本章摘要: 比較 LSM-Tree 與 B-Tree 兩大 OLTP 索引結構的讀寫取捨,並介紹列式儲存與點陣圖編碼等 OLAP 最佳化技術,說明交易處理與分析查詢為何需要截然不同的儲存引擎設計。
本章從資料庫的角度出發,探討資料如何被儲存以及如何被找回。身為應用程式開發者,理解儲存引擎的內部運作方式,有助於針對特定工作負載選擇並調校合適的資料庫。本章的核心區分是:針對 交易處理 (OLTP) 最佳化的儲存引擎,與針對 分析查詢 (OLAP) 最佳化的儲存引擎,兩者有截然不同的設計哲學。
驅動資料庫的資料結構#
最簡單的資料庫可以用兩個 Bash 函式實作:db_set 將鍵值對追加到檔案末尾,db_get 則掃描整個檔案找出某個鍵的最新值。追加寫入 (append) 的效能極佳,但讀取的時間複雜度為 O(n),隨著資料量增長而線性變慢。
為了加速讀取,我們需要索引 (index)——一種從主資料衍生出的額外結構,作為路標指引我們找到目標資料。然而索引會拖慢寫入速度,因為每次寫入都需同步更新索引。這是儲存系統中的核心取捨:
精心選擇的索引能加速讀取查詢,但每個索引都會拖慢寫入。資料庫通常不會預設索引所有欄位,而是由開發者根據應用程式的查詢模式手動選擇。
Hash Indexes#
雜湊索引是最簡單的索引策略:在記憶體中維護一個雜湊表,將每個鍵對應到資料檔案中的位元組偏移量 (byte offset)。寫入時追加到檔案並更新雜湊表,讀取時透過雜湊表定位偏移量再讀取值。
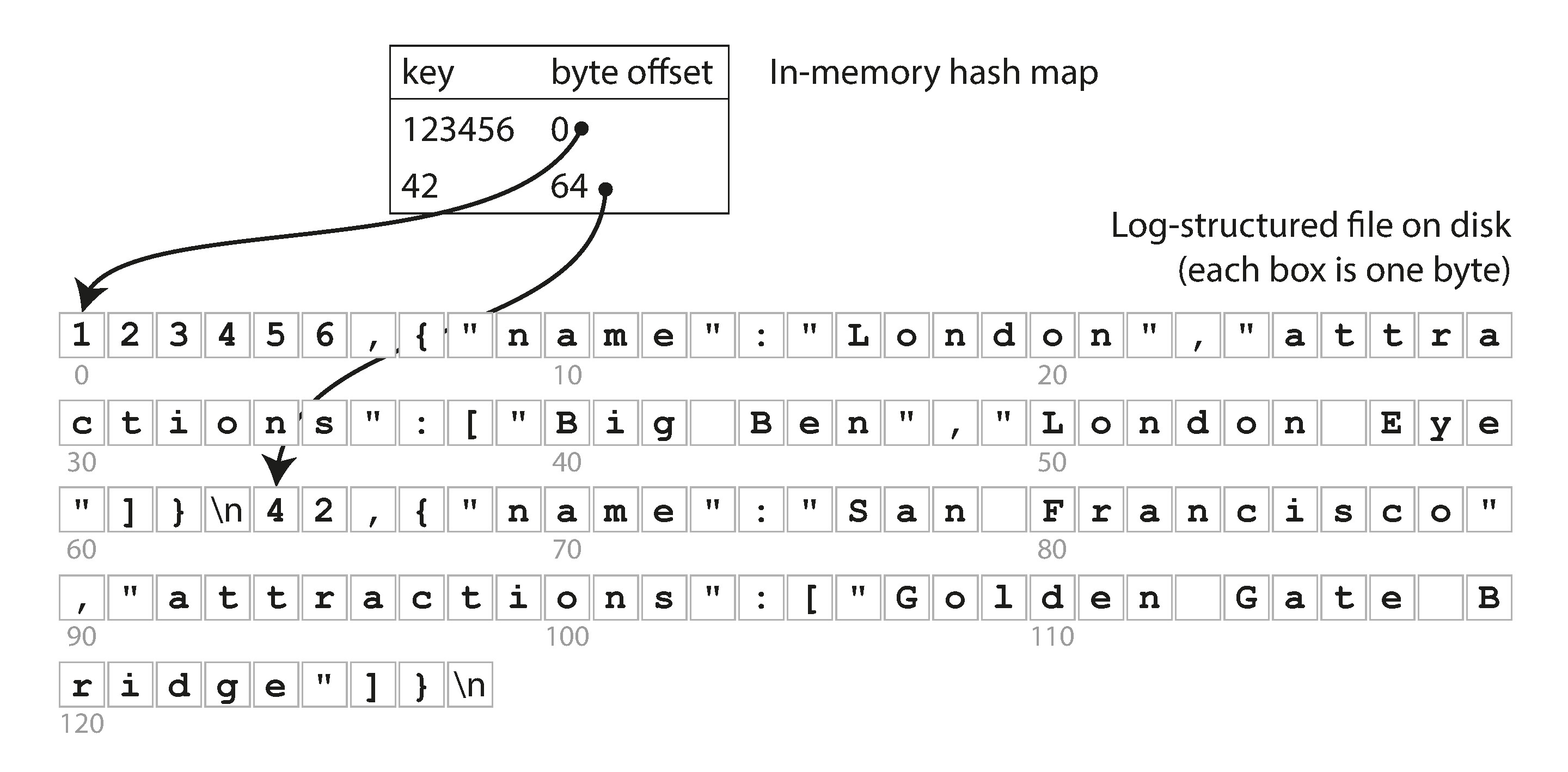
Figure 3-1: 使用記憶體雜湊表索引的鍵值對日誌儲存
這正是 Bitcask(Riak 的預設儲存引擎)的做法。它的前提是所有鍵都能放進 RAM,而值可以比記憶體大,因為讀取值只需一次磁碟搜尋。這種引擎特別適合鍵的種類不多、但每個鍵頻繁更新的場景(例如影片播放次數計數器)。
段壓縮與合併#
為避免磁碟空間耗盡,日誌被切分為固定大小的段 (segment)。對已關閉的段進行壓縮 (compaction)——丟棄重複的鍵,只保留每個鍵的最新值。
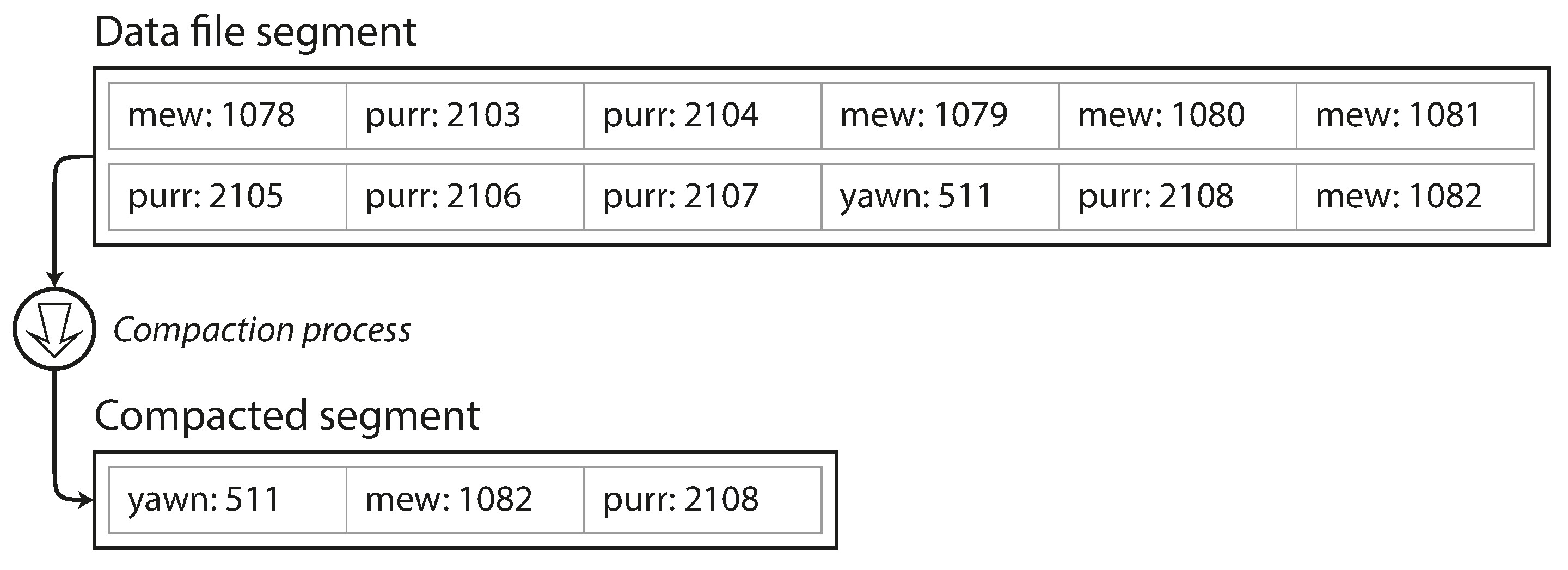
Figure 3-2: 鍵值更新日誌的壓縮
壓縮後的段通常變得更小,因此可以同時將多個段合併 (merge) 為新的段。合併在背景執行緒進行,期間舊段仍可正常服務讀寫請求。合併完成後切換到新段,舊段即可刪除。

Figure 3-3: 同時進行壓縮與段合併
實作細節#
實務中需要考慮的重要問題:
| 議題 | 解決方式 |
|---|---|
| 檔案格式 | 使用二進位格式(先編碼字串長度再接原始字串)比 CSV 更快更簡潔 |
