本章摘要: 從線性一致性出發,揭示順序保證、全序廣播與共識問題之間的等價關係。分析兩階段提交的阻塞風險與 Raft/Paxos 等容錯共識演算法,並介紹 ZooKeeper 如何將共識封裝為實用的分散式原語。
分散式系統中各種問題都可能發生:封包遺失、延遲、節點當機、時鐘偏移。面對這些故障,最簡單的方式是讓整個服務失敗並顯示錯誤訊息,但這通常不可接受。我們需要找到能容錯(Fault-Tolerant)的演算法與協定,讓服務在部分元件故障時仍能正確運作。
關鍵的思路與第七章的交易一樣:找到通用的抽象層,提供有用的保證,實作一次後讓所有應用程式都能依賴。交易抽象隱藏了當機與競爭條件,本章探討的抽象則讓應用程式能忽略分散式系統的部分問題。其中最重要的抽象就是共識(Consensus)——讓所有節點對某件事達成一致。
本章的結構循序漸進:先探討線性一致性(最強的一致性保證)及其代價,再討論順序與因果關係作為替代方案,接著引出全序廣播,最後深入共識問題本身——包括兩階段提交的局限和容錯共識演算法的突破。最終我們會看到,這些看似不同的問題其實在根本上是等價的。
線性一致性(Linearizability)#
在最終一致性(Eventually Consistent)的資料庫中,如果同時向兩個不同的副本查詢同一筆資料,可能會得到不同的答案。這對使用者來說十分困惑。
線性一致性(也稱為原子一致性 Atomic Consistency、強一致性 Strong Consistency、即時一致性 Immediate Consistency 或 External Consistency)的核心思想是:讓系統看起來好像只有一份資料的副本,且所有操作都是原子性的。一旦新值寫入,所有後續讀取都必須看到新值。
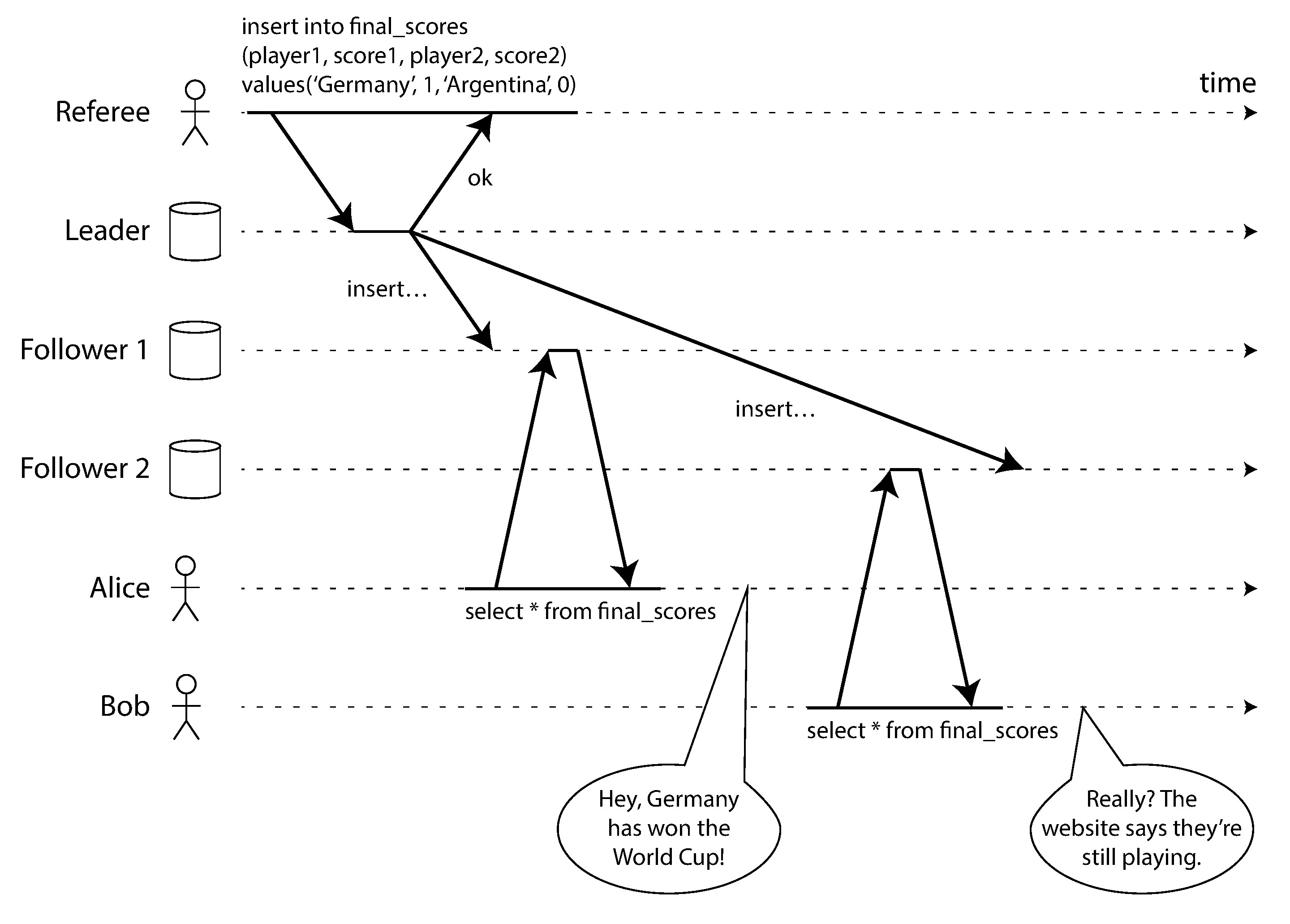
Figure 9-1: 非線性一致性系統導致球迷看到不同比分
以足球比賽為例:Alice 和 Bob 同時在手機上查看比分。Alice 看到比賽結束的最終比分,興奮地告訴旁邊的 Bob。Bob 重新整理自己的頁面,卻仍然顯示比賽進行中。這對 Bob 來說非常困惑——Alice 已經「看到了未來」,Bob 卻還停留在「過去」。如果資料庫是線性一致的,這種情況不會發生:一旦 Alice 的讀取返回了最終比分(代表該寫入已經「生效」),Bob 後續的讀取也必須返回最終比分。
什麼使系統具備線性一致性?#
線性一致性的基本要求可以用幾個讀寫場景來理解。考慮一個暫存器 x 的值從 0 被更新為 1 的過程:
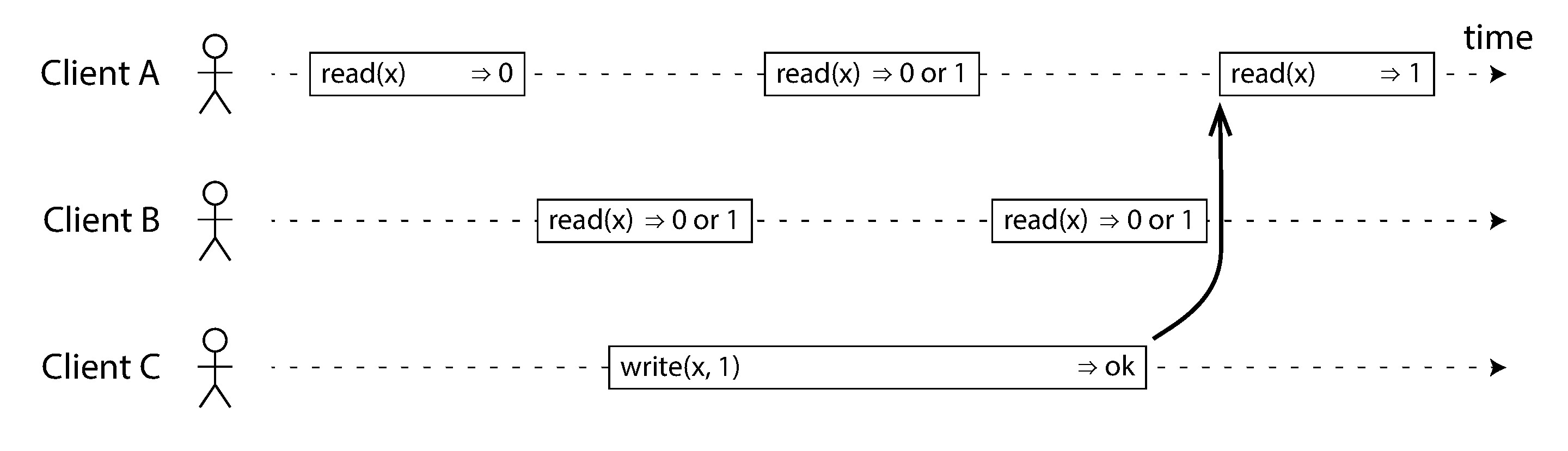
Figure 9-2: 讀取與寫入並行時可能返回舊值或新值
當讀取與寫入在時間上重疊時,讀取可能返回舊值 0 或新值 1——兩者都是合理的。但線性一致性加了一個關鍵約束:
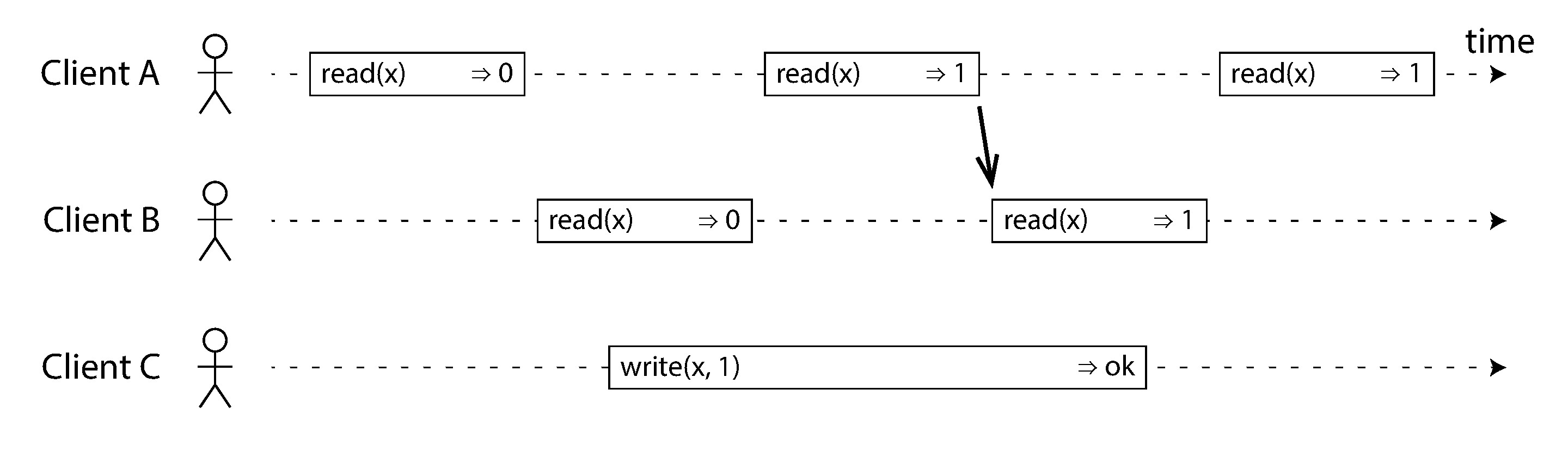
Figure 9-3: 任一讀取返回新值後,所有後續讀取必須返回新值
一旦某個讀取操作返回了新值,所有因果上在其之後的讀取(包括其他客戶端的讀取)都必須返回新值。不能「回到過去」看到舊值——這是線性一致性的核心要求。
更精確地說,線性一致性要求我們能為每個操作找到一個生效時間點(位於操作的呼叫與完成之間),使得所有操作按此時間點排序後,符合暫存器的順序讀寫語義。
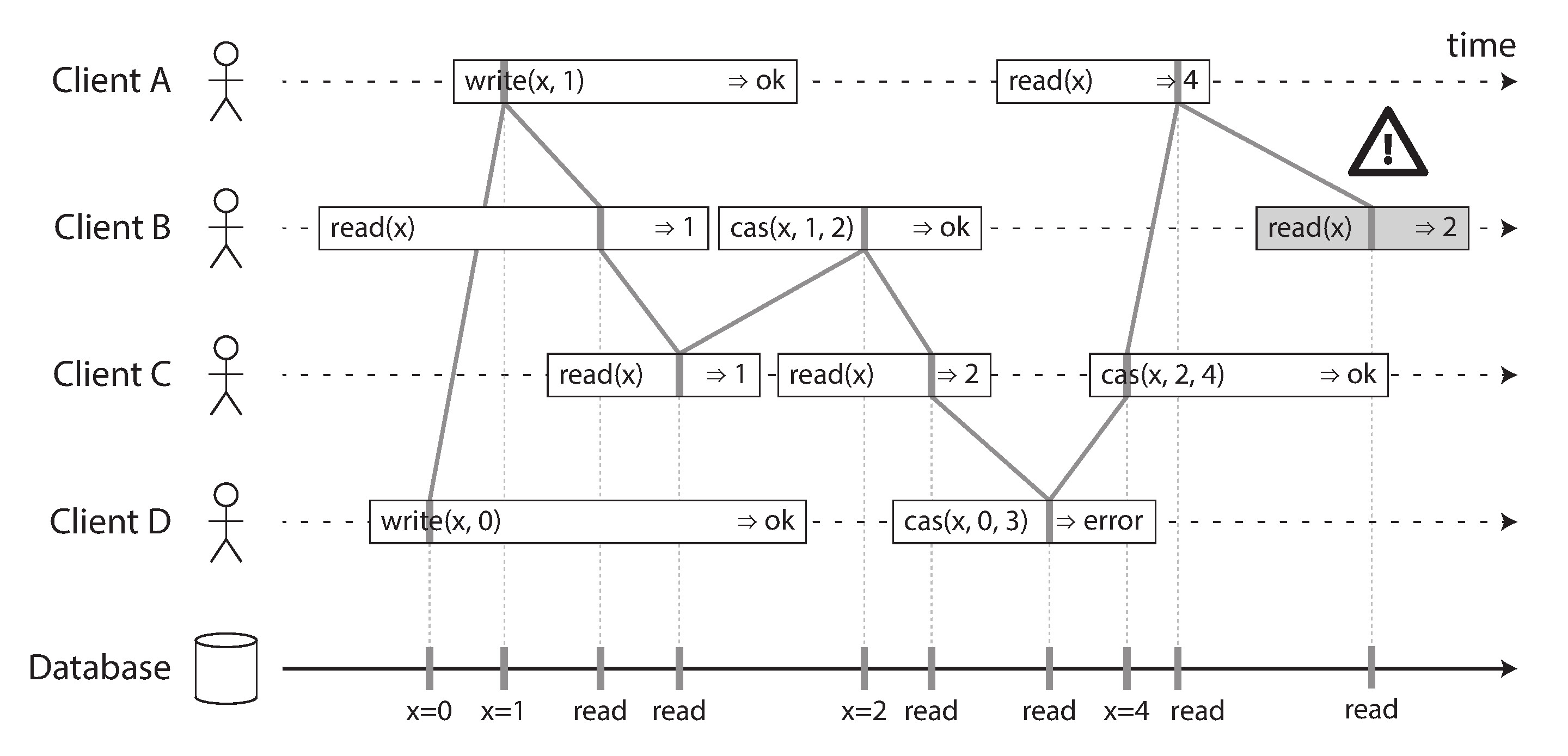
Figure 9-4: 視覺化讀寫操作看似生效的時間點
如果將每個操作的生效時間點用箭頭連起來,箭頭必須始終向右(時間前進方向)。如果能找到這樣一條合法的時間線,系統就是線性一致的;如果找不到(例如箭頭必須向左),就不是線性一致的。
線性一致性與可序列化(Serializability)是不同的概念,容易混淆。可序列化是交易的隔離屬性,保證多個交易的執行結果等同於某種順序執行;線性一致性是對單一物件讀寫的即時性保證,不涉及交易或分組操作。兩者可以組合為嚴格可序列化(Strict Serializability),即 strong one-copy serializability,例如實際序列化執行和兩階段鎖都提供此保證。
