B-Tree 變體共享一些共同特性:樹結構、透過 split 與 merge 進行平衡,以及查找與刪除演算法。然而在並行控制、磁碟頁面表示方式、兄弟節點連結,以及維護流程等細節上,不同實作之間可能存在顯著差異。
本章討論數種可用於實作高效 B-Tree 的技術與資料結構:
- Copy-on-write B-Trees:節點不可變,頁面複製後寫入新位置,而非就地更新
- Lazy B-Trees:透過在節點上緩衝更新,減少後續對同一節點的 I/O 請求次數
- FD-Trees:採用與 LSM Tree 類似的緩衝方式,將更新緩衝在小型 B-Tree 中,再以 cascading 方式傳播至不可變的 run 中
- Bw-Trees:將節點拆分為多個較小部分,以 append-only 方式寫入,透過批次處理降低小型寫入成本
- Cache-oblivious B-Trees:允許以接近記憶體中資料結構的方式來處理磁碟上的資料結構
Copy-on-Write#
有些資料庫不使用複雜的 latch 機制,而是採用 copy-on-write 技術,在並行操作下保證資料完整性。其運作方式如下:
- 當某個頁面即將被修改時,先複製其內容
- 在複製的頁面上進行修改
- 建立一個平行的樹階層結構
- 原子性地更新指向最頂層頁面的指標
舊版本的樹仍可供與寫入者同時執行的讀取者存取。新頁面階層建立完成後,指向頂層頁面的指標被原子性地更新,並重用未被修改的頁面。
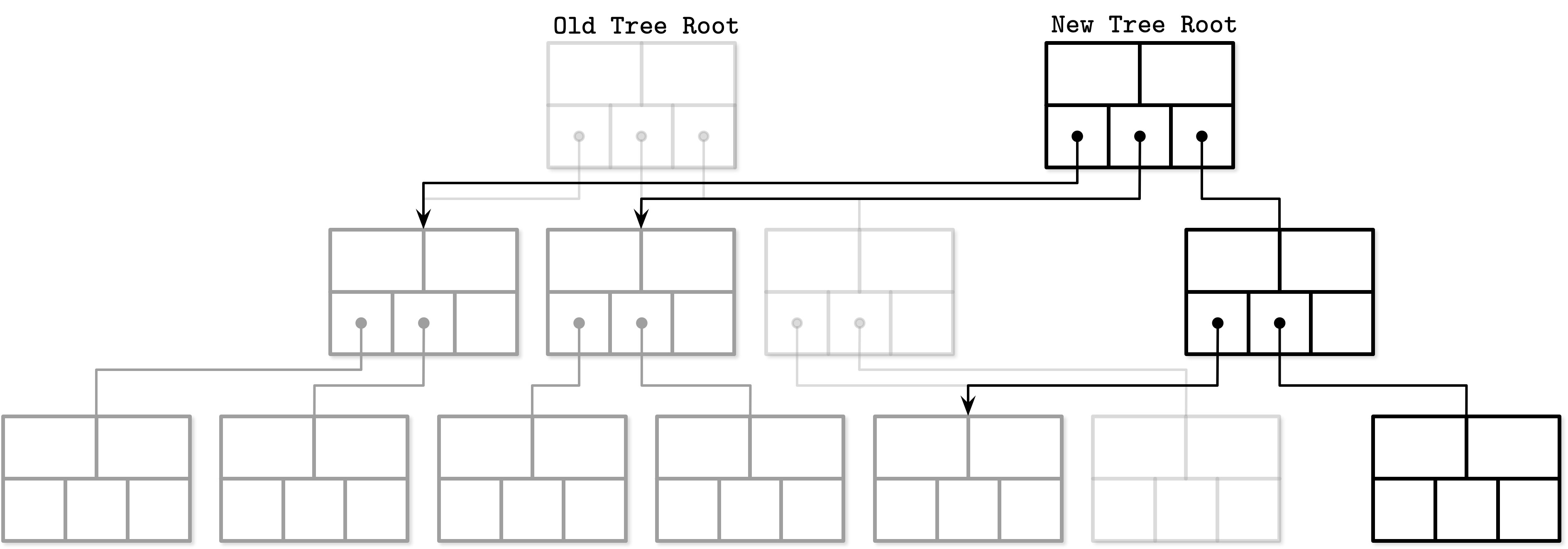
