為什麼需要 Leader?#
在分散式系統中,同步(synchronization)的代價很高:若每個演算法步驟都需要聯繫所有參與者,通訊開銷將十分龐大,尤其在大型且地理分散的網路中更為明顯。為了降低同步成本和訊息往返次數,許多演算法引入了 Leader(有時稱為 coordinator)的角色,由它負責執行或協調分散式演算法的各個步驟。
Leader 的核心價值:
- 減少狀態同步:避免遠端參與者之間頻繁的狀態同步
- 降低訊息量:由單一程序驅動執行,而非點對點協調
- 簡化協調:在廣播中實現訊息的全序(total order),或在故障後協調系統重組
Leader 的特性#
- 分散式系統中的程序通常是對等的(uniform),任何程序都能擔任 Leader
- Leader 角色並非永久性——程序會持續擔任 Leader 直到當機為止
- 當 Leader 當機後,其他程序可發起新一輪選舉,接替其工作
Liveness 與 Safety#
- Liveness 保證:大多數時間系統都有 Leader,且選舉最終會完成(系統不應無限期處於選舉狀態)
- Safety 保證:理想情況下,任何時刻最多只有一個 Leader,完全排除 split brain(兩個 Leader 同時存在但彼此不知)的可能性
- 但在實務中,許多 Leader 選舉演算法會違反 safety 保證
Leader Election vs. Distributed Locking#
雖然 Leader 選舉和分散式鎖看起來相似,但有關鍵差異:
| Leader Election | Distributed Locking | |
|---|---|---|
| 身份是否重要 | 所有參與者都需知道 Leader 是誰 | 其他程序不需要知道誰持有鎖 |
| 持有時間 | 長期持有,直到當機 | 最終必須釋放 |
| 偏好性 | 偏好穩定的 Leader | 不應偏好特定程序(否則造成 starvation) |
Leader 的瓶頸問題#
Leader 可能成為系統瓶頸。常見的解決方式是將資料分割為不相交的獨立副本集(replica set),每個副本集擁有自己的 Leader,而非使用單一的系統級 Leader。例如 Spanner 就採用了這種方式。
與共識演算法的關係#
ZAB、Multi-Paxos、Raft 等演算法使用臨時 Leader 來減少達成共識所需的訊息數量,但它們各自有專屬的 Leader 選舉、故障偵測和衝突解決機制。
Bully Algorithm#
