分散式交易概觀#
在分散式系統中,我們經常需要原子性地(atomically)執行多個操作。原子操作可用狀態轉換來解釋:資料庫在交易開始前處於狀態 A,完成後轉移至狀態 B。交易處理的核心在於判定可允許的歷史(permissible histories),亦即對交錯執行情境的建模。若某段歷史等價於某個循序執行的歷史(具有相同的相依圖),則稱該歷史是可序列化的(serializable)。
本章是第五章(節點本地交易處理)在分散式環境下的對應。
- 單分區交易可沿用悲觀(基於鎖或追蹤)或樂觀(先嘗試再驗證)的並行控制方案
- 多分區交易則需要跨伺服器協調、分散式提交與回滾協定
即使是看似簡單的轉帳操作,內部也涉及讀取餘額、加減金額、寫回結果等多個子步驟,每個子步驟又包含數百個更小的操作。因此必須先執行完交易,再使結果可見。
交易的基本性質#
- 原子性(Atomicity):交易的所有結果要麼全部可見,要麼全部不可見
- 可復原性(Recoverability):若交易無法完成、被中止或逾時,其結果必須完全回滾
- 跨節點一致性:節點可能獨立故障與復原,但所有參與節點的狀態必須保持一致——變更要麼持久傳播到所有參與節點,要麼一個也不傳播
使操作呈現原子性#
為了讓多個操作(尤其包含遠端操作)看起來是原子的,需要使用**原子提交(Atomic Commitment)**演算法。其核心特性:
- 不允許參與者之間有分歧——只要一個參與者投反對票,交易就不會提交
- 失敗的行程必須與其他成員達成相同結論
- 不適用於拜占庭故障:當行程謊報自身狀態或做出任意決定時,違反了一致性要求
原子提交要解決的問題是:就是否執行所提議的交易達成一致。參與者(cohort)不能選擇、影響或變更所提議的交易,只能投票表示願意或拒絕。
資料庫實作者需決定:
- 何時認為資料已準備好提交(只差一步指標切換就能公開變更)
- 如何執行提交本身,以在最短時間內使結果可見
- 如何在演算法決定不提交時回滾變更
在資料庫中,分散式交易由**交易管理器(Transaction Manager)**負責排程、協調、執行和追蹤交易,確保節點本地的可見性保證與分散式原子操作所規定的可見性一致。
二階段提交(Two-Phase Commit, 2PC)#
二階段提交是最直接的分散式提交協定,允許多分區的原子更新。
角色與前提#
- 協調者(Coordinator / Leader):持有狀態、收集投票,作為協議輪次的主要參考點
- 參與者(Cohort):通常是操作不相交資料集的各分區
