本章摘要: 探討 JSON、Thrift、Protocol Buffers、Avro 等編碼格式如何影響前後向相容性,以及透過資料庫、REST/RPC 和非同步訊息傳遞三種資料流模式,在系統演化中維持新舊版本程式碼的安全共存。
應用程式不可避免地會隨時間演化:新增功能、修改需求、調整商業邏輯。當應用程式變更時,儲存的資料格式往往也需要跟著改變。在大型系統中,程式碼的更新無法一次到位——伺服器端採用**滾動升級(rolling upgrade)**逐步部署,客戶端則取決於使用者何時更新。這意味著新舊版本的程式碼與資料格式會同時並存。
為了讓系統在演化過程中持續運作,我們需要維護兩個方向的相容性:
- 向後相容(backward compatibility):新版程式碼能讀取舊版寫入的資料
- 向前相容(forward compatibility):舊版程式碼能讀取新版寫入的資料
向後相容通常較容易實現,因為開發者知道舊格式的樣貌。向前相容則更為棘手,需要舊版程式碼能忽略新版新增的內容。
資料編碼格式#
程式在記憶體中以物件、結構、陣列、雜湊表等形式運作,但寫入檔案或透過網路傳送時,必須將其編碼(encoding)為位元組序列;反向的操作則稱為解碼(decoding)。
編碼又稱 serialization 或 marshalling,解碼又稱 parsing、deserialization 或 unmarshalling。本書使用「encoding」以避免與交易中的 serialization 混淆。
語言特定格式#
許多程式語言內建序列化機制,例如 Java 的 java.io.Serializable、Python 的 pickle、Ruby 的 Marshal。這些格式雖然方便,但有嚴重的缺陷:
| 問題 | 說明 |
|---|---|
| 語言綁定 | 資料被鎖定在特定語言中,難以跨語言整合 |
| 安全風險 | 解碼過程可能實例化任意類別,成為遠端程式碼執行的攻擊面 |
| 版本控制薄弱 | 前後向相容性通常是事後才考慮的 |
| 效能不佳 | 例如 Java 內建序列化以效能差和編碼膨脹聞名 |
語言特定的序列化格式僅適合非常短暫的用途,不應用於持久化儲存或跨服務通訊。
JSON、XML 與 CSV#
JSON 和 XML 是最廣泛使用的跨語言文字格式,CSV 則是另一種常見選擇。它們具有人類可讀性,但也有微妙的問題:
