本章探討 Log-Structured Storage(日誌結構儲存)的核心設計——以不可變(immutable)檔案取代原地更新,透過追加寫入與合併來實現高效的寫入效能。B-Tree 是可變結構的代表,而 LSM Tree(Log-Structured Merge Tree)則是不可變結構的經典範例。
可變 vs. 不可變儲存結構#
資料庫儲存結構可以依據是否原地修改(in-place update)來分類:
- 可變結構(Mutable):如 B-Tree,直接在磁碟上修改記錄。讀取效能優秀(定位後直接返回),但寫入需要先定位再修改。
- 不可變結構(Immutable):如 LSM Tree,檔案寫入後不再修改,新記錄追加到新檔案。寫入效能高(不需先定位),但讀取需要從多個檔案合併與調和(reconcile)。
不可變結構的優勢:
- 檔案一旦建立就不變,可安全地並行存取,不需要額外的鎖或閂鎖
- 順序寫入避免碎片化,頁面密度更高(不需預留空間給未來更新)
- 寫入不需定位舊記錄,大幅提升寫入吞吐量
B-Tree 的 I/O 多為隨機讀寫:寫入前需先定位頁面,且節點分裂與合併會搬移已寫入的記錄。相較之下,LSM Tree 將多個小寫入合併為順序寫入,有效降低隨機 I/O 的開銷。
LSM Tree#
LSM Tree 利用緩衝(buffering)與追加寫入(append-only storage)來實現順序寫入。此概念由 Patrick O’Neil 與 Edward Cheng 在 1996 年提出,名稱源自 log-structured filesystem。
LSM Tree 寫入不可變檔案並隨時間合併。這些檔案通常自帶索引(例如內嵌 B-Tree)以加速查詢。雖然 LSM Tree 常被視為 B-Tree 的替代方案,但 B-Tree 本身也常作為 LSM Tree 不可變檔案內部的索引結構。
核心運作原理:
- 寫入:先緩衝在記憶體中的表(memtable),達到閾值後才刷出(flush)到磁碟的不可變檔案
- 讀取:需要同時查詢記憶體與多個磁碟檔案,合併結果後返回
- 維護:定期執行 compaction,將多個檔案合併為較少的檔案,減少讀取時需存取的檔案數
LSM Tree 特別適合寫入遠多於讀取的工作負載,這在現代資料密集型系統中非常常見。
LSM Tree 結構#
LSM Tree 由兩種元件組成:
- 記憶體元件(Memtable):可變的記憶體中排序結構,接收所有讀寫操作。更新不涉及磁碟 I/O。為保證持久性,搭配 Write-Ahead Log(WAL) 使用——記錄先寫入 WAL 並提交到記憶體,才向客戶端確認。
- 磁碟元件(Disk-resident tables):由 memtable 刷出產生的不可變檔案,僅用於讀取。
二元件 LSM Tree#
二元件 LSM Tree(Two-component LSM Tree)只有一個磁碟元件,以 100% 佔用率的唯讀 B-Tree 結構組織。