Figure 6.1: Copy-on-write B-Trees
此方式的缺點是需要更多空間(儘管舊版本僅保留短暫時間)及處理器時間(需複製整個頁面內容)。但由於 B-Tree 通常較淺,簡潔性往往足以彌補其不足。
重點: Copy-on-write 最大的優勢在於讀取者不需要任何同步機制——已寫入的頁面是不可變的,可在無需額外 latch 的情況下存取。
LMDB 實作#
LMDB(Lightning Memory-Mapped Database)是使用 copy-on-write 的儲存引擎。由於其設計架構,LMDB 不需要頁面快取、write-ahead log、checkpointing 或 compaction。
LMDB 的關鍵特性:
- 以單層資料儲存實作,讀寫操作直接透過 memory map 完成
- 更新時,從根到目標葉節點路徑上的每個分支節點都會被複製並可能被修改,其餘節點保持不變
- 只保留根節點的兩個版本
- 因為 append-only 設計,不使用 sibling pointer
Abstracting Node Updates#
更新磁碟上的頁面時,需要先更新其記憶體中的表示。節點在記憶體中的表示方式有幾種:
- 直接存取快取版本
- 透過包裝物件操作
- 建立實作語言原生的記憶體表示
補充: 磁碟頁面、快取版本及其記憶體表示可以有不同的生命週期。例如,可以緩衝 insert、update、delete 操作,並在讀取時將記憶體中的變更與原始磁碟版本進行調和(reconciliation)。
Lazy B-Trees#