- 數字的模糊性:JSON 不區分整數與浮點數,且未規定精度。大於 2^53 的整數在 JavaScript 中會失去精度(Twitter 因此在 API 回應中同時提供數字與字串兩種格式的 tweet ID)
- 不支援二進制字串:只能透過 Base64 編碼繞過,但這會增加約 33% 的資料量
- Schema 支援不一:XML Schema 與 JSON Schema 功能強大但複雜;CSV 則完全沒有 schema,欄位語義全由應用程式自行定義
儘管有這些缺陷,JSON、XML 和 CSV 作為組織間的資料交換格式仍然非常實用——讓不同組織同意使用同一格式,本身就已經是最大的挑戰。
二進制編碼#
對於組織內部的資料,可以選擇更緊湊、更快速的二進制編碼。JSON 的二進制變體包括 MessagePack、BSON、BJSON 等,但由於它們保留 JSON 的資料模型且不依賴 schema,仍需在編碼中包含所有欄位名稱。
以下是將此範例記錄編碼的過程:
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}使用 MessagePack 編碼後為 66 bytes,相比移除空白的 JSON(81 bytes)節省有限,且犧牲了可讀性。
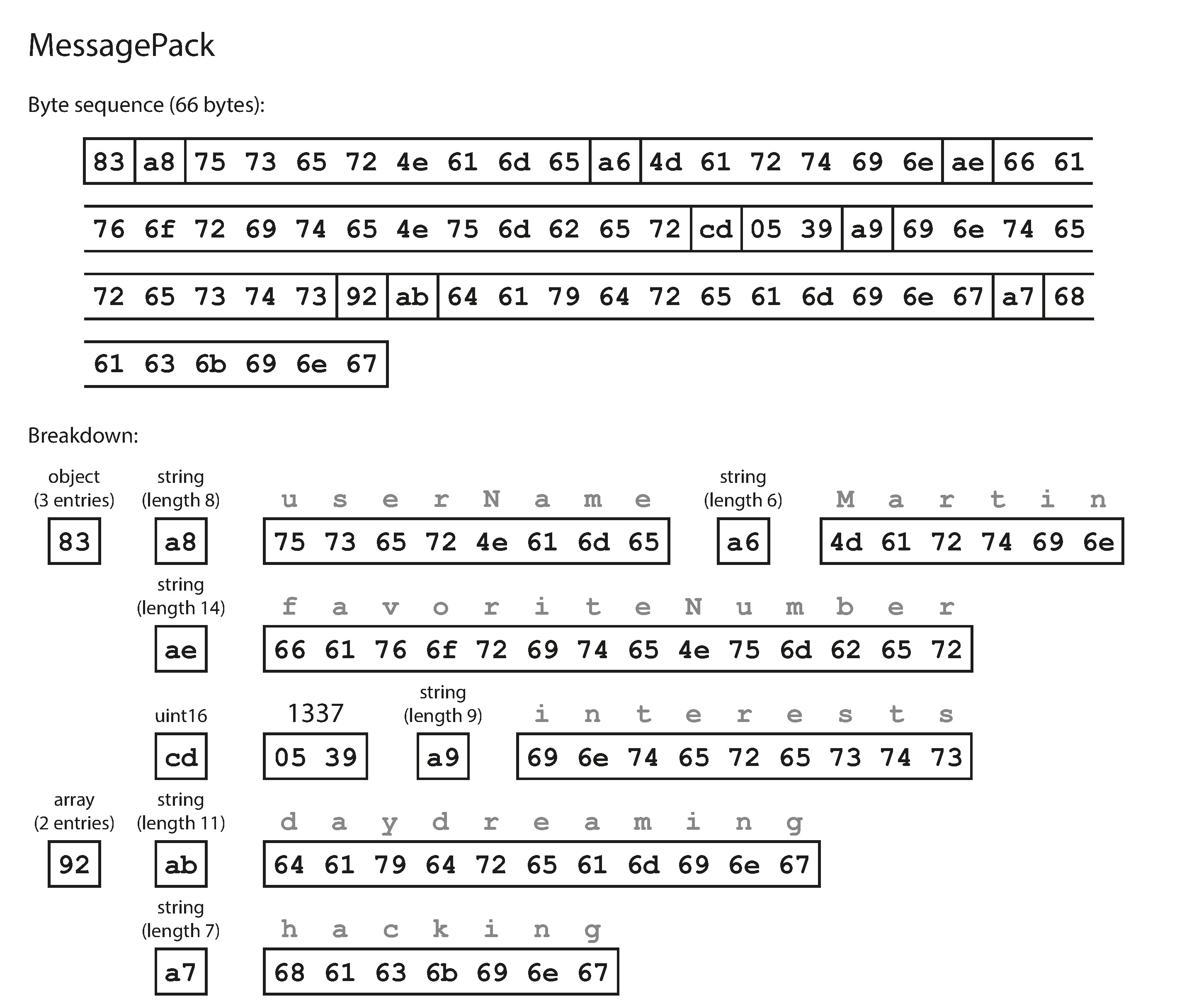
Figure 4-1: 使用 MessagePack 編碼的記錄範例
Thrift 與 Protocol Buffers#
Apache Thrift(Facebook 開發)和 Protocol Buffers(Google 開發)是基於相同原理的二進制編碼函式庫,兩者都在 2007-08 年開源。它們的核心思想是:透過 schema 定義取代在編碼中嵌入欄位名稱。
Thrift 的 schema 定義(IDL):
struct Person {
1: required string userName,
2: optional i64 favoriteNumber,
3: optional list<string> interests
}Protocol Buffers 的 schema 定義:
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}兩者的關鍵設計是:每個欄位都有一個欄位標籤(field tag)——即 schema 中的數字(1, 2, 3)。編碼後的資料只包含標籤編號而非欄位名稱,大幅縮小了資料量。
