本章為第二部分「分散式系統」的開篇,介紹分散式系統與單節點系統的根本差異,建立後續章節所需的核心詞彙與概念框架。
並行執行(Concurrent Execution)#
在單執行緒程式中,變數的操作歷程是確定的。但當兩個執行緒可以同時存取同一個變數時,結果就變得不可預測——除非明確進行同步。
以一個簡單的例子來說,變數 x = 1,一個執行緒做加法 +2,另一個做乘法 *2,可能的結果包括:
- x = 2:兩者都讀到初始值,加法先寫入但被乘法覆蓋
- x = 3:兩者都讀到初始值,乘法先寫入但被加法覆蓋
- x = 4:乘法在加法開始前就完成了讀取與執行
- x = 6:加法在乘法開始前就完成了讀取與執行
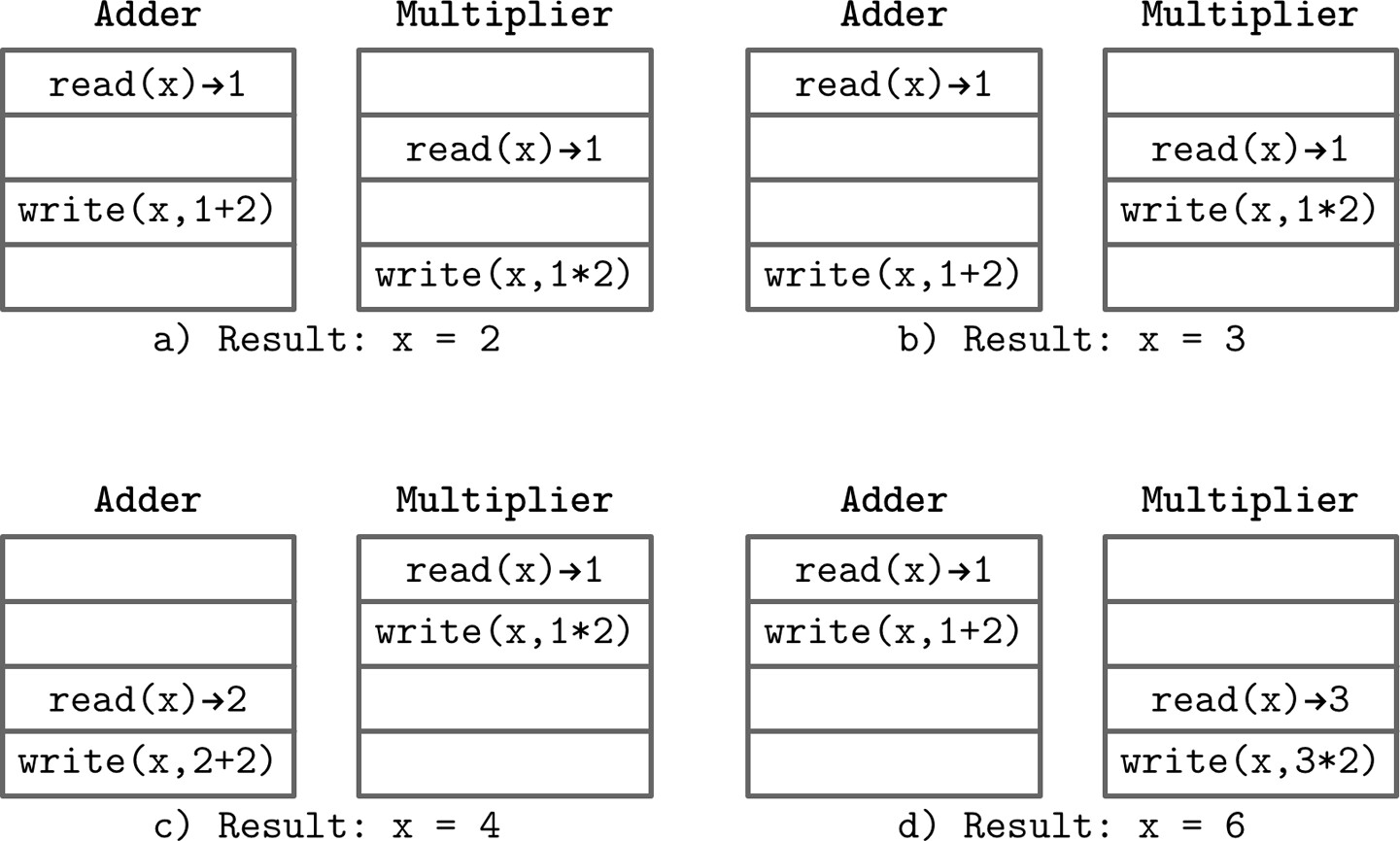
Figure 8.1: Possible interleavings of concurrent executions
這揭示了分散式系統的第一個問題:並行性(concurrency)。每個並行程式都具有分散式系統的某些特性——執行緒存取共享狀態、在本地進行運算、再將結果傳播回去。
為了精確定義執行歷史並減少可能的結果數量,我們需要一致性模型(consistency models)。一致性模型描述並行執行的順序,規範操作可以在何時被執行與被觀察到。
並行(concurrent)與平行(parallel)的區別:並行是指兩個操作序列在時間上重疊,但同一時刻只有一個在執行;平行則是多個處理器同時執行。Erlang 創造者 Joe Armstrong 的比喻:並行是兩條隊伍共用一台咖啡機,平行是兩條隊伍各有一台咖啡機。
分散式系統中的共享狀態#
嘗試在分散式系統中引入共享記憶體(例如一個中央資料庫)看似直觀,但即使解決了並行存取問題,仍無法保證所有行程保持同步。原因在於:
- 行程必須透過傳送與接收訊息來查詢或修改狀態
- 若某個行程長時間未收到回應,我們不知道是資料庫過載、不可用、網路問題,還是行程本身當機
- 引入同步性假設(synchrony assumptions) 才能定義逾時與重試機制
- 需要定義故障模型(failure model) 來描述故障的發生方式
為了消除單點故障,可以引入備份資料庫,但隨之而來的問題是:如何讓多個共享狀態的副本保持同步?
分散式運算的謬誤(Fallacies of Distributed Computing)#
1994 年 Peter Deutsch 提出了著名的「分散式運算的謬誤」清單,指出我們容易忽略的問題:
- 網路是可靠的——連線可能中斷,回應可能遺失
- 延遲為零——訊息必須經過多個軟體層與物理介質傳輸,絕非即時
- 頻寬是無限的——隨著訊息數量與大小增長,頻寬限制會成為瓶頸
- 網路是安全的——可能存在惡意方
- 拓撲不會改變——網路配置隨時可能變動
- 存在單一管理者——實際上沒有單一權威能掌控整個網路
處理(Processing)#
遠端行程在回應前必須執行本地工作,因此處理不是即時的。需要注意的要點:
- 訊息送達後不一定馬上被處理,可能需在待處理佇列中等待
