本章探討分散式系統中如何透過 反熵(Anti-Entropy) 機制與 資訊散播(Dissemination) 協定,確保節點之間的資料最終一致性。
在之前的章節中,通訊模式多為點對點或一對多(協調者與副本)。但要在整個系統中可靠地傳播資料,單靠協調者是不夠的——它的吞吐量有限,而且必須在線。對於叢集範圍的元資料(成員變更、節點狀態、故障資訊、schema 變更等),雖然訊息量小且不頻繁,但必須盡可能快速且可靠地傳播到所有節點。
更新資訊可透過以下三大類方法傳播:
- a) 廣播(Broadcast):由一個程序向所有其他程序發送通知
- b) 反熵(Anti-Entropy):週期性的點對點資訊交換,節點兩兩配對交換訊息
- c) Gossip(合作式廣播):訊息接收者成為廣播者,協助更快、更可靠地散播資訊
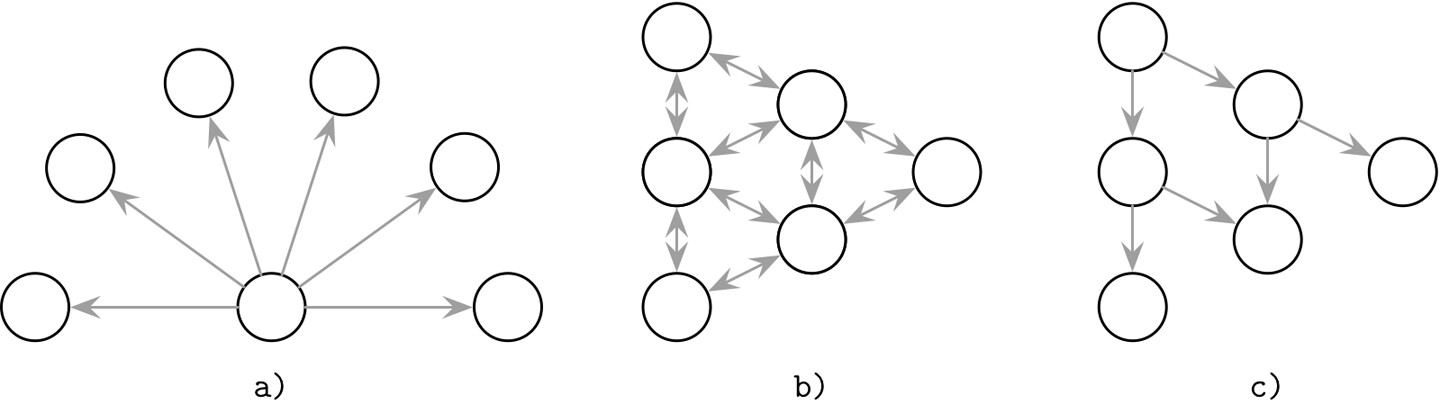
Figure 12.1: Broadcast (a), anti-entropy (b), and gossip (c)
廣播 在小型叢集中運作良好,但在大型叢集中因節點數量多而代價昂貴,且過度依賴單一程序使其不夠可靠。為放寬這些限制,可以假設部分更新可能傳播失敗——協調者盡力傳遞訊息給所有可用節點,再由反熵機制在失敗時將節點重新同步。責任由此分為兩步:主要傳遞(primary delivery) 與 週期性同步(periodic sync)。
熵(Entropy) 代表系統中的失序程度;在分散式系統中,代表節點之間的狀態偏差。反熵的目標是降低最終一致系統的收斂時間上界,讓系統即使協調者失敗,其他節點也能繼續散播資訊。
反熵觸發背景或前景程序來比較並調和缺失或衝突的記錄:
- 背景反熵:使用輔助結構如 Merkle Tree 和更新日誌來識別偏差
- 前景反熵:搭載於讀取或寫入請求上,例如 Hinted Handoff、Read Repair 等
Read Repair#
Read Repair 是在讀取時偵測副本偏差最直覺的方式。協調者執行分散式讀取時,假設所有副本同步,向它們請求查詢的資料。如果回應不同,協調者就將缺失的更新發送給落後的副本。
核心流程:
- 協調者向副本發送讀取請求
- 等待回應並進行比較
- 發現不一致時,將更新發回落後的副本
部分 Dynamo 風格資料庫使用 可調式一致性等級(tunable consistency levels) 取代接觸所有副本的需求。使用 quorum 讀寫仍能取得一致結果,但部分副本可能缺少某些寫入。