- 協調者與每個參與者都為每個執行步驟維護本地操作日誌
- 協調者可以是接收到交易請求的節點,或透過選舉、手動指定等方式決定
兩個階段#
準備階段(Prepare):
- 協調者發送 Propose 訊息通知參與者新交易
- 參與者決定是否能提交其負責的交易部分
- 若可以提交,回覆正面投票;否則要求中止
- 所有決定都持久化到協調者日誌,各參與者也在本地保留副本
提交/中止階段(Commit/Abort):
- 若任一參與者投票中止,協調者向所有人發送 Abort 訊息
- 僅當所有參與者都投下正面票,協調者才發送 Commit 訊息
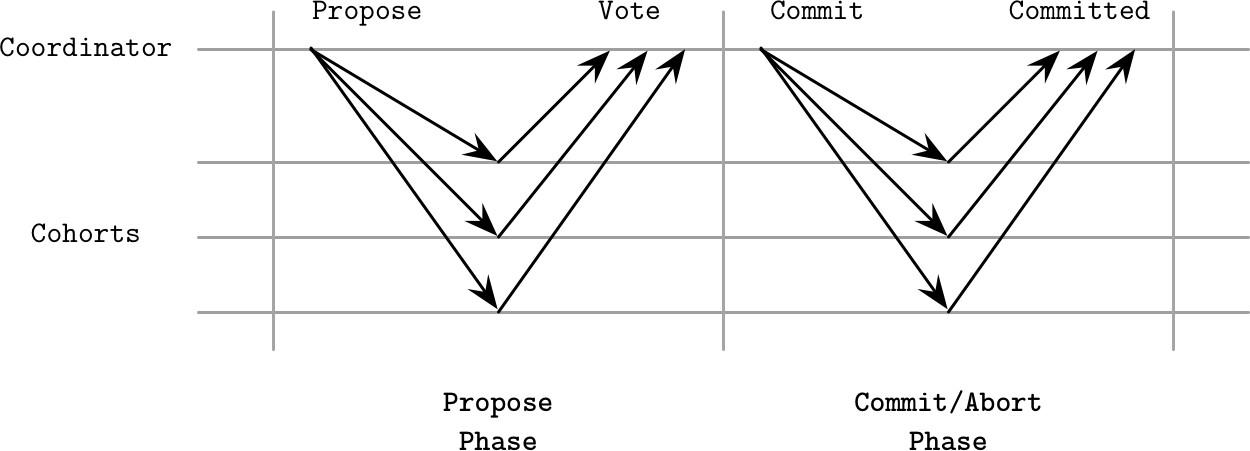
Figure 13.1: Two-phase commit protocol
在資料庫系統中,每一輪 2PC 通常負責一筆交易。準備階段期間,交易內容(操作、識別碼及其他中繼資料)從協調者傳送到參與者。參與者在本地執行交易,並將其置於部分提交狀態(precommitted),等待協調者在下一階段最終確認或中止。
參與者故障#
- 若某參與者在準備階段故障,協調者因無法獲得全部正面投票而中止交易
- 這意味著單一節點的故障就能阻止交易完成,對可用性有負面影響
- 某些系統(如 Spanner)在 Paxos 群組上執行 2PC 以提升可用性
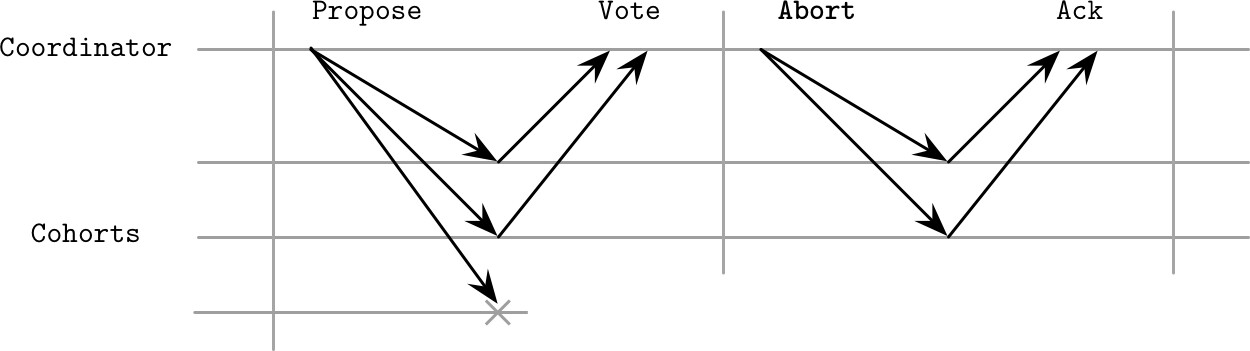
Figure 13.2: Cohort failure during the propose phase
2PC 的關鍵概念:一旦參與者正面回應提議,就不能反悔,只有協調者能中止交易。若參與者在接受提議後故障,復原時必須先得知最終投票結果才能正確提供服務。
協調者故障#
第二階段的故障:若參與者未收到 Commit 或 Abort 命令,應嘗試從同儕的交易日誌或備用協調者取得決定結果。複製提交決定是安全的,因為它總是一致的。
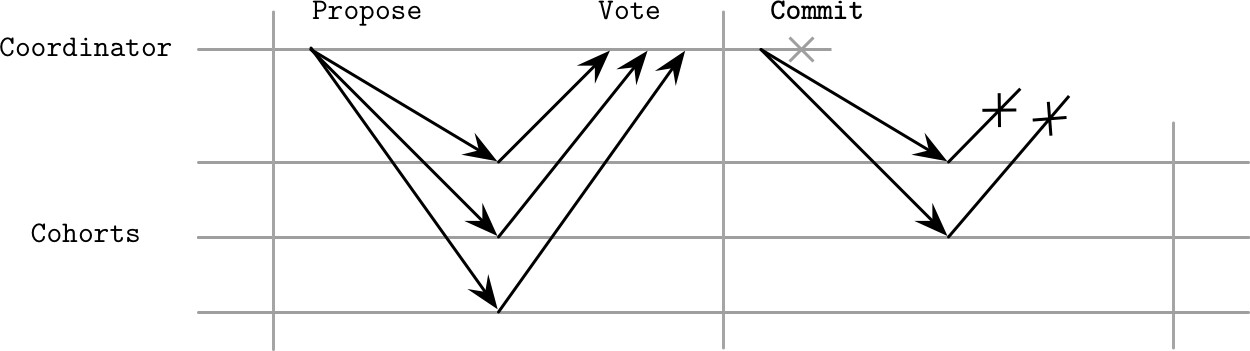
Figure 13.3: Coordinator failure after the propose phase
第一階段後的故障:若協調者在收集完投票後、廣播結果前故障,參與者陷入不確定狀態(uncertainty)——不知道協調者做了什麼決定,也不知道是否有其他參與者已被通知。
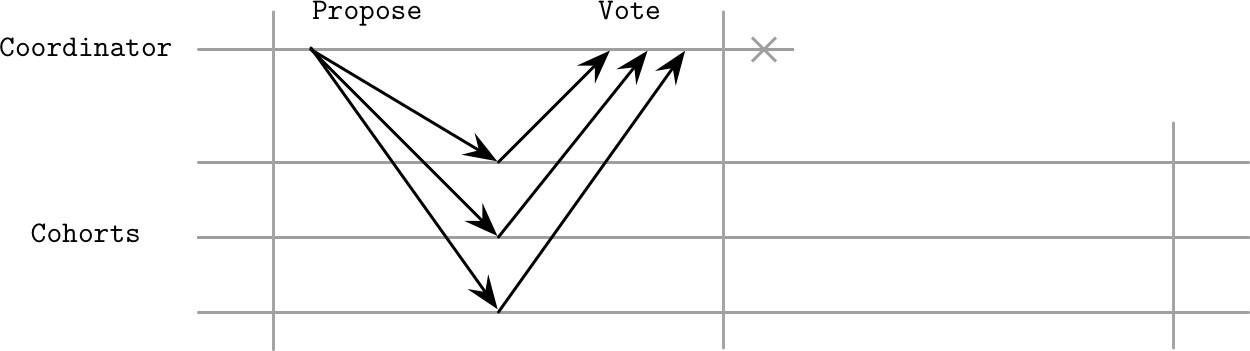