Thrift 的兩種編碼格式#
BinaryProtocol 編碼同一筆記錄需要 59 bytes。每個欄位包含型別標註、欄位標籤和值。
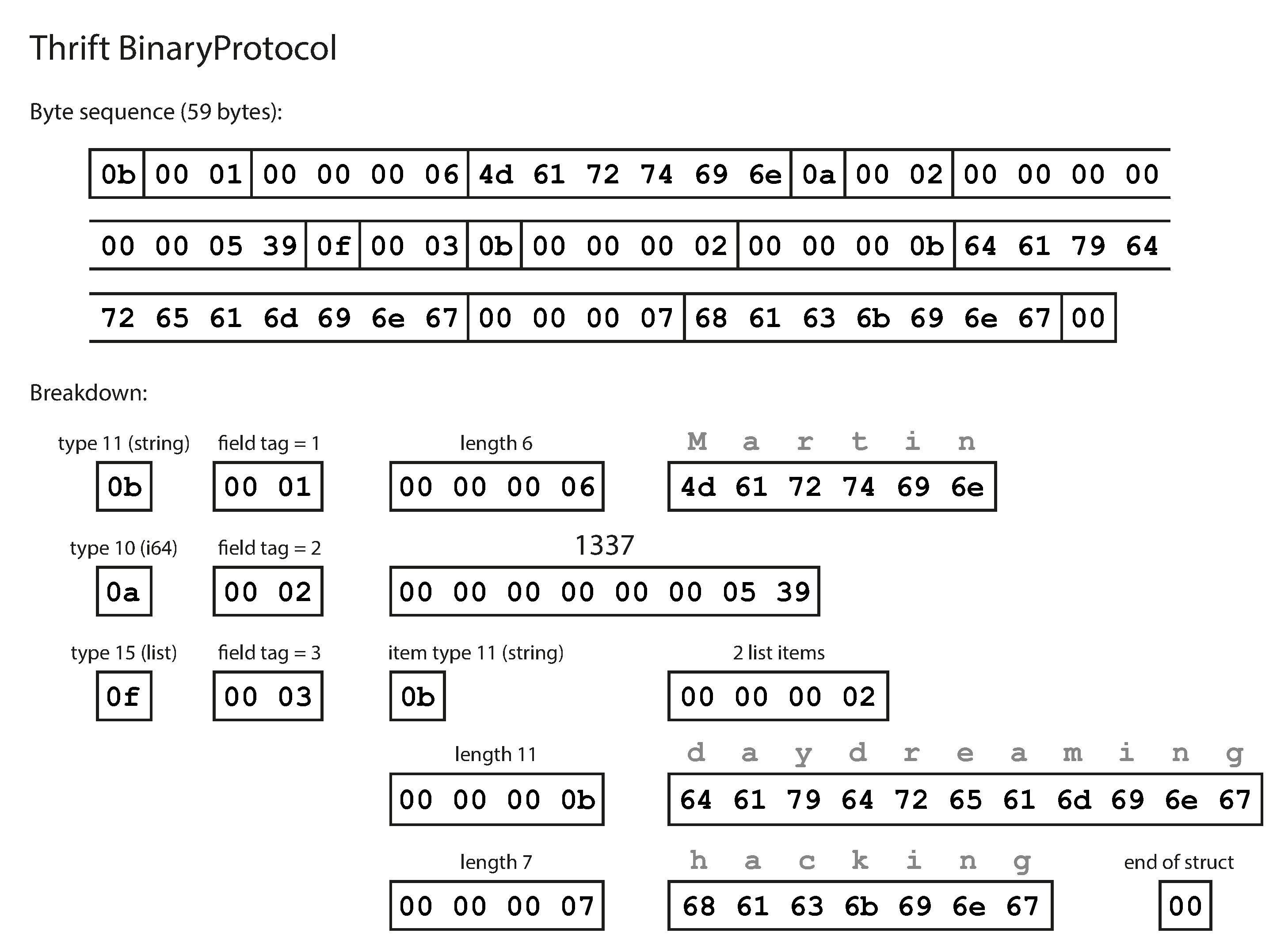
Figure 4-2: 使用 Thrift BinaryProtocol 編碼的記錄
CompactProtocol 僅需 34 bytes,透過兩項優化達成:將欄位型別與標籤編號壓縮進單一位元組,以及使用**可變長度整數(variable-length integer)**編碼——小數字用較少位元組,大數字用較多位元組。
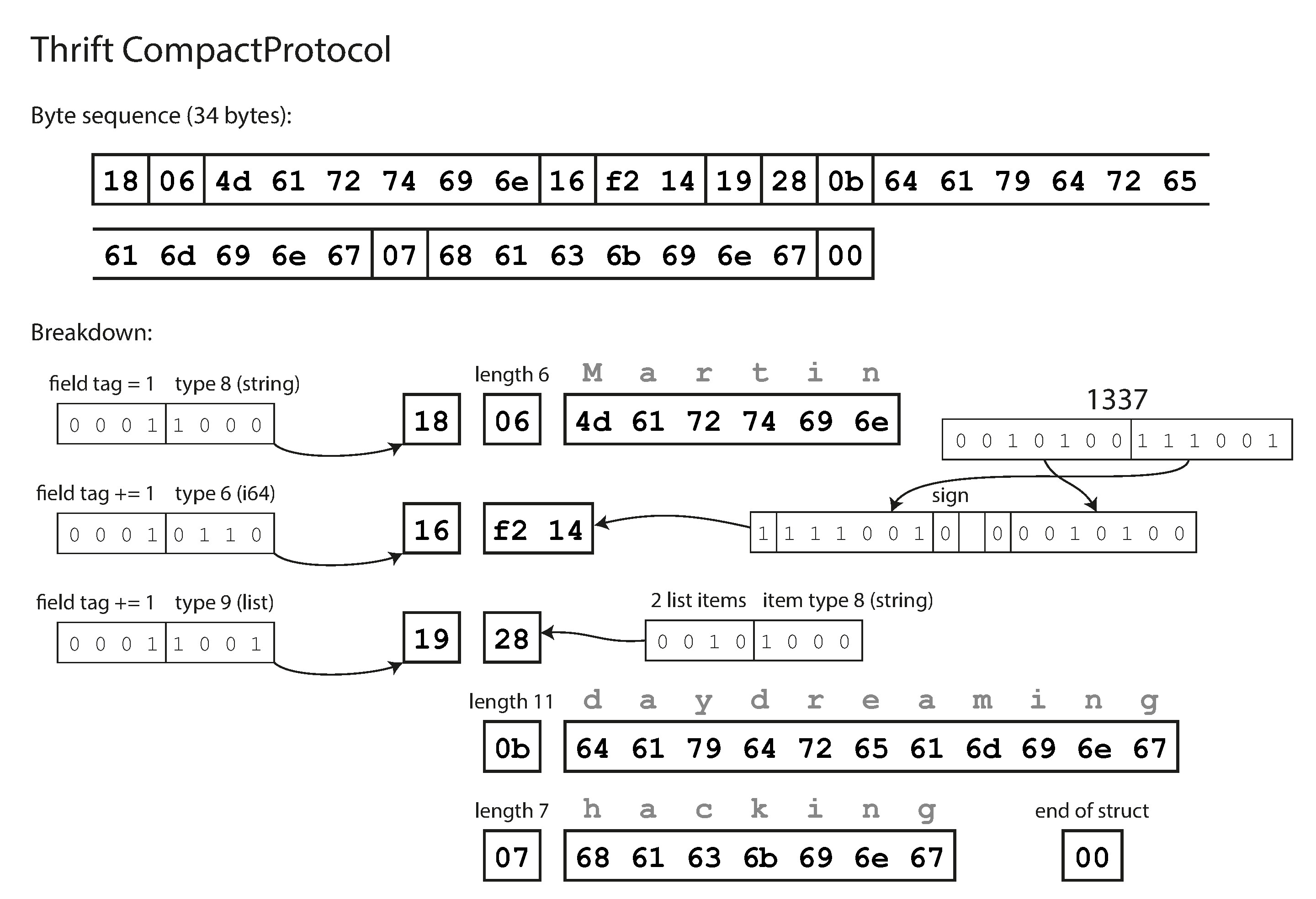
Figure 4-3: 使用 Thrift CompactProtocol 編碼的記錄
Protocol Buffers 的編碼#
Protocol Buffers 只有一種二進制編碼格式,與 Thrift CompactProtocol 非常相似,同一筆記錄壓縮到 33 bytes。
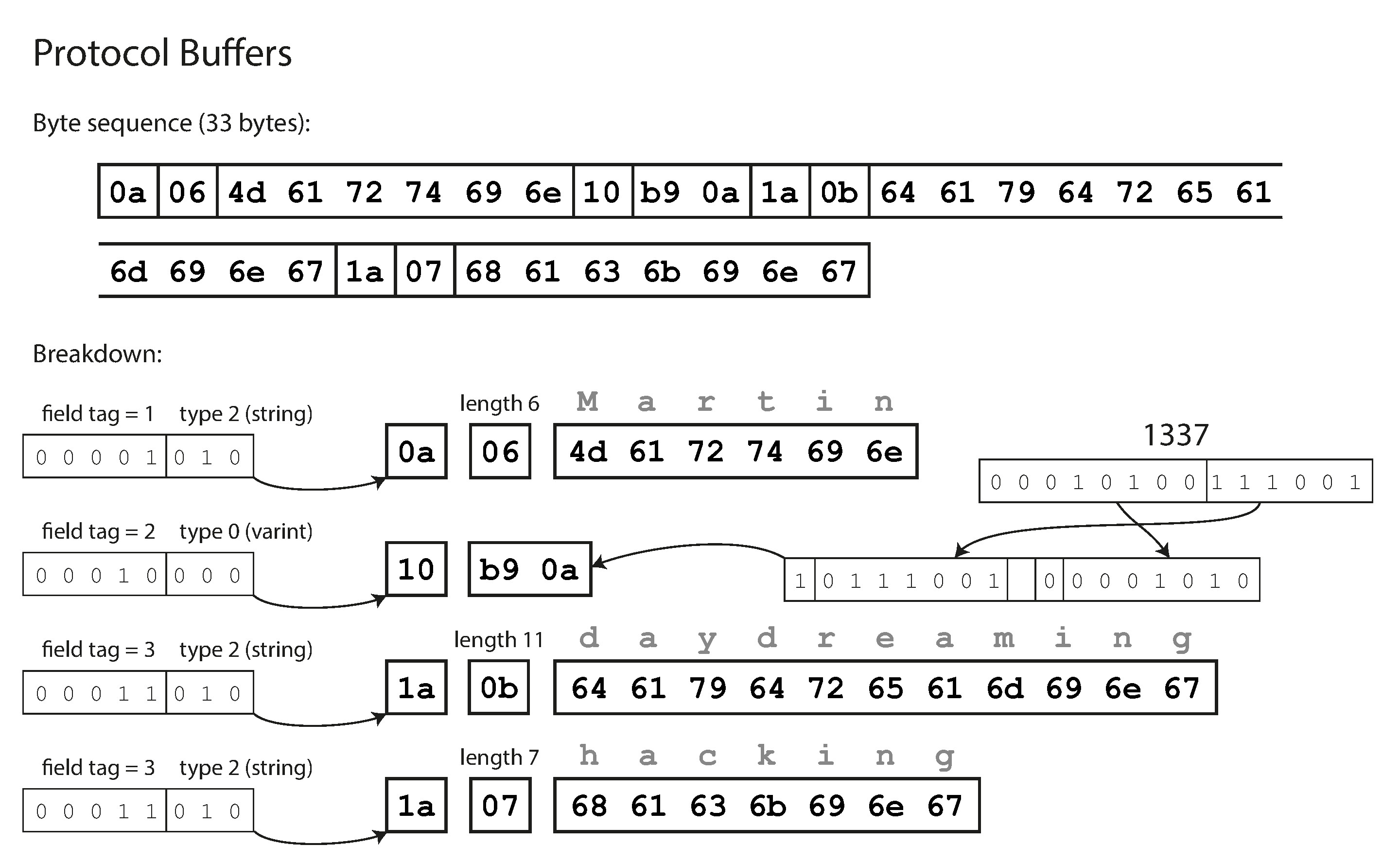
Figure 4-4: 使用 Protocol Buffers 編碼的記錄
Schema 中的
required和optional標記不影響編碼方式(二進制資料中沒有對應的標記),它們僅在執行期間檢查欄位是否存在。
欄位標籤與 Schema 演化#
欄位標籤是編碼資料語義的核心。演化規則如下:
- 可以更改欄位名稱,因為編碼資料中只有標籤編號
- 不能更改欄位標籤,否則所有既有編碼資料都會失效
- 新增欄位時給予新的標籤編號,舊程式碼遇到不認識的標籤時直接跳過(向前相容)
- 新增的欄位必須是 optional 或有預設值,否則新程式碼讀取舊資料時會因缺少該欄位而失敗(破壞向後相容)
- 移除欄位只能移除 optional 欄位,且其標籤編號永遠不能重複使用
資料型別與 Schema 演化#
更改欄位的資料型別是可能的但有風險。例如將 32 位元整數改為 64 位元整數,新程式碼讀取舊資料時可以補零,但舊程式碼讀取新資料時可能發生截斷。
Protocol Buffers 的一個特點是沒有 list 型別,而是使用 repeated 標記。編碼時同一標籤會出現多次。這使得從 optional(單值)演化為 repeated(多值)成為可能——舊程式碼讀取新資料時只會看到最後一個元素。