- 不同節點的硬體規格、軟體版本不同,處理速率也不一致
- 平行等待多個遠端伺服器時,整體速度取決於最慢的那個
背壓(Backpressure) 是一種重要但常被忽視的機制,允許消費者在處理速度跟不上生產者時減慢生產者的速度。
行程本地佇列的用途:
- 解耦(Decoupling):接收與處理在時間上分離
- 流水線(Pipelining):不同階段由系統的獨立部分處理
- 吸收短時間突發流量(Absorbing bursts):平滑系統負載變化
時鐘與時間(Clocks and Time)#
假設遠端機器的時鐘同步是危險的。結合「延遲為零」和「處理即時」等錯誤假設,會導致各種問題,尤其在時間序列與即時資料處理中。
關鍵要點:
- 收集來自不同參與者的資料時,應理解時間漂移(time drift) 並進行正規化,而非依賴來源時間戳
- 除非使用專用高精度時間源,否則不應依賴時間戳進行同步或排序
- Google Spanner 使用特殊的時間 API,回傳時間戳與不確定性範圍(uncertainty bounds) 來強制交易順序
- 理解時鐘源是否為單調遞增(monotonic) 很重要
狀態一致性(State Consistency)#
分散式演算法不總是保證嚴格的狀態一致性。部分方法允許副本之間的狀態分歧,依賴衝突解決(conflict resolution) 和讀取時修復(read-time data repair)。
實際案例:
- Apache Cassandra schema 傳播 bug:schema 變更在不同伺服器上的傳播時間不同,若在傳播期間讀取資料,一個伺服器用一個 schema 編碼,另一個用不同 schema 解碼,導致資料損壞
- Ring view 分歧 bug:節點對叢集拓撲的認知不一致,導致資料被錯放或讀取到空結果
本地與遠端執行(Local and Remote Execution)#
將遠端呼叫隱藏在與本地相同的 API 後面可能產生誤導。遠端呼叫的成本遠高於本地呼叫,涉及雙向網路傳輸、序列化/反序列化等步驟。混合使用本地呼叫與阻塞式遠端呼叫可能導致效能退化。
必須處理故障(Need to Handle Failures)#
在長期運行的系統中,節點可能因維護而關閉、因軟體問題當機、因 OOM Killer 被終止等。當遠端伺服器不回應時,可能是當機、網路故障、行程緩慢等多種原因。分散式演算法使用心跳協定(heartbeat protocols) 和故障偵測器(failure detectors) 來判斷參與者是否存活。
網路分割與部分故障(Network Partitions and Partial Failures)#
當兩個或多個伺服器無法互相通訊時,稱為網路分割(network partition)。
- 一般的網路不可靠性(封包遺失、重傳、延遲)是可容忍的
- 網路分割更嚴重:獨立的群組可以繼續執行並產生衝突的結果
- 網路連結可能不對稱失敗:A 能傳給 B,但 B 無法傳給 A
- 必須考慮部分故障(partial failures),確保系統在部分不可用時仍能運作