- 刷出時,將記憶體子樹與對應的磁碟子樹合併,寫出到新的磁碟位置
- 合併採用迭代器逐步推進(lockstep),因為兩個來源都已排序,只需比較當前值即可產生排序結果
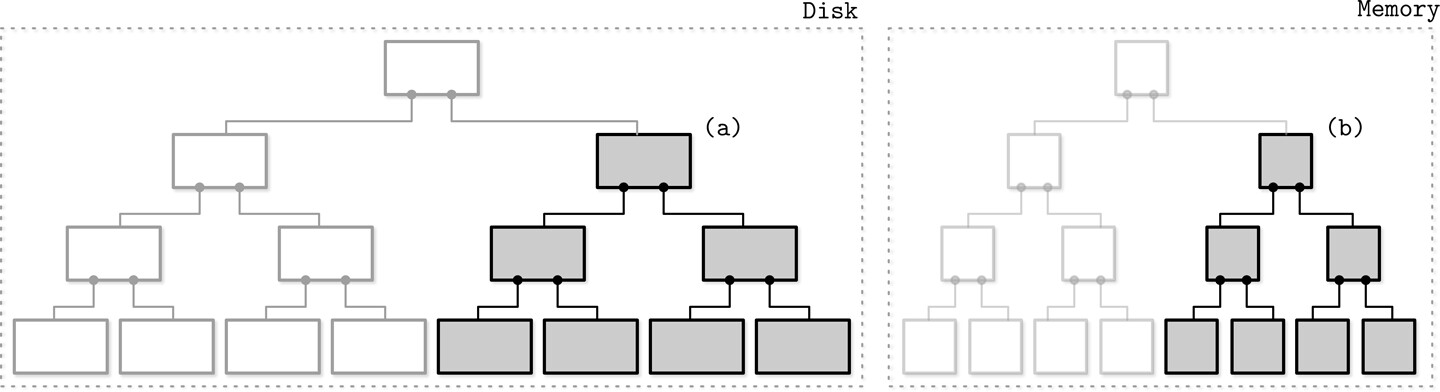
Figure 7.1: Two-component LSM Tree before a flush
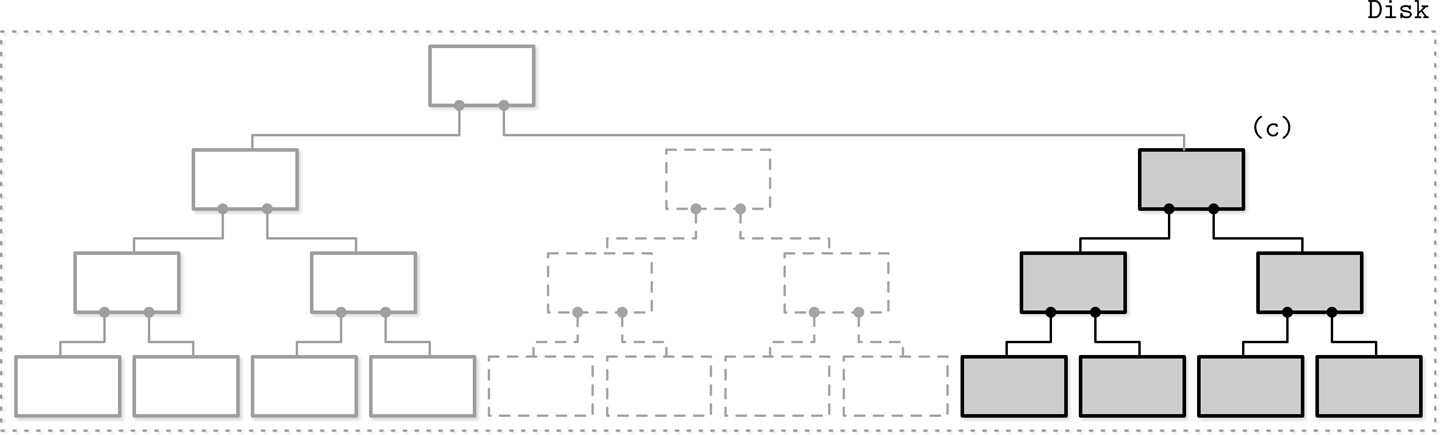
Figure 7.2: Two-component LSM Tree after a flush
刷出過程需確保三件事:
- 刷出開始後,所有新寫入必須導向新的 memtable
- 刷出期間,磁碟子樹和正在刷出的記憶體子樹都必須仍可讀取
- 刷出完成後,發布合併結果與丟棄舊內容必須是原子操作
二元件 LSM Tree 的寫入放大特性較差,因為每次 memtable 刷出都會觸發合併。目前沒有已知的實際實作採用此方案。
多元件 LSM Tree#
多元件 LSM Tree(Multicomponent LSM Tree)允許多個磁碟表存在。每次刷出將整個 memtable 一次寫出為一個獨立的磁碟表。
隨著刷出次數增加,磁碟表數量持續成長,讀取時可能需要存取多個檔案。為控制檔案數量,定期觸發 compaction:選取數個表、讀取合併其內容、寫出為新的合併表,同時丟棄舊表。
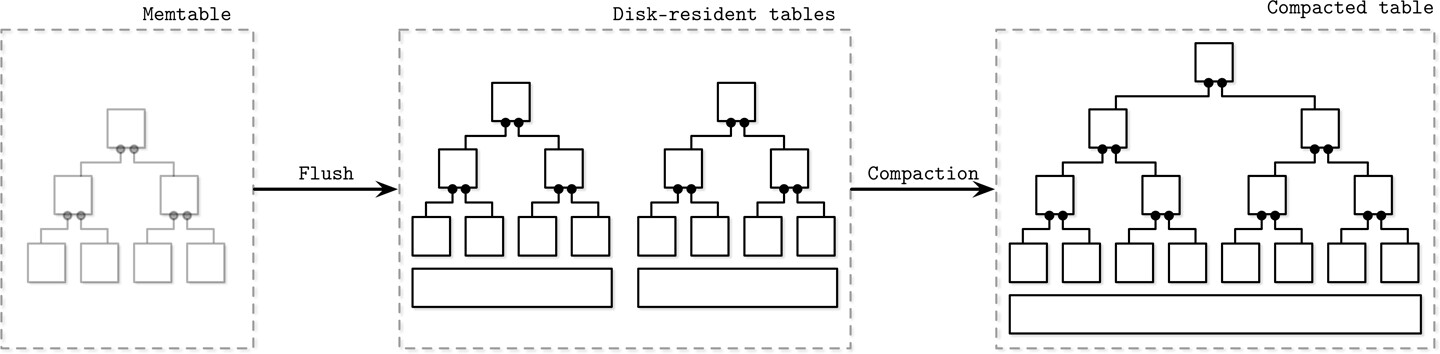
Figure 7.3: Multicomponent LSM Tree data life cycle
記憶體表(Memtable)#
Memtable 可依大小閾值或定期觸發刷出。刷出流程:
- 分配新的 memtable,成為所有新寫入的目標(此步驟需原子執行)
- 舊 memtable 轉為刷出狀態,仍可供讀取
- 將舊 memtable 內容順序寫出到磁碟
- 完成後丟棄舊 memtable,新的磁碟表開放讀取
- WAL 中對應的日誌段可以被截斷丟棄
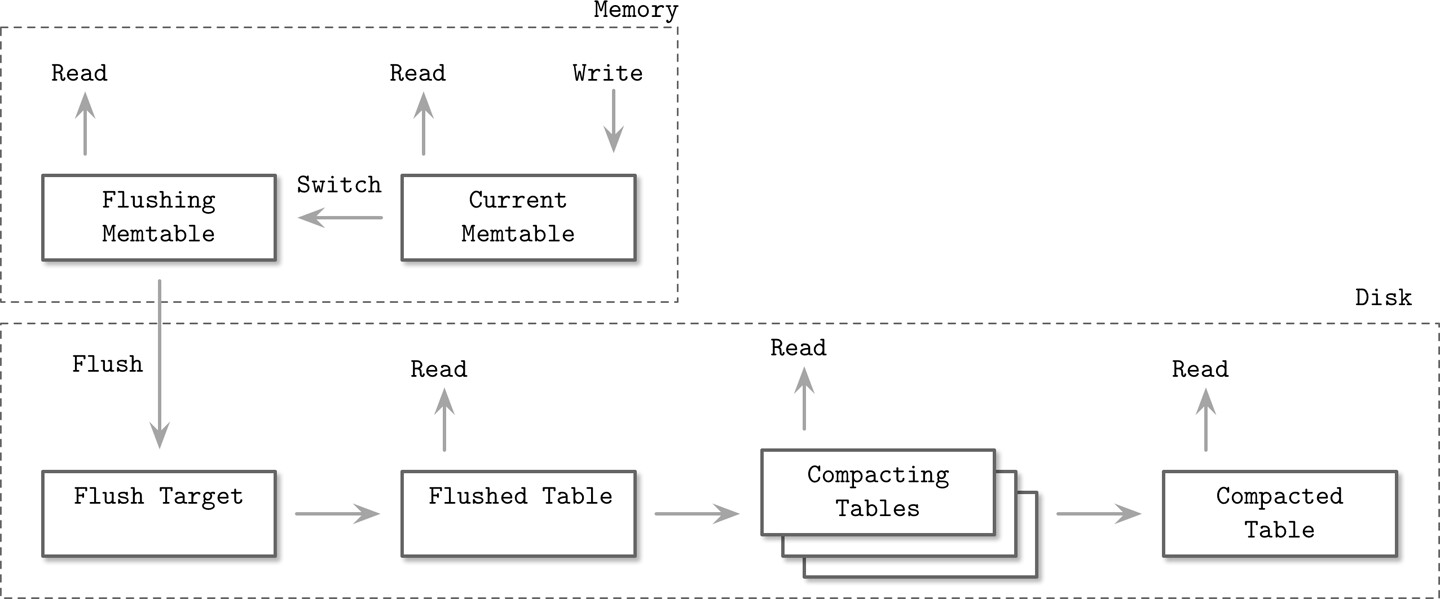
Figure 7.4: LSM component structure
LSM Tree 的各元件與其狀態轉換:
- Current memtable:接收寫入並服務讀取
- Flushing memtable:僅供讀取
- On-disk flush target:正在寫入中,不參與讀取(內容不完整)
- Flushed tables:刷出完成後可供讀取
- Compacting tables:正在參與合併的磁碟表
- Compacted tables:合併產生的新表
更新與刪除#
LSM Tree 的插入、更新、刪除都不需要定位磁碟上的舊記錄,衝突在讀取時才調和。
