本章是分散式系統研究的集大成之作:分散式共識(Distributed Consensus)。前面章節依序介紹了連結與程序、故障模型、故障偵測器、領導者選舉及一致性模型,這些概念最終匯聚於共識演算法。
共識的定義與性質#
共識演算法允許分散式系統中的多個程序就某個值達成一致。根據 FLP 不可能性定理,在完全非同步的系統中,不可能在有限時間內保證共識——即使訊息傳遞有保障,一個程序也無法區分另一個程序是崩潰了還是執行緩慢。
共識演算法假設非同步模型並保證安全性(Safety),同時依賴外部故障偵測器提供關於其他程序的資訊以保證活性(Liveness)。
從理論角度看,共識演算法具有三個基本性質:
- 一致性(Agreement):所有正確的程序做出相同的決定
- 有效性(Validity):決定的值必須是由某個程序所提議的
- 終止性(Termination):所有正確的程序最終都會達成決定
若沒有有效性,共識可以是平凡的(所有程序使用預設值即可達成一致,但毫無用處)。若沒有終止性,演算法將永遠運行而不產生任何結論。
廣播(Broadcast)#
廣播是分散式系統中常見的通訊抽象,用於在一組程序間散佈資訊。廣播常用於資料庫複製——由單一協調者節點將資料分發給所有參與者。
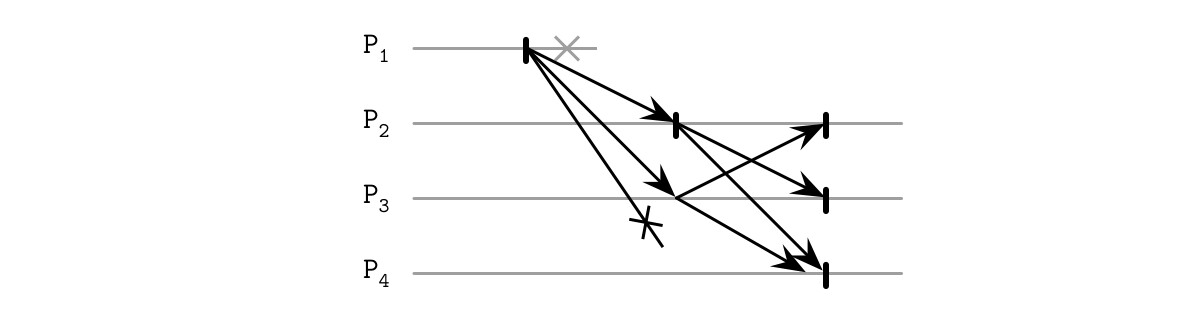
Figure 14.1: Broadcast
最簡單的廣播:Best-Effort Broadcast#
- 發送者負責確保訊息傳遞給所有目標
- 若發送者失敗,其他參與者不會嘗試重新廣播
- 協調者崩潰時,此類廣播會靜默失敗
可靠廣播(Reliable Broadcast)#
- 保證所有正確的程序收到相同的訊息,即使發送者在傳輸過程中崩潰
- 樸素實作方式:允許每個收到訊息的程序將其轉發給其他所有已知的程序
- 當來源程序失敗時,其他程序偵測到故障並繼續廣播,形成洪泛(Flooding)——產生 N^2 則訊息
- 缺點正是訊息數量為 N^2(N 為剩餘接收者數量)
原子廣播(Atomic Broadcast)#
原子廣播(又稱全序多播,Total Order Multicast)同時保證可靠傳遞和全序。
原子廣播必須確保兩個關鍵性質:
- 原子性(Atomicity):程序們必須就收到的訊息集合達成一致——要嘛所有未故障的程序都傳遞該訊息,要嘛都不傳遞
- 順序(Order):所有未故障的程序以相同的順序傳遞訊息
虛擬同步(Virtual Synchrony)#
虛擬同步是一種基於廣播的群組通訊框架,與原子廣播不同的是,它可以向動態群組傳遞全序訊息。
核心概念:
- 程序被組織成群組,群組存在期間訊息以相同順序傳遞給所有成員
- 當參與者加入、離開或故障被踢出時,群組視圖(Group View) 發生變化
- 區分訊息接收(Receipt)與訊息傳遞(Delivery):傳遞只在所有群組成員都收到訊息後才發生
- 訊息屬於特定群組,除非視圖變更前所有程序都收到訊息,否則不算已傳遞
- 群組視圖充當訊息廣播無法跨越的屏障(Barrier)
部分全序廣播演算法使用單一程序(Sequencer)來決定順序。這種方式實作較簡單,但依賴領導者故障偵測來保證活性。可透過分區請求來擴展。儘管技術上完善,虛擬同步並未獲得廣泛採用。
Zookeeper 原子廣播(ZAB)#
