在探討共識(consensus)與原子提交(atomic commitment)演算法之前,本章先整理一塊重要的拼圖:一致性模型(consistency models)。當系統中存在多份資料複本時,一致性模型定義了資料的可見性語意與系統行為。
容錯與複製#
容錯(fault tolerance) 是指系統在部分元件故障時仍能正確運作的能力。要達成容錯,核心策略是:
- 消除單點故障(single point of failure),為關鍵元件提供冗餘
- 冗餘對使用者應完全透明
- 當一台機器故障時,另一台可接手(failover)
資料複製(data replication) 是引入冗餘的方式,在系統中維護多份資料複本。然而,原子性地更新所有複本等同於共識問題,成本很高。因此我們需要更具成本效益的方式,在允許一定程度分歧的前提下,讓使用者感受到一致。
複製在多資料中心部署(multidatacenter deployment) 中特別重要:
- 提高可用性,承受一個或多個資料中心故障
- 將資料放置在靠近客戶端的位置,降低延遲
談到複製時,最核心的三個事件是:寫入(write)、副本更新(replica update)、讀取(read)。
實現可用性#
系統可用性(availability) 極為重要——軟體已成為社會不可或缺的一部分(銀行交易、通訊、旅行等),缺乏可用性意味著失去客戶或金錢。
要建構高可用系統:
- 設計能優雅處理一個或多個參與者故障的架構
- 引入冗餘與複製
- 一旦加入冗餘,就面臨多份資料同步與恢復機制的挑戰
CAP 定理#
可用性(availability) 衡量系統對每個請求成功回應的能力。一致性(consistency) 在此定義為原子性或線性化一致性(linearizable consistency)。理想情況下,我們希望在容忍網路分區的同時,同時達成一致性與可用性。
CAP 定理(由 Eric Brewer 提出)指出:在網路分區(partition)存在的情況下,不可能同時保證可用性和一致性。我們只能在兩者之間取其一:
- CP 系統(一致且分區容忍):偏好拒絕請求,而非提供可能不一致的資料。例如共識演算法的實作,需要多數節點才能運作。
- AP 系統(可用且分區容忍):放鬆一致性要求,允許在請求期間提供可能不一致的值。例如只要有一個副本在線就接受寫入的資料庫。
PACELC 定理(CAP 的擴展)進一步指出:在網路分區時需要在一致性與可用性之間選擇(PAC);即使系統正常運行(E),仍需在延遲(latency) 與一致性之間做出抉擇。
正確理解 CAP#
使用 CAP 時需注意幾個重點:
- CAP 討論的是網路分區而非節點當機——即使所有節點都在線,只要存在連線問題就會面臨一致性問題
- CAP 有時被畫成三角形,暗示可以在三者間調節,但分區容忍(partition tolerance) 不是可以現實調整或交換的屬性
- CAP 中的一致性與 ACID 中的一致性不同:ACID 一致性是指交易將資料庫從一個合法狀態帶到另一個合法狀態;CAP 一致性是指操作要麼完全成功要麼完全失敗且不留下不一致狀態
- CAP 中的可用性也與高可用性不同:CAP 的定義不限制執行延遲,也不要求每個未故障節點都回應每個請求
Harvest 與 Yield#
CAP 只討論最強形式的一致性與可用性,迫使我們做硬性取捨。我們可以定義兩個可調指標:
- Harvest(收穫):查詢結果的完整度。若查詢應回傳 100 筆但只能取得 99 筆,仍可能優於完全失敗
