7: 三種將請求路由到正確節點的方式
| 方式 | 說明 |
|---|---|
| 方式一:任意節點轉發 | 客戶端可以連接任何節點。如果該節點恰好擁有對應的分片就直接處理,否則將請求轉發到正確的節點 |
| 方式二:路由層 | 所有請求先經過一個路由層(routing tier),由它判斷應該交給哪個節點處理。路由層本身不處理資料,只做分片感知的負載平衡 |
| 方式三:客戶端感知 | 客戶端自行維護分片到節點的對應關係,直接連接正確的節點 |
三種方式的核心問題都是一樣的:做路由決策的那個元件(無論是節點、路由層或客戶端),如何得知分片到節點的對應關係變化?
ZooKeeper 的角色#
許多分散式系統使用獨立的協調服務(coordination service)如 ZooKeeper 來管理叢集的後設資料。
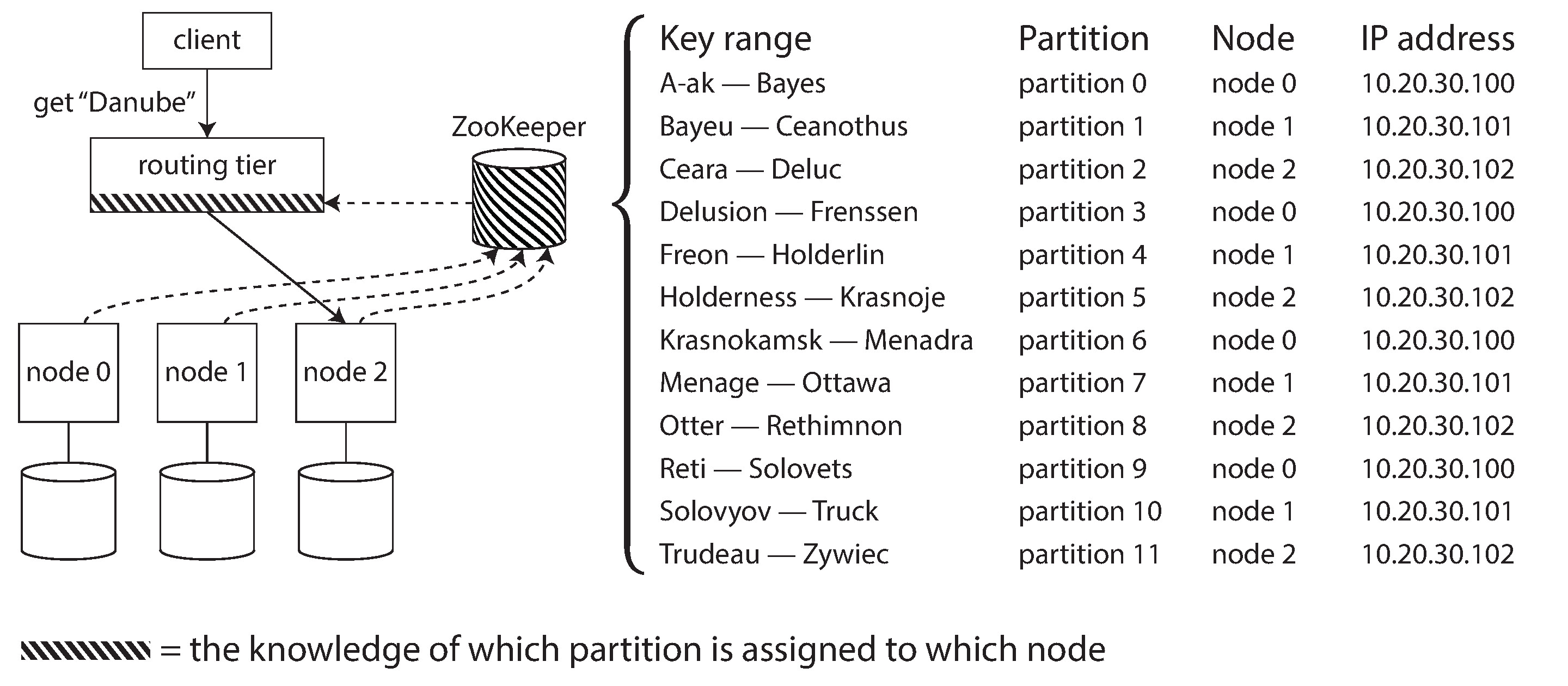
Figure 6-8: 使用 ZooKeeper 追蹤分片到節點的分配
運作方式如下:
- 每個節點在 ZooKeeper 中註冊自己
- ZooKeeper 維護分片到節點的權威對應(authoritative mapping)
- 路由層或客戶端訂閱 ZooKeeper 中的資訊
- 當分片的擁有者變更或節點增減時,ZooKeeper 通知所有訂閱者更新路由資訊
採用 ZooKeeper 的系統包括:LinkedIn 的 Espresso(透過 Helix)、HBase、SolrCloud、Kafka。MongoDB 則使用自己的 config server 實作和 mongos 作為路由層。
不依賴 ZooKeeper 的做法#
Cassandra 和 Riak 採用八卦協定(gossip protocol),節點之間彼此傳播叢集狀態的變化。請求可以發送到任何節點,由該節點轉發到正確的分片擁有者(即方式一)。這種做法避免了對外部協調服務的依賴,但增加了資料庫節點本身的複雜度。
至於客戶端一開始需要連接哪些 IP 位址,由於這個資訊的變化頻率遠低於分片對應關係,通常使用 DNS 即可。
平行查詢執行#
本章聚焦於單一鍵的讀寫查詢,這是多數 NoSQL 分散式資料庫所支援的存取層級。但大規模平行處理(MPP)的關聯式資料庫在分析型查詢上更為複雜:MPP 查詢最佳化器會將複雜查詢拆解為多個執行階段,分散到不同節點上平行執行。涉及大量資料掃描的查詢從這種平行執行中獲益最大。
小結#
本章探討了將大型資料集分割成較小子集的各種策略:
- 兩種主要分片策略:
- 按鍵範圍分片:鍵保持排序,範圍查詢高效,但容易產生熱點。通常搭配動態分片
- 按雜湊值分片:負載分佈較均勻,但失去範圍查詢能力。通常搭配固定分片數
- 也可採用混合方式,如 Cassandra 的複合主鍵
- 次要索引與分片的交互:
- 按文件分片(本地索引):寫入只涉及單一分片,但讀取需要 scatter/gather
- 按詞彙分片(全域索引):讀取高效,但寫入需更新多個分片,且通常是非同步的
- 重新平衡策略:固定分片數、動態分片、按節點比例分片,各有適用場景
- 請求路由:透過節點轉發、路由層或客戶端感知來定位正確的分片,ZooKeeper 等協調服務在其中扮演關鍵角色
分片的設計原則是讓每個分片盡可能獨立運作,這正是分片資料庫能水平擴展的基礎。然而,需要跨多個分片寫入的操作(例如一次寫入成功、另一次失敗時該如何處理)會帶來額外的複雜性——這將是後續章節的主題。