ZAB 是由 Apache ZooKeeper 使用的原子廣播實作,ZooKeeper 是一個階層式分散式鍵值儲存系統,利用 ZAB 來確保事件的全序和原子傳遞,以維持副本狀態之間的一致性。
角色#
- Leader(領導者):臨時角色,驅動演算法步驟、廣播訊息給追隨者、建立事件順序
- Follower(追隨者):接受領導者的提議
客戶端連接到叢集中的任一節點。若該節點為 Leader 則直接處理請求,否則轉發給 Leader。
Epoch 機制#
為保證 Leader 唯一性,協定時間線被切割為 Epoch(由單調遞增的唯一數字標識)。在任何 Epoch 期間只能有一個 Leader。
三個階段#
ZAB 協定在選出候選 Leader 後,按三個階段執行:
Discovery(發現):候選 Leader 了解每個程序已知的最新 Epoch,並提議一個大於所有追隨者當前 Epoch 的新 Epoch。追隨者回應前一個 Epoch 中最後看到的交易識別碼。此步驟後,沒有程序會接受更早 Epoch 的廣播提議。
Synchronization(同步):用於從前一個 Leader 的故障中恢復並讓落後的追隨者趕上進度。候選 Leader 發送訊息提議自己為新 Epoch 的 Leader 並收集確認。確認收到後,Leader 正式確立。此後追隨者不再接受其他程序成為 Epoch Leader 的嘗試。同步期間新 Leader 確保追隨者擁有相同的歷史記錄。
Broadcast(廣播):追隨者同步完成後開始主動訊息傳遞。Leader 接收客戶端訊息、建立順序並廣播:發送新提議 → 等待法定多數追隨者確認 → 提交。類似於沒有中止的兩階段提交——投票僅為確認,客戶端不能對有效 Leader 的提議投反對票。

Figure 14.2: ZAB protocol summary
安全性與效率#
- 安全性保證:追隨者只接受已確立 Epoch 之 Leader 的提議
- Leader 和追隨者依賴心跳來判斷遠端程序的存活狀態
- 訊息完全有序,Leader 在前一則訊息被確認前不會發送下一則
- ZAB 能處理多個併發的客戶端狀態變更
- 同步階段中,追隨者回報最高已提交的提議,Leader 只需從擁有最高提議的節點複製訊息即可恢復
- 廣播過程僅需兩輪訊息,效率極高
Paxos#
原子廣播與共識在具有崩潰故障的非同步系統中是等價問題。Paxos 可能是最廣為人知的共識演算法,由 Leslie Lamport 在 1998 年的 “The Part-Time Parliament” 論文中首次提出,並在 2001 年的 “Paxos Made Simple” 中以更簡單的術語重新描述。
角色#
- Proposer(提議者):從客戶端接收值,建立提議並嘗試從 Acceptor 收集投票
- Acceptor(接受者):投票接受或拒絕提議的值。為了容錯需要多個 Acceptor,但為了活性只需**法定多數(Quorum)**的投票
- Learner(學習者):作為副本,儲存已接受提議的結果
任何參與者都可以擔任任何角色,大多數實作將它們共置在同一程序中。
每個提議由客戶端提出的值和一個唯一的單調遞增提議號碼組成,通常以 (id, timestamp) 對來實作。
Paxos 演算法流程#