- Yield(產出):成功完成的請求數佔總嘗試請求數的比例。不同於 uptime,因為忙碌的節點不算宕機但仍可能無法回應部分請求
這將取捨從絕對轉為相對:可以犧牲 harvest 換取 yield,例如只從可用分區回傳結果,或要求關鍵資料必須完整但允許其他請求有所偏差。
共享記憶體模型#
對客戶端而言,分散式資料存儲系統就像擁有共享儲存空間一樣。一個可讀寫的單一儲存單元稱為暫存器(register),可將共享記憶體視為暫存器陣列。
每個操作由呼叫(invocation) 和完成(completion) 事件識別。若一個操作的呼叫與完成事件都在另一操作呼叫之前發生,則這兩個操作是循序的(sequential);否則是並行的(concurrent)。

Figure 11.1: Sequential and concurrent operations
根據暫存器在並行操作下的行為,可分為三類:
- Safe 暫存器:在並行寫入期間,讀取可能回傳暫存器範圍內的任意值
- Regular 暫存器:讀取只能回傳最近完成寫入的值,或與當前讀取重疊的寫入所寫的值
- Atomic 暫存器:保證線性化——每個寫入都有一個時間點,在此之前讀取回傳舊值,之後回傳新值
操作排序#
在分散式系統中,很難精確知道事情何時發生並即時讓全叢集都擁有此資訊。每個參與者可能有自己的狀態視角,因此必須以呼叫和完成事件來描述操作邊界。
思考一致性模型最簡單的方式是考慮讀寫操作如何重疊:讀取無副作用,寫入改變暫存器狀態。若所有操作由單一行程執行,可強制嚴格排序;多行程則更為複雜,困難可歸為兩類:
- 操作可能重疊
- 非重疊呼叫的效果可能無法立即可見
一致性模型#
一致性模型提供不同的語意與保證,可視為參與者之間的契約:每個副本需要做什麼來滿足語意要求,使用者在讀寫操作時可以期望什麼。
沒有全域時鐘,就很難給分散式操作一個精確且確定的順序。就像資料的「狹義相對論」:每個參與者對狀態和時間都有自己的觀點。
一致性模型在 CAP 之外增加了另一個維度:不僅需要在一致性與可用性之間取捨,還需考慮同步成本(synchronization costs)——延遲、額外 CPU 週期、磁碟 I/O、等待時間、網路 I/O 等。
嚴格一致性(Strict Consistency)#
嚴格一致性是完全複製透明性的等價物:任何行程的寫入都即時可供所有後續讀取使用。它涉及全域時鐘的概念——若在時刻 t1 執行 write(x, 1),則在任何 t2 > t1 時刻的 read(x) 都回傳 1。
這只是一個理論模型,不可能實作,因為物理定律與分散式系統的運作方式限制了事情發生的速度。
線性化(Linearizability)#
線性化是最強的單物件、單操作一致性模型。其核心特性:
- 寫入的效果在其開始與結束之間的某個時間點對所有讀者同時可見
- 沒有客戶端能觀察到部分或未完成寫入操作的狀態轉換或副作用
- 並行操作被表示為某種可能的循序歷史
- 若兩個操作重疊,可以任意順序生效
- 一旦某個讀取回傳特定值,之後所有讀取都回傳至少與該值一樣新的值
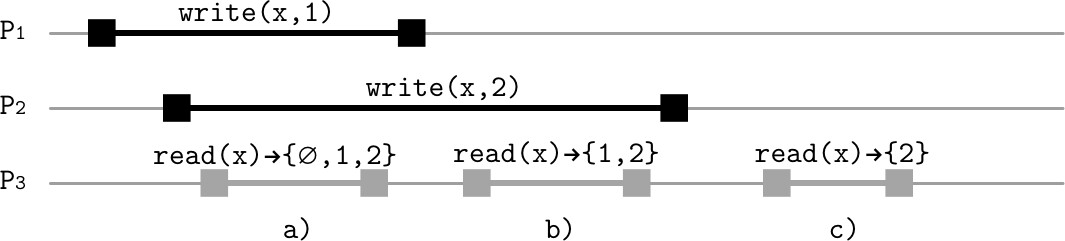
Figure 11.2: Example of linearizability
線性化點(Linearization Point)#
