本章摘要: 比較關聯式、文件式與圖三種資料模型的適用場景與設計取捨,並探討 SQL、MapReduce、Cypher、SPARQL 等查詢語言如何從宣告式與命令式兩種哲學出發,影響應用程式的資料存取方式。
資料模型的重要性#
資料模型(Data Model)可能是軟體開發中最重要的決策之一,因為它深刻影響了軟體的寫法,以及我們對問題的思考方式。大多數應用程式透過層層堆疊的資料模型來建構:
| 層級 | 說明 |
|---|---|
| 應用層 | 開發者將真實世界建模為物件、資料結構與 API |
| 儲存層 | 以通用資料模型(JSON、關聯式表格、圖)來表示這些結構 |
| 資料庫引擎層 | 將上述模型轉換為記憶體、磁碟上的位元組表示 |
| 硬體層 | 以電流、光脈衝、磁場來表示位元組 |
每一層都透過提供乾淨的資料模型,隱藏下層的複雜度。選擇合適的資料模型至關重要——不同模型對不同操作的支援程度差異極大。
關聯式模型 vs 文件模型#
關聯式模型的歷史#
今日最知名的資料模型是 SQL,基於 Edgar Codd 於 1970 年提出的關聯式模型(Relational Model):資料組織為 relations(表格),每個 relation 是 tuples(列)的無序集合。
