本章摘要: 現代應用的核心挑戰在於資料量、複雜度與變化速度,而非 CPU 運算能力。當工程師組合多個資料工具對外提供服務時,實際上扮演了資料系統設計者的角色——本章定義了貫穿全書的三大設計支柱:可靠性、可擴展性與可維護性。
本章是 DDIA 全書的起點,從最根本的問題出發:現代應用程式面對的核心挑戰是什麼?作者 Martin Kleppmann 開宗明義地指出,當今多數應用是資料密集型(data-intensive)而非計算密集型(compute-intensive)。這個觀察奠定了整本書的基調。
資料密集型 vs 計算密集型#
對於現代應用程式而言,原始的 CPU 運算能力很少成為瓶頸。真正的挑戰來自於:
- 資料量(amount of data):需要儲存和處理的資料規模持續成長
- 資料複雜度(complexity of data):資料之間的關聯與結構日益複雜
- 資料變化速度(speed at which data is changing):資料的更新頻率越來越高
這就是所謂的資料密集型應用。相比之下,計算密集型應用(如科學模擬、影像渲染)的瓶頸在於 CPU 處理能力,但這並非本書關注的範疇。
資料系統的基本組成元件#
一個典型的資料密集型應用會由以下標準建構模組(building blocks)組合而成:
| 元件 | 英文 | 用途 |
|---|---|---|
| 資料庫 | Databases | 儲存資料,供應用程式日後查詢使用 |
| 快取 | Caches | 記住耗時運算的結果,加速後續的讀取操作 |
| 搜尋索引 | Search Indexes | 允許使用者透過關鍵字或篩選條件搜尋資料 |
| 串流處理 | Stream Processing | 將訊息傳送給另一個程序,進行非同步處理 |
| 批次處理 | Batch Processing | 定期對大量累積的資料進行運算 |
這些元件各自解決不同的問題,且都已經是成熟的抽象概念。多數工程師不會想從頭寫一個資料庫引擎,因為現成的工具已經足夠好用。
這些建構模組看似理所當然,但它們之所以「理所當然」,正是因為它們作為抽象概念非常成功。我們每天都在使用它們,卻很少深入思考它們的設計取捨。
工具邊界的模糊化#
然而,現實比上述分類更加複雜。我們習慣將資料庫、訊息佇列、快取等視為截然不同的工具類別。雖然資料庫和訊息佇列表面上有相似之處——都會在某段時間內儲存資料——但它們有著完全不同的存取模式(access patterns),因此在效能特性和實作方式上也大相逕庭。
那麼,為什麼要把它們統稱為「資料系統」呢?因為近年來出現了許多新的資料儲存與處理工具,它們不再整齊地歸入傳統分類。作者舉出兩個經典的例子:
- Redis:本質上是 datastore,但也可以當作 message queue 使用
- Apache Kafka:本質上是 message queue,但提供了類似資料庫的持久性保證(durability guarantees)
這種邊界模糊化的趨勢意味著,我們不能再用簡單的標籤(「這是資料庫」、「那是快取」)來思考工具的選擇。每個工具都有其獨特的存取模式、效能特性與實作方式,需要根據具體需求來評估。
組合多個工具的架構挑戰#
現代應用的需求往往過於廣泛,單一工具已無法滿足所有的資料處理與儲存需求。因此,工程師必須將工作拆解為不同的任務,交由各自擅長的工具處理,再透過應用程式碼將它們整合在一起。
舉例來說,一個常見的架構可能包含:
- 主資料庫負責核心資料儲存
- Memcached 或類似工具提供應用層快取
- Elasticsearch 或 Solr 提供全文搜尋功能
在這樣的架構中,保持快取和索引與主資料庫的同步是應用程式碼的責任。這看似簡單,實際上卻涉及許多微妙的問題:快取何時失效?索引如何即時更新?當其中一個元件故障時,其他元件如何維持一致性?