連鎖故障(Cascading Failures)#
故障無法總是被完全隔離:一個節點在高負載下崩潰,會增加其餘叢集的負載,使更多節點也可能崩潰。
防護機制:
- 斷路器(Circuit Breakers):監控故障並提供回退機制,讓故障的服務有時間恢復
- 退避策略(Backoff):不立即重試,而是逐漸增加重試間隔
- 抖動(Jitter):在退避時間加入隨機偏移量,避免多個客戶端同時重試
- 校驗和驗證(Checksumming & Validation):驗證節點間交換內容的完整性,防止損壞的資料被複製傳播
- 協調者(Coordinator):基於可用資源準備執行計畫,預測負載
開源故障測試工具:Toxiproxy 模擬網路問題(限制頻寬、注入延遲);Chaos Monkey 隨機關閉生產環境中的服務;CharybdeFS 模擬檔案系統與硬體錯誤;CrashMonkey 測試持久化檔案的資料與中繼資料一致性。
分散式系統抽象(Distributed Systems Abstractions)#
連結(Links)#
網路不可靠:訊息可能遺失、延遲、亂序。書中從最不可靠的通訊協定開始,逐步建立更強的保證。
公平遺失連結(Fair-loss Link)#
兩個行程透過連結傳送訊息,這是最基本的抽象。

Figure 8.2: Simplest, unreliable form of communication
發送者無法得知訊息是否已送達。其性質為:
- 公平遺失(Fair loss):若雙方皆正確且發送者不斷重傳,訊息最終會被遞送
- 有限重複(Finite duplication):訊息不會被無限次遞送
- 無中生有(No creation):連結不會遞送從未被發送的訊息
這類似於 UDP 協定,不在協定層面提供可靠遞送語義。
訊息確認(Message Acknowledgments)#
為改善通訊可靠性,引入確認機制(ACK):接收者通知發送者已收到訊息。需要雙向通訊通道與唯一訊息識別碼(如序號)。

Figure 8.3: Sending a message with an acknowledgment
在 A 收到 ACK 之前,訊息仍可能處於未遞送、遺失或已遞送三種狀態之一。收到 ACK 後,A 可確信訊息已被 B 接收。
訊息重傳(Message Retransmits)#
加入確認仍不足以稱為可靠通訊。透過重傳,發送者在逾時後重新發送訊息。這種抽象稱為固執連結(stubborn link)——發送者不斷重發。
重傳的問題在於可能產生重複訊息。處理重複只在操作是冪等的(idempotent) 時才安全。冪等操作可被多次執行而產生相同結果、不產生額外副作用(例如關閉伺服器)。但並非所有操作都是冪等的(例如信用卡扣款),因此需要去重(deduplication) 機制。
訊息排序(Message Order)#
不可靠網路帶來兩個問題:訊息可能亂序到達,且因重傳可能重複到達。利用序號可以在接收端實現 FIFO 排序:
- n_consecutive:已連續收到的最高序號,用於重新排序