Read Repair 可實作為 阻塞式(blocking) 或 非同步式(asynchronous):
- 阻塞式:客戶端請求需等待協調者完成副本修復。確保 quorum 讀取的 讀取單調性(read monotonicity)——一旦客戶端讀到某值,後續讀取至少會回傳同樣新的值。代價是犧牲可用性,因為修復必須等待目標副本確認
- 非同步式:修復工作排程在回應返回使用者之後執行
為偵測副本之間的差異,部分資料庫(如 Apache Cassandra)使用帶有合併監聽器的特化迭代器,重建合併結果與個別輸入之間的差異,再由協調者通知副本補齊缺失資料。
Digest Reads#
為減少網路開銷,協調者可以只向一個節點發出 完整讀取請求,向其餘副本發送 摘要請求(digest request)。摘要請求讀取本地資料後計算雜湊值(而非回傳完整快照),協調者比對完整讀取的雜湊值與所有摘要:
- 摘要全部相符:確信副本已同步
- 摘要不相符:協調者無法判斷哪些副本領先或落後,必須向不一致的副本發出完整讀取,比較回應、調和資料,再將更新發送給落後的副本
摘要通常使用非加密雜湊函數(如 MD5)計算,以確保「正常路徑」的效能。雜湊碰撞的機率在實務上可忽略不計,加上資料庫通常使用多重反熵機制,即便極罕見的碰撞也能被其他子系統調和。
Hinted Handoff#
Hinted Handoff 是一種 寫入端修復機制。當目標節點無法確認寫入時,寫入協調者或某個副本會儲存一筆特殊記錄——提示(hint),待目標節點恢復後重播給它。
關鍵特性:
- 在 Apache Cassandra 中,除非使用 ANY 一致性等級,提示寫入 不計入複製因子,因為提示日誌中的資料無法被讀取,僅用於幫助落後節點追趕
- 部分資料庫(如 Riak)搭配 寬鬆仲裁(sloppy quorum) 使用 Hinted Handoff
Sloppy Quorum 範例#
假設五節點叢集 {A, B, C, D, E},其中 {A, B, C} 為寫入操作的副本,B 宕機:
- 協調者 A 挑選節點 D 來滿足 sloppy quorum,資料複製到 {A, D, C}
- D 上的記錄元資料包含提示,表明該寫入原本針對 B
- B 恢復後,D 嘗試將提示轉發給 B