關聯式資料庫的根源在於商業資料處理——交易處理(銷售、銀行、航空訂位)與批次處理(發票、薪資、報表)。在 1970-80 年代,它擊敗了網路模型(Network Model)與階層式模型(Hierarchical Model),至今仍主導著 Web 應用程式的資料儲存。
NoSQL 的誕生#
2010 年代,NoSQL 成為挑戰關聯式模型的最新嘗試。這個名稱源自 2009 年一個 Twitter 標籤,後來被重新詮釋為 Not Only SQL。驅動 NoSQL 採用的因素包括:
- 需要超越關聯式資料庫的可擴展性(大型資料集、高寫入吞吐量)
- 偏好開源軟體而非商業資料庫產品
- 關聯式模型不善支援的特殊查詢操作
- 對關聯式 schema 限制的不滿,渴望更動態、表達力更強的資料模型
未來關聯式資料庫很可能會與各種非關聯式資料儲存並行使用,這個概念稱為多語持久化(Polyglot Persistence)。
物件-關聯不匹配(Object-Relational Mismatch)#
現代應用程式多以物件導向語言開發,這導致了物件與關聯式表格之間的阻抗不匹配(Impedance Mismatch)——需要一個笨拙的轉譯層。ORM 框架(如 ActiveRecord、Hibernate)能減少樣板程式碼,但無法完全消除兩種模型的差異。