Avro#
Apache Avro 是為 Hadoop 設計的二進制編碼格式,誕生於 2009 年,因為 Thrift 不完全適合 Hadoop 的使用情境。Avro 有兩種 schema 語言:一種是人類友善的 Avro IDL,另一種是基於 JSON 的機器可讀格式。
record Person {
string userName;
union { null, long } favoriteNumber = null;
array<string> interests;
}Avro 與 Thrift/Protocol Buffers 最大的差異是:schema 中沒有標籤編號。編碼後的資料僅為值的連續排列,不包含欄位識別資訊或型別標記,同一筆記錄只需 32 bytes——是所有格式中最緊湊的。
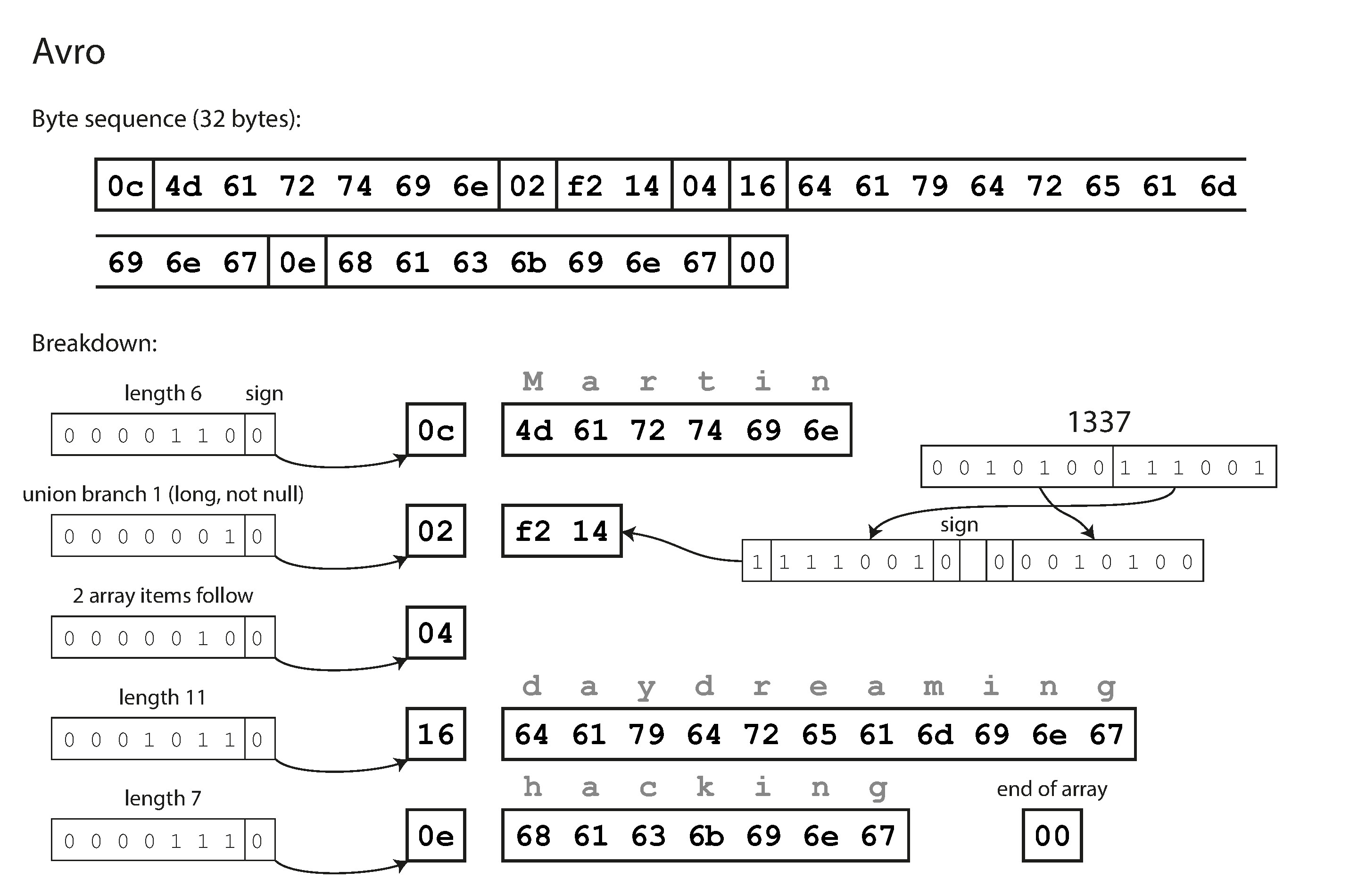
Figure 4-5: 使用 Avro 編碼的記錄
解碼時必須按照 schema 中欄位的順序逐一解析,因此讀取者必須使用與寫入者完全相同的 schema 才能正確解碼。
Writer’s Schema 與 Reader’s Schema#
Avro 的核心設計理念是:寫入者的 schema(writer’s schema)和讀取者的 schema(reader’s schema)不必相同,只需相容。Avro 函式庫會比對兩個 schema,自動解析差異進行轉換:
- 欄位順序不同沒關係,透過欄位名稱匹配
- 寫入者有但讀取者沒有的欄位會被忽略
- 讀取者有但寫入者沒有的欄位會填入預設值
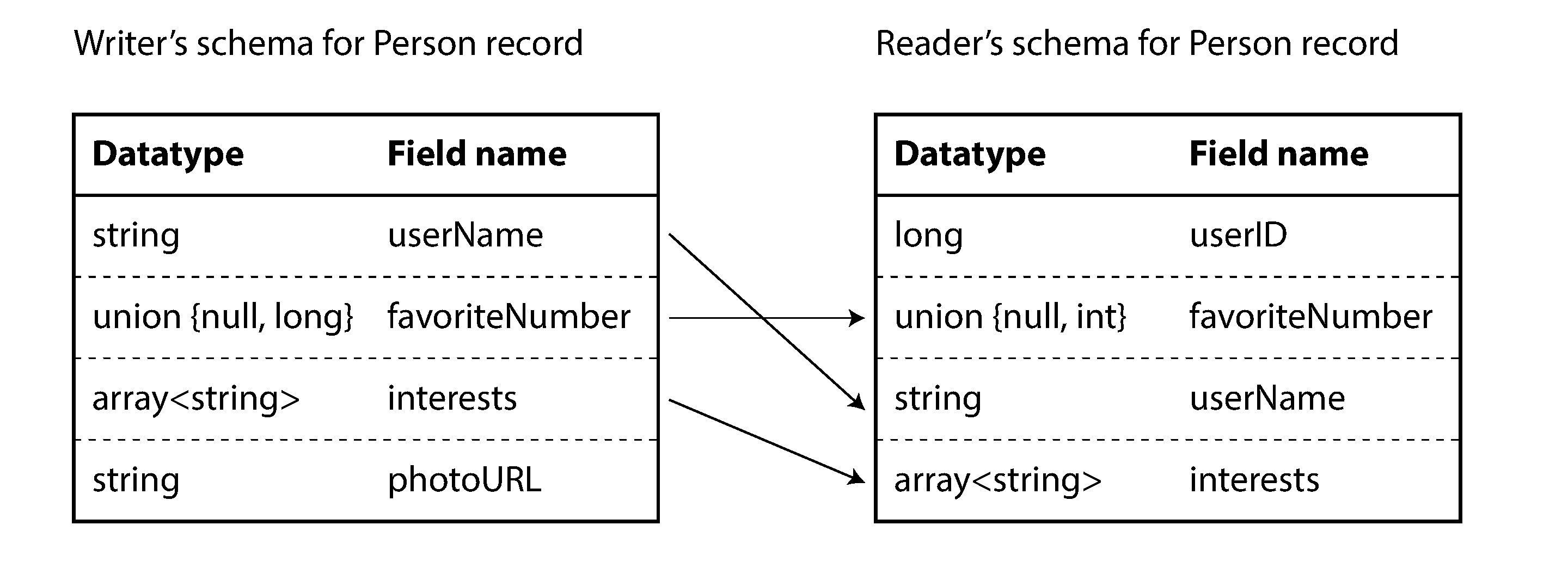
Figure 4-6: Avro 讀取器解析寫入者與讀取者 schema 的差異
Avro 的 Schema 演化規則#
- 只能新增或移除有預設值的欄位,以維持前後向相容
- 若要允許欄位為 null,必須使用 union 型別(例如
union { null, long })——Avro 不允許任意欄位預設為 null - 欄位改名是向後相容但不向前相容的(reader’s schema 可透過 alias 匹配舊名稱)