Figure 13.4: Coordinator failure before it could contact any cohorts
協調者永久故障意味著參與者無法得知最終決定。因此 2PC 被稱為**阻塞式原子提交(Blocking Atomic Commitment)**演算法。若協調者永遠不復原,其替代者必須重新收集投票並做出最終決定。
儘管有此缺陷,許多資料庫仍採用 2PC(MySQL、PostgreSQL、MongoDB 等),原因在於其簡單易懂、容易實作與除錯,且訊息複雜度與往返次數低。
三階段提交(Three-Phase Commit, 3PC)#
為克服 2PC 中協調者故障導致的阻塞問題,三階段提交增加了一個額外步驟,並在雙方加入逾時機制,使參與者在協調者故障時能自行推進提交或中止。
3PC 假設同步模型且通訊故障不會發生。在存在網路分區的環境下,3PC 可能產生矛盾狀態。
三個階段#
- 提議(Propose):協調者發送提議值並收集投票
- 準備(Prepare):協調者將投票結果通知參與者。若投票通過(所有參與者決定提交),發送 Prepare 訊息;否則發送 Abort
- 提交(Commit):協調者通知參與者提交交易
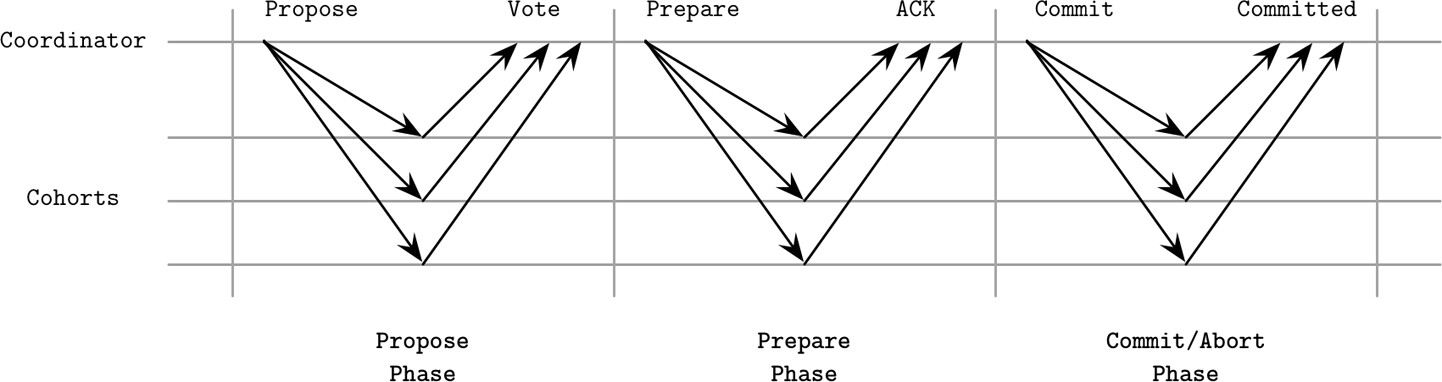
Figure 13.5: Three-phase commit
關鍵機制#
- 提議階段與 2PC 類似,若協調者崩潰導致逾時或任一參與者投反對票,交易中止
- 準備階段結束後,若所有參與者成功進入 prepared 狀態且協調者收到確認,即使任一方故障,交易仍將提交——因為此時所有參與者對狀態有相同的認知
- 提交階段重設逾時計數器,完成交易
協調者故障場景#
- 若參與者在準備階段前未收到協調者訊息,可在逾時後安全中止
- 最糟糕的情況是網路分區:部分節點成功進入 prepared 狀態後逾時提交,另一部分因無法與協調者通訊而逾時中止,導致腦裂(split brain)
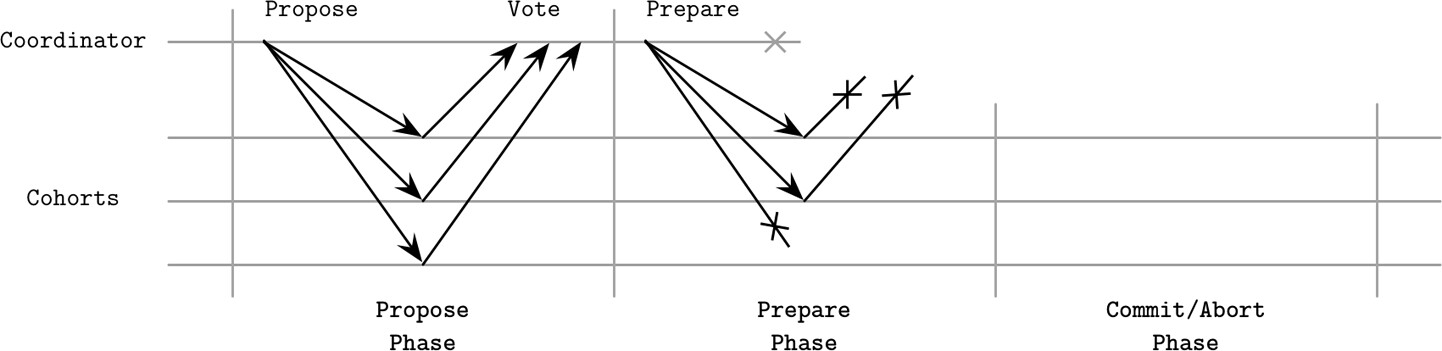
Figure 13.6: Coordinator failure during the second phase
雖然 3PC 在理論上解決了 2PC 的阻塞問題,但它有更高的訊息開銷、可能產生矛盾狀態,且在網路分區存在時表現不佳。這可能是 3PC 在實務中不被廣泛使用的主要原因。
使用 Calvin 的分散式交易#