有些演算法透過使用更輕量、並行友善且更新友善的記憶體結構來緩衝更新,從而降低 B-Tree 的更新成本,並延遲傳播更新。
WiredTiger#
WiredTiger 是 MongoDB 現在預設的儲存引擎。其 row store B-Tree 實作對記憶體頁面和磁碟頁面使用不同的格式,在記憶體頁面被持久化之前,需要經過 reconciliation 流程。
WiredTiger 頁面的組成結構中,一個 clean page 僅由索引組成,最初從磁碟頁面映像構建。更新會先儲存到 update buffer 中。
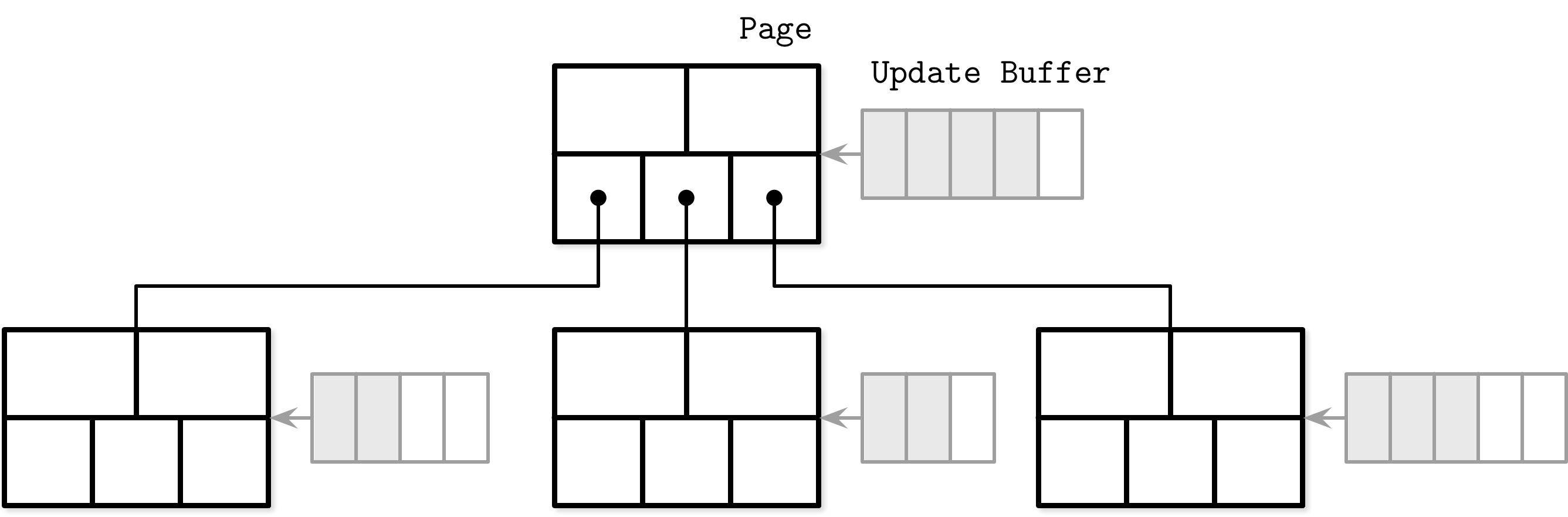
Figure 6.2: WiredTiger: high-level overview
Update buffer 的運作機制:
- 讀取時:buffer 內容與原始磁碟頁面內容合併,回傳最新資料
- Flush 時:buffer 內容與頁面內容調和並持久化到磁碟
- 實作方式:使用 skiplist,具有與搜尋樹類似的複雜度,但有更好的並行性
Clean page 和 dirty page 都有記憶體版本,並引用磁碟上的基本映像。Dirty page 還額外有一個 update buffer。
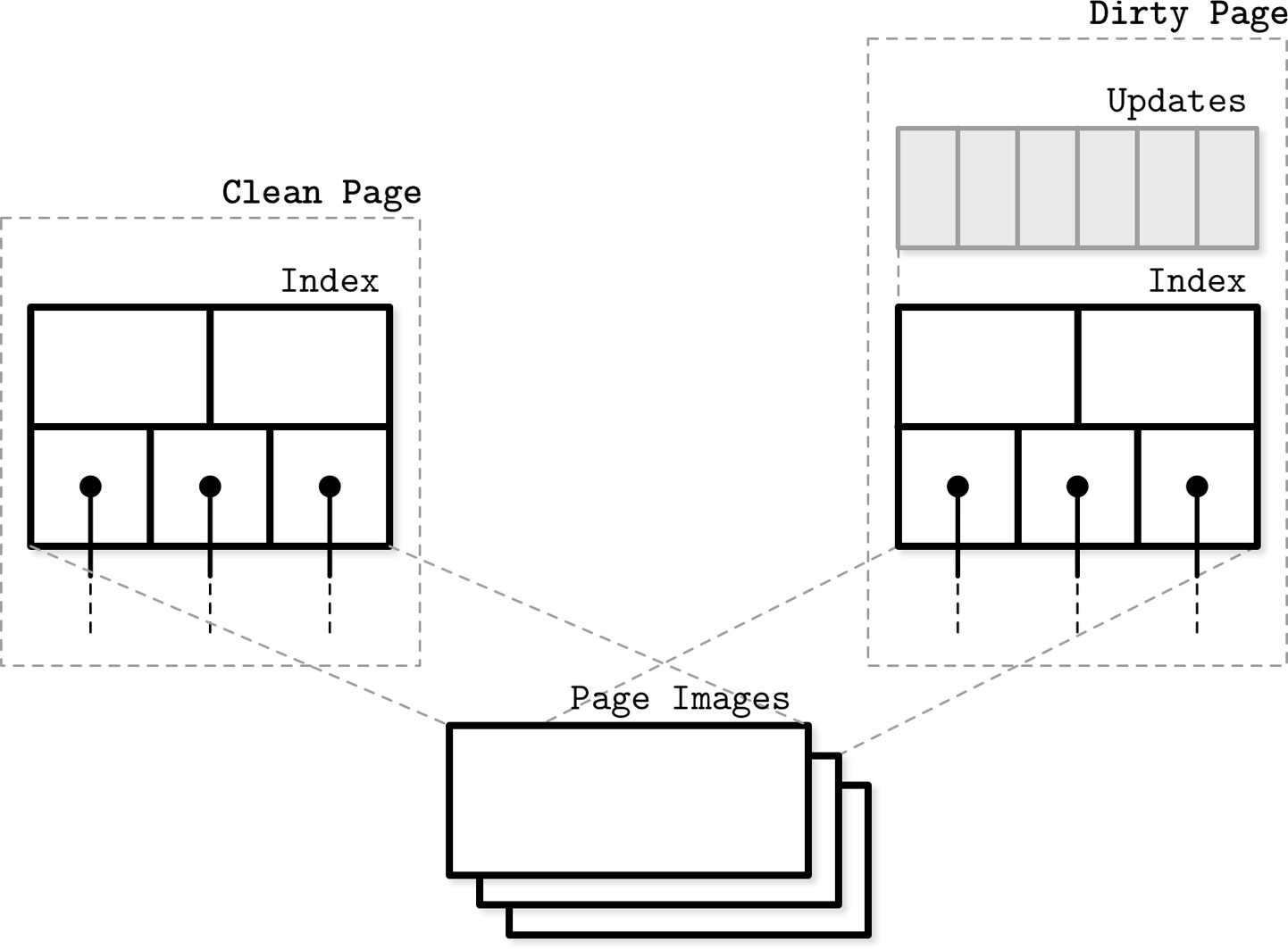
Figure 6.3: WiredTiger pages
頁面更新和結構性修改(split 與 merge)由背景執行緒執行,讀寫流程不需要等待這些操作完成。
Lazy-Adaptive Tree#