刪除的特殊處理:不能只從 memtable 移除記錄,因為其他磁碟表可能持有同一 key 的舊值。若只是刪除 memtable 中的項目,會導致舊值「復活」。因此,刪除需要插入一個特殊的 tombstone(墓碑記錄),標示該 key 已被刪除。調和過程會辨識 tombstone 並過濾掉被覆蓋的值。
範圍刪除(Predicate deletes):可使用謂詞刪除連續範圍的 key。Apache Cassandra 實作了 range tombstone,覆蓋一個 key 範圍而非單一 key。使用 range tombstone 時需小心處理重疊範圍與表邊界的解析規則。
LSM Tree 查詢#
LSM Tree 的查詢需要存取多個元件並合併調和。
合併迭代(Merge-Iteration)#
由於各磁碟表內容已排序,可使用多路合併排序(multiway merge-sort)演算法:
- 使用優先佇列(priority queue,如 min-heap)維護最多 N 個元素(N = 迭代器數量)
- 將每個迭代器的頭部元素放入佇列
- 取出佇列中最小的元素作為輸出
- 從對應的迭代器補充下一個元素到佇列
- 重複直到所有迭代器耗盡或查詢條件滿足
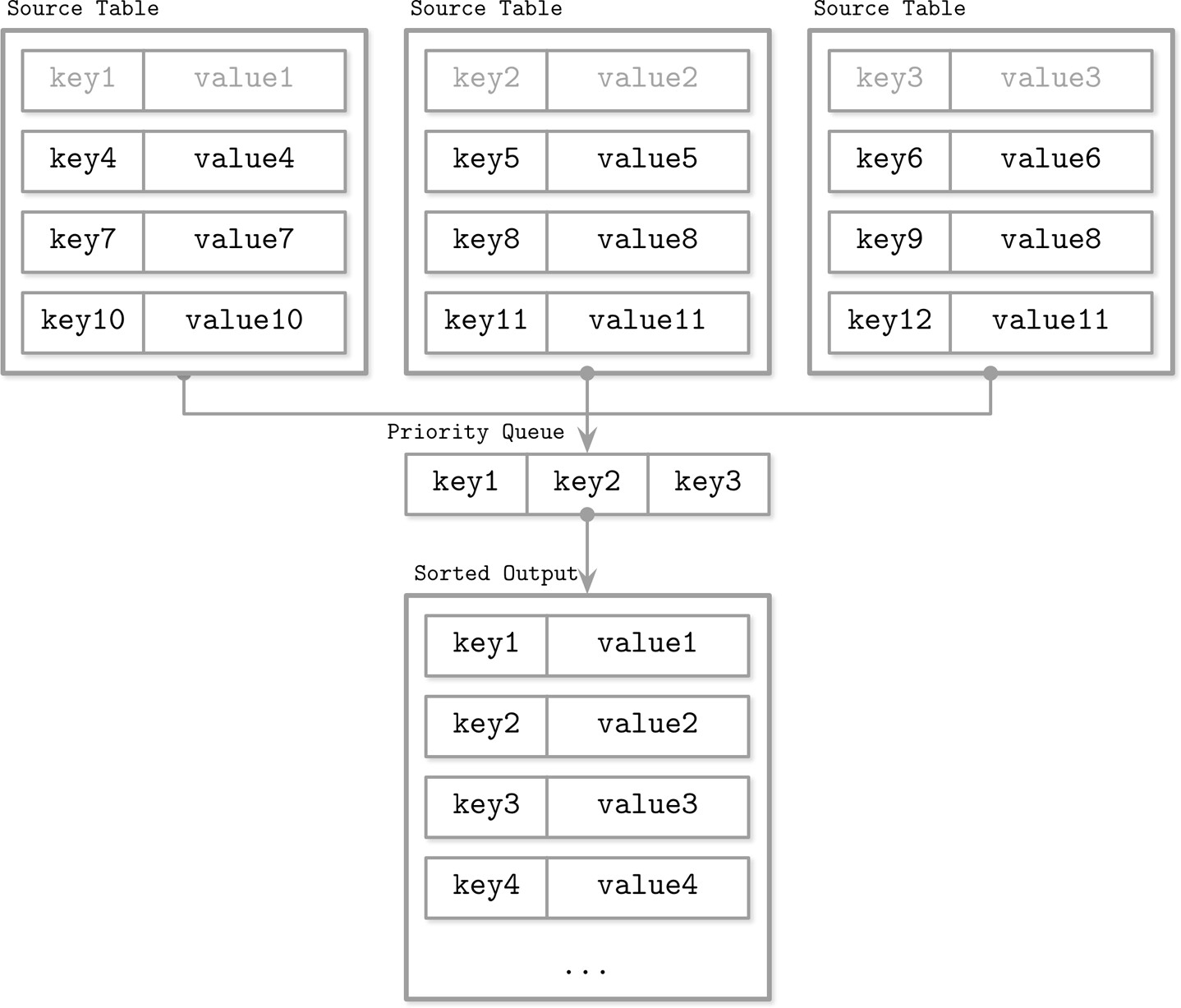
Figure 7.5: LSM merge mechanics
複雜度:記憶體開銷 O(N),佇列維護 O(log N)(平均情況)。
若同一 key 出現在多個迭代器中,佇列中會同時存在多筆相同 key 的記錄(來自不同迭代器),需要進行調和。
調和(Reconciliation)#
不同的表可能持有同一 key 的不同版本(更新或刪除)。調和規則:
- 資料記錄帶有 timestamp 等元資料,用於判斷優先順序
- 較新的記錄覆蓋較舊的記錄
- 被覆蓋的記錄不會返回給客戶端,也不會在 compaction 時寫出
LSM Tree 中的 insert 和 update 操作無法區分,因為它們都不會嘗試從所有來源定位舊記錄。這種行為等同於 upsert(存在則更新,不存在則插入)。
LSM Tree 維護#
Compaction#
Compaction 選取多個磁碟表,使用合併排序與調和演算法迭代其全部內容,將結果寫出為新表。
特性:
- 記憶體使用量有理論上界:只需保留迭代器頭部在記憶體中
- 所有內容順序讀取,合併結果也順序寫出
- 參與 compaction 的表在過程完成前仍可供讀取,因此需要足夠的磁碟空間容納新表
- 多個 compaction 可並行執行,但通常作用於不重疊的表集合
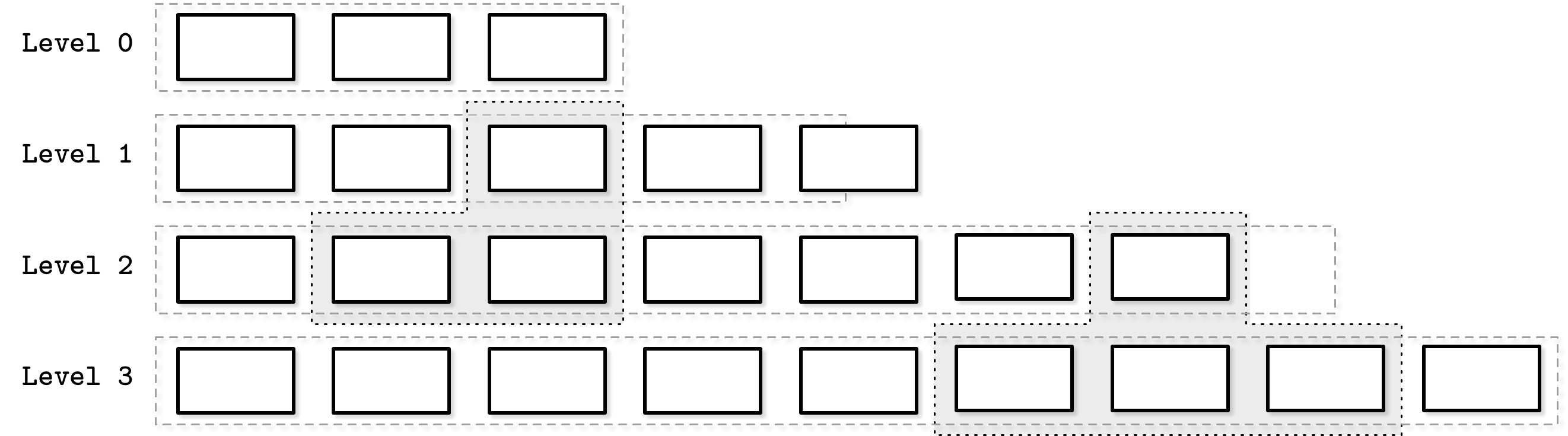
Figure 7.6: Compaction process
Tombstone 與 Compaction:compaction 期間不能立即丟棄 tombstone,因為其他表可能仍持有被 tombstone 覆蓋的舊記錄。RocksDB 保留 tombstone 直到最底層;Apache Cassandra 保留至 GC 寬限期到期(因其最終一致性需確保其他節點看到 tombstone)。過早丟棄 tombstone 會導致資料復活。