線性一致性的使用場景#
線性一致性不只是理論上的優雅特性,它在許多實務場景中不可或缺:
鎖與 Leader 選舉
單一 leader 複寫系統需要確保在任何時刻只有一個 leader。常見做法是使用鎖——每個節點啟動時嘗試取得鎖,成功取得者成為 leader。這個鎖必須是線性一致的:所有節點必須就「誰持有鎖」達成一致,否則可能出現腦裂(Split Brain),多個節點同時自認為是 leader。Apache ZooKeeper 和 etcd 等協調服務正是被用來實現分散式鎖和 leader 選舉——它們內部使用共識演算法來保證線性一致性。
唯一性約束
使用者名稱或 email 必須唯一、銀行帳戶餘額不能為負、同一座位不能賣給兩個人。這些約束本質上都需要線性一致性——當兩個人同時嘗試註冊同一個使用者名稱時,系統必須就「哪個請求先到」達成一致,確保只有一個成功。這與取得鎖的問題結構相同:都是一種 compare-and-set 操作。
跨通道的時序依賴
當系統有多個通訊管道時,線性一致性特別重要。
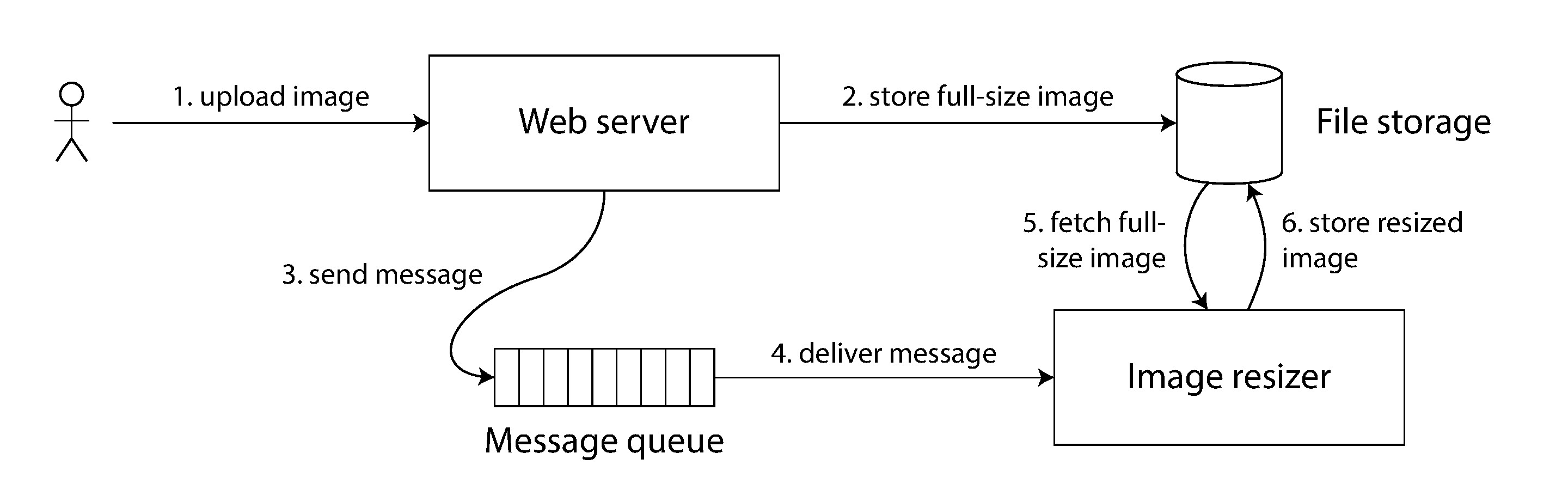
Figure 9-5: Web 伺服器與圖片縮放器透過檔案儲存和訊息佇列通訊
以圖片上傳為例:Web 伺服器將圖片寫入檔案儲存後,透過訊息佇列通知圖片縮放器處理。如果檔案儲存不是線性一致的,縮放器收到訊息後可能看到檔案的舊版本或空內容——因為訊息佇列的傳遞可能比檔案儲存的複寫更快。這裡的關鍵是存在兩個獨立的通道(檔案儲存和訊息佇列),缺乏線性一致性就可能導致競態條件。
實作線性一致性#
不同的複寫策略對線性一致性的支援程度差異極大:
| 複製策略 | 線性一致性 | 說明 |
|---|---|---|
| 單一 leader 複寫 | 可能 | 如果所有讀取都從 leader 讀取,或從同步更新的 follower 讀取,可能提供線性一致性。但若使用快照隔離(Snapshot Isolation)設計或在 failover 時意外選出落後的節點作為新 leader,就可能違反 |
| 共識演算法 | 是 | 類似單一 leader,但內建防止腦裂與過期副本的機制。ZooKeeper 和 etcd 正是這樣運作的 |
| Multi-leader 複寫 | 否 | 多個節點同時接受寫入並非同步複寫,會產生需要解決的衝突寫入。由於衝突解決是在事後進行的,系統無法保證即時看到最新值 |
| Leaderless 複寫 | 可能不是 | 即使使用嚴格 quorum(w + r > n),基於時鐘的 LWW 衝突解決策略、sloppy quorum 以及可變的網路延遲都可能破壞線性一致性 |
線性一致性與 Quorum#
直覺上,Dynamo 風格資料庫的嚴格 quorum 讀寫應該提供線性一致性。但在網路延遲不均勻的情況下,仍可能出現競態條件:
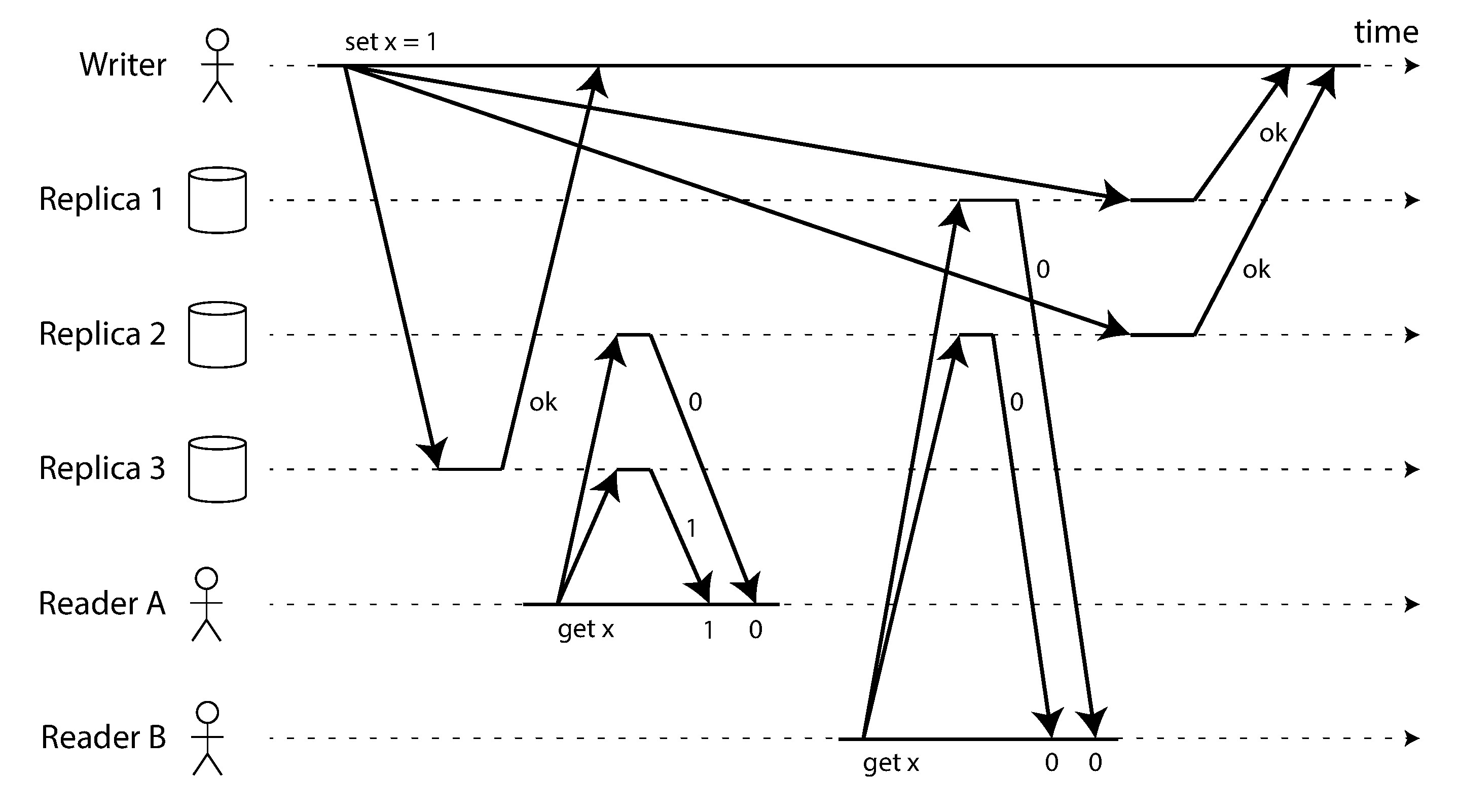
Figure 9-6: 即使使用嚴格 quorum 仍可能出現非線性一致性執行
設 x 初始值為 0,寫入者將 x 更新為 1 並寫入所有三個副本(n=3, w=3)。同時客戶端 A 從 quorum(r=2)讀到一個新值 1 和一個未更新的節點;客戶端 B 從不同的 quorum 讀到兩個舊值 0。quorum 條件滿足,但這個執行不是線性一致的——A 已經看到了 1,但在因果上之後的 B 卻看到 0。
理論上可以透過同步讀取修復(Read Repair)來解決——讀取者在返回值之前先將最新值寫回所有過期的節點,確保後續讀取者不會看到舊值。但這會犧牲效能,Riak 等系統選擇不這樣做。Cassandra 的基於時鐘的 LWW 衝突解決更是從根本上無法保證線性一致性,因為時鐘偏移意味著時間戳順序與實際因果順序可能不一致。
CAP 定理#
線性一致性的代價是什麼?考慮一個跨機房(Datacenter)部署的系統。如果兩個機房之間的網路中斷了:
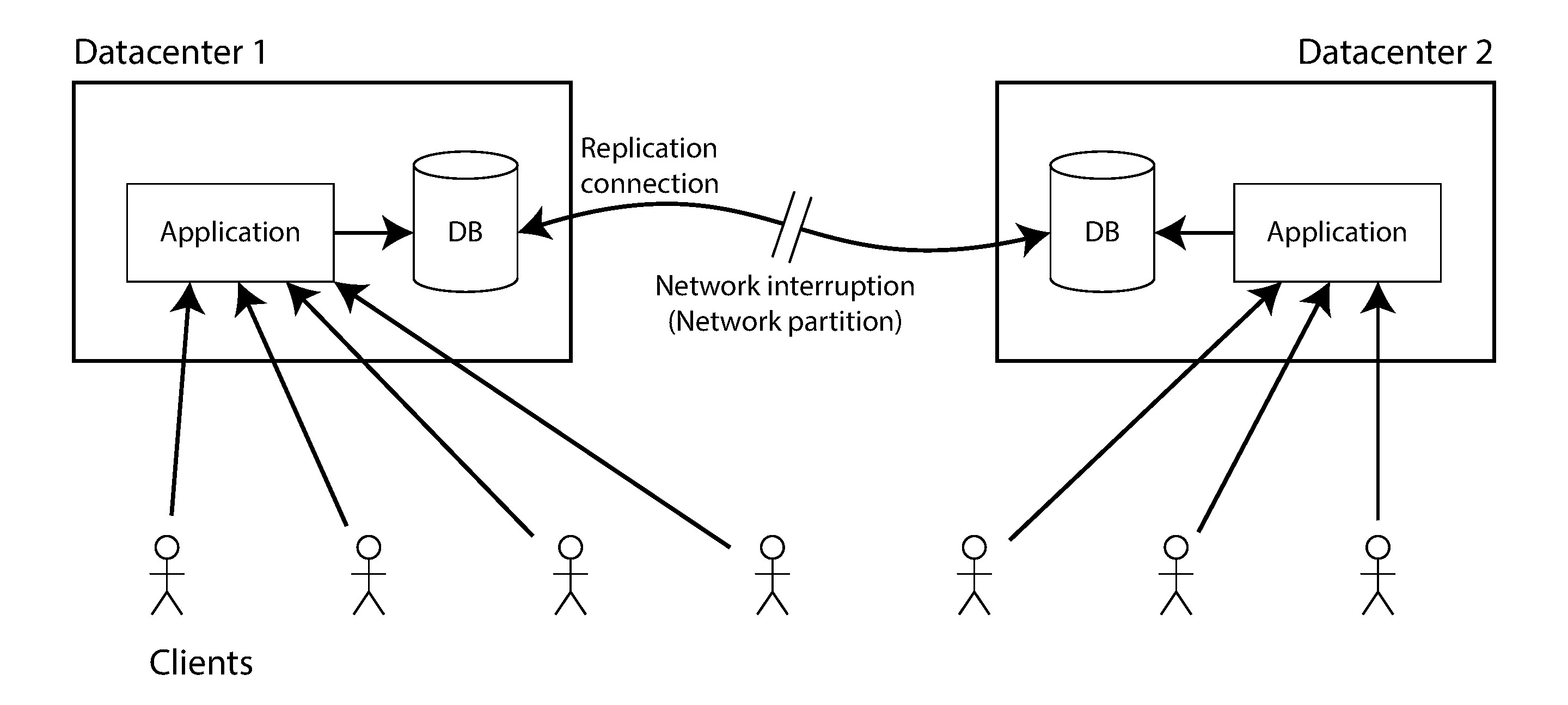