線性化最重要的特性是可見性:一旦操作完成,所有人都必須看到它,系統不能「回到過去」。線性化禁止過時讀取(stale reads) 並要求讀取是單調的(monotonic)。
線性化點是操作效果變得可見的時刻,讓操作看起來像是瞬間完成的。在寫入操作的線性化點之後,每個行程都必須看到該操作寫入的值或之後寫入的更新值。可見值在下一個值變得可見之前應保持穩定。

Figure 11.3: Time bounds of a linearizable operation
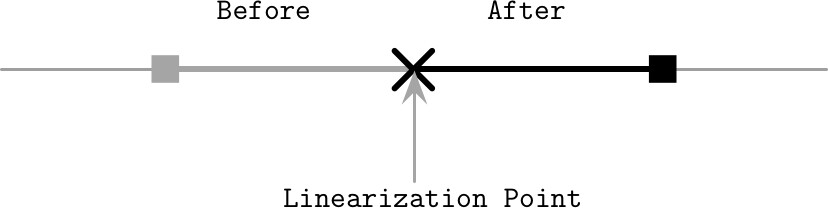
Figure 11.4: Linearization point
線性化的成本#
許多系統今天避免實作線性化。甚至 CPU 預設也不提供線性化記憶體存取,因為同步指令昂貴、緩慢,涉及跨節點 CPU 流量和快取失效。
- 在並行程式設計中,可使用 compare-and-swap(CAS)操作引入線性化
- 在分散式系統中,線性化需要協調與排序,可透過共識實作:客戶端與複製存儲互動,共識模組確保操作在叢集中一致
- 線性化是局部屬性(local property),意味著組合線性化歷史也是線性化的——但範圍僅限於單一物件
RIFL(Reusable Infrastructure for Linearizability) 是實作線性化遠端程序呼叫(RPC)的機制。透過客戶端 ID 與單調遞增序號唯一識別訊息,並使用租約(lease)確保唯一性。若伺服器在確認寫入前當機,客戶端可能重試已套用的操作。RIFL 透過儲存完成物件(completion object) 防止重複執行,使操作結果原子性可見,從而實現線性化。
循序一致性(Sequential Consistency)#
線性化可能太昂貴。循序一致性放鬆了模型,但仍提供相當強的保證:
- 操作可被排序為某種循序順序
- 每個個別行程的操作按其執行順序排列
- 行程可觀察到其他參與者的操作,但從全域視角來看可能是任意過時的
- 跨行程的執行順序未定義,因為沒有共享的時間概念
與線性化的關鍵差異:
| 特性 | 線性化 | 循序一致性 |
|---|---|---|
| 全域排序 | 是 | 是 |
| 尊重即時操作順序 | 是 | 否 |
| 可組合性 | 是 | 否 |
| 同源寫入順序 | 保留 | 保留 |

Figure 11.5: Ordering in sequential consistency
循序一致性的核心差異在於缺乏全域強制時間邊界。操作結果可在完成之後才變得可見,只要從個別處理器的視角來看順序是一致的。同源寫入不能互相跳過——相對於執行行程的程式順序必須被保留。
現代 CPU 預設不保證循序一致性。因為處理器可能重排指令,需使用記憶體屏障(memory barriers / fences) 確保寫入按序對並行線程可見。
因果一致性(Causal Consistency)#
即使全域操作順序通常不必要,某些操作之間仍可能需要建立順序。因果一致性要求:
- 所有行程必須以相同順序看到因果相關的操作
- 無因果關係的並行寫入可被不同處理器以不同順序觀察
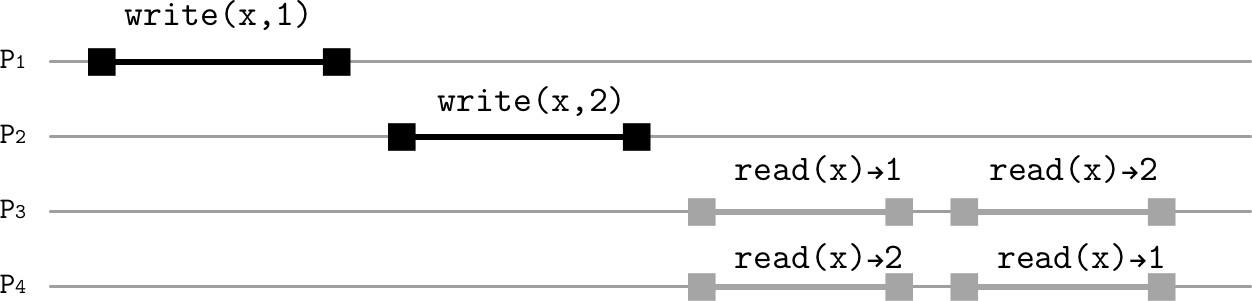
Figure 11.6: Write operations with no causal relationship

Figure 11.7: Causally related write operations