Avro 不同於 Thrift 和 Protocol Buffers 的 optional/required 機制,而是使用 union 型別 + 預設值來處理可選欄位,這迫使開發者明確定義哪些欄位可以為 null。
讀取者如何得知 Writer’s Schema?#
根據使用場景不同,有幾種方式傳遞 writer’s schema:
| 場景 | 傳遞方式 |
|---|---|
| 大檔案(如 Hadoop) | 在檔案開頭寫入一次 schema(Avro object container file 格式) |
| 資料庫中的個別記錄 | 每筆記錄附帶 schema 版本號,從 schema registry 查詢對應的 schema |
| 網路連線 | 在連線建立時協商 schema 版本,整個連線期間使用該 schema |
動態生成 Schema 的優勢#
Avro 沒有標籤編號的設計讓它特別適合動態生成 schema。例如將關聯式資料庫的內容匯出為 Avro 格式時,可以直接從資料庫 schema 自動產生 Avro schema(每個表格對應一個 record,每個欄位對應一個 field)。當資料庫 schema 變更時,只需重新產生 Avro schema 即可,不需要手動管理標籤編號的對應。
相較之下,使用 Thrift 或 Protocol Buffers 時,每次資料庫 schema 變更都需要有人手動更新欄位標籤的對應——這並非它們的設計目標。
Schema 的好處#
基於 schema 的二進制編碼(Thrift、Protocol Buffers、Avro)相比文字格式有多項優勢:
| 優勢 | 說明 |
|---|---|
| 更緊湊 | 省略欄位名稱,比各種「binary JSON」變體更小 |
| Schema 即文件 | 因為解碼必須依賴 schema,可以確保文件永遠與實際格式一致 |
| 相容性檢查 | 維護 schema 版本資料庫,可在部署前驗證前後向相容性 |
| 程式碼生成 | 對靜態型別語言提供編譯期型別檢查 |
Schema 演化提供了與 schemaless/schema-on-read JSON 資料庫相同的靈活度,同時還能對資料提供更好的保證和工具支援。
資料流模式#
資料從一個程序流向另一個程序有多種方式。以下討論三種最常見的模式:透過資料庫、透過服務呼叫、透過非同步訊息傳遞。
透過資料庫的資料流#