- n_processed:已按序處理的最高序號,用於去重
完美連結(Perfect Link)#
結合以上機制,得到的抽象稱為完美連結(perfect link),保證:
- 可靠遞送(Reliable delivery):正確行程 A 發送給正確行程 B 的訊息最終會被遞送
- 無重複(No duplication):訊息不會被遞送超過一次
- 無中生有(No creation):只遞送實際被發送的訊息
這類似於 TCP 協定(但 TCP 的可靠遞送僅在單一 session 範圍內保證)。
恰好一次遞送(Exactly-once Delivery)#
關於「恰好一次遞送」是否可能,關鍵在於語義與定義層級的區分:
- 至少一次(At-least-once):發送者重試直到收到確認
- 至多一次(At-most-once):發送者不期待遞送確認
- 恰好一次處理(Exactly-once processing):真正重要的是「處理」而非「遞送」——透過去重機制,從發送者的角度創造恰好一次遞送的「幻象」
不可能建構一個完全不重複傳輸訊息的可靠連結,但可以透過處理一次、忽略重複來達成等效效果。要使恰好一次保證成立,節點需要共同知識(common knowledge):所有人都知道某個事實,且知道其他人也知道。
兩將軍問題(Two Generals’ Problem)#
這個著名的思想實驗說明:在通訊為非同步且存在連結故障的情況下,兩方之間不可能達成共識。
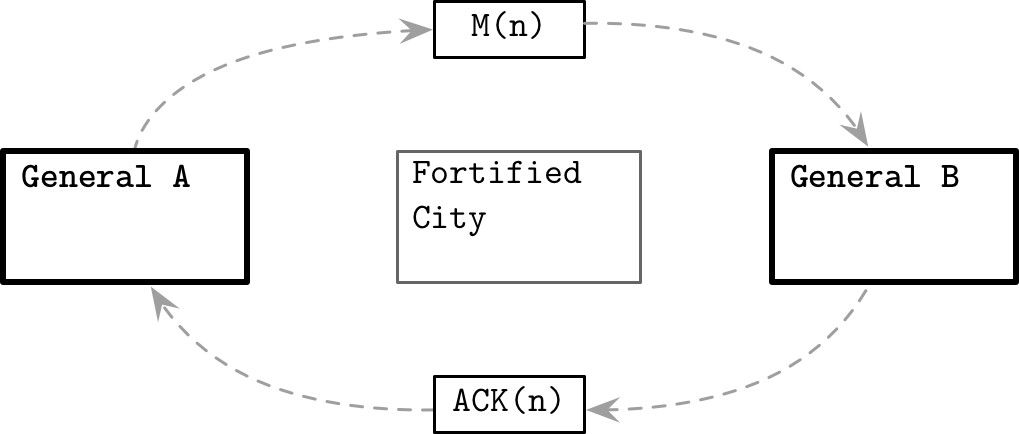
Figure 8.4: Two Generals' Problem illustrated
情境:兩支軍隊分別位於城市兩側,必須同時進攻才能成功。將軍只能透過信使通訊,而信使可能被攔截。
- 將軍 A 發送進攻意圖
MSG(N) - 將軍 B 收到後發送確認
ACK(MSG(N)),但確認也可能遺失 - B 必須等待
ACK(ACK(MSG(N))),但這個確認的確認也可能遺失 - 無論發送多少層確認,總是差一個 ACK 才能確定對方已收到
這個問題沒有解——通訊是完全非同步的,對回應時間沒有上限。
FLP 不可能性(FLP Impossibility)#
Fischer、Lynch 和 Paterson 在論文中證明了:在完全非同步的系統中,即使只有一個行程可能當機,也不存在能保證在有限時間內達成共識的確定性演算法。
共識協定必須滿足三個性質:
- 一致性(Agreement):所有行程必須決定相同的值
- 有效性(Validity):決定的值必須是某個參與者提出的
- 終止性(Termination):所有行程最終都必須到達決策狀態
FLP 不可能性並不意味著共識不可達成。它只是說明在完全非同步系統中無法在有限時間內保證共識。實際系統至少展現某種程度的同步性,使問題可以在更精緻的模型下被解決。
系統同步性(System Synchrony)#
時序假設是分散式系統的關鍵特徵。系統可分為三種模型:
| 模型 | 特性 |
|---|---|