Bully Algorithm(霸凌演算法)利用程序的 rank(排名)來決定新 Leader:rank 最高的程序成為 Leader。因為最高排名的節點會「霸凌」其他節點接受它的領導,故得此名。也被稱為 monarchial leader election——最高排名的「繼承人」在前任消失後成為君主。
選舉流程#
當某個程序發現系統中沒有 Leader(首次初始化)或前任 Leader 無回應時,選舉開始,分三步進行:
- 該程序向所有 rank 更高 的程序發送 Election 訊息
- 等待更高 rank 的程序回應:
- 若無人回應,進入步驟 3
- 若有人回應,通知回應中 rank 最高者,讓其繼續步驟 3
- 該程序確認沒有更高 rank 的活躍程序,通知所有 rank 更低 的程序關於新 Leader 的消息
圖解範例#
- (a) 程序 3 發現前任 Leader 6 已當機,向更高 rank 的程序發送 Election 訊息
- (b) 程序 4 和 5 回應 Alive(它們的 rank 比 3 高)
- (c) 程序 3 通知本輪回應中 rank 最高的程序 5
- (d) 程序 5 當選為新 Leader,廣播 Elected 訊息通知所有較低 rank 的程序
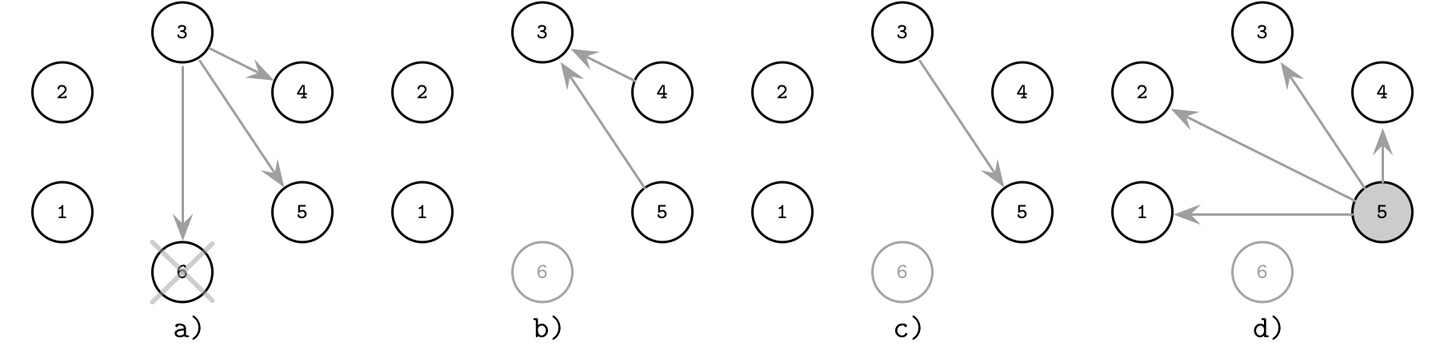
Figure 10.1: Bully algorithm: previous leader (6) fails and process 3 starts the new election
問題#
- Split brain:在網路分區(network partition)的情況下,違反 safety 保證——節點可能被分割成多個獨立子集,各自選出自己的 Leader
- 不穩定的高 rank 節點:若最高 rank 的節點頻繁當機,系統將陷入永久重選的狀態——它自薦為 Leader、隨即當機、再次贏得選舉、再次當機,不斷循環。可透過分發主機品質指標(host quality metrics)並在選舉中納入考量來解決
Next-In-Line Failover#
這是 Bully Algorithm 的改良版,利用多個備選程序(failover nodes)來縮短重選時間。
運作方式#
- 每個當選的 Leader 提供一份 failover 節點清單
- 當某程序偵測到 Leader 故障時,向清單中 rank 最高的備選程序發送訊息
- 若該備選程序存活,它直接成為新 Leader,無需完整的選舉流程
- 若偵測到故障的程序本身就是清單中 rank 最高的,可立即通知其他程序