Paxos 分為兩個階段:投票(Propose)階段和複製(Replication)階段。
階段一:Propose
- Proposer 發送
Prepare(n)訊息(n 為提議號碼)給多數 Acceptor,嘗試收集投票 - Acceptor 收到 Prepare 請求後,遵循以下不變式:
- 若尚未回應過更高序號的 Prepare 請求,則承諾不再接受序號更低的提議
- 若已接受過其他提議,則回應
Promise(m, v_accepted),通知 Proposer 已接受的提議 - 若已回應過更高序號的 Prepare 請求,則通知 Proposer 存在更高號碼的提議
- Acceptor 可以回應多個 Prepare 請求,只要後者序號更高
階段二:Replication
- 收集到多數投票後,Proposer 發送
Accept!(n, v)訊息 - v 是回應中最高號碼提議對應的值,若回應中沒有已接受的提議則可使用自己的值
- Acceptor 接受提議號碼為 n 的提議,除非在 Propose 階段已回應過更高號碼的 Prepare
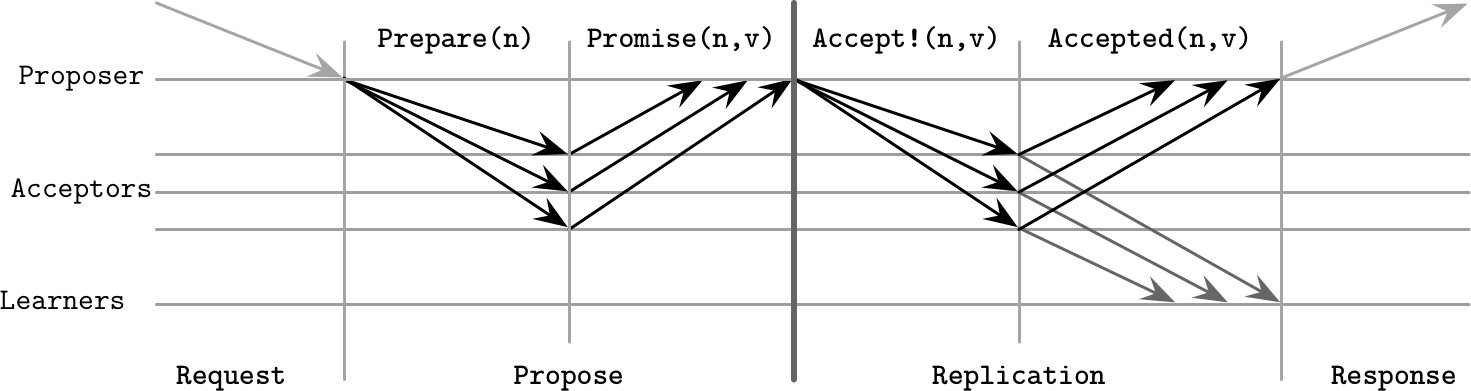
Figure 14.3: Paxos algorithm: normal execution
一旦某個值達成共識(被至少一個 Acceptor 接受),未來的 Proposer 必須決定相同的值以保證一致性。Learner 在收到多數 Acceptor 的通知後得知已決定的值。
Paxos 中的法定人數(Quorum)#
- Quorum 是操作所需的最小投票數,通常是參與者的多數
- 核心思想:即使部分參與者故障或被網路分割隔離,至少有一個共同參與者充當仲裁者
- 任意兩個多數集合至少有一個共同成員
- Paxos 在任意數量的故障下保證安全性
- 活性在 f 個程序故障時有保證,需要總共 2f + 1 個程序
Quorum 僅描述系統的阻塞性質。為保證安全性,每一步都必須等待至少一個 Quorum 的節點回應。我們可以向更多節點發送提議和接受指令,但不必等待所有回應即可繼續。部分系統使用投機執行來發送冗餘查詢以應對節點故障。
故障場景#
分散式演算法在故障情境下最有意思。以下是 Paxos 的幾個典型故障場景:
場景一:Proposer 故障,決定舊值
- Proposer P1 在 Propose 階段以提議號碼 1 通過,但在複製階段僅向 Acceptor A1 發送值 V1 後崩潰
- 新的 Proposer P2 以更高提議號碼 2 開始新輪次,收集到 A1 和 A2 的 Quorum 回應,繼而提交 P1 的舊值 V1
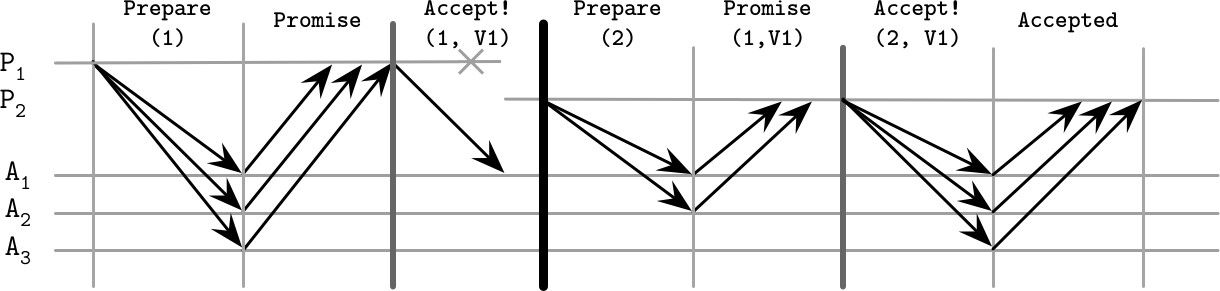
Figure 14.4: Paxos failure scenario: proposer failure, deciding on the old value
場景二:Proposer 故障,決定新值
- P1 同樣在僅向 A1 發送值 V1 後崩潰
- P2 收集 Quorum 回應時,A2 和 A3 先回應(未包含 A1),因此 P2 可以提交自己的新值
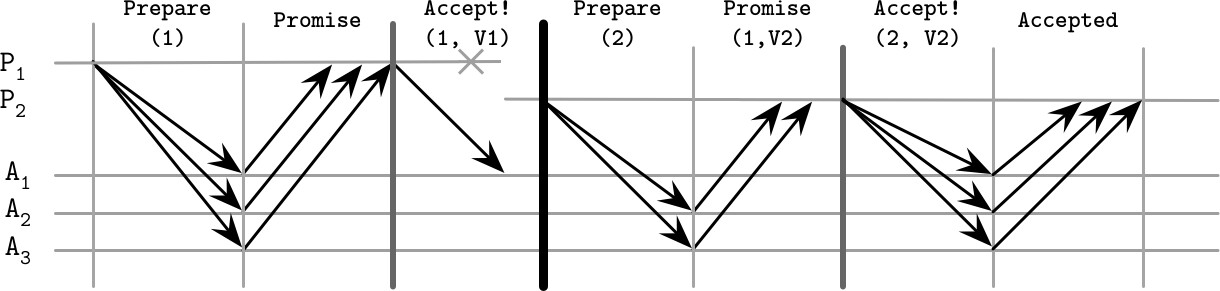