Lazy-Adaptive Tree(LA-Tree) 不是對個別節點進行緩衝,而是將節點分組為子樹,並為每個子樹附加一個 update buffer,以批次處理針對子樹頂部節點及其後代的所有操作。
更新傳播流程:
- 新項目首先被加入根節點的 update buffer
- 當 buffer 滿時,變更被複製並傳播到較低層級的 buffer
- 此操作可遞迴地持續進行,直到最終到達葉節點
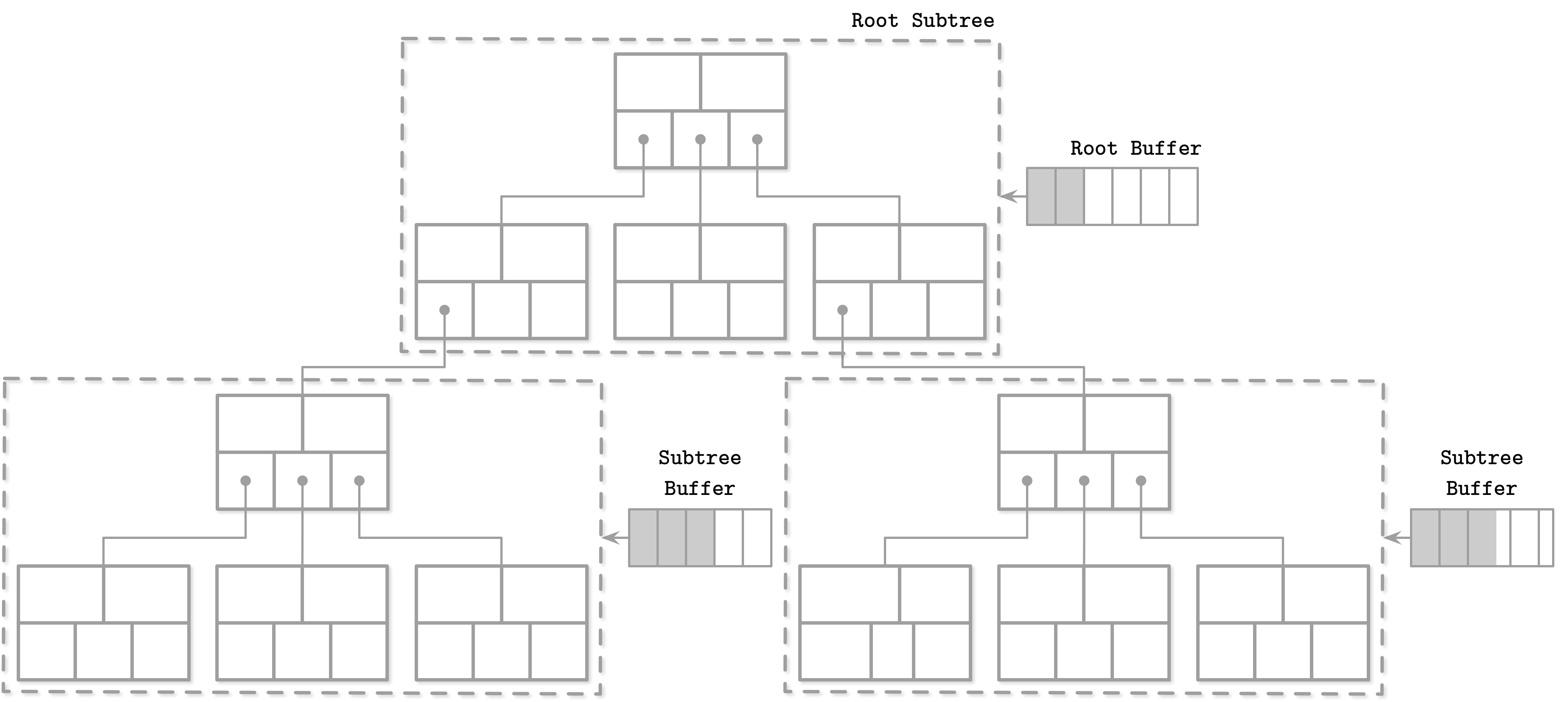
Figure 6.4: LA-Tree
Buffer 具有階層依賴關係,且是 cascaded 的:所有更新都從較高層級的 buffer 傳播到較低層級。當更新到達葉節點層級時,批次的 insert、update、delete 操作會一次性地應用所有變更到樹的內容和結構上。
FD-Trees#
緩衝是資料庫儲存中廣泛使用的概念:它幫助避免大量小型隨機寫入,改為執行單一較大的寫入。Flash Disk Tree(FD-Tree) 就是使用這種方式進行索引的一個例子。
FD-Tree 由兩個核心組件構成:
- 一個小型可變的 head tree(即一個小型 B-Tree)
- 多個不可變的排序 run
此方式將隨機寫入 I/O 限制在 head tree 的範圍內。當 head tree 填滿時,其內容會被轉移到不可變的 run 中。如果新寫入的 run 大小超過閾值,其內容會與下一層級合併,逐漸將資料記錄從上層傳播到下層。
Fractional Cascading#