Calvin 的核心思想是:讓所有副本在取得鎖並執行之前,先就執行順序和交易邊界達成共識。若能做到這一點,節點故障就不會導致交易中止,因為其他平行執行相同交易的節點可以恢復狀態。
確定性交易順序#
傳統資料庫使用二階段鎖定或樂觀並行控制,沒有確定性的交易順序,因此需要跨節點協調。Calvin 的確定性交易順序消除了執行階段的協調開銷——所有副本收到相同輸入,也產生相同輸出。
架構元件#
- 定序器(Sequencer):所有交易的入口點,決定交易執行順序,建立全域交易輸入序列
- 將時間線分割為 epoch
- 收集交易並分組為短時間窗口(原始論文提及 10 毫秒批次),同時作為複製單元
- 排程器(Scheduler):接收成功複製的交易批次,使用確定性排程協定平行執行交易部分,同時保持定序器指定的循序執行順序
- 工作執行緒(Worker Thread):由排程器管理,執行四個步驟:
- 分析交易的讀取集與寫入集,確定本地資料記錄,建立活躍參與者清單
- 收集執行交易所需的本地資料(讀取集中恰好在本節點的記錄),轉發給對應的活躍參與者
- 若在活躍參與者節點上,接收其他參與者轉發的資料記錄
- 執行交易批次,將結果持久化到本地儲存。不需轉發結果給其他節點,因為它們收到相同輸入並在本地執行
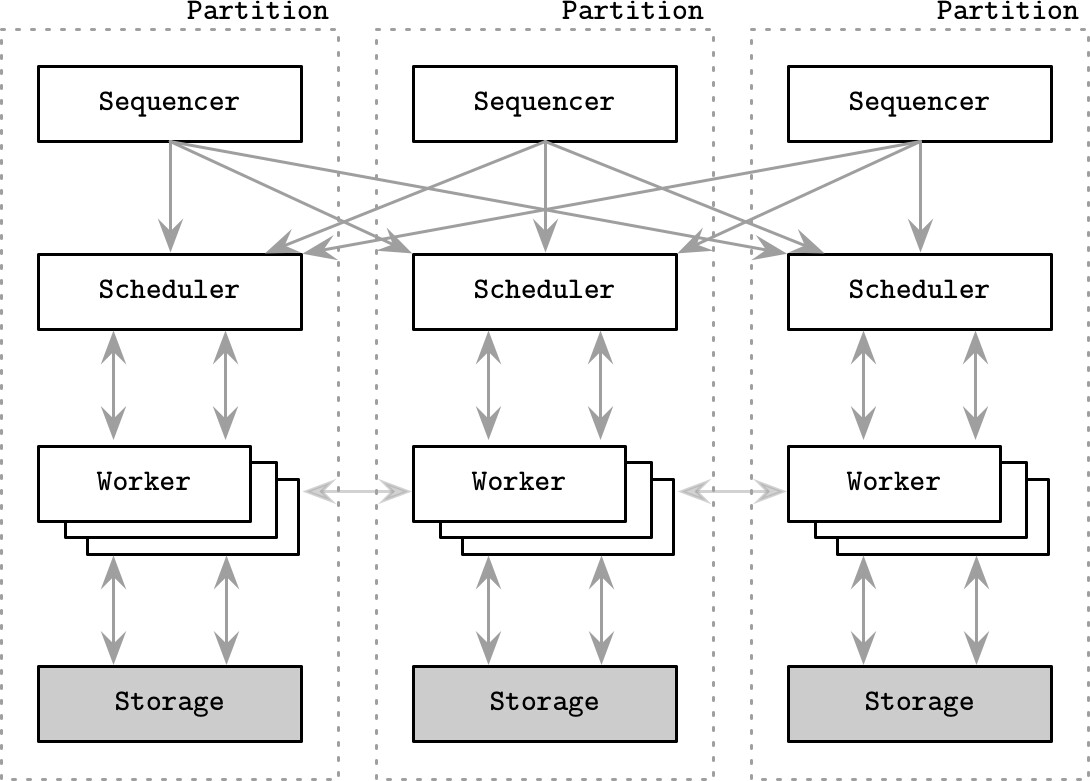
Figure 13.7: Calvin architecture
讀取集與寫入集#
每筆交易都有:
- 讀取集(Read Set):交易的相依資料,執行所需的當前資料庫記錄
- 寫入集(Write Set):交易執行的結果,即其副作用
Calvin 不原生支援需要額外讀取來決定讀寫集的交易。
定序器間的共識使用 Paxos 演算法或非同步複製(指定一個副本為 leader)。使用 leader 可降低延遲,但復原成本較高。
使用 Spanner 的分散式交易#
Spanner 常與 Calvin 對比。Calvin 透過定序器達成全域交易順序共識,而 Spanner 在每個分區的共識群組上使用二階段提交。
TrueTime#
Spanner 使用 TrueTime——一個高精度掛鐘 API,同時暴露不確定性邊界(uncertainty bound)。本地操作可引入人工延遲以等待不確定性邊界過去,藉此實現一致性和交易排序。
三種操作類型#
| 操作類型 | 鎖定 | 並行控制 | Leader 需求 |
|---|---|---|---|
| 讀寫交易 | 需要 | 悲觀 | 需要 Leader 副本 |
| 唯讀交易 | 不需要 | 無鎖 | 僅最新時間戳讀取需要 |