圖解範例#
- (a) Leader 6(指定備選 {5, 4})當機。程序 3 偵測到故障,聯繫清單中 rank 最高的備選程序 5
- (b) 程序 5 回應 Alive,阻止程序 3 繼續聯繫其他備選
- (c) 程序 5 通知其他節點它是新 Leader
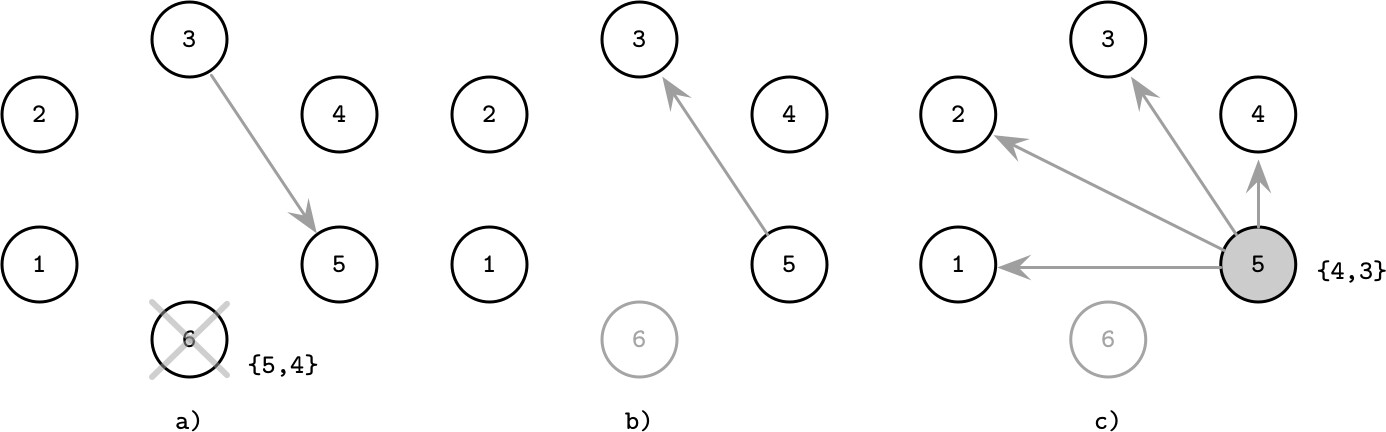
Figure 10.2: Bully algorithm with failover
此優化的效果:若下一順位的備選程序存活,選舉所需步驟大幅減少。
Candidate/Ordinary Optimization#
此演算法將節點分為兩個子集以降低訊息數量:
- Candidate 節點:有資格成為 Leader 的候選者
- Ordinary 節點:普通節點,負責發起選舉並通知結果
選舉流程#
- Ordinary 程序偵測到 Leader 故障後,聯繫所有 Candidate 節點
- 收集 Candidate 的回應,選出 rank 最高的存活 Candidate 作為新 Leader
- 通知所有節點選舉結果
避免同時選舉#
為解決多個程序同時發起選舉的問題,演算法引入 tiebreaker 變數 δ——每個程序有各自不同的延遲值:
- 高優先權的節點有較低的 δ(較早發起選舉)
- 低優先權的節點有較高的 δ(較晚發起選舉)
- δ 通常大於訊息的往返時間(round-trip time)
圖解範例#
- (a) Ordinary 集合中的程序 4 偵測到 Leader 6 故障,聯繫所有剩餘的 Candidate 程序
- (b) Candidate 程序回應通知程序 4 它們仍存活
- (c) 程序 4 通知所有程序新 Leader 為程序 2
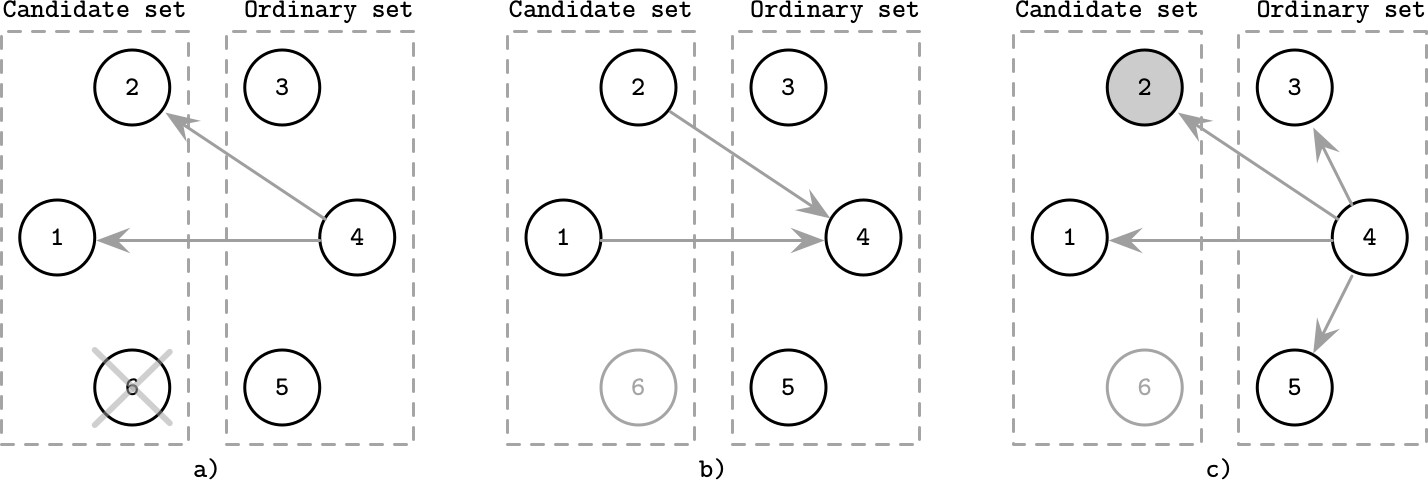
Figure 10.3: Candidate/ordinary modification of the bully algorithm
Invitation Algorithm#
Invitation Algorithm 採用截然不同的策略:不是讓程序互相競爭排名,而是允許程序邀請其他程序加入自己的群組。此演算法允許多個 Leader 同時存在,因為每個群組都有自己的 Leader。
運作方式#
- 每個程序一開始都是自己所屬群組的 Leader(群組只有自己一個成員)
- 群組 Leader 聯繫不屬於其群組的其他程序,邀請它們加入
- 若被聯繫的程序本身也是 Leader,則兩個群組合併