Figure 9-7: 網路中斷迫使在線性一致性與可用性之間抉擇
- 若要求線性一致性:連不到 leader 的機房必須停止接受寫入,甚至可能無法服務讀取,對該機房的客戶端來說服務不可用
- 若要求可用性:每個機房獨立處理請求,但兩邊的資料可能不一致,無法保證線性一致性
這就是 CAP 定理的核心:在網路分區(Network Partition)發生時,必須在一致性(線性一致性)和可用性之間二擇一。
CAP 定理被廣泛誤解為「三選二」,但更精確的表述是:當網路分區發生時,你必須在線性一致性與可用性之間做選擇。網路正常時可以同時擁有兩者。此外,CAP 中的 C 僅指線性一致性這一種特定的一致性模型,不涵蓋其他更弱的一致性保證。CAP 作為一個定理在學術上有嚴格的定義,但作為系統設計的指導原則,其範圍太窄,實用性有限。
即使沒有網路分區,線性一致性也有效能代價。Attiya 和 Welch 的研究證明:如果要求線性一致性,讀寫的回應時間至少與網路延遲成正比。這不是特定實作的限制,而是根本性的數學結論。
對延遲敏感的系統因此常選擇放棄線性一致性——甚至現代多核 CPU 的 RAM 也不提供線性一致性,因為每次寫入都要同步到所有核心的快取代價太高。多數系統在這個問題上的立場是務實的:只在確實需要的地方使用線性一致性,其他地方採用更弱但更高效的一致性模型。
順序保證(Ordering Guarantees)#
順序是分散式系統中反覆出現的主題。回顧前面幾章的內容:
- 第五章:leader 的複寫日誌定義了寫入順序,follower 按此順序套用寫入
- 第七章:可序列化隔離意味著交易的行為如同按某種順序執行
- 第八章:時間戳和時鐘試圖在充滿不確定性的物理世界中引入秩序
順序、線性一致性和共識之間有著深刻的聯繫。本節將逐步揭示這些關聯。
順序與因果關係(Ordering and Causality)#
順序之所以重要,根本原因在於它保留了因果關係(Causality)。「因果」在這裡不是嚴格的物理因果,而是指「一個事件的結果影響了另一個事件」的邏輯依賴關係。因果關係的例子處處可見:
- 對話中的問答有先後——回答在問題之後才有意義
- 資料庫中的一行必須先插入才能被更新
- 先前的寫入決定了後續讀取能看到什麼值
因果關係對事件施加了一個偏序(Partial Order)——某些事件有確定的因果先後,某些則是並行的(Concurrent),沒有因果關係,無法比較先後。這與線性一致性的全序(Total Order)不同:線性一致性要求任何兩個操作都有明確的先後順序。
這個偏序的概念與第五章討論過的情況一致:在「happens-before」關係中,如果操作 A 因果上在操作 B 之前(A 的結果影響了 B),那麼 A 先於 B;如果 A 與 B 互不知曉,它們就是並行的。
因果一致性(Causal Consistency)是比線性一致性更弱但仍有用的保證。線性一致性隱含了因果一致性——任何線性一致的系統都能正確保留因果順序。但反過來不成立:因果一致性不要求線性一致性。好消息是,研究者發現因果一致性是可以在不犧牲效能和可用性的情況下達成的最強一致性模型。這在理論上很重要——它意味著在 CAP 定理的限制之下,因果一致性是我們能得到的「最佳折衷」。
序列號排序#
追蹤所有因果依賴關係在實務上不切實際。但有更好的方法:使用序列號(Sequence Number)或時間戳(不一定是實體時鐘,可以是邏輯計數器)來為事件建立全序,且此全序與因果一致。
在單一 leader 系統中,leader 的複寫日誌自然定義了因果一致的全序——每個操作在日誌中有一個單調遞增的位置(即序號)。如果沒有使用單一 leader(例如 multi-leader 或 leaderless 系統),序列號的產生就變得棘手。可以考慮以下方法,但它們都有根本性的缺陷:
- 每個節點產生獨立序列號:例如一個節點用奇數、另一個用偶數。雖然每個節點的序號是遞增的,但跨節點的序號無法比較因果順序——節點 A 的序號 5 和節點 B 的序號 8 誰在先?無從得知。