為了在各層級之間維護指標,FD-Tree 使用一種稱為 fractional cascading 的技術。此方式透過在相鄰層級的排序陣列之間建立 bridge(橋接),來減少定位元素的成本。Bridge 是透過從較低層級 pull 元素到較高層級來建立的。
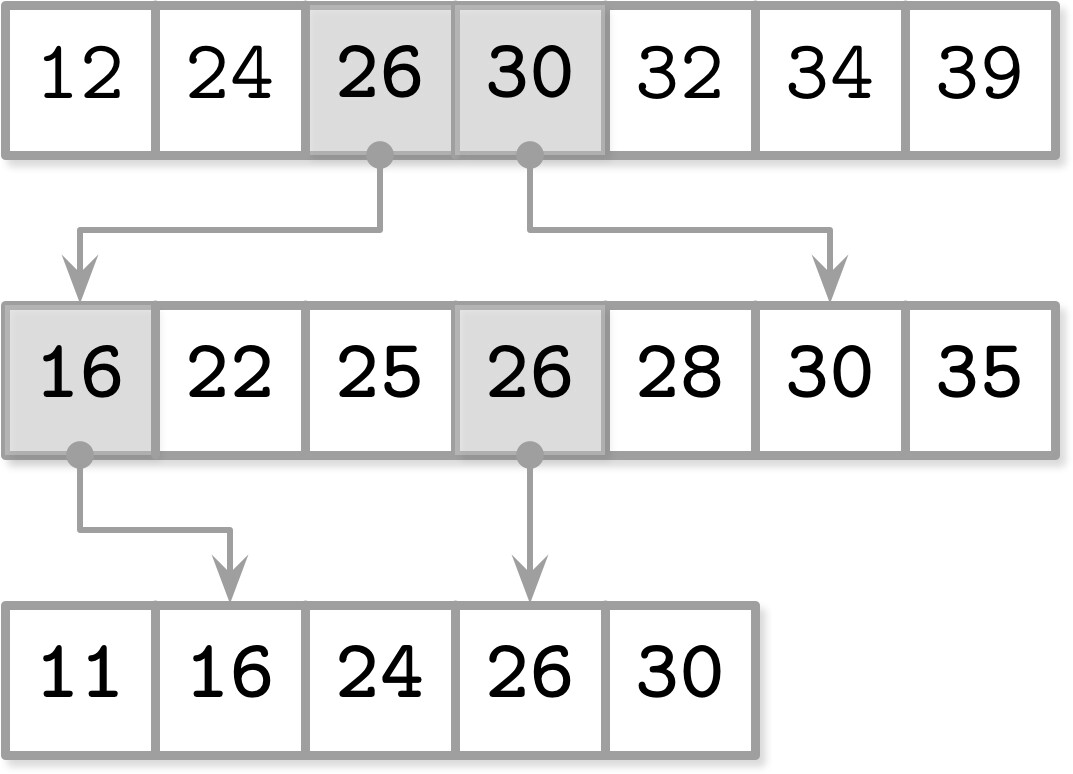
Figure 6.5: Fractional cascading
搜尋所有陣列中的元素時,在最高層級執行二元搜尋,而下一層級的搜尋空間會大幅縮減,因為我們可以透過 bridge 被導向到搜尋項目的近似位置。這使我們能夠連接多個排序 run 並降低搜尋成本。
Logarithmic Runs#
FD-Tree 結合 fractional cascading 與 logarithmically sized sorted runs(對數大小的不可變排序陣列),每層大小以因子 k 遞增,透過合併前一層級與當前層級來建立。
- 最高層級的 run 在 head tree 填滿時建立
- 較低層級的 run 在較高層級 run 的大小達到閾值時建立
補充: 此流程與 LSM Tree 中的 compaction 非常類似。
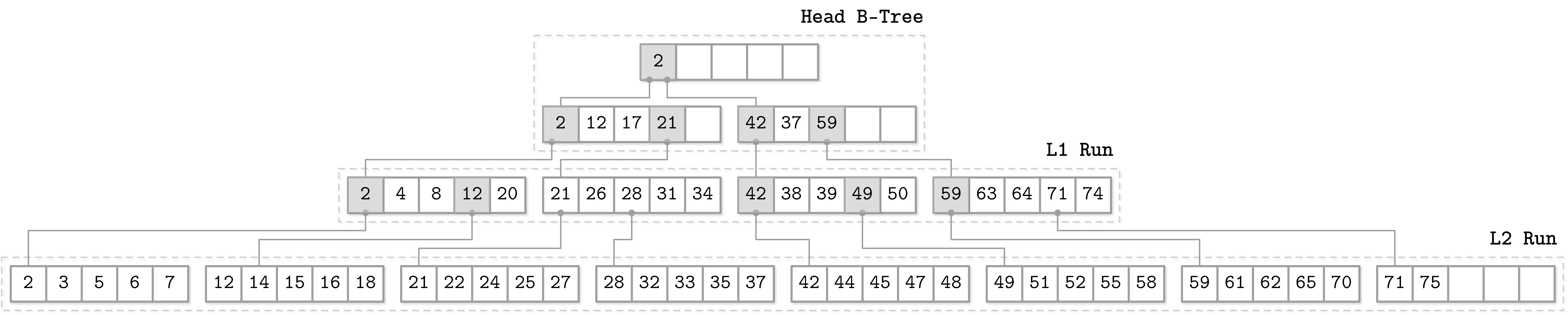
Figure 6.6: Schematic FD-Tree overview
FD-Tree 不會就地更新頁面。當同一個 key 出現在多個層級時,透過插入 tombstone(FD-Tree 論文稱之為 filter entry)來標記刪除。當 tombstone 傳播到最低層級時,即可被丟棄。