在資料庫中,寫入的程序負責編碼,讀取的程序負責解碼。資料庫需要同時支援向後相容(讀取過去寫入的資料)和向前相容(舊版程式碼讀取新版寫入的資料)。
一個容易被忽略的問題是:當舊版程式碼讀取包含新欄位的記錄、更新後重新寫回時,可能會遺失新增的欄位。應用程式層面需要注意保留未知欄位。
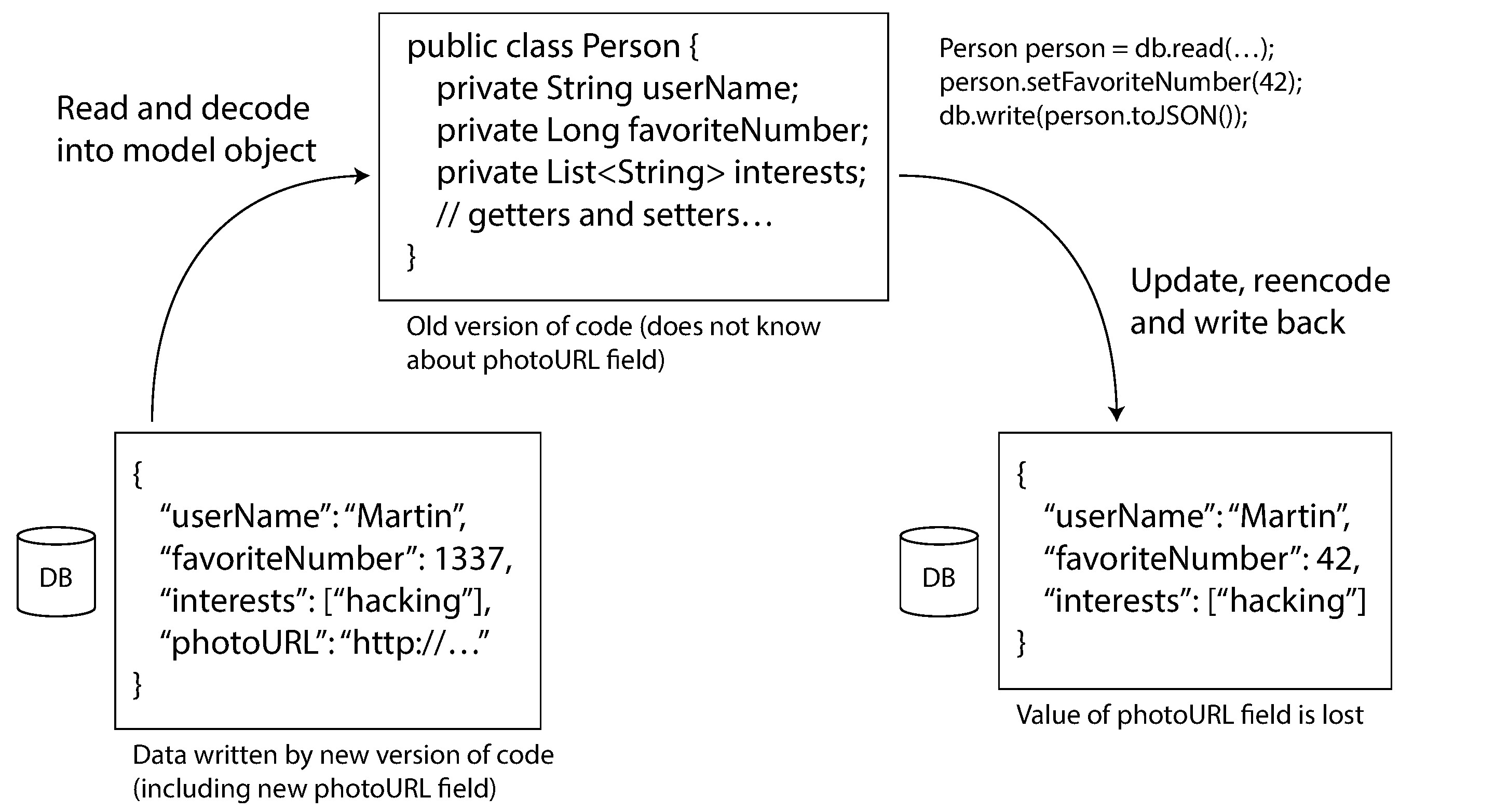
Figure 4-7: 舊版應用程式更新由新版寫入的資料時可能遺失欄位
資料壽命超越程式碼(data outlives code):資料庫中可能同時存在五毫秒前和五年前寫入的資料。程式碼可以在幾分鐘內完全替換,但資料不會——除非主動遷移。大多數關聯式資料庫允許簡單的 schema 變更(如新增帶有 null 預設值的欄位),而無需重寫既有資料。Schema 演化使得整個資料庫看起來像是使用單一 schema 編碼的,即使底層實際包含各個歷史版本的 schema。
對於歸檔儲存(如備份或載入資料倉儲),通常會使用最新版 schema 統一編碼所有資料,此時 Avro object container file 或如 Parquet 的欄式格式是很好的選擇。
透過服務的資料流:REST 與 RPC#
在網路通訊中,最常見的安排是客戶端-伺服器模型:伺服器透過網路公開 API(即服務),客戶端連線進行請求。伺服器本身也可以是其他服務的客戶端,這種做法構成了服務導向架構(SOA),更近期則被稱為微服務架構(microservices architecture)。
微服務架構的核心設計目標是讓服務可以獨立部署和演化。每個服務由一個團隊擁有,可以頻繁釋出新版本而無需與其他團隊協調。因此服務間的資料編碼必須跨版本相容。
REST 與 SOAP#
兩種主流的 Web 服務方案哲學截然對立:
- REST 是一種設計哲學,建立在 HTTP 原則之上,強調簡單的資料格式、用 URL 識別資源、善用 HTTP 特性。遵循 REST 原則的 API 稱為 RESTful API
- SOAP 是基於 XML 的網路 API 請求協議,使用 WSDL 描述 API,依賴程式碼生成。雖然仍在大型企業使用,但因複雜性和互通性問題,已在較小的公司中失去青睞
RESTful API 傾向更簡單的做法,搭配 OpenAPI(Swagger)等定義格式來產生文件。
RPC 的問題#