以 LinkedIn 個人檔案為例,使用者有姓名(出現一次)以及多筆工作經歷、教育背景、聯絡資訊(一對多關係)。在關聯式模型中,這些需要拆分到多個表格:
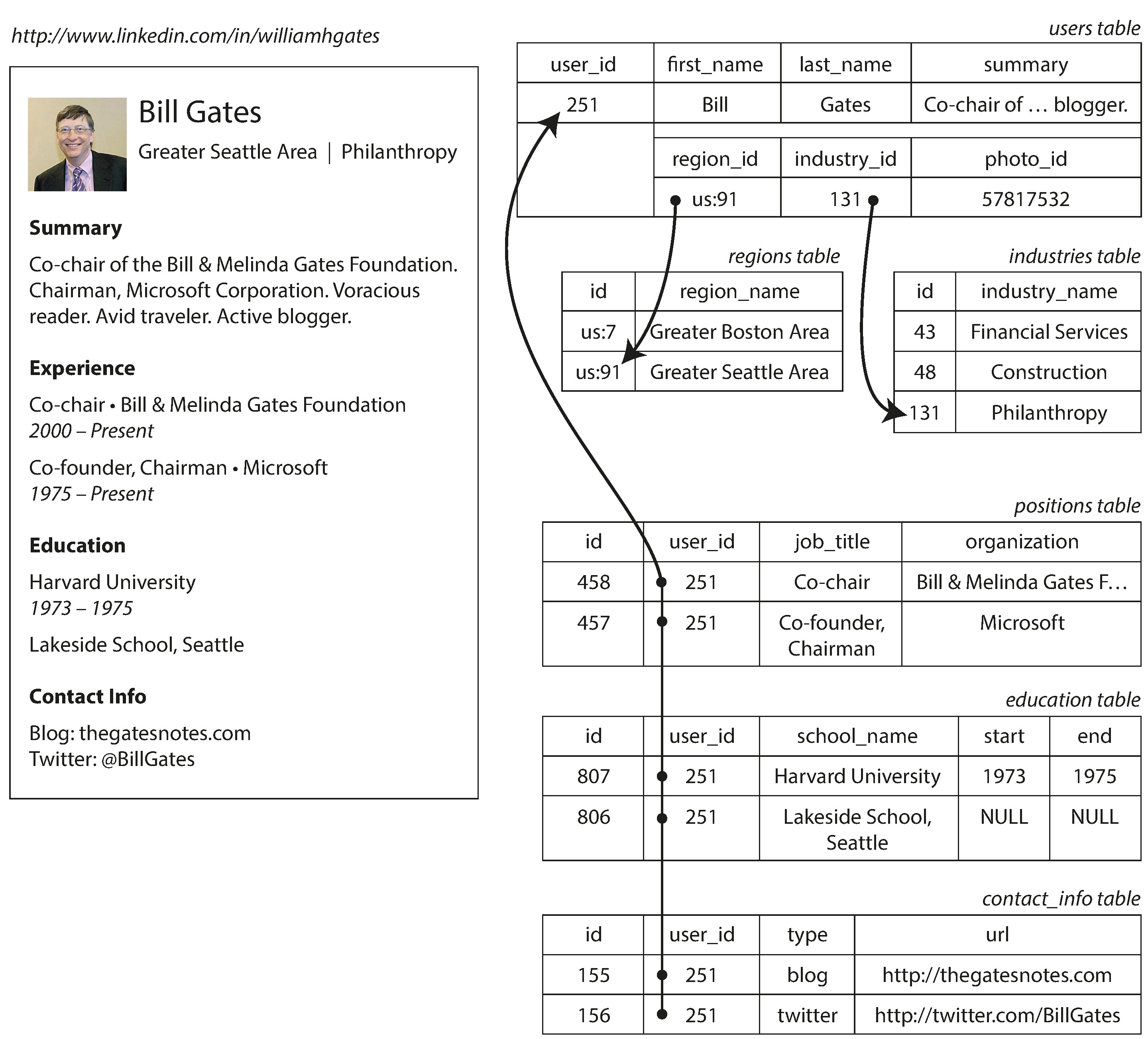
Figure 2-1: 使用關聯式架構表示 LinkedIn 個人檔案
相比之下,JSON 表示法將所有資訊集中在一份文件中,具有更好的資料局部性(Data Locality)——一次查詢即可取得所有資料,不需多表 JOIN。一對多關係自然形成樹狀結構,JSON 讓這個結構一目了然:
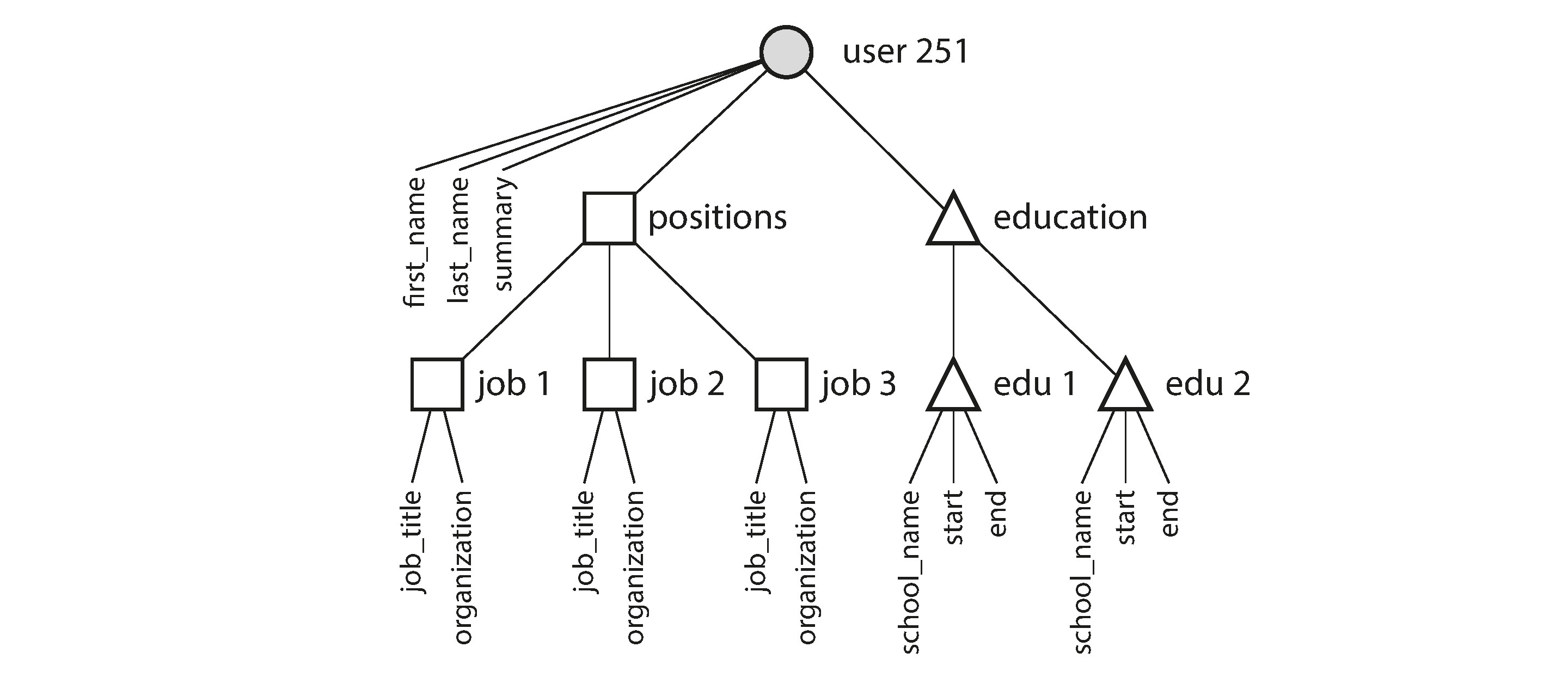
Figure 2-2: 一對多關係形成的樹狀結構
多對一與多對多關係#
使用 ID 而非純文字來表示地區、產業等欄位,是正規化(Normalization)的關鍵思想——消除重複,將人類可讀的資訊只儲存在一個地方。ID 的優勢在於它對人類無意義,因此永遠不需要改變。
然而,正規化需要多對一關係(多人住在同一地區、多人在同一產業),這在文件模型中並不自然。關聯式資料庫透過 ID 引用其他列,JOIN 很容易;文件資料庫的 JOIN 支援通常較弱。
隨著功能增加,資料往往變得越來越互相關聯。例如,組織和學校可能不只是字串,而是指向實體的參照;推薦功能需要在不同使用者間建立連結:

Figure 2-3: 公司名稱不只是字串,而是指向公司實體的連結
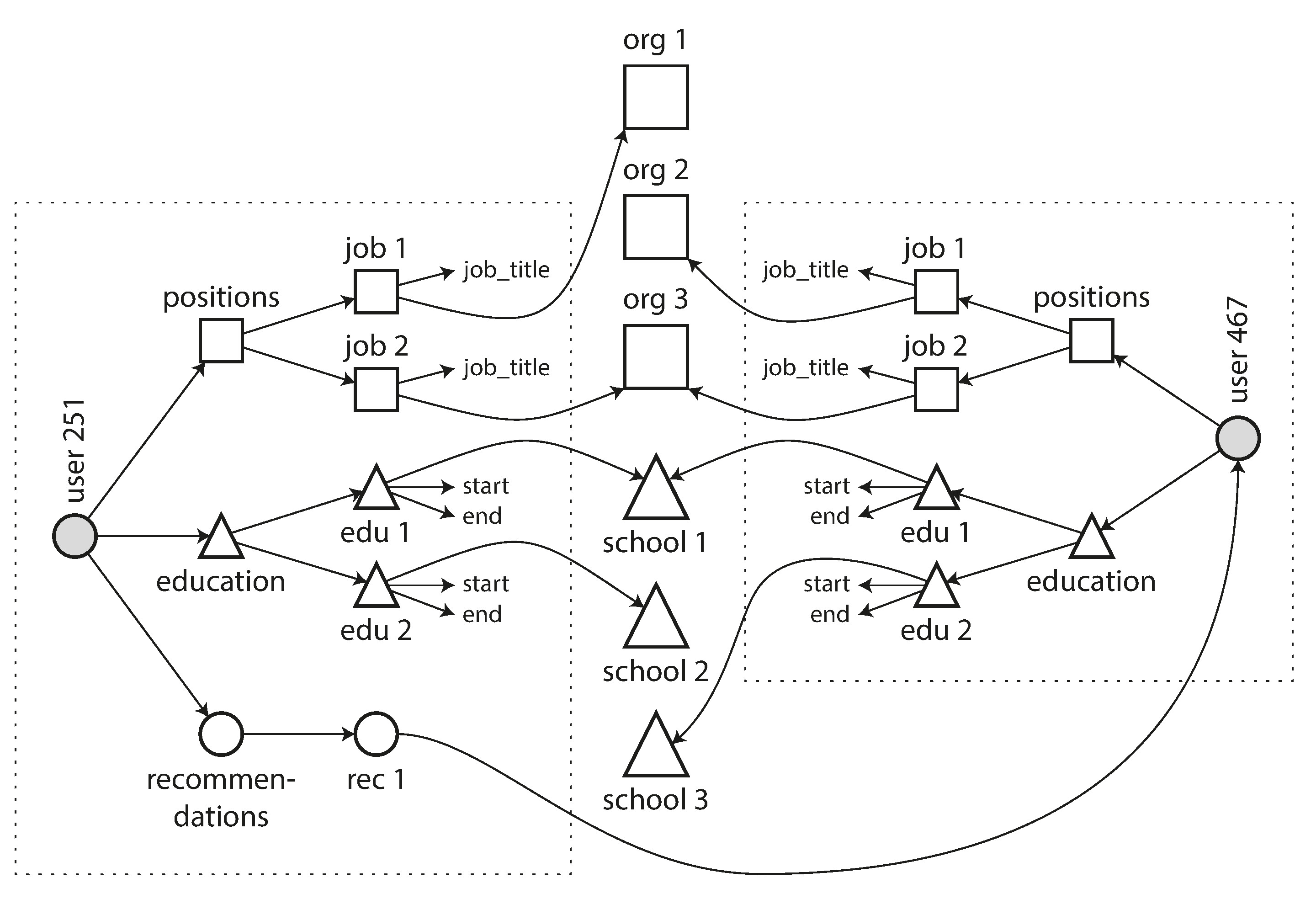
Figure 2-4: 使用多對多關係擴展履歷資料
文件資料庫是否在重蹈歷史?#
1970 年代最流行的 IBM IMS 使用階層式模型,與今日文件資料庫的 JSON 模型驚人地相似——都以巢狀記錄的樹狀結構表示資料。IMS 處理一對多關係很好,但多對多關係困難且不支援 JOIN。
為解決階層式模型的限制,出現了兩個方案:
- 網路模型(CODASYL Model):允許一筆記錄有多個父節點,透過存取路徑(Access Path)來導航資料。但程式碼複雜、不靈活,修改資料模型代價高昂。
- 關聯式模型:將資料攤平為表格與列,由查詢最佳化器(Query Optimizer)自動決定存取路徑。只需建立一次最佳化器,所有應用程式都能受益。
文件資料庫在巢狀記錄(一對多)方面回歸了階層式模型,但在多對一和多對多關係上,文件資料庫與關聯式資料庫並無根本差異——都透過唯一識別碼引用相關項目(關聯式稱 foreign key,文件模型稱 document reference),在讀取時透過 JOIN 或後續查詢來解析。
關聯式 vs 文件模型的比較#
哪種模型讓應用程式碼更簡單?