Bw-Trees#
寫入放大是 B-Tree 就地更新實作的最大問題之一。Buzzword-Tree(Bw-Tree) 採用了一種完全不同的方式來解決此問題:
- 透過 append-only 儲存,將對不同節點的更新批次連結成鏈
- 使用記憶體中的資料結構,透過單一 compare-and-swap 操作安裝節點之間的指標
- 使樹成為 lock-free
Update Chains#
Bw-Tree 將 base node 與其修改分開寫入。修改(delta node)形成一個鏈:從最新的修改到較舊的修改,再到最末端的 base node。每次更新都可以單獨儲存,不需要重寫既有節點。
典範轉換: 將節點視為邏輯而非物理實體——不需要預先分配空間、不要求節點有固定大小,甚至不需要將它們保存在連續的記憶體區段中。
透過 Compare-and-Swap 管理並行#
Bw-Tree 節點(由 delta 鏈和 base node 組成)有邏輯識別符,並使用記憶體中的 mapping table 將識別符對應到磁碟上的實際位置。使用 mapping table 也幫助消除 latch 的需求:Bw-Tree 使用 compare-and-swap 操作來更新 mapping table 中的實體偏移量。
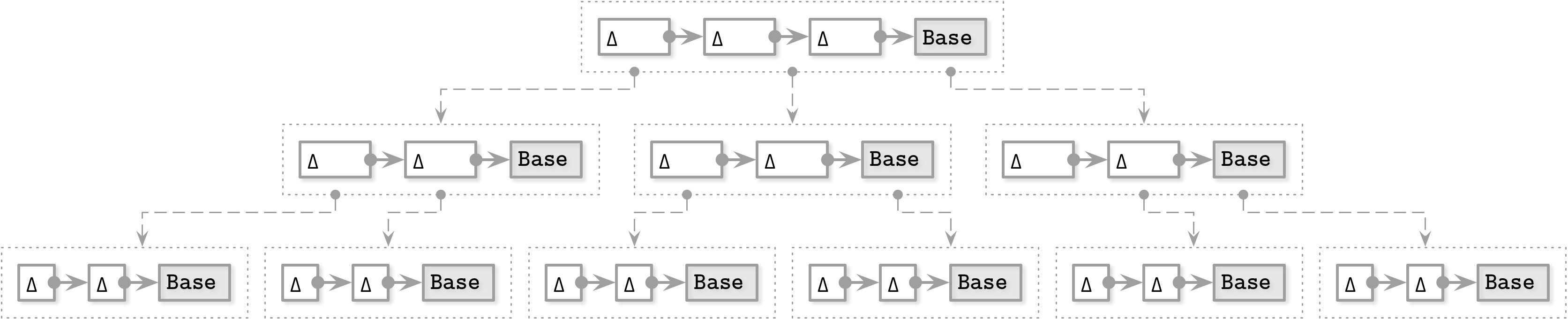
Figure 6.7: Bw-Tree
Structural Modification Operations#