- 提示在 B 重播後可安全移除,不會減少副本總數
若 {B, C} 因網路分區暫時與其餘節點隔離,sloppy quorum 寫入至 {A, D, E} 後,在 {B, C} 上的讀取將 無法觀察到最新寫入。換言之,sloppy quorum 以一致性換取可用性。
Merkle Trees#
Read Repair 只能修復當前查詢的資料。對於未被主動查詢的資料,需要不同機制來發現與修復不一致。逐筆比較整個資料集代價極高,因此許多資料庫採用 Merkle Tree(雜湊樹)來降低調和成本。
Merkle Tree 的結構:
- 最底層:掃描整個資料表,計算記錄範圍的雜湊值
- 較高層級:對下層雜湊值再次雜湊,遞迴往上建構直到樹根
- 形成資料的 階層式壓縮雜湊表示
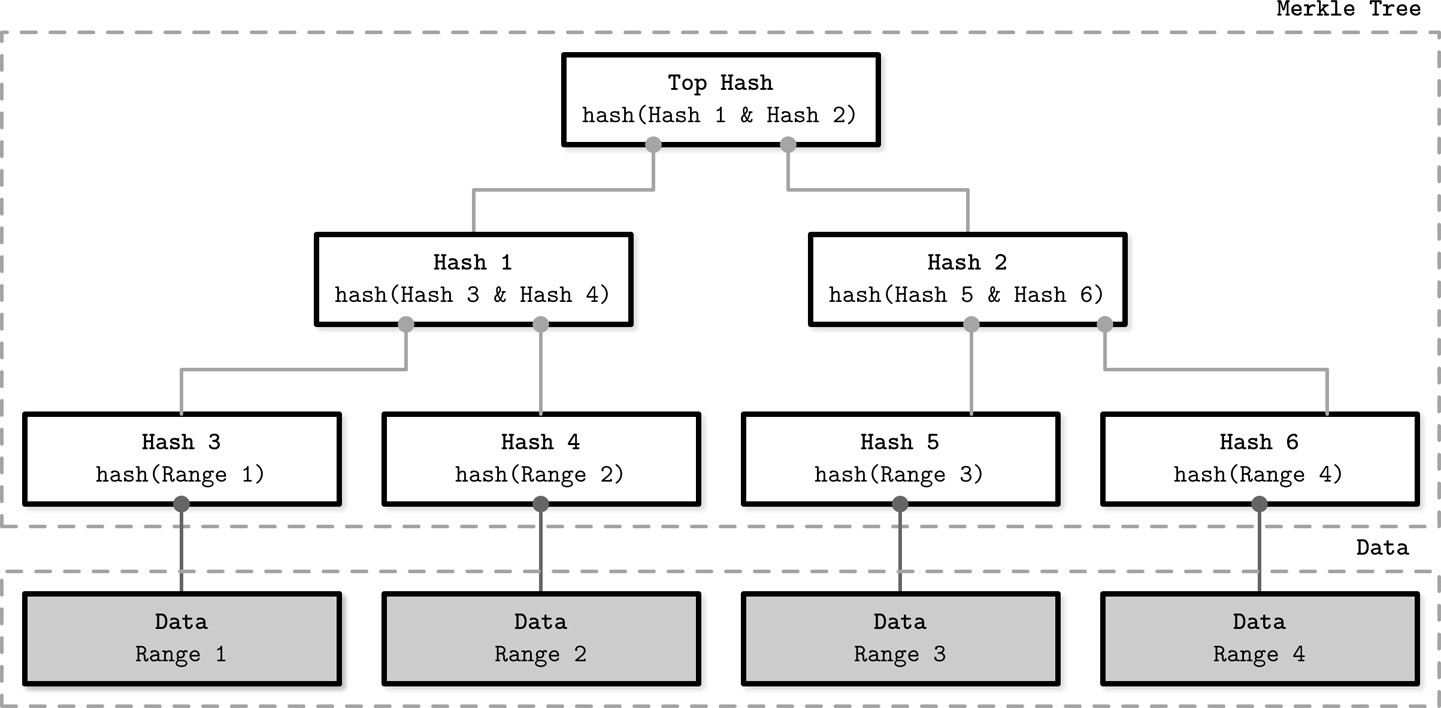
Figure 12.2: Merkle tree
使用方式:
- 只需比較兩個副本的 根層級雜湊 即可判斷是否存在不一致
- 從上到下逐層比對雜湊,定位包含差異的範圍
- 僅修復這些範圍內的資料記錄
Merkle Tree 從底部向上遞迴計算,資料變更會觸發整棵子樹的重新計算。樹的大小(訊息大小)與精確度(範圍的細緻程度)之間存在取捨。
Bitmap Version Vectors#
Bitmap Version Vectors(BVV) 是更近期的研究成果,可基於新近性(recency)解決資料衝突。每個節點維護一份 逐節點的操作日誌,記錄本地發生或被複製的操作。反熵時比較日誌,將缺失資料複製到目標節點。
核心概念#
- 每次由節點協調的寫入表示為一個 點(dot)
(i, n):序號i、協調節點n - 序號從 1 開始,每次寫入遞增
- 節點的 邏輯時鐘 記錄它所見過的所有點集合——包含直接協調的與經由複製傳遞的
同步機制#
- 節點自身協調的事件序號不會有間隙
- 未從其他節點複製的寫入會在時鐘中產生 間隙(gaps)
- 兩節點交換邏輯時鐘後,識別出缺失的點,再複製對應的資料記錄
- 使用 Dotted Causal Container(DCC) 將點映射到因果資訊,捕捉寫入之間的因果關係
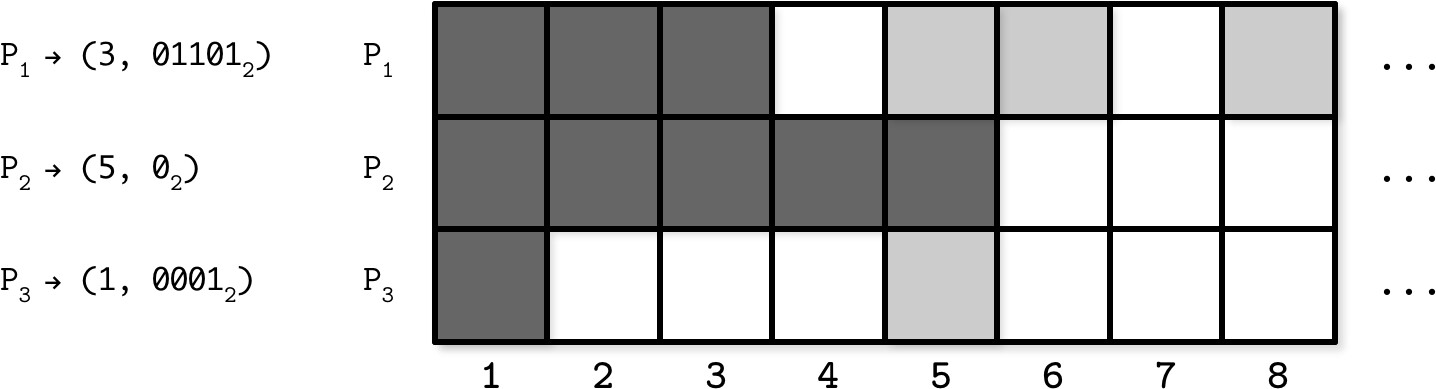
Figure 12.3: Bitmap version vector example
BVV 的壓縮表示#
以三節點系統 P1、P2、P3 為例,從 P2 的視角追蹤已見值:
- 複製時,P2 建立緊湊表示:節點識別碼對應到「已見連續寫入的最新值」加上「其他已見寫入的 bitmap」
- 例如
(3, 011012)表示 P2 已見到第 3 個值之前的所有連續更新,以及相對於 3 的第 2、3、5 個位置的值(即序號 5、6、8) - 當所有節點都見到索引
i之前的連續值時,version vector 可截斷至該索引
優點:捕捉寫入之間的因果關係,精確識別其他節點缺失的資料點
缺點:若節點長時間宕機,對等節點無法截斷日誌,必須等該節點恢復後再複製資料
Gossip Dissemination#
Gossip 協定 是基於機率的通訊程序,靈感來自謠言在人類社會中的傳播或疾病在群體中的蔓延。其主要目標是利用 合作式傳播,將資訊從一個程序散播到叢集其餘節點。
狀態模型#
Gossip 使用流行病學模型描述節點狀態:
- Infective(感染態):持有需散播的記錄,主動向隨機鄰居傳播
- Susceptible(易感態):尚未收到更新
- Removed(移除態):已確定更新傳播完成,不再傳播
所有程序從 susceptible 開始。收到更新後進入 infective 狀態,開始向隨機鄰居散播。確定更新已傳播後進入 removed 狀態。
適用場景#
- 非同步訊息傳遞的同質去中心化系統
- 成員彈性變動(頻繁加入和離開)的系統或 mesh 網路
- 不需要明確協調,非常健壯,在失敗情境下仍能高度可靠
- 即使部分通訊元件失敗,訊息仍可透過不同路徑送達
Gossip 機制#
程序週期性地隨機選取 f 個對等節點(f 為可配置的 fanout 參數),交換當前「熱門」資訊。
關鍵指標:
- 訊息冗餘度(message redundancy):因重複傳遞造成的額外開銷。冗餘是 gossip 的核心特性
- 延遲(latency):系統達到收斂所需時間。Fanout 與延遲取決於系統規模——較大系統需增加 fanout 以維持穩定延遲,或容許更高延遲
興趣衰減(interest loss) 控制停止傳播的時機:
- 機率式:每一步對每個程序計算停止傳播的機率
- 閾值式:計算收到的重複訊息數量,超過閾值則停止傳播
在一致性方面,gossip 提供 收斂一致性(convergent consistency):節點對越久以前發生的事件越可能擁有相同的視圖。
Overlay Networks#