Figure 14.5: Paxos failure scenario: proposer failure, deciding on the new value
場景三:Proposer 故障後 Acceptor 也故障
- P1 崩潰後只有 A1 接受了值 V1,隨後 A1 也崩潰
- P2 的 Quorum 不與 A1 重疊,因此提交自己的值
- 之後任何與 A1 重疊的 Proposer 都會忽略 A1 的舊值,選擇更近期的已接受提議
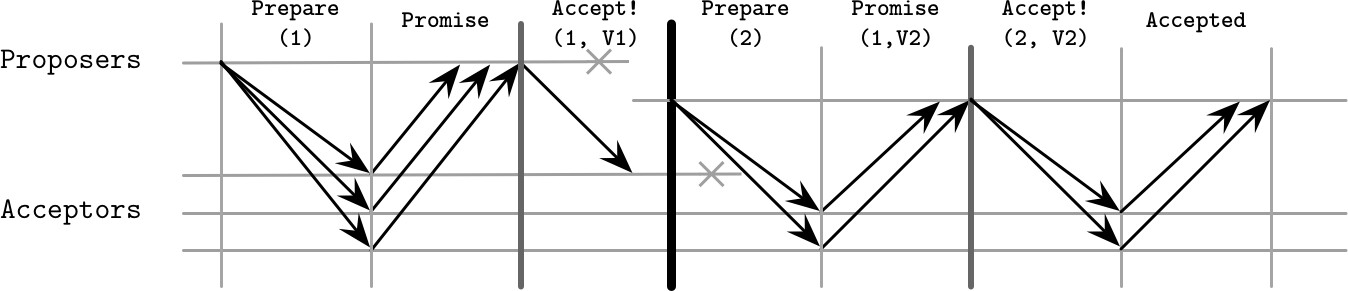
Figure 14.6: Paxos failure scenario: proposer failure, followed by the acceptor failure
場景四:競爭的 Proposer(活鎖)
- 兩個或多個 Proposer 競爭,各自嘗試通過 Propose 階段但持續因對方的更高序號而失敗
- 通常透過加入隨機退避(Random Backoff) 來解決
Multi-Paxos#
經典 Paxos 的問題在於每輪複製都需要一次 Propose 輪次。Multi-Paxos 引入長期 Leader(Distinguished Proposer) 的概念——已確立的 Leader 可以跳過 Propose 階段直接進入複製,顯著提升效率。
關鍵特性:
- Leader 可以複製多個值而非僅一個
- 部分實作使用 Lease 機制:Leader 週期性聯繫參與者通知自己仍然存活,參與者承諾在 Lease 期間不接受其他 Leader 的提議
- Lease 不是正確性保證而是效能優化,允許從活躍 Leader 直接讀取而不需收集 Quorum
- Lease 依賴參與者間的有界時鐘同步——若時鐘漂移過大,線性化保證無法維持
- Multi-Paxos 常被描述為操作的複製日誌(Replicated Log)
- 為防止日誌無限增長,內容應定期套用到主結構建立快照(Snapshot),之後可截斷日誌
可以如此類比:單值 Paxos 像一個一次性寫入暫存器,而 Multi-Paxos 像一個僅追加日誌。
Fast Paxos#
Fast Paxos 透過讓任何 Proposer 直接聯繫 Acceptor(繞過 Leader)來減少一次往返。代價是需要更大的 Quorum:
- Quorum 大小增加到 2f + 1(經典 Paxos 為 f + 1)
- 總 Acceptor 數量需 3f + 1
Fast Paxos 有兩類輪次:
- Classic Round:與經典 Paxos 相同
- Fast Round:協調者發出特殊的
Any訊息,允許 Acceptor 獨立決定接受來自不同 Proposer 的值
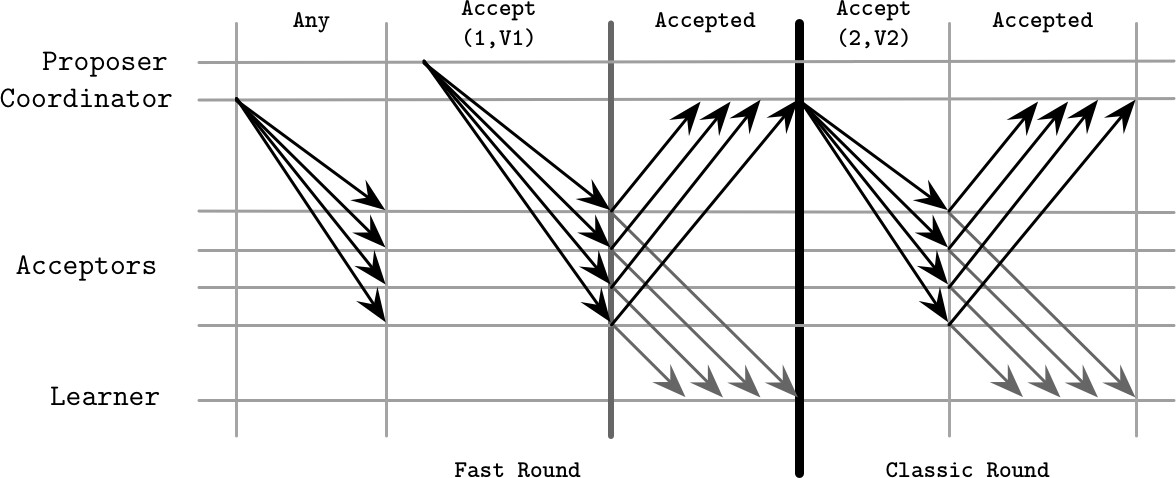
Figure 14.7: Fast Paxos algorithm: fast and classic rounds
缺點:容易發生碰撞(Collision)——當多個 Proposer 同時使用 Fast Round 時,Acceptor 可能決定衝突的值。協調者需介入並啟動新輪次來恢復。在高請求率下碰撞會增加往返次數和延遲,實際延遲可能高於經典 Paxos。
Egalitarian Paxos(EPaxos)#