分層壓縮(Leveled Compaction)#
RocksDB 等系統使用的策略。將磁碟表按層級(level)組織:
- Level 0:由 memtable 刷出產生,key 範圍可重疊
- Level 1+:key 範圍不重疊。Level 0 的表需要被分割成不重疊的範圍後,與 Level 1 對應範圍合併
- 各層之間的大小指數增長:最新資料在最低層級,較舊資料逐漸遷移到更高層級
- 當某層的表數量達到閾值,觸發與下一層的合併
大小分層壓縮(Size-Tiered Compaction)#
依大小分組而非層級:
- 小表與小表合併,大表與大表合併
- Level 0 持有最小的表(來自 memtable 刷出或 compaction)
- 合併結果寫到持有對應大小表的層級,遞迴進行
表飢餓(Table Starvation) 問題:若 compaction 後的表仍然很小(例如記錄被 tombstone 覆蓋),較高層級可能長期得不到 compaction,其 tombstone 不被處理,增加讀取成本。此時需強制觸發 compaction。
其他策略如 Apache Cassandra 的 Time Window Compaction,適用於帶 TTL 的時間序列資料,可直接丟棄過期時間範圍的整個檔案。
讀取、寫入與空間放大#
不可變儲存面臨三個核心權衡:
| 問題 | 來源 |
|---|---|
| Read Amplification(讀取放大) | 需存取多個表才能取得完整資料 |
| Write Amplification(寫入放大) | Compaction 過程不斷重寫資料 |
| Space Amplification(空間放大) | 同一 key 的多個版本佔用空間 |
設計 compaction 策略時需在三者之間取捨:頻繁 compaction 降低讀取與空間放大,但增加寫入放大;反之,減少 compaction 則降低寫入放大,但增加讀取與空間放大。
B-Tree 與 LSM Tree 的寫入放大來源不同。B-Tree 來自回寫操作與對同一節點的重複更新;LSM Tree 來自 compaction 時將資料從一個檔案遷移到另一個。直接比較兩者可能導致錯誤結論。
RUM 猜想(RUM Conjecture)#
RUM Conjecture 考量三個因素:Read、Update、Memory 開銷。該猜想指出:降低其中兩項必然導致第三項惡化,最佳化只能以犧牲其中一項為代價。
- B-Tree:讀取最佳化。寫入需先定位記錄,預留空間增加空間開銷。
- LSM Tree:寫入最佳化。不需定位記錄,不預留額外空間,但預設讀取更昂貴。
此模型不涵蓋延遲、存取模式、實作複雜度、硬體特性、一致性等因素,但可作為初步近似與經驗法則。