| 刪除記錄 | 追加一筆特殊的墓碑記錄 (tombstone),合併時丟棄該鍵的所有舊值 |
| 崩潰恢復 | Bitcask 在磁碟上儲存雜湊表的快照,避免重新掃描整個段檔案 |
| 部分寫入 | 使用校驗碼 (checksum) 偵測並忽略損壞的記錄 |
| 並行控制 | 通常只有一個寫入執行緒;段檔案為不可變的,可被多個執行緒同時讀取 |
追加式設計的優點與限制#
追加式日誌的優點:循序寫入遠快於隨機寫入(無論是 HDD 或 SSD);不可變的段檔案讓並行控制和崩潰恢復更簡單;合併舊段可避免檔案碎片化。
但雜湊表索引有兩個根本限制:
- 雜湊表必須放進記憶體。若鍵的數量超過可用 RAM,理論上可以在磁碟上維護雜湊表,但磁碟上的雜湊表需要大量隨機 I/O、擴容困難、且雜湊碰撞處理複雜
- 範圍查詢效率低落。例如無法有效掃描
kitty00000到kitty99999之間的所有鍵,只能逐一查找
SSTables 與 LSM-Trees#
Sorted String Table (SSTable)#
如果我們要求段檔案中的鍵值對按鍵排序,就得到了 SSTable (Sorted String Table)。相較於雜湊索引的段,SSTable 有三大優勢:
1. 合併更高效:採用類似合併排序 (mergesort) 的方法,同時讀取多個輸入檔案,依排序順序輸出最小的鍵。若同一鍵出現在多個段中,保留最新段的值。

Figure 3-4: 合併多個 SSTable 段,只保留每個鍵的最新值
2. 不需在記憶體中保存所有鍵:只需一個稀疏索引 (sparse index),每隔幾 KB 記錄一個鍵的偏移量。查找時跳到最接近的已知位置,然後往前掃描即可。
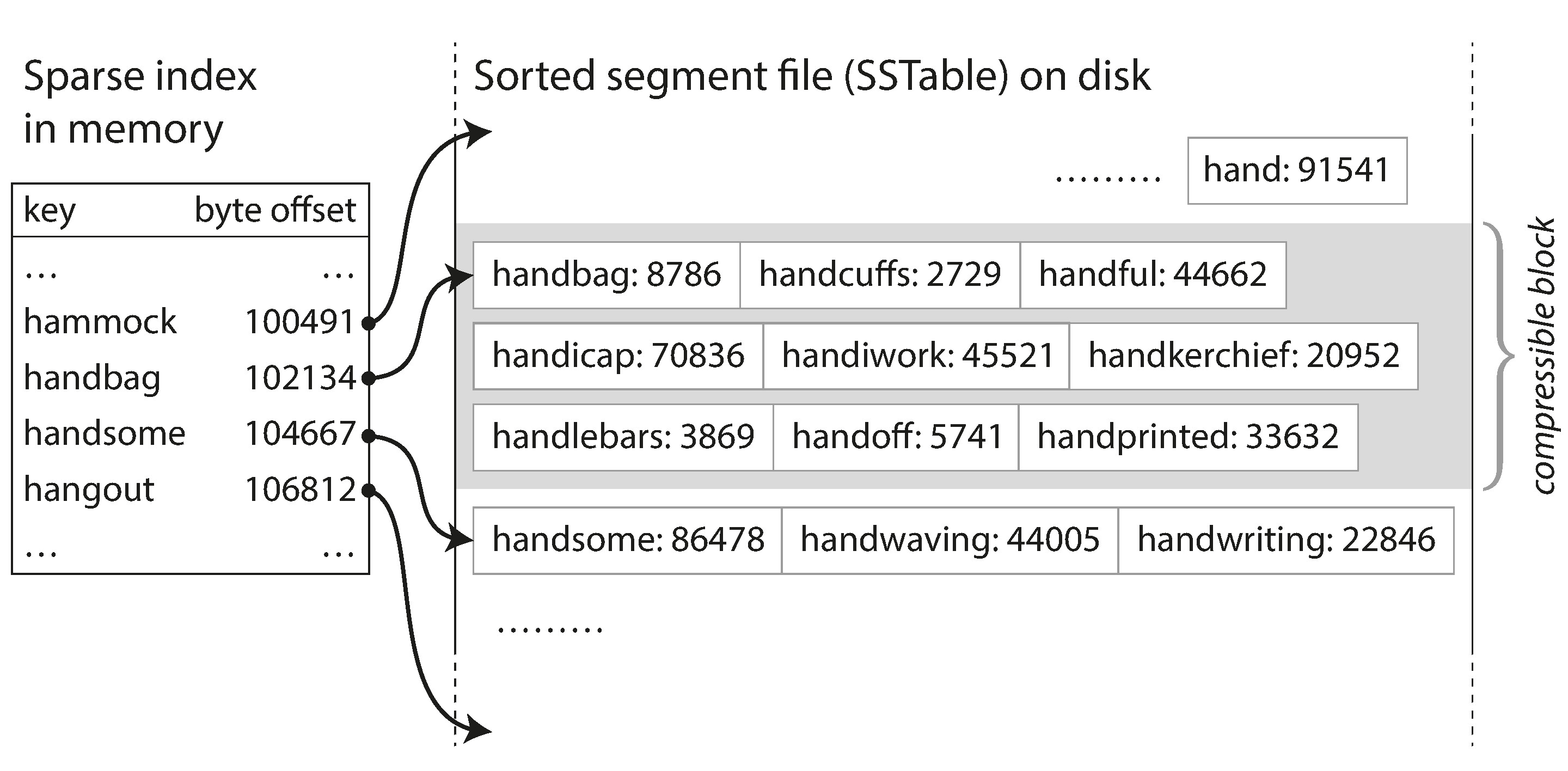
Figure 3-5: 帶有記憶體索引的 SSTable
3. 支援區塊壓縮:由於讀取時需掃描一段範圍,可將記錄分組壓縮後再寫入磁碟,稀疏索引的每個項目指向壓縮區塊的起始位置,節省磁碟空間和 I/O 頻寬。
構建與維護 SSTable#
既然寫入是隨機順序的,如何產生排序好的段?答案是在記憶體中維護排序結構(如紅黑樹或 AVL 樹),稱為 memtable:
- 寫入時先加到 memtable
- 當 memtable 超過閾值(通常數 MB),寫出為 SSTable 檔案,同時開一個新的 memtable 繼續接收寫入
- 讀取時依序查找:memtable → 最新段 → 次新段 → …
- 背景持續執行合併與壓縮
memtable 中的資料尚未寫入磁碟,若資料庫崩潰會遺失。解法是額外維護一個預寫日誌 (WAL),每次寫入立即追加到此日誌。memtable 寫出為 SSTable 後,對應的日誌即可丟棄。
從 SSTable 到 LSM-Tree#