- 如果資料具有文件式結構(一對多的樹狀結構,整棵樹通常一次載入),文件模型是好選擇。關聯式的「拆解」(Shredding)可能導致冗長的 schema 與複雜的程式碼。
- 如果應用程式需要多對多關係,文件模型就不那麼吸引人了。雖然可以透過反正規化來減少 JOIN,但這將一致性維護的複雜度推給了應用程式碼。
- 對於高度互聯的資料,文件模型笨拙,關聯式模型尚可,圖模型最為自然。
Schema 彈性
文件資料庫通常不強制 schema,常被稱為「無 schema」(Schemaless),但更精確的說法是 schema-on-read——資料結構在讀取時隱式解讀。相對地,關聯式資料庫是 schema-on-write——schema 明確且資料庫確保寫入的資料符合 schema。
- Schema-on-read 如同動態型別檢查,適合異質性資料(多種物件型態、外部系統控制的結構)
- Schema-on-write 如同靜態型別檢查,適合結構統一的記錄
查詢的資料局部性
文件通常以單一連續字串儲存。如果應用程式經常需要存取整份文件,這種儲存局部性帶來效能優勢。但局部性優勢僅在需要文件大部分內容時才成立——更新時通常需要重寫整份文件,因此建議保持文件精簡。
資料局部性不限於文件模型。Google Spanner 允許在關聯式模型中宣告表格列交錯嵌套;Bigtable 的 column-family 概念(用於 Cassandra、HBase)也有類似的局部性管理目的。
文件與關聯式的收斂#
兩種模型正在互相靠近:
- 關聯式資料庫(PostgreSQL、MySQL、IBM DB2)紛紛加入 JSON 與 XML 支援,允許在文件內查詢與索引
- 文件資料庫(RethinkDB)支援類似關聯式的 JOIN;部分 MongoDB 驅動程式自動解析文件參照
關聯式與文件模型互為補充。一個同時支援文件式資料處理與關聯式查詢的混合型資料庫,是未來的良好方向。
資料查詢語言#
宣告式 vs 命令式#
關聯式模型引入了新的查詢方式:SQL 是宣告式查詢語言(Declarative),而 IMS 和 CODASYL 使用命令式程式碼(Imperative)。
- 命令式:逐步告訴電腦以特定順序執行特定操作
- 宣告式:只描述想要的資料模式(條件、排序、聚合),由資料庫系統的查詢最佳化器決定如何實現
宣告式語言的優勢:
- 通常更簡潔、更容易使用
- 隱藏實作細節,資料庫可以在不修改查詢的情況下引入效能改進
- 更適合平行執行——只指定結果模式而非演算法,資料庫可自由使用平行實作
宣告式方法的優勢不限於資料庫。在網頁瀏覽器中,CSS(宣告式)遠優於直接用 JavaScript 操作 DOM(命令式)——CSS 更簡潔,且瀏覽器可在不破壞相容性的前提下改進效能。
MapReduce 查詢#
MapReduce 是 Google 推廣的大規模資料處理模型,MongoDB 和 CouchDB 支援其有限形式。它介於宣告式與命令式之間——查詢邏輯以程式碼片段表達,由處理框架反覆呼叫。