遠端程序呼叫(RPC) 試圖讓網路服務請求看起來像本地函式呼叫(稱為位置透明性 / location transparency),但這種抽象本質上有缺陷,因為網路請求與本地呼叫截然不同:
- 網路請求可能因網路問題而不可預測地失敗
- 請求可能超時而無結果,且你無法得知請求是否已被處理
- 重試可能導致重複執行,除非有冪等性(idempotence)機制
- 延遲變化劇烈,與本地呼叫的穩定耗時不同
- 參數需要編碼為位元組序列,對大型物件尤其困難
- 客戶端與伺服器可能使用不同的程式語言,型別轉換可能造成問題
新一代 RPC 框架(如 gRPC、Finagle、Rest.li)更明確地區分遠端請求與本地呼叫,使用 futures/promises 封裝非同步操作,gRPC 支援串流(streams)。
REST 適合作為公開 API 的風格,優點是方便實驗和除錯、生態系豐富。RPC 框架則主要用於同組織內部的服務間通訊,能透過二進制編碼達到更好的效能。
RPC 的資料編碼與演化#
對於透過服務的資料流,可以合理假設伺服器會先更新、客戶端後更新,因此需要:
- 請求端維持向後相容
- 回應端維持向前相容
各框架的相容性繼承自其底層編碼格式。服務相容性的額外挑戰在於跨組織通訊時,服務提供者無法控制客戶端的升級,因此常需要長期維護多個 API 版本。API 版本化的常見做法包括在 URL 中加入版本號或使用 HTTP Accept header。
透過訊息傳遞的資料流#
非同步訊息傳遞(asynchronous message passing) 介於 RPC 和資料庫之間:像 RPC 一樣以低延遲將訊息送達另一個程序,但像資料庫一樣透過中介——訊息代理(message broker / message queue)——暫存訊息。
使用訊息代理的優勢:
| 優勢 | 說明 |
|---|---|
| 緩衝區 | 收件者不可用時暫存訊息,提升系統可靠性 |
| 自動重新派送 | 可自動將訊息重新派送給崩潰後重啟的程序 |
| 位置透明 | 發送者不需要知道收件者的 IP 和 port |
| 多播 | 一則訊息可以送達多個收件者 |
| 邏輯解耦 | 發送者與收件者在邏輯上解耦 |
訊息傳遞通常是單向的:發送者不期望收到回覆。回覆若有需要,會在另一個獨立的 channel 上進行。
訊息代理#
常見的開源訊息代理包括 RabbitMQ、ActiveMQ、NATS 和 Apache Kafka。基本運作模式是:一個程序將訊息發送到具名的 queue 或 topic,代理確保訊息被遞送給該 topic 的一個或多個 consumer。