此演算法本質上就是 LevelDB 和 RocksDB 的做法,也被 Cassandra、HBase 採用,靈感源自 Google 的 Bigtable 論文。這種索引結構由 Patrick O’Neil 等人命名為 Log-Structured Merge-Tree (LSM-Tree)。Lucene(Elasticsearch 和 Solr 的底層索引引擎)也使用類似方法儲存其詞彙字典。
效能最佳化#
- Bloom filter:一種記憶體高效的資料結構,可快速判斷某個鍵是否不存在於資料庫中,避免對不存在的鍵進行多層無謂的磁碟讀取
- 壓縮策略:常見有 size-tiered compaction(較新較小的 SSTable 合併為較大的)和 leveled compaction(鍵範圍被分割到不同層級,壓縮更漸進、佔用更少磁碟空間)。LevelDB/RocksDB 使用 leveled,HBase 使用 size-tiered,Cassandra 兩者皆支援
B-Trees#
B-tree 是最廣泛使用的索引結構,自 1970 年問世以來一直是幾乎所有關聯式資料庫的標準實作。與 SSTable 相同,B-tree 也按鍵排序,支援高效的鍵值查找和範圍查詢,但設計哲學截然不同。
B-tree 將資料庫分解為固定大小的頁面 (page)(通常 4 KB),每次讀寫一個頁面,與底層硬體的區塊設計一致。頁面之間透過位址引用構成樹狀結構。
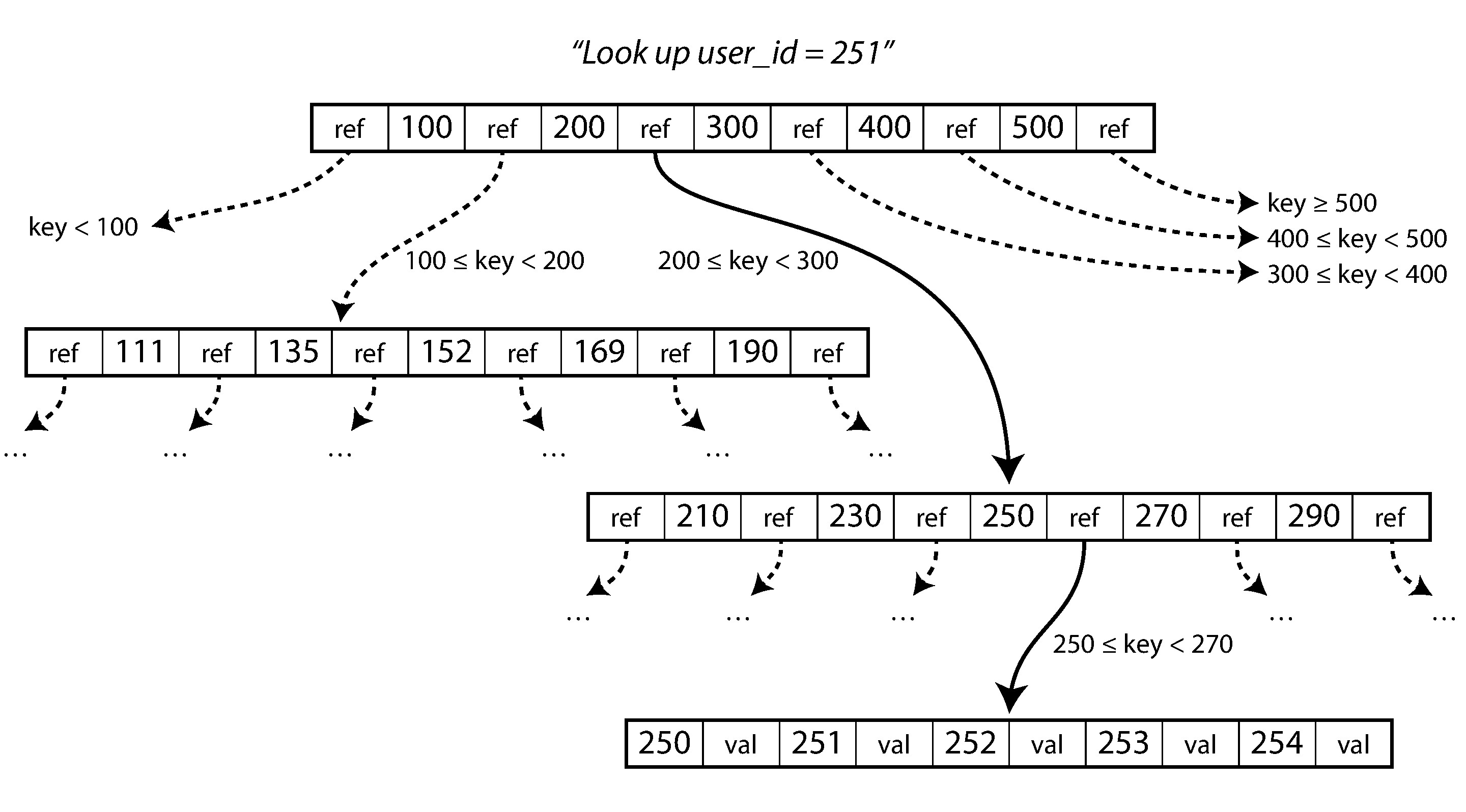
Figure 3-6: 使用 B-tree 索引查找鍵值
- 根頁面是查找的起點,包含若干鍵和子頁面引用
- 每個子頁面負責一段連續的鍵範圍,引用之間的鍵標示範圍邊界
- 最終到達葉頁面 (leaf page),包含實際的值或指向值所在位置的引用
- 分支因子 (branching factor):一個頁面中的子引用數量,實務上通常達數百
當新增的鍵使頁面空間不足時,頁面會被分裂 (split) 為兩個半滿的頁面,父頁面同步更新。
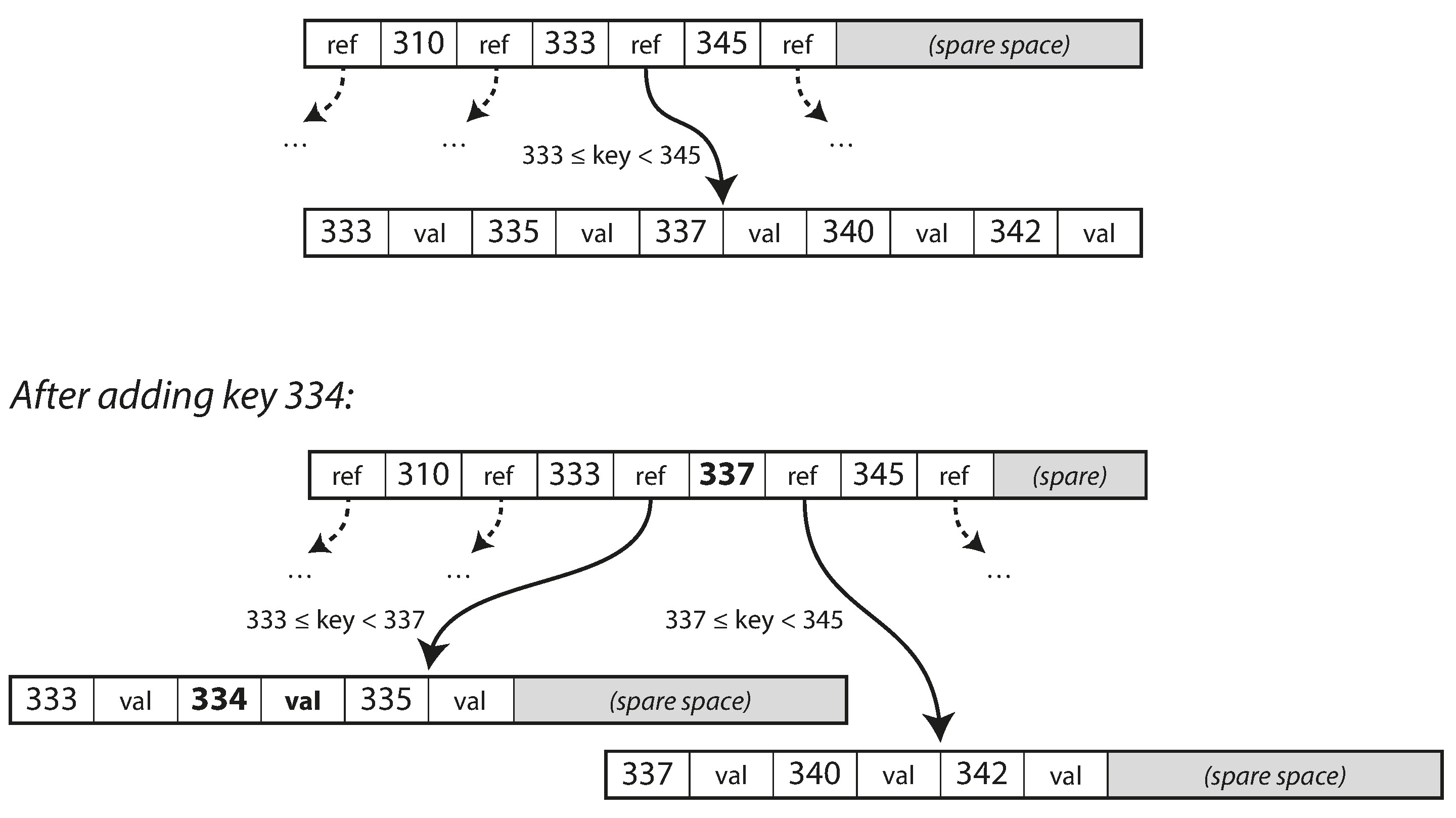
Figure 3-7: 透過分裂頁面來擴展 B-tree
B-tree 的深度為 O(log n),大多數資料庫只需 3-4 層。一棵 4 層的 B-tree(4 KB 頁面、分支因子 500)即可儲存高達 256 TB 的資料。
使 B-tree 可靠#
B-tree 的寫入操作是原地覆寫 (overwrite in place),這與 LSM-tree 的追加式設計形成鮮明對比。頁面分裂需要同時寫入多個頁面,若中途崩潰可能導致索引損壞。因此 B-tree 實作通常搭配 WAL (Write-Ahead Log),也稱為 redo log:所有修改必須先寫入 WAL,再套用到樹頁面上。