使用長期 Leader 帶來兩個問題:Leader 故障需選舉新 Leader,且 Leader 可能承受不成比例的負載。EPaxos 的解決方式是讓每個命令有自己的 Leader,並透過查找和設定依賴關係(Dependencies) 來建立順序,而非依靠提議號碼排序。
避免將所有負載集中在 Leader 上的另一種方式是分區(Partitioning)。將可能的值範圍分成更小的區段,讓系統的一部分負責特定範圍。這有助於可用性(隔離故障)、效能(不重疊的區段)和可擴展性(增加分區即可擴展)。但跨分區操作需要原子提交。
EPaxos 試圖兼顧經典 Paxos 的高可用性和 Multi-Paxos 的高吞吐量。
Pre-Accept 階段:
- 程序成為特定提議的 Leader
- 每個提議包含:依賴清單(可能與當前提議衝突的所有命令)和序號(大於所有已知依賴的序號)
- 將
PreAccept訊息轉發給 Fast Quorum(⌈3f/4⌉ 個副本) - 副本檢查本地命令日誌,更新提議依賴並回報
兩種可能路徑:
- Fast Path:依賴清單一致,Leader 可直接進入提交階段
- Slow Path:副本間存在分歧,Leader 需更新依賴清單和序號,再發送給 ⌊f/2⌋ + 1 個副本後方可提交
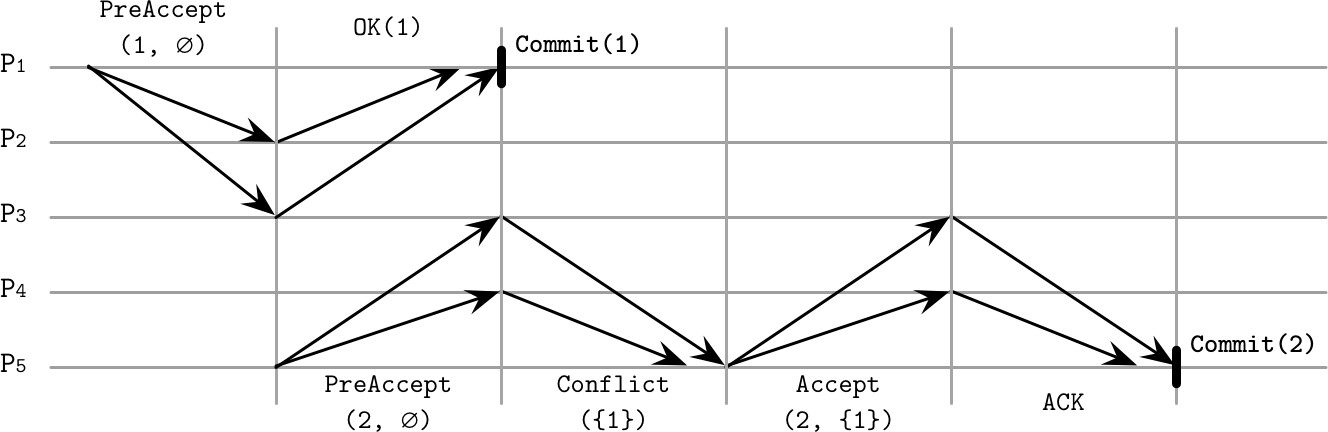
Figure 14.8: EPaxos algorithm run
兩個命令 A 和 B 只有在其執行順序影響結果時才算互相干擾(Interfere)。執行命令時,副本建立依賴圖並按逆依賴順序執行。由於只有互相干擾的命令需要依賴關係,對大多數工作負載來說這種情況相對少見。
Flexible Paxos#
傳統上 Quorum 定義為多數程序。Flexible Paxos 提出一個重要觀察:
- 在 Paxos 中,我們只需要第一階段(選舉 Leader)的節點群組與第二階段(接受提議)的節點群組有交集
- 定義 N 為總參與者數、Q1 為 Propose 階段所需節點數、Q2 為 Accept 階段所需節點數,只需確保 Q1 + Q2 > N
- 由於第二階段通常更頻繁,Q2 可以僅包含 N/2 個 Acceptor,只要 Q1 相應增大
範例:5 個 Acceptor,選舉輪次需 4 個投票,則複製階段僅需等待 2 個節點回應,甚至可以向不相交的 Acceptor 集合提交提議。
Flexible Paxos 允許用可用性換延遲:減少第二階段的參與者但在選舉階段需要更多投票。只要當前 Leader 穩定且不需要新選舉,此配置可在複製階段容忍最多 N - Q2 個節點故障。
共識的廣義解(Generalized Solution)#
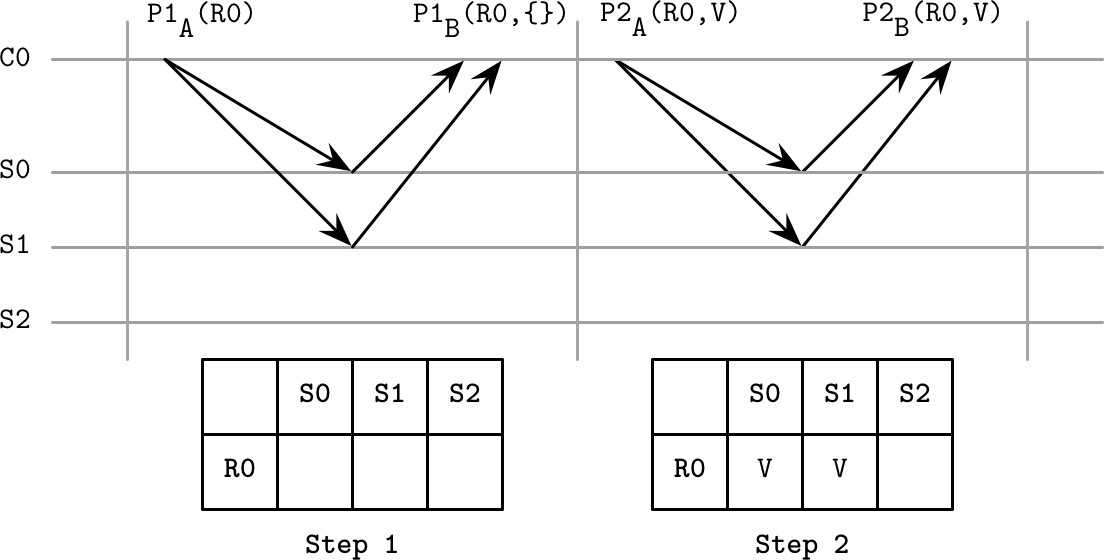
Figure 14.9: Generalization of Paxos
Paxos 有時難以推理。一種更簡潔的理解方式是使用一次性寫入暫存器(Write-Once Register) 的概念:
- 系統由客戶端和一組伺服器組成,每個伺服器有多個暫存器
- 暫存器有索引,只能寫入一次,可處於三種狀態:未寫入、包含值、包含 nil
- 相同索引的暫存器在不同伺服器上構成一個暫存器集合(Register Set)
- 每個暫存器集合可有一個或多個 Quorum
Quorum 可處於以下狀態:
- Any:未來可決定任何值
- Maybe v:若達成決定只能是 v
- None:無法決定值
- Decided v:已決定值 v
兩階段決策過程:
- Phase 1:客戶端發送
P1A(register)檢查暫存器是否未寫入。若收到多數伺服器回應,則選擇最大索引暫存器的非空值,或使用自己的值 - Phase 2:客戶端發送
P2A(register, value)通知所有伺服器。若多數伺服器回應,輸出決定值;否則重新從 Phase 1 開始
此方法將 Paxos 語義轉化為已知狀態的角度來理解,移除了可能的模糊性。不可變狀態和訊息傳遞也更容易正確實作。
Raft#
Paxos 長期以來被認為難以理解和推理。2013 年出現的 Raft 演算法旨在成為一個易於理解和實作的共識演算法,其論文標題即為 “In Search of an Understandable Consensus Algorithm”。
角色#
- Candidate(候選者):領導權是臨時的,任何參與者都可成為候選者。候選者嘗試收集多數投票以成為 Leader。若投票分裂(無人獲得多數),則進入新 Term 重新選舉
- Leader(領導者):當前的臨時叢集領導者,處理客戶端請求並操作複製狀態機。Leader 被選舉於一個 Term 中,每個 Term 由單調遞增的數字標識
- Follower(追隨者):被動的參與者,持久化日誌條目並回應 Leader 和候選者的請求。每個程序以 Follower 身分啟動
Term 與訊息順序#
時間被劃分為 Term(類似 Epoch),在此期間 Leader 唯一且穩定。每個命令由 Term 號碼和 Term 內的訊息號碼唯一標識。若參與者發現自己的 Term 過時,會更新到更高號碼的 Term。
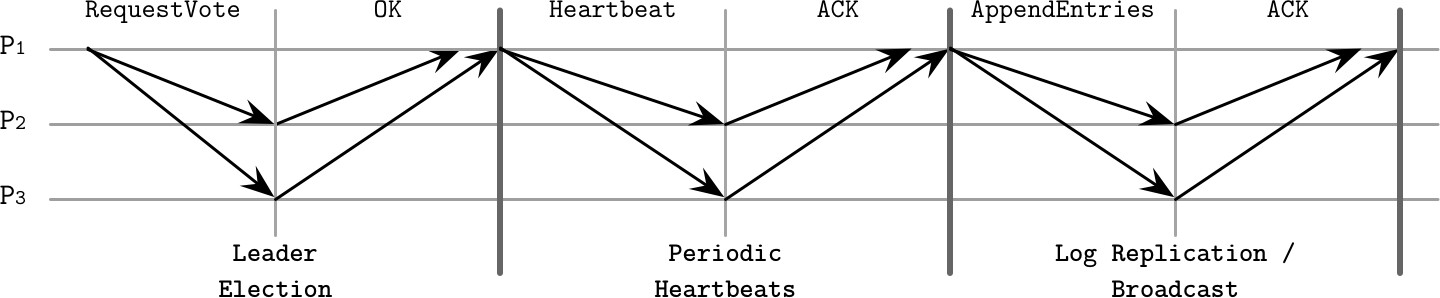
Figure 14.10: Raft consensus algorithm summary
演算法核心組件#
- Leader 選舉:候選者 P1 發送
RequestVote訊息(包含候選者的 Term、最後已知 Term 和最後日誌條目 ID)。收集到多數投票後成功當選。每個程序對每個 Term 最多投一票 - 週期性心跳:Leader 定期發送心跳維持其 Term。若 Follower 在**選舉逾時(Election Timeout)**期間未收到心跳,則假定 Leader 已故障並啟動新選舉
- 日誌複製/廣播:Leader 透過發送
AppendEntries訊息將新值追加到複製日誌(包含 Leader 的 Term、索引、前一個日誌條目的 Term 和索引、以及一或多個待儲存的條目)
Leader 在 Raft 中的角色#
- 只有持有所有已提交條目的節點才能被選為 Leader
- 若 Follower 的日誌比候選者更新(更高 Term ID 或更長日誌序列),投票被拒絕
- Leader 接受客戶端請求(也可由其他節點轉發)並平行複製到所有 Follower
- Follower 收到
AppendEntries後追加條目到本地日誌並確認 - 收到足夠副本確認後,條目被視為已提交
- 日誌條目只從 Leader 流向 Follower,不會反向流動