訊息代理通常不強制特定的資料模型——訊息只是帶有中繼資料的位元組序列,可以使用任何編碼格式。只要編碼格式支援前後向相容,就能獨立更新 publisher 和 consumer。
若 consumer 將訊息重新發布到另一個 topic,需注意保留未知欄位,以避免與資料庫場景中相同的欄位遺失問題(見 Figure 4-7)。
分散式 Actor 框架#
Actor 模型是一種並行程式設計模型:邏輯封裝在 actor 中,每個 actor 有自己的局部狀態,透過非同步訊息與其他 actor 溝通。分散式 actor 框架將此模型擴展到多節點——無論 actor 在同一節點還是不同節點,都使用相同的訊息傳遞機制。
Actor 模型中位置透明性比 RPC 更自然,因為 actor 模型本身就假設訊息可能會遺失。三個主要的分散式 actor 框架在訊息編碼上的策略:
| 框架 | 訊息編碼策略 |
|---|---|
| Akka | 預設使用 Java 內建序列化(不支援前後向相容),但可替換為 Protocol Buffers |
| Orleans | 預設使用不支援滾動升級的自訂格式,需部署新叢集來更新;可使用自訂序列化外掛 |
| Erlang OTP | 更改 record schema 出乎意料地困難,滾動升級需要謹慎規劃 |
本章小結#
本章探討了將資料結構轉換為網路或磁碟位元組的各種方式,以及這些編碼方式如何影響應用程式架構和部署策略。
編碼格式的相容性光譜:
- 語言特定編碼:受限於單一語言,通常缺乏前後向相容性
- 文字格式(JSON、XML、CSV):廣泛使用,相容性取決於使用方式,資料型別定義較模糊
- 二進制 schema 驅動格式(Thrift、Protocol Buffers、Avro):緊湊高效、前後向相容語義明確、schema 可作為文件和程式碼生成的基礎
資料流模式各有其相容性考量:
- 資料庫:寫入者編碼、讀取者解碼,需注意資料壽命超越程式碼
- RPC 與 REST API:客戶端編碼請求、伺服器解碼後編碼回應,跨組織時需長期維護相容性
- 非同步訊息傳遞:透過訊息代理或 actor 框架傳遞編碼後的訊息,發送者與接收者解耦
只要稍加注意,前後向相容性和滾動升級是完全可以實現的。讓你的應用程式快速演化,讓你的部署頻繁進行。