因果順序透過邏輯時鐘(logical clock) 建立。即使後發生的寫入比前一個傳播得更快,在所有依賴都到達並從邏輯時間戳重建事件順序之前,它不會被設為可見。happened-before 關係是在不使用物理時鐘的情況下邏輯建立的。
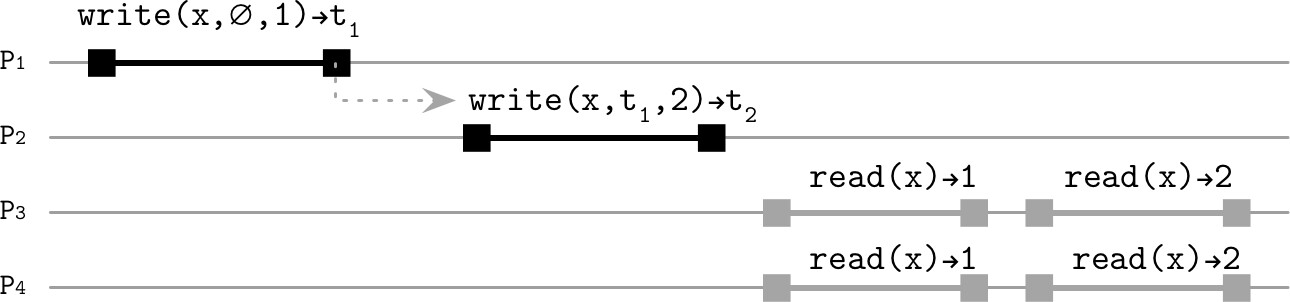
Figure 11.8: Write operations with causal relationship
在因果一致系統中,應用程式獲得工作階段保證(session guarantees):
- 單調讀取(monotonic reads)
- 單調寫入(monotonic writes)
- 讀己所寫(read-your-writes)
- 寫隨讀後(writes-follow-reads)
因果一致性的實作:透過邏輯時鐘並在每條訊息中傳送上下文中繼資料,摘要哪些操作邏輯上先於當前操作。接收到更新時包含最新版本的上下文,只有所有前置操作已套用後才能處理操作。上下文不匹配的訊息會被緩衝。
兩個知名的因果一致性實作:
- COPS(Clusters of Order-Preserving Servers):透過鍵版本追蹤依賴
- Eiger:建立操作順序(操作可依賴其他節點上的操作)
向量時鐘(Vector Clocks)#
向量時鐘是建立事件間偏序(partial order) 的結構,用於偵測和解決事件鏈分歧。許多資料庫(如 Dynamo、Riak)使用向量時鐘建立因果順序。
運作方式:
- 行程維護邏輯時鐘向量,每個行程一個時鐘
- 每個時鐘從初始值開始,每次新事件到達時遞增
- 接收其他行程的時鐘向量時,更新本地向量為每個行程的最高時鐘值
用於衝突解決時:
- 寫入前先檢查本地是否已有該鍵的值
- 若有,將新版本附加到版本向量,建立兩次寫入的因果關係
- 否則,開始新的事件鏈並以單一版本初始化

Figure 11.9: Divergent histories under causal consistency
向量時鐘能告訴你衝突已發生,但不提供如何解決的方案,因為解決語意通常是應用程式特定的。因此某些最終一致性資料庫(如 Apache Cassandra)不使用因果排序,而是使用 last-write-wins 規則進行衝突解決。
工作階段模型(Session Models)#
從客戶端視角看分散式系統的一致性,比從多客戶端的值傳播角度更直觀。工作階段模型(也稱客戶端為中心的一致性模型)描述單一客戶端如何觀察系統狀態。
在分散式系統中,客戶端通常可連接到任何可用副本。若最近對一個副本的寫入尚未傳播到另一個,客戶端可能無法觀察到自己的狀態變更。
四種工作階段模型:
- 讀己所寫(Read-own-writes):跟隨寫入的每個讀取操作(無論在同一或不同副本)都必須觀察到更新的值
- 單調讀取(Monotonic reads):若
read(x)觀察到值 V,後續讀取必須觀察到至少與 V 一樣新的值 - 單調寫入(Monotonic writes):來自同一客戶端的值按客戶端執行的順序出現。若
write(x,V2)在write(x,V1)之後,效果必須以相同順序(V1 先、V2 後)對所有行程可見。沒有此保證,舊資料可能「復活」,導致資料遺失 - 寫隨讀後(Writes-follow-reads):也稱工作階段因果性。寫入在先前讀取觀察到的寫入之後排序
工作階段模型不對不同行程或不同邏輯工作階段的操作做假設。這些模型描述的是單一行程視角的操作排序。但同樣的保證必須對系統中的每個行程都成立。