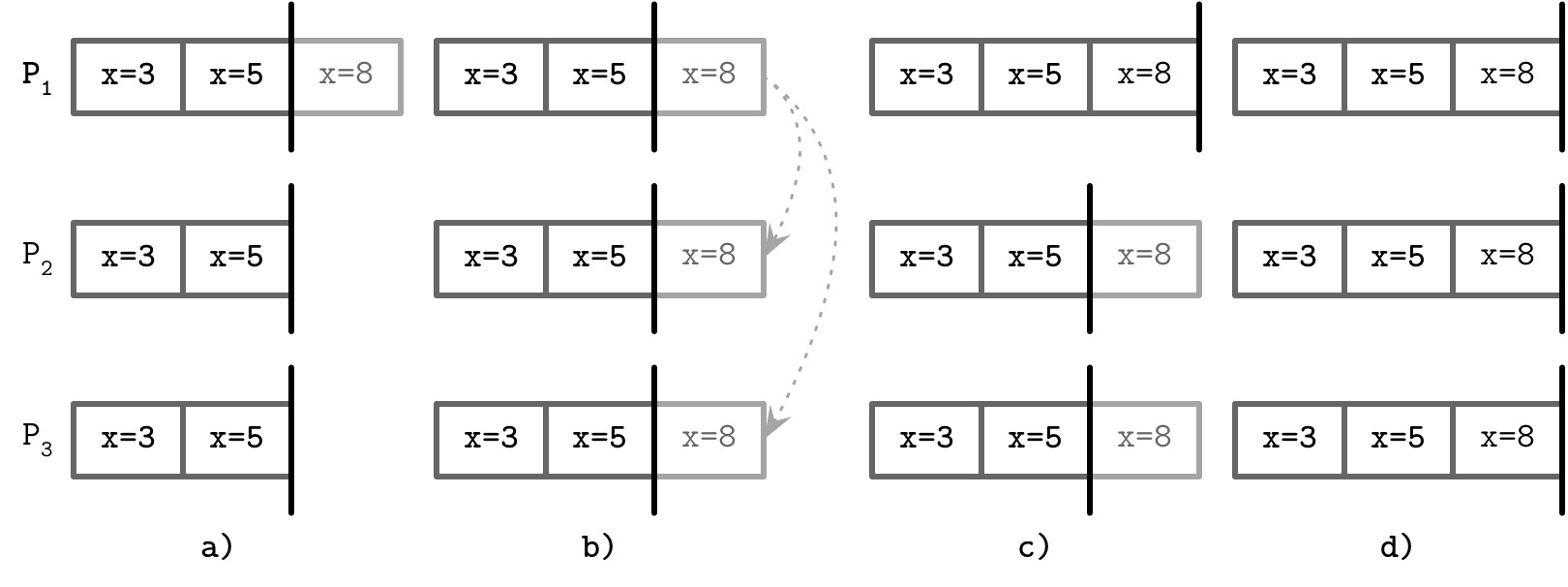
Figure 14.11: Procedure of a commit in Raft with P1 as a leader
提交流程:
- 新命令追加到 Leader 的日誌
- 複製到多數參與者
- Leader 本地提交該值
- 提交決定複製到 Follower
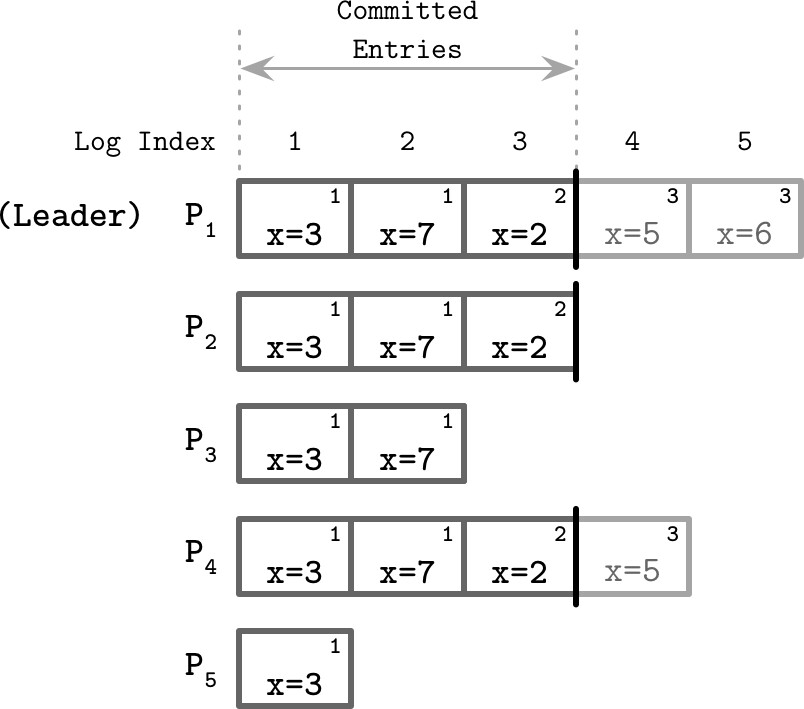
Figure 14.12: Raft state machine
Raft 的故障場景#
- 投票分裂(Split Vote):多個 Follower 同時成為候選者且無人獲得多數。Raft 使用隨機化計時器降低連續分裂投票的機率——某個候選者可以更早開始下一輪選舉
- Follower 可能當機或回應緩慢,Leader 須盡最大努力確保訊息傳遞(在預期時限內未收到確認則重送)
- 由於條目唯一標識,重複訊息傳遞不會破壞日誌順序。Follower 使用序列 ID 去重
- Follower 若發現前一條目的 ID 和 Term 不匹配,會拒絕更高號碼的條目
Leader 故障恢復:新 Leader 找到與 Follower 的共同基點(雙方都同意的最高日誌條目),命令 Follower 丟棄此點之後的所有未提交條目,然後發送自己的最新條目覆蓋 Follower 的歷史。Leader 自己的日誌記錄永遠不會被移除或覆蓋。
Raft 的保證#
- 在給定 Term 中只有一個 Leader 可以被選出
- Leader 不會移除或重新排序日誌內容,只追加新訊息
- 已提交的日誌條目保證存在於後續 Leader 的日誌中,無法被撤銷
- 所有訊息由訊息 ID 和 Term ID 唯一標識,不會重複使用相同識別碼
Raft 自問世以來已非常流行,被 CockroachDB、Etcd 和 Consul 等多個資料庫和分散式系統採用。這不僅歸功於其簡潔性,也證明 Raft 確實是一個可靠的共識演算法。
拜占庭共識(Byzantine Consensus)#
前述所有共識演算法都假設非拜占庭故障——即節點「善意地」執行演算法而不會偽造結果。這個假設允許以更少的參與者和更少的往返次數達成共識。
然而,當分散式系統部署在潛在敵對的環境中(節點不受同一實體控制),就需要能在部分節點行為異常甚至惡意的情況下仍正確運作的演算法。拜占庭故障也可能由 Bug、錯誤配置、硬體問題或資料損壞引起。
大多數拜占庭共識演算法每一步需要 N^2 則訊息(N 為 Quorum 大小),因為每個節點需要與其他每個節點交叉驗證。
PBFT(Practical Byzantine Fault Tolerance)#
PBFT 假設獨立的節點故障,系統做出弱同步假設(網路正常行為,故障非永久且最終會恢復)。所有節點間通訊加密以防止訊息偽造。
容錯要求:
- 最多 (n - 1)/3 個副本可以是故障的
- 為承受 f 個被入侵的節點,至少需要 n = 3f + 1 個節點
- 原因:f 個可能故障 + f 個可能無回應但未故障,演算法仍需收集足夠正確副本的回應
PBFT 使用 View 來區分叢集配置。每個 View 中一個副本為 Primary(主節點),其餘為 Backup(備份)。Primary 的索引為 v mod N。客戶端對 Primary 執行操作,Primary 廣播給 Backup。客戶端等待 f + 1 個副本回覆相同結果。