實作細節#
Sorted String Tables(SSTable)#
磁碟表通常以 SSTable 實作,由兩個元件組成:
- Index file:使用 B-Tree(對數查找)或 hashtable(常數時間查找)實作,儲存 key 與資料偏移量
- Data file:按 key 排序的串接 key-value 記錄
即使使用 hashtable 索引,由於資料檔案本身已排序,range scan 仍然可行——只需定位範圍起始 key,然後順序讀取。
SSTable 的特性:
- cell 順序寫入,生命週期中不被修改
- compaction 時可順序讀取資料檔案,不需查索引
- 合併結果也是順序寫出,完成後視為不可變
SSTable-Attached Secondary Indexes(SASI):Apache Cassandra 的實作,將二級索引的生命週期與 SSTable 綁定。Memtable 刷出時同時建立二級索引檔案。記憶體中維護獨立的索引結構處理 memtable 內容。讀取時合併索引內容定位主鍵,再合併資料記錄。
Bloom Filter#
讀取放大的根源是不知道哪個磁碟表包含目標 key。Bloom Filter 是一種空間效率高的概率性資料結構,用於測試元素是否為集合成員:
- 可能產生偽陽性(false positive):報告元素在集合中,但實際不存在
- 不會產生偽陰性(false negative):若報告不在集合中,則保證不存在
運作原理:
- 使用大型位元陣列和多個雜湊函數
- 插入 key 時,計算所有雜湊函數的結果,將對應位元設為 1
- 查詢時,計算所有雜湊函數,若所有對應位元皆為 1,則回報「可能存在」
- 只要任一位元為 0,即確定「不存在」
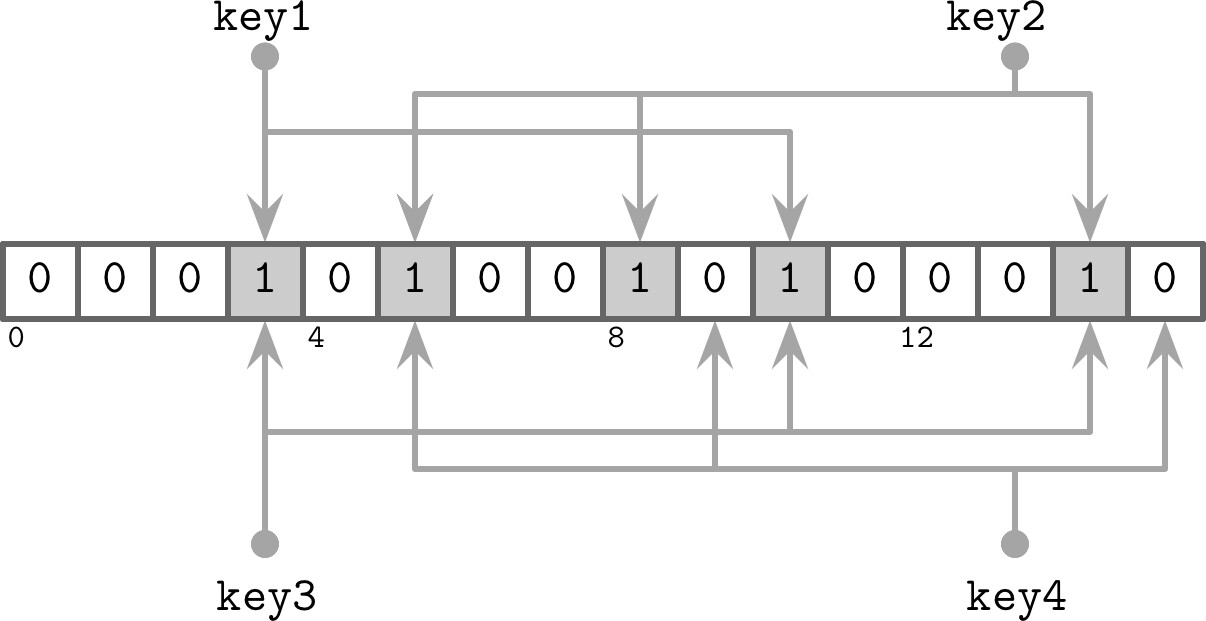
Figure 7.7: Bloom filter
偽陽性率可透過調整位元陣列大小與雜湊函數數量來控制。由於 LSM Tree 的表不可變,集合大小已知,可精確計算最佳參數。
Skiplist#
Skiplist 是一種用於記憶體中排序資料的資料結構,因其簡潔性而受到廣泛使用。
- 由一系列不同高度的節點組成,形成多層鏈結階層
- 節點高度由隨機函數決定,使用概率性平衡
- 不需要旋轉或搬移操作(相較於平衡樹)
- 各層級的節點數量指數遞減

Figure 7.8: Skiplist
查詢流程:從最高層級開始,若目標 key 大於當前節點則向前推進,若小於則下降到下一層級,遞迴直到找到目標或其前驅節點。
並行版本:使用 fully_linked 旗標搭配 CAS(compare-and-swap)實現線性化。在無管理記憶體的語言中,使用 reference counting 或 hazard pointer 確保並行存取安全。