此外,多執行緒存取 B-tree 時需要閂鎖 (latch)(輕量級鎖)做並行控制——否則執行緒可能看到不一致的樹狀態。相較之下,LSM-tree 在背景進行合併時不干擾查詢,並透過原子性地替換舊段來避免此問題。
B-tree 最佳化技巧#
- 使用 copy-on-write 取代原地覆寫(如 LMDB),修改過的頁面寫到新位置,同時建立新的父頁面指向它
- 縮寫鍵以節省頁面空間,提高分支因子、減少樹的層數(即 B+ tree 的概念)
- 嘗試讓葉頁面在磁碟上循序排列,減少範圍掃描時的磁碟搜尋次數
- 葉頁面新增指向兄弟頁面的引用,便於順序掃描
- 分形樹 (fractal tree) 等變體借鑑了日誌結構的思想來減少磁碟搜尋
LSM-Trees vs B-Trees 比較#
雖然 B-tree 實作通常更成熟,LSM-tree 因其效能特性同樣值得關注。經驗法則是:LSM-tree 通常寫入更快,B-tree 通常讀取更快(LSM-tree 讀取較慢是因為需要檢查多個不同階段的資料結構和 SSTable)。但基準測試往往結果不一致且對工作負載細節敏感,需要以實際資料測試才能做出有效比較。
LSM-Tree 的優勢#
- 寫入放大 (write amplification) 通常較低。B-tree 每筆資料至少寫兩次(WAL + 頁面本身),且即使只改幾個位元組也要寫整個頁面。LSM-tree 雖然也因壓縮與合併而多次重寫,但循序寫入壓縮過的 SSTable 通常更高效。寫入放大在 SSD 上尤其值得關注,因為 SSD 的寫入次數有限
- 在 HDD 上循序寫入遠快於隨機寫入,LSM-tree 的寫入吞吐量因此更高
- LSM-tree 壓縮率更好、檔案更小,因為它定期重寫以消除碎片化,而 B-tree 的頁面分裂可能留下未使用的空間。更緊湊的資料表示能在可用的 I/O 頻寬內處理更多讀寫請求
LSM-Tree 的劣勢#
- 壓縮過程可能干擾正常讀寫,造成高百分位數延遲。B-tree 的延遲更可預測
- 在高寫入吞吐量下,壓縮可能跟不上寫入速度,導致未合併的段持續累積、磁碟空間耗盡、讀取變慢。需要明確的監控來偵測此狀況
- B-tree 中每個鍵只存在於索引的一個位置,有利於實作強交易語意(如使用鎖來實現交易隔離)
其他索引結構#
次要索引#
次要索引 (secondary index) 的鍵不唯一,可透過兩種方式處理:讓索引值存放符合條件的列識別符清單(類似倒排索引),或在鍵後面附加列識別符使其唯一。B-tree 和 LSM-tree 都可用作次要索引。
在索引中儲存值#