Bw-Tree 在邏輯上的結構類似 B-Tree,因此節點仍可能因為過大(overflow)或過小(underflow)而需要結構修改操作(SMO),如 split 和 merge。Split SMO 會先附加一個 split delta 到正在分裂的節點上,然後更新父節點。Merge SMO 則以類似的方式運作。
Consolidation 與 Garbage Collection#
Delta 鏈可以變得任意長。當達到可配置的閾值時,需要透過合併 base node 和所有 delta 來重建節點(consolidation)。Bw-Tree 使用 epoch-based reclamation 來追蹤活躍頁面並安全地進行垃圾回收。
Cache-Oblivious B-Trees#
區塊大小、節點大小、cache line 對齊等可配置參數都會影響 B-Tree 效能。Cache-oblivious 資料結構可以在不需要知道底層記憶體階層參數的情況下,提供漸近最優的效能。
傳統上我們從兩層記憶體階層(page cache 和 disk)的角度來看 B-Tree。Cache-oblivious 演算法則允許以兩層記憶體模型來推理資料結構,同時提供多層階層的效益。
van Emde Boas Layout#
Cache-oblivious B-Tree 由一棵靜態 B-Tree 和一個 packed array 結構組成。靜態 B-Tree 使用 van Emde Boas layout 建構:在樹的邊的中間層級進行分割,然後以類似方式遞迴分割每個子樹,使得任何遞迴子樹都儲存在連續的記憶體區塊中。