- 附上實體時鐘時間戳:看起來自然,但第八章已經說明了時鐘偏移(Clock Skew)的問題——不同節點的時鐘可能不同步,導致時間戳順序與實際因果順序不一致。
- 預先分配序列號區段:例如節點 A 用 1-1000、節點 B 用 1001-2000。但如果節點 A 的操作 1000 因果上在節點 B 的操作 1001 之後發生,序號卻顯示相反的順序。
Lamport 時間戳#
有一個簡單而優雅的方法:Leslie Lamport 於 1978 年提出的 Lamport 時間戳。
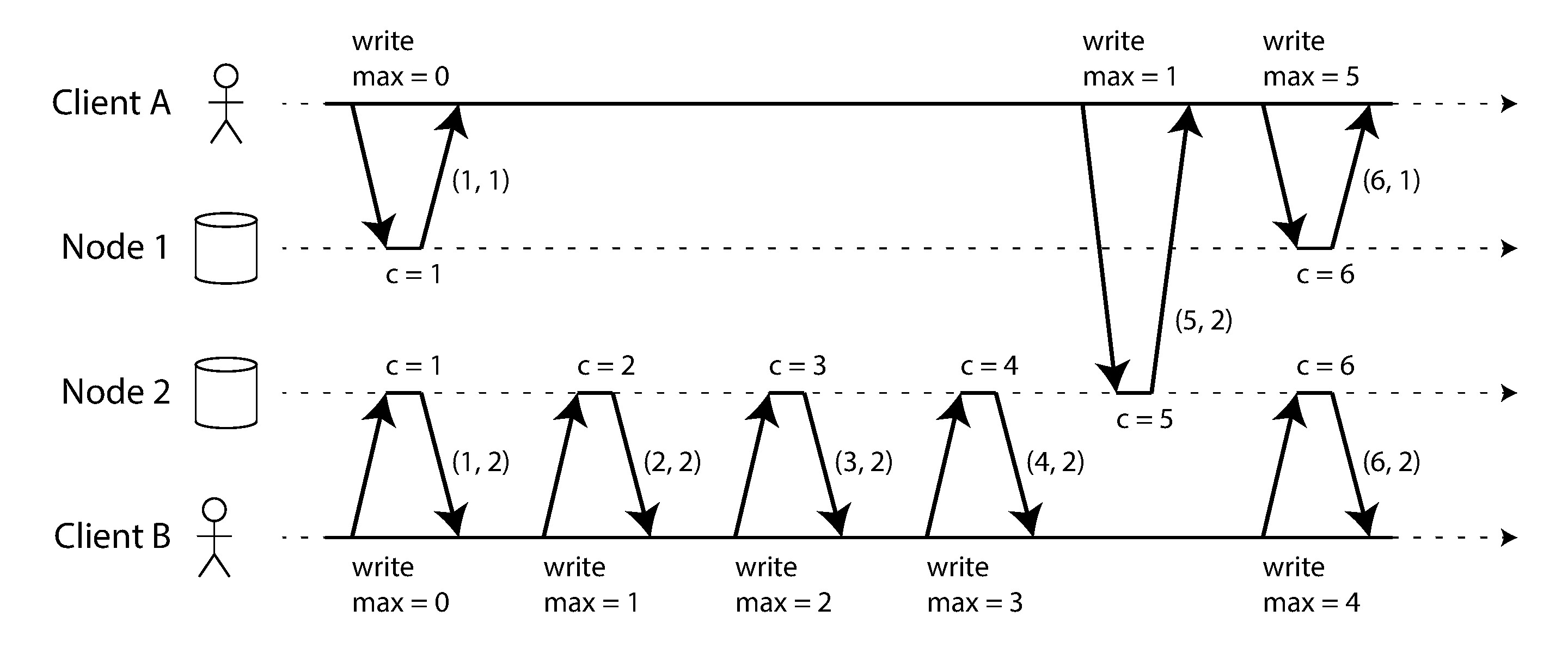
Figure 9-8: Lamport 時間戳提供與因果一致的全序
每個節點有唯一 ID,並維護一個操作計數器。Lamport 時間戳是一對 (counter, nodeID)。排序規則:
- 計數器較大者排在後面
- 計數器相同時,節點 ID 較大者排在後面
關鍵機制在於:每個節點與客戶端都追蹤目前看過的最大計數器值,並在每次請求中附帶此值。當節點收到的請求或回應包含比自己更大的計數器值時,立即將自己的計數器提升到該值。這保證了因果上後發生的事件一定有更大的時間戳。
Lamport 時間戳與版本向量(Version Vector)的用途不同。版本向量能區分兩個操作是並行的還是有因果關係;Lamport 時間戳強制將所有操作排成全序,無法區分並行操作。兩者各有用途。
Lamport 時間戳的局限#
雖然 Lamport 時間戳定義了因果一致的全序,但它不足以解決許多實際的分散式系統問題。
以「確保使用者名稱唯一」為例:兩個使用者在不同節點上同時註冊同一名稱。每個節點可以用 Lamport 時間戳為請求排序——但在收到請求的當下,節點不知道是否有另一個節點正在同時處理衝突的請求。要等到收集完所有節點的操作後才能確定全序中誰排第一。如果有節點故障或網路延遲,這個等待可能永無止境。
我們需要的不只是事後回溯的全序,而是一個能在操作發生的當下就即時決定全序的方法。Lamport 時間戳只能在事後比較,無法幫助節點在收到請求的瞬間做出正確決策。
全序廣播(Total Order Broadcast)#
全序廣播(又稱原子廣播,Atomic Broadcast)是一個訊息傳遞協定,保證兩個屬性:
- 可靠傳遞(Reliable Delivery):訊息不會遺失——如果被傳遞給某個節點,就必須被傳遞給所有節點
- 全序傳遞(Totally Ordered Delivery):所有節點以完全相同的順序接收訊息
即使節點或網路故障,這兩個屬性也必須成立。當然,在節點故障的瞬間它不會收到訊息,但如果它恢復了,就能從頭按序接收遺漏的訊息。
注意全序廣播與 Lamport 時間戳的區別:Lamport 時間戳定義的全序只能在事後透過比較所有操作的時間戳得知,而全序廣播保證的是訊息在被傳遞的當下就已確定其在全序中的位置。節點在處理一條訊息時就知道:在它之前的所有訊息都已處理完畢,在它之後的訊息都還沒到。
全序廣播的重要應用包括:
- 資料庫複寫(State Machine Replication):每條訊息代表一次寫入操作,所有副本以相同順序套用這些寫入,就能保持完全一致的狀態。這正是狀態機複寫的原理——如果每個副本以相同的順序處理相同的輸入,它們的輸出也一定相同。
- 可序列化交易:每條訊息代表一個確定性交易,所有節點以相同順序執行這些交易,不需要額外的並發控制就能達到可序列化隔離。
- 提供 fencing token 的鎖:每次取得鎖的操作附帶一個單調遞增的序號(即 fencing token),後續的資源存取操作帶上此 token,資源端可以拒絕持有較舊 token 的請求,防止因程序暫停或網路延遲導致的過期鎖問題。
全序廣播與線性一致性的關係密切但有區別。全序廣播是非同步的——訊息保證按固定順序傳遞,但不保證何時傳遞完成。線性一致性則要求讀取能立即看到最新寫入。但兩者可以互相建構:
- 用全序廣播實作線性一致性寫入:將「我要申請使用者名稱 X」這樣的訊息追加到全序廣播日誌中,然後讀取日誌。如果日誌中自己的訊息是第一個申請 X 的,就成功;否則就失敗。這實現了線性一致的 compare-and-set 操作。線性一致的讀取也可以用類似方式實現——追加一條讀取訊息到日誌,等到日誌中此訊息被傳遞時再讀取,或者如果日誌允許,從已同步到最新的副本讀取。
- 用線性一致性實作全序廣播:使用一個線性一致的遞增計數器為每條訊息分配序號(每條訊息的序號比前一條多 1,不允許跳號),以此序號定義全序
實作線性一致的 compare-and-set 或遞增計數器與實作全序廣播等價於共識問題。解決其中一個就能解決另一個。這是本章的核心結論之一。
分散式事務與共識#
共識是分散式系統中最重要也最基本的問題之一:讓多個節點就某個值達成一致。表面上看很簡單——幾個節點提議各自的值,然後同意其中一個——但實際上出奇地困難。
FLP 不可能定理(Fischer, Lynch, Paterson, 1985)證明了一個令人驚訝的結論:在確定性的非同步系統模型中,如果即使只有一個節點可能當機,就不存在保證總能達成共識的演算法。但這不代表共識在實務中不可行——透過引入逾時機制(本質上是使用時鐘,跳出了純非同步模型的限制)來偵測可能當機的節點,共識演算法在實際系統中運作良好。
共識的重要場景包括:
- Leader 選舉:所有節點必須就誰是 leader 達成一致,否則出現腦裂與資料損壞
- 原子提交(Atomic Commit):跨多個節點或分區的交易必須全部提交或全部中止,不允許部分成功
原子提交與兩階段提交(2PC)#
在單一節點上,交易的原子性由儲存引擎保證——寫入提交紀錄到 WAL(Write-Ahead Log)是一個原子操作,成為交易是否提交的關鍵時刻。但在多節點的情況下,問題複雜得多。不能簡單地讓每個節點各自獨立決定提交或中止——如果某些節點成功提交而其他節點中止,就違反了原子性。而且一旦某個節點提交了交易,就無法撤回,因為其他交易可能已經讀取了提交的資料。
兩階段提交(Two-Phase Commit, 2PC)是最經典的跨節點原子提交演算法,名稱來自其兩個階段:準備階段(Prepare Phase)和提交階段(Commit Phase)。不要將 2PC 與第七章的兩階段鎖(2PL)混淆——兩者是完全不同的概念。
2PC 引入了一個新角色——協調者(Coordinator,也稱 Transaction Manager),通常以程式庫的形式嵌入在發起交易的應用程式中,但也可以是獨立的服務或程序。
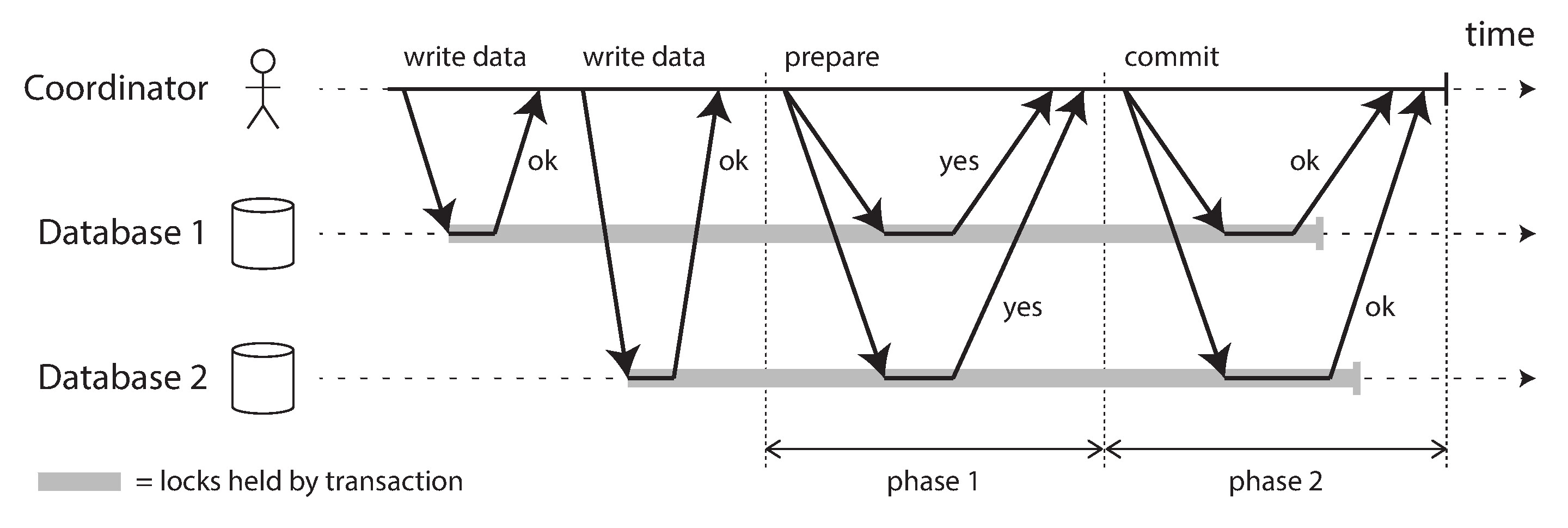
Figure 9-9: 兩階段提交(2PC)的成功執行
2PC 的完整流程:
- 應用程式向協調者請求一個全域唯一的交易 ID
- 應用程式在每個參與節點上以該交易 ID 執行讀寫,任何節點在此階段發現問題都可以中止
- 應用程式準備提交時,協調者向所有參與者發送 prepare 請求
- 參與者收到 prepare 後,確認自己確實能夠提交——將所有交易資料寫入磁碟、檢查衝突。回覆 yes 代表一個不可撤回的承諾
- 協調者收齊所有回覆後做出最終決定——只有全部投 yes 才提交。協調者將決定寫入磁碟上的交易日誌,這是提交點(Commit Point)
- 決定寫入後,協調者向所有參與者發送 commit 或 abort。如果發送失敗,必須無限重試直到成功
兩個不可逆時刻(Point of No Return)定義了 2PC 的正確性:參與者投 yes 後,承諾只要協調者決定提交就一定能提交(即使參與者之後當機,恢復後也必須提交);協調者將決定寫入磁碟後不可撤回,必須重試直到所有參與者都確認。這兩個承諾共同確保了跨節點的原子性。
書中用了一個生動的比喻:2PC 就像婚禮。在說「我願意」之前,你可以隨時反悔;但一旦說了「我願意」,即使你之後暈倒沒聽到牧師宣佈結果,婚姻也已經成立了。
協調者故障#
2PC 的致命弱點在於協調者故障。如果協調者在所有參與者投 yes 之後、發送 commit/abort 之前當機,參與者就陷入疑問狀態(In-Doubt / Uncertain)。
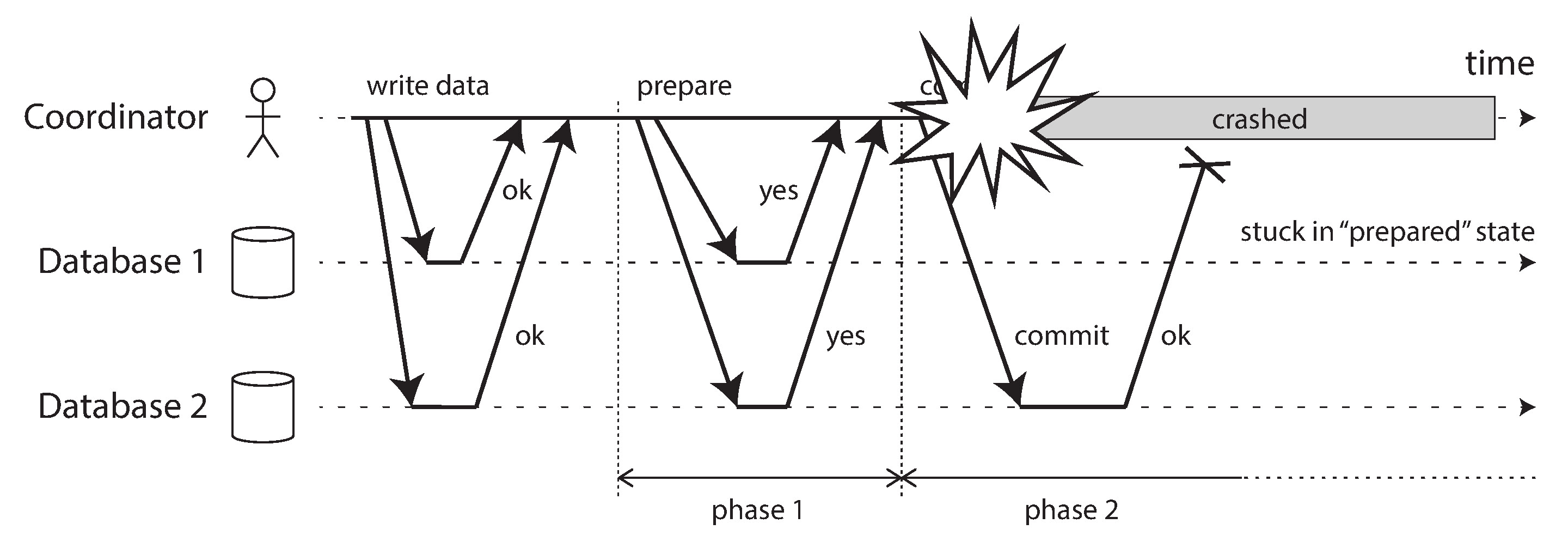