索引的值可以是實際的列資料,也可以是指向堆檔案 (heap file) 的引用。堆檔案以無特定順序儲存資料,多個次要索引可以同時引用堆檔案中的位置,避免資料重複。當更新值但不改變鍵時,若新值不比舊值大,可以原地覆寫;若更大,可能需要搬移並在舊位置留下轉發指標 (forwarding pointer)。
叢集索引 (clustered index) 將資料直接存在索引中(如 MySQL InnoDB 的主鍵索引,次要索引則引用主鍵而非堆檔案位置)。覆蓋索引 (covering index) 則只將部分欄位存在索引中,讓某些查詢可以僅靠索引就完成(此時稱索引「覆蓋」了該查詢),不需回查原始資料。叢集和覆蓋索引能加速讀取,但需要額外的儲存空間和寫入開銷。
多欄索引#
- 串接索引 (concatenated index):將多個欄位串接為一個鍵,類似電話簿的(姓, 名)索引。查找「姓=張」有效,但查找「名=明」無效
- 多維索引:用於地理空間查詢等需要同時篩選多個維度的場景。例如餐廳搜尋需要同時篩選緯度和經度範圍,標準的 B-tree 或 LSM-tree 只能在一個維度上篩選。一種方法是使用空間填充曲線 (space-filling curve) 將二維轉為一維後用 B-tree 索引;更常見的做法是使用 R-tree 等專門的空間索引結構(如 PostGIS 即基於 R-tree)
- 多維索引不限於地理位置,也可用於顏色搜尋 (RGB 三維) 或天氣資料的 (日期, 溫度) 雙維查詢。HyperDex 即採用此技術
全文搜尋與模糊索引#
全文搜尋引擎(如 Lucene)需要支援同義詞擴展、詞形變化、拼寫容錯等功能。Lucene 使用類似 SSTable 的結構儲存詞彙字典,記憶體中的索引使用有限狀態自動機 (finite state automaton),可轉換為 Levenshtein 自動機支援編輯距離內的高效搜尋。
記憶體資料庫#
隨著 RAM 成本下降,將整個資料集放在記憶體中變得可行。記憶體資料庫(如 Redis、VoltDB、MemSQL)的效能優勢並非來自「不需讀取磁碟」(因為 OS 的檔案系統快取已經在做這件事),而是來自省去了將記憶體資料結構編碼為磁碟格式的開銷。
記憶體資料庫仍可透過 WAL、定期快照或跨機器複製來實現持久性。此外,記憶體資料庫還能提供磁碟索引難以實現的資料模型(如 Redis 的優先佇列和集合)。研究中的 anti-caching 方法可將最少使用的資料驅逐到磁碟,讓記憶體資料庫支援超出可用記憶體的資料集。
交易處理與分析#
OLTP vs OLAP#
早期的資料庫寫入通常對應一筆商業交易(銷售、下單、發薪等),因此「交易 (transaction)」一詞沿用至今——儘管現代資料庫早已用於各種非金融場景。交易處理的意思是允許客戶端進行低延遲的讀寫操作,而非定期執行的批次處理。
資料庫的使用模式可大致分為兩類:
| 特性 | OLTP | OLAP |
|---|---|---|
| 讀取模式 | 按鍵取少量記錄 | 大量記錄的聚合 |
| 寫入模式 | 隨機存取、低延遲 | 批次匯入 (ETL) 或事件串流 |
| 主要使用者 | 終端使用者 / 應用程式 | 內部分析師 |
| 資料代表 | 資料的最新狀態 | 歷史事件記錄 |
| 資料量 | GB 到 TB | TB 到 PB |
資料倉儲 (Data Warehousing)#
企業通常有數十個 OLTP 系統(網站、POS、倉儲、物流等),這些系統需要高可用和低延遲,不適合讓分析師在上面跑耗費資源的分析查詢。
資料倉儲是獨立的資料庫,包含所有 OLTP 系統資料的唯讀副本。資料透過 ETL (Extract-Transform-Load) 流程匯入:從 OLTP 資料庫提取(定期資料傾印或持續更新串流)、轉換為適合分析的 schema、清理後載入倉儲。
資料倉儲的最大優勢在於可以獨立於 OLTP 系統進行分析存取模式的最佳化。前半章討論的索引演算法適合 OLTP,但不擅長回答分析查詢。
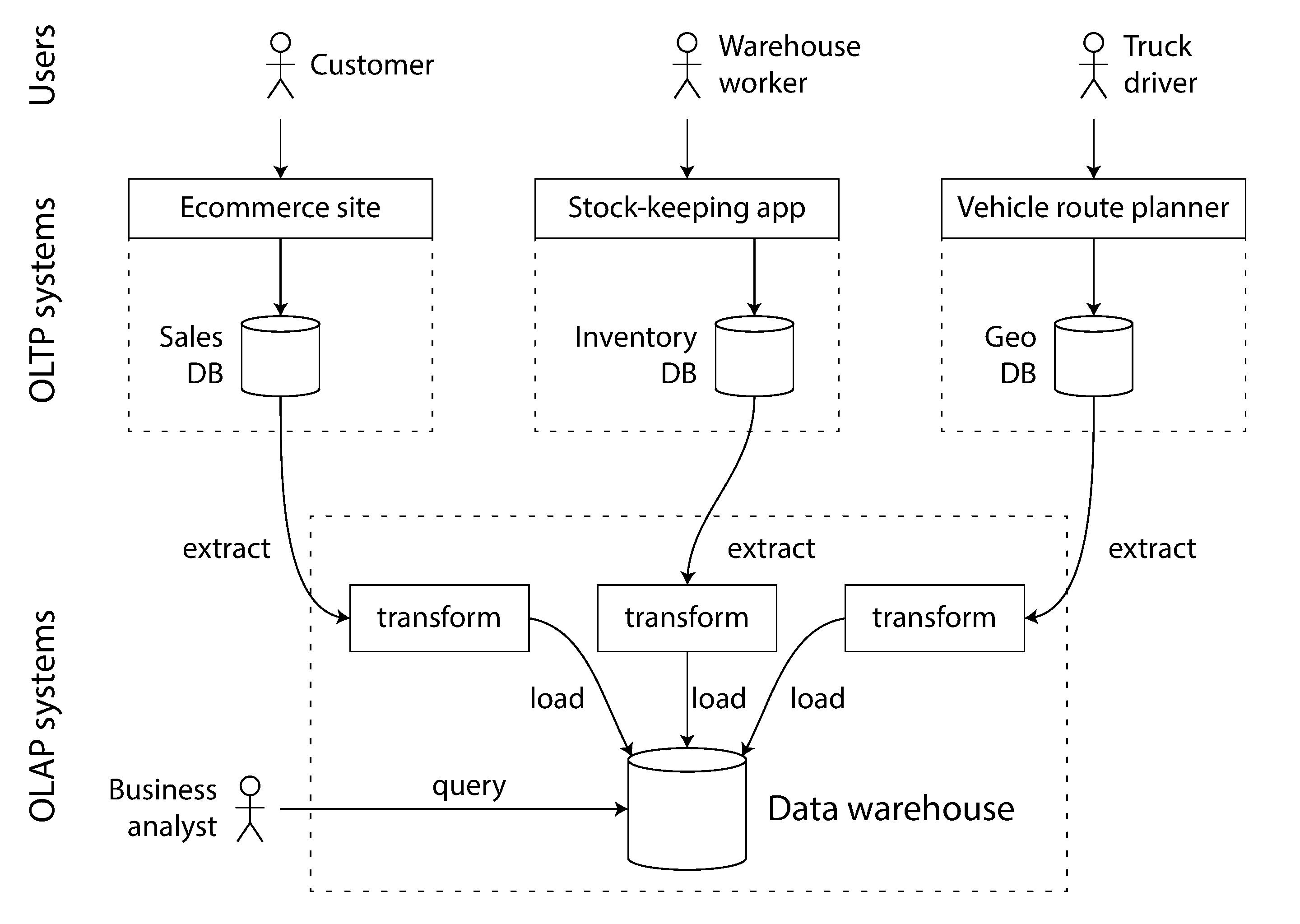
Figure 3-8: ETL 流程簡化示意圖
雖然資料倉儲和 OLTP 資料庫都使用 SQL 介面,但內部的儲存引擎截然不同。許多供應商已專注於其中一種工作負載。商業方案如 Teradata、Vertica、Amazon Redshift;開源方案如 Apache Hive、Spark SQL、Presto 等。
星型與雪花型架構#
資料倉儲最常使用星型架構 (star schema),也稱為維度建模 (dimensional modeling)。其核心是事實表 (fact table),每一列代表一個事件(如一筆銷售交易)。事實表的欄位包括屬性(如售價、成本)和指向維度表 (dimension table) 的外鍵。
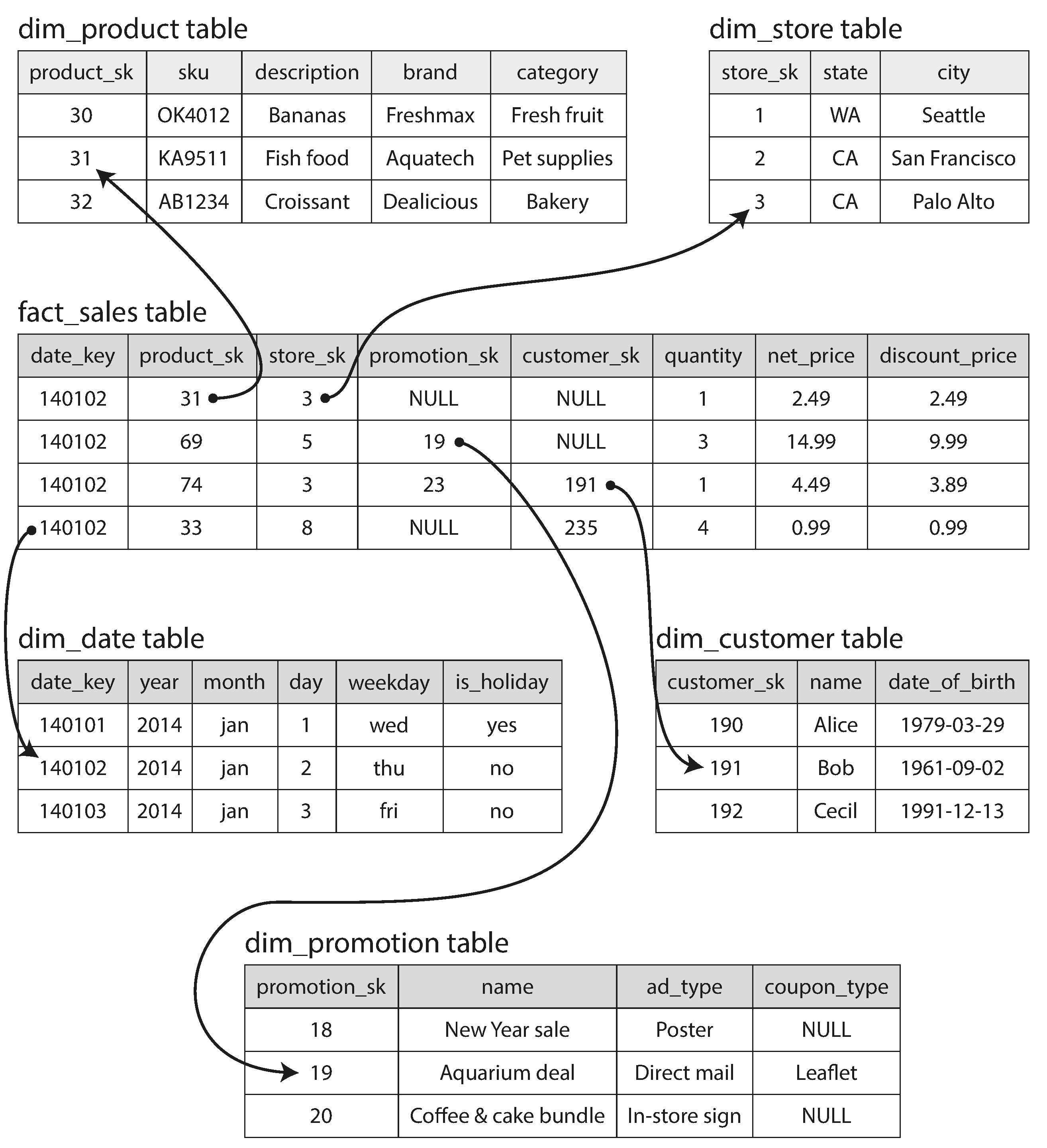
Figure 3-9: 資料倉儲中的星型架構範例
維度表描述事件的 who、what、where、when、how、why(如產品資訊、商店資訊、日期資訊等)。事實表居中、維度表環繞,像星星的光芒——這就是「星型」名稱的由來。
「星型」名稱的由來是:視覺化表格關係時,事實表在中央、維度表環繞,如同星星的光芒。即使日期和時間也常以維度表表示,以便編碼額外資訊(如公共假日),讓查詢能區分假日與非假日的銷售。
雪花型架構 (snowflake schema) 是星型的變體,將維度進一步拆分為子維度(如品牌表和類別表從產品表中獨立出來,產品表以外鍵引用它們)。雪花型更正規化,但星型因為對分析師來說更簡單直觀而更常被偏好。