| 非同步(Asynchronous) | 不知道行程的相對速度,無法保證訊息在有限時間或特定順序內遞送。行程可能無限期地不回應,故障無法被可靠偵測 |
| 同步(Synchronous) | 行程以可比較的速率運行,傳輸延遲有上限,訊息遞送不會任意延長。可使用逾時機制,建構 leader election、共識、故障偵測等抽象 |
| 部分同步(Partially Synchronous) | 結合兩者的特性,訊息遞送與時鐘漂移的上限大部分時候成立,但不是絕對的 |
同步模型允許使用逾時(timeouts),使最佳情境更穩健,但若時序假設不成立則可能失敗。例如 Raft 共識演算法中,可能出現多個行程同時認為自己是 leader 的情況。
故障模型(Failure Models)#
故障模型描述行程在分散式系統中可能如何崩潰,演算法據此開發。
當機故障(Crash Faults)#
- 當機停止(Crash-stop):行程停止執行所有後續步驟,不再發送訊息。這是最簡單的故障模型。演算法不依賴恢復來保證正確性或活性
- 當機恢復(Crash-recovery):行程停止後在稍後恢復並嘗試繼續執行。需要引入持久化狀態(durable state) 和恢復協定(recovery protocol)。恢復的行程可能從其已知的最後一步嘗試繼續
遺漏故障(Omission Faults)#
行程跳過某些演算法步驟,或其執行結果對其他參與者不可見,或無法收發訊息。此模型涵蓋:
- 網路連結故障、交換器故障、網路壅塞造成的網路分割
- 行程運行過慢,回應嚴重延遲(看起來像是「健忘」)
- 間歇性暫停、佇列滿溢等情況
拜占庭故障(Arbitrary / Byzantine Faults)#
最難克服的故障類型:行程繼續執行但違反演算法規範(例如在共識演算法中決定一個從未被提出的值)。
成因包括:
- 軟體 bug 或不同版本的演算法
- 惡意行程故意誤導其他參與者
應用場景:航空太空系統(不直接信任子元件的回應,進行交叉驗證)、加密貨幣(無中央權威,參與者有物質動機偽造值)。
處理故障的方式#
- 透過行程群組和冗餘(redundancy) 來遮蔽故障
- 故障發生時可能有效能懲罰,系統需退回到較慢的錯誤處理路徑
- 透過程式碼審查、廣泛測試、逾時與重試、確保步驟按序執行等軟體層面措施來預防故障
- 本書大多數演算法假設當機故障模型,並透過引入冗餘來處理故障
總結#
本章建立了分散式系統的核心概念框架,為後續章節奠定基礎:
- 並行性是分散式系統的第一個挑戰,需要一致性模型來約束可能的狀態
- 分散式運算的謬誤提醒我們不能假設網路可靠、延遲為零、頻寬無限、時鐘同步
- 通訊抽象從公平遺失連結逐步建構到完美連結,透過確認、重傳、序號、去重等機制提供更強的保證
- 兩將軍問題與 FLP 不可能性說明在非同步系統中達成共識的理論限制
- 系統同步性的假設直接影響可使用的演算法與可達成的保證
- 故障模型(當機、遺漏、拜占庭)定義了行程可能的失敗方式,演算法據此設計容錯機制
理解這些基礎概念——什麼可能出錯、以及我們有哪些工具來應對——是設計與實作穩健分散式系統的前提。