以「統計每月鯊魚觀察數量」為例,SQL 一個查詢就能完成,而 MapReduce 需要撰寫兩個精心協調的 JavaScript 函式(map 和 reduce)。這些函式必須是純函式(Pure Function),不能有副作用,這使得資料庫能在任何地方、任何順序執行它們。
MapReduce 的可用性問題在於撰寫兩個函式比撰寫單一查詢困難,且宣告式語言提供更多最佳化機會。因此 MongoDB 2.2 加入了宣告式的 aggregation pipeline——一個 JSON 語法版的 SQL 子集。
NoSQL 系統可能不自覺地重新發明了 SQL,只是換了一層偽裝。這說明宣告式查詢的優勢是跨越資料模型的普遍原則。
圖資料模型#
當資料中的多對多關係非常普遍時,圖模型(Graph Model)是最自然的選擇。圖由兩種物件組成:頂點(Vertex,又稱節點)和邊(Edge,又稱關係)。
常見的圖模型應用場景:
| 場景 | 頂點 | 邊 |
|---|---|---|
| 社群圖譜 | 人 | 誰認識誰 |
| 網頁圖譜 | 網頁 | HTML 連結 |
| 道路或鐵路網路 | 交叉口 | 路段 |
圖模型的強大之處在於能在同一個資料儲存中容納完全不同類型的物件。例如 Facebook 的圖包含人物、地點、事件、打卡、留言等不同頂點類型與多種邊類型。
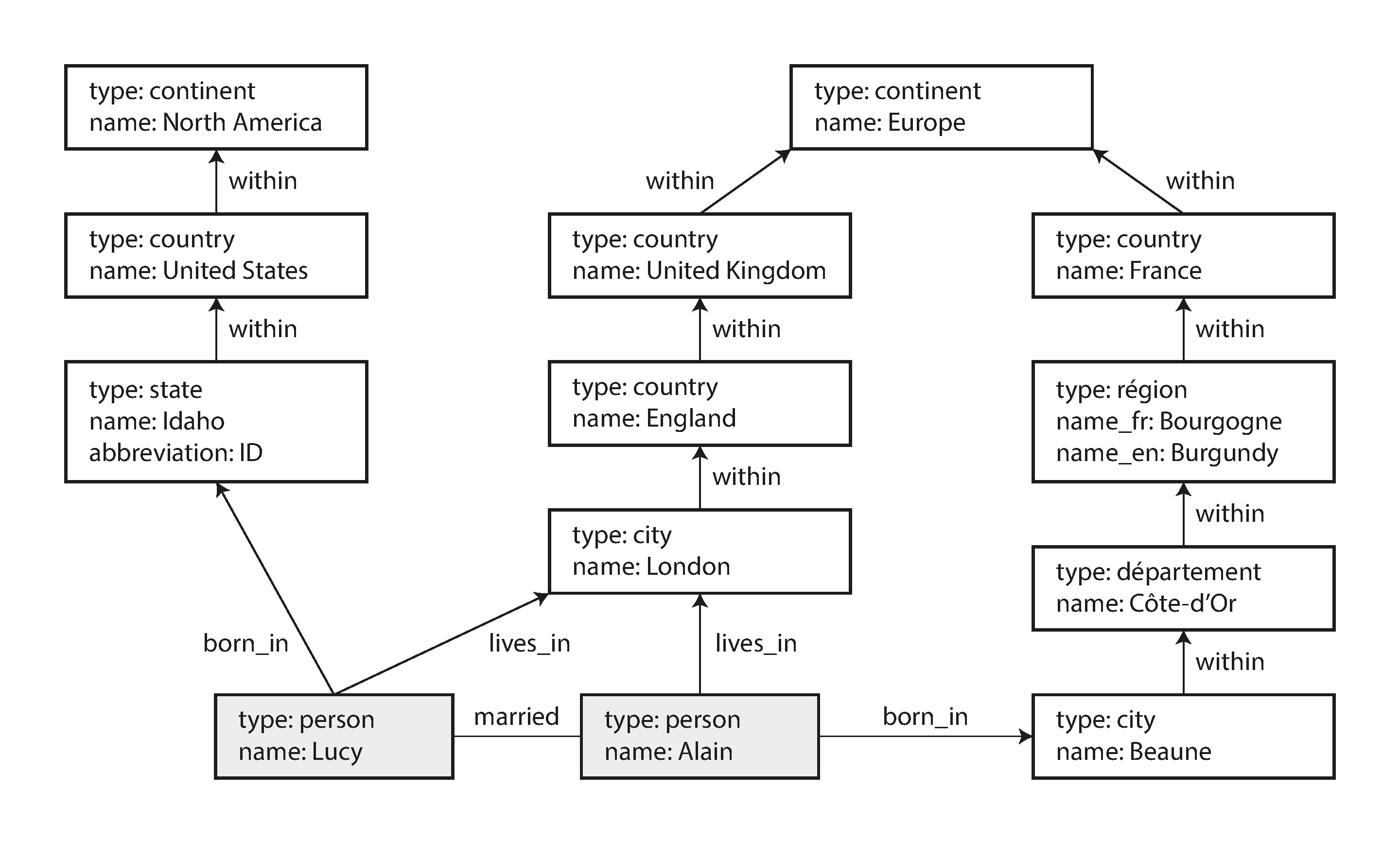
Figure 2-5: 圖結構資料範例
屬性圖(Property Graph)#
在屬性圖模型中(Neo4j、Titan、InfiniteGraph),每個頂點包含唯一識別碼、出入邊集合、屬性集合(鍵值對);每條邊包含唯一識別碼、起始/終止頂點、標籤(描述關係種類)、屬性集合。
屬性圖可以用兩張關聯式表格(vertices 和 edges)來表示。重要特性:
- 無 schema 限制:任何頂點都能與任何其他頂點建立邊
- 高效遍歷:可快速找到頂點的所有出入邊,雙向遍歷圖
- 多種關係共存:透過不同標籤在同一張圖中儲存不同類型的資訊
這賦予圖模型極大的彈性——例如能自然表達不同國家的行政區劃差異(法國有 departements 和 regions,美國有 counties 和 states),以及不同粒度的地理資料。
Cypher 查詢語言#
Cypher 是為 Neo4j 圖資料庫建立的宣告式查詢語言。使用箭頭表示法來建立與匹配圖中的模式,例如 (Idaho) -[:WITHIN]-> (USA) 建立一條標籤為 WITHIN 的邊。
查詢「找出所有從美國移居歐洲的人」在 Cypher 中只需 4 行:
MATCH
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (us:Location {name:'United States'}),
(person) -[:LIVES_IN]-> () -[:WITHIN*0..]-> (eu:Location {name:'Europe'})
RETURN person.name其中 :WITHIN*0.. 表示沿著 WITHIN 邊遍歷零次或多次(類似正規表達式的 * 運算子)。作為宣告式語言,不需指定執行細節,查詢最佳化器會自動選擇最有效的策略。