| 快照讀取 | 不需要 | 無鎖 | 不需要 |
每筆資料記錄都附有交易提交時間的時間戳,因此可儲存同一記錄的多個版本。
架構#
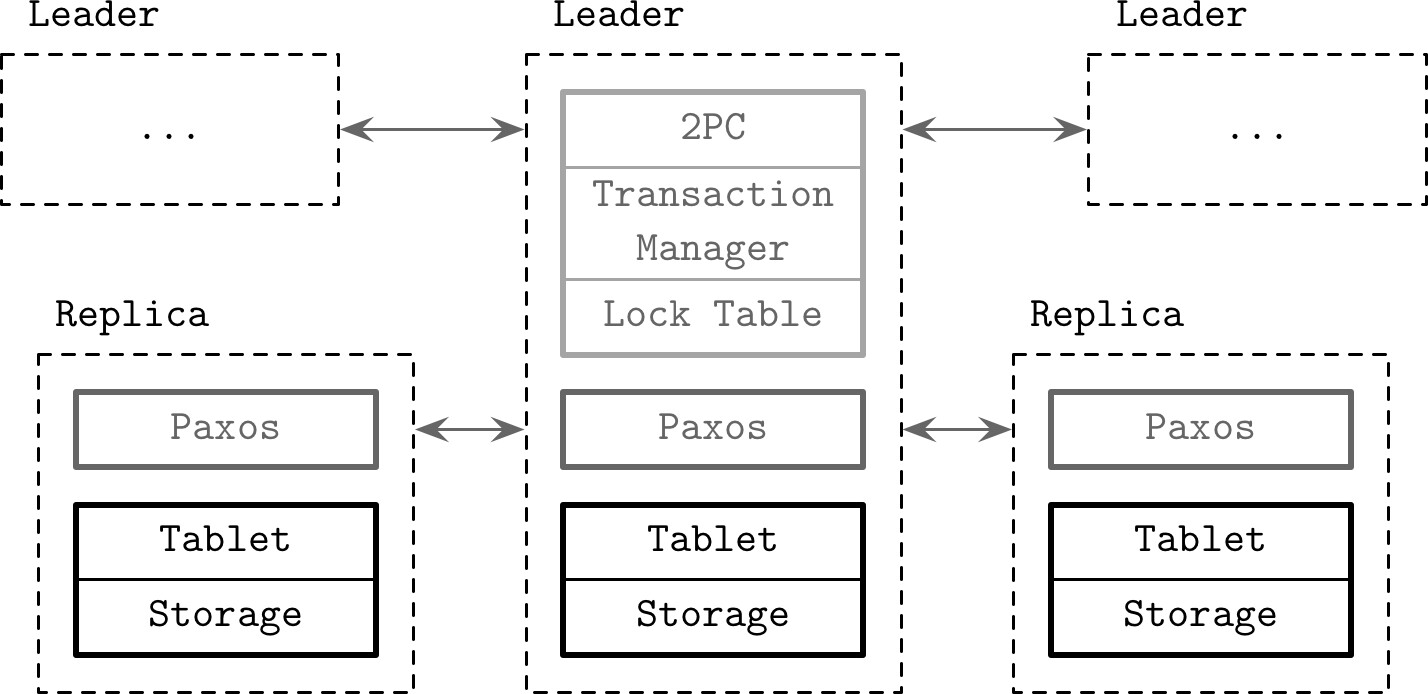
Figure 13.8: Spanner architecture
- Spanserver(副本 / 伺服器實例)持有多個 tablet,各附加 Paxos 狀態機
- 副本被分組為 Paxos 群組,作為資料放置與複製的單元
- 每個 Paxos 群組有一個長期存活的 leader
- 所有寫入必須經過 Paxos 群組 leader;讀取可直接從最新副本的 tablet 取得
Leader 持有:
- 鎖表(Lock Table):實作二階段鎖定的並行控制
- 交易管理器(Transaction Manager):負責跨分片的分散式交易
多分片交易流程#
- 各群組 leader 之間協調,執行 2PC 確保一致性,使用二階段鎖定確保隔離性
- 由於 2PC 需要所有參與者存在,Spanner 以 Paxos 群組(而非個別節點)作為參與者,即使部分群組成員當機也能繼續
- Paxos leader 先取得寫入鎖,選擇保證大於所有先前交易時間戳的寫入時間戳,通過 Paxos 記錄 2PC prepare 項目
- 交易協調者收集時間戳,產生大於所有 prepare 時間戳的提交時間戳,通過 Paxos 記錄 commit 項目
- 協調者等到所選提交時間戳已成為過去(保證客戶端只看到過去時間戳的交易結果),然後發送時間戳給客戶端和 leader
單分片交易不需要諮詢交易管理器,無需跨分區 2PC,因為 Paxos 群組加上鎖表就足以保證順序和一致性。
外部一致性(External Consistency)#
Spanner 的讀寫交易提供外部一致性:交易時間戳反映序列化順序,即使是分散式交易也是如此。其具有等同於**線性化(Linearizability)**的即時性質:若交易 T1 在 T2 開始前提交,則 T1 的時間戳必小於 T2 的時間戳。
Calvin vs. Spanner 比較#
| 面向 | Calvin | Spanner |
|---|---|---|
| 交易排序 | 定序器共識 | TrueTime 確定性排序 |
| 一致性複製 | Paxos / 非同步複製 | Paxos |
| 跨分片交易 | 確定性排程,無額外開銷 | 需額外 2PC 輪次 |