Apache Cassandra 將 skiplist 用於二級索引的 memtable 實作;WiredTiger 在部分記憶體操作中使用 skiplist。
磁碟存取#
LSM Tree 實作通常依賴 page cache 進行磁碟存取與快取。與 B-Tree 的差異:
- 記憶體中的內容不可變,不需額外的鎖或閂鎖
- 使用 reference counting 確保正在存取的頁面不被驅逐
- 資料記錄不一定對齊頁面邊界,指標使用絕對偏移量而非頁面 ID
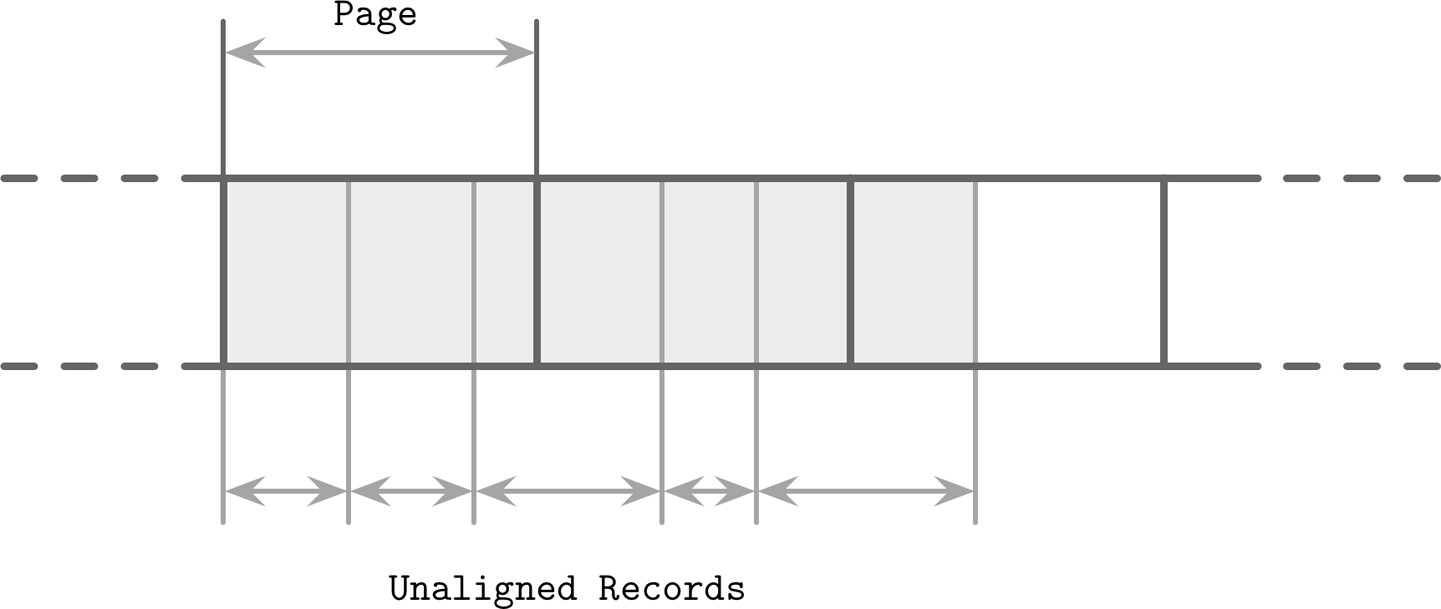
Figure 7.9: Unaligned data records
壓縮(Compression)#
LSM Tree 的壓縮與 B-Tree 類似,但因表不可變且通常一次寫入:
- 壓縮後的頁面大小不一,無法對齊頁面邊界
- 需要間接層(indirection layer)儲存壓縮頁面的偏移量與大小
- 刷出與 compaction 時順序追加壓縮頁面,壓縮資訊存於獨立檔案區段
- 讀取時查找壓縮頁面偏移量,解壓後在記憶體中實體化
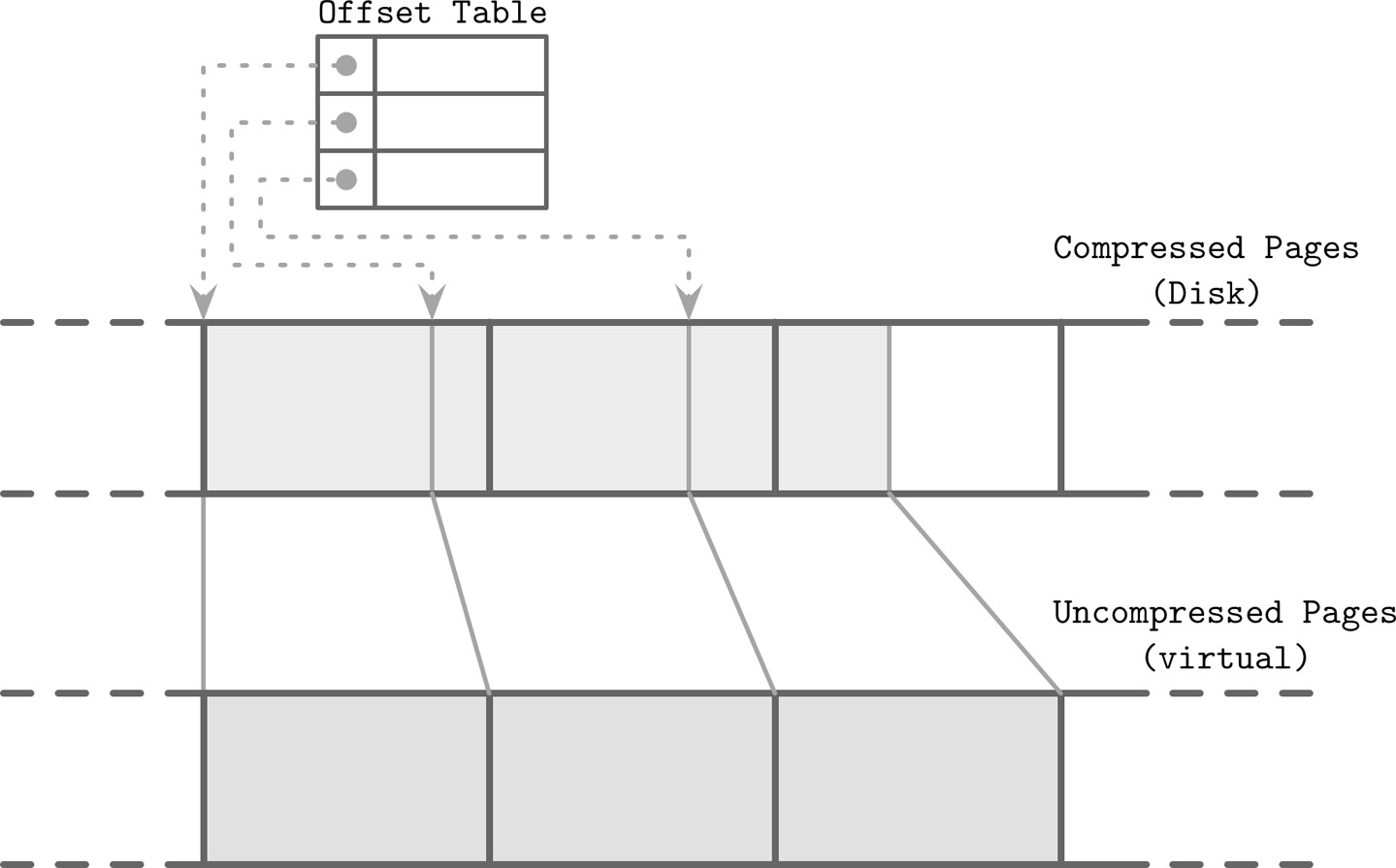
Figure 7.10: Reading compressed blocks
無序 LSM 儲存#
前面討論的結構都按 key 排序。本節探討按插入順序儲存的結構,可省去排序成本並降低寫入開銷。
Bitcask#
Bitcask 是 Riak 使用的無序 log-structured 儲存引擎,不使用 memtable,直接將記錄寫入 logfile。
- 使用 keydir(記憶體中的 hashmap)保存每個 key 最新記錄的位置
- 寫入:key 和記錄追加到 logfile,指標更新到 keydir
- 讀取:查詢 keydir 定位 key,跟隨指標讀取 logfile
- Compaction:順序讀取所有 logfile,合併後只保留最新的記錄,更新 keydir 指標
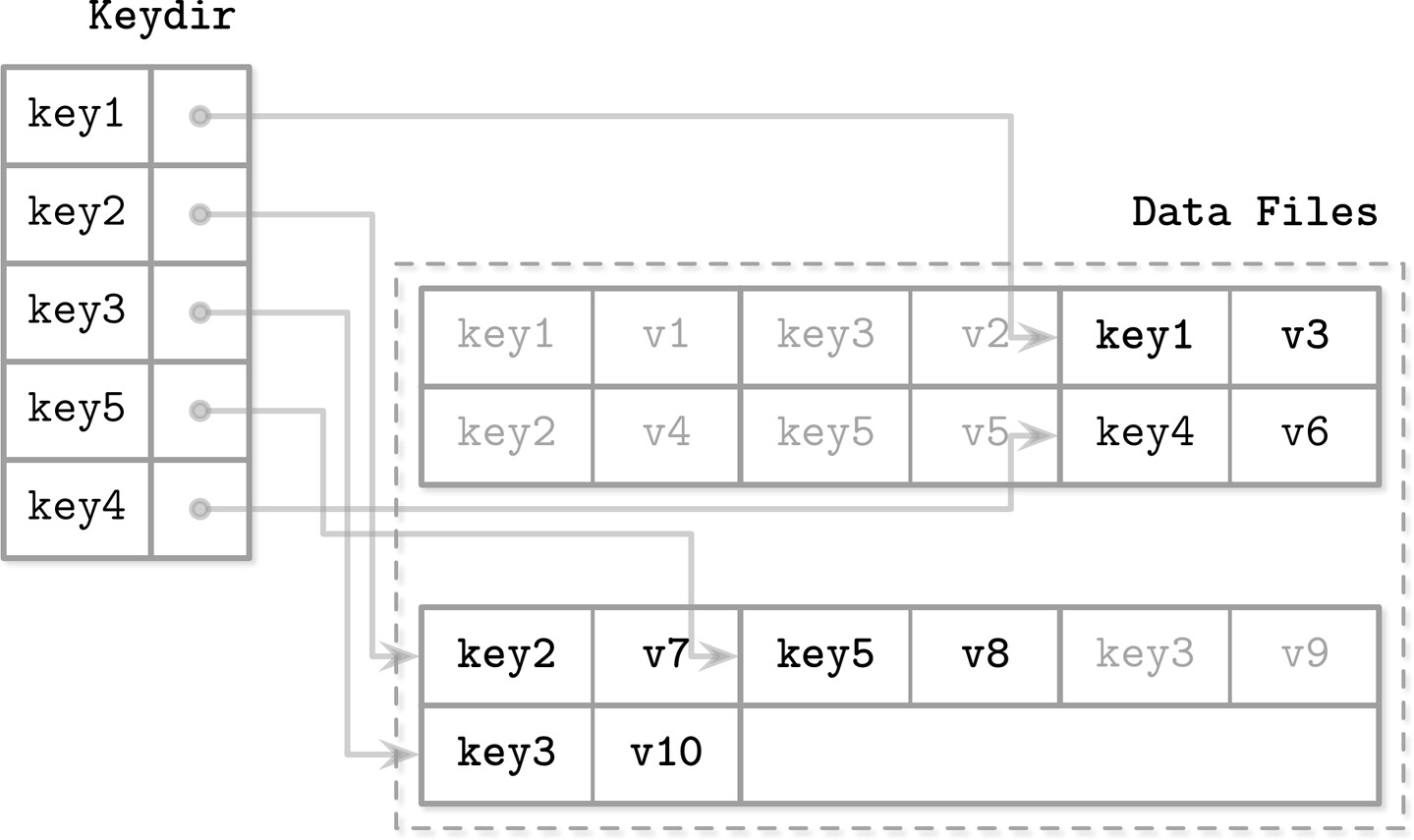
Figure 7.11: Mapping between keydir and data files in Bitcask
優勢與限制:
- 簡單且點查詢效能極佳(每個 key 在 keydir 中只有一個值)
- 不需要額外的 WAL(資料直接在 logfile 中)
- 不支援範圍查詢(keydir 和 logfile 都無序)
- 所有 key 必須放在記憶體中,啟動時需重建 keydir
WiscKey#
WiscKey 將排序與垃圾回收解耦:
- Key 儲存在排序的 LSM Tree 中
- Value 儲存在無序的追加檔案 vLog(value log)中
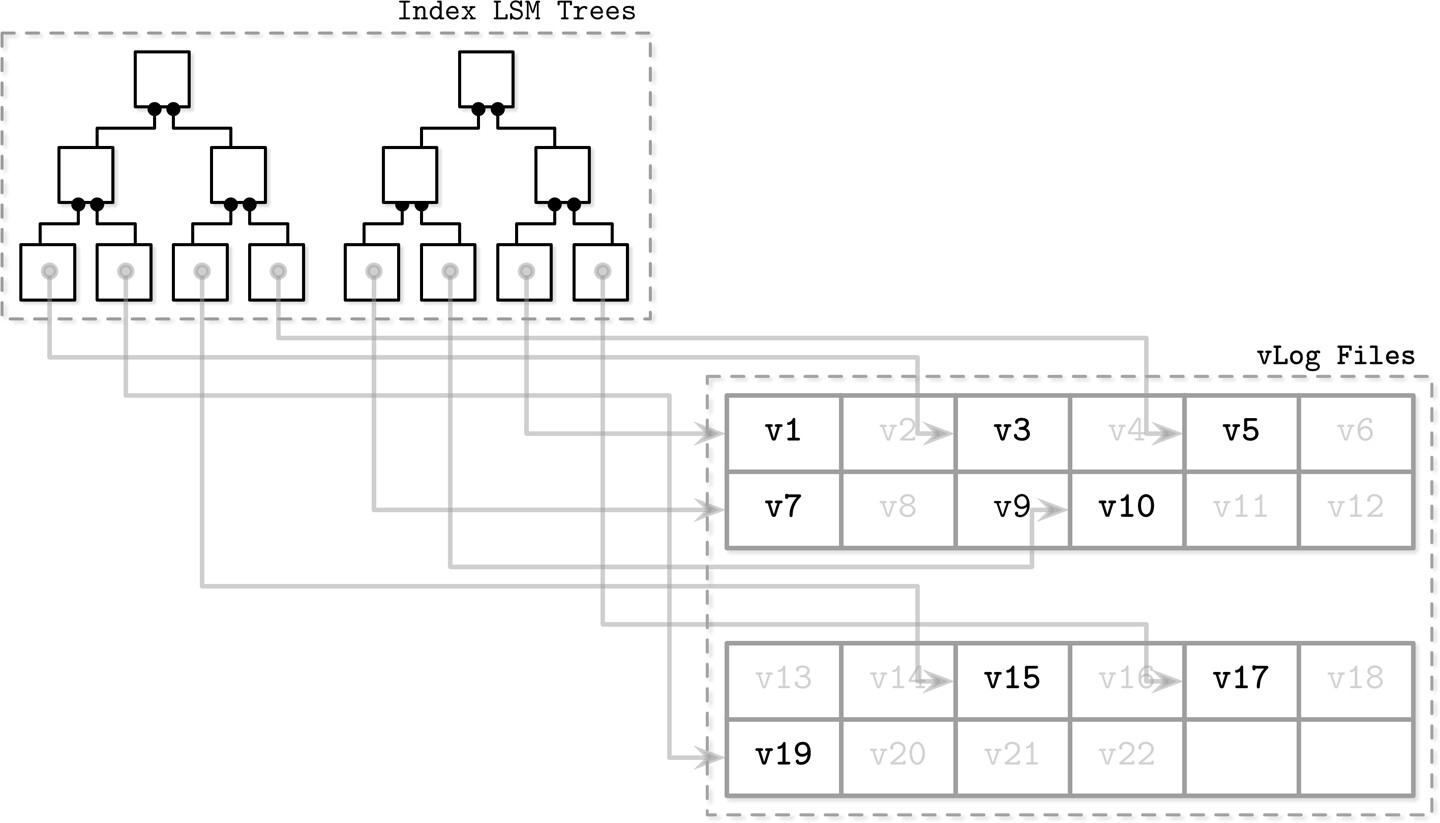
Figure 7.12: Key components of WiscKey: index LSM Trees and vLog files