儘管 gossip 協定實用,它們通常只適用於特定問題。非流行病式方法 能以非機率性確定性、更少冗餘、更最佳化的方式分發訊息。Gossip 可在 log N 輪訊息內分發訊息(N 為叢集大小),但冗餘訊息數量不容忽視。
折衷方案是在 gossip 系統中建構 臨時固定拓撲,形成 覆蓋網路(overlay network)。節點可取樣對等節點,依據 接近度(通常以延遲衡量) 選擇最佳聯絡點。
節點可形成 生成樹(spanning tree):無向、無迴圈、邊不重複、覆蓋整個網路的圖。有了這樣的圖,訊息可在固定步數內分發。
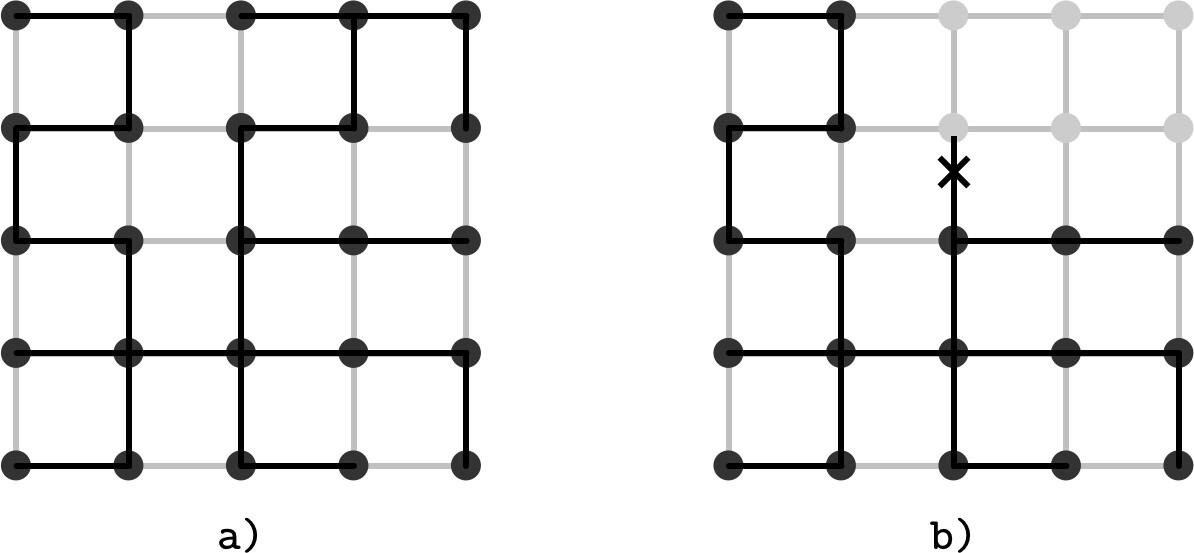
Figure 12.4: Spanning tree
生成樹的特性:
- 優點:不使用所有邊即可達成全連通
- 缺點:單一鏈結斷裂就可能失去與整棵子樹的連通性
- 可能導致形成互相偏好的「孤島」
最佳策略是 混合兩種方法:穩定時使用固定拓撲和樹狀廣播,失敗時回退到 gossip 進行故障轉移和系統恢復。
Hybrid Gossip(Plumtree)#
Push/Lazy-Push Multicast Trees(Plumtree) 結合了流行病式與樹狀廣播的優點,建立生成樹覆蓋網路以最小開銷主動分發訊息。
運作方式:
- 節點將 完整訊息 發送給少數對等節點子集
- 對其餘節點僅 懶推送(lazy-push)訊息 ID
- 若節點收到從未見過的訊息 ID,可向對等節點查詢取得完整訊息
- 懶推送步驟確保高可靠性,並提供快速修復廣播樹的方式
- 失敗時,協定透過懶推送步驟回退到 gossip,廣播訊息並修復覆蓋網路
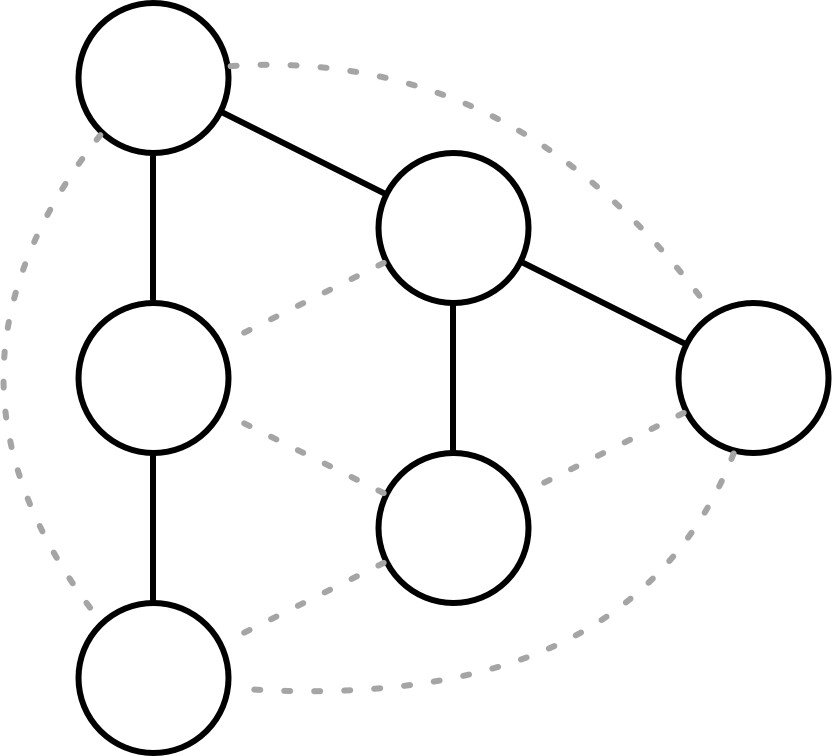
Figure 12.5: Lazy and eager push networks
懶推送機制的優勢:在負載穩定的網路中,傾向生成同時最小化訊息延遲的樹,因為最先回應的節點會被加入廣播樹。
Partial Views#
向所有已知對等節點廣播並維護叢集的完整視圖代價昂貴,特別是 churn(節點加入和離開的頻率) 很高時。Gossip 協定常使用 對等節點取樣服務(peer sampling service) 來維護叢集的 部分視圖(partial view)。
HyParView 協定 維護兩種視圖:
- Active View(主動視圖):小型,節點形成用於訊息散播的覆蓋網路