在典型的資料倉儲中,事實表通常有超過 100 個欄位(甚至數百個),維度表也可能非常寬——例如商店維度表可能包含哪些服務可用、是否有烘焙坊、面積、開店日期、距最近高速公路的距離等所有可能與分析相關的元資料。
列式儲存 (Column-Oriented Storage)#
事實表可能有數兆筆資料和 PB 級的容量,但分析查詢通常只存取其中 4-5 個欄位。在傳統的行式儲存中,即使只需要幾個欄位,也必須從磁碟載入整列(超過 100 個欄位),再過濾不需要的——這非常浪費。
列式儲存的核心思想:不把同一列(row)的所有欄位存在一起,而是把同一個欄位(column)的所有值存在一起。查詢時只需讀取用到的欄位檔案,大幅減少 I/O。
列式儲存的概念在關聯式模型中最容易理解,但同樣適用於非關聯式資料。例如 Parquet 是一種支援文件資料模型的列式儲存格式,源自 Google 的 Dremel。
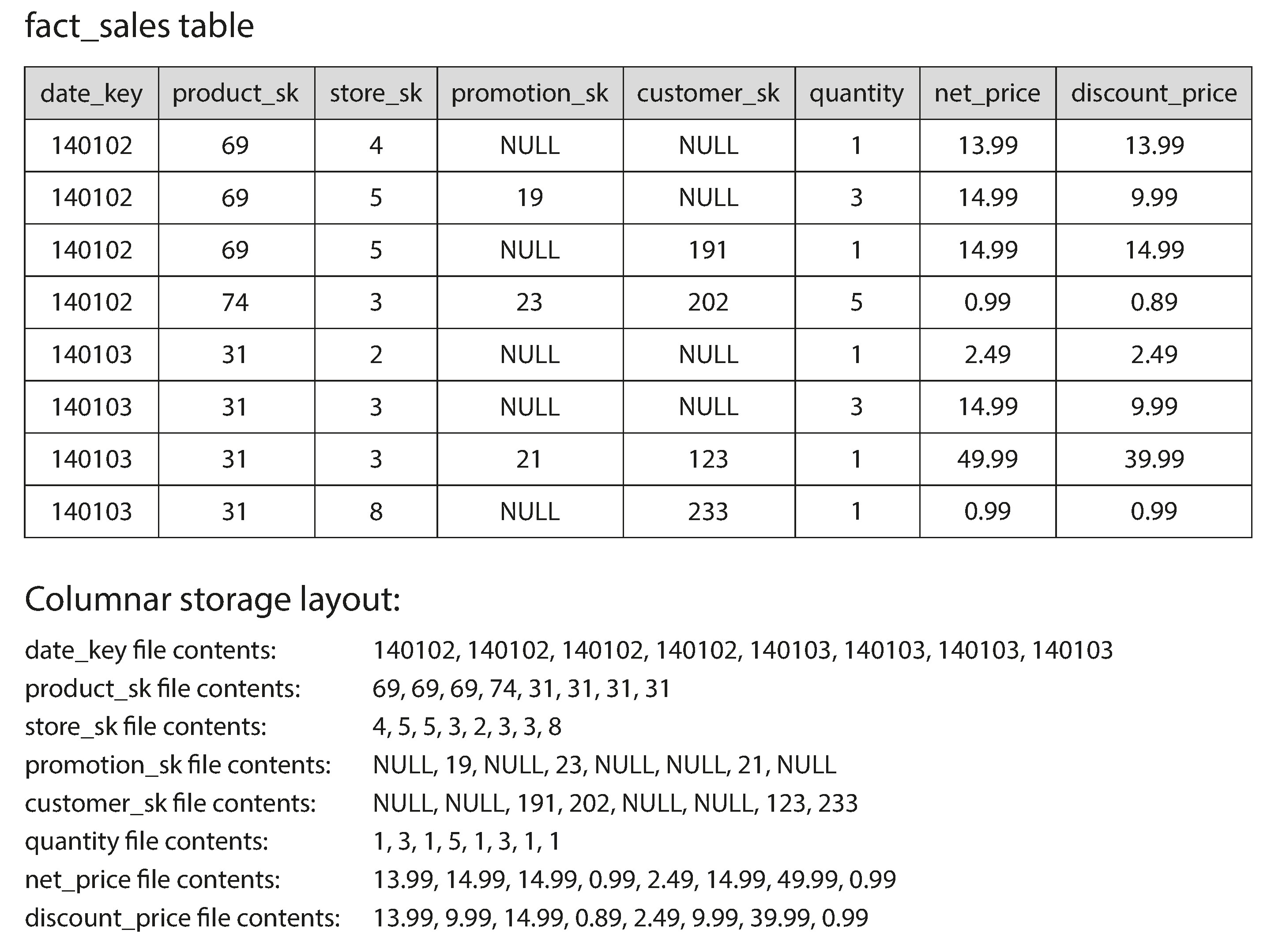
Figure 3-10: 按列而非按行儲存關聯式資料
列式儲存依賴一個關鍵假設:每個欄位檔案中的列必須以相同順序排列。要重組某一列的完整資料,只需從每個欄位檔案取出第 k 筆項目即可。
列壓縮 (Column Compression)#
列式儲存特別適合壓縮,因為同一欄位的值通常高度重複。點陣圖編碼 (bitmap encoding) 是資料倉儲中特別有效的壓縮技術:

Figure 3-11: 單一列的壓縮點陣圖索引儲存
對於有 n 個不同值的欄位,建立 n 個點陣圖,每個點陣圖有一個位元對應每一列。若 n 很小,每列只需一個位元;若 n 較大導致點陣圖稀疏,可進一步使用遊程編碼 (run-length encoding) 壓縮。
點陣圖索引特別適合資料倉儲的典型查詢:
WHERE product_sk IN (30, 68, 69):載入三個點陣圖,計算 bitwise ORWHERE product_sk = 31 AND store_sk = 3:載入兩個點陣圖,計算 bitwise AND
記憶體頻寬與向量化處理#
分析查詢的瓶頸不只是磁碟到記憶體的頻寬,還有記憶體到 CPU 快取的頻寬。列式儲存的壓縮資料能更好地利用 CPU L1 快取,在緊密迴圈中高效迭代,並運用 SIMD 指令直接對壓縮的列資料進行位元運算,這種技術稱為向量化處理 (vectorized processing)。
列式儲存中的排序#
列式儲存可以按特定欄位排序(但必須整列一起排序,以維持欄位間的對應關係)。管理員可根據常見查詢選擇排序鍵,例如先按日期排序再按產品排序,讓日期範圍查詢只需掃描一小部分資料。排序也有助於壓縮——排序後的第一個鍵會產生大量重複值,遊程編碼可將其壓縮到極小。