由於 key 通常比 value 小得多,compaction 效率顯著提高。此方法特別適合低更新/刪除率的場景。
主要挑戰:
- vLog 無序,range scan 需要隨機 I/O
- WiscKey 利用 SSD 內部平行性預取區塊以降低成本
- 垃圾回收需查詢 key tree 判斷哪些 value 仍存活,增加複雜度
LSM Tree 的並行控制#
主要挑戰在於表視圖切換(flush 與 compaction 改變記憶體/磁碟表的集合)和日誌同步。
Flush 期間的同步點#
- Memtable 切換:新 memtable 成為主要寫入目標,舊的仍可讀取
- Flush 完成:用磁碟表取代舊 memtable(在表視圖中)
- WAL 截斷:丟棄對應已刷出 memtable 的日誌段
這些操作有嚴格的正確性要求:
- 繼續寫入舊 memtable 可能導致資料遺失(寫入已刷出的區段)
- 過早移除舊 memtable 會導致讀取結果不完整
- WAL 截斷未與 flush 同步會導致資料遺失(崩潰後日誌無法重播)
Compaction 期間#
舊磁碟表在新表完全寫入並就緒前,必須保持可讀取。需避免同一表同時參與多個並行 compaction。
Log Stacking#
許多現代檔案系統和 SSD 本身也使用 log-structured 儲存。當多層 log-structured 系統堆疊時,可能反而加劇我們試圖解決的問題。
Flash Translation Layer(FTL)#
SSD 使用 FTL 的動機:
- 小的隨機寫入需要批次合併到物理頁面
- SSD 使用 program/erase 週期:寫入只能在已清除的頁面上進行
- 單一頁面無法單獨清除,只能以區塊(block,通常 64-512 頁)為單位清除
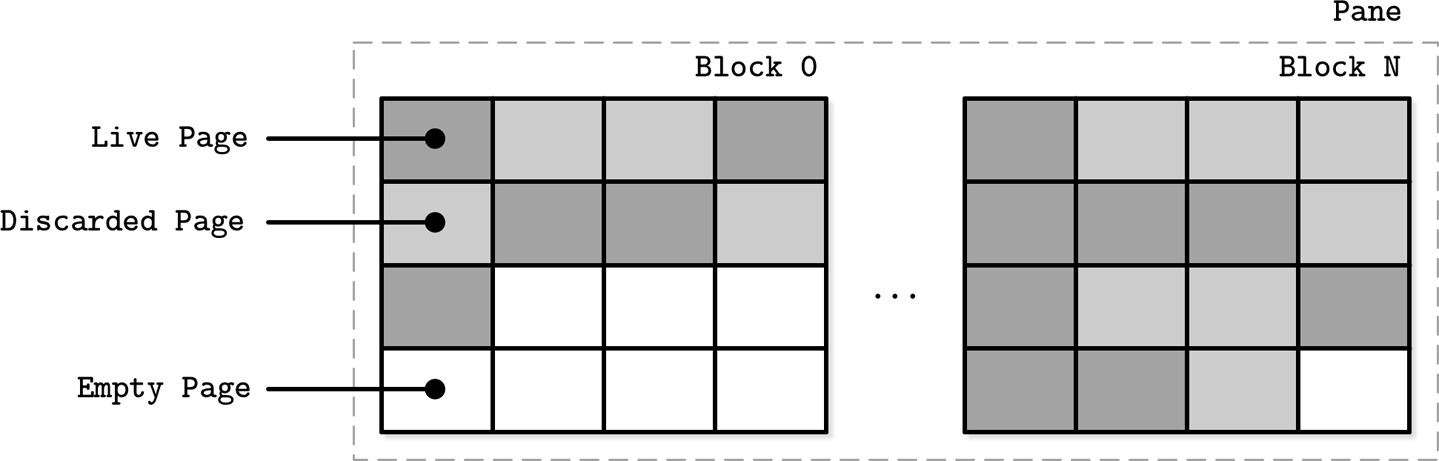
Figure 7.13: SSD pages, grouped into blocks
FTL 的垃圾回收流程:
- 當空閒頁面不足時觸發
- 將待清除區塊中仍存活的頁面搬遷到其他區塊
- 清除整個區塊,空頁面可供寫入
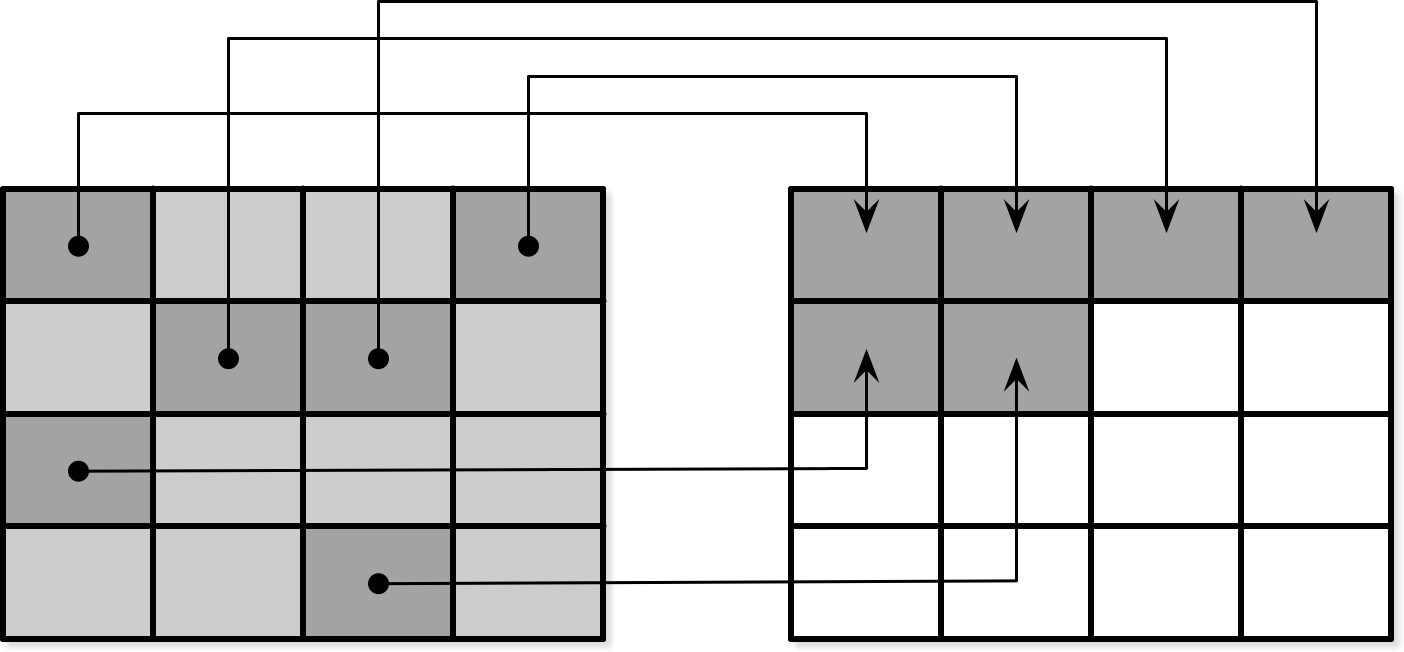
Figure 7.14: Page relocation during garbage collection
FTL 同時負責 wear leveling(磨損均衡),將負載均勻分布,避免某些區塊因過多 program-erase 週期而提前失效。
檔案系統日誌#
檔案系統也使用日誌技術做寫入緩衝。多層堆疊的問題:
- 各層執行各自的簿記(bookkeeping),底層日誌不暴露資訊給上層,導致重複工作
- 不對齊的區段寫入會導致碎片化與搬遷
- 多個寫入流(如日誌寫入與資料記錄寫入)在硬體層面交錯,實際上並非真正的順序寫入