相同查詢在 SQL 中需要使用 WITH RECURSIVE 語法(遞迴共用表格表達式),長達 29 行——這說明不同資料模型適合不同的使用場景。
三元組儲存與 SPARQL#
三元組儲存(Triple-Store)與屬性圖模型大致等價,以三元組 (subject, predicate, object) 形式儲存所有資訊。例如 (Jim, likes, bananas) 中,Jim 是主詞、likes 是謂詞、bananas 是受詞。
- 若 object 是基本型別值,則 predicate 和 object 相當於主詞頂點的屬性鍵值對
- 若 object 是另一個頂點,則 predicate 是圖中的邊
三元組可用 Turtle 格式(N3 子集)書寫,例如:_:lucy :bornIn _:idaho. 表示 Lucy 出生於 Idaho。
SPARQL 是基於 RDF 資料模型的三元組查詢語言。同樣的移民查詢在 SPARQL 中甚至比 Cypher 更簡潔:
PREFIX : <urn:example:>
SELECT ?personName WHERE {
?person :name ?personName.
?person :bornIn / :within* / :name "United States".
?person :livesIn / :within* / :name "Europe".
}圖資料庫與 CODASYL 網路模型雖然表面相似,但有本質差異:圖資料庫沒有 schema 限制(任何頂點可連接任何頂點)、可透過 ID 或索引直接存取頂點、頂點與邊無序,且支援 Cypher、SPARQL 等高階宣告式查詢語言。
Datalog#
Datalog 比 SPARQL 和 Cypher 更古老(1980 年代),卻是許多後續查詢語言的基礎。它被用於 Datomic 和 Cascalog(Hadoop 上的 Datalog 實作)。
Datalog 的資料模型類似三元組,但寫成 predicate(subject, object) 形式,例如 within(idaho, usa).。查詢透過定義規則(rules)來建構,規則可以參照其他規則或遞迴呼叫自身:
within_recursive(Location, Name) :- name(Location, Name).
within_recursive(Location, Name) :- within(Location, Via),
within_recursive(Via, Name).
migrated(Name, BornIn, LivingIn) :- name(Person, Name),
born_in(Person, BornLoc),
within_recursive(BornLoc, BornIn),
lives_in(Person, LivingLoc),
within_recursive(LivingLoc, LivingIn).