PBFT 三階段#
Pre-prepare:Primary 廣播包含 View ID、唯一單調遞增識別碼、載荷和載荷摘要的訊息。Backup 在 View 匹配且載荷未被竄改時接受訊息
Prepare:Backup 接受 Pre-prepare 後進入 Prepare 階段,向所有其他副本廣播
Prepare訊息(View ID、訊息 ID、載荷摘要,但不含載荷本身)。副本需收到 2f 個匹配的 Prepare 才能進入下一階段Commit:副本廣播
Commit訊息並等待收集 2f + 1 個匹配的 Commit 訊息
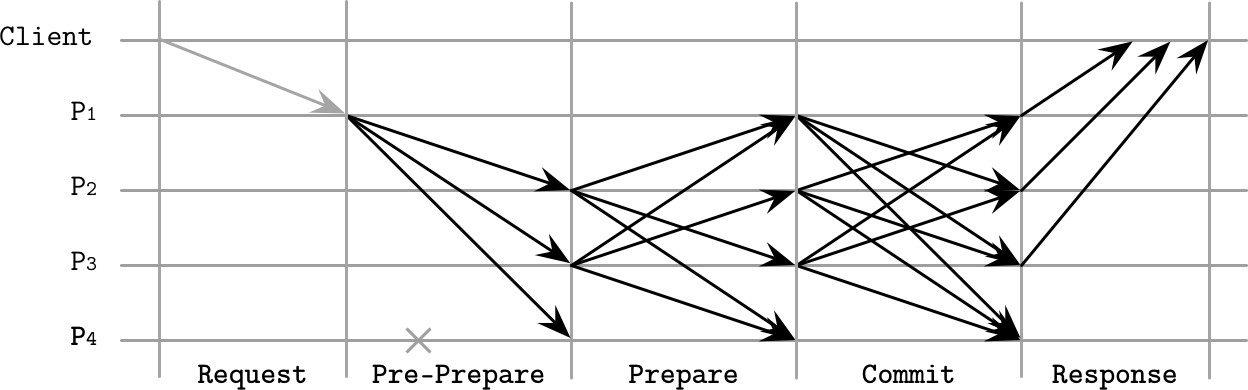
Figure 14.13: PBFT consensus, normal-case operation
在 Prepare 和 Commit 階段,節點透過互相發送訊息並等待對應數量的匹配訊息來交叉驗證,確保只有正確的節點能成功提交。
View 變更:當副本注意到 Primary 不活躍時,停止回應進一步訊息,廣播 View 變更通知並等待確認。新 View 的 Primary 收到 2f 個 View 變更事件後啟動新 View。
效能優化:
- 客戶端可收集 2f + 1 個來自暫時性執行請求的匹配回應,以減少訊息數量
- 唯讀操作僅需一次往返:客戶端向所有副本發送讀取請求,收集 2f + 1 個相同值的回應即可完成
恢復與檢查點#
- 副本將已接受的訊息保存在穩定日誌中,每則訊息需保留直到被至少 f + 1 個節點執行
- 為驗證狀態正確性,節點計算訊息的摘要(Digest) 並互相比較
- 每 N 個請求後,Primary 建立一個穩定檢查點(Stable Checkpoint):廣播最新序號和狀態摘要,等待 2f + 1 個副本回應作為該檢查點的證明
拜占庭容錯對於部署在潛在敵對網路的儲存系統至關重要。大多數時候加密和驗證節點間通訊已足夠,但當系統各部分之間缺乏信任時,就必須採用類似 PBFT 的演算法。由於抗拜占庭故障的演算法在訊息交換數量上有顯著開銷,理解其適用場景非常重要。
總結#
共識演算法是分散式系統中最有趣也最複雜的主題之一。本章討論了經典 Paxos 及其多個變體,以及 Raft 和拜占庭容錯演算法。
Paxos 家族#
| 變體 | 改進重點 |
|---|---|
| Multi-Paxos | 允許 Proposer 保持角色並複製多個值 |
| Fast Paxos | 透過 Fast Round 減少訊息數量,Acceptor 可直接接受非 Leader 的提議 |
| EPaxos | 透過解析命令間依賴關係來建立事件順序,無需固定 Leader |
| Flexible Paxos | 放寬 Quorum 要求,僅需第一階段(投票)與第二階段(複製)的 Quorum 有交集 |
Raft#
- 簡化共識描述的術語,將 Leader 設為演算法的一等公民
- 清楚分離日誌複製、Leader 選舉和安全性三個關注點
拜占庭共識(PBFT)#
- 用於需要在敵對環境中保證安全的場景
- 參與者交叉驗證彼此的回應
- 僅在有足夠數量的節點遵守演算法規則時才繼續執行步驟
- 訊息開銷為 N^2,使用時需審慎評估場景需求