- 若被聯繫的程序不是 Leader,它會回應自己的群組 Leader ID,讓兩個 Leader 能直接建立聯繫並合併群組
合併策略#
- 合併時,由較大群組的 Leader 成為新群組的 Leader
- 這樣只有較小群組的成員需要被通知 Leader 變更,減少訊息數量
圖解範例#
- (a) 四個程序各自作為只有一個成員的群組 Leader。程序 1 邀請 2 加入,程序 3 邀請 4 加入
- (b) 程序 2 加入程序 1 的群組,程序 4 加入程序 3 的群組。程序 1 聯繫程序 3 進行群組合併
- (c) 兩個群組合併,程序 1 成為擴展群組的 Leader
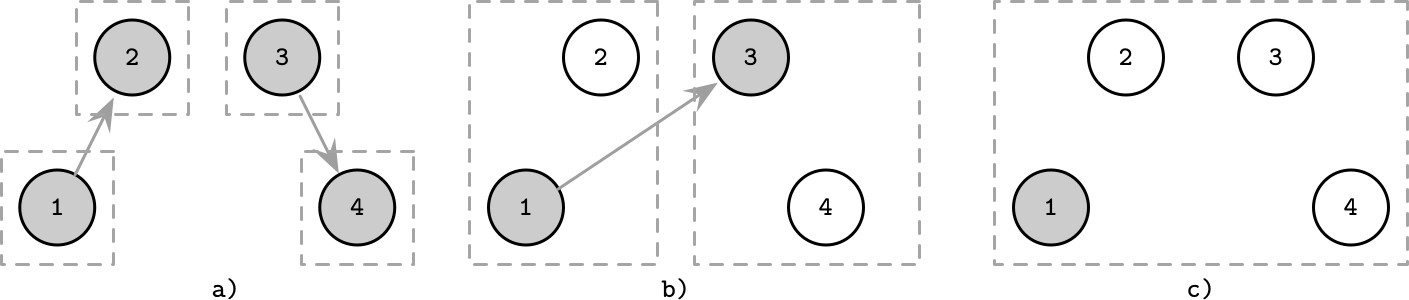
Figure 10.4: Invitation algorithm
Invitation Algorithm 的優勢在於可以建立程序群組並合併它們,而無需從頭觸發新的選舉,從而減少完成選舉所需的訊息數量。但與其他演算法一樣,它也可能產生多個 Leader。
Ring Algorithm#
在 Ring Algorithm 中,系統中的所有節點形成一個環(ring),且每個節點都知道環的拓撲結構(即自己的前驅和後繼節點)。
選舉流程#
- 當某程序偵測到 Leader 故障時,啟動新選舉
- Election 訊息沿著環轉發:每個程序聯繫其後繼節點
- 若後繼節點不可達,則跳過並嘗試聯繫環上更後面的節點
- 節點在轉發訊息時,將自己的 ID 加入存活節點集合
- 當訊息繞完整個環回到發起者時,從存活集合中選出 rank 最高的節點作為新 Leader
- 發起者再發送一輪訊息,將新 Leader 的資訊散布到整個環
圖解範例#
- (a) 前任 Leader 6 已故障,每個程序都有自己對環的視角
- (b) 程序 3 啟動選舉,開始環上遍歷。每一步都附帶目前已遍歷的節點集合。程序 5 無法到達 6,因此跳過直接前往程序 1
- (c) 由於程序 5 的 rank 最高,程序 3 啟動另一輪訊息散布新 Leader 的資訊
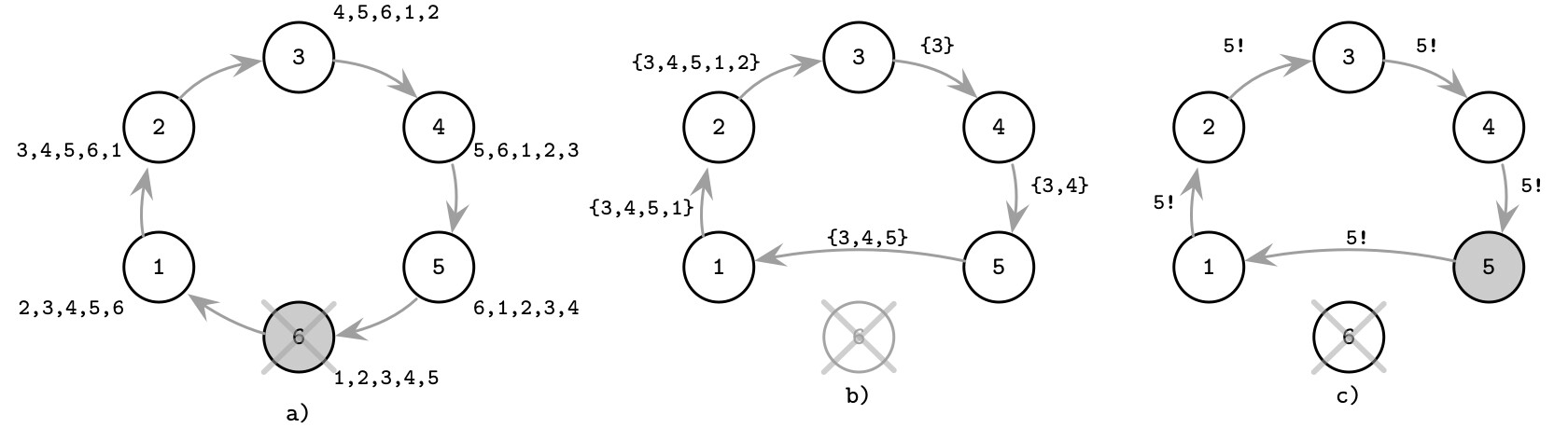
Figure 10.5: Ring algorithm
變體與限制#
- 空間優化:可以只傳遞目前已知的最高 rank ID,而非整個存活節點集合(因為 max 函數具有交換律)
- Safety 問題:環可能被分區為兩個或更多部分,各部分可能各自選出自己的 Leader,因此此演算法同樣不滿足 safety 性質