Figure 9-10: 協調者在參與者投票後當機
處於疑問狀態的參與者無法單方面做決定:
- 不能單方面中止——因為其他參與者可能已經收到 commit 指令並提交了,此時自己中止就會導致不一致
- 不能單方面提交——因為其他參與者可能已收到 abort 指令並中止了
- 不能向其他參與者詢問——它們可能也處於疑問狀態,同樣不知道該怎麼辦
- 不能直接逾時中止——這會違反 2PC 的協定,因為已經承諾了可以提交
唯一的解法是等待協調者恢復。在等待期間,交易持有的資料庫行級鎖不會釋放,阻塞所有嘗試讀取或寫入這些行的其他交易。這個阻塞效應可能波及整個系統。
疑問交易持有的鎖可能阻塞整個資料庫。在實務中,曾發生過協調者故障數小時甚至數天的案例,大量交易被阻塞。唯一的手動解法是讓管理員逐一決定每個疑問交易的命運,但這可能違反原子性保證。
三階段提交(3PC)#
理論上,三階段提交(3PC)在 2PC 的基礎上加入了逾時機制,讓參與者在協調者故障時能自行做出決定,避免阻塞。但 3PC 的正確性假設了有界的網路延遲和有界的節點回應時間——也就是說,如果一個節點在固定時間內沒有回應,就可以安全地假設它已經當機。但在實際的網路中,延遲是不可預測的(第八章已詳細討論過),一個節點暫時沒有回應可能只是因為網路擁塞或 GC 暫停,而非真的當機。在這種情況下,3PC 可能做出不安全的決定。因此,儘管 2PC 有阻塞的問題,它仍然是實務中跨節點原子提交的主流方案。
實務中的分散式事務#
分散式事務有兩種截然不同的類型:
- 資料庫內部分散式事務:同一資料庫軟體的不同節點之間(如 VoltDB、MySQL Cluster)。因為所有節點使用相同軟體與協定,可以做到良好的效能最佳化,效果通常不錯。
- 異質分散式事務:跨越不同技術的系統——例如兩個不同廠商的資料庫之間,或訊息代理(Message Broker)與資料庫之間。技術差異使得這類事務極具挑戰性。
XA 事務(eXtended Architecture)是跨異質技術實作 2PC 的標準。PostgreSQL、MySQL、DB2、SQL Server 以及 ActiveMQ、HornetQ、MSMQ、IBM MQ 等訊息代理都支援 XA。它不是網路協定,而是一個 C API,讓應用程式與交易協調者互動。
XA 事務的實務問題包括:
- 協調者是單點故障:如果協調者所在機器故障(而非只是應用程式當機),疑問交易的參與者就被鎖住,可能需要人工介入
- 協調者有狀態:它不再是可以隨意水平擴展的無狀態服務,而是需要持久化交易日誌的關鍵元件
- 相容性限制最佳化空間:XA 是最小公分母標準,各資料庫無法使用 SSI 等高階隔離機制
- 放大故障傾向:分散式事務的存在就是為了在故障時保持一致性,但諷刺的是,當故障真正發生時,疑問交易的鎖定效應往往讓情況更糟——原本只影響單一系統的故障,透過 2PC 的鎖定機制擴散到了所有參與系統
許多雲端服務選擇不實作 XA,因為它與無狀態水平擴展的架構哲學衝突。但對於需要「恰好一次」(exactly-once)語義的訊息處理場景,某種形式的交易協定仍然有價值。
容錯共識演算法#
共識問題的正式定義:一個或多個節點可以提議(Propose)值,共識演算法決定(Decide)其中一個值。演算法必須滿足四個屬性:
| 屬性 | 類型 | 說明 |
|---|---|---|
| 一致同意(Uniform Agreement) | Safety | 沒有兩個節點做出不同的決定 |
| 完整性(Integrity) | Safety | 沒有節點決定兩次 |
| 有效性(Validity) | Safety | 決定的值必須是某個節點提議過的(排除虛假值) |
| 終止性(Termination) | Liveness | 所有未當機的節點最終都會做出決定 |
前三個是安全性(Safety)屬性——在任何情況下都不能被違反,即使所有節點當機或整個網路故障也是如此。第四個是活性(Liveness)屬性——保證系統最終會有進展而非永遠卡住,但它需要一個前提:大多數節點必須存活且能互相通訊。如果超過半數節點永久故障,演算法可以安全地等待(不做出錯誤決定),但無法保證進展。