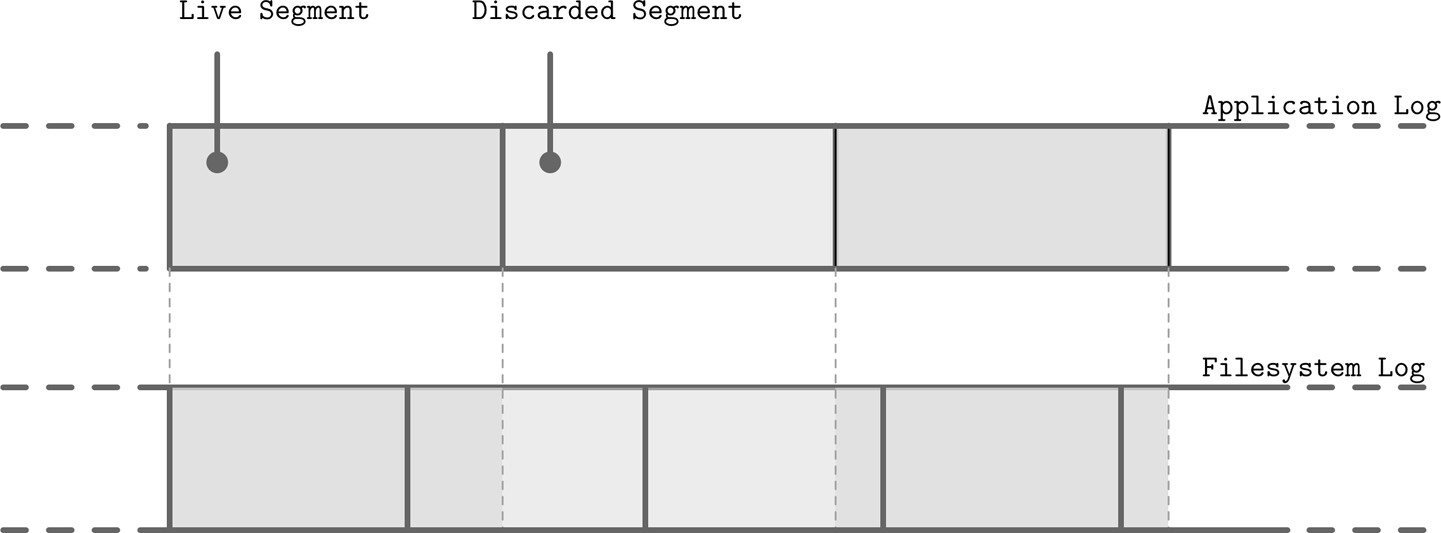
Figure 7.15: Misaligned writes and discarding of a higher-level log segment
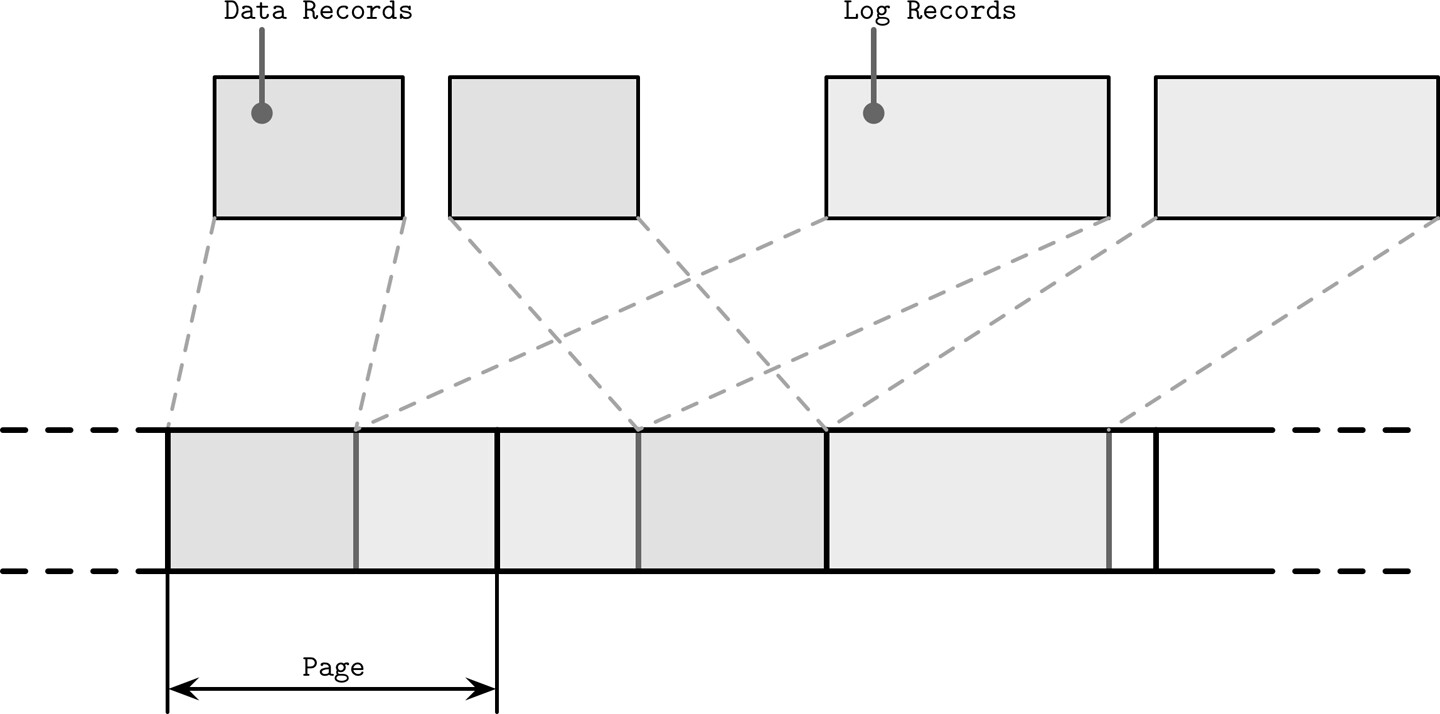
Figure 7.16: Unaligned multistream writes
建議將日誌放在獨立裝置上以隔離工作負載,且保持分割區對齊底層硬體、寫入對齊頁面大小。
LLAMA 與有意識的堆疊#
Bw-Tree 建構在 LLAMA(Latch-free, Log-structured, Access-method Aware)儲存子系統之上,展示了軟體層之間協調的好處。
LLAMA 的 access-method awareness 帶來的優勢:
- 將屬於同一邏輯節點的多個 delta node 合併寫入單一連續位置
- 若兩個 delta 互相抵消(如 insert 後 delete),可執行邏輯合併,只保留後者
- 垃圾回收時可將多個 delta 重寫為單一 base node(所有 delta 已套用),同時降低空間使用與讀取延遲
Open-Channel SSD#
跳過所有中間層直接使用硬體:
- 避免檔案系統和 FTL 的兩層日誌
- 開發者可直接控制 wear leveling、垃圾回收、資料放置與排程
- 範例:LOCS(LSM Tree-based KV Store on Open-Channel SSD)、LightNVM(Linux kernel 實作)
- Software Defined Flash(SDF) 暴露不對稱 I/O 介面,寫入單位等於清除單位(區塊),大幅降低寫入放大
總結#
- Log-Structured Storage 廣泛應用於 FTL、檔案系統到資料庫系統,透過將小的隨機寫入批次為記憶體中的順序寫入來降低寫入放大
- LSM Tree 將寫入緩衝在記憶體(memtable),刷出為不可變的磁碟表(SSTable),並透過 compaction 合併多個表、回收空間、移除過時記錄
- 不可變設計帶來並行安全與高寫入吞吐量,但讀取需合併多個來源,引入讀取放大
- Compaction 策略(leveled、size-tiered、time window 等)在讀取/寫入/空間放大之間取捨
- Bloom Filter 有效減少讀取時需存取的表數量;Skiplist 常作為 memtable 的排序結構
- 無序儲存(Bitcask、WiscKey)在特定場景下提供更高的寫入效率,但犧牲部分查詢能力
- 多層 log-structured 系統的堆疊(FTL、檔案系統、應用程式)需謹慎設計,避免重複的垃圾回收與寫入放大。透過 LLAMA 等 access-method aware 方案或 Open-Channel SSD 直接存取硬體,可有效改善堆疊問題