Leader 選舉與共識的關係#
Leader 選舉與共識(consensus)之間存在深層聯繫:
- 要選出 Leader,需要對其身份達成共識
- 若能就 Leader 身份達成共識,同樣的機制也可用於對任何事達成共識
- 為了避免 split brain,必須取得叢集範圍內的多數票(cluster-wide majority)
穩定 Leader 選舉#
程序對 Leader 的本地認知可能過時(Leader 身份可能已變更而程序尚不知情)。Stable Leader Election 演算法結合了 Leader 選舉與故障偵測:
- 使用具有唯一穩定 Leader 的回合制
- 基於 timeout 的故障偵測
- 保證 Leader 只要不當機且可達,就能維持其地位
共識演算法中的 Leader 衝突處理#
許多共識演算法允許多個 Leader 暫時存在,但會盡快解決衝突:
- Multi-Paxos:當兩個衝突的 Leader(proposer)出現時,只有一個能繼續。透過收集第二個 quorum 來解決衝突,保證不會同時接受兩個不同 proposer 的值
- Raft:Leader 可以發現自己的 term 已過期(暗示系統中存在另一個 Leader),然後將自己的 term 更新為更新的值
擁有 Leader 是為了確保 liveness(若當前 Leader 故障,需要選出新的)。允許多個 Leader 同時存在是一種效能優化:演算法可以繼續進行複製階段,而 safety 則透過偵測和解決衝突來保證。
總結#
- Leader 的價值:使用指定的 Leader 有助於降低協調開銷、提升演算法效能。選舉回合雖然代價高,但因為不頻繁,不會對整體效能產生負面影響
- 瓶頸解決:單一 Leader 可能成為瓶頸,通常透過資料分區(data partitioning)和使用 per-partition Leader 來解決
- Split brain 問題:本章討論的所有演算法都容易出現 split brain——兩個 Leader 在獨立子網中存在但彼此不知。要避免此問題,必須取得叢集範圍內的多數票
- Leader 選舉即共識:Leader 選舉本質上就是一種共識問題。若能就 Leader 身份達成共識,就能用同樣的方法對任何事達成共識
- 穩定性保證:需結合 Leader 選舉與故障偵測,確保程序對 Leader 的認知始終有效
- 衝突容忍:實務中的共識演算法(如 Multi-Paxos、Raft)允許多 Leader 暫時存在,透過衝突偵測與解決來保證正確性