?- migrated(Who, 'United States', 'Europe').透過規則的反覆套用,within_recursive 可以推導出所有包含在北美洲(或任何地點名稱)內的位置:
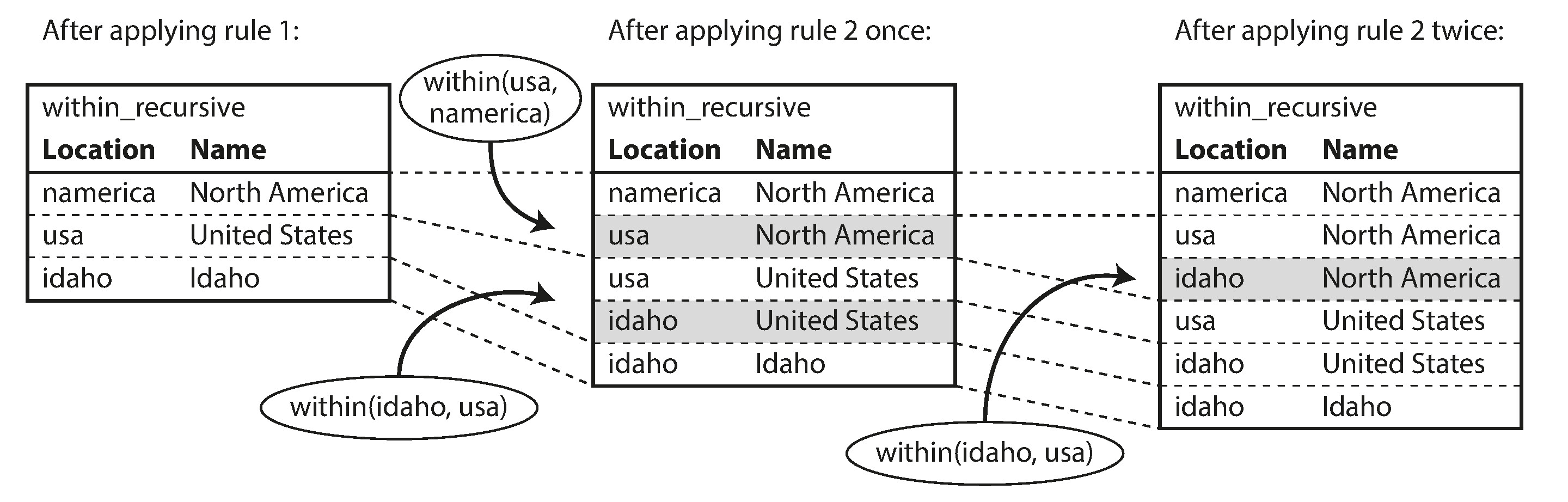
Figure 2-6: 使用 Datalog 規則推導 Idaho 位於北美洲
Datalog 的方法需要不同的思維方式,但非常強大——規則可以在不同查詢中組合與重用。對於簡單的一次性查詢可能不太方便,但面對複雜資料時表現更佳。
本章總結#
資料模型是一個龐大的主題,本章快速瀏覽了多種模型。歷史上,資料從階層式模型(大樹)起步,因無法處理多對多關係而誕生了關聯式模型。近年來,非關聯式的 NoSQL 資料儲存分為兩大方向:
- 文件資料庫:適合資料為自包含文件、文件間關聯稀少的場景
- 圖資料庫:適合任何事物都可能與其他事物關聯的場景
三種模型(文件、關聯式、圖)今日都被廣泛使用,各有所長。一個模型可以用另一個模型來模擬,但結果往往不自然——這就是為什麼我們需要不同的系統來處理不同的需求。
文件與圖資料庫的共同點是通常不強制 schema,使應用程式更容易適應需求變化。但應用程式仍然假設資料具有特定結構——差別在於 schema 是顯式的(寫入時強制)還是隱式的(讀取時處理)。
每種資料模型都伴隨著自己的查詢語言或框架——SQL、MapReduce、MongoDB aggregation pipeline、Cypher、SPARQL、Datalog——選擇適合應用場景的資料模型與查詢語言,是架構設計中最關鍵的決策之一。