- Passive View(被動視圖):較大,維護可用於替換主動視圖中失敗節點的候選列表
運作機制:
- 節點週期性執行 shuffle 操作,交換主動和被動視圖
- 將從對等節點收到的視圖成員加入被動視圖,淘汰最舊的值以控制列表大小
主動視圖更新規則:
- 若 P1 懷疑主動視圖中的 P2 已失敗,P1 移除 P2 並嘗試與被動視圖中的 P3 建立連線
- 若連線失敗,P3 從 P1 的被動視圖中移除
- 若 P3 的主動視圖已滿,可選擇拒絕連線
- 若 P1 的主動視圖為空,P3 必須替換其當前主動視圖中的某個節點以容納 P1——這有助於啟動中或恢復中的節點快速成為叢集的有效成員
HyParView 與 Plumtree 使用混合式 gossip 方法:以少數對等節點子集廣播訊息,失敗或網路分區時回退到更廣泛的對等節點網路。兩者都不依賴包含所有成員的全域視圖,部分視圖讓節點只需與少數鄰近節點主動通訊。
總結#
最終一致系統容許副本狀態偏差,可透過以下反熵機制解決:
| 機制 | 類型 | 說明 |
|---|---|---|
| Hinted Handoff | 寫入端 | 目標節點宕機時,暫存寫入於鄰近節點,目標恢復後重播 |
| Read Repair | 讀取端 | 讀取時比較副本回應,偵測缺失記錄並發送給落後副本 |
| Merkle Tree | 背景 | 計算並交換階層雜湊樹,偵測需要修復的資料範圍 |
| Bitmap Version Vectors | 背景 | 維護緊湊記錄,包含最近寫入資訊,偵測缺失的副本寫入 |
這些方法各自針對三個參數之一進行最佳化:
- 範圍縮減(scope reduction):僅同步被主動查詢的資料(Read Repair)或個別缺失寫入(Hinted Handoff)
- 新近性(recency):假設多數故障為暫時性,儲存最近偏差事件的日誌,精確知道需同步的內容(Bitmap Version Vectors)
- 完整性(completeness):需要逐對比較多節點上的完整資料集時,雜湊資料並比較雜湊值(Merkle Trees)
在大規模系統中可靠地分發資訊,可使用 Gossip 協定。混合式 gossip(如 Plumtree、HyParView)在減少交換訊息數量的同時,保持對網路分區的抵抗力。許多現代系統使用 gossip 進行故障偵測與成員資訊管理。