結合單調讀取、單調寫入和讀己所寫,可得到 Pipelined RAM(PRAM)一致性(也稱 FIFO 一致性):保證來自一個行程的寫入按該行程執行的順序傳播。與循序一致性不同,來自不同行程的寫入可被以不同順序觀察。
最終一致性(Eventual Consistency)#
同步是昂貴的。我們可以放鬆一致性保證,允許節點之間的一些分歧。
最終一致性正式定義:若對資料項目沒有額外更新,最終所有存取都會回傳最後寫入的值。發生衝突時,「最新值」的概念可能改變,需透過衝突解決策略(如 last-write-wins 或向量時鐘)調和分歧副本的值。
「最終」是個有趣的術語——它不指定硬性時間邊界。但在實務中,許多資料庫被描述為最終一致性且運作良好。
可調一致性(Tunable Consistency)#
最終一致性系統通常從伺服器端實作可調一致性,使用三個變數:
| 變數 | 說明 |
|---|---|
| 複製因子 N | 儲存資料複本的節點數 |
| 寫入一致性 W | 需確認寫入的節點數 |
| 讀取一致性 R | 需回應讀取的節點數 |
當 R + W > N 時,系統可保證回傳最近寫入的值,因為讀取與寫入集合之間一定有重疊。
例如 N=3, W=2, R=2:
- 系統可容忍一個節點故障
- 三個中的兩個必須確認寫入
- 在理想情況下,系統也會非同步複製到第三個節點
- 讀取時任意兩個節點的組合都至少有一個擁有最新記錄
不同策略的取捨:
- 寫入密集系統:可選擇 W=1, R=N(寫入只需一個節點確認,但讀取需要所有副本可用)
- 讀取密集系統:可選擇 W=N, R=1(任何節點都能讀到最新值,但寫入需所有副本確認)
- 提高讀取或寫入一致性級別會增加延遲並提高節點可用性要求
- 降低則改善系統可用性但犧牲一致性
法定人數(Quorum)#
由 ⌊N/2⌋ + 1 個節點組成的一致性級別稱為法定人數(quorum),即節點的多數。在 2f + 1 個節點的系統中,最多可容忍 f 個節點故障。
使用法定人數讀寫不保證單調性。若某個寫入操作只寫入三個副本中的一個後就失敗了,法定人數讀取可能交替回傳不完整操作的結果或舊值。要達成讀取單調性(以犧牲可用性為代價),需使用阻塞式讀修復(blocking read-repair)。
見證副本(Witness Replicas)#
法定人數提高了可用性,但增加了儲存成本(複製因子為 5 就需要 5 份複本)。見證副本可改善此問題:
- 將副本分為複本副本(copy replicas) 和見證副本(witness replicas)
- 複本副本持有完整資料記錄
- 見證副本在正常情況下只儲存表示寫入操作已發生的記錄
- 當複本副本數量過低時(例如故障),見證副本可暫時升級為儲存完整記錄
- 原始複本副本恢復後,升級的副本恢復為見證狀態
具有 n 個複本副本和 m 個見證副本的系統,擁有與 n + m 個複本相同的可用性保證,前提是:
- 讀寫操作使用多數(N/2 + 1 個參與者)
- 法定人數中至少一個是複本副本
實作範例:Spanner 與 Apache Cassandra。
強最終一致性與 CRDTs#
強最終一致性(Strong Eventual Consistency, SEC) 是強一致性與弱一致性之間的折衷:
- 允許更新晚到或亂序傳播
- 當所有更新最終傳播到目標節點時,衝突可被解決並合併產生相同的合法狀態
無衝突複製資料類型(CRDTs)#