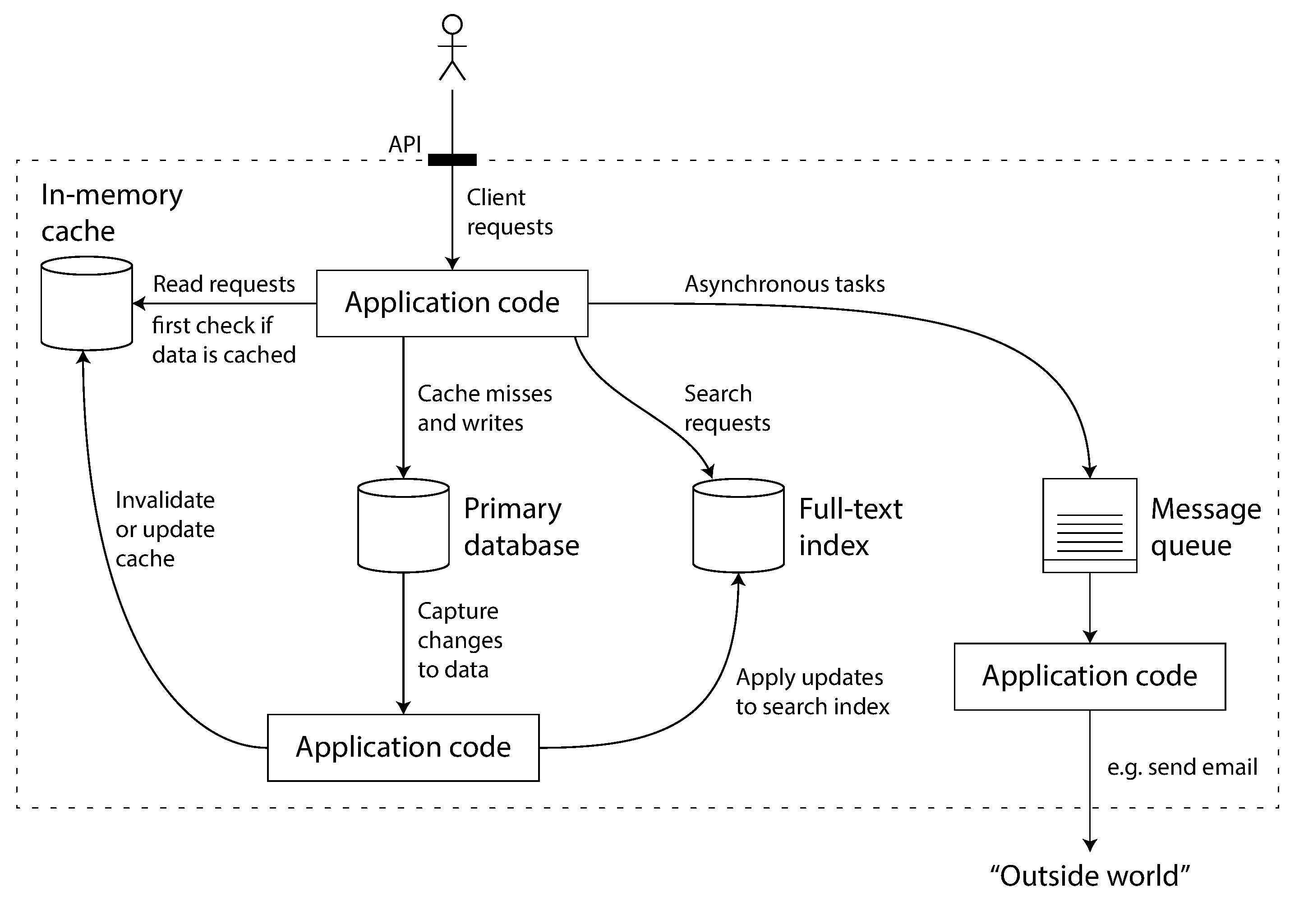
Figure 1-1: 結合多個元件的資料系統架構範例
你不只是開發者,更是資料系統設計者#
當你將多個工具組合起來對外提供服務時,服務的 API 通常會對客戶端隱藏內部的實作細節。此時你實際上是用較小的、通用的元件,建構了一個全新的、專用的資料系統。
這個複合式資料系統需要提供一定的保證,例如:
- 快取在寫入時會被正確地失效或更新
- 外部客戶端能看到一致的結果
在這個角色轉換中,你不僅僅是應用程式開發者,更是資料系統設計者(data system designer)。這意味著你需要面對一系列深層的設計問題。
設計資料系統時的核心問題#
當你設計一個資料系統或服務時,會遇到以下關鍵問題:
| 問題 | 說明 |
|---|---|
| 正確性 | 在內部發生故障時,如何確保資料依然正確且完整? |
| 效能 | 在系統部分功能降級時,如何持續提供穩定的效能? |
| 擴展性 | 如何應對負載的增長? |
| API 設計 | 什麼樣的 API 對服務來說是合理的? |
影響設計決策的因素還有很多,包括團隊的技能與經驗、既有系統的限制(legacy system dependencies)、交付時程、組織對不同風險的容忍度,以及法規要求等。這些因素高度依賴具體情境,沒有放諸四海皆準的標準答案。
本書聚焦的三大關注點#
面對這些複雜的設計挑戰,本書選擇聚焦於大多數軟體系統都重視的三個核心特性:
- 可靠性(Reliability):系統即使在面對逆境(硬體故障、軟體錯誤、人為失誤)時,仍能正確地運作,維持預期的效能水準。簡言之,就是「即使出了問題,系統仍能正常工作」
- 可擴展性(Scalability):當系統成長(資料量、流量、複雜度增加)時,有合理的方式來應對這些成長。重點不在於「能不能擴展」,而在於「有沒有合理的方式」來擴展
- 可維護性(Maintainability):隨著時間推移,不同的人(工程團隊與維運團隊)會參與系統的開發與維運,他們都應該能高效地工作。系統不僅要維持現有行為,還要能適應新的使用場景
這三個詞彙在業界經常被提及,卻很少有人真正釐清它們的含義。本書的價值之一,就是用嚴謹的方式定義這些概念,並探討實現它們的具體技術與架構。
小結#
本節建立了全書的核心框架:
- 現代應用是資料密集型的,CPU 不再是主要瓶頸
- 資料系統由多種工具組合而成,工具之間的邊界日益模糊
- 組合多個工具時,開發者同時扮演著資料系統設計者的角色
- 設計決策圍繞著可靠性、可擴展性、可維護性這三大支柱展開
後續章節將逐層深入,探討在建構資料密集型應用時需要考慮的各種設計決策、技術與演算法。