為了讓系統能夠適當地對故障做出反應,必須及時偵測到故障。在非同步分散式系統中偵測故障極為困難,因為在沒有任何時間假設的情況下,無法判斷一個程序是已經崩潰、運行緩慢,還是需要很長時間才能回應。
Failure detector 是一個負責識別故障或不可達程序的本地子系統,將它們從演算法中排除,同時保證 liveness 和 safety。
重點: 故障偵測演算法需要在 completeness(完整性)和 accuracy(準確性)之間取得平衡——更高效的演算法可能不夠精確,而更精確的演算法通常效率較低。
Heartbeats and Pings#
我們可以透過兩種週期性機制來查詢遠端程序的狀態:
- Ping:主動發送訊息給遠端程序,檢查它們是否存活
- Heartbeat:程序主動通知其同伴自己仍在運行
每個程序維護一份其他程序的清單(包含存活、死亡和可疑狀態),並記錄每個程序的最後回應時間。如果一個程序在較長時間內未能回應 ping 訊息,它就會被標記為 suspected。
在正常運作下,程序 P1 查詢鄰近節點 P2 的狀態,P2 以確認訊息回應:

Figure 9.1: Pings for failure detection: normal functioning, no message delays
注意: 當確認訊息被延遲時,可能會導致將仍然存活的程序錯誤地標記為已停止運作(false positive)。

Figure 9.2: Pings for failure detection: responses are delayed
許多故障偵測演算法基於 heartbeat 和 timeout。這種方法的精確度依賴於對 ping 頻率和 timeout 的仔細選擇,而且它無法從其他程序的角度捕捉程序的可見性。
Timeout-Free Failure Detector#
有些演算法避免依賴 timeout 來偵測故障。例如 Heartbeat(一種 timeout-free 故障偵測器),它只計算 heartbeat 次數,並允許應用程式根據 heartbeat 計數器向量中的資料來偵測程序故障。由於不使用 timeout,它在 asynchronous 系統假設下運作。
Outsourced Heartbeats#
SWIM(Scalable Weakly Consistent Infection-style Process Group Membership Protocol)使用 outsourced heartbeats 來改善可靠性。這種方法的運作方式:
- 程序 P1 向程序 P2 發送 ping 訊息
- 若 P2 沒有回應,P1 選擇多個隨機成員(如 P3 和 P4)
- 這些成員嘗試向 P2 發送 heartbeat 訊息
- 如果 P2 回應,確認會被轉發回 P1
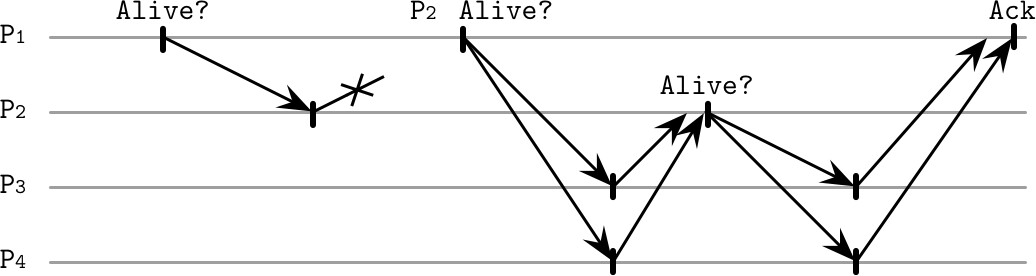
Figure 9.3: Outsourcing heartbeats
技巧: 這種方式不需要程序知道網路中的所有其他程序,只需要知道已連接的 peers 子集,同時考慮直接和間接的可達性,通過分散責任來實現可靠的故障偵測。
Phi-Accrual Failure Detector#
與將節點故障視為二元問題不同,phi-accrual(φ-accrual)故障偵測器使用連續刻度,捕捉被監控程序崩潰的機率。
其核心機制:
- 維護一個滑動視窗,收集最近 heartbeat 的到達時間
- 計算 suspicion level φ:在目前的網路條件下,故障偵測器對該故障有多大的確定性
補充: 此演算法由日本先端科學技術大學院大學(JAIST)的研究人員開發,現被許多分散式系統使用,例如 Cassandra 和 Akka。
Gossip and Failure Detection#
另一種避免依賴單一節點觀點的方法是 gossip-style 故障偵測服務。其運作流程:
- 每個成員維護其他成員的清單、heartbeat counters 和 timestamps
- 週期性地,每個成員遞增其 heartbeat 計數器並將清單分發給隨機鄰居
- 收到訊息的鄰居節點將清單與自己的合併,更新其他鄰居的 heartbeat 計數器
- 如果任何節點在足夠長的時間內未更新其計數器,則被視為已故障
Figure 9.4: Replicated heartbeat table for failure detection
這種方式可以偵測崩潰的節點以及無法被任何其他叢集成員存取的節點,因為叢集的觀點是從多個節點的聚合結果。
Reversing Failure Detection Problem Statement#
FUSE(failure notification service)專注於可靠且低成本的故障傳播,即使在網路分割的情況下也能運作。它將所有活躍程序安排成群組——如果群組中的一個成員變得不可用,所有參與者都會偵測到故障,每個單一程序的故障都會被轉換並傳播為 group failure。
故障傳播機制:
- 群組中的程序週期性地互相發送 ping 訊息
- 如果某個成員無法回應,發起 ping 的成員也會停止回應 ping 訊息
- 故障從源頭傳播到所有其他參與者
- 參與者逐漸停止回應 ping,從個別節點故障轉變為群組故障

Figure 9.5: FUSE failure detection
技巧: FUSE 利用「通訊的缺失」作為傳播手段——每個成員都保證能得知群組故障並適當地做出反應。
總結#
故障偵測器是任何分散式系統的重要組成部分。本章涵蓋的演算法各有不同的偵測策略:
- 直接通訊:透過 ping/heartbeat 偵測故障(Timeout-Free、Outsourced Heartbeats)
- 廣播/Gossip:聚合多個節點的觀點,提高準確性(Phi-Accrual、Gossip-style)
- 靜默傳播:利用通訊的缺失作為故障訊號(FUSE)