最著名的容錯共識演算法包括 Viewstamped Replication(VSR)、Paxos、Raft 和 Zab(ZooKeeper 使用)。這些演算法的歷史各有不同——Paxos 由 Leslie Lamport 於 1989 年提出,是最早也最具影響力的,但以難以理解著稱;Raft 於 2014 年發表,明確以「可理解性」為設計目標。雖然細節不同,它們的高層設計大多相似:
- 透過投票選出一個 leader(稱為 epoch 或 term 或 ballot)
- 每輪選舉的編號單調遞增,且保證每個編號內最多一個 leader
- Leader 提議值,其他節點投票——只有獲得 quorum(多數)同意才被接受
- 每次投票前,節點檢查是否有更高編號的 leader;如果有,就放棄當前 leader
- 投票過程中的兩輪 quorum(選舉和提議投票)保證了如果一個值被決定,後續任何當選的 leader 都能發現它
與 2PC 的關鍵差異在於:
- 2PC 要求所有參與者投 yes,共識只需要多數(quorum)
- 2PC 的協調者是固定指派的,不由選舉產生;共識演算法的 leader 由投票選出,故障時可以安全地選出新 leader
- 2PC 中協調者故障可能導致永久阻塞;共識演算法透過多數機制保證即使部分節點故障也能持續進展
- 共識演算法在安全性屬性上不做任何假設(即使所有節點都當機也不會做出錯誤決定),只在活性屬性上要求多數節點存活
共識的代價與限制#
共識演算法是分散式系統理論的重大突破,但並非沒有代價:
- 效能代價:每個提議都需要至少一輪網路往返來收集多數投票,延遲取決於最慢的 quorum 成員的回應時間。這等同於同步複寫——已確認的資料不會因 leader 故障而遺失,但代價是更高的寫入延遲。
- 系統暫停:在 leader 故障到新 leader 選出期間(通常是逾時時間加上選舉過程),系統無法處理任何寫入請求。某些演算法的設計能在此期間仍提供讀取服務,但寫入必須等待。
- 需要嚴格多數:至少三個節點才能容忍一個節點故障,五個節點才能容忍兩個。增加節點不一定能提升效能,因為每次決定都需要更多節點參與投票。節點的動態增減需要額外的成員變更(Membership Change)協定。
- 對網路敏感:大多數共識演算法使用逾時來偵測 leader 故障。在高度波動的網路中(例如地理分散的部署),頻繁的誤判 leader 故障會觸發不必要的選舉,導致系統花大部分時間在選舉而非做實際工作。Raft 在某些特定網路故障模式下(例如只有一條網路連結不穩定)甚至會出現 leader 不斷在兩個節點間跳轉的情況。設計對不穩定網路更健壯的共識演算法仍是開放的研究問題。
成員資格與協調服務#
ZooKeeper 和 etcd 等專案常被描述為「分散式鍵值儲存」或「協調與設定服務」。它們的 API 看起來像資料庫,但它們與一般資料庫有根本性的不同——設計來儲存少量、完全放入記憶體的資料,透過全序廣播複寫到所有節點。
ZooKeeper 提供的核心功能:
| 功能 | 說明 |
|---|---|
| 線性一致的原子操作 | 原子 compare-and-set,可用來實作分散式鎖。配合租約(Lease,帶過期時間的鎖),即使鎖持有者當機也能自動釋放 |
| 操作的全序排列 | 每個操作有一個單調遞增的 transaction ID(zxid)和版本號(cversion),可作為 fencing token 防止過期操作 |
| 故障偵測 | 客戶端與伺服器間維持長期會話(Session),透過心跳偵測。會話逾時時,該會話持有的所有鎖和臨時節點(Ephemeral Node)自動釋放 |
| 變更通知 | 客戶端可以監聽(Watch)鍵值的變化,收到推播通知而非反覆輪詢 |
ZooKeeper 的典型應用#
在實務中,應用程式開發者很少直接使用 ZooKeeper。更常見的是透過依賴它的專案間接使用。HBase、Hadoop YARN、OpenStack Nova、Apache Kafka 都在背景依賴 ZooKeeper。