排序對壓縮的幫助在第一排序鍵上最為顯著,後續的排序鍵效果遞減。即便如此,前幾個排序鍵的壓縮改善仍然是整體的勝出。
Vertica 更進一步:在不同副本上使用不同的排序順序。由於資料本來就需要複製到多台機器以防故障,不如讓每份副本使用不同的排序方式,查詢時選用最適合的版本。這類似於行式儲存中的多重次要索引,但差別在於列式儲存中沒有指向其他位置的指標,只有包含值的欄位。
寫入列式儲存#
列式儲存的壓縮和排序讓讀取極快,但寫入更困難——無法像 B-tree 那樣原地更新壓縮過的欄位。若要在排序表格中間插入一列,必須重寫所有欄位檔案。
解法是借用 LSM-tree 的思想:寫入先進入記憶體中的排序結構(不論記憶體中是行式或列式),累積到一定量後批次合併到磁碟上的列式檔案中。查詢需要同時檢查磁碟上的欄位資料和記憶體中的最新寫入,但查詢最佳化器會對使用者隱藏此區分。這正是 Vertica 的做法。
物化聚合:資料立方體與物化檢視#
物化檢視 (materialized view) 是將查詢結果實際寫入磁碟的副本(不同於虛擬檢視在查詢時即時展開)。當底層資料變更時需要更新物化檢視,因此會增加寫入成本。在讀取密集的資料倉儲中,這個取捨通常值得。
資料立方體 (data cube / OLAP cube) 是物化檢視的一種特例:按不同維度預先計算聚合值。
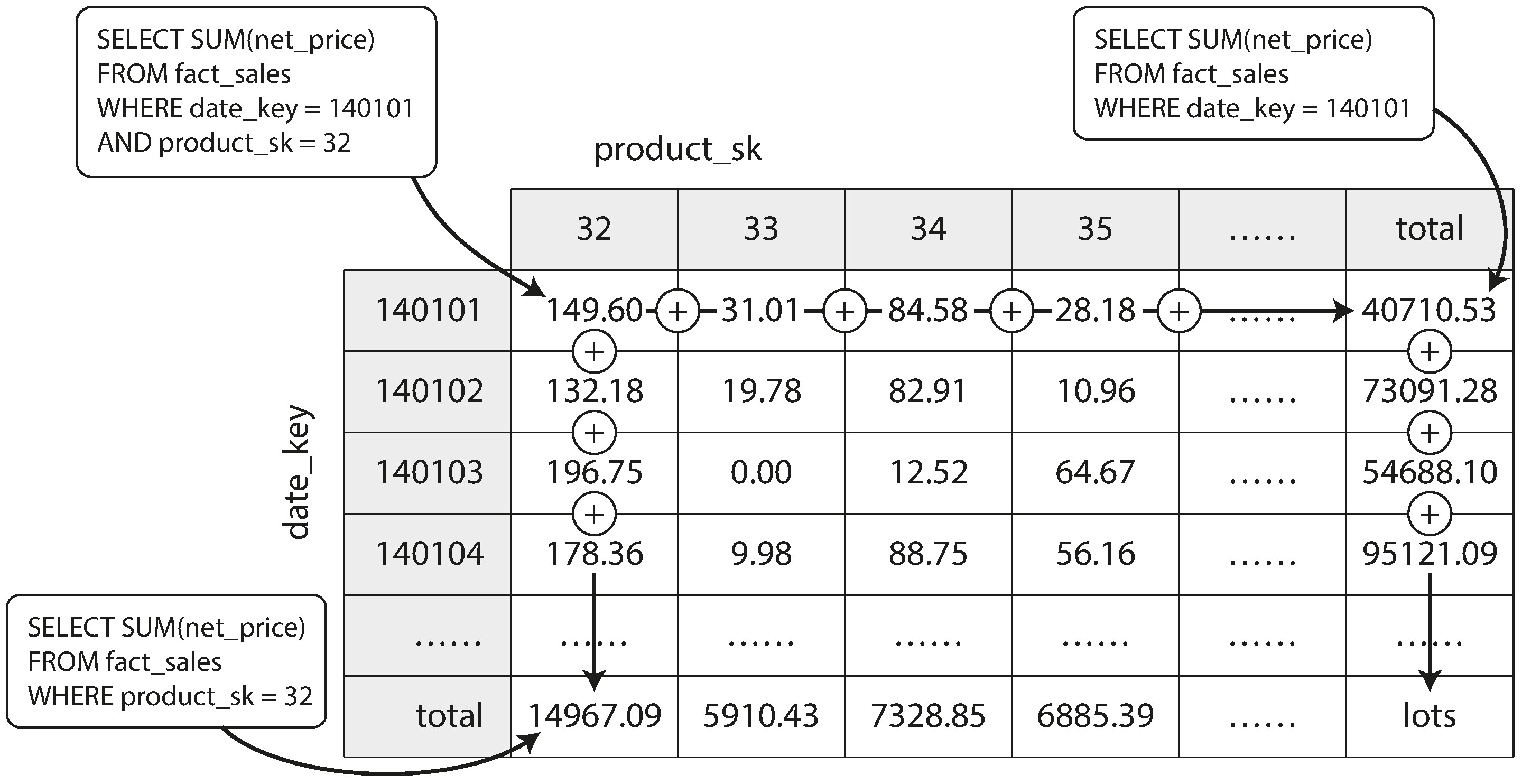
Figure 3-12: 資料立方體的二維聚合
以日期和產品為兩個維度的二維表為例,每個格子包含對應日期-產品組合的聚合值(如 SUM)。沿著列或欄加總,可得到按單一維度彙總的結果。實際的事實表可能有五個以上的維度,形成高維度的超立方體。
資料立方體讓某些查詢極快(因為已預先計算),但喪失了查詢原始資料的彈性——例如無法計算「售價超過 100 元的銷售佔比」(除非售價是維度之一)。因此大多數資料倉儲會盡可能保留原始資料,僅將資料立方體作為特定查詢的效能加速手段。
本章總結#
儲存引擎分為兩大陣營:
OLTP 儲存引擎有兩大流派:
- 日誌結構流派 (Log-Structured):只允許追加和刪除,永不修改已寫入的檔案。將隨機寫入轉為循序寫入,獲得更高的寫入吞吐量。代表:Bitcask、SSTable/LSM-tree、LevelDB、RocksDB、Cassandra、HBase、Lucene
- 原地更新流派 (Update-in-Place):將磁碟視為固定大小的頁面,可以覆寫。代表:B-tree,幾乎所有主流關聯式資料庫都使用
OLAP 儲存引擎針對分析工作負載設計:
- 查詢需要掃描大量列,索引的重要性下降,資料壓縮和列式儲存成為關鍵
- 資料倉儲使用星型/雪花型架構組織資料
- 列式儲存配合點陣圖編碼、向量化處理等技術,大幅提升分析查詢效能