| 多分區交易成本 | 較低 | 較高(2PC 開銷) |
資料庫分區(Database Partitioning)#
現代應用難以將所有記錄存放在單一節點,因此需要分區(Partitioning)——將資料邏輯劃分為更小的可管理區段。
分片(Sharding)#
最直接的分區方式是範圍分割:每個副本集管理特定範圍,客戶端根據路由鍵將請求導向正確的副本集。
分區大小應考量:
- 負載分佈:高頻存取的範圍可分割為更小的分區以分散負載
- 值分佈密度:某些值範圍的資料比其他範圍密集(如以郵遞區號為路由鍵,人口密集區會有更多資料)
當節點加入或離開叢集時,需要重新分區以維持平衡。部分資料庫支援自動分片,使用放置演算法根據讀寫負載和各分片資料量來決定最佳分區。
雜湊分區#
某些系統計算路由鍵的雜湊值,再映射到節點 ID:
- 優點:減少範圍熱點,因雜湊值不按原始值排序
- 最簡單的映射:
hash(v) mod N - 主要問題:當叢集大小從 N 變為 N’ 時,大部分
hash(v) mod N'的結果會改變,導致大量資料搬遷
一致性雜湊(Consistent Hashing)#
為減緩上述問題,Apache Cassandra、Riak 等資料庫使用一致性雜湊:
- 雜湊值映射到一個環(ring),最大值之後繞回最小值
- 每個節點在環上佔一個位置,負責前驅位置到自身位置之間的範圍
- 優勢:環的變動只影響離開或加入節點的鄰居,而非整個叢集
- 若有 K 個可能的雜湊鍵和 n 個節點,平均只需重新定位 K/n 個鍵
使用 Percolator 的分散式交易#
快照隔離(Snapshot Isolation, SI)#
若應用不要求可序列化,快照隔離是避免寫入異常的一種交易模型:
- 交易中所有讀取都與資料庫快照一致,快照包含交易開始時間戳之前所有已提交的值
- 若兩個並行交易嘗試寫入同一儲存格(write-write conflict),只有一個能提交——先提交者勝出(First Committer Wins)
快照隔離的便利特性:
- 只允許可重複讀取已提交的資料
- 值是一致的,因為它們從特定時間戳的快照讀取
- 衝突寫入被中止並重試以防止不一致
快照隔離下的歷史並非可序列化。由於只中止對相同儲存格的衝突寫入,仍可能出現寫入偏差(Write Skew)——兩個交易修改不相交的值集合,各自維護其寫入資料的不變式,但兩者寫入的組合可能違反這些不變式。
Percolator 架構#