CRDTs(Conflict-Free Replicated Data Types) 是專門設計的資料結構,排除衝突的存在,允許操作以任意順序套用而不改變結果。例如在 Redis 中實作。
CRDT 的價值:在多節點系統中,即使節點因網路分區無法通訊,也能獨立執行操作。通訊恢復後,所有節點的結果可調和,不會遺失任何操作。
操作型 CmRDTs(Commutative Replicated Data Types) 要求操作滿足:
- 無副作用(side-effect free):不改變系統狀態
- 交換律(commutative):x . y = y . x
- 因果排序(causally ordered):成功遞送依賴於前置條件
CRDT 範例#
Grow-only Counter(只增計數器):
- 每個伺服器持有一個狀態向量,記錄所有參與者的最新計數器更新
- 每個伺服器只能修改自己在向量中的值
- 合併函數:取每個位置的最大值
初始: Node 1: [0,0,0] Node 2: [0,0,0] Node 3: [0,0,0]
更新後: Node 1: [1,0,0] Node 2: [0,0,0] Node 3: [0,0,1]
合併: merge([1,0,0], [0,0,1]) = [1,0,1] → sum = 2PN-Counter(正負計數器):使用兩個向量 P(遞增)和 N(遞減),支援遞增和遞減操作。
LWW Register(Last-Write-Wins 暫存器):附加全域排序時間戳,衝突時保留較大時間戳的值。若不能丟棄值,可使用多值暫存器(multi-value register) 儲存所有值讓應用程式選擇。
G-Set(Grow-only Set):每個節點維護本地狀態並追加元素,合併兩個集合也是交換操作。可用兩個集合支援新增和移除(加法集 - 移除集 = 當前狀態)。
更複雜的範例如無衝突複製 JSON 資料類型,允許在深層巢狀 JSON 文件上執行插入、刪除和賦值操作,在客戶端執行合併操作,不要求操作以特定順序傳播。
總結#
容錯系統使用複製提高可用性,但維持多份複本同步需要額外協調。本章討論了數個單操作一致性模型,從保證最強到最弱排列:
| 一致性模型 | 核心保證 |
|---|---|
| 線性化(Linearizability) | 操作看起來瞬間套用,維持即時操作順序 |
| 循序一致性(Sequential) | 操作效果以某種全序傳播,與個別行程的執行順序一致 |
| 因果一致性(Causal) | 因果相關操作的效果以相同順序對所有行程可見 |
| PRAM/FIFO 一致性 | 操作效果按個別行程的執行順序可見;不同行程的寫入可被以不同順序觀察 |
工作階段模型從客戶端視角描述一致性:
| 工作階段模型 | 保證 |
|---|---|
| 讀己所寫 | 讀取反映先前的寫入 |
| 單調讀取 | 觀察到的值不會回退 |
| 單調寫入 | 同一客戶端的寫入按序傳播 |
| 寫隨讀後 | 寫入排在先前讀取所觀察到的寫入之後 |
最終一致性與可調一致性提供了靈活性:法定人數系統使用多數來提供一致資料,見證副本可降低儲存成本。CRDTs 透過排除衝突的資料結構設計,在允許副本暫時分歧的同時仍能保證最終收斂到相同狀態。
理解這些概念有助於掌握底層系統的保證,並正確用於應用程式開發。在保證較弱的系統上堆疊更弱保證的系統,或忽略底層系統的一致性影響,可能導致不可恢復的不一致與資料遺失。