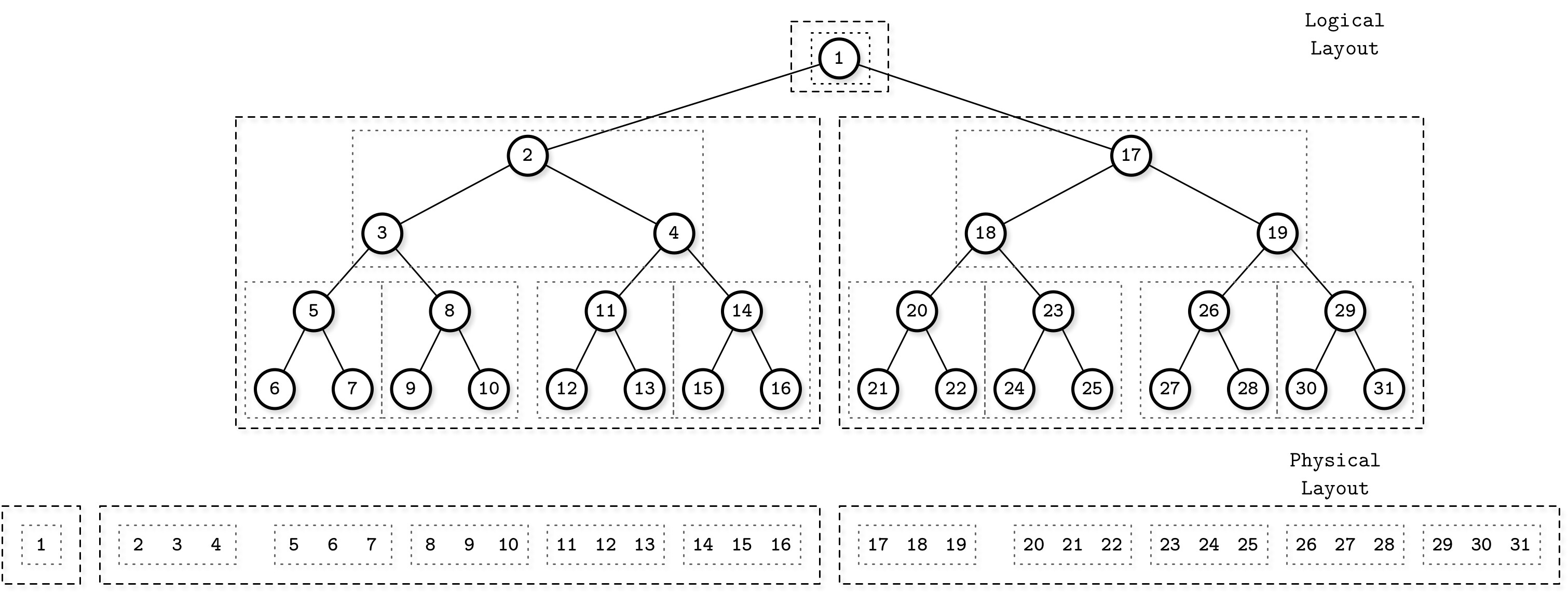
Figure 6.8: van Emde Boas layout
為了支援動態操作(insert、update、delete),cache-oblivious tree 使用 packed array 資料結構——以連續記憶體區段儲存元素,但保留間隙供未來插入使用。

Figure 6.9: Packed array
此方式允許以較少的重定位將項目插入樹中。當 packed array 變得太密或太稀疏時,需要重建結構以調整大小。靜態樹作為底層 packed array 的索引,需要根據重定位的元素進行更新。
總結#
原始 B-Tree 設計在旋轉磁碟上運作良好,但在 SSD 上效率較低,主要面臨兩大問題:高 write amplification(因頁面重寫)和高 space overhead(需預留空間給未來寫入)。
各變體的解決策略:
- Write amplification → 透過緩衝降低:Lazy B-Tree(如 WiredTiger 和 LA-Tree)將記憶體 buffer 附加到節點或節點群組上,緩衝後續更新,減少 I/O 次數
- Space amplification → 透過不可變性降低:FD-Tree 將資料記錄儲存在不可變的排序 run 中,限制可變 B-Tree 的大小
- 兩者兼顧 → Bw-Tree 將節點與更新儲存在不同磁碟位置,持久化在 log-structured store 中,同時透過 compare-and-swap 消除 latch 需求