Percolator 是在分散式資料庫 Bigtable 之上實作交易 API 的函式庫,將資料記錄、已提交資料點位置(寫入中繼資料)和鎖分別存放在不同欄位。使用 Bigtable 的**條件式變異(Conditional Mutation)**API,在單一 RPC 呼叫中完成讀取-修改-寫入。
每筆交易需諮詢**時間戳預言機(Timestamp Oracle)**兩次:
- 取得交易開始時間戳
- 提交時取得提交時間戳
寫入被緩衝,使用客戶端驅動的二階段提交進行提交。
交易執行步驟#
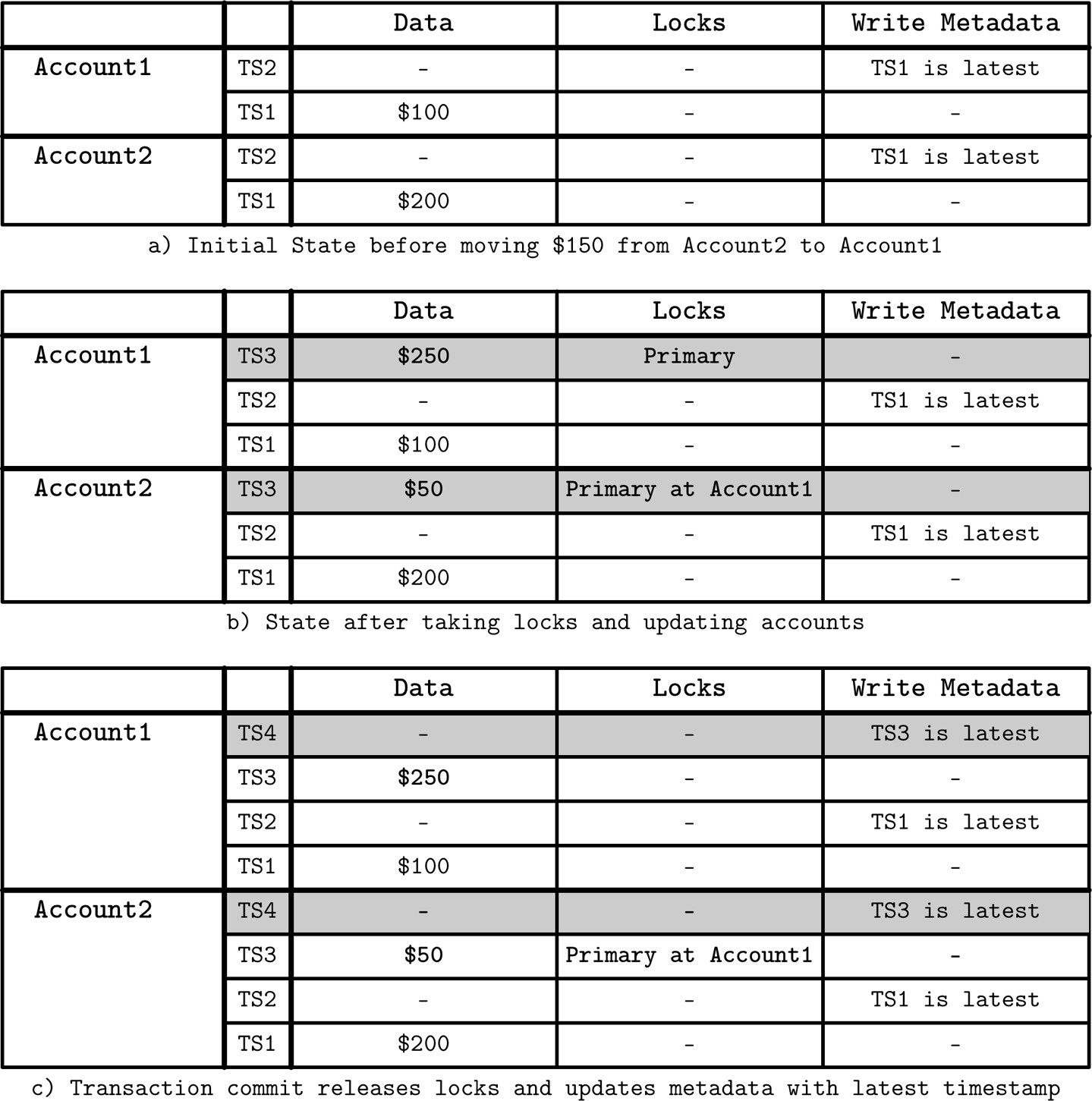
Figure 13.9: Percolator transaction execution steps
- a) 初始狀態:前一筆交易執行後,TS1 是兩個帳戶的最新時間戳,無鎖被持有
- b) 預寫階段(Prewrite):
- 嘗試為交易期間寫入的所有儲存格取得鎖
- 其中一個鎖標記為 primary,用於客戶端復原
- 檢查可能的衝突:是否有其他交易已在更晚的時間戳寫入資料,或在任何時間戳存在未釋放的鎖
- 若偵測到任何衝突,交易中止
- c) 提交階段:
- 若所有鎖成功取得且排除衝突可能,客戶端從 primary 鎖開始釋放鎖
- 以寫入記錄取代鎖,更新寫入中繼資料為最新資料點的時間戳
客戶端故障處理#
若客戶端在提交過程中故障,可能留下不完整狀態。後續交易遇到此狀態時應:
- 嘗試釋放 primary 鎖並提交交易
- 若 primary 鎖已釋放,則交易內容必須被提交
- 由於同一時間只有一個交易能持有鎖,且所有狀態轉換都是原子的,不會出現兩個交易同時操作相同內容的情況
基於 Percolator 模型的知名資料庫範例是 TiDB(Ti 代表 Titanium),一個強一致性、高可用、水平擴展的開源資料庫,相容 MySQL 協定。
協調避免(Coordination Avoidance)#
協調避免的核心思想:在仍提供強一致性保證的前提下,盡量減少協調量。
不變式融合(Invariant Confluence, I-Confluence)#
若操作具有不變式融合特性,就可以在保持資料完整性約束的同時避免協調:
- 定義:兩個各自有效但已分歧的資料庫狀態,可以合併為一個有效的最終狀態
- 含義:I-Confluent 的操作可以不經額外協調就執行,顯著提升效能與可擴展性
- 實作要求:除了定義將資料庫帶到新狀態的操作,還需定義一個合併函式接受兩個狀態,在狀態獨立更新後使其重新收斂
系統模型保證#
允許協調避免的系統模型必須保證:
- 全域有效性(Global Validity):不變式在合併和分歧的已提交狀態下始終被滿足
- 可用性(Availability):若所有持有狀態的節點都可達,交易必須能做出提交或中止決定
- 收斂性(Convergence):在沒有進一步交易和無限期網路分區的情況下,節點必須能達到相同狀態
- 協調自由(Coordination Freedom):本地交易執行獨立於其他節點代為執行的操作
RAMP 交易#
**Read-Atomic Multi Partition(RAMP)**交易是實現協調避免的一個範例,使用多版本並行控制和進行中操作的中繼資料來從其他節點取得缺少的狀態更新。
RAMP 提供兩個特性:
- 同步獨立性(Synchronization Independence):一個客戶端的交易不會使其他客戶端的交易停滯、中止或等待
- 分區獨立性(Partition Independence):客戶端不需聯繫其交易未涉及的分區
Read Atomic 隔離層級:交易不能觀察到進行中、未提交或已中止交易的任何狀態變更,也排除了碎裂讀取(Fractured Reads)——即交易僅觀察到另一交易部分寫入的情況。
RAMP 的寫入使用二階段提交安裝並使其可見:
- Prepare:將寫入放置到各自的目標分區,但不使其可見
- Commit/Abort:原子地跨所有分區公開或回滾寫入
RAMP 允許同一記錄同時存在多個版本(最新值、進行中的未提交變更、被後續交易覆寫的舊版本)。舊版本只需保留到所有並行讀取者完成為止。
總結#
本章討論了分散式交易的多種實作方式:
- 2PC(二階段提交):簡單易懂,但協調者(或至少其替代者)必須在整個提交過程中存活,顯著降低可用性。屬於阻塞式原子提交
- 3PC(三階段提交):在某些情況下解除阻塞要求,但在網路分區時容易產生腦裂
- Calvin:透過確定性交易排序,消除執行階段的協調開銷。所有副本接收相同輸入,產生相同輸出
- Spanner:結合 Paxos、2PC 和 TrueTime,提供外部一致性。多分區交易因額外 2PC 輪次而成本較高
- Percolator:在 Bigtable 上實作快照隔離的交易 API,使用客戶端驅動的 2PC
- 協調避免(RAMP):透過不變式融合減少協調量,在不犧牲一致性保證的前提下提升效能
現代分散式資料庫系統的交易實作通常依賴共識演算法(如 Paxos),它比原子提交演算法更複雜,但具有更好的容錯特性,將決定與其發起者解耦,允許參與者決定一個值,而非僅決定是否接受某個值。