典型使用模式:
- 工作分配:當有數百個節點的叢集需要將工作(如分區)分配給各節點時,新節點加入或舊節點離開時,其他節點透過 Watch 機制即時收到通知並自動重新分配。結合原子操作,可以確保同一份工作不會被分配給兩個節點。這種模式避免了每次小變動都進行全叢集的共識投票——共識只在初始的 ZooKeeper 層面完成一次,之後的工作分配透過 ZooKeeper 的原語高效完成。
- 服務發現(Service Discovery):服務啟動時向 ZooKeeper 註冊自己的 IP 和端口,讓其他服務知道如何連線。讀取不需要線性一致性(略為過期的連線資訊通常無害),因此 DNS 是更傳統的替代方案。但在需要知道「某服務當前的 leader 是誰」這類問題時,共識基礎的服務發現就比 DNS 更有價值。
- 成員資格管理:追蹤哪些節點目前是叢集的活躍成員。結合故障偵測與臨時節點,可在節點故障時自動觸發重新分配。這對於需要知道「目前有哪些活躍節點」的系統(如分散式資料庫的分區重新平衡)至關重要。
ZooKeeper、etcd 和 Consul 都可用於服務發現,但是否真的需要共識來實作服務發現是有爭議的。如果只是需要查找某個服務的 IP 位址,傳統的 DNS 加上最終一致性就足夠了,而且更健壯、更簡單。但如果讀取需要線性一致性(例如確定唯一的 leader),ZooKeeper 的共識基礎就有不可替代的價值。
設計哲學:少量共識,大量資料#
ZooKeeper 叢集通常只有三到五個節點,但它們協調的應用程式可能有數千個節點。這體現了一個重要的設計原則:
- 少量需要共識的中繼資料(leader 資訊、成員列表、工作分配)交由共識系統管理
- 大量的應用資料流向不需要共識的系統處理
這種分層架構讓大量資料的讀寫不被共識演算法的效能限制拖累,同時在關鍵的協調決策(如「誰是 leader」、「哪些節點還活著」、「工作如何分配」)上保持嚴格的正確性與容錯能力。
這也解釋了為什麼 ZooKeeper 不適合當作通用資料庫使用——它為少量高一致性資料而最佳化,不是為大量資料的高吞吐量讀寫設計的。試圖在 ZooKeeper 中存放大量應用資料會遇到嚴重的效能瓶頸。
本章總結#
本章探討了分散式系統中從強到弱的多種一致性與共識保證,以及它們之間的等價關係。
一致性模型的光譜:
- 線性一致性是最強的一致性模型,讓系統表現得像只有一份資料。直覺且易推理,但效能代價高昂——回應時間至少與網路延遲成正比。在網路分區時必須犧牲可用性(CAP 定理)。
- 因果一致性弱於線性一致性但效能更好。它保留了因果順序,允許並行事件的不同排列。研究表明這是不犧牲效能和可用性的最強一致性模型。
- 最終一致性是最弱的保證——副本最終會收斂,但過程中可能出現各種不一致。
從順序到共識:
- 全序廣播保證所有節點以相同順序收到所有訊息,等價於重複執行多輪共識。它是實作狀態機複寫和可序列化交易的基礎。
- 兩階段提交(2PC) 可以實作跨節點原子提交,但協調者故障會導致無限期阻塞。嚴格來說這不是容錯共識演算法,因為它不滿足終止性。
- 容錯共識演算法(Raft、Paxos、Zab)透過多數決機制保證即使部分節點故障也能持續運作。它們是分散式系統理論的重大突破,但需要至少三個節點且對網路品質敏感。
實務層面:
- ZooKeeper 等協調服務將共識的複雜性封裝為實用的操作原語——鎖、leader 選舉、成員管理、故障偵測——讓應用程式無需直接實作共識即可受益。
- XA 事務提供了跨異質系統的原子提交,但在實務中因協調者單點故障和效能問題而備受爭議。
並非所有系統都需要共識。Leaderless 和 multi-leader 系統選擇不使用全域共識,代價是需要處理衝突與最終一致性的複雜性(參見第五章)。但對於需要線性一致性、唯一性約束或跨節點原子操作的場景,共識是不可或缺的基礎建設。
最終,本章揭示了一個優美的理論結果:線性一致的 compare-and-set 暫存器、全序廣播和共識在本質上是等價的問題。解決其中一個就能解決其他所有問題。這個等價關係是理解分散